こちらの記事をご覧いただきありがとうございます。
以前スクレイピングの基本の記事を投稿しました。こちらの記事では、スクレイピングを使ってSUUMOの物件情報を自動取得したその過程を書きます。
ご覧いただいた皆様に学びがあれば幸いです。
↓が私が以前投稿したスクレイピングの記事です。こちらの記事ではスクレイピングの技術的な話を書くつもりはあまりないので、スクレイピングの手法はこちらをご確認ください。
SUUMO とは
SUUMOとは国内最大手の不動産情報サイトです。↓にURLを載せておきます。
僕も東京に引越しをするときの物件探しでSUUMOを使いました。希望の条件を細かく指定することができて、かつたくさんの物件から探すことができるので、とてもありがたかったです。ロフトとかバルコニーがあるといいなーと思っておりましたもので(結局家賃に負けてついてない物件にしましたが)。
沿線で探せるのはもちろん
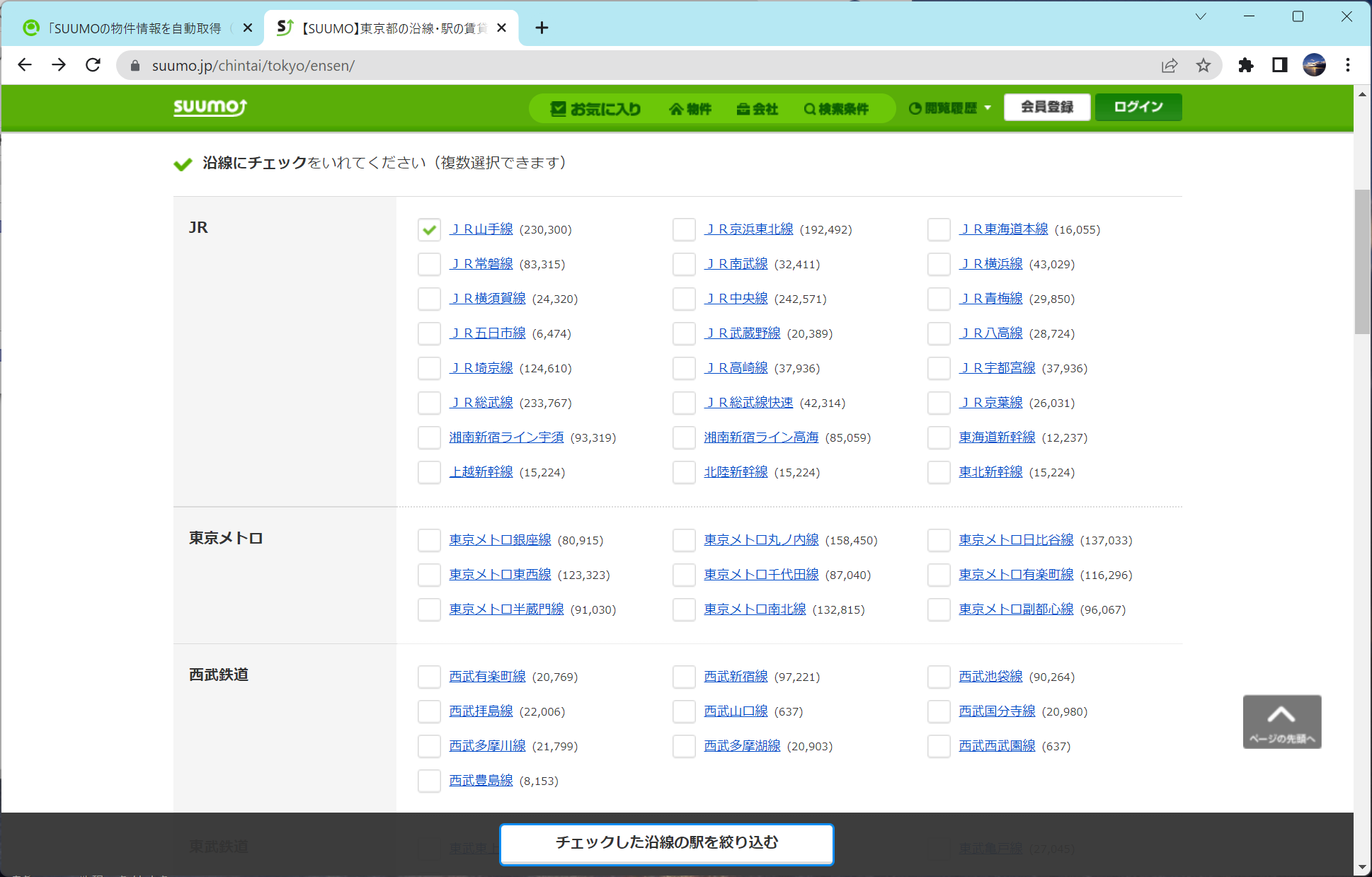
家賃、駅徒歩、間取り、築年数、などももちろん…
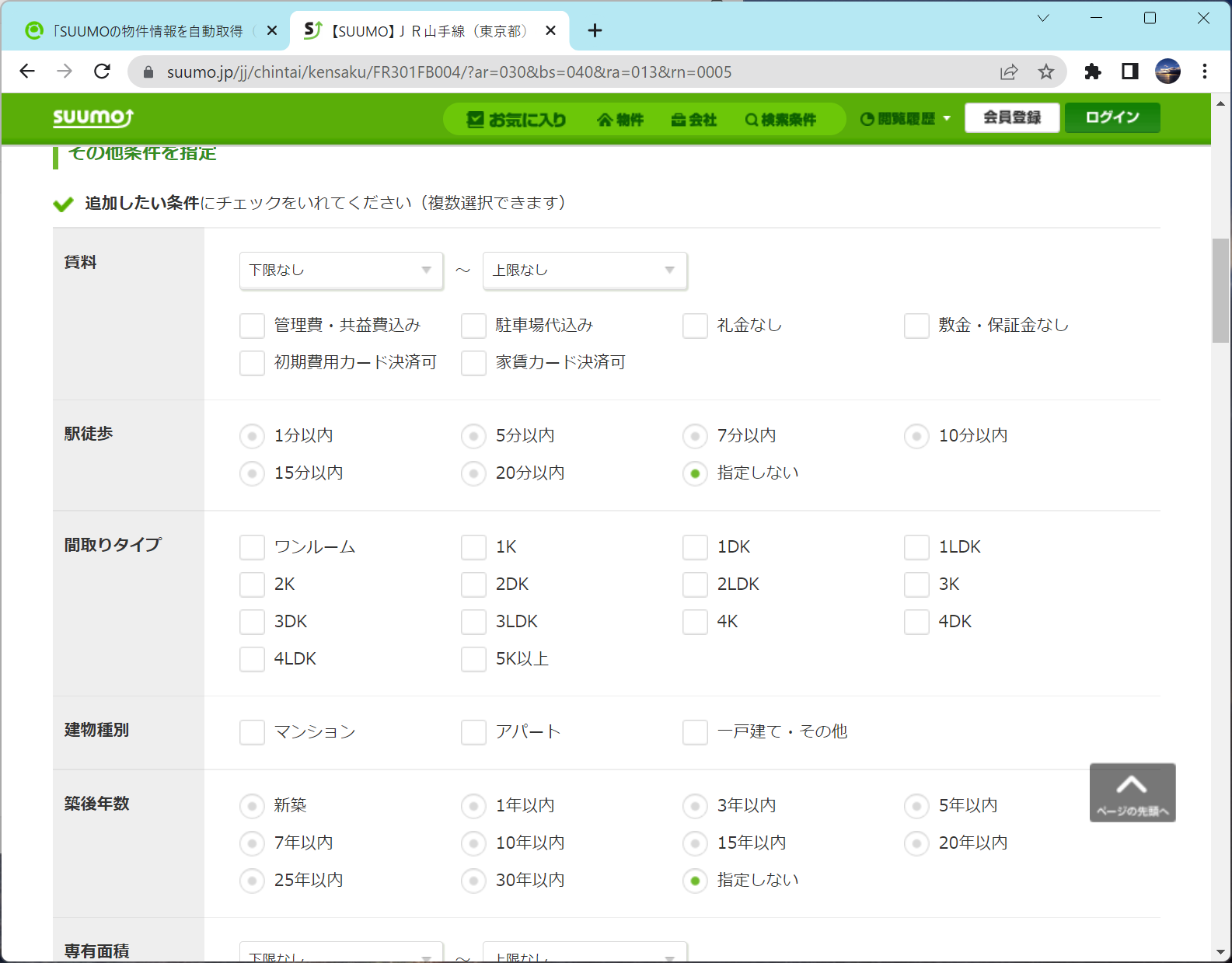
結構細かい条件も指定できる
使い勝手が良いのもそうですが、スクレイピングする視点だと構造がキレイでやりやすいって点もよいところでした。実際にスクレイピングしてみると実感できると思います。
物件情報をスクレイピングする
では早速スクレイピングをした過程の話を進めます。
SUUMOに登録されている全物件をスクレイピングするとたぶん膨大な量になりかねないので、都内23区だけに絞ります。23区で条件指定して検索した物件を表示します。
23区の物件を検索
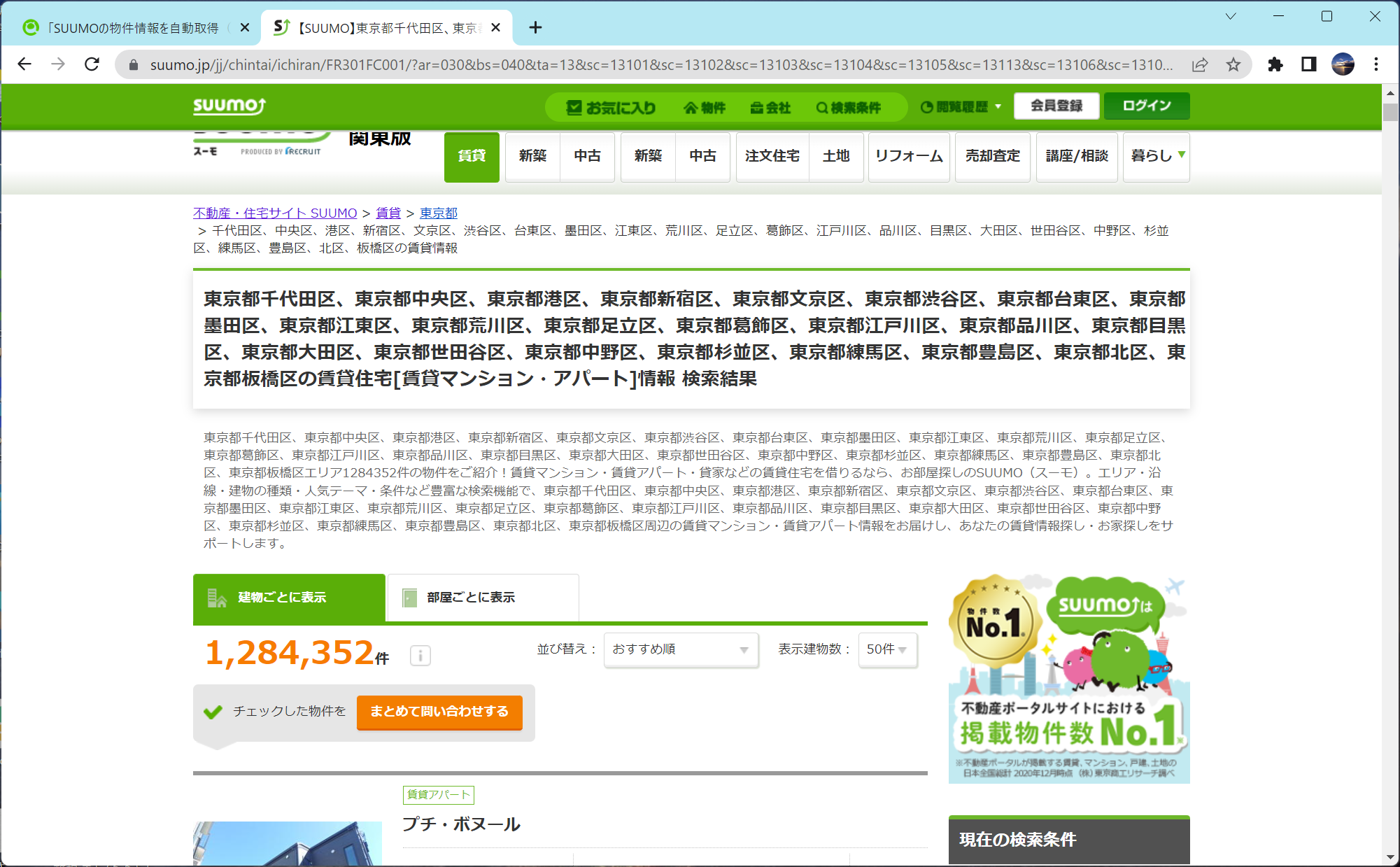
全部で1,284,352件もあるんですね。これを全部スクレイピングしようとしたら、このページだけでなく2ページ目以降もスクレイピングする必要があります。何ページあるんでしょうか?
※実際にスクレイピングすると22万件くらいしか取得できませんでした。これの理由はよくわかりませんでした。。
全部で2920ページあるらしい
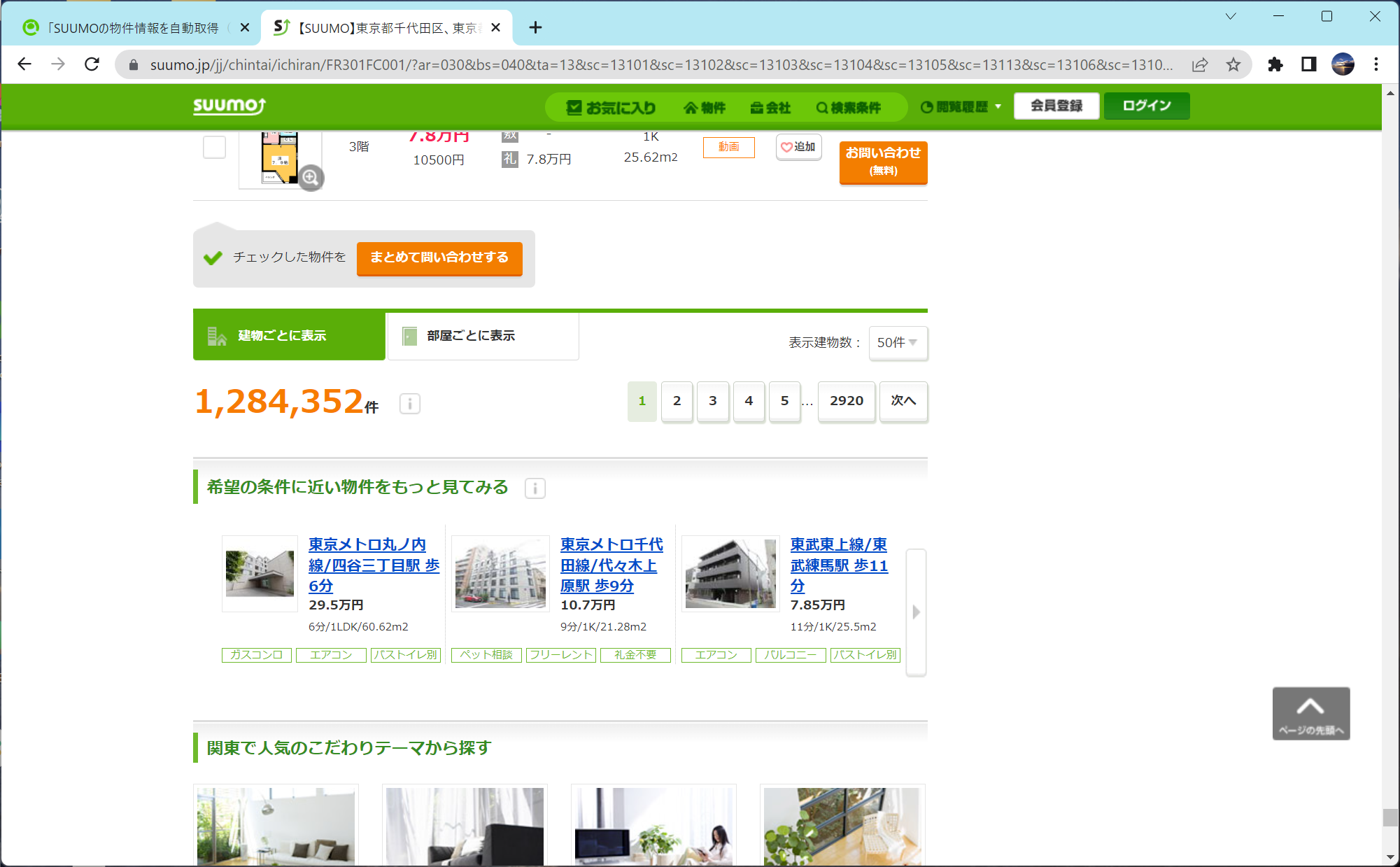
全部で2920ページもあるんですね。これを全部スクレイピングすると結構な時間になりそう…?。実際にスクレイピングした結果、かかった時間はおよそ5時間くらいでした。これくらいなら許容範囲でしょうか?
もう一つ、データを取り出す範囲ですが、検索結果に出てくる情報のみ取り出しました。物件詳細のリンク先からさらに情報を取り出すことも考えましたが、実際にやろうとしたら結構な時間がかかるっぽかったので…(推定10日くらいかかる計算でした。23区じゃなくて新宿だけに絞るとかならアリかもしれませんね)。
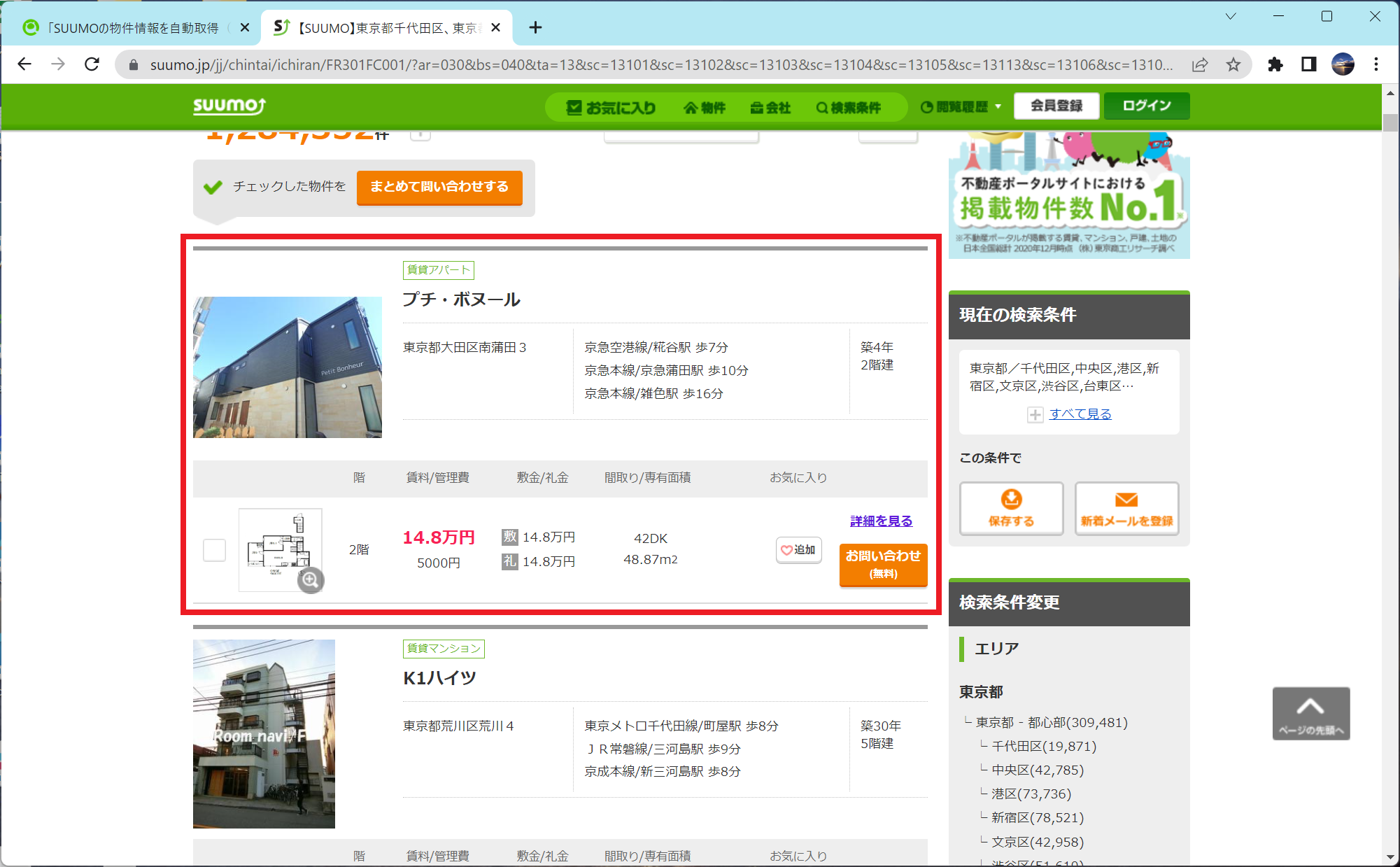
赤枠の情報だけ取り出す
スクレイピングのコードと解説
ここからは実際に自分がスクレイピングした時のコードをご紹介します。先に全体を出しますが結構長いです。あとから要所ごとに解説します。
まずは必要なライブラリです。
import requests
from bs4 import BeautifulSoup
from retry import retry
import urllib
import time
ここからスクレイピングするコードです。
(変数の命名がいろいろ怪しいですが気にしないでください)
# 複数ページの情報をまとめて取得
data_samples = []
# スクレイピングするページ数
max_page = 2000
# SUUMOを東京都23区のみ指定して検索して出力した画面のurl(ページ数フォーマットが必要)
url = 'https://suumo.jp/jj/chintai/ichiran/FR301FC001/?ar=030&bs=040&ta=13&sc=13101&sc=13102&sc=13103&sc=13104&sc=13105&sc=13113&sc=13106&sc=13107&sc=13108&sc=13118&sc=13121&sc=13122&sc=13123&sc=13109&sc=13110&sc=13111&sc=13112&sc=13114&sc=13115&sc=13120&sc=13116&sc=13117&sc=13119&cb=0.0&ct=9999999&mb=0&mt=9999999&et=9999999&cn=9999999&shkr1=03&shkr2=03&shkr3=03&shkr4=03&sngz=&po1=25&pc=50&page={}'
# リクエストがうまく行かないパターンを回避するためのやり直し
@retry(tries=3, delay=10, backoff=2)
def load_page(url):
html = requests.get(url)
soup = BeautifulSoup(html.content, 'html.parser')
return soup
# 処理時間を測りたい
start = time.time()
times = []
# ページごとの処理
for page in range(1,max_page+1):
before = time.time()
# ページ情報
soup = load_page(url.format(page))
# 物件情報リストを指定
mother = soup.find_all(class_='cassetteitem')
# 物件ごとの処理
for child in mother:
# 建物情報
data_home = []
# カテゴリ
data_home.append(child.find(class_='ui-pct ui-pct--util1').text)
# 建物名
data_home.append(child.find(class_='cassetteitem_content-title').text)
# 住所
data_home.append(child.find(class_='cassetteitem_detail-col1').text)
# 最寄り駅のアクセス
children = child.find(class_='cassetteitem_detail-col2')
for id,grandchild in enumerate(children.find_all(class_='cassetteitem_detail-text')):
data_home.append(grandchild.text)
# 築年数と階数
children = child.find(class_='cassetteitem_detail-col3')
for grandchild in children.find_all('div'):
data_home.append(grandchild.text)
# 部屋情報
rooms = child.find(class_='cassetteitem_other')
for room in rooms.find_all(class_='js-cassette_link'):
data_room = []
# 部屋情報が入っている表を探索
for id_, grandchild in enumerate(room.find_all('td')):
# 階
if id_ == 2:
data_room.append(grandchild.text.strip())
# 家賃と管理費
elif id_ == 3:
data_room.append(grandchild.find(class_='cassetteitem_other-emphasis ui-text--bold').text)
data_room.append(grandchild.find(class_='cassetteitem_price cassetteitem_price--administration').text)
# 敷金と礼金
elif id_ == 4:
data_room.append(grandchild.find(class_='cassetteitem_price cassetteitem_price--deposit').text)
data_room.append(grandchild.find(class_='cassetteitem_price cassetteitem_price--gratuity').text)
# 間取りと面積
elif id_ == 5:
data_room.append(grandchild.find(class_='cassetteitem_madori').text)
data_room.append(grandchild.find(class_='cassetteitem_menseki').text)
# url
elif id_ == 8:
get_url = grandchild.find(class_='js-cassette_link_href cassetteitem_other-linktext').get('href')
abs_url = urllib.parse.urljoin(url,get_url)
data_room.append(abs_url)
# 物件情報と部屋情報をくっつける
data_sample = data_home + data_room
data_samples.append(data_sample)
# 1アクセスごとに1秒休む
time.sleep(1)
# 進捗確認
# このページの作業時間を表示
after = time.time()
running_time = after - before
times.append(running_time)
print(f'{page}ページ目:{running_time}秒')
# 取得した件数
print(f'総取得件数:{len(data_samples)}')
# 作業進捗
complete_ratio = round(page/max_page*100,3)
print(f'完了:{complete_ratio}%')
# 作業の残り時間目安を表示
running_mean = np.mean(times)
running_required_time = running_mean * (max_page - page)
hour = int(running_required_time/3600)
minute = int((running_required_time%3600)/60)
second = int(running_required_time%60)
print(f'残り時間:{hour}時間{minute}分{second}秒\n')
# 音を出す
def sound():
!rundll32 user32.dll,MessageBeep
# 処理時間を測りたい
finish = time.time()
running_all = finish - start
print('総経過時間:',running_all)
sound()
…長いですね。もっと効率の良い書き方をご存じの方はぜひご教授ください。
このコードは大きく4パートに分かれます。
- スクレイピングの準備
- スクレイピングで情報を取得
- 進捗を表示
- 最後に処理時間を計算して表示
それぞれ分けて解説します。
スクレイピングの準備
準備の部分のコードは以下となります。
# 複数ページの情報をまとめて取得
data_samples = []
# スクレイピングするページ数
max_page = 2000
# SUUMOを東京都23区のみ指定して検索して出力した画面のurl(ページ数フォーマットが必要)
url = 'https://suumo.jp/jj/chintai/ichiran/FR301FC001/?ar=030&bs=040&ta=13&sc=13101&sc=13102&sc=13103&sc=13104&sc=13105&sc=13113&sc=13106&sc=13107&sc=13108&sc=13118&sc=13121&sc=13122&sc=13123&sc=13109&sc=13110&sc=13111&sc=13112&sc=13114&sc=13115&sc=13120&sc=13116&sc=13117&sc=13119&cb=0.0&ct=9999999&mb=0&mt=9999999&et=9999999&cn=9999999&shkr1=03&shkr2=03&shkr3=03&shkr4=03&sngz=&po1=25&pc=50&page={}'
# リクエストがうまく行かないパターンを回避するためのやり直し
@retry(tries=3, delay=10, backoff=2)
def load_page(url):
html = requests.get(url)
soup = BeautifulSoup(html.content, 'html.parser')
return soup
# -15行目まで-
このうち、
# 複数ページの情報をまとめて取得
data_samples = []
これはスクレイピングした情報を貯めておくための空リストです。
# スクレイピングするページ数
max_page = 2000
# SUUMOを東京都23区のみ指定して検索して出力した画面のurl(ページ数フォーマットが必要)
url = 'https://suumo.jp/jj/chintai/ichiran/FR301FC001/?ar=030&bs=040&ta=13&sc=13101&sc=13102&sc=13103&sc=13104&sc=13105&sc=13113&sc=13106&sc=13107&sc=13108&sc=13118&sc=13121&sc=13122&sc=13123&sc=13109&sc=13110&sc=13111&sc=13112&sc=13114&sc=13115&sc=13120&sc=13116&sc=13117&sc=13119&cb=0.0&ct=9999999&mb=0&mt=9999999&et=9999999&cn=9999999&shkr1=03&shkr2=03&shkr3=03&shkr4=03&sngz=&po1=25&pc=50&page={}'
これはスクレイピングするurlと、最大ページ数です。
urlの後ろの方を見ると、page={}という部分があります。formatの形式で{}に数字を入れてページ遷移を作っています。
最大数を2000で入れてありますが、SUUMOで2000ページ以降を開いても検索結果が表示されない仕様になっているっぽいです。2900くらいページがありましたがそこまでやる意味がありませんでした。
# リクエストがうまく行かないパターンを回避するためのやり直し
@retry(tries=3, delay=10, backoff=2)
def load_page(url):
html = requests.get(url)
soup = BeautifulSoup(html.content, 'html.parser')
return soup
これはページ情報を取得する関数と、うまく行かなかったときのリトライ機能です。ページ情報の取得については省略します。以前書いたスクレイピング基本の記事に書いてあります。
リトライ機能について、アクセスがうまく行かない時にやり直せるように付けてあります。普段Googleとかで検索したページを開いてもなんか知らないけど開けないことってあると思います。で何回かやり直すとちゃんと開ける。それをしてもらうためのretryです。
retryの詳しい使い方は↓をご覧ください。
スクレイピングで情報を取得
続いては実際にページにアクセスして情報を取得する部分です。
# -19行目から-
# ページごとの処理
for page in range(1,max_page+1):
before = time.time()
# ページ情報
soup = load_page(url.format(page))
# 物件情報リストを指定
mother = soup.find_all(class_='cassetteitem')
# 物件ごとの処理
for child in mother:
# 建物情報
data_home = []
# カテゴリ
data_home.append(child.find(class_='ui-pct ui-pct--util1').text)
# 建物名
data_home.append(child.find(class_='cassetteitem_content-title').text)
# 住所
data_home.append(child.find(class_='cassetteitem_detail-col1').text)
# 最寄り駅のアクセス
children = child.find(class_='cassetteitem_detail-col2')
for id,grandchild in enumerate(children.find_all(class_='cassetteitem_detail-text')):
data_home.append(grandchild.text)
# 築年数と階数
children = child.find(class_='cassetteitem_detail-col3')
for grandchild in children.find_all('div'):
data_home.append(grandchild.text)
# 部屋情報
rooms = child.find(class_='cassetteitem_other')
for room in rooms.find_all(class_='js-cassette_link'):
data_room = []
# 部屋情報が入っている表を探索
for id_, grandchild in enumerate(room.find_all('td')):
# 階
if id_ == 2:
data_room.append(grandchild.text.strip())
# 家賃と管理費
elif id_ == 3:
data_room.append(grandchild.find(class_='cassetteitem_other-emphasis ui-text--bold').text)
data_room.append(grandchild.find(class_='cassetteitem_price cassetteitem_price--administration').text)
# 敷金と礼金
elif id_ == 4:
data_room.append(grandchild.find(class_='cassetteitem_price cassetteitem_price--deposit').text)
data_room.append(grandchild.find(class_='cassetteitem_price cassetteitem_price--gratuity').text)
# 間取りと面積
elif id_ == 5:
data_room.append(grandchild.find(class_='cassetteitem_madori').text)
data_room.append(grandchild.find(class_='cassetteitem_menseki').text)
# url
elif id_ == 8:
get_url = grandchild.find(class_='js-cassette_link_href cassetteitem_other-linktext').get('href')
abs_url = urllib.parse.urljoin(url,get_url)
data_room.append(abs_url)
# 物件情報と部屋情報をくっつける
data_sample = data_home + data_room
data_samples.append(data_sample)
# 1アクセスごとに1秒休む
time.sleep(1)
# -81行目まで-
…長いですね。構造がわかりやすいように少し簡略化します。
# ページごとの処理
for page in range(1,max_page+1):
# ページ情報
soup = load_page(url.format(page))
# 物件情報リストを指定
mother = soup.find_all(class_='cassetteitem')
# 物件ごとの処理
for child in mother:
# 建物情報
# 以下を欲しい情報の分だけ書きます
data_home.append('''物件情報を取得するコード''')
# 部屋情報
rooms = child.find(class_='cassetteitem_other')
for room in rooms.find_all(class_='js-cassette_link'):
data_room = []
# 部屋情報が入っている表を探索
for id_, grandchild in enumerate(room.find_all('td')):
# 以下を欲しい情報の分だけ書きます
if id_ == '''数字''':
data_room.append('''部屋情報を取得するコード''')
# 物件情報と部屋情報をくっつける
data_sample = data_home + data_room
data_samples.append(data_sample)
# 1アクセスごとに1秒休む
time.sleep(1)
多少マシになったでしょうか。それでは解説します。ページを開いてデベロッパーツールを確認しながら見ていただくとわかりやすい気がします。
まず検索結果のページの構造を確認します。
物件情報の構造
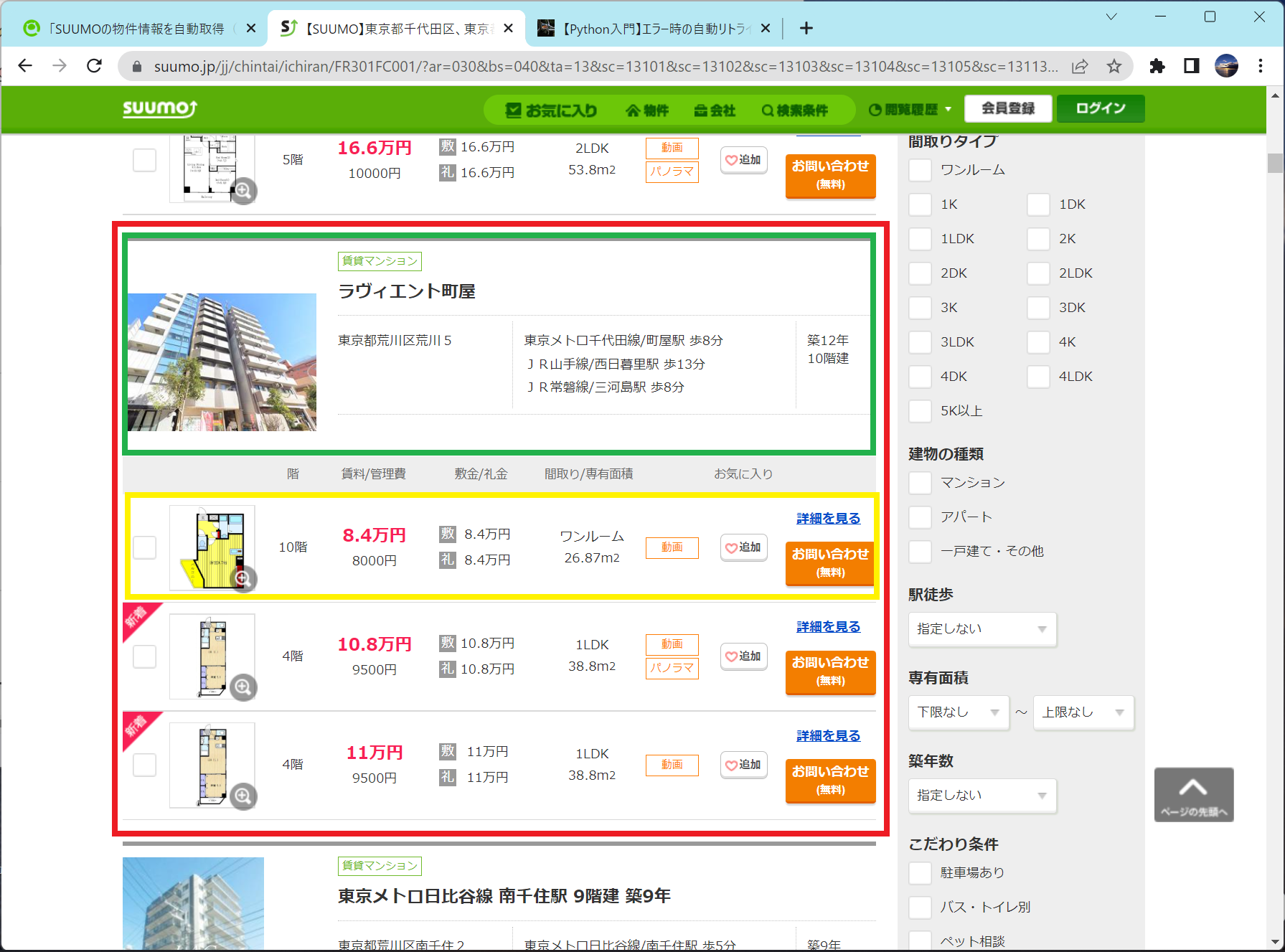
上の画像のうち、赤が物件ごとの情報です。赤枠が物件ごとに繰り返し表示されています。
緑が建物の情報です。黄色が建物内の部屋情報です。建物によっては空き部屋がたくさんあります。
先ほどのコードにはforループが3つあります。1つ目がページごとに処理を行うループ、2つ目が建物ごと(赤枠)に処理するループ、3つ目が部屋ごと(黄色枠)ごとに処理を行うループです。
雑に書くとこんな感じです。
for ページ in ページ全部:
ページ情報を取得
for 建物 in ページ内の建物全部:
建物情報(緑枠)を取得
for 部屋 in 建物:
部屋情報(黄色枠)を取得
建物情報と部屋情報をくっつけてリストに保存
1秒休憩
欲しい情報の取り出し方について、建物情報はclassを指定すればいいので簡単です。部屋情報は表に入っているだけでclassがないので、find_all('td')でまとめて取り出して必要なところだけ後から抜き取ります。URLの情報は相対パスで取得できるのでurllibで絶対パスに変換します。
一応休憩時間を付けています。ページ情報の取得と保存でそこそこの処理時間だったので必要性は薄いのかもしれませんが、forループがうまく機能しなかったときに連続アクセスすることになってしまうので予防は必要だと思います。
進捗を表示
結構な処理時間でちゃんと進んでいるか心配になってしまったので取り付けました。
# -19行目から-
# ページごとの処理
for page in range(1,max_page+1):
before = time.time()
# -24~80行省略-
# 進捗確認
# このページの作業時間を表示
after = time.time()
running_time = after - before
times.append(running_time)
print(f'{page}ページ目:{running_time}秒')
# 取得した件数
print(f'総取得件数:{len(data_samples)}')
# 作業進捗
complete_ratio = round(page/max_page*100,3)
print(f'完了:{complete_ratio}%')
# 作業の残り時間目安を表示
running_mean = np.mean(times)
running_required_time = running_mean * (max_page - page)
hour = int(running_required_time/3600)
minute = int((running_required_time%3600)/60)
second = int(running_required_time%60)
print(f'残り時間:{hour}時間{minute}分{second}秒\n')
# -100行目まで-
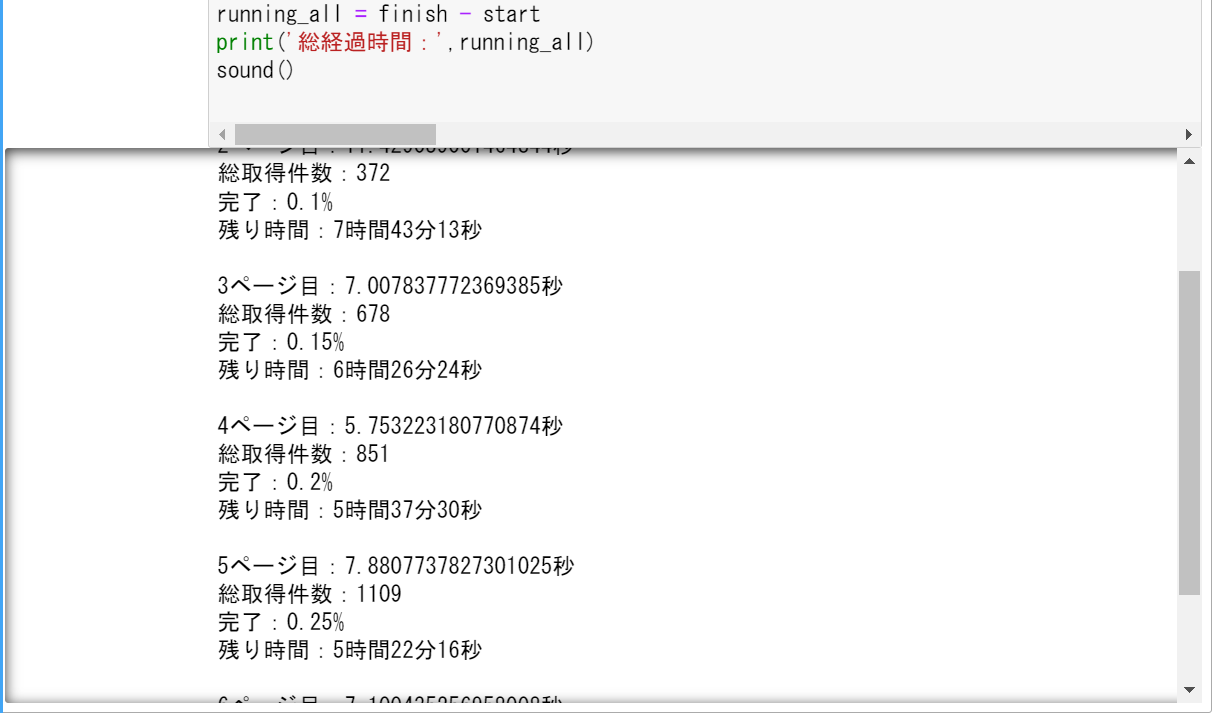
1ページ終わるごとに、
- 何ページ処理が完了したか
- このページの処理にどのくらい時間がかかったか
= ページごとのループ内処理終了時間 - 開始時間 - 取得した物件の総数
- 全体の何割進んだか = 完了したページ数 / 全ページ数
- 残り時間の目安 = これまでの1ページ処理時間の平均 * 残りのページ数
を表示してくれます。
進捗の表示
最後に処理時間を計算して表示
最後に全体でかかった処理時間を表示できるようにしました。
# -15行目から-
# 処理時間を測りたい
start = time.time()
times = []
# 20~99行省略
# 音を出す
def sound():
!rundll32 user32.dll,MessageBeep
# 処理時間を測りたい
finish = time.time()
running_all = finish - start
print('総経過時間:',running_all)
sound()
これは処理開始前と終了後の時間を測って全体の処理時間を計算しています。また、処理完了時に通知音が出るようにしました。
通知音については↓を参考(コピペ)して作りました。ぜひご覧ください。
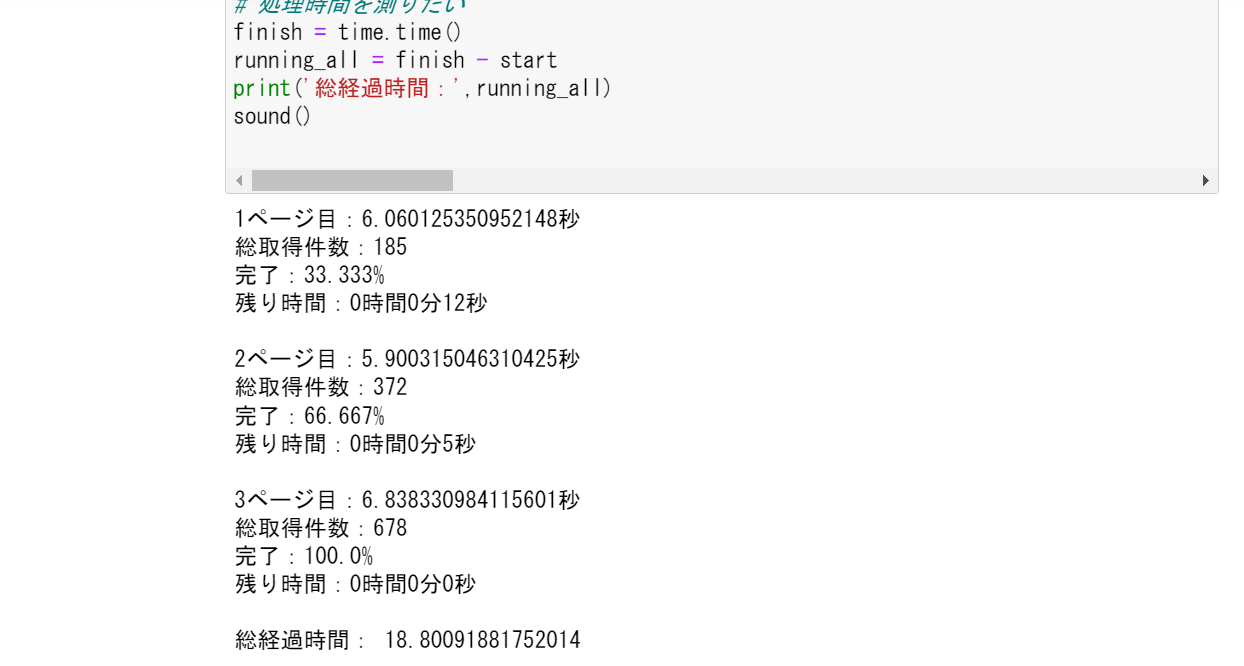
画像を貼りたかったけど5時間待たないといけないので許してください。かわりに3ページ分だけスクレイピングした場合の処理時間表示の画像を貼ります。
処理時間の表示
物件情報はリストの中に
実際にコードを実行して取得した物件情報はdata_samplesにリストで入っています。あとはpandasでDataFrameに変えるなりなんなりご自由にお使いください。
コード改善(?)案
記事を書いているうちにコードの改善(?)案を思いついたので書いておきます。
紹介したコードは↓の構造でした。
for ページ in ページ全部:
ページ情報を取得
for 建物 in ページ内の建物全部:
建物情報(緑枠)を取得
for 部屋 in 建物:
部屋情報(黄色枠)を取得
建物情報と部屋情報をくっつけてリストに保存
1秒休憩
これを以下に変えます。
for ページ in ページ全部:
ページ情報を取得
1秒休憩
for ページ情報 in 取得したページ情報全部:
for 建物 in ページ内の建物全部:
建物情報(緑枠)を取得
for 部屋 in 建物:
部屋情報(黄色枠)を取得
建物情報と部屋情報をくっつけてリストに保存
こうすることで、ページにアクセスする部分とページ情報から欲しいものを取り出す処理の部分を分けることができます。ページ情報取得と欲しいものを抜き取る作業を別々に行えるし、並列で作業させることも可能になります。
終わり。
SUUMOの物件情報を取得することに成功しました。このデータで機械学習してあんなことやこんなことなどいろいろ試してみたいと考えています。
その前に、スクレイピングした情報を分析しやすくするための前処理が必要ですね。前処理の過程を解説する記事もそのうち書くかもしれません。
→書きました。以下からぜひご覧ください。
参考
コードを書くときに以下のページを参考にしました。よろしければぜひご覧ください。
他のSUUMO記事
まとめ記事書いたのでぜひご覧ください。




コメント @ScrapeStorm-JP
@ScrapeStorm-JP0
スクレイピングについていろいろ勉強になりました。ありがとう!