
Introduction
I have been writing posts critical of mainstream EA narratives about AI capabilities and timelines for many years now. Compared to the situation when I wrote my posts in 2018 or 2020, LLMs now dominate the discussion, and timelines have also shrunk enormously. The ‘mainstream view’ within EA now appears to be that human-level AI will be arriving by 2030, even as early as 2027. This view has been articulated by 80,000 Hours, on the forum (though see this excellent piece excellent piece arguing against short timelines), and in the highly engaging science fiction scenario of AI 2027. While my article piece is directed generally against all such short-horizon views, I will focus on responding to relevant portions of the article ‘Preparing for the Intelligence Explosion’ by Will MacAskill and Fin Moorhouse.
Rates of Growth
The authors summarise their argument as follows:
Currently, total global research effort grows slowly, increasing at less than 5% per year. But total AI cognitive labour is growing more than 500x faster than total human cognitive labour, and this seems likely to remain true up to and beyond the point where the cognitive capabilities of AI surpasses all humans. So, once total AI cognitive labour starts to rival total human cognitive labour, the growth rate of overall cognitive labour will increase massively. That will drive faster technological progress.
MacAskill and Moorhouse argue that increases in training compute, inference compute and algorithmic efficiency have been increasing at a rate of 25 times per year, compared to the number of human researchers which increases 0.04 times per year, hence the 500x faster rate of growth. This is an inapt comparison, because in the calculation the capabilities of ‘AI researchers’ are based on their access to compute and other performance improvements, while no such adjustment is made for human researchers, who also have access to more compute and other productivity enhancements each year.
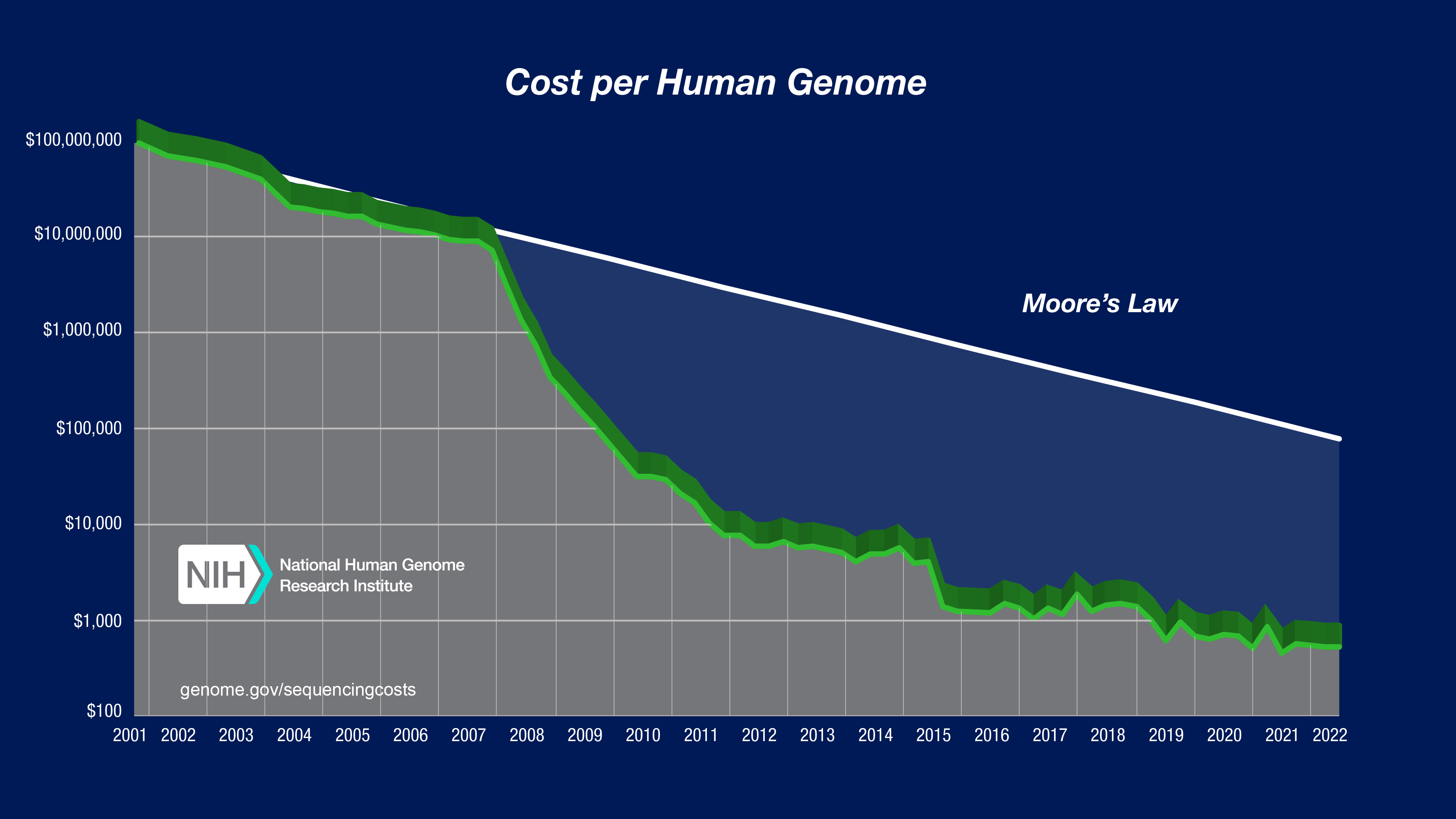
It is also highly unclear if current rates of increase can reasonably be extrapolated. In particular, the components of the rate of increase of ‘AI researchers’ are not independent, since if the rate of algorithmic improvement slows, then it is highly likely investments in training and inference compute will also slow down. Furthermore, most new technologies improve very rapidly at first and then performance significantly slows; the cost for genome sequencing is a good recent example. Such a slowdown may already be beginning. For example, after months of anticipation prior to its release in February, OpenAI recently announced they will remove their new GPT4.5 model from API access in July. This apparently is due to the high cost of such a large model with only modest improvement in performance. The recent release of Llama 4 was also met with mixed reception owing to disappointing performance and controversies about its development. For all these reasons, I do not believe the 500-fold greater rate of increase in ‘AI researchers’ compared to human researchers is particularly accurate nor can it be confidently extrapolated to continue over the coming decade.
The authors then argue that even in the absence of continued increases in compute, deployment of AI to improve AI research could lead to a ‘software feedback loop’, where AI capabilities continue to improve due to improvements in AI capabilities elicited by AI researchers. MacAskill and Moorhouse defend this claim by quoting evidence that “empirical estimates of efficiency gains in various software domains suggest that doubling cognitive inputs (research effort) generally yields more than a doubling in software performance or efficiency.” Here they cite a paper which presents estimates for returns on research efforts for four software domains: computer vision, sampling efficiency in reinforcement learning, SAT solvers, and linear programming. These are all substantially more narrowly-defined than the very general capabilities required for improving AI researcher capability. Furthermore, the two machine learning related tasks (computer vision and sampling efficiency in RL) covered timespans of only ten and four years respectively. Furthermore, the paper in question is a methodological survey, and highlights that all presented estimates suffer from significant methodological shortcomings that are very difficult to overcome empirically. As such, this evidence is not a very convincing reason to think that doubling the number of ‘AI researchers’ working on improving AI will result in a self-sustaining software feedback loop for any significant period of time.
The Limitations of Benchmarks
MacAskill and Moorhouse also argue that individual AI systems are becoming rapidly more capable at performing research-related tasks, and will soon reach parity with human researchers. Specifically, they claim that within the next five years there will be ‘models which surpass the research ability of even the smartest human researchers, in basically every important cognitive domain’. Given the centrality of this claim to their overall case, they devote surprisingly little space to substantiating it. Indeed, their justification consists entirely of appeals to rapid increases in the performance of LLMs on various benchmark tasks. They cite GPQA (multiple choice questions covering PhD-level science topics), RE-Bench (machine learning optimisation coding tasks), and SWE-Bench (real-world software tasks). They also mention that LLMs can now ‘answer questions fluently and with more general knowledge than any living person.’
Exactly why improved performance on these tasks should warrant the conclusion that models will soon surpass research ability on ‘basically every important cognitive domain’ is not explained. As a cognitive science researcher, I find this level of analysis incredibly simplistic. The authors don’t explain what they mean by ‘cognitive domain’ or how they arrive at their conclusions about the capabilities of current LLMs compared to humans. Wikipedia has a nice list of cognitive capabilities, types of thinking, and domains of thought, and it seems to me that current LLMs have minimal ability to perform most of these reliably. Of course, my subjective look at such a list isn’t very convincing evidence of anything. But neither is the unexamined and often unarticulated claim that performance on coding problems, math tasks, and science multiple choice questions is somehow predictive of performance across the entire scope of human cognition. I am continually surprised at the willingness of EAs to make sweeping claims about the cognitive capabilities of LLMs with little to no theoretical or empirical analysis of human cognition or LLMs, other than a selection of machine learning benchmarks.
Beyond these general concerns, I documented in my earlier paper several major limitations with the use of benchmarks for assessing the performance of LLMs. Here I summarise the major issues:
- Tests should only be used to evaluate the capabilities of a person or model if they have been validated as successfully generalising to tasks beyond the test itself. Extensive research is conducted within cognitive psychology for human intelligence and other psychometric tests, but much less work has been done for LLM benchmarks. The research that has been conducted often shows limited generalisation and significant overfitting of models to benchmarks.
- Use of adversarial and interpretation techniques has repeatedly found that LLMs perform poorly on many tasks when more difficult examples are used. Further, models often do not use appropriate reasoning steps, instead confabulating explanations that seem plausible but do not actually account for the provided solution.
- LLMs often do not successfully generalise to versions of the task beyond those they were trained on. The models often use superficial heuristics and pattern-matching rather than genuine understanding or reasoning steps.
- The training data for many LLMs is contaminated with questions and solutions from known benchmarks, as well as synthetic data generated from such benchmarks. This is worsened by strong incentives of developers to fudge the training or evaluation process to achieve better benchmark results. Most recently, OpenAI has attracted criticism for their reporting of results on both the ARC-AI and the Frontier Math benchmarks.
Even more recent results corroborate these points. One recent analysis of the performance of LLMs on a new, and hence previously unseen, mathematics task found that “all tested models struggled significantly: only GEMINI-2.5-PRO achieves a non-trivial score of 25%, while all other models achieve less than 5%. Through detailed analysis of reasoning traces, we identify the most common failure modes and find several unwanted artifacts arising from the optimization strategies employed during model training.” A separate analysis of similar data found that models regularly rely on pattern recognition and heuristic shortcuts rather than engaging in genuine mathematical reasoning.
Real-World Adoption
One final issue pertains to the speed with which LLMs can be adapted to perform real-world tasks. MacAskill and Moorhouse discuss at length the possibility for ‘AI researchers’ to dramatically speed up the process of scientific research. However so far, the only example of a machine learning system performing a significant scientific research task is AlphaFold, a system designed to predict the structure of protein molecules given their amino acid sequence. In addition to being eight years old, AlphaFold does not solve the problem of protein folding. It is simply a tool for predicting protein structure, and even in that narrow task is has many limitations. LLMs are increasingly utilised in cognitive science research as an object of study in their own right, as well as providing a useful tool for text processing or data validation. However I am not aware of any examples of LLMs being applied to significantly accelerate any aspect of scientific research. Perhaps this will change rapidly within the next few years, but MacAskill and Moorhouse do not give any reasons for thinking so beyond generic appeals to increased performance on coding and multiple-choice benchmarks.
Other lines of evidence also indicate that the real-world impact of LLMs is modest. For instance, a large survey of workers in 11 exposed occupations in Denmark found effects of LLM adoption on earnings and hours worked of less than 1%. Similarly, a series of interviews of 19 policy analysts, academic researchers, and industry professionals who have used benchmarks to inform decisions regarding adoption or development of LLMs found that most respondents were skeptical of the relevance of benchmark performance for real-world tasks. As with past technologies, many factors including reliability problems, supply chain bottlenecks, organisational inertia, user training, and difficulty in adapting to specific use cases will mean that the real-world impacts of LLMs are likely to develop over the timespan of decades rather than a few years.
Conclusion
The coming few years will undoubtedly see continued progress and ongoing adoption of LLMs in various economic sectors. However, I find the case for 3-5 timelines for the development of AGI to be unconvincing. These arguments are overly dependent on simple explanations of existing trends while paying insufficient attention to the known limitations of such benchmarks. Similarly, I find that such arguments often rely on extensive speculation based primarily on science fiction scenarios and thought experiments, rather than careful modelling, historical parallels, or detailed consideration of the similarities and differences between LLMs and human cognition.




{kind=link}
Executive summary: In this critical and cautious analysis, the author argues that predictions of AGI emerging by 2030—especially claims centered on AI self-improvement and benchmark performance—are based on overstated analogies, flawed extrapolations, and speculative reasoning, and should not be treated as robust forecasts.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.