
はじめに
こんばんは、mirukyです。
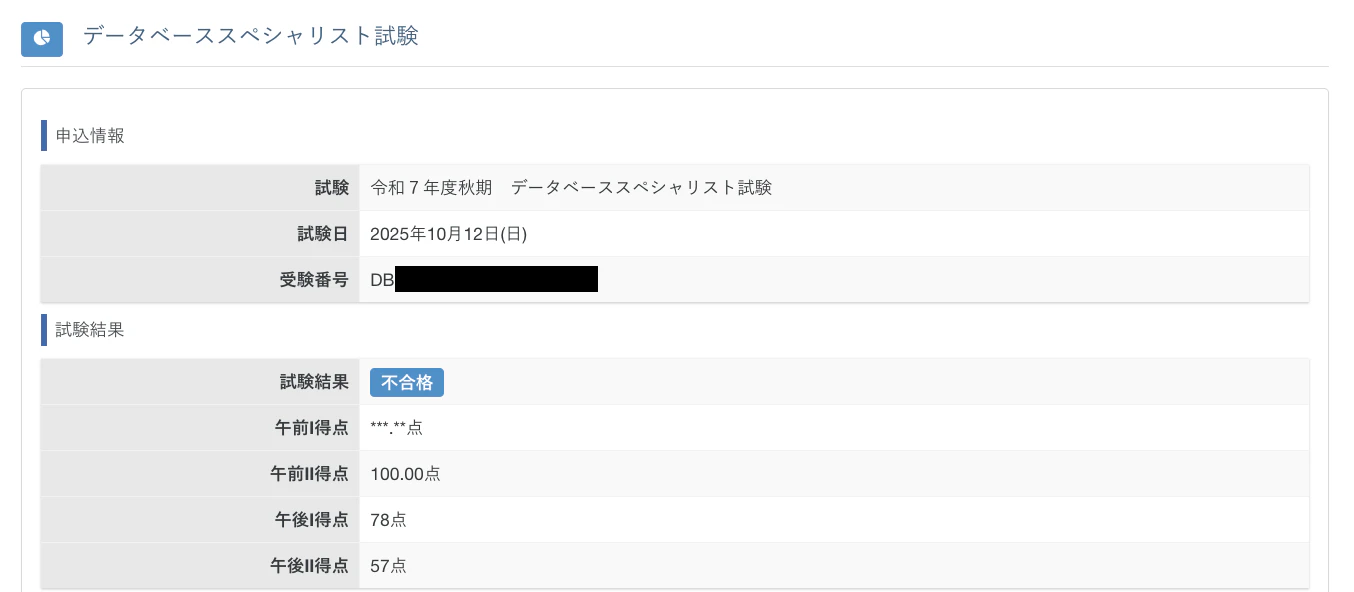
昨年、データベーススペシャリスト試験に挑戦しましたが、午後II試験に 3点差 で落ちました、、(泣)
そんな私ですが、勉強の過程や実務を通じてデータベース(DB)に関してはかなり自信がついたので、まとめたナレッジを共有できればと思います。
この記事では、DBの基礎概念から正規化、SQL、そして 実際にSQLiteでスコアリングシステムを設計・構築するまで を一気に解説します。初心者の方でも順番に読み進めれば理解できるよう、図やコード例を多めに盛り込みました。
DBは非常に面白い分野なので、ぜひ楽しみながら学んでいただければと思います!
この記事は、DBの固有製品(MySQLやPostgreSQLなど)に囚われない 汎用的なDB設計やDB構造 を解説します。特定のRDBMS固有の機能には触れませんのでご了承ください。
余談(おすすめ参考書・技術書)
本で勉強したい方は、下記の二冊が本当にオススメです。めちゃくちゃわかりやすいです。




目次
1. DBとは
そもそもデータベース(DB)とは何でしょうか。
わかりやすく言うと、DBとは 「データを整理して保存し、必要なときにすぐ取り出せる仕組み」 のことです。
結構一つ一つの言葉が大事で、DBを使うことでデータを 「整理」 して 「保存」 しておき、「すぐに取り出す」 ことができます。
DBMSはそんなDBを管理している(マネジメントのM)システム(システムのS)です。
あまり難しく考える必要はありません。
Excelのスプレッドシートとの違いを意識するとわかりやすいかもしれません。

私たちが普段使うWebサービスやアプリの裏側には、ほぼ必ずデータベースが存在します。ユーザー情報、商品情報、注文履歴など、あらゆるデータがDBに格納されていると考えてください。
データベースは非常に重要です。
2. DBの各種制約
リレーショナルデータベース(RDB)には、データの正確性と一貫性を保つための 制約 という仕組みがあります。制約を正しく設定することで、不正なデータの混入を防げます。
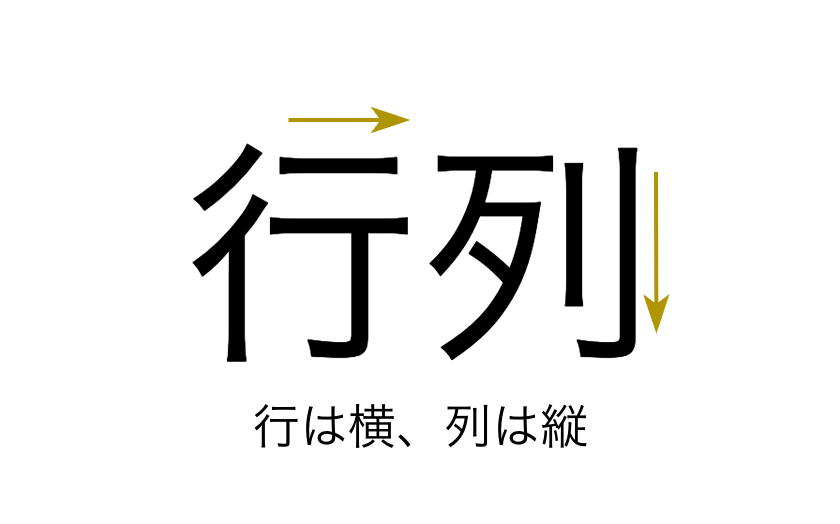
2-1. NOT NULL制約 (非NULL制約)
カラム(列)に NULLを許可しない 制約です。必ず値を入れなければならないカラムに設定します。
この例では、下のテーブルのnameカラムにNOT NULL制約を付けています。つまり、idは入っていてもnameが空のレコードは登録できません。
NOT NULL制約の定義例を見る
-- 社員名は必ず入力が必要
CREATE TABLE employees (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL -- NULLを許可しない
);
たとえば、社員テーブルで名前が空のレコードが入ってしまったら困りますよね。NOT NULL制約を付けておけば、名前なしの追加処理(INSERT)はエラーになります。
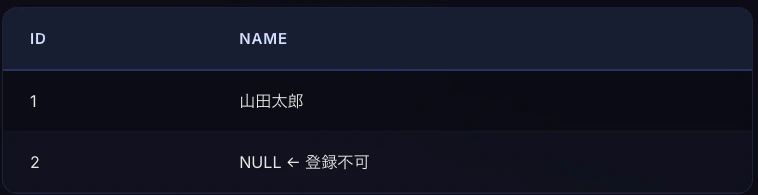
2-2. ユニーク制約 (UNIQUE制約)
カラムの値が テーブル内で一意(重複なし) であることを保証します。
1つの列に、同一の値が複数存在することを許さない強い制約です。
この例では、テーブルのemailカラムにUNIQUE制約を付けています。そのため、idが違っていても同じemail値は登録できません。
UNIQUE制約の定義例を見る
-- メールアドレスは重複を許可しない
CREATE TABLE users (
id INTEGER PRIMARY KEY,
email TEXT NOT NULL UNIQUE -- 同じメールアドレスは登録できない
);
2-3. 主キー制約 (PRIMARY KEY制約)
超大事な制約です。
各行を 一意に識別する ためのカラムに付与します。内部的にはNOT NULL + UNIQUEの組み合わせです。 1テーブルに1つだけ設定できます。
めちゃくちゃ大事なので、「主キー = NOT NULL + UNIQUEの組み合わせ」という文言を、自分はトイレの壁に貼っていました。おかげで完全に覚えました。
この例では、テーブルのidカラムにPRIMARY KEY制約を付けています。つまり、idは空にもできず、同じ値を2回使うこともできません。
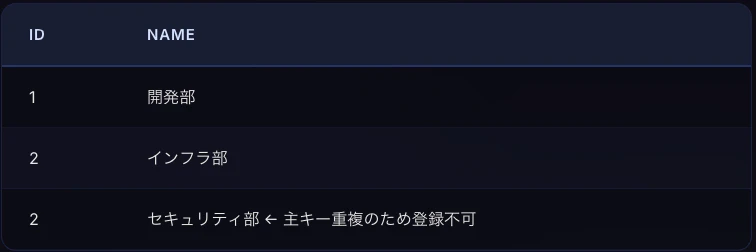
PRIMARY KEY制約の定義例を見る
-- idが主キー(各行を一意に識別)
CREATE TABLE departments (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL
);
主キーは、そのテーブルの 「住所」 のようなものです。主キーがあるからこそ、特定の1行を正確に指定できます。
2-4. 外部キー制約 (FOREIGN KEY制約)
他のテーブルの主キーを参照し、 テーブル間のリレーション(関係) を定義します。存在しない値を参照できないようにすることで、データの整合性を保ちます。
この例では、employeesテーブルのdepartment_idカラムに外部キー制約を付けて、departmentsテーブルのidカラムを参照させています。
まさしく下の図のようなイメージです。
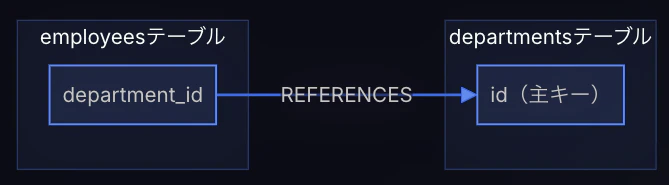
departmentsテーブル
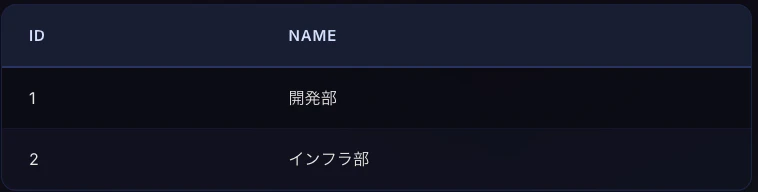
employeesテーブル(department_idが上のdepartmentsテーブルのidを参照している)
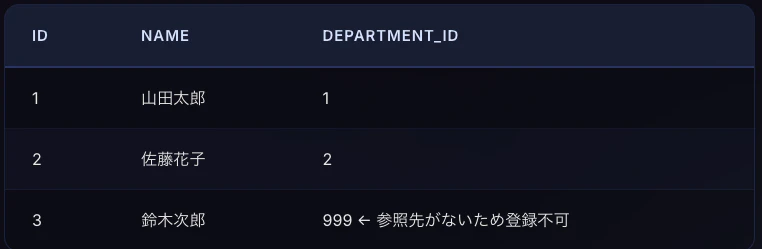
FOREIGN KEY制約の定義例を見る
CREATE TABLE employees (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
department_id INTEGER NOT NULL,
-- departmentsテーブルのidを参照
FOREIGN KEY (department_id) REFERENCES departments(id)
);
たとえば、部署テーブルに存在しない department_id = 999 を持つ社員レコードを登録しようとするとエラーになります。外部キーは 「この値は必ずあちらのテーブルに存在する」 という約束です。
ちなみに、外部キーが参照する対象は、相手のテーブルの「主キー」であるのが設計の原則だったりします。
あと、やや発展的ですが、外部キーには 「参照先のレコードが削除されたとき、参照元をどうするか」 を指定するオプションがあります。
この場合、親レコードとはdepartmentsテーブルのidです。
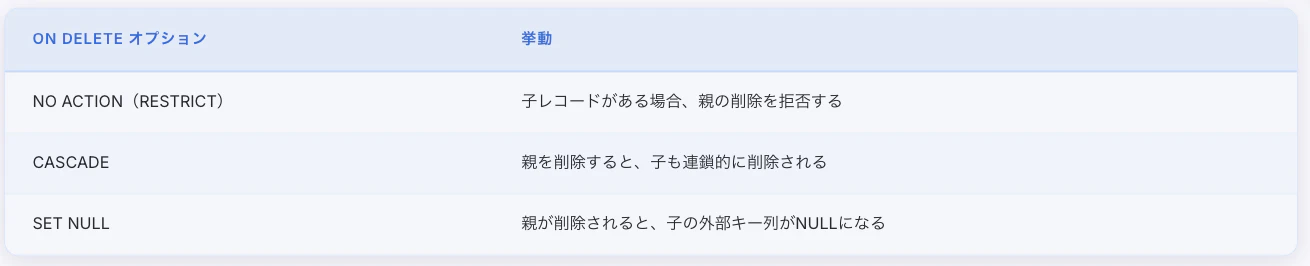
CASCADEとNO ACTIONの違いは、設計段階で決めておかないと後からの変更が非常に大変です。
2-5. CHECK制約 (上4つよりは優先度下がります)
カラムの値が 指定した条件を満たすこと を保証します。
この例では、テーブルのitss_levelカラムにCHECK制約を付けて、1から7までの値だけを許可しています。
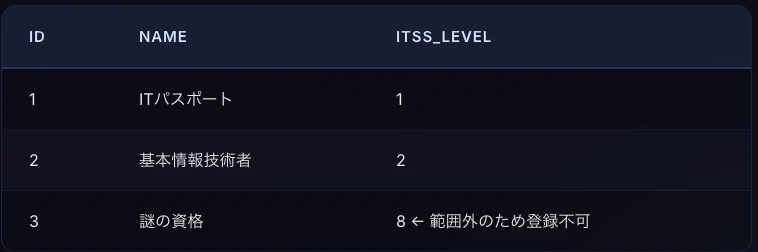
CHECK制約の定義例を見る
CREATE TABLE certifications (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
itss_level INTEGER NOT NULL CHECK(itss_level BETWEEN 1 AND 7)
-- ITSSレベルは1〜7の範囲のみ許可
);
2-6. DEFAULT制約 (上4つよりは優先度下がります)
値が指定されなかったときに 自動的に設定されるデフォルト値 を定義します。
この例では、logsテーブルのcreated_atカラムにDEFAULT制約を付けています。そのため、追加処理時(INSERT)にcreated_atを省略すると現在日時が自動で入ります。
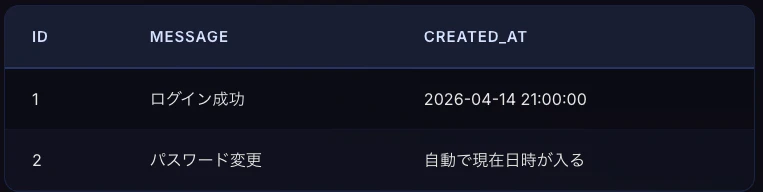
DEFAULT制約の定義例を見る
CREATE TABLE logs (
id INTEGER PRIMARY KEY,
message TEXT NOT NULL,
created_at TEXT DEFAULT (datetime('now')) -- 挿入時に自動で現在日時
);
制約はDB設計のかなめ!
制約を適切に設定することで、アプリケーション側でバリデーションを書かなくても、DB層でデータの品質を保証できます。「アプリにバグがあっても、DBが最後の砦として不正データを弾く」という考え方は、堅牢なシステム設計の基本ですね。
3. DBの構造と正規化
リレーショナルデータベースでは、データを テーブル(表) に格納します。テーブルは 行(レコード) と 列(カラム) で構成され、Excelのシートに似た構造です。
ただし、データをどのようにテーブルに分割するかが非常に重要です。分割の仕方が悪いと、データの重複や更新時の矛盾が発生します。この「テーブルを適切に分割するルール」が 正規化 です。
ここでは、「社員の資格取得記録」を例に、正規化のステップを見ていきましょう。
下のような流れで進めます。

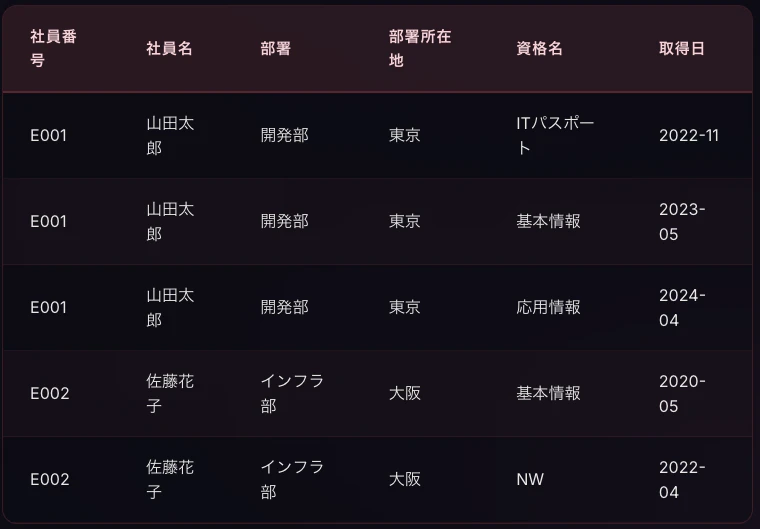
【非正規形(正規化前)】
まず、正規化されていない状態のテーブルです。1つのセルに複数の値が入っていて、資格も取得日もカンマ区切りで詰め込まれています。

この構造には問題があります。クエリ(問い合わせ)を行う時を想像してください。
例えば「基本情報(資格名)」を検索したいときに、文字列をカンマで分解してリストに格納する処理が必要になりますし、1つのセルに複数値が入っているので、DBとして非常に扱いにくいです。
「基本情報」を複数箇所で持っていて名称変更時に漏れが出ないか、というプログラミング言語の変数的な問題もあります。
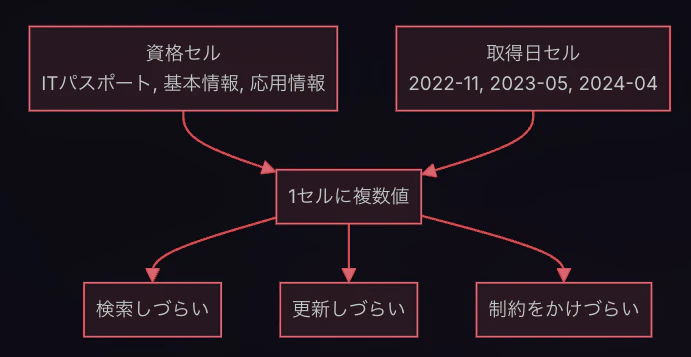
よって、先人達は正規形という便利な形を編み出してくださいました。
(DB苦手な方は「ウッ」となるかもですが、全然むずかしくないのでご安心ください!)
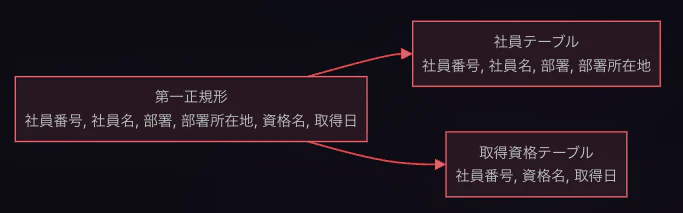
3-1. 第一正規形
繰り返しの列を排除 し、1つのセルに1つの値だけが入る状態にします。
さっきは資格列にたくさん資格名が並んでいたので、これを分解するイメージです(取得日も)。
このようになりました。ただし、主キーは {社員番号, 資格名} の複合キーになります。このテーブルにはまだ問題が残っています。「山田太郎」「開発部」「東京」が何度も重複していますね。
すっきりしたようで、ちょっと冗長っぽい形になってしまいました。
3-2. 第二正規形
第二正規形では、部分関数従属を排除 します。
部分関数従属とは、複合主キーの一部だけで決まる列がある状態です。
{A,B,C,D}の属性があり、{A,B}が複合主キーのとき、Cは{A,B}が決まることで定まりますが、DはBが定まることで決まる、みたいなものです。
この場合、Dは部分関数従属がある状態です。
上のテーブルでは、主キーが{社員番号, 資格名}ですが、「社員名」「部署」「部署所在地」は 社員番号だけで決まります 。DB設計は業務要件も重要になるのでイメージしていただきたいのですが、実社会でも、社員名、部署などは社員番号が定まることでわかりますよね。むしろ、そのための社員番号です。しかし、取得日に関しては社員番号のみではわからず、社員番号と資格名が定まって初めてわかります。
これが部分関数従属です。
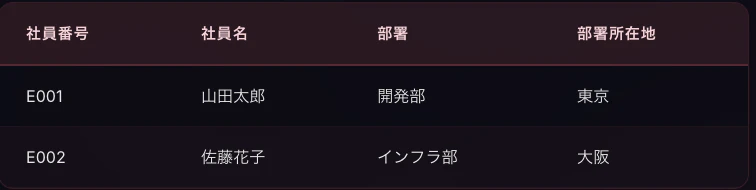
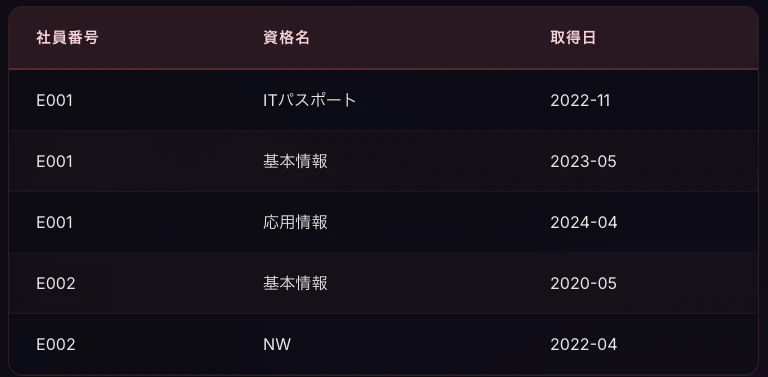
これを解消するために、テーブルを分割します。
社員番号によって定まる社員名、部署(、部署所在地)を別テーブルに、そして社員番号と資格名によって定まる取得日をそれぞれ別テーブルに分割しました。
社員テーブル
取得資格テーブル
社員の情報は1箇所にまとまりました。名前の変更があっても1行だけ更新すれば済みます。
3-3. 第三正規形
第三正規形では、推移的関数従属を排除 します。
推移的関数従属とは、「A → B → C」のように、主キーAからBが決まり、Bから別の値Cが決まる状態です。
「推移的」は難しい表現ですが、「A → B → C」の矢印が「なんか推移してるっぽいな〜」っていうイメージでも持てれば大丈夫です。
社員テーブルを見てみましょう。
さっきは触れませんでしたが、実は部署所在地って、部署が決まることで一意に定まるんですよね。
下のようなイメージです。
- 社員番号 → 部署(社員番号で部署が決まる)
- 部署 → 部署所在地(部署名で所在地が決まる)
「部署所在地」は社員番号から直接決まるのではなく、部署を経由して決まっています。これが推移的関数従属です。
解消するために、部署の情報を更に別テーブルに切り出します。
さっきの取得資格テーブルと合わせると、これで3つのテーブルの完成です。
社員テーブル
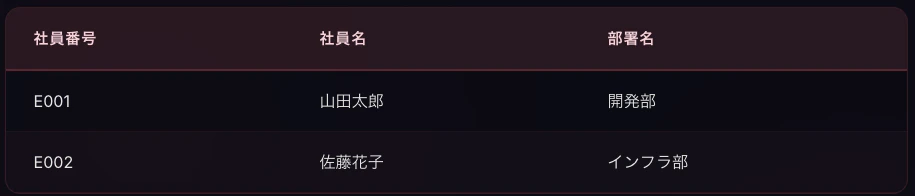
部署テーブル
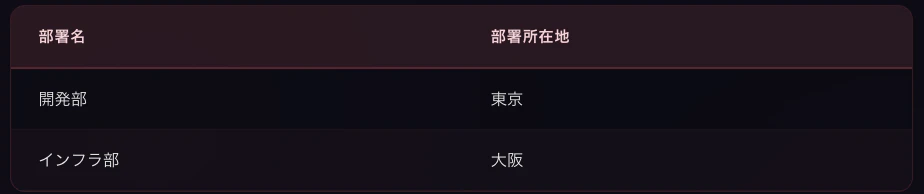
これで、部署の所在地が変わっても 部署テーブルの1行を更新するだけ で済みます。社員テーブルは部署名で部署テーブルを参照しているため、自動的に最新情報と紐づきます。
正規化のルールは確かに重要ですが、慣れると暗記で覚えるよりも 「このテーブル構造で更新したとき、矛盾が起きるかどうか」 で判断すると正しく分解できます。
正規化のポイント
正規化の本質は 「同じ情報を2箇所以上に持たない」 ことです。データの重複がなくなれば、更新漏れや矛盾が起きなくなります。実務では第三正規形まで適用すれば十分なケースがほとんどです。
4. SQLとNoSQL
4-1. SQLとは
SQL(Structured Query Language) は、リレーショナルデータベースを操作するための言語です。SQLは「プログラミング言語」というより、 「データベースへの命令文」 と考えるとわかりやすいです。
SQLの命令は大きく3種類に分かれます。
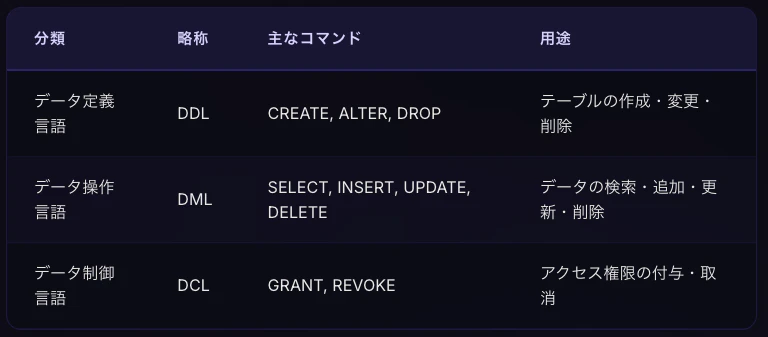
おすすめの覚え方
現場ではよくDDLとかDMLとかの略称で呼ばれることがあります。3種類のうち先頭のDと末尾のLはどれも「Data」と「Language」なので、真ん中の違いで覚えましょう!
Definitionは定義なのでDDL(データ定義言語)、
Manipulationは操作なのでDML(データ操作言語)、
Controlは制御なのでDCL(データ制御言語)です。
Manipulation(操作)とControl(制御)は日本語感覚的に混同しがちなので、注意して覚えましょう。
4-2. 基本的なSQL文
現場ではCRUDと言われる処理をSQLでよく行います。
Create(追加)、Read(読み取り)、Update(更新)、Delete(削除)ですね。
ここではさらっとしか触れませんが、もし更なる知識が必要な方は下の技術書を読むか、調べてみてください。


最も使う頻度が高いのはReadの SELECT文 です。
-- employeesテーブルから全社員を取得
SELECT *
FROM employees;
-- employeesテーブルからdepartment_id=1の社員の名前と雇用開始日を取得
SELECT name, hire_date
FROM employees
WHERE department_id = 1;
-- 社員を入社日の新しい順(降順)で取得
SELECT *
FROM employees
ORDER BY hire_date DESC;
データの追加(Create)・更新(Update)・削除(Delete)も簡潔に書けます。
INSERT文が追加、UPDATE文は更新、DELETE文は削除です。
初心者の頃は、よくDELETEをDELITEとタイポしていました。ちなみにDELETE文は結構危険な動作だったりするので、絶対にWHERE句を忘れないことと、入念なチェックを行って実行してください。
WHERE句を忘れてテーブル全消ししてしまった、みたいな事案は新人エンジニアあるあるです。
-- データの追加
INSERT INTO employees (name, department_id)
VALUES ('鈴木次郎', 1);
-- データの更新
UPDATE employees
SET department_id = 2
WHERE id = 1;
-- データの削除
DELETE FROM employees
WHERE id = 1;
4-3. 内部結合と外部結合
複数のテーブルをつなげて検索するのが 結合(JOIN) です。DB設計でテーブルを分割した以上、元の情報を復元するにはJOINが不可欠です。
【内部結合(INNER JOIN)】
両方のテーブルに一致するデータだけ を取得します。
以下の2つのテーブルを結合します。
employeesテーブル(社員)
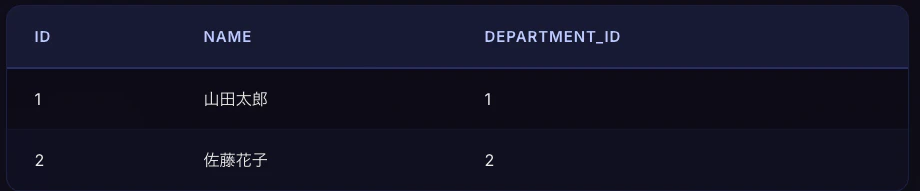
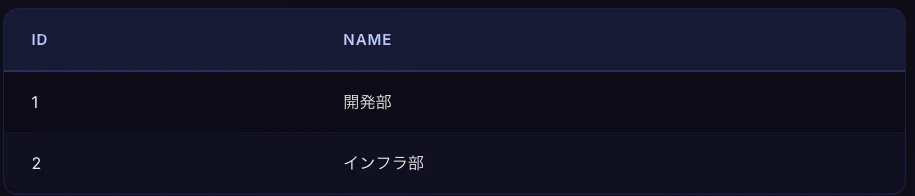
departmentsテーブル(部署)
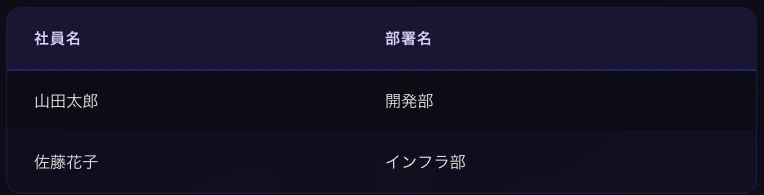
-- 社員名と部署名を結合して取得
SELECT e.name AS 社員名, d.name AS 部署名
FROM employees e
INNER JOIN departments d ON e.department_id = d.id;
結果
【左外部結合(LEFT JOIN)】
左側のテーブルは全行残し 、右側に一致するデータがなければNULLで埋めます。
右外部結合もありますが、存在するだけであまり使いませんので省略します。
以下の3つのテーブルを結合します。
employeesテーブル(社員)
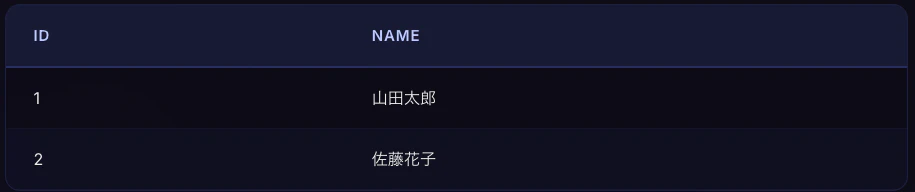
employee_certificationsテーブル(取得資格)
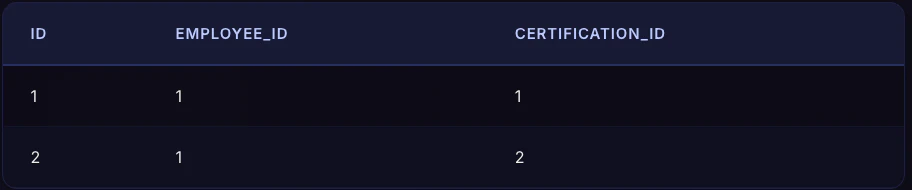
certificationsテーブル(資格)

佐藤花子(id=2)はemployee_certificationsにレコードがないため、LEFT JOINではNULLになります。
-- 資格を持っていない社員も含めて取得
SELECT e.name AS 社員名, c.name AS 資格名
FROM employees e
LEFT JOIN employee_certifications ec ON e.id = ec.employee_id
LEFT JOIN certifications c ON ec.certification_id = c.id;
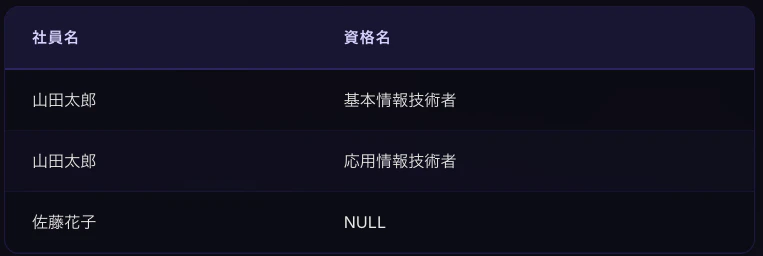
LEFT JOINは 「資格を1つも持っていない社員も一覧に表示したい」 といったケースで活躍します。
補足ですが、LEFT JOINを使うときは、SUMとかCOUNTとかの集計関数のNULLの扱いに注意してください。 COUNT(*) は行数を数えるのでNULL行もカウントしますが、 SUM(列名) はNULLを無視します。LEFT JOINの結果にNULLが混ざる場面では、この違いがバグの温床になります。デスペの午後試験でもたまに見た記憶があります。
4-4. NoSQLとは
ここまで紹介してきたリレーショナルデータベース(RDB)に対して、 NoSQL というカテゴリのデータベースも存在します。
NoSQLは、SQLと違って言語ではなく、そういう種類のデータベースという意味で用いられます。
もっと詳しく言うと、NoSQLは 「Not Only SQL」 の略という説が通説で、RDBのようなテーブル構造ではなく、 非構造化・半構造化データをそのまま格納する データベースそのものを指します。
以下の表のような「ドキュメント型」、「キーバリュー型」、「カラム指向型」、「グラフ型」などの種類があります。

RDBが 「事前にテーブル定義を厳密に決めてからデータを格納する」 のに対し、NoSQLは 「柔軟な構造でスキーマレスにデータを格納する」 アプローチを取ります。
結構最初は驚きだったのですが、AWSのDynamoDBなんかはパーティションキーとソートキー(任意)を定義すれば、後はプログラム側で自在なカラムを設定できます。
こういう扱いやすい部分は、NoSQLの強みです。
なお、NoSQLでもRDBほど厳密ではありませんが、クエリを想定した、きちんとしたDB設計は必要不可欠です。
どちらが優れているという話ではなく、用途に応じて使い分けるものです。業務システムのようにデータの整合性が重要な場面ではRDB、大量のログ収集やリアルタイム分析にはNoSQL、という選択が一般的です。
サーバレスを好む現場では、全てDynamoDBで作っているみたいな話も聞いたことがあります。結局現場次第ですね。
5. DB設計の流れ
DB設計は、 概念設計 → 論理設計 → 物理設計 の3段階で進めます。いきなりCREATE TABLE文を書き始めるのではなく、段階を踏んで抽象的な設計から具体的な実装に落とし込んでいくのがセオリーです。
こういうしっかりした手順を踏む理由は、リレーショナルデータベース設計はなかなか後戻りが難しいからです。
従来のウォーターフォール開発と似た部分があります。その代わり、堅牢で綺麗なデータが担保されるので、運用・保守性が高いのは魅力的です。

5-1. 概念設計
「何を管理するのか」 を整理するフェーズです。業務要件をヒアリングし、管理対象(エンティティ)とその関連(リレーションシップ)を洗い出して、 概念データモデル としてER図(エンティティ-リレーションシップ図)にまとめます。
この段階では、カラムのデータ型やインデックスのことは考えません。あくまで 「どんなモノとモノがどう関わっているか」 をER図で可視化するのが目的です。概念設計の成果物であるER図が、次の論理設計への入力になります。
ER図の詳しい書き方等については、実際に作ってみるセクションで解説します。実際のものを見たほうがわかりやすいと思いますので!
5-2. 論理設計
概念設計で作成したER図をもとに、 関係スキーマを作成してテーブル構造を具体的に定義する フェーズです。関係スキーマとは、テーブル名とその属性(カラム)を下記の形式で表現したもので、ER図のエンティティをテーブルに変換する作業にあたります。実線は主キー、破線は外部キーを示します。
どんなテーブルや列が必要か、各列のデータ型を何にするかを決めていくのがこのフェーズです。特定のDBMS(MySQL、PostgreSQLなど)に依存しない 論理的なデータモデル を作るのがポイントです。
論理設計は、以下の3ステップで進めると良いです。

特にステップ1の「関係スキーマへの変換」では、 キーの設計 が非常に重要です。主キーの選び方で、テーブルの使い勝手が大きく変わります。
【自然キー vs 代理キー(サロゲートキー)】
主キーを決めるとき、「業務データをそのまま主キーにするか(自然キー)」「意味のない連番IDを主キーにするか(代理キー/サロゲートキー)」という選択が発生します。
仮に部署テーブルのカラムが部署名と部署所在地だとした場合、ここに更に「部署ID」を追加し、これを主キーとする場合はサロゲートキーになります。

実務では サロゲートキーを主キーにするケースが多い です。理由は単純で、業務データは仕様変更で変わり得るからです。たとえば「メールアドレスを主キーにしたけど、ユーザーがメアドを変更できるようになった」とか、「社員コードの採番ルールが変わった」といったケースは実際によく起きます。
サロゲートキーであれば、業務データがどう変わっても主キーに影響しません。外部キーで参照している子テーブルへの連鎖的な影響も避けられます。
(自分が受験した回のDBスペシャリスト午後Ⅱ論理設計はIPAからサロゲートキー禁止命令があり、実務経験者からの小言が散見されました。そのくらいサロゲートキーはよく使われます。)
ただし、サロゲートキーだけに頼ると、業務上の一意性が失われるリスクがあります。サロゲートキーを使う場合でも、 業務的に一意であるべきカラムにはUNIQUE制約を必ず付ける 習慣をつけましょう。
サロゲートキーが万能というわけではなく、テーブルの性質や業務要件に応じた判断が大事、という点がポイントです。
5-3. 物理設計
論理設計の結果を 実際のDBMSに実装する フェーズです。論理設計がDBMS非依存の「論理的な世界」だったのに対し、物理設計は パフォーマンスとDBMS、ハードウェアを意識した「物理的な世界」 です。
物理設計では、以下の5つの要素を検討します。
クラウド環境ではいくつか省略される要素もありますが、一旦それは度外視して解説します。

DBMSごとの方言(AUTO_INCREMENT vs AUTOINCREMENT vs SERIALなど)を考慮するのはこの段階です。
【インデックス設計】
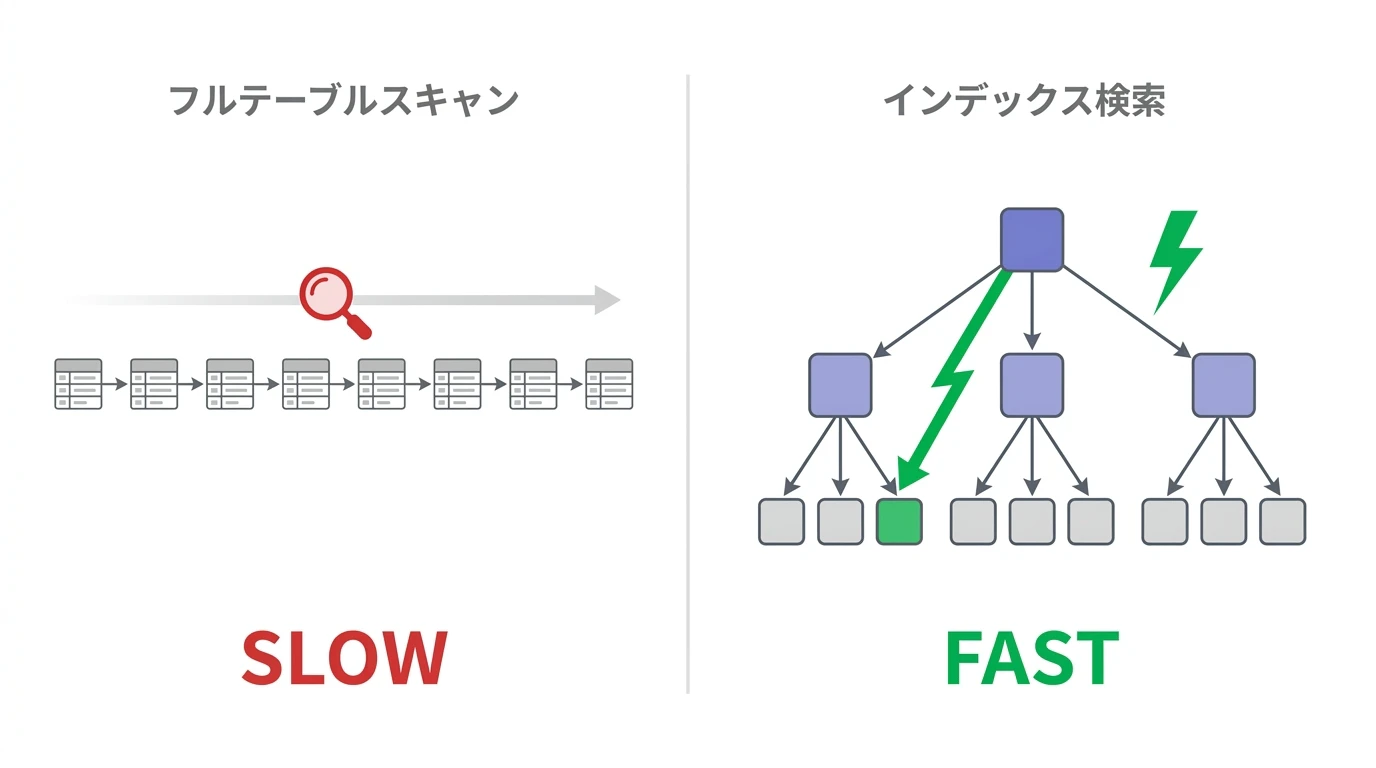
物理設計の中で最もパフォーマンスへの影響が大きいのが インデックス設計 です。インデックスとは、本の巻末にある索引と同じ仕組みです。テーブルの全行を順番になめる(フルテーブルスキャン、表探索)のではなく、インデックスを使って目的のデータに素早くアクセスできます。
たとえば、employeesテーブルに10万行のデータがあるとき、WHERE department_id = 2 で検索する場合を考えます。インデックスがないと、DBは先頭から10万行を順番にチェックします(フルテーブルスキャン、表探索)。一方、department_idにインデックスが張られていれば、木構造をたどってごく少数のノードだけで該当データに到達できます。
下の画像のようなイメージですね。インデックスを用いた検索は、当たりをつけて検索できるので、その分フルテーブルスキャンよりも多くの場合早く検索できます。
多くのRDBMSで実際に採用されているのは、B-treeを改良した B+tree(ビープラスツリー)インデックス です。B+treeには2つの大きな特徴があります。
- 実データはリーフノード(末端)にだけ格納される …… 内部ノード(途中のノード)には「どの方向に進むか」のキーだけが入り、データ本体は入りません。そのため、1ノードあたりに格納できるキー数が増え、木の高さが低くなります。木の高さが低いほどディスクアクセスが少なく済むので、検索が高速になります
-
リーフノード同士がリンクリストでつながっている …… 範囲検索(
WHERE price BETWEEN 100 AND 500)のとき、開始位置のリーフを見つけたら、あとはリンクをたどるだけで連続したデータを取得できます。毎回ルートからたどり直す必要がないため、範囲検索が非常に高速です
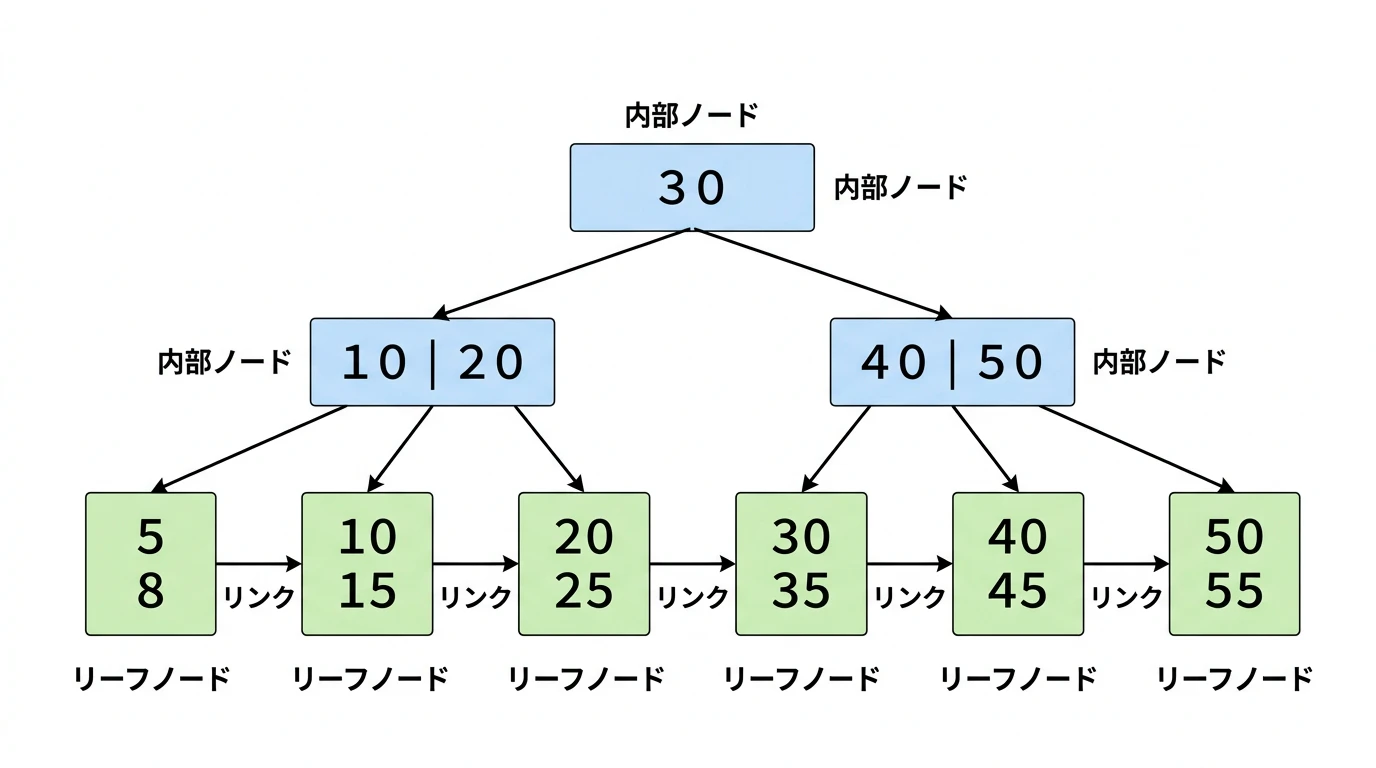
上の図のように、内部ノードは「どの子ノードに進むか」の指標だけを持ち、実際のデータはリーフノード(最下段)に格納されています。そしてリーフ同士が「リンク」でつながっているのがポイントです。たとえば WHERE id BETWEEN 15 AND 38 の範囲検索では、ルートから「15」の位置まで辞書的にたどり、そこから「38」までリンクをたどるだけで全データを取得できます。
ちなみに等価検索(WHERE id = 1)でも範囲検索でも高速に動作するため、MySQL、PostgreSQL、SQLite、Oracleなど主要なRDBMSはいずれもB+treeをデフォルトのインデックス構造として採用しています。
インデックスを張るべきカラムの判断基準は以下のとおりです。

インデックスはSELECTを速くする代わりに、INSERT/UPDATE/DELETEを遅くします。データを書き込むたびにインデックスも更新する必要があるからです。これはRDBだけでなくNoSQLでも同様です。例えば、AWSのDynamoDBはLSI(ローカルセカンダリーインデックス)という機能があり、インデックスによって追加のソートキー(パーティションキーは固定)を定義できますが、更新処理などが遅くなります。「とりあえず全カラムにインデックスを張る」のは逆効果なので、本当に必要なカラムに絞りましょう。
【ストレージの冗長構成(RAID)】
本番環境では、ディスク故障に備えて RAID(Redundant Arrays of Independent Disks) を構成するのが一般的です。主要なRAIDレベルの特徴を押さえておきましょう。

DB用途で最も推奨されるのは RAID 10 です。RAID 5は書き込み時のパリティ計算がオーバーヘッドになるため、DBのように書き込みが多いワークロードには向いていません。ただし、RAID 10はディスクの利用効率が50%なので、コストとのトレードオフになります。
RAID10は「10(じゅう)」ではなく、RAIDの「1(ミラーリング)」+「0(ストライピング)」と覚えると良いです。
クラウド環境(AWS RDS、Aurora等)ではRAIDの選定をユーザーが意識する必要はほぼありませんが、オンプレミスやEC2上にDBを構築する場合は依然として重要な設計判断です。知識として知っておいて損はありませんね。
6. スコアリングシステムを作ってみよう
ここからは、実際にDB設計の3ステップ(概念設計 → 論理設計 → 物理設計)を体験してみましょう。
【お題】
ITSSベースの資格スコアリングシステム を設計・構築します。
IPA(情報処理推進機構)が定める ITSS(ITスキル標準) では、情報処理技術者試験の各資格にレベルが割り当てられています。
ITSSは資格ではレベル4が最高レベルですが、経験スキルや社内・業界での立ち位置などといったやや曖昧な指標を含めるとレベル7まであります(今回は関係ありません)。

【スコアリングの仕組み】
あるジャンル(カテゴリ)に属する 全資格のITSSレベルを合計 した値を「満点」とします。従業員が保有する資格のITSSレベル合計を満点で割り、100をかけることで 100点満点のスコア を算出します。
たとえば、「セキュリティ」ジャンルに情報セキュリティマネジメント(Lv2)と情報処理安全確保支援士(Lv4)の2資格があるとします。満点は2 + 4 = 6です。従業員が情報セキュリティマネジメントだけ持っていれば、スコアは 2 / 6 × 100 = 33.3点 になります。
【テーブル数】
結果的に 8テーブル となりました。
7. 概念設計
5-1で述べたとおり、概念設計では 「何を管理するのか」 を整理します。業務要件から管理対象(エンティティ)を洗い出し、それぞれがどう関わっているか(リレーションシップ)を明らかにするフェーズです。
この段階ではカラムのデータ型やインデックスのことは考えません。あくまで「業務をデータの視点で切り取る」ことに集中します。
7-1. エンティティの洗い出し
まず、スコアリングシステムに必要なエンティティ(実体)を洗い出します。洗い出しの基本は 「業務の中で管理・記録したいモノ・コト」 を列挙することです。
ここで「種別」を意識するのがポイントです。 リソース系エンティティ は比較的変化が少ないマスタデータ(従業員、部署、資格など)、 イベント系エンティティ は業務の中で発生するトランザクションデータ(取得資格、注文、ログなど)、 サマリ系エンティティ は集計・計算結果を保持するものです。
種別を分けておくと、後の論理設計でテーブルの更新頻度やデータ量が見積もりやすくなります。
7-2. リレーションシップの整理
エンティティを洗い出したら、次にエンティティ間の関連を整理します。
今回のシステムでは、従業員と資格が 多対多 の関係にあります。1人の従業員が複数の資格を取得でき、1つの資格を複数の従業員が保有できるからです。
リレーションシップを考える時のコツですが、AとBの関係を見る時、それぞれを主人公に見ます。まずAを主人公として見る時、Aが「1つのとき」、Bは何個あるか考えます。今回は便宜上、従業員をAとすると、従業員1人につき、資格は複数(多)です。現実世界でも、1人の従業員が複数資格を取得しているケースはよくありますよね。次に、Bを主人公としてみます。今回はBは資格として、資格が「1つのとき」、従業員は何人かを考えます。答えは複数人ですね。例えば基本情報技術者を考えた時、社内に複数の従業員が取得しているケースが容易に想像できます。このように、それぞれを主人公に見立て、「1つのとき」を基準にして考えると、比較的簡単にリレーションシップを読み取れます。今回は多対多ですね。
かなり重要な点として、RDBでは多対多の関連を直接テーブルで表現できません。とんでもなく複雑な関係になってしまうためです。なので、間に 中間テーブル(連関エンティティ) を置いて1対多と多対1の組み合わせに分解します。さっきの従業員と資格の多対多の例では、間に従業員-資格テーブルという従業員がどの資格を持っているかのテーブルを置きます。従業員-資格テーブルの主キーは、従業員テーブルの主キーを参照する外部キー、資格テーブルの主キーを参照する外部キーとすれば、リレーションシップとしては、従業員テーブルと従業員-資格テーブルは1対多、資格テーブルと従業員-資格テーブルも1対多となります。
今回のお題では「取得資格」テーブル(employee_certifications)がその役割を担います。
各リレーションシップを整理すると、以下のようになります。一旦は文字ベースで表します。図解すると一気にわかりやすくなるので、ER図の記法を紹介した後で、図解も示します。
- 1つの 部署 に0人以上の 従業員 が所属する(1対多)
- 1つの 役職 に0人以上の 従業員 が紐づく(1対多)
- 1つの 資格ジャンル に1つ以上の 資格 が属する(1対多)
- 従業員 と 資格 は多対多で、取得資格 テーブルで分解
- 1つの 資格ジャンル に1つの ジャンル別ITSS合計 が対応する(1対1)
- 従業員スコア は 従業員 と 資格ジャンル の組み合わせ(多対1 × 2)
7-3. ER図
ER図は、エンティティ同士の関連を視覚化した設計図です。テーブル定義やSQLを書く前に、 「何と何がどう関わっているか」 を俯瞰するために作成します。
ER図の読み方はシンプルです。四角がエンティティ(テーブルの候補)、線がリレーションシップ(関連)を表します。線の端についた記号で 多重度(カーディナリティとも言います) を示します。今回のER図では Crow's Foot(鳥の足)記法 を使っています。ER図は色々な記法があります。PJによって使用している記法が変わってくる場合がありますが、根本の考え方は同じなので臨機応変に行うこともそんなに難しくないと思います。
覚え方としては、「◯」は0っぽいので◯を表し、「|」は縦棒1つなので1、間の「-」はいわゆるAからBまでのからの部分を表します。「A〜B」みたいな感じですね。そして、鶏の足みたいなマークは「多」です。
こう覚えれば、「縦棒2つ」は1 1で「必ず1」、「◯-|」は0から1、つまり「0または1」です。「|-鶏の足」は1から多なので「1以上」、「◯-鶏の足」は0から多なので「0以上」です。
記号だけではピンとこないと思うので、今回のシステムの関連を使ってパターンごとに見ていきましょう。
【1対多(1:N)】
最も基本的な関連パターンです。「1つの部署に0人以上の従業員が所属する」関係を図にすると、以下のようになります。
補足ですが、一番上の段がテーブル名、二段目が主キー、三段目がそれ以外のカラムです。idや部署IDの左側にある黒丸「●」は非NULL制約、つまりNULLを許さない制約を示し、<>は外部キー制約を示します。下の図の場合、従業員テーブルの部署IDは部署テーブルの主キーであるidを参照している関係になります(1対多の場合、多側のどれかのカラムが1側の主キーを参照する)。
上の || は「必ず1つ」、下の o-鶏の足 は「0以上」です。従業員は 必ずどこか1つの部署に所属 しますが、部署側から見ると 従業員が0人のこともあり得ます (新設部署など)。
繰り返しになりますが、「多」の側(従業員)が「1」の側(部署)の主キーを外部キー(部署ID)として持つのがポイントです。1対多ではこの原則が常に成り立ちます。
【1対1(1:1)】
「1つの資格ジャンルに対して、集計レコードが最大1つだけ対応する」関係です。
上の || は「必ず1つ」、下の o-| は「0または1」です。ジャンル別ITSS合計は各ジャンルに 最大で1つ しか存在しませんが、まだ集計データが未作成のジャンルもあり得るため「0または1」としています。
1対1は一見すると同じテーブルにまとめればよさそうですが、更新頻度やアクセスパターンが異なるデータを別テーブルに分離しておくほうが管理しやすくなります。
【多対多(M:N)】
「1人の従業員が複数の資格を取得でき、1つの資格を複数の従業員が保有できる」関係です。RDBでは多対多を直接テーブルで表現できないため、間に 中間テーブル(連関エンティティ) を置いて1対多の組み合わせに分解します。
中間テーブル(連関エンティティ)である「取得資格(employee_certifications)」が両側のテーブルの主キーを外部キーとして持つことで、多対多が「従業員 → 取得資格」の 1対多 と「資格 → 取得資格」の 1対多 に分解されています。
中間テーブルには取得日(acquired_date)のような 「関連そのものに属する情報」 を持たせることもできます。「いつ取得したか」は従業員にも資格にも属さず、「取得した」という事実に紐づく情報だからです。
【完成版ER図】
以上のパターンを組み合わせると、スコアリングシステム全体のER図は以下のようになります。
【ジャンル分け】
今回は資格を以下の4ジャンルに分類します。図らずもですが、特に高度試験がIPAの新試験方式の区分けっぽくなっています。ネットワークスペシャリスト=NWみたいに略称で表しています。
計算式をもう一度お示しすると、下記です。
8. 論理設計
概念設計のER図をもとに、関係スキーマを作成し、各テーブルのカラム・データ型・制約を定義します。5-2で述べたとおり、論理設計では「関係スキーマへの変換 → データ型・制約の定義 → 正規化」の3ステップで進めます。
DBMS非依存の論理モデルを作るのが重要なポイントで、ここでのデータ型はINTEGER(整数)、TEXT(文字列)、REAL(実数)程度の抽象レベルにとどめます。MySQLのVARCHAR(255)やPostgreSQLのSERIALといった固有の型は使いません。
テーブル名やカラム名の命名規則もこの段階で統一します。今回は以下のルールを採用しました。
- テーブル名は 英語の複数形(employees, certifications)
- カラム名は スネークケース(department_id, hire_date)
- 主キーは一律 id、外部キーは 参照先テーブルの単数形_id(department_id, employee_id)
- ブール値が必要な場合は is_プレフィックス(is_active)
こうした命名規則を最初に決めておくと、テーブルが増えても一貫性を保てます。
8-1. 関係スキーマへの変換
概念設計で作成したER図のエンティティを、関係スキーマに変換します。関係スキーマとは、テーブルの構造を テーブル名(属性1, 属性2, ...) の形式で一行に表現したものです。
以下が今回の8テーブルの関係スキーマです。セクション5-2で紹介したとおり、実線は主キー、破線は外部キーを示します。Qiitaの記法の関係で破線が少し下にありますが、お気になさらずお願いします。
8-2. テーブル定義一覧(データ型と制約の定義)
関係スキーマの各テーブルに対して、カラムのデータ型と制約を具体的に定義していきます。現場のテーブル定義書っぽく書いてみます。一番右の列が備考になって、そこに自動連番などを書くケースもあります。
【1. 部署テーブル(departments)】
| カラム名 | データ型 | 主キー | 非NULL | ユニーク | 自動採番 | 外部キー |
|---|---|---|---|---|---|---|
| id | INTEGER | ○ | ○ | ○ | ○ | |
| 部署名(name) | TEXT | ○ | ○ |
シンプルなマスタテーブルです。部署名(name)にユニーク制約を付けることで、同じ部署名の重複登録を防ぎます。idは代理キー(サロゲートキー)を採用しています。
【2. 役職テーブル(positions)】
| カラム名 | データ型 | 主キー | 非NULL | ユニーク | 自動採番 | 外部キー |
|---|---|---|---|---|---|---|
| id | INTEGER | ○ | ○ | ○ | ○ | |
| 役職名(name) | TEXT | ○ | ○ |
部署テーブル(departments)と同様のマスタテーブルです。役職名の変更があっても、外部キーで参照しているのはidなので他テーブルへの影響がありません。これが代理キーのメリットです。
【3. 従業員テーブル(employees)】
| カラム名 | データ型 | 主キー | 非NULL | ユニーク | 自動採番 | 外部キー |
|---|---|---|---|---|---|---|
| id | INTEGER | ○ | ○ | ○ | ○ | |
| 従業員名(name) | TEXT | ○ | ||||
| 部署ID(department_id) | INTEGER | ○ | departments(id) | |||
| 役職ID(position_id) | INTEGER | ○ | positions(id) | |||
| 入社日(hire_date) | TEXT | ○ |
部署ID(department_id)と役職ID(position_id)が 外部キー です。非NULLにしているので、部署未所属・役職未設定の従業員は登録できません。業務要件上「必ずどこかの部署に所属する」なら、この設計が正しいです。もし「未配属」の状態を許容するなら、非NULLを外してNULLを許可する設計もあり得ます。
入社日(hire_date)をTEXT型にしているのはSQLiteの特性です。SQLiteにはDATE型が存在しないため、ISO 8601形式(YYYY-MM-DD)の文字列で日付を扱います。
【4. 資格ジャンルテーブル(categories)】
| カラム名 | データ型 | 主キー | 非NULL | ユニーク | 自動採番 | 外部キー |
|---|---|---|---|---|---|---|
| id | INTEGER | ○ | ○ | ○ | ○ | |
| ジャンル名(name) | TEXT | ○ | ○ |
【5. 資格マスタテーブル(certifications)】
| カラム名 | データ型 | 主キー | 非NULL | ユニーク | 自動採番 | 外部キー |
|---|---|---|---|---|---|---|
| id | INTEGER | ○ | ○ | ○ | ○ | |
| 資格名(name) | TEXT | ○ | ||||
| 略称(abbreviation) | TEXT | ○ | ||||
| ITSSレベル(itss_level) | INTEGER | ○ | ||||
| ジャンルID(category_id) | INTEGER | ○ | categories(id) |
ITSSレベル(itss_level)にCHECK制約を設けて、1〜7の範囲のみを許可しています。こうすることで、アプリケーション側にバグがあっても「レベル0」や「レベル100」といった不正な値がDBに入ることを防げます。セクション2-5で解説した制約の実践例です。
【6. 取得資格テーブル(employee_certifications)】
| カラム名 | データ型 | 主キー | 非NULL | ユニーク | 自動採番 | 外部キー |
|---|---|---|---|---|---|---|
| id | INTEGER | ○ | ○ | ○ | ○ | |
| 従業員ID(employee_id) | INTEGER | ○ | employees(id) | |||
| 資格ID(certification_id) | INTEGER | ○ | certifications(id) | |||
| 取得日(acquired_date) | TEXT | ○ |
従業員と資格の 多対多リレーション を解決する中間テーブルです。同じ従業員が同じ資格を重複登録しないよう、従業員ID(employee_id)と資格ID(certification_id)の複合ユニーク制約も設定します。
中間テーブルの設計で見落としがちなのが、 中間テーブル自体に属性を持たせられる 点です。今回の取得日(acquired_date)がまさにそれで、この情報は従業員テーブルにも資格テーブルにも置けません。「誰が」「何を」「いつ」取得したかという3者の交差点に存在する情報だからです。
【7. ジャンル別ITSS合計テーブル(category_itss_totals)】
| カラム名 | データ型 | 主キー | 非NULL | ユニーク | 自動採番 | 外部キー |
|---|---|---|---|---|---|---|
| id | INTEGER | ○ | ○ | ○ | ○ | |
| ジャンルID(category_id) | INTEGER | ○ | ○ | categories(id) | ||
| ITSS合計(max_itss_total) | INTEGER | ○ |
スコア計算の分母となる値です。資格マスタから集計して格納します。
「毎回集計すれば良いのでは?」と思うかもしれませんが、スコア計算のたびに資格マスタテーブル(certifications)をSUM集計すると、データ量が増えたときに計算コストが問題になります。事前に集計結果をテーブルに保持しておくことで、スコア計算のSQLがシンプルかつ高速になります。これは 非正規化(冗長化) の一種ですが、計算結果のキャッシュとして許容される設計パターンです。
ただし、この設計には注意点があります。資格マスタテーブル(certifications)に新しい資格を追加したとき、ジャンル別ITSS合計テーブル(category_itss_totals)の値も手動で再計算しないと整合性が崩れます。今回は学習目的なのでこの構成を採用しますが、実務で集計テーブルを導入する場合は、「元データが変わったら集計も自動で更新される仕組み」(トリガーやバッチ処理)を必ずセットで設計してください。
【8. 従業員スコアテーブル(employee_scores)】
| カラム名 | データ型 | 主キー | 非NULL | ユニーク | 自動採番 | 外部キー |
|---|---|---|---|---|---|---|
| id | INTEGER | ○ | ○ | ○ | ○ | |
| 従業員ID(employee_id) | INTEGER | ○ | employees(id) | |||
| ジャンルID(category_id) | INTEGER | ○ | categories(id) | |||
| スコア(score) | REAL | ○ | ||||
| 算出日時(calculated_at) | TEXT | ○ |
算出日時(calculated_at)を持たせることで、 いつ時点のスコアか を記録できます。従業員が新たに資格を取得した場合、再計算して新しいレコードをINSERTすることで、スコアの推移を追跡できる設計です。
8-3. 正規化の確認
設計したテーブルが第三正規形を満たしているか、セクション3で学んだチェックポイントに沿って確認します。
【第一正規形のチェック】
すべてのカラムが単一値(アトミック)であること。繰り返しグループがないこと。
今回の設計では、1つのセルに複数の値が入っているカラムはありません。従業員が複数の資格を持つ場合も、取得資格テーブル(employee_certifications)に1資格1レコードで格納しています。第一正規形を満たしています。
【第二正規形のチェック】
部分関数従属がないこと。
複合キーを持つのは実質、取得資格テーブル(employee_certifications)だけです(論理的には従業員ID(employee_id)+ 資格ID(certification_id)が候補キー)。非キーカラムの取得日(acquired_date)は、従業員ID単独でも資格ID単独でも決まらず、両方が揃って初めて決まります。部分関数従属はありません。第二正規形を満たしています。
【第三正規形のチェック】
推移的関数従属がないこと。
たとえば従業員テーブル(employees)では、id → 部署ID(department_id)、部署ID → 部署名という推移的な従属がありそうに見えます。しかし、部署名は部署テーブル(departments)に分離済みで、従業員テーブルには部署ID(外部キー)しか持っていません。推移的関数従属は排除されています。第三正規形を満たしています。
9. 物理設計(SQLiteで実装)
いよいよ論理設計で定義したテーブルを、実際のDBMS上に実装します。今回はRDBMSに SQLite を採用しました。理由は以下のとおりです。
- インストール不要(macOS / Linuxなら標準搭載)
- サーバープロセスが不要で、ファイル1つで完結する
- SQL構文はほぼ標準SQLに準拠しており、学習用に最適
SQLiteはMySQLやPostgreSQLと比べて機能が限定的ですが、論理設計の検証やプロトタイプ開発には十分です。本番環境ではMySQL、PostgreSQL、Amazon Aurora等を検討してください。
SQLをみたい方はトグルを開いていただけると、見れるようになっています。
9-1. テーブル作成
論理設計(セクション8)で定義した8テーブルをCREATE TABLEで作成します。
テーブル作成SQLを見る
-- 外部キー制約を有効化(SQLiteはデフォルトで無効)
PRAGMA foreign_keys = ON;
-- 1. 部署テーブル
CREATE TABLE departments (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL UNIQUE
);
-- 2. 役職テーブル
CREATE TABLE positions (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL UNIQUE
);
-- 3. 従業員テーブル
CREATE TABLE employees (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
department_id INTEGER NOT NULL,
position_id INTEGER NOT NULL,
hire_date TEXT NOT NULL,
FOREIGN KEY (department_id) REFERENCES departments(id),
FOREIGN KEY (position_id) REFERENCES positions(id)
);
-- 4. 資格ジャンルテーブル
CREATE TABLE categories (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL UNIQUE
);
-- 5. 資格マスタテーブル
CREATE TABLE certifications (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
abbreviation TEXT NOT NULL,
itss_level INTEGER NOT NULL CHECK(itss_level BETWEEN 1 AND 7),
category_id INTEGER NOT NULL,
FOREIGN KEY (category_id) REFERENCES categories(id)
);
-- 6. 取得資格テーブル(中間テーブル)
CREATE TABLE employee_certifications (
id INTEGER PRIMARY KEY AUTOINCREMENT,
employee_id INTEGER NOT NULL,
certification_id INTEGER NOT NULL,
acquired_date TEXT NOT NULL,
FOREIGN KEY (employee_id) REFERENCES employees(id),
FOREIGN KEY (certification_id) REFERENCES certifications(id),
UNIQUE(employee_id, certification_id)
);
-- 7. ジャンル別ITSS合計テーブル
CREATE TABLE category_itss_totals (
id INTEGER PRIMARY KEY AUTOINCREMENT,
category_id INTEGER NOT NULL UNIQUE,
max_itss_total INTEGER NOT NULL,
FOREIGN KEY (category_id) REFERENCES categories(id)
);
-- 8. 従業員スコアテーブル
CREATE TABLE employee_scores (
id INTEGER PRIMARY KEY AUTOINCREMENT,
employee_id INTEGER NOT NULL,
category_id INTEGER NOT NULL,
score REAL NOT NULL,
calculated_at TEXT NOT NULL DEFAULT (datetime('now')),
FOREIGN KEY (employee_id) REFERENCES employees(id),
FOREIGN KEY (category_id) REFERENCES categories(id)
);
いくつか補足します。
PRAGMA foreign_keys = ON は SQLite固有の設定 です。SQLiteは互換性の都合上、デフォルトで外部キー制約が無効になっています。この1行を忘れると、存在しない部署IDの従業員を登録しても何のエラーも出ません。接続のたびに毎回実行する必要がある点に注意してください。
AUTOINCREMENT について。SQLiteでは INTEGER PRIMARY KEY だけでも自動採番されますが、AUTOINCREMENTを付けると 過去に使われたIDの再利用を防止 できます。AUTOINCREMENTなしの場合、SQLiteは「現在テーブルに存在する最大のROWID + 1」を新しいIDとして割り当てます。そのため、 最大IDを持つ行を削除した場合に限り 、そのIDが再利用される可能性があります。たとえばID=1〜5のレコードがあり、最後のID=5を削除してから新しいレコードを追加すると、再びID=5が割り当てられることがあります。AUTOINCREMENTを付ければ、そのテーブルで 過去に使われた最大のROWIDより必ず大きい値 が割り当てられるため、この再利用が起きません。
9-2. マスタデータの投入
マスタデータ投入SQLを見る
-- 部署
INSERT INTO departments (name) VALUES ('開発部');
INSERT INTO departments (name) VALUES ('インフラ部');
INSERT INTO departments (name) VALUES ('セキュリティ部');
-- 役職
INSERT INTO positions (name) VALUES ('一般');
INSERT INTO positions (name) VALUES ('シニア');
INSERT INTO positions (name) VALUES ('リーダー');
-- 資格ジャンル
INSERT INTO categories (name) VALUES ('基礎');
INSERT INTO categories (name) VALUES ('セキュリティ');
INSERT INTO categories (name) VALUES ('テクニカルスペシャリスト');
INSERT INTO categories (name) VALUES ('マネジメント・戦略');
-- 資格マスタ(13資格)
-- 基礎(category_id = 1)
INSERT INTO certifications (name, abbreviation, itss_level, category_id)
VALUES ('ITパスポート', 'IP', 1, 1);
INSERT INTO certifications (name, abbreviation, itss_level, category_id)
VALUES ('基本情報技術者', 'FE', 2, 1);
INSERT INTO certifications (name, abbreviation, itss_level, category_id)
VALUES ('応用情報技術者', 'AP', 3, 1);
-- セキュリティ(category_id = 2)
INSERT INTO certifications (name, abbreviation, itss_level, category_id)
VALUES ('情報セキュリティマネジメント', 'SG', 2, 2);
INSERT INTO certifications (name, abbreviation, itss_level, category_id)
VALUES ('情報処理安全確保支援士', 'SC', 4, 2);
-- テクニカルスペシャリスト(category_id = 3)
INSERT INTO certifications (name, abbreviation, itss_level, category_id)
VALUES ('ネットワークスペシャリスト', 'NW', 4, 3);
INSERT INTO certifications (name, abbreviation, itss_level, category_id)
VALUES ('データベーススペシャリスト', 'DB', 4, 3);
INSERT INTO certifications (name, abbreviation, itss_level, category_id)
VALUES ('エンベデッドシステムスペシャリスト', 'ES', 4, 3);
INSERT INTO certifications (name, abbreviation, itss_level, category_id)
VALUES ('システムアーキテクト', 'SA', 4, 3);
-- マネジメント・戦略(category_id = 4)
INSERT INTO certifications (name, abbreviation, itss_level, category_id)
VALUES ('プロジェクトマネージャ', 'PM', 4, 4);
INSERT INTO certifications (name, abbreviation, itss_level, category_id)
VALUES ('ITサービスマネージャ', 'SM', 4, 4);
INSERT INTO certifications (name, abbreviation, itss_level, category_id)
VALUES ('ITストラテジスト', 'ST', 4, 4);
INSERT INTO certifications (name, abbreviation, itss_level, category_id)
VALUES ('システム監査技術者', 'AU', 4, 4);
9-3. 従業員データと取得資格の投入
従業員データ投入SQLを見る
-- 従業員
INSERT INTO employees (name, department_id, position_id, hire_date)
VALUES ('山田太郎', 1, 1, '2023-04-01');
INSERT INTO employees (name, department_id, position_id, hire_date)
VALUES ('佐藤花子', 2, 2, '2020-04-01');
INSERT INTO employees (name, department_id, position_id, hire_date)
VALUES ('田中一郎', 3, 3, '2018-04-01');
-- 山田太郎の取得資格(基礎3つ + DB)
INSERT INTO employee_certifications (employee_id, certification_id, acquired_date)
VALUES (1, 1, '2022-11-01'); -- ITパスポート
INSERT INTO employee_certifications (employee_id, certification_id, acquired_date)
VALUES (1, 2, '2023-05-01'); -- 基本情報技術者
INSERT INTO employee_certifications (employee_id, certification_id, acquired_date)
VALUES (1, 3, '2024-04-01'); -- 応用情報技術者
INSERT INTO employee_certifications (employee_id, certification_id, acquired_date)
VALUES (1, 7, '2025-04-01'); -- データベーススペシャリスト
-- 佐藤花子の取得資格(基礎3つ + NW + セキュリティ2つ)
INSERT INTO employee_certifications (employee_id, certification_id, acquired_date)
VALUES (2, 1, '2019-11-01'); -- ITパスポート
INSERT INTO employee_certifications (employee_id, certification_id, acquired_date)
VALUES (2, 2, '2020-05-01'); -- 基本情報技術者
INSERT INTO employee_certifications (employee_id, certification_id, acquired_date)
VALUES (2, 3, '2021-04-01'); -- 応用情報技術者
INSERT INTO employee_certifications (employee_id, certification_id, acquired_date)
VALUES (2, 6, '2022-04-01'); -- ネットワークスペシャリスト
INSERT INTO employee_certifications (employee_id, certification_id, acquired_date)
VALUES (2, 4, '2021-06-01'); -- 情報セキュリティマネジメント
INSERT INTO employee_certifications (employee_id, certification_id, acquired_date)
VALUES (2, 5, '2023-04-01'); -- 情報処理安全確保支援士
-- 田中一郎の取得資格(基礎2つ + セキュリティ2つ + NW)
INSERT INTO employee_certifications (employee_id, certification_id, acquired_date)
VALUES (3, 2, '2018-05-01'); -- 基本情報技術者
INSERT INTO employee_certifications (employee_id, certification_id, acquired_date)
VALUES (3, 3, '2019-04-01'); -- 応用情報技術者
INSERT INTO employee_certifications (employee_id, certification_id, acquired_date)
VALUES (3, 4, '2019-06-01'); -- 情報セキュリティマネジメント
INSERT INTO employee_certifications (employee_id, certification_id, acquired_date)
VALUES (3, 5, '2020-04-01'); -- 情報処理安全確保支援士
INSERT INTO employee_certifications (employee_id, certification_id, acquired_date)
VALUES (3, 6, '2021-04-01'); -- ネットワークスペシャリスト
9-4. スコアの算出
まず、各ジャンルのITSS合計(満点)を集計してテーブルに格納します。
ジャンル別ITSS合計を計算するSQLを見る
-- ジャンル別ITSS合計を算出
INSERT INTO category_itss_totals (category_id, max_itss_total)
SELECT category_id, SUM(itss_level)
FROM certifications
GROUP BY category_id;
次に、各従業員のジャンル別スコアを算出します。
従業員スコアを計算するSQLを見る
-- 従業員スコアを算出
INSERT INTO employee_scores (employee_id, category_id, score)
SELECT
e.id,
cat.id,
ROUND(
CAST(COALESCE(acquired.total_level, 0) AS REAL)
/ cit.max_itss_total * 100,
1
)
FROM employees e
CROSS JOIN categories cat
JOIN category_itss_totals cit ON cat.id = cit.category_id
LEFT JOIN (
-- 従業員ごと・ジャンルごとの取得ITSSレベル合計
SELECT
ec.employee_id,
c.category_id,
SUM(c.itss_level) AS total_level
FROM employee_certifications ec
JOIN certifications c ON ec.certification_id = c.id
GROUP BY ec.employee_id, c.category_id
) acquired ON e.id = acquired.employee_id AND cat.id = acquired.category_id;
ポイントは CROSS JOIN です。全従業員 × 全ジャンルの組み合わせを作り、そこにLEFT JOINで実際の取得状況を結合します。資格を1つも持っていないジャンルはCOALESCEで0になり、スコアは0.0点になります。
このSQLの処理の流れを整理すると、次のようになります。
-
employees CROSS JOIN categoriesで、全従業員 × 全ジャンルの直積(デカルト積)を生成する。3人 × 4ジャンル = 12行 -
JOIN category_itss_totalsで、各ジャンルの満点(分母)を付与する - サブクエリ
acquiredで、従業員ごと・ジャンルごとの取得ITSSレベル合計(分子)を事前に計算する -
LEFT JOINで分子を結合する。資格を1つも持っていない組み合わせはNULLになる -
COALESCE(acquired.total_level, 0)で、NULLを0に変換する -
CAST(... AS REAL)で整数除算を防ぎ、ROUND(..., 1)で小数第1位に丸める
CROSS JOINは「すべての組み合わせを網羅的に作りたいとき」に使うJOINです。通常のINNER JOINやLEFT JOINでは、結合条件に一致するレコードしか結果に含まれません。今回の場合、ある従業員がセキュリティ資格を1つも持っていなくても、「スコア0.0点」として結果に含めたいので、CROSS JOINで全組み合わせを作ってからLEFT JOINする、という手順が必要になります。
9-5. 結果の確認
結果確認用SQLを見る
-- スコア一覧を見やすく表示
SELECT
e.name AS 従業員名,
d.name AS 部署,
p.name AS 役職,
cat.name AS ジャンル,
es.score AS スコア
FROM employee_scores es
JOIN employees e ON es.employee_id = e.id
JOIN departments d ON e.department_id = d.id
JOIN positions p ON e.position_id = p.id
JOIN categories cat ON es.category_id = cat.id
ORDER BY e.id, cat.id;
スコアがきれいに算出されました。佐藤花子は基礎とセキュリティが満点(100.0)、田中一郎はITパスポートを持っていないため基礎が83.3点になっています。
10. 実務の中でわかったこと
ここまで教科書どおりの綺麗なDB設計をしてきましたが、はっきり言って、 実務はこのとおりにいかないことも多いです 。
10-1. 思ったよりとんでもなくデータは汚い
実際に現場で出会うデータは、とんでもない構造をしていることが珍しくありません。
- 1つのカラムにカンマ区切りで複数の値が入っている(第一正規形すら満たしていない)
- 外部キー制約が一切設定されておらず、存在しないIDを参照しているレコードが大量にある
- カラム名が「data1」「data2」「data3」で、何のデータかコードを読まないとわからない
- 同じ情報が5つのテーブルに重複して保存されており、それぞれ微妙に値が違う
こうした状況に直面すると、「正規化とか制約って教科書の中だけの話では?」と感じることもあるかもしれません。
しかし、 概念設計 → 論理設計 → 物理設計の順をしっかり踏むことで、たとえ汚いデータに対しても「現状における最善の設計」を導き出せる と私は考えています。
実際、私が一緒に仕事をしている20年以上DB設計に携わっている先輩も同じようなことを言っていました。
「結局さ、どんな案件でもまず『この業務で何を扱ってるか』から入るんだよ。ER描くかどうかは別にして、頭の中では絶対そこを通す。構造に落とすのはその次で、テーブルや型の話はもっと後。この順番さえブレなきゃ、データがどれだけ汚くても、あとでドキュメント書くときに『なんでこうなってるか』を自分の言葉で説明できる。逆にここ飛ばして物理から入った設計は、半年後の自分が一番困るんだよね」
(かっこいい感じに意訳)
先輩はわざわざ教科書チックな概念設計、論理設計、物理設計という言葉を使ってはいませんでしたが、本質的にはこの流れのことを言っています。つまり、これは概念とか論理とかの堅苦しい名前がついているだけの話で、業務要件から入るというごく一般的なITの開発プロセスと同様だと考えています。
新規設計であれば今回のようにスッキリした構造が作れますが、レガシーシステムのリプレイスや既存DBの改善では、理想と現実のギャップを埋める作業が発生します。それでも設計プロセスを丁寧に踏むことで、改善の方向性を見失わずに済みます。
10-2. 正規化と非正規化のバランス
正規化はデータの整合性を守る最善の方法ですが、テーブル数が増えるとJOINが多くなり、パフォーマンスが低下することがあります。たとえば、レポート画面で毎回7テーブルをJOINするクエリが走っている場合、冗長カラムの追加やサマリテーブルの導入で大幅に速度が改善することがあります。
今回のジャンル別ITSS合計テーブル(category_itss_totals)も、本来は資格マスタテーブル(certifications)からリアルタイムに集計できるデータをあえてテーブルに保持しています。これは非正規化の一例です。
ただし、非正規化は 整合性というコストと引き換えに速度を買う選択 です。まずは正規化された状態でインデックスの最適化やクエリの見直しを行い、それでも足りない場合に検討するのが基本です。
10-3. 論理設計のアンチパターン
【単一参照テーブル(とりあえずマスタ)】
部署、役職、資格ジャンルといった異なる種類のマスタを、1つの汎用テーブルにまとめてしまうパターンです。 type カラムで区別するため一見スッキリしますが、外部キー制約が正しく効かない、CHECK制約がtype別に定義できないなど、制約の恩恵を受けられなくなります。
【ダブルミーニング(1つのカラムに複数の意味)】
時期や条件によってカラムの意味が変わる設計です。たとえば「status」カラムに、ある時期は「承認状態」、別の時期は「支払い状態」を入れているケース。SQLのWHERE句が複雑になり、バグの温床になります。
【テーブル分割の誤り】
「データが多いからテーブルを分割しよう」と、年度別にテーブルを分けてしまうパターンです(orders_2024、orders_2025…)。年度をまたぐ検索でUNION ALLが必要になり、SQLが煩雑化します。水平分割が必要な場合は、DBMSのパーティション機能を使うのが正解です。
10-4. デッドロックへの対処
もう1つ、実務で地味にハマりやすいのが デッドロック です。複数のトランザクションが互いに相手のロック解放を待ち続ける状態で、処理が停止します。
たとえば、トランザクションAが「従業員テーブル(employees) → 資格マスタテーブル(certifications)」の順にロックを取得し、トランザクションBが「資格マスタテーブル(certifications) → 従業員テーブル(employees)」の順にロックを取得すると、互いに相手のロック解放を待ち続けてデッドロックが発生します。

対策の第一原則は 「すべてのトランザクションで、テーブルへのアクセス順序を統一する」 ことです。上記の例なら、AもBも「従業員テーブル(employees) → 資格マスタテーブル(certifications)」の順でアクセスすればデッドロックは起きません。加えて、トランザクションの範囲を必要最小限に絞り、ロックを保持する時間を短くすることも効果的です。
SQLiteはファイル単位のロック機構を使うため、同時書き込みが多い環境ではデッドロックよりも「database is locked」エラーに遭遇しやすいです。本番環境で同時アクセスがある場合は、MySQL / PostgreSQLなどの行レベルロックに対応したDBMSを使いましょう。
実務で出会う汚いデータに心が折れそうになったら、この章を思い出してください!
おわりに
おつかれさまでした〜!!
ここまでお読みいただきありがとうございます。
DB設計はとても楽しいものです。私にとっては パズル みたいな感覚に近いです。
実際のデータは汚く、整えることが難しかったりもしますが、正規化やテーブル分割がうまくはまったときは非常に気持ちが良いです、笑。
今回作ったスコアリングシステムはシンプルな構造ですが、DB設計の基礎である 制約・正規化・ER図・3段階の設計プロセス がすべて詰まっています。ぜひ手元のSQLiteで動かしてみてください。
データベーススペシャリスト試験は落ちましたが、この記事が誰かの学びの役に立てば、あの3点差も無駄ではなかったと思えます。
運よくネットワークスペシャリストや情報処理安全確保支援士試験(旧セキュリティスペシャリスト)には合格していますので、また機会があればネットワークやセキュリティについてもまとめてみようと思います。
ではまた、お会いしましょう。

Comments
Let's comment your feelings that are more than good