Summary of Qwen3.5 GGUF Evaluations + My Evaluation Method
Including evaluations with KV cache quantized
The GGUF format for LLMs is now extremely popular because many applications have been built around it. LM Studio and Ollama, for instance, make running LLMs locally very easy through GGUF models.
While 16-bit GGUF versions do exist, most GGUFs are used in quantized form to reduce memory consumption and speed up inference. Dozens of quantization formats are available. I discussed their differences here:

The problem is that, despite how widely they are used, they are often poorly evaluated. Most users do not know how good the particular version they are using actually is. They rely on vibes and feelings, often without even knowing how the original model performs.
In this article, I summarize all my Qwen3.5 GGUF evaluations and give more details on how I ran them. I also provide evaluation results for abliterated models and with the KV cache quantized.
Note: I’ll publish later this week another (large) study on Qwen3.5 quantization, including INT4 and NVFP4 quantization recipes and evaluations, in format optimized to run with fast inference engines like vLLM and SGLang.
How to Evaluate GGUFs?
Perplexity (PPL) and KL divergence (KLD) can be used to capture trends. Unsloth has published these numbers from time to time, and will now do so more systematically for their releases. That’s a huge advance given how popular their models are.
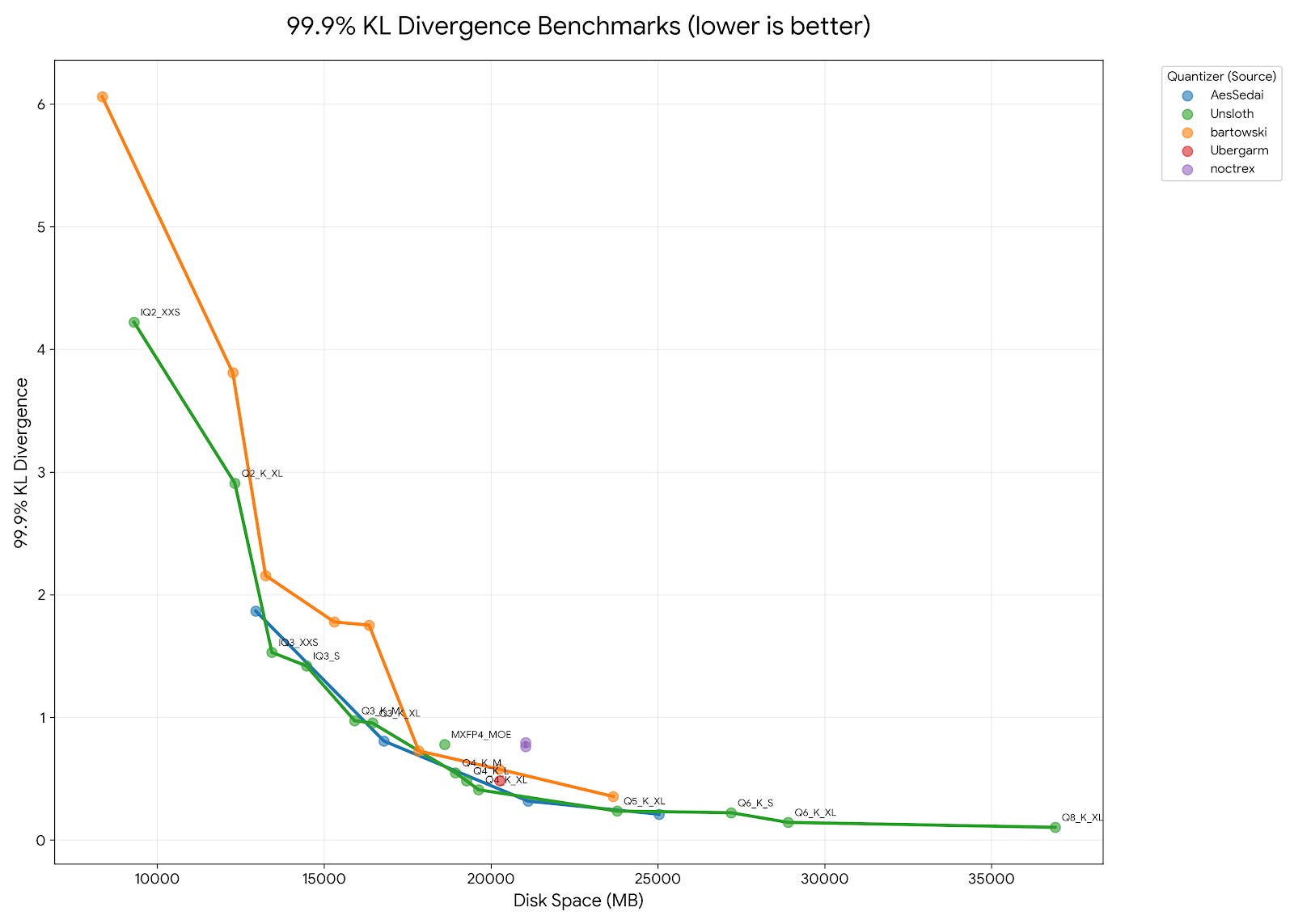
Yet differences in PPL and KLD are very hard to interpret. They do not tell you how much worse the quantized model is on a particular task. Moreover, since most GGUF users do not have a machine learning background, these metrics are often misinterpreted. People get misled by statements like “+0.5 PPL is big.” No, not necessarily. It can be insignificant. It always depends on the model.
So why not use the same standard benchmarks (coding, MCQ, …) we use to evaluate the original non-GGUF LLMs?
Because it is slow and costly.
The llama.cpp backend, which most inference frameworks use for GGUFs, is very slow under high concurrency. Throwing hundreds of benchmark prompts at a llama-server is much slower than sending the same prompts to a vLLM server.
Why not use vLLM to serve GGUFs directly?
Yes, vLLM can serve GGUF models. But support is still experimental and performance is poor. Also, since this is not the same implementation as llama.cpp, it could produce different results from what users actually see in practice.
Another option I tried a few times was converting GGUF back to safetensors and then serving the resulting model with vLLM. That gives you the full speed and optimizations of vLLM. In practice, though, this is cumbersome. Converting from safetensors to GGUF is easy; the reverse operation is error-prone because you need to reconstruct the original Transformers-compatible files. It is not impossible, but it is messy.
And even if you do manage to get it working, the resulting model is not the same as the original GGUF. It becomes a dequantized 16-bit model. It is close, but the inference math is slightly different.
So that leaves the original option: llama.cpp as the backend.
Hardware: GH200
For the past few months, I have been renting a GH200 through Prime Intellect (provisioned by Lambda). In terms of cost and capability, I think this is the ideal “GPU” for GGUF benchmarking, although NVIDIA calls it a “superchip.” I rent it for $1.49/hour, and it offers H100-class compute, more GPU memory (96 GB vs 80 GB on the H100), and around 460 GB of unified memory.
That unified memory is particularly important here. llama.cpp supports it very well. Without it, I would not have been able to evaluate GGUF versions of Qwen3.5 397B.
The main downside is that this is an ARM machine. It comes with some compilation issues. But since the release of the DGX Spark, another popular ARM machine by NVIDIA, support across most frameworks has improved substantially. I cannot wait to try the GB300.
Subsampling Benchmarks for Cheaper GGUF Evaluations
The goal is to use as few samples as possible to reduce costs while getting meaningful evaluation results.
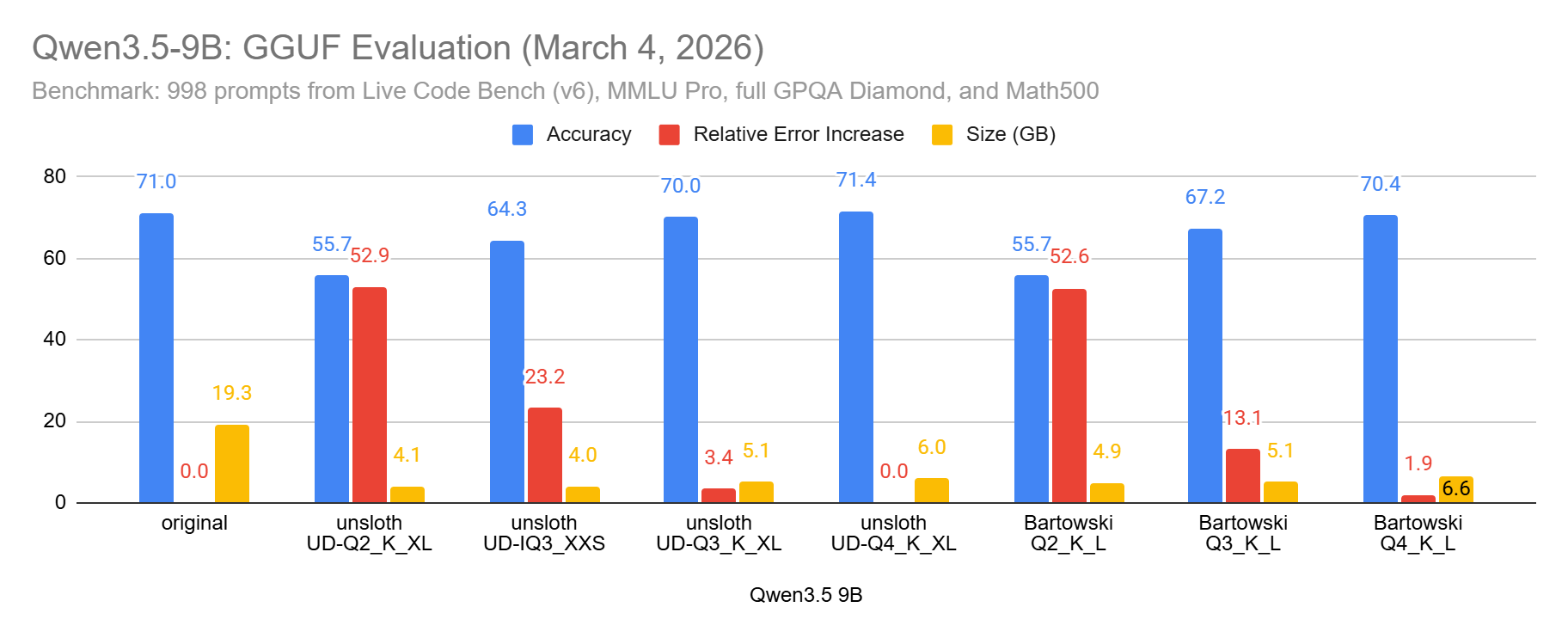
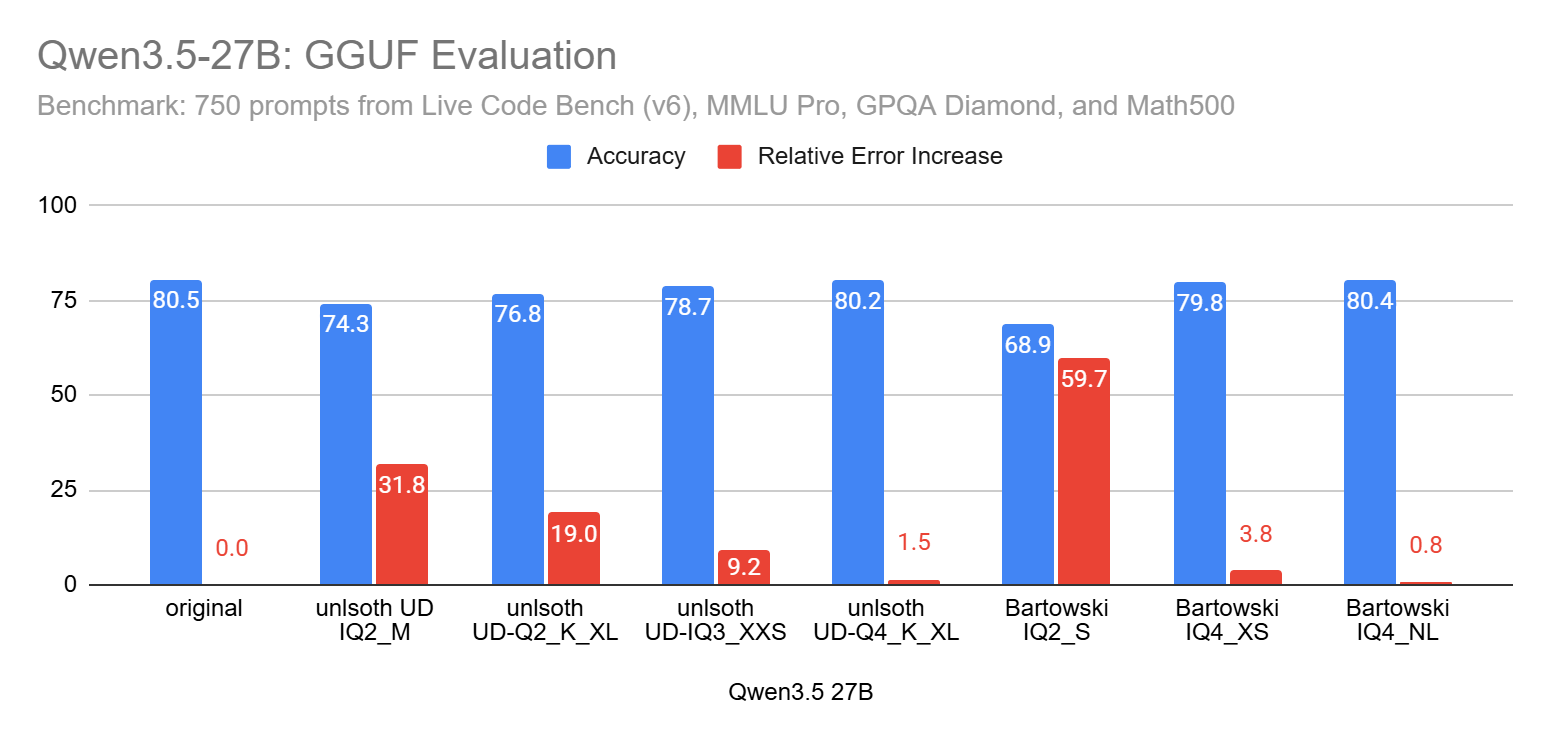
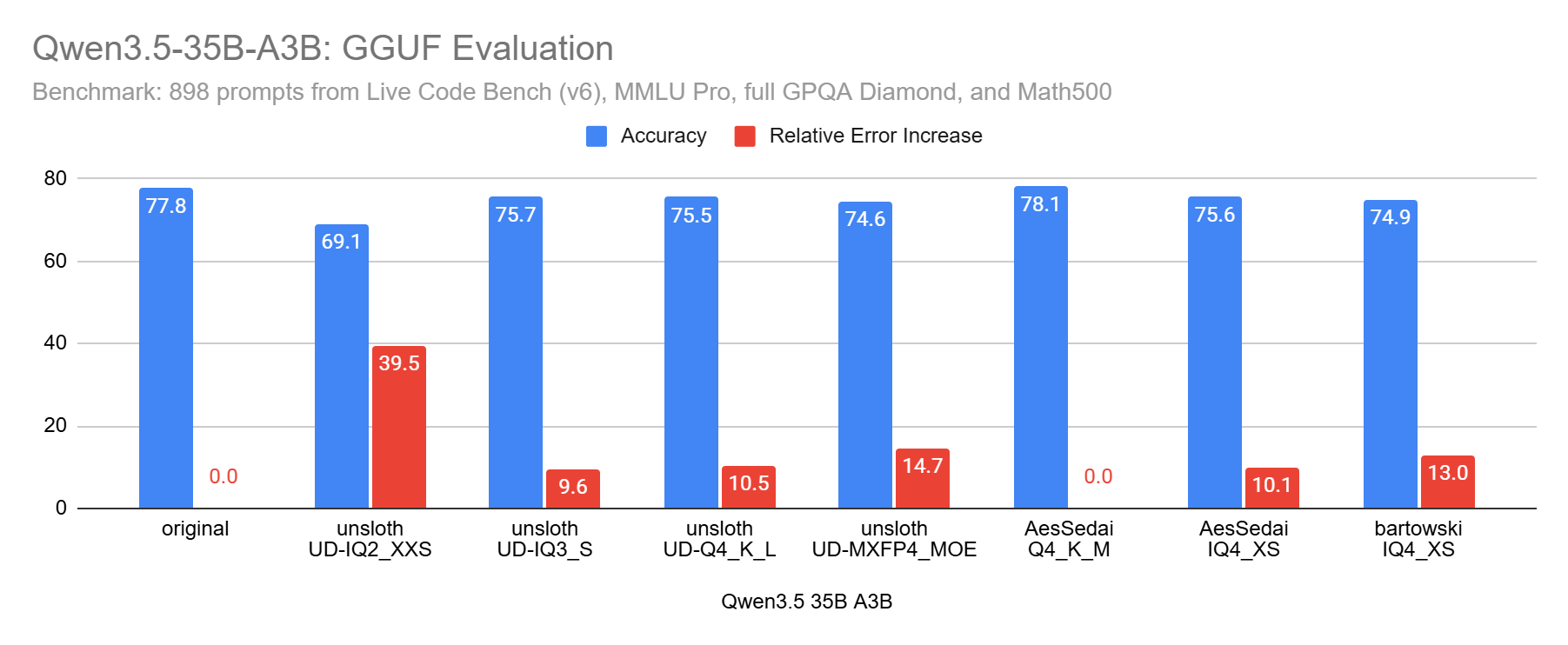
I used between 750 and 998 prompts from LiveCodeBench (coding problems), GPQA Diamond (difficult Science questions), MMLU-Pro (general knowledge MCQ), and Math500 (easy to moderately difficult Math questions). For smaller models, like Qwen3.5 9B, I used 998 prompts, and fewer for the larger ones.
LiveCodeBench, GPQA Diamond, and MMLU-Pro are useful because they reveal different kinds of degradation after quantization. Reasoning benchmarks such as GPQA Diamond and LiveCodeBench are especially sensitive because quantization errors can compound across multiple steps of reasoning. A model may still look fluent while becoming less reliable whenever it needs to chain many operations together.
MMLU-Pro is useful for a different reason: it is less about long reasoning chains and more about whether the model still retains the same breadth of knowledge. Quantization tends to smooth out weight outliers and compress fine-grained distinctions in the parameter space. That can remove or blur some of the knowledge stored in the original model, even when the model still “sounds” competent. Taken together, these benchmarks help separate three effects: loss of reasoning robustness, loss of knowledge, and general accuracy degradation.
The reason for including Math500 is slightly different.
Math500 is old and easy for LLMs. Many models score near 100%, especially after accounting for ambiguous or incorrect items in the benchmark. So why use it?
Start with an easy test to reduce costs.
If a recent model drops by more than 3% on Math500, it is almost certainly a bad quantization. In most cases, you can stop the evaluation there after several reruns to confirm it.
Math500 tells me when a model is nearly broken, but it does not tell me how close it is to the original.
In my Qwen3.5 runs, even at Q2, Math500 stays roughly stable. Basic reasoning still looks fine.
That matches why many low-bit GGUFs can feel “unchanged” on moderately difficult tasks. But once you move to MMLU-Pro and more reasoning-heavy workloads, the gap shows up quickly: models look less knowledgeable, and performance drops become obvious. In many cases, you get the performance of an older model at far greater cost.
Results for Qwen3.5 397B, 35B, 27B, and 9B
Some caveats
Very important points:
Using only up to 1k samples, as I did, is far from enough to conclude anything with 100% certainty.
To reduce the cost, I limited the number of new tokens generated to 32k. This is enough to see how quantization errors accumulate for most use cases. Performance for longer sequences will be worse. But for the max context length of Qwen3.5 (262k), you are unlikely to see a significant difference between 32k vs 262k tokens, except if you quantize the KV cache (not automatically worse, but I didn’t confirm).
I used different numbers of evaluation samples for each model. The results are not comparable across models (e.g., comparing 9B’s scores against 27B’s scores is tempting but completely meaningless).
Moreover, multiple GGUFs I evaluated have since been updated. I know both Unsloth and Bartowski have done this. Note, however, that I ran my evaluations of Unsloth GGUFs after they had already removed MXFP4 from their 35B, 27B, and 9 models (except, of course, for MXFP4_MOE), though more updates followed after that.
They both claim improved KLD and/or PPL. So presumably the benchmark results are now better, but there is no guarantee. It is unlikely, but they could be worse. It is also very unlikely that a model with a very high relative error would suddenly become much better after their update.
Nonetheless, treat my results as a blurry picture of the truth rather than a perfectly current snapshot.
How to interpret the results
Benchmark scores vary from one seed to another, and the size of that variation depends on the benchmark. As a result, when quantization is done well, a quantized model can sometimes score higher than the original model. When that happens, it should not be interpreted as evidence that the quantized model is better. Rather, it is strong evidence that the quantized model performs similarly to the original.
Averaging scores across benchmarks helps smooth out this variation. I do not report per-benchmark results because the number of samples for each benchmark is too small, and presenting them individually would be misleading.
Given the margin of error in these benchmarks, a relative error change of around ±10% is not especially meaningful. Once the increase goes beyond 10%, it becomes reasonable to question whether the model is still worth using, or whether a smaller but less aggressively quantized model would be a better choice.
Relative Error Increase calculation
In the evaluations below, I report the Relative Error Increase.
Given a benchmark with 100 prompts:
Model A: 90% accuracy → 10 errors
Quantized Model A: 85% accuracy → 15 errors
That is a 50% relative error increase.
This is much easier to read than raw accuracy alone.
Results
Note: I didn’t report the model size in all the charts because I didn’t note it when I ran the evaluations. Since the models have been updated, I can’t easily retrieve it.
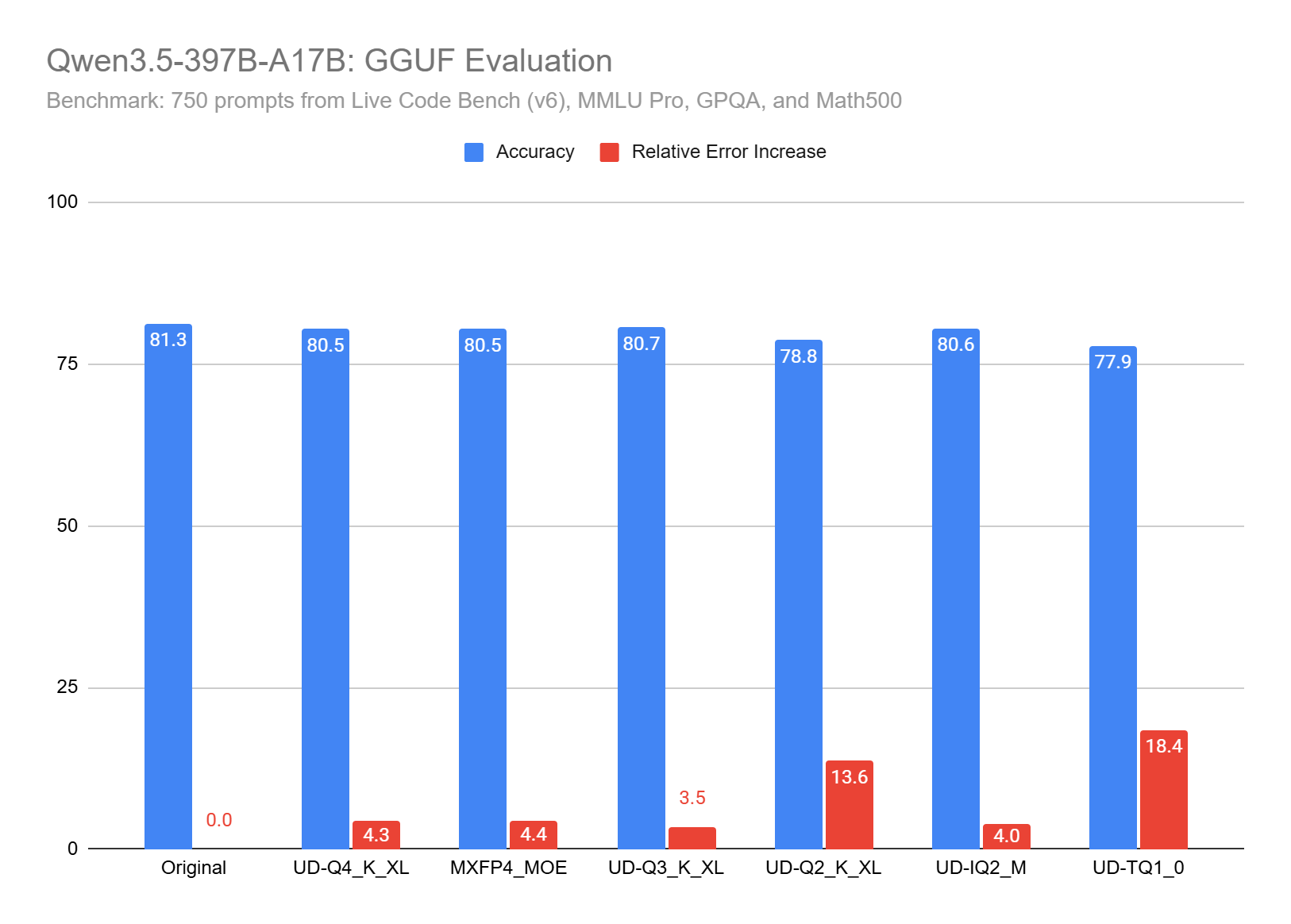
Conclusion
Qwen3.5 397B is very robust to quantization. Many weights can be compressed without much impact on the final accuracy. I think many of these weights could even be entirely removed. I’ll try it in another article. Unsloth’s UD IQ2_M is safe to use while reducing the memory consumption by several hundred GBs.
For all the other Qwen3.5 I’ve evaluated: Avoid Q2. If with Q3 you still don’t have enough memory, use a smaller Qwen3.5. But note that even Q3 is not always good enough. However, Q4 overall is very safe.
Abliterated Qwen3.5 9B GGUFs
Since these models are quite popular, I was also curious to see how good the abliterated (uncensored) versions of Qwen3.5 are.
As I expected, even at Q6_K, the results are bad:
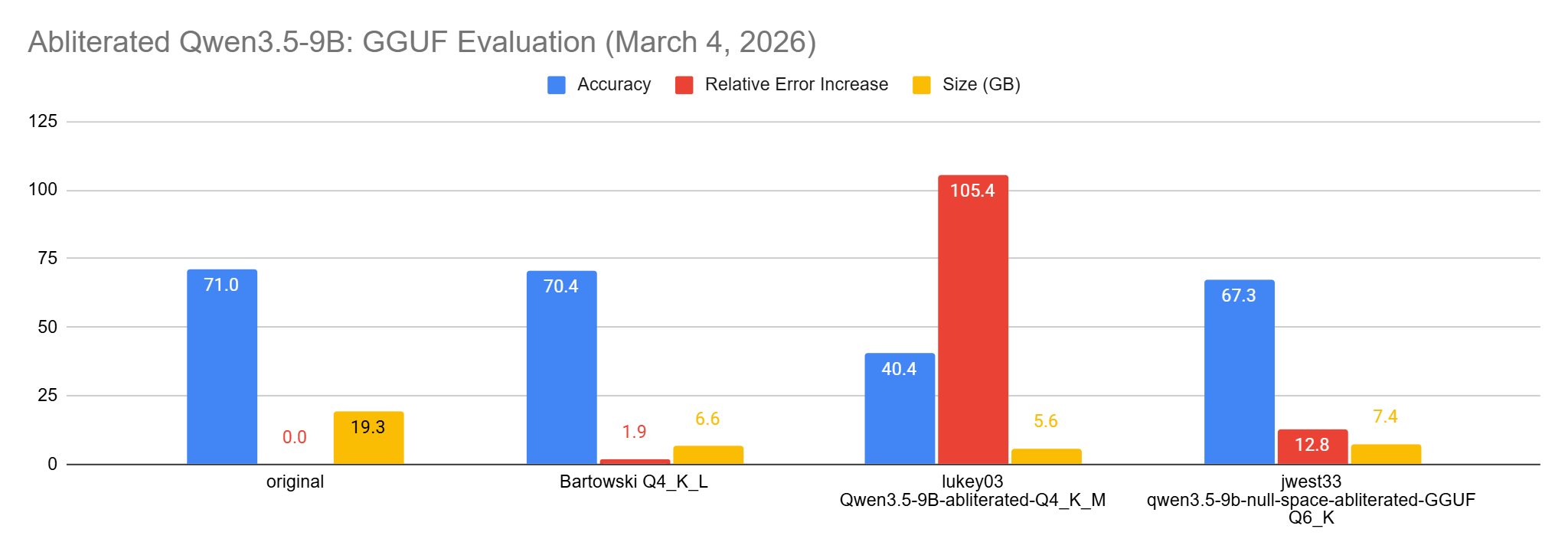
The two most popular abliterated GGUF versions of Qwen3.5 9B significantly underperform a Q4_K_L.
Abliterating a model while preserving its accuracy is hard. Some models will be better than this, but since they are not evaluated, it’s not easy to know how much this uncensoring costs in terms of accuracy.
