はじめに
アドベントカレンダーの2023記事です。
家の設備のトラブルで、アドベントカレンダーどころではなくなってしまい、連載がストップしてしましたが記事を埋めていこうと思います。
Crystalの実行速度には目を見張るものがあります。
Crystalの高速さをさらに活用するために、Crystalの並列実行について調べ直しました。以前にも同じような内容の記事というよりメモを書いていますが、内容を強化しています。
忙しい人のための要点
コンパイル
フラグ preview_mt を指定してコンパイルする。(preview multi thread?)
crystal build -D preview_mt hoge.cr
環境変数
環境変数 CRYSTAL_WORKERS でワーカーの数を指定できる。(異なるアプリケーションには異なるワーカーの数を指定できる)
CRYSTAL_WORKERS=4 first_app
CRYSTAL_WORKERS=12 second_app
並列実行したい処理は Fiber で記述する。Fiber は spawn で作成する。Fiber 同士のデータのやり取りは Channel を用いる。
簡単な Producer-Consumer パターン
array = [ #...
# チャンネルを作成
channel = Channel(MyClass).new(array.size)
array.each do |value|
# Fiber を作成
spawn do
result = process(value)# 処理
channel.send(result)
end
end
results = Array.new(array.size) { channel.receive }
Cの関数を呼び出している場合のために、spawn には same_thread 引数が指定できる。
def spawn(*, name : String | Nil = nil, same_thread = false, &block)
資料
「平行性」に関しては公式のドキュメントがあります。
「並列性」に関してはプレビュー機能なので、公式ドキュメントはありません。ブログの記事ぐらいです。
英語ですが、次の dev.to の資料が大変わかりやすいです。
平行性と並列性の違いについてですが、Rubyでいうと、Threadが平行性、Ractorが並列性ということになると思います。
| コンセプト | 説明 |
|---|---|
| 並行性 (Concurrency) | 複数のタスクを管理できるが、必ずしも同時に実行するわけではない。 |
| 並列性 (Parallelism) | 複数のタスクを同時に実行すること。 |
もう少し詳しい説明
まずはFiberありき
Crystalで、並行実行、並列実行を行うときは Fiber を使います。Fiberを書いた処理は、-D preview_mt をつけることで並列でも実行できるようにしたい(既存のWebアプリの高速化)というのが、Crystalのチームの考え方のようです。
| 特徴 | 説明 |
|---|---|
| 軽量性 | OSスレッドよりも軽量で、8MBのスタックを持つ。 |
| 協調性 | ファイバーは自発的にランタイム・スケジューラに制御を譲る必要がある。 |
| 数量 | 64ビットマシンでは数百万のファイバーを生成可能。 |
Rubyには、Thread、Fiber、Ractor、などいろいろありますが、CrystalではFiberだけです。fork メソッドも以前はあったようですが、現在は廃止されているようです。
クリスタルにおけるプログラム実行の要素
| コンポーネント | 説明 |
|---|---|
| ランタイム・スケジューラ | 適切なタイミングで全てのファイバーを実行する。 |
| イベントループ | 非同期タスクを管理するファイバー。 |
| チャネル | ファイバー間でデータを伝達する手段。 |
| ガベージコレクター | 使用されなくなったメモリをクリーンアップする。 |
libevent を用いて実装されているそうです。ランタイムスケジュラーは1つでFiberが切り替わる、というのが平行性の仕組みでるようです、
Crystalの並列性における静的スレッドプール
下記サイトの内容を箇条書きで要約します。
- 並列処理は、アプリが起動する時に設定される
- アプリケーションコードの実行を開始する前に必要なすべてが接続される。
- 並列処理は静的なスレッドプールにより達成される。
- アプリのコードの最初の行が実行されるまでに全スレッドが作成される。
- 実行中にスレッドが新規作成されたり削除されたりすることはない。
↑このような特性から、環境変数 CRYSTAL_WORKERS で利用するCPUのコア数を指定するような使い方になってるようです。
- プール内の各スレッドに、Fiberスケジューラが付属している。
- シングルスレッドモードで行えることを、複数のスレッドで行う。
- Fiberは最初に割り当てられたスレッド内でのみ実行される。
- ただし、これはファイバーを作成したスレッドと同じとは限らない。
- 例えば、「スレッド1」でspawnを呼び出すと、新しいFiberは「スレッド4」に割り当てられ、その後最後までまで「スレッド4」で実行される。
チャネルによる通信
| チャネルの種類 | 説明 |
|---|---|
| バッファーなしチャネル | バッファがなく、送信時に受信待ちのファイバーに直ちに切り替える。 |
| バッファーありチャネル | バッファサイズが設定され、バッファがいっぱいになるまで送信がブロックされない。 |
バッファーなしチャンネル
channel = Channel(T).new
channel = Channel(Int32).new
バッファーありチャンネル
channel = Channel(T).new(buffer_size)
channel = Channel(Int32).new(5)
並行性のサンプルコード
僕はWebアプリを作らないしIOを気にしているわけでもないので、あまり平行性のメリットを享受することはないと思いますが、ChatGPTに頼んで平行性のサンプルコードを書いてもらいました。(下の▶マークをクリックすると開きます)
Crystalの平行性のサンプルコード
require "socket"
# メインファイバーが起動
spawn do
# サーバーを作成して接続を待つファイバー
server = TCPServer.new("0.0.0.0", 8080)
socket = server.accept
# ソケットからデータを受信し、処理する
while line = socket.gets
puts "Received from socket: #{line}"
end
end
# チャネルの作成(Int32型のデータを伝達するためのチャネル)
channel = Channel(Int32).new
# 10個のファイバーを生成し、それぞれに値をチャネルに送信させる
10.times do |i|
spawn do
channel.send(i * 2)
end
end
# メインファイバーでチャネルから値を受信し、合計を計算
sum = 0
10.times do
sum += channel.receive
end
puts "Sum of received values: #{sum}"
# ファイバーの切り替えを可能にするための待機
Fiber.yield
# 無限ループのファイバーを生成し、定期的にメッセージを出力
spawn do
loop do
puts "Hello from the loop!"
sleep 1.second
end
end
# 無限ループのファイバーが動作し続けるようにメインファイバーを待機状態にする
sleep
並列性のサンプルコード
あまりいい例とは言えませんが、モンテカルロ法を用いて、円周率を計算してみました。
N = ARGV[0].to_i
M = 32
channel = Channel(Float64).new(N)
M.times do |value|
# Fiber を作成
spawn do
c = 0
N.times do
x = Random.rand
y = Random.rand
r = x ** 2 + y ** 2
c += 1 if r < 1
end
channel.send(c / N.to_f)
end
end
r = Array.new(M){ channel.receive }.sum / M
puts r * 4
次のようにビルドします。
crystal build --release -D preview_mt pi_mt.cr
hyperfineでベンチマークを取ってみました。確かに速くなっているようです。
| Command | Mean [s] | Min [s] | Max [s] | Relative |
|---|---|---|---|---|
CRYSTAL_WORKERS=1 ./pi_mt 5000000 |
1.200 ± 0.008 | 1.185 | 1.213 | 5.68 ± 0.12 |
CRYSTAL_WORKERS=2 ./pi_mt 5000000 |
0.620 ± 0.004 | 0.612 | 0.624 | 2.93 ± 0.06 |
CRYSTAL_WORKERS=4 ./pi_mt 5000000 |
0.335 ± 0.007 | 0.328 | 0.355 | 1.59 ± 0.05 |
CRYSTAL_WORKERS=6 ./pi_mt 5000000 |
0.257 ± 0.009 | 0.251 | 0.283 | 1.21 ± 0.05 |
CRYSTAL_WORKERS=8 ./pi_mt 5000000 |
0.211 ± 0.004 | 0.206 | 0.223 | 1.00 |
上記の実行時間の結果を棒グラフにしてみました。
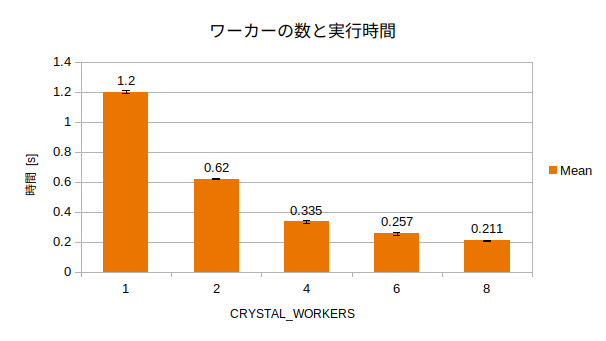
ワーカーの数が増えると実行時間が顕著に減っています。しかし、実はWORKERの数を8以上にしてもこれ以上の実行時間の減少はなく、かえって増えるような傾向すら見られたのでWORKERの数はほどほどにした方がいいかも知れません。
また手軽だからといってFiberを万単位でどんどん量産すると比較的簡単にセグフォするような傾向が見られました。ひょっとすると僕のコードの書き方が悪いだけかもしれませんが、Fiberをたくさん作りすぎるのは要注意かもしれません。
並列で実行できているか確かめるためのテストコード
以下のようなコードが有効です。
16.times { spawn { loop {} } }
sleep # Keep the main thread from exiting
htop などタスクマネージャーの画面でCPUの使用率を確認しましょう。
Windows対応
あまり資料がないのでよくわかりませんが、Windowsでも一応は動くようです。少なくとも私の環境では上記のテストコードが -D preview_mt でビルドでき、リソースモニタで CRYSTAL_WORKERS の数に応じてPCに負荷が増えるのを確認できました。Windowsでも並列で実行できているものと思われます。
この記事は以上です。

コメント
いいね以上の気持ちはコメントで