表題の件、Numeraiトーナメントにおける直交化に関するテクニックを紹介します。
直交化とは
Numeraiでは、しばしば直交化(neutralization、orthogonalization)という所作が用いられます。直交化とは、ある対象の数値ベクトルについて可能な限り元の情報を維持しつつ、別の数値ベクトルによる寄与分を控除する手法です。
もう少し簡単に言うと、直交化前の数値ベクトルをa、直交化に用いる数値ベクトルをb、直交化後のベクトルをa'とすると、
- aとa'の相関は1.0に近い値を保持する(bの選び方によっては低下する場合もある)
- a'とbの相関はほぼ0となる
ここで、Numeraiのフォーラムでは、以下のような直交化するための関数が紹介されています。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def neutralize_series(series, by, proportion=1.0):
scores = series.values.reshape(-1, 1)
exposures = by.values.reshape(-1, 1)
exposures = np.hstack((exposures, np.array([np.mean(series)] * len(exposures)).reshape(-1, 1)))
correction = proportion * (exposures.dot(np.linalg.lstsq(exposures, scores)[0]))
corrected_scores = scores - correction
neutralized = pd.Series(corrected_scores.ravel(), index=series.index)
return neutralized
例えば、Numeraiトーナメントの特徴量dexterity7をtargetに対して直交化してみましょう。
data = pd.read_csv("numerai_training_data.csv").set_index("id")
f1 = data["feature_dexterity7"]
target = data["target"]
f1_nt = neutralize_series(f1, target)
print(np.corrcoef(f1, target)[0, 1]) # dexterity7とtargetの相関
print(np.corrcoef(f1_nt, target)[0, 1]) # 直交化したdexterity7とターゲットの相関
print(np.corrcoef(f1, f1_nt)[0, 1]) # 直交化前後の相関
<実行画面>
-0.012174692404028822
-7.319948614012781e-13
0.9999258856859752
上記の通り、直交化前は-0.0121であった相関係数が、直交化後はほぼ0となり且つ元々のデータとの相関はほぼ1を維持していることが分かります。
線形回帰による直交化
さて、上記の直交化関数は非常に複雑な計算をしているようですが、実のところは線形回帰の残差を取っているだけなのです(proportion=1.0の場合)。以下のようにdexterity7をtargetで回帰して残差を取ると、直交化関数の結果と一致することが分かります。
from sklearn.linear_model import LinearRegression
lm = LinearRegression()
lm.fit(data[["target"]], data["feature_dexterity7"])
f1_nt2 = data["feature_dexterity7"] - lm.predict(data[["target"]])
pd.DataFrame({"NT1":f1_nt, "NT2":f1_nt2})
<実行画面>
NT1 NT2
id
n000315175b67977 0.500019 0.500019
n0014af834a96cdd -0.254801 -0.254801
n001c93979ac41d4 0.495199 0.495199
n0034e4143f22a13 -0.254801 -0.254801
n00679d1a636062f 0.254839 0.254839
... ... ...
nff6a8a8feaeeb52 0.000019 0.000019
nff6af62a0996372 -0.495161 -0.495161
nff9288983b8c040 -0.004801 -0.004801
nffaab4e1cacc4b1 0.500019 0.500019
nffba5460b572cfa 0.250019 0.250019
[501808 rows x 2 columns]
重回帰による直交化
前章で「直交化とは線形回帰の残差である」ということが分かりました。もう少し考えてみると、重回帰を行うことで複数の数値ベクトルに対してまとめて直交化を行うことができることに気付きます。
ここでは例として特徴量同士の直交化を行ってみましょう。
まず、クラスターマップを使って特徴量同士の相関を確認します。
import seaborn as sns
intelligence = [f for f in data.columns if "intelligence" in f]
sns.clustermap(data[intelligence].corr())
<実行画面>
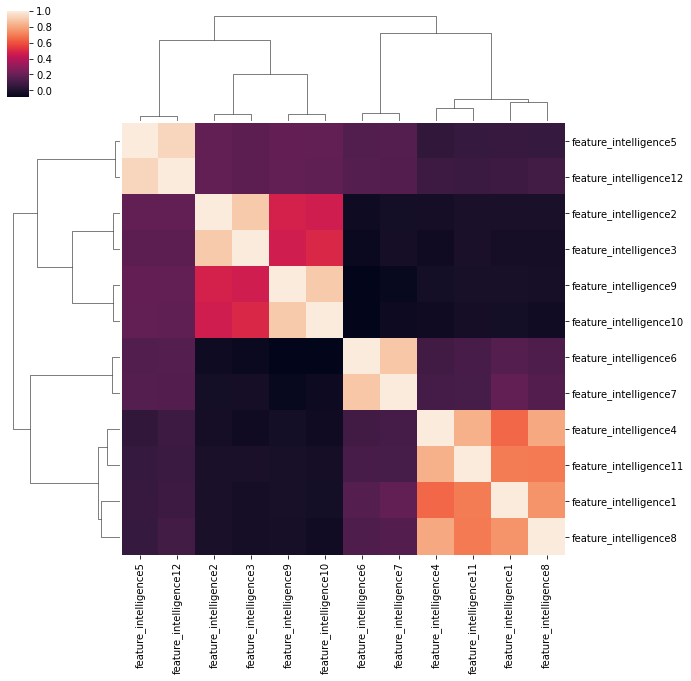
特徴量同士の相関はそれなりに大きくなっています。まず最初にintelligence1をその他の特徴量を用いて直交化してみます。
import copy
data2 = data[intelligence].copy()
f = "feature_intelligence1"
x_feature = copy.deepcopy(intelligence)
x_feature.remove(f)
tmp_model = LinearRegression()
tmp_model.fit(data2[x_feature], data2[f])
data2[f] -= tmp_model.predict(data2[x_feature])
sns.clustermap(data2[intelligence].corr())
<実行画面>
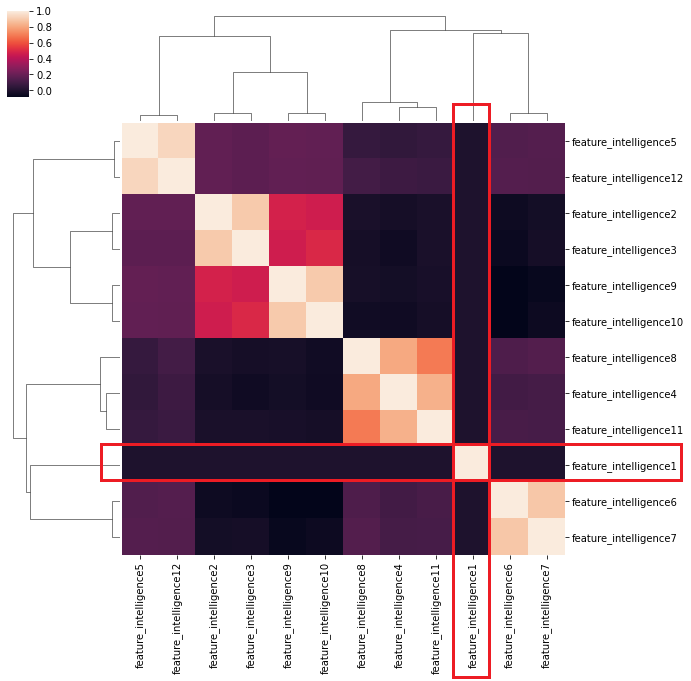
御覧の通り、他の特徴量との相関がほぼ0となりました。このような所作を繰り返すと、全ての特徴量間において相関を0にすることができます。
data2 = data[intelligence].copy()
for f in intelligence:
x_feature = copy.deepcopy(intelligence)
x_feature.remove(f)
tmp_model = LinearRegression()
tmp_model.fit(data2[x_feature], data2[f])
data2[f] -= tmp_model.predict(data2[x_feature])
sns.clustermap(data2[intelligence].corr())
<実行画面>
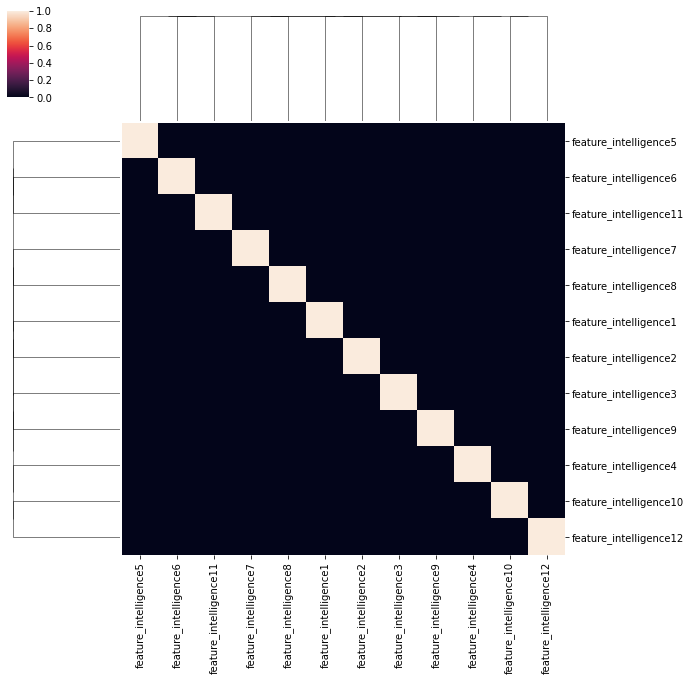
上記の通り、特徴量同士の相関は0となります。このとき、元のデータに対してどれくらい情報を保持しているでしょうか。直交化前後の数値ベクトルの相関を観察してみましょう。
corr = []
name = ["int"+str(i+1) for i in range(12)]
for f in intelligence:
corr.append(np.corrcoef(data[f], data2[f])[0, 1])
plt.bar(name, corr)
<実行画面>
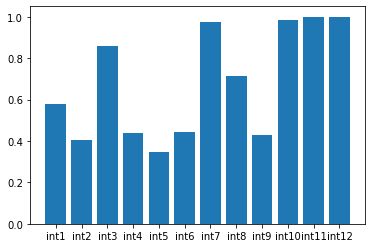
特徴量の中には大きく相関が低下しているものもあります。これは直交化の順序にも依りますが、元の情報から大きく相関が低下する特徴量は、そもそも保有している独自の情報が少ないことを示唆します。
少しだけインテリジェントな直交化
最後に少しだけ工夫した使い方を紹介します。それはLASSOやRIDGEによる直交化です。
以下、事例です。
from sklearn.linear_model import Lasso
feature_names = [f for f in tournament_data.columns if "feature" in f]
lasso = Lasso(alpha=0.0005)
lasso.fit(tournament_data[feature_names], tournament_data["prediction"])
tournament_data["prediction"] -= lasso.predict(tournament_data[feature_names])
このようにすると、自身の予測結果に対して関連の強い特徴量のみを選んで直交化することができ、効率的にfeature exposureを下げることができます。シャープの改善に寄与できる場合があります。
以上。
コメント
いいね以上の気持ちはコメントで