




著作権フリーな98万冊の書籍からテキストを抽出したデータセット「Institutional Books」をハーバード大学が公開、Googleブックスの書籍インデックス化プロジェクトのデータを活用

ハーバード大学ロースクール図書館が98万3000冊の書籍からテキストデータを抽出したデータセット「Institutional Books」を公開しました。データセットの作成にはGoogleブックスの成果が活用されています。
Institutional Books | Institutional Data Initiative
https://www.institutionaldatainitiative.org/institutional-books
Institutional Booksには98万3000冊の書籍のデータが含まれており、総ページ数は3億8600万ページに及びます。また、学習元の書籍に使われていた言語は254種でした。

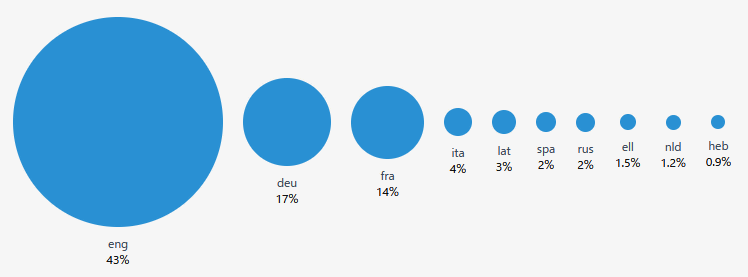
言語の内訳は以下の通り。最も多いのは英語の43%で、その後にドイツ語(17%)、フランス語(14%)、イタリア語(4%)、ラテン語(3%)、スペイン語(2%)、ロシア語(2%)、ギリシャ語(1.5%)、オランダ語(1.2%)、ヘブライ語(0.9%)と続きます。
書式が記された年をまとめたグラフが以下。1800年から1900年頃に記された書籍が多かったようです。

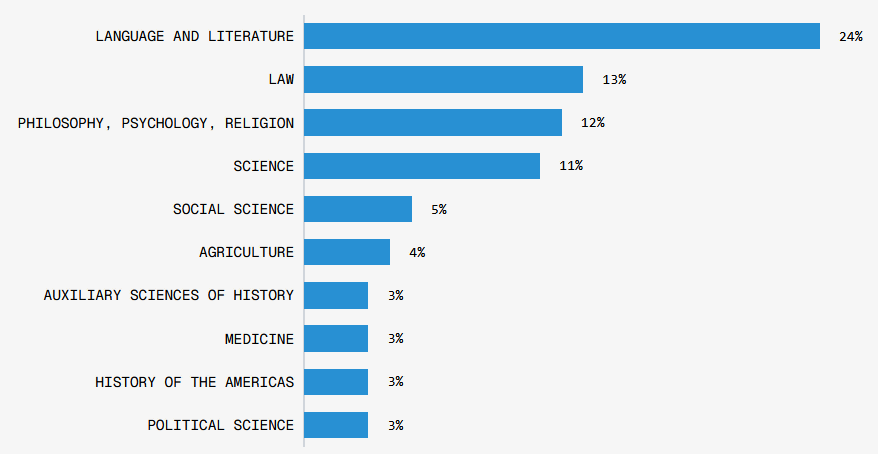
アメリカ議会図書館の分類表に合わせて書籍を分類した結果、最も多い分類は「言語、文学」(24%)でした。他に「法律」(13%)や「哲学、心理学、宗教」(12%)、「科学」(11%)も多く含まれています。
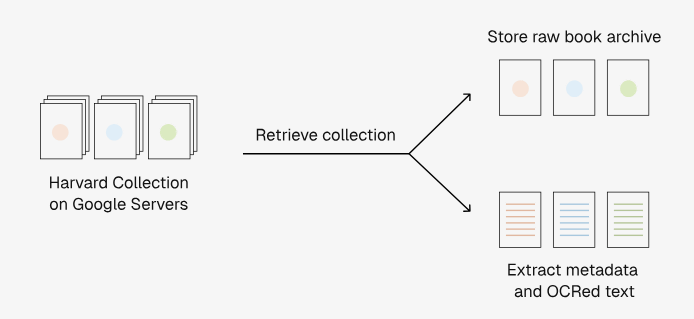
Institutional Booksの構築に際して、Googleのサーバー上にあるハーバード大学の書籍コレクションデータからデータを抽出する専用のパイプラインが開発されました。パイプラインでは、まずGoogleのサーバーから書籍の内容や書籍情報をダウンロードします。
ダウンロードした書籍データをOCR処理して、使用言語やトピックを分類しました。この作業の過程で「ラテン語で記されたと分類されていた書籍がラテン語とフランス語で記されたものであることが判明」といった新発見があったそうです。

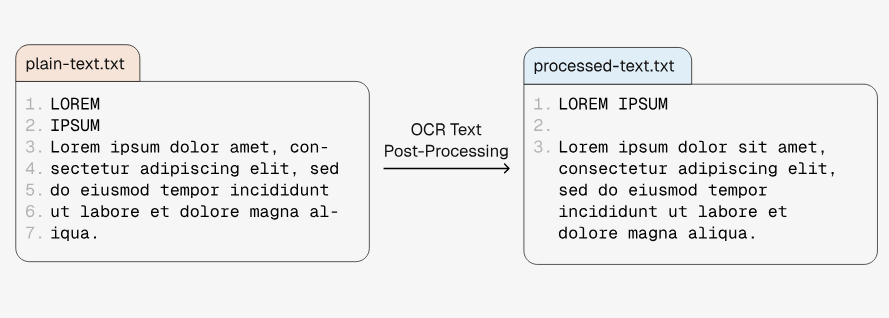
書籍をOCRによってテキストデータ化すると、読みにくい位置に改行が挟まることがあります。新開発のパイプラインには、この改行位置を読みやすいように調整する機能も含まれています。
Institutional Booksのデータは以下のリンク先で公開されており、非営利目的にのみ自由に利用できます。
institutional/institutional-books-1.0 · Datasets at Hugging Face
https://huggingface.co/datasets/institutional/institutional-books-1.0
また、Institutional Booksの構築に使われたパイプラインのソースコードは以下のGitHubリポジトリで公開されています。
GitHub - instdin/institutional-books-1-pipeline: The Institutional Data Initiative's pipeline for analyzing, refining, and publishing the Institutional Books 1.0 collection.
https://github.com/instdin/institutional-books-1-pipeline
さらに、Institutional Booksの構築に関する論文が以下のリンク先で公開されています。
Institutional Books 1.0: A 242B token dataset from Harvard Library's collections, refined for accuracy and usability
https://arxiv.org/abs/2506.08300

・関連記事
パブリックドメインおよびオープンライセンスのコンテンツのみで構成された約8TBの巨大データセット「Common Pile v0.1」をAI研究機関・EleutherAIがリリース - GIGAZINE
Metaが1億件以上の分子構造データを含む大規模量子化学データセット「OMol25」とAIモデル「Universal Model for Atoms(UMA)」をリリース - GIGAZINE
テキストから物理的に安定したレゴブロックの構造物を生成するモデル「LegoGPT」とデータセット「StableText2Lego」が公開中 - GIGAZINE
1兆のテキストトークン・34億個の画像・PDF・ArXivの論文などを含むオープンソースのデータセット「MINT-1T」をSalesforceが公開 - GIGAZINE
AIモデルのトレーニングで使えるアニメーション特化のデータセット「Sakuga-42M」が登場 - GIGAZINE
MetaのAIのトレーニングに使われた書籍データセット「Books3」には村上春樹やスティーブン・キングの著作も含まれている - GIGAZINE
・関連コンテンツ




in ソフトウェア, Posted by log1o_hf
You can read the machine translated English article Harvard University releases 'Institution….