
論文は5ページしか無くて、内容も単純明解に見えますが、この結果が与える知見は割と大きいのでは...?
LLMs Do Not Think Step-by-step In Implicit Reasoning
Yijiong Yu Tsinghua University
arXiv preprint arXiv:2411.15862 (2024).
1 Introduction大規模言語モデル(LLM)の進歩により、複雑な推論タスクを処理する能力が明らかになりました。
Chain-of-Thought (CoT)プロンプティングは特に、中間推論ステップを明示的にマッピングする事で、LLM の推論能力が大幅に向上する事を実証しました。
しかし、CoT アプローチは、その有効性にもかかわらず、推論速度が遅くなり、計算コストが高くなるという欠点があります。これらの欠点により、中間トークンの明示的な生成を回避し、内部処理層を通じてモデル固有の「垂直」推論機能を活用する代替推論方法論の研究が促進されました。
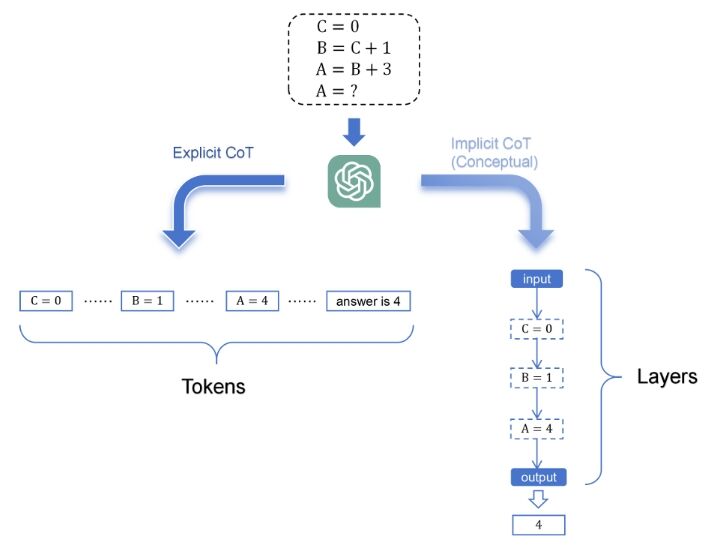
先行研究によって、CoT 推論の中間状態をエミュレートするエミュレーターを学習し、これらの暗黙の状態から回答を生成するようにモデルを学習します。
この形式の推論では、中間結果をトークンとして出力する必要がなく、暗黙の推論または垂直推論と呼ばれ、「水平」推論、つまり一般的な CoT とは対照的です。
「暗黙の CoT (推論)」の概念が直接言及される事はほとんどありませんが、低レイテンシが求められる多くのシナリオでは、ユーザーは通常、LLM に最終回答を直接出力するように要求するため、実際には LLM は暗黙の推論方法を採用せざるを得ません。
「LLM は暗黙的および明示的 CoT のプロセスで同じ事を行っているのか?」や
「隠された内部のレイヤーごとの処理は、本当に明示的 CoT 推論と同等の役割を果たす事が出来るのか?」等
暗黙的推論の性質に関する基本的な疑問が生じています。
これらの疑問に答えるために、本研究では、大規模言語モデル内の暗黙的推論プロセスを明らかにする事を目的とした実験を設計し、具体的には、明示的な中間ステップの出力に頼る事なく、複数ステップの算術問題を処理するプロセスを対象としています。
.................
.................
2 Approach推論手順を明確に示すために、加算と減算のみの単純な多段階算術問題を採用します。通常、このような問題が与えられた場合、現代の LLM は自動的に CoT 方式を使用して対処します。
2.1 Expriment Design
5 ステップの問題であるプロンプトの例は次のとおりです。
E = 8;
D = E - 5;
C = D + 2;
B = C + 5;
A = B - 1;
Question: What is the value of A? You must answer directly with A=xxx.
Answer: A=
問題の値をランダムに変更して2000個の異なるサンプルを生成し、それぞれの中間結果を記録します。
モデルはプロンプトの後に回答を直接出力します。
そのため、プロンプトの最後のトークンを主な調査対象として、各層の隠れ状態を記録します。
次に、1 層 MLP を使用する一般的な線形プローブ法を採用して、隠れ状態から各中間結果を予測します。
プローブが 21 クラス分類器 (各値が 1 つのクラスに対応) になるように、すべての中間値を -10 から 10 の範囲に制御します。
1600サンプルを使用して分類器を10エポック学習し、400サンプルを使用して精度をテストします。そして、20グループの各隠れ状態を入力特徴として使用して、個々の分類器を学習します。
したがって、最終的に 20*ステップ の分類器が得られます。k 番目の隠し状態の分類器が n 番目のステップで高い精度を示した場合、モデルが k 番目の隠し状態で n 番目のステップの結果を計算した事を示します。
暗黙的推論を実行するために、大規模なモデルである Qwen2.5-72B-Instructを選択しました。
小規模な 7B レベルのモデルでは CoT なしでは複数ステップの問題を正しく実行する事がほとんど出来ないのに対し、70B レベルのモデルでは 50% を超える精度を達成出来る事が分かったためです。
72B モデルには 80 層があるため、計算コストを削減するために、連続する 4 つの層ごとに非表示状態を平均化します。そのため、モデルがプロンプトを処理すると、サンプルごとに 20 グループの非表示状態とその回答が得られます。
2.2 Results of Probing Intermediate Steps図は、問題が 3 ステップまたは 5 ステップの場合の各ステップの中間結果のプローブの精度を示しています。
どちらの状況でも、最初のステップと最後のステップの結果は常にバックレイヤーで正常にプローブ出来る事は明らかであり、モデルが入力値 (最初のステップの結果) を記憶し、最終的な答え (最後のステップの結果) を考えている事は明らかです。
また、2 番目のステップの結果もある程度検出出来るため、LLM は暗黙的推論で 2 ホップ推論 (3 ステップの問題では、最初のステップの結果がすでに与えられているため、実際には 2 ホップしか必要ありません) を実行出来る可能性があります。この現象は、以前の研究と一致しています。
しかし、対照的に、5 ステップの問題では、他のステップ (3 番目、 4 番目) の結果はほとんど検出されません。最後のステップの曲線は、3 番目または 4 番目のステップの処理を待たなくても、最後のレイヤーで急上昇するように見えます。したがって、モデルは 3 番目と 4 番目のステップの結果をまったく計算しない可能性があります。
これは、問題が2ホップを超える場合には、モデルが正しい答えを出す事が出来るにも関わらず、モデルが中間ステップの結果を計算する状態は実際には存在しない事を示しています。
中間ステップをスキップして最終結果を直接導き出します。
おそらく大規模言語モデルの抽象化と記憶能力により、学習段階で数学の問題に対する多数の答えを学習したと考えられます。
直感と経験を通じて、複数のステップを含む問題をほぼ直接答えにマッピング出来るため、「暗黙の推論」効果を生み出すものの、実際には、その内部メカニズムは明示的なCoTプロセスとは全く同等ではありません。
2.3 Result of Modifying the Problem Presentation問題を 2 つの方法で少し変更します。
方程式の順序を逆にする。
すべての値を 10 で割る。
こうして、3 種類の問題表現が得られます。
A = B - 1;
B = C + 5;
C = D + 2;
D = E - 5;
E = 8;
E = 0.8;
D = E - 0.5;
C = D + 0.2;
B = C + 0.5;
A = B - 0.1;
推論手順は全く変更ないため、これによって問題の難易度が上がる事はほとんどありません。
ただし、直感と経験のみに依存するモデルの場合、与えられた問題の形式と経験の形式の間に大きな違いが生じます。
元の問題と比較すると、修正された問題では暗黙的推論を使用するとパフォーマンスが大幅に低下する事がはっきりと分かります。
明示的推論のパフォーマンスは常に100%なので、暗黙的推論では、実際にはモデルは経験と直感によって直接答えており、段階的な推論によって答えているわけではないという本研究の仮説を裏付けます。
これにより、暗黙的推論の方法は堅牢性が低く、信頼性が低くなります。
3 Conclusion
この結果は、無料で得られるものはない事、現在の技術状況では、複雑な問題を解く精度を保ちながら LLM が非常に少ないトークンを出力するような完璧なソリューションは存在しないかもしれない事示唆します。
LLM に直接答えを求める場合、実際には推論が行われていない事を知っておく必要があります。
明示的な CoT を使用してテスト時間をスケーリングする事は、現時点では LLM の機能を推進するための最も実現可能な方法である可能性があります。

0
- カテゴリ

研究開発
学問・科学カテゴリ
<a href="http://www.soken.ac.jp/">総合研究大学院大学</a> 複合科学研究科 情報学専攻 卒 <a href="http://www.nii.ac.jp/">博士(情報学)</a> <br>
自然言語処理や機械学習、データ分析に関する研究内容とwebシステムの開発と運用について書いています。
<br>
<br>
<font size=1>シリコンバレーベンチャーみたいに深い技術の事業化をしたいと思っています。
<a href="mailto:updatenews @ hr.sub.jp"><u>ご興味ある方はご連絡ください。</u></a></font>
<table><tr><td>
<!--
<a href="http://blog.livedoor.jp/tak_tak0/index.rdf"><img src="http://livedoor.blogimg.jp/tak_tak0/imgs/b/f/bffdfd20.png"
alt="RSS" width=50% height=50%/></a>
-->
</td><td>
</td><td>
<script type="text/javascript">
var gaJsHost = (("https:" == document.location.protocol) ? "https://ssl." : "http://www.");
document.write(unescape("%3Cscript src='" + gaJsHost + "google-analytics.com/ga.js' type='text/javascript'%3E%3C/script%3E"));
</script>
<script type="text/javascript">
try {
var pageTracker = _gat._getTracker("UA-7999782-2");
pageTracker._trackPageview();
} catch(err) {}</script>
</td><td>
<!-- Twitter universal website tag code -->
<script>
!function(e,t,n,s,u,a){e.twq||(s=e.twq=function(){s.exe?s.exe.apply(s,arguments):s.queue.push(arguments);
},s.version='1.1',s.queue=[],u=t.createElement(n),u.async=!0,u.src='//static.ads-twitter.com/uwt.js',
a=t.getElementsByTagName(n)[0],a.parentNode.insertBefore(u,a))}(window,document,'script');
// Insert Twitter Pixel ID and Standard Event data below
twq('init','nxjex');
twq('track','PageView');
</script>
<!-- End Twitter universal website tag code -->
<!-- Twitter AMP-compatible universal website tag code -->
<amp-img height="1" width="1" style="display:none;" alt="" src="https://analytics.twitter.com/i/adsct?p_id=Twitter&p_user_id=0&txn_id=nxjex&events=%5B%5B%22pageview%22%2Cnull%5D%5D&tw_sale_amount=0&tw_order_quantity=0"></amp-img>
<amp-img height="1" width="1" style="display:none;" alt="" src="//t.co/i/adsct?p_id=Twitter&p_user_id=0&txn_id=nxjex&events=%5B%5B%22pageview%22%2Cnull%5D%5D&tw_sale_amount=0&tw_order_quantity=0"></amp-img>
<!-- End Twitter AMP-compatible universal website tag code -->
</td><td>
<!--
<a href="http://blog.livedoor.jp/tak_tak0/archives/51245507.html"><b><font color=yellow size=+1><u>splog対策に関するGoogleの回答</u></font></b></a>
-->
</td></tr></table>
フォローするとアプリで新着記事や
過去記事の閲覧ができます
過去記事の閲覧ができます
 ライブドアアプリでフォローする
ライブドアアプリでフォローする
コメントを書く