Adobe、MAXカンファレンスで画期的な音声合成システム、VoCoをスニーク・プレビュー
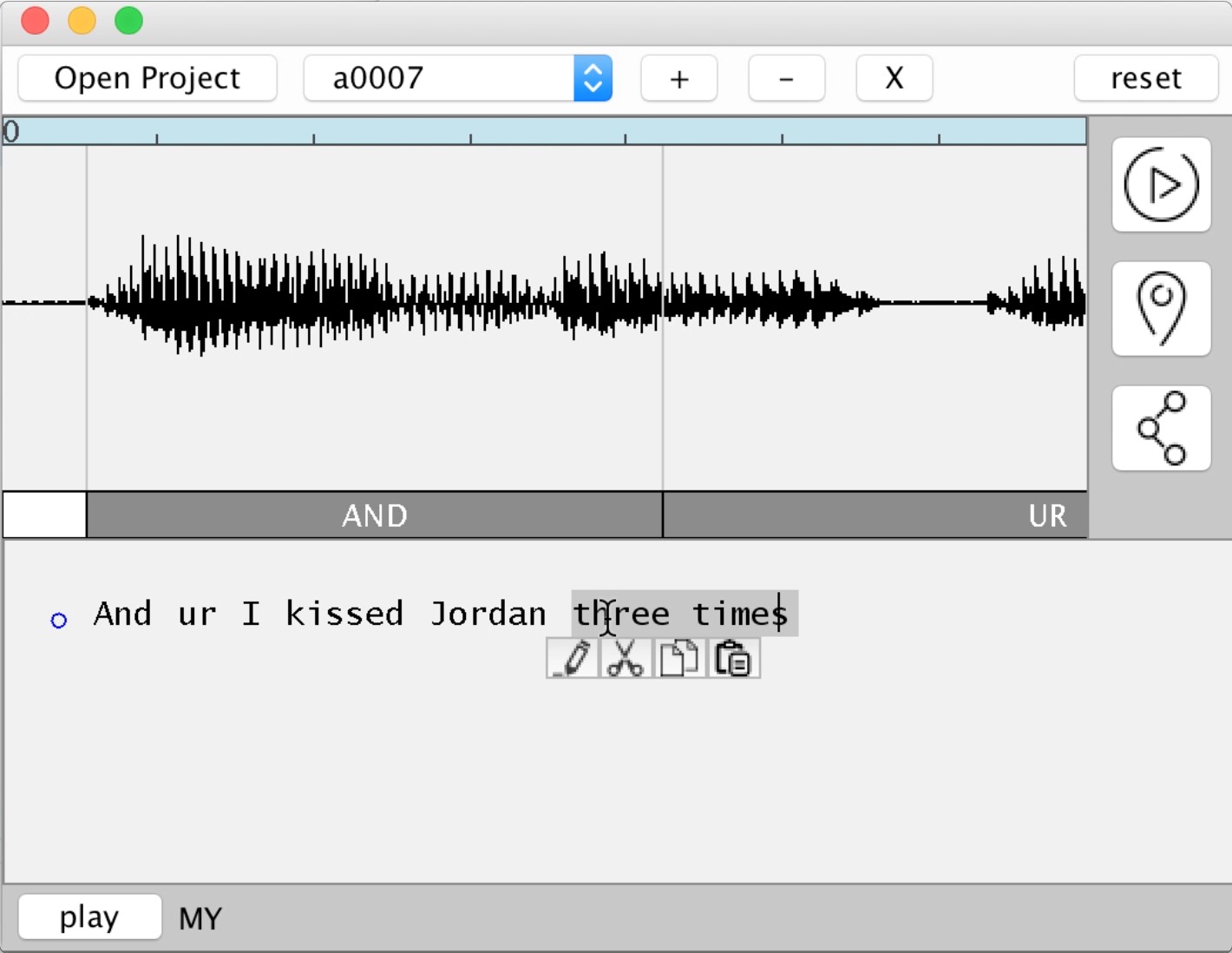
今日(米国時間11/3)、Adobeはサンディエゴで開催中のMAXカンファレンスで開発中のプロジェクト、VoCoのプレビューを公開した。VoCoは音声をテキストと同様に簡単に編集することができる。それも既存の録音された音声を編集できるだけでなく、十分な音声データさえあれば、このシステムはまったく新しい発言を作り出すこともできる。
作動の仕組みは簡単に言えばこうだ。プロジェクトVoCoはまずそれぞれの話者につき20分程度の音声サンプルを必要とする。システムは音声素材を分析し、個々の音素(フォニーム)を抽出して音声モデルを作成する。VoCoのユーザーはこの音素を用いて新しい文章を発生させることができる。現段階では、耳をすませば、どこが編集された部分なのか、違いを聞き取れる。しかし実際の録音と生成された発言(つまりフェイク)との違いが判別できなくなる日も遠くないかもしれない。

今日のデモは小人数のプレスが対象だったが、Adobeの説明によればVoCoは従来の音声合成システムとはまったく異なるテクノロジーだという。Adobeはこれをvoice conversionと名付けている(したがってVoCoだ)。 注目すべき点は、ユーザーがマニュアルで音声データを細かく修正する必要がほとんどないところだろう。もちろんテキストから自動生成された音声データをさらに自然に聞こえるようにするために手を加えることはできる。しかしたとえば編集のためにタイムスタンプを改めて設定するなどの必要はまったくない。こうしたことはすべてアルゴリズムが自動的にやってくれる。
このデモを見ると当然さまざまな疑問が湧いてくる。たとえば、近い将来、本人が喋ったとしか思われない録音を聞いてもそれが本物であるかどうか確信がもてない事態が訪れるのだろうか? もちろん純然たるテクノロジー上の見地からすればCoVoは画期的なシステムだ。
CoVoが紹介されたのと同じプレス・イベントでAdobeはさらに2種類の編集プロジェクトをデモした。Project Quick Layoutは―名前どおり―印刷物のレイアウトの編集を簡単にする。Project CloverはVR環境中で対象物を編集できるVRツールだった。
これらすべて「スニーク・プレビュー」で、Adobeは将来一般に利用できる商用プロダクトになることを約束しているわけではない。しかしこれまでの例をみると、こうしたブロジェクトの多くはAdobeのプロダクト中に活かされてきた。
[原文へ]
(翻訳:滑川海彦@Facebook Google+)