はじめに
世間では生成AIのニュースで賑やかです。生成AIには、①GAN、②VAE、③Diffusion modelなどがあります。拡散モデル(Diffusion model)を知らなかったので調査しました。本記事では、③Diffusion modelについて簡単に紹介します。
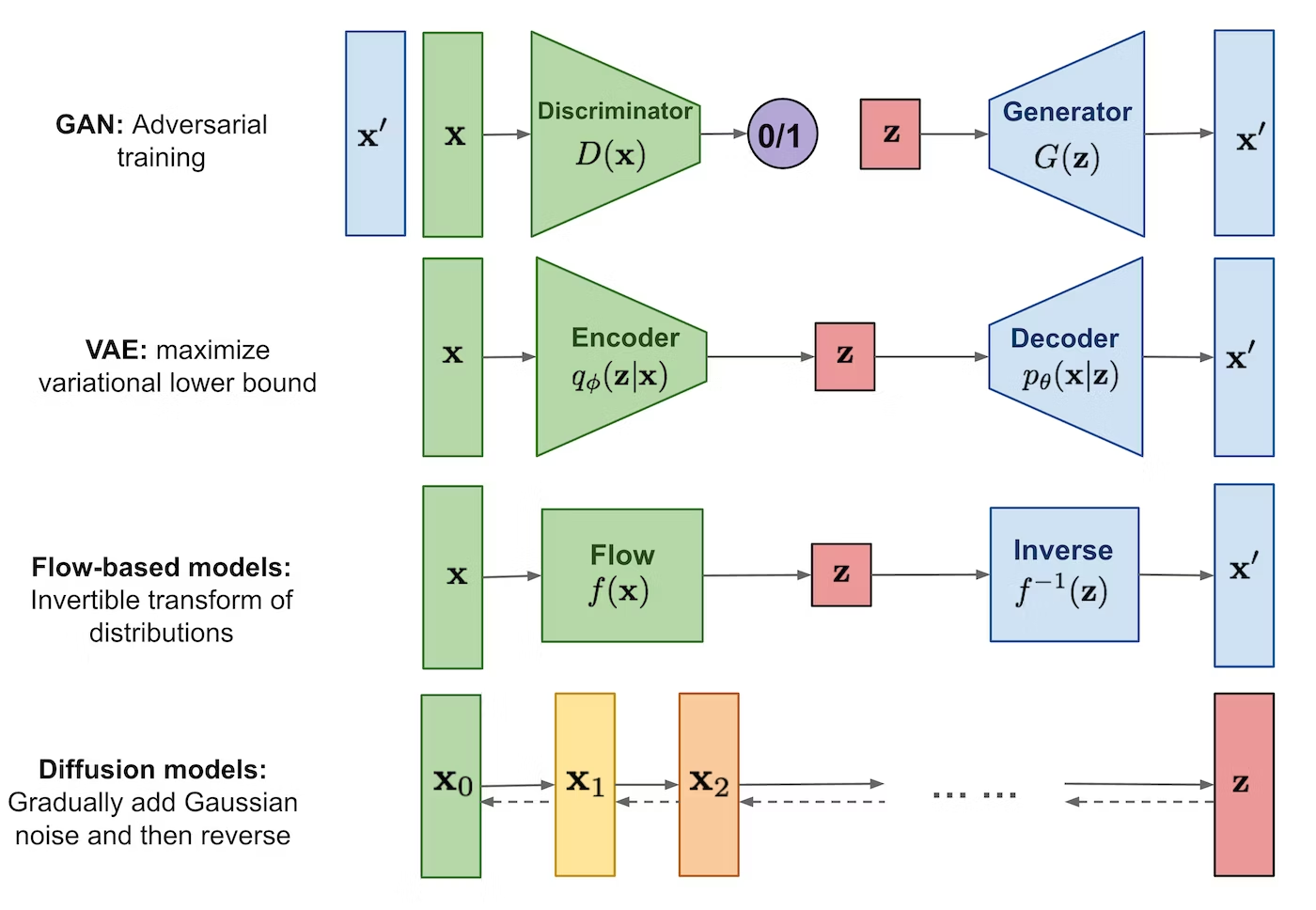
GANやVAEとなにがちがうの?
拡散モデルは、データからノイズ(潜在変数)への変換の逆変換と考えるところがGANやVAEと違います。拡散モデルでは、データに徐々にノイズを付加する過程(拡散過程)と、徐々にノイズを除去する過程(逆拡散過程)を考えます。拡散過程を仮定したことで、Encoderのパラメータの学習が不要になりました。
拡散モデルの長所と短所
長所
- 2乗誤差最小化であるため最適化がシンプルである
- 多様なデータの生成に強い
- 理論的な背景が明確
短所
- 生成が遅い
- 高次元データの生成する際は、潜在変数は同じ次元であるため、次元が高くなる
変分下限(Evidence Lower Bound:ELBO)
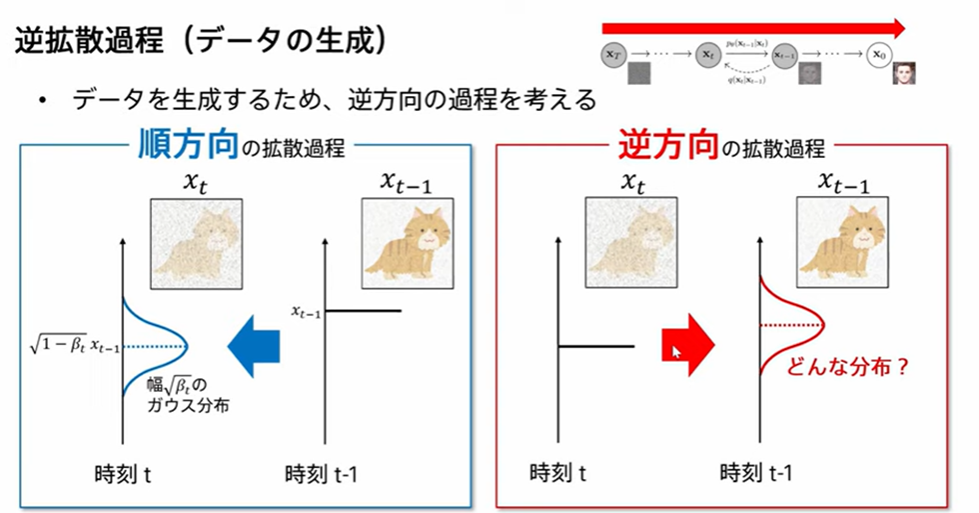
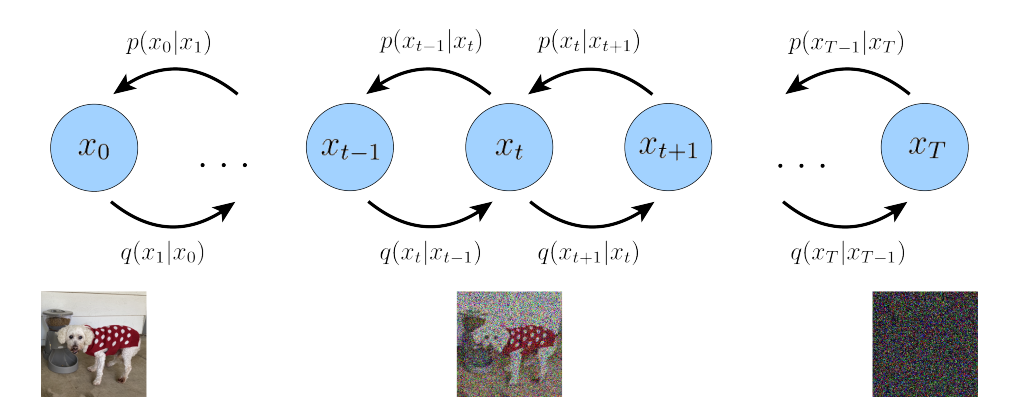
まず、順方向の拡散過程を考えます。
ここで、データに徐々にノイズを付加する過程(拡散過程)は、もはや確率分布
つぎに、逆方向の拡散過程を考えます。
ノイズを除去する過程(逆拡散過程)での条件付き確率
表記を簡単にするために、
対数尤度
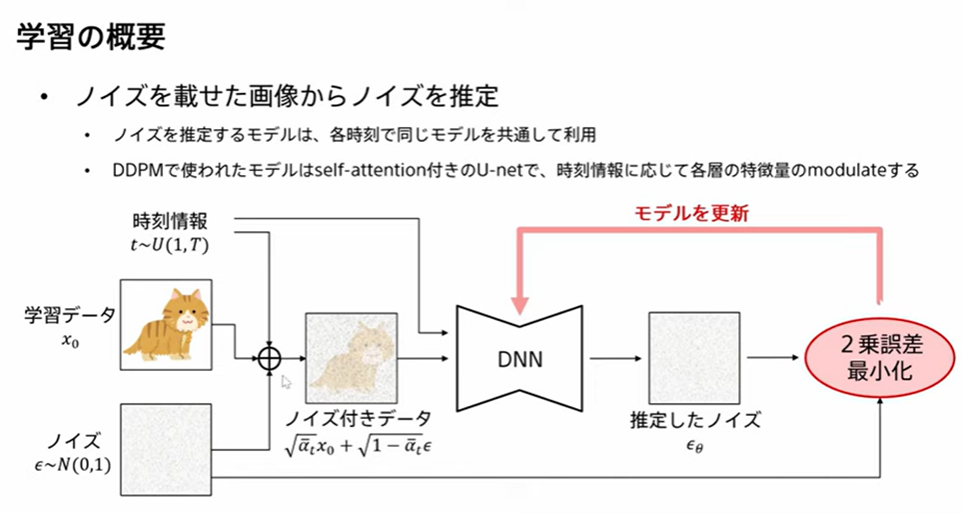
拡散モデルの学習
式変形の詳細は下記を参考にしてください。
VAEと同様にELBO
ELBO
第3項をさらに式変形すると、
数値実験で、係数を無視しても問題がないことがわかっているので、えいや!と無視してしまいます。
推定したノイズ
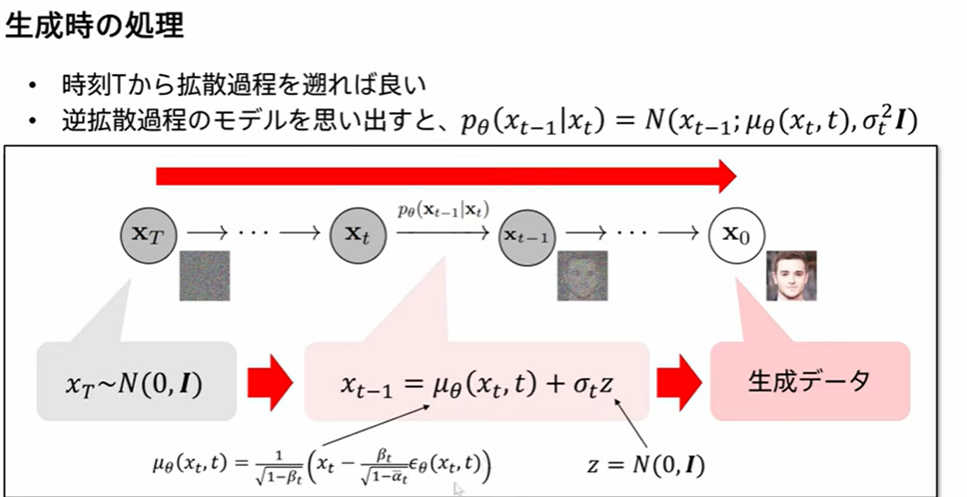
データの生成
参考文献
- データ生成・変換のための機械学習 第7回前編「Diffusion models」
- Understanding Diffusion Models: A Unified Perspective
- 拡散モデル データ生成技術の数理、岡野原大輔、岩波書店
- 拡散モデルのPytorch実装
- 多変量正規分布の場合のKullback Leibler Divergenceの導出
- Step-by-Step Diffusion: An Elementary Tutorial
おわりに
ELBO

Comments
Let's comment your feelings that are more than good