Claude Code token optimization - best practices
I tested at least 20 viral Github repos to find the best techniques for token optimization. Only a couple actually worked
👋 Hi everyone, I am Hamza. I have 18 years of building large scale ecosystems and I teach at UCLA and MAVEN, and founder of Traversaal.ai.
Welcome to Edition #36 of a newsletter that 15,000+ people around the world actually look forward to reading.
We’re living through a strange moment: the internet is drowning in polished AI noise that says nothing. This isn’t that. You’ll find raw, honest, human insight here, the kind that challenges how you think, not just what you know. Thanks for being part of a community that still values depth over volume.

🎓 Read my free book: Claude Code: A Practitioner’s Approach
Most developers enable prompt caching and see modest savings, the ones hitting 90% reductions are doing something structurally different that almost nobody talks about.
Why You’re Not Getting Claude’s 90% Cost Savings (And How to Fix It)
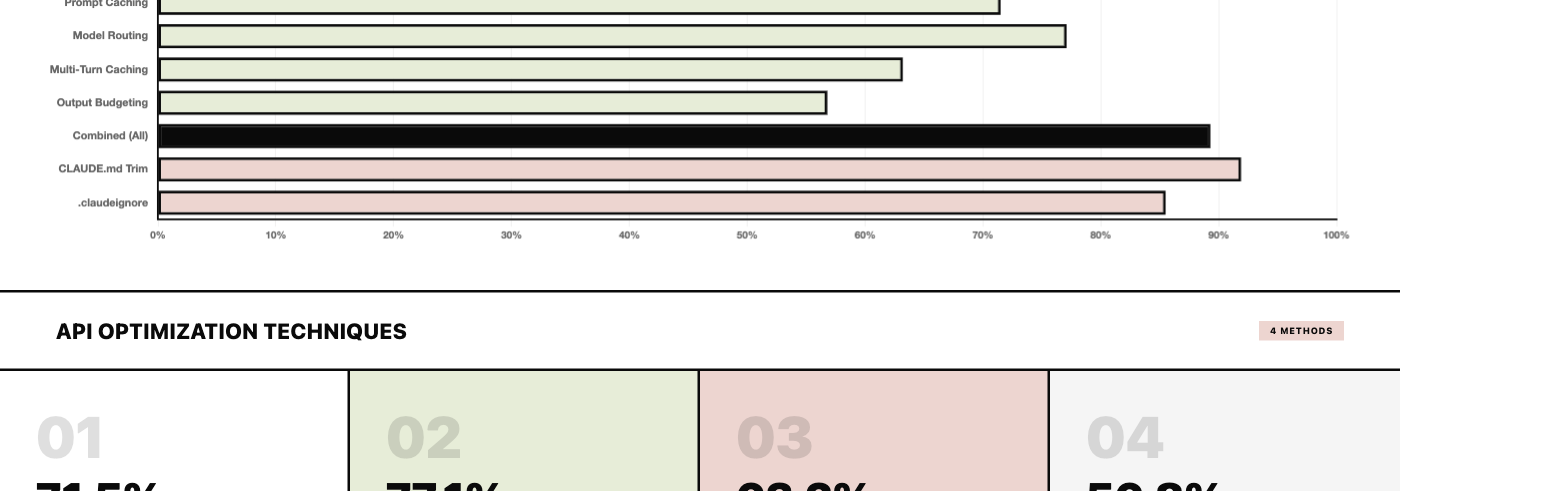
, .claudeignore 85.5% ($428/mo), Combined All 89.3% ($447/mo), Model Routing 77.1% ($385/mo), Prompt Caching 71.5% ($358/mo) — based on $500/month API spend")
Introduction: the token cost problem that’s now a board-level conversation
By mid-2026, Claude Code is inside CI/CD pipelines, code review systems, and multi-agent workflows at enough companies that token costs are showing up in budget spreadsheets rather than expense reports. Engineers who used to say “it’s not that much” are now getting questions from finance.
The math is real. Claude Sonnet 4 runs ~$3.00 per million input tokens at standard rates. Cache reads are $0.30, one-tenth the price. (Source: https://www.anthropic.com/pricing) A team burning five million input tokens per day on Sonnet spends $15,000 at standard rates. Shift 80% of that to cache reads: $3,500. That’s an $11,500 daily difference, or roughly $4M annualized, from one structural change.
The problem is that almost nobody is actually hitting that. Threads on r/ClaudeAI, the Anthropic Discord, and Hacker News keep surfacing the same thing: “I enabled caching, I see cache_creation_input_tokens in the response, but my bill barely moved.” Anthropic says 70–90% savings. Developers are seeing 5–15%.
The gap is structural, not a bug. Prompt caching is not a setting you flip.
It only works when your prompts are built in a specific way, stable content before dynamic content, above a token threshold, with cache breakpoints in the right places. This guide covers both sides: the Claude Code CLI techniques that cut context volume before any API call happens, and the API-level techniques that determine what you actually pay per token.
First, a necessary distinction. This guide covers two separate problems:
If you’re on the Claude API (building products, running agents, CI/CD pipelines), you pay per token. The 89.3% combined saving from API techniques in Sections 1–6 is what cuts your bill.
If you’re using Claude Code CLI (subscription or enterprise), you’re not paying per token, but you are paying with response quality. Every token in your context window is context Claude has to reason over. Bloated config files and noisy directories don’t inflate your invoice; they dilute Claude’s attention, producing generic answers and missed context. The techniques in this section fix that. For API users who also use Claude Code CLI, these optimizations reduce the base token volume before API-level techniques apply.
These are different problems with different solutions. The benchmark numbers measure different things and don’t add together into one figure.
🔑 Key takeaways
🗂️ Two tracks, two different problems: Claude Code CLI users pay with response quality (context bloat = worse outputs); Claude API users pay with money. The techniques are different, the numbers aren’t comparable.
📋 20,000–30,000 tokens load before you type anything — system prompt, CLAUDE.md, memory, MCP tool names, and skill descriptions all enter context at session start. This is your highest-leverage optimization surface.
✂️ CLAUDE.md under 500 tokens, path-scoped rules for the rest — strip CLAUDE.md to only what Claude can’t infer from code (91.9% context reduction); move domain-specific rules to
.claude/rules/withpaths:frontmatter so they’re invisible until needed (41% overhead reduction documented).🔌 MCP servers add 10,000–20,000 tokens of silent overhead per session — every connected server loads its tool schema into every request by default;
ENABLE_TOOL_SEARCHdefers schemas until needed and can recover 50,000–70,000 tokens in heavy MCP setups. Connecting or disconnecting MCP mid-session also wipes your entire prompt cache.🪝 Hooks filter noise before Claude sees it — a PostToolUse hook on Bash commands can compress a 10,000-line build log to a 200-line error summary before it enters context; the RTK open-source tool automates this and reports 80–99% reduction on build/test output.
💰 Claude API: four techniques combined save 89.3% — model routing (77.1%), prompt caching (71.5%), multi-turn caching (63.2%), and output budgeting (56.8%) are separate levers that stack. None of them work correctly without deliberate prompt structure.
Track 1: How Claude Code fills its context window, what loads before you type anything
Most people treat Claude Code’s context window as a black box. It isn’t. Claude Code loads context in a fixed order at session start, and you can see exactly what’s in there. Here’s what enters the window before you type anything:
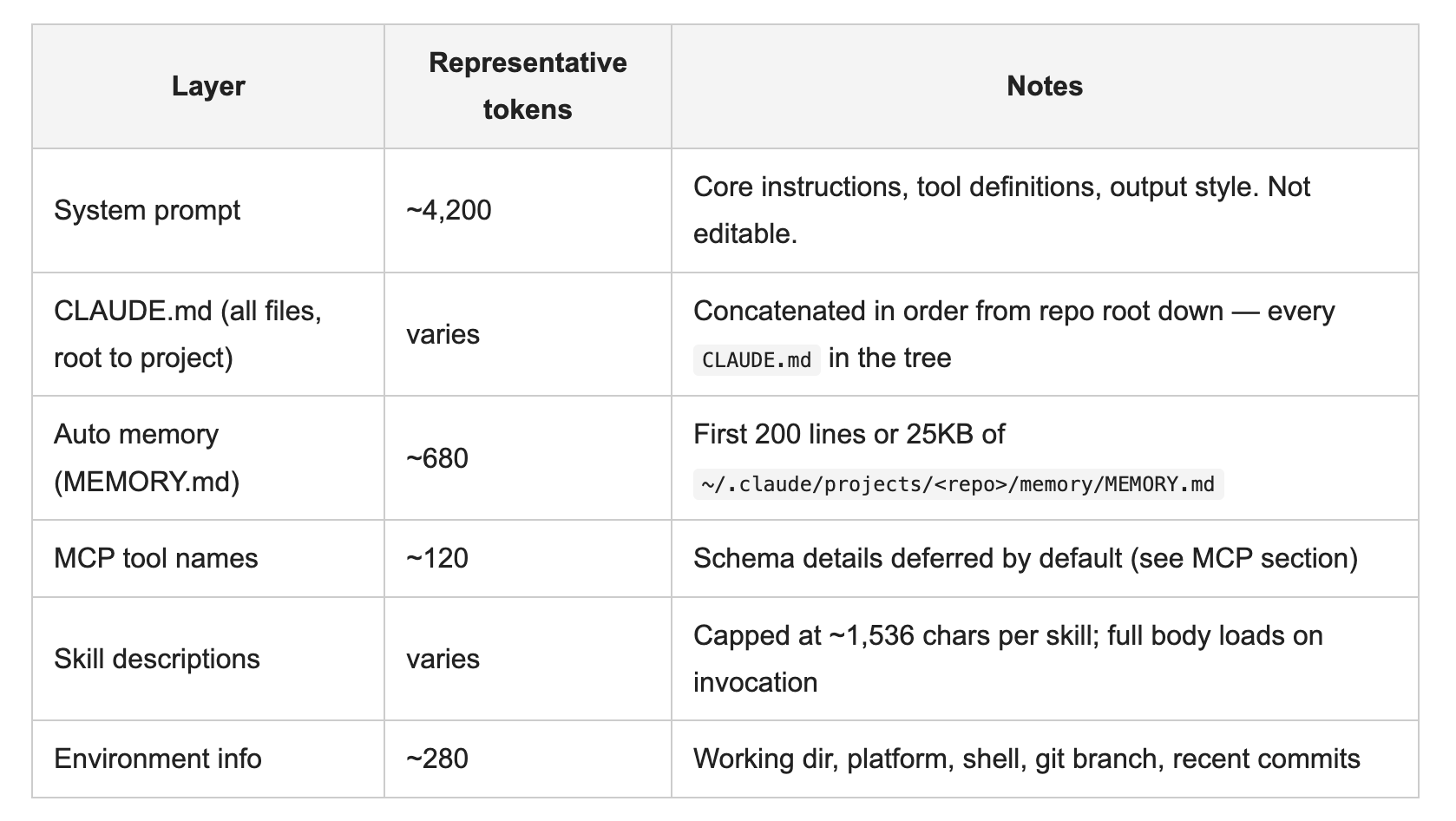
Total base overhead before you type a single character: roughly 20,000–30,000 tokens on a clean session. A GitHub issue (#52979) confirmed a simple “hi” prompt consumed ~31,000 tokens. This is the floor you’re working with.
Claude Code does not proactively crawl or index your project.
Files only enter context when: referenced in CLAUDE.md or memory (loaded at startup), you explicitly ask Claude to read them, or Claude decides to search during a task. This means the startup layers, CLAUDE.md, memory, MCP, skills, are where most waste accumulates and where the highest-leverage fixes are.
Run /context at any point in a session for a live breakdown by category with optimization suggestions. Run /memory to see exactly which CLAUDE.md and memory files loaded at startup.
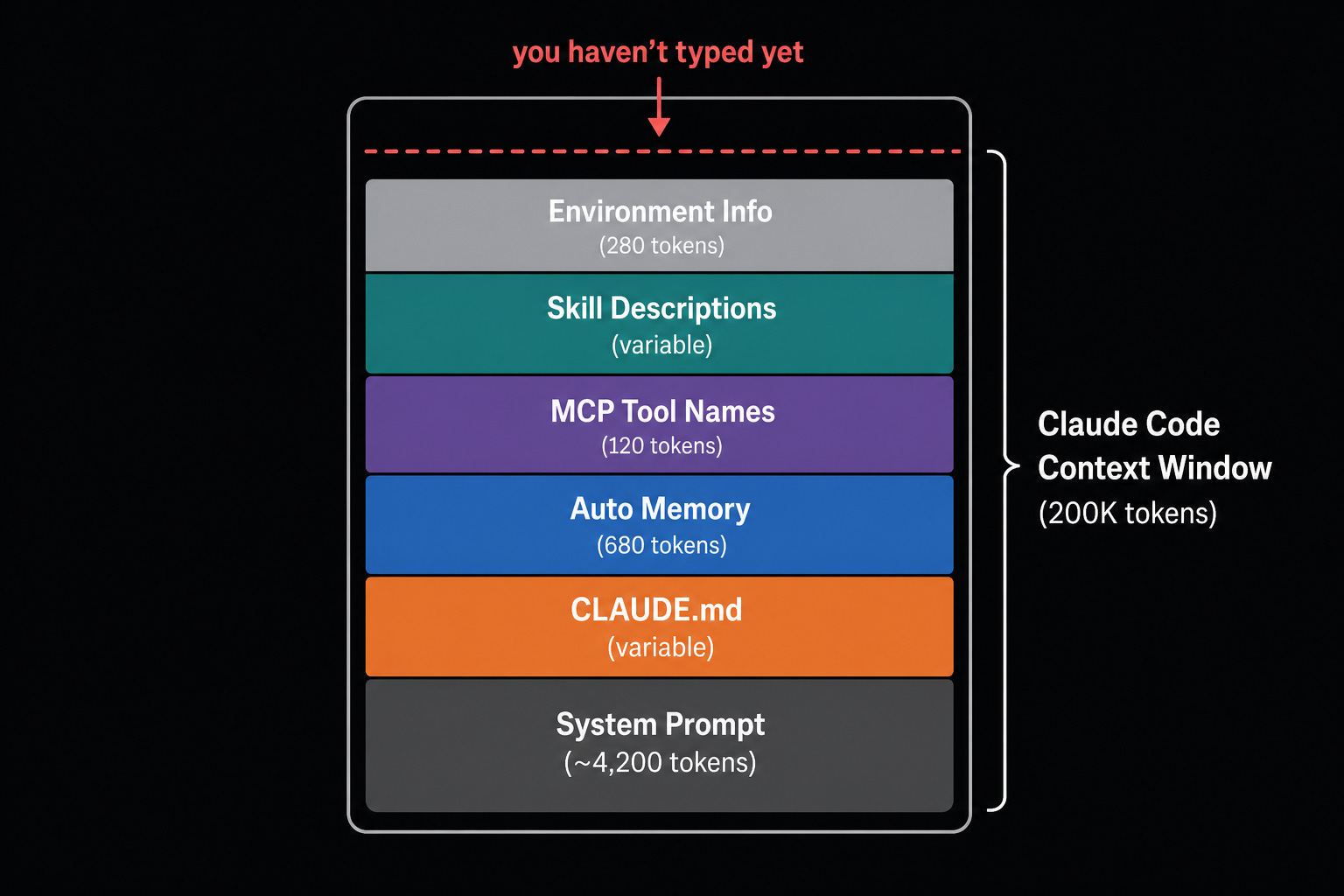
CLAUDE.md: cut to under 500 tokens
Every Claude Code session loads your CLAUDE.md into every request. It’s the most expensive single file you control, paid on every turn, forever. The token-optimizer benchmark compared a 3,847-token CLAUDE.md (generated by letting Claude document everything it encountered during onboarding) with a 312-token version stripped to only what Claude cannot infer from the code itself. Result: 91.9% context reduction, no quality regression.
Cut anything Claude already knows from training: Next.js routing, TypeScript syntax, React patterns. Cut team rosters, meeting schedules, contact info, generic preambles (”you are a helpful assistant”). Cut FAQs Claude can’t act on. Cut anything a new developer could figure out by reading the code for 20 minutes.
Keep non-obvious build and test commands. Keep architecture decisions that go against framework defaults. Keep project-specific constraints. A useful test: would this genuinely surprise an experienced developer new to the repo? If not, it probably shouldn’t be there.
Target: under 500 tokens. Anthropic’s official guidance is under 200 lines. Some teams run it at 60.
Three things most people don’t know about CLAUDE.md:
HTML comments (<!-- internal note -->) are stripped before injection. They cost zero tokens. Use them for notes to teammates, rationale, anything humans need but Claude doesn’t.
@path/to/file imports let you split CLAUDE.md across multiple files. But all imported files still load at session start. Splitting is purely organizational, it doesn’t save tokens.
CLAUDE.local.md (gitignored) is your personal preferences file. Good for local sandbox URLs and notes you don’t want in the shared config. It loads alongside CLAUDE.md.
One more: edits to CLAUDE.md during a session don’t apply until the next restart or /compact. Claude reads it once at startup and that’s it.
The token_audit.py tool in token-optimizer automates the before/after comparison:
python claude_code/token_audit.py --compare claude_code/before/CLAUDE.md claude_code/after/CLAUDE.md
python claude_code/token_audit.py --scan-dir . # full project scan
.claudeignore vs permissions.deny, know the difference
.claudeignore signals to Claude that certain files are not relevant.
It is advisory, not enforced, Claude can still read ignored files if it decides they’re necessary. Multiple GitHub issues (#36163, #51105) document this behavior.
For actual enforcement, use permissions.deny in .claude/settings.json:
{
"permissions": {
"deny": ["Read(node_modules/**)", "Read(dist/**)", "Read(*.lock)"]
}
}
This blocks the Read tool for those paths entirely. Claude cannot read them regardless of what it decides.
In practice, use both: .claudeignore handles the signal layer (Claude won’t proactively include these files), permissions.deny handles the hard block (Claude can’t read them even if it tries). The benchmark’s 85.5% context reduction from .claudeignore was measured on the signal layer. Teams with strict context discipline use permissions.deny in addition.
Minimum .claudeignore for any project:
node_modules/
dist/
build/
.next/
__pycache__/
*.pyc
*.lock
package-lock.json
yarn.lock
poetry.lock
coverage/
*.generated.*
*.min.js
*.min.css
Check it into version control, every team member gets the same context discipline automatically.

Path-scoped rules in .claude/rules/ — the 41% win almost nobody uses
.claude/rules/ lets you place rules files that load selectively. Rules without frontmatter load at session start like a second CLAUDE.md, no savings. Rules with paths: frontmatter load only when Claude reads a file matching that pattern, zero token cost until triggered.
---
paths:
- "src/api/**/*.ts"
---
# API Layer Rules
All endpoints must validate input with Zod schemas.
Response errors must use the shared ApiError class.
Never return raw Prisma errors to the client.
This rule costs nothing during frontend work, database work, or test writing. It only enters context when Claude first touches a file in src/api/. This is the key insight: path-scoped rules are invisible until needed.
One documented case (Zenn, 2025) reduced always-loaded rule overhead from 1,358 lines to 807 lines — 41% reduction — by: - Converting 5 procedure-heavy rule files into Skills (on-demand only) - Scoping 8 domain-specific rules to their respective directories - Keeping only truly global rules unscoped

.claude/rules/ subdirectories and they only load when relevant.

{kind=link}
{kind=link}