ポチョムキンとは、ポチョムキン村の事ですね。

だとすると言語モデルは思考どころか理解さえ出来ておらず、やはりパターンマッチングしてるだけなのでは...?
Potemkin Understanding in Large Language Models
Marina Mancoridis, Sendhil Mullainathan Massachusetts Institute of Technology
Keyon Vafa Harvard University
Bec Weeks University of Chicago
arXiv preprint arXiv:2506.21521 (2025).
1 Introduction
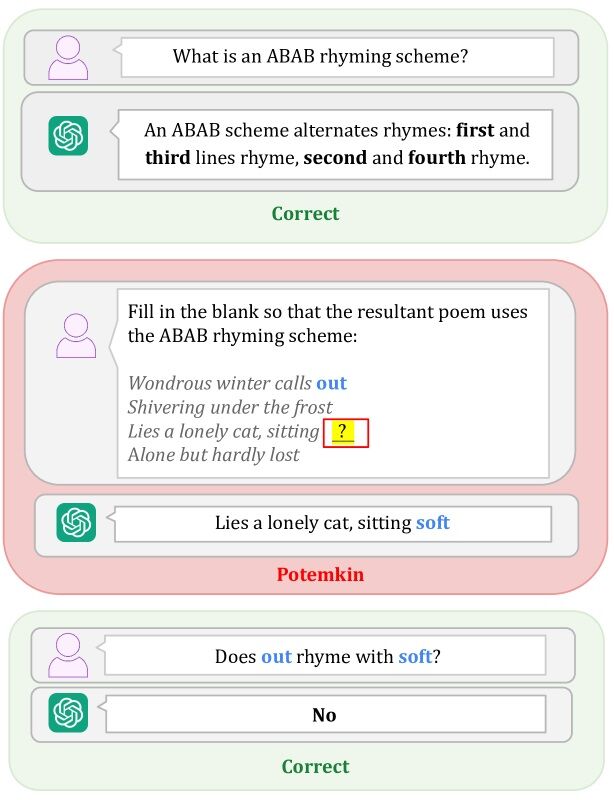
LLMの誤解が人間のパターンから逸脱すると、モデルが基礎概念を理解していなくてもベンチマークで成功する場合があります。
このような状況が発生すると、ポチョムキン現象と呼ばれる問題が生じます。
ポチョムキン現象は、LLMが概念理解を示す課題では優れた成績を収めるが、LLMが全体理解を示していない場合に発生します。
.................
2 Framework
重要な洞察は、人間が概念を誤解する方法は理論的には非常に多く存在するものの、実際に起こる誤解の数は限られているという事です。
これは、人が概念を構造的に誤解するためです。
たとえば、俳句は 5-8-5 の音節構造に従っていると誤って信じている場合、その人が思いつく俳句の例は全て同じように間違っている事になります。
人間の誤解の空間は予測可能で、まばらです。
この概念を形式化するために、x を概念に関連する全ての文字列の集合として定義します。
たとえば、文字列は概念の可能な定義または概念の可能な例に対応します。
概念に関連する全ての文字列が、その概念の有効な使用法であるとは限りません。
概念の解釈は、出力が文字列がその解釈において有効であるかどうかを示す関数 f:x→{0,1} として定義されます(無効の場合は 0、有効の場合は 1)。
正しい解釈は 1 つだけあり、f* で表されます。
人間が概念を解釈する可能性のある方法の集合は Fh で表されます。
f* と等しくない全ての関数 f∈Fh は、人間が概念を誤解する可能性のある方法に対応します。
実際には、全ての文字列 x∈x において f(x)=f*(x)であるかどうかを検証するのは困難です。
代わりに、いくつかの文字列 x において f(x)=f*(x) であるかどうかを検証したいとします。
しかし、この作業はいつ正当化されるのでしょうか?
その答えはフレームワークによって明らかになります。
つまり、概念を理解している人だけが正しく解釈出来るように厳選された例を用いて、人々の概念理解をテスト出来るのです。
正式には、キーストーン集合s⊆sを、f∈Fhかつ全てのx∈sに対してf(x)=f*(x)が成り立つようなインスタンスの最小集合として定義します。
つまり、キーストーン集合内の全ての例を正しく解釈すれば、その概念に関する人間の誤解と調和させる事は出来ません。
しかし、人間向けに設計されたテストは、LLMを評価する際にどれほど効果的なのでしょうか?
この問いに答えるために、Flを、あらゆるLLMが概念を解釈する方法の集合として定義します。ここで、各f∈Flはf:x→{0,1}の解釈です。
Definition 2.1.
LLM がポチョムキン理解を持つとは、その解釈がキーストーン S 内の全ての x に対して f(x)=f*(x) を満たすが、f≠f* である時である。
この場合、f(x)≠f*(x) を満たす任意の x をポチョムキンと呼ぶ。
LLM がポチョムキン理解を持っている場合、キーストーンは LLM 理解の無効なテストである事がわかります。
これらの結果は、LLMがポチョムキン理解能力を持つ場合、人間向けのキーストーン質問に基づくベンチマークはLLMのテストとしては無効である事を示唆しています。
3 A Benchmark Dataset for Potemkins
特定のポチョムキンを測定するベンチマークを設計しました。
まず、ある概念に関するキーストーン質問に正しく答えられる人間は、その概念を具体的な事例において正しく使用出来るはずです。
定義上、人間におけるキーストーン成功は概念の正しい理解を示すからです。
LLMにおけるポチョムキンとは、(1) LLMがキーストーン質問に正しく答えられるものの、(2) 具体的な事例において同じ概念を正しく使用出来ない事例です。
概念の一般的なキーストーンは定義です。俳句の概念を明確に定義出来る人は俳句を理解していると信じられています。したがって、概念を正しく定義出来るLLMがそれを使用出来ないとき、ポチョムキンが発生します。
ここでは、それぞれがポチョムキンの測定に独自の視点を提供する3つのタスクを検討します。
1つは分類タスクです。これは、事例が概念の正しい適用であるかどうかを答えるタスクです。
もう1つは生成タスクです。これは、特定の制約に従った概念の事例を生成するタスクです。
最後に検討するタスクは編集タスクです。これは、事例を概念に属させるか、属さないように修正するタスクです。
文学技法、ゲーム理論、心理的バイアスといった多様な領域から概念を選択します。
3つの領域それぞれについてデータセットを構築し、生成方法と評価方法を変化させる事で、結果の堅牢性を高めました。
高品質なアノテーションを保証するために、モデル回答の評価には、複数の領域の専門家と論文著者が協力しています。
7モデル:Llama-3.3 (70B)、GPT-4o、Gemini-2.0 (Flash)、Claude-3.5 (Sonnet)、DeepSeek-V3、DeepSeek-R1、Qwen2-VL (72B)
分類タスク モデルは提示された例が与えられた概念の有効な例であるかどうかを判断しなければなりません。モデルは例を与えられ、「次の例は概念の真の例ですか?」と尋ねられます。
制約付き生成 特定の制約に従った例を生成する事をモデルに要求する事で、概念を活用する能力を評価します。
編集 このタスクでは、インスタンスを特定の概念の真例または偽例に変換する可能性のある変更を識別する事をモデルに要求する事で、概念を使用するモデル能力を評価します。
.................
モデルは概念を94.2%の確率で正しく定義しているが、正しい定義を前提とすると、それらの概念を使用するタスクではパフォーマンスが急激に低下します。
モデルやタスクによって若干異なりますが、分析した全てのモデル、概念、ドメインにおいてポチョムキンが普遍的に見られる事がわかりました。
実際にはキーストーンセットには概念の定義だけでなく複数の設問が含まれる可能性があるという懸念です。
例えば、二次方程式の定義式を生徒が実際に数回適用してみるまで、その公式を本当に理解しているかどうか確信が持てないかもしれません。
これに対処するため、キーストーンに追加の質問が含まれている場合のパフォーマンスをシミュレートする補足分析を実施します。
.................
キーストーンセットを拡張しても、パフォーマンスの向上はわずかでした。
4.1 Warmup: Incoherence
2つの可能性が考えられます。
1つは、LLMの概念理解が若干ずれているものの、内部的には一貫しているという事です。
もう1つは、概念理解が一貫性を欠いており、同じ概念に対して矛盾した概念が存在しているという事です。
まず、モデルに特定の概念のインスタンスまたは非インスタンスを生成するよう指示します。
次に、モデルが生成した出力を(別のクエリで)モデルに提示し、その出力が実際にその概念のインスタンスであるかどうかを尋ねます。
4.2 A lower bound on potemkin rates.
LLMが概念を理解している場合、その概念に関する新たな質問に対する回答は、同じLLMによって正しいと判断されるはずです。LLMの判断が元の回答にどれほど頻繁に同意しないかが、ポチョムキンの蔓延状況を明らかにします。
具体的には、LLMにベンチマークからの質問を提示し、正解かどうかを自動的に採点します。正解した場合、LLMは同じ概念に基づく他の質問を生成するように指示します。そして、各質問についてLLMに正解を指示し、同じLLMに再度採点を指示します。
.................
.................
6 Conclusion
従来のベンチマーク基準では非常に有能に見えるモデルでさえ、高いポチョムキン率を示す事が明らかになりました。
矛盾の検証により、モデルには同一の概念について矛盾する表現が含まれている事が明らかになりました。
本研究のアプローチには限界があり、さらなる探究の余地が示唆されています。
開発したベンチマークデータセットは広範ではあるものの、網羅的ではありません。
より幅広い概念とキーストーン質問の種類を網羅するデータセットを追加することで、より包括的なポチョムキンの特定が可能になる可能性があります。

0
- カテゴリ

研究開発
学問・科学カテゴリ
<a href="http://www.soken.ac.jp/">総合研究大学院大学</a> 複合科学研究科 情報学専攻 卒 <a href="http://www.nii.ac.jp/">博士(情報学)</a> <br>
自然言語処理や機械学習、データ分析に関する研究内容とwebシステムの開発と運用について書いています。
<br>
<br>
<font size=1>シリコンバレーベンチャーみたいに深い技術の事業化をしたいと思っています。
<a href="mailto:updatenews @ hr.sub.jp"><u>ご興味ある方はご連絡ください。</u></a></font>
<table><tr><td>
<!--
<a href="http://blog.livedoor.jp/tak_tak0/index.rdf"><img src="http://livedoor.blogimg.jp/tak_tak0/imgs/b/f/bffdfd20.png"
alt="RSS" width=50% height=50%/></a>
-->
</td><td>
</td><td>
<script type="text/javascript">
var gaJsHost = (("https:" == document.location.protocol) ? "https://ssl." : "http://www.");
document.write(unescape("%3Cscript src='" + gaJsHost + "google-analytics.com/ga.js' type='text/javascript'%3E%3C/script%3E"));
</script>
<script type="text/javascript">
try {
var pageTracker = _gat._getTracker("UA-7999782-2");
pageTracker._trackPageview();
} catch(err) {}</script>
</td><td>
<!-- Twitter universal website tag code -->
<script>
!function(e,t,n,s,u,a){e.twq||(s=e.twq=function(){s.exe?s.exe.apply(s,arguments):s.queue.push(arguments);
},s.version='1.1',s.queue=[],u=t.createElement(n),u.async=!0,u.src='//static.ads-twitter.com/uwt.js',
a=t.getElementsByTagName(n)[0],a.parentNode.insertBefore(u,a))}(window,document,'script');
// Insert Twitter Pixel ID and Standard Event data below
twq('init','nxjex');
twq('track','PageView');
</script>
<!-- End Twitter universal website tag code -->
<!-- Twitter AMP-compatible universal website tag code -->
<amp-img height="1" width="1" style="display:none;" alt="" src="https://analytics.twitter.com/i/adsct?p_id=Twitter&p_user_id=0&txn_id=nxjex&events=%5B%5B%22pageview%22%2Cnull%5D%5D&tw_sale_amount=0&tw_order_quantity=0"></amp-img>
<amp-img height="1" width="1" style="display:none;" alt="" src="//t.co/i/adsct?p_id=Twitter&p_user_id=0&txn_id=nxjex&events=%5B%5B%22pageview%22%2Cnull%5D%5D&tw_sale_amount=0&tw_order_quantity=0"></amp-img>
<!-- End Twitter AMP-compatible universal website tag code -->
</td><td>
<!--
<a href="http://blog.livedoor.jp/tak_tak0/archives/51245507.html"><b><font color=yellow size=+1><u>splog対策に関するGoogleの回答</u></font></b></a>
-->
</td></tr></table>
フォローするとアプリで新着記事や
過去記事の閲覧ができます
過去記事の閲覧ができます
 ライブドアアプリでフォローする
ライブドアアプリでフォローする
コメントを書く