CPU <-> GPU でのメモリ転送
私は Cupy を深層学習以外の目的に使っていますが、その主なボトルネックになるのは、CPU <-> GPU 間のメモリの転送です。
GPUメモリはだいたい 4GB とか 8GB とかしかないので、学習データの全てをGPUに置けないことが多くなります。
そのため、メインメモリに置いてあるデータを毎回読みだしてGPUメモリに転送して、それを使ってトレーニングするということになります。
ただし、メインメモリからGPUメモリにデータを転送するには結構時間がかかってしまうので、小さなネットワークだと訓練時間よりもデータ転送に時間がかかってしまって、CPUで計算したほうが速いなんてこともよくあります。
非同期処理を行うことでそれを解決できることがあるかもしれません。
つまり、あるミニバッチを用いてモデルを訓練している間に、次のミニバッチをGPUに転送しておくことができると、メモリ転送時間の影響を実効的に削減できます。
cupy.ndarray へのメモリの転送
Cupyのドキュメント にはいくつかGPUメモリの確保・転送の方法が載っています。
array_cpu = numpy.ones((1000, 10000))
array_gpu = cupy.array(array_cpu)
とすると、とりあえずGPUメモリ上にデータを転送できますが、これでは非同期処理はできません。
なお Python の Thread を使って上記コードを非同期処理したところで、実際のメモリ転送はバックグラウンドで行われません。GPUメモリへの転送は CUDA が握っており、CUDA上での非同期処理を行う必要があります。
ほかにもGPUメモリ上にデータを転送する方法として cupy.ndarray.set() があります。
array_cpu = numpy.ones((1000, 10000))
array_gpu = cupy.ndarray(array_cpu.shape, array_cpu.dtype)
array_gpu.set(array_cpu)
とすることでデータを転送できます。
Cupy.cuda.Stream
cupy.ndarray.set() のドキュメント には set() メソッドは np.ndarray の他に、cupy.cuda.Stream オブジェクトを受け取ることができると書いてあります。
cuda.Stream はCUDAで非同期処理を行うためのAPIです。
それぞれ別のStreamに操作を割り当てることで、操作を非同期に実現できることになっています。
まず、以下を試しました(うまくいかない例です。)
array1_cpu = numpy.ones((1000, 10000))
array2_cpu = numpy.ones((1000, 10000))
# GPU上にメモリを確保
array1_gpu = cupy.ndarray(array1_cpu.shape, array1_cpu.dtype)
array2_gpu = cupy.ndarray(array2_cpu.shape, array2_cpu.dtype)
# Stream オブジェクトの確保
stream1 = cupy.cuda.Stream(non_blocking=True)
stream2 = cupy.cuda.Stream(non_blocking=True)
# Cupy は最初の実行にはコンパイルを行うので、ベンチマークに含めないようここで行っておく
cupy.ones(2) * 2
# GPU 上にメモリを転送
array1_gpu.set(array1_cpu, stream=stream1)
array2_gpu.set(array2_cpu, stream=stream1)
# array2_cpu の転送を待ってから計算を行う (うまくいかない)
stream1.synchronize()
array1_gpu *= 2
これを、nvida のパフォーマンス確認ツールである nvprof を用いて確認した結果が以下のとおりです。
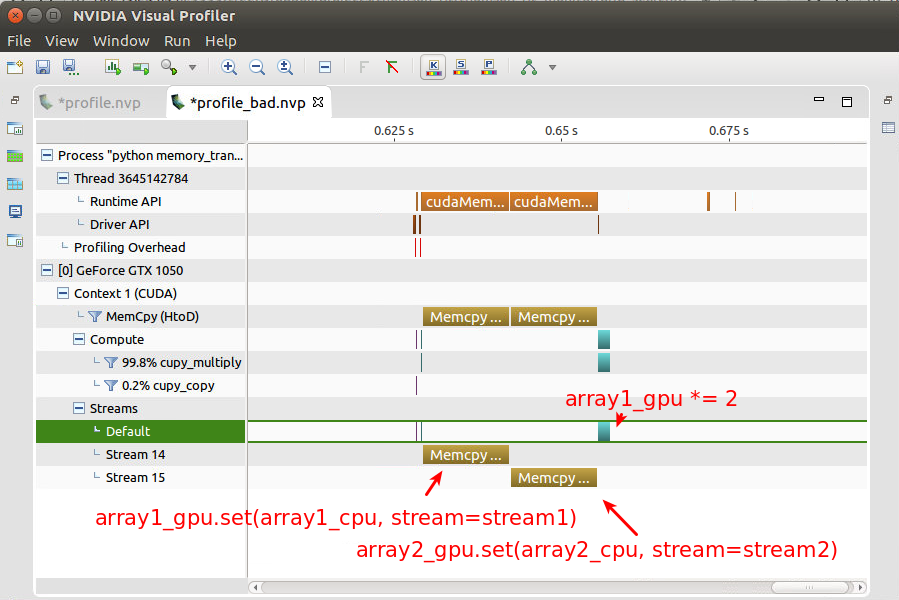
array1.set(), array2.set() が別々のStreamで行われていることは確認できましたが、非同期処理は行われていないようです。
つまり、 array2_gpu.set が完了してから array1_gpu *= 2 が実行されているので、これではうまくいっているとは言えません。
StackOverflow で質問しても 回答は得られずどうすればいいのわからずずっと悩んでいましたが、Chaniner のソースコードを読むことでその方法を見つけました。
Cupy を用いたGPUメモリへの非同期転送
Chaniner.to_gpuでは、なぜか np.ndarray を一度コピーしてからGPUメモリに転送していました。
単純化したコードは以下のような感じです
def to_gpu(array, stream):
...
# src (np.ndarray)で使うメインメモリ上の領域を確保
mem = cupy.cuda.alloc_pinned_memory(array.nbytes)
# 確保したメモリを元にnp.ndarrayを作る
src = numpy.frombuffer(
mem, array.dtype, array.size).reshape(array.shape)
# 確保したメモリ上にデータを転送
src[...] = array
# GPUメモリ上にデータを転送
ret.set(src, stream)
return ret
どうも、numpy にまかせたメモリ確保ではうまくStreamで扱えないようで(Pythonがガベージコレクションを握っているからでしょうか?)、明示的にメモリを確保する必要があるようです。
[追記] このあたりの件について、 nus_miz さんからコメントをいただきました。 ありがとうございました。
pinned memory にコピーする必要があるのは、numpyやcupyのせいではなくCUDAの仕様です。
CUDAの非同期メモリ転送(cudaMemcpyAsync)は、CPUではなくDMAを用いてメモリをコピーします。
この際OSによりホスト側メモリがスワップアウトすると困るので、スワップアウトされないメモリ(pinned memory)を特別に確保(cudaMallocHost)して使用する必要があります。
これを参考にした以下のコード
def to_pinned_memory(array):
mem = cupy.cuda.alloc_pinned_memory(array.nbytes)
src = numpy.frombuffer(mem, array.dtype, array.size).reshape(array.shape)
src[...] = array
return src
# array1_cpu, array2_cpu を pinned_memory として確保
array1_cpu = to_pinned_memory(numpy.ones((1000, 10000)))
array2_cpu = to_pinned_memory(numpy.ones((1000, 10000)))
# GPU上にメモリを確保
array1_gpu = cupy.ndarray(array1_cpu.shape, array1_cpu.dtype)
array2_gpu = cupy.ndarray(array2_cpu.shape, array2_cpu.dtype)
# Stream オブジェクトの確保
stream1 = cupy.cuda.Stream(non_blocking=True)
stream2 = cupy.cuda.Stream(non_blocking=True)
# Cupy は最初の実行にはコンパイルを行うので、ベンチマークに含めないようここで行っておく
cupy.ones(2) * 2
# GPU 上にメモリを転送
array1_gpu.set(array1_cpu, stream=stream1)
array2_gpu.set(array2_cpu, stream=stream1)
# array2_cpu の転送を待ってから計算を行う
stream1.synchronize()
array1_gpu *= 2
を用いることで、無事最終行が非同期で実行されました。
nvprof で確認した様子が以下のとおりです。
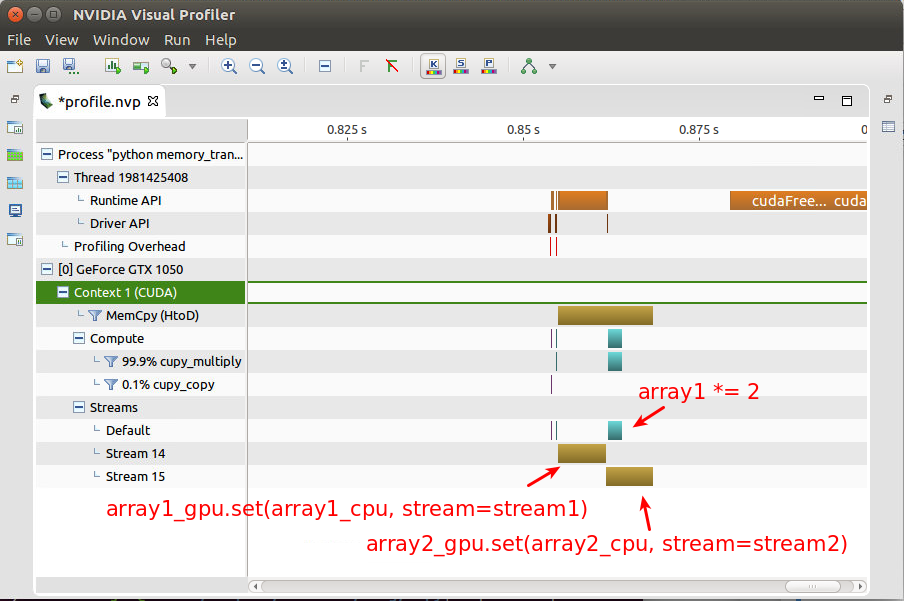
array2_gpu.set と同時に array1_gpu *= 2 が実行されています。これをうまく組み合わせることで、メモリ転送の時間を削減できそうです。
Cupy を用いたGPUメモリからCPUメモリへの非同期転送
詳しくは省略しますが、逆方向のメモリ転送は以下のようにすることで非同期実行できます。
# 移動元の np.ndarray のメモリ領域を指すポインタを取得
ptr = array_cpu.ctypes.get_as_parameter()
array_gpu.data.copy_to_host_async(ptr, array_gpu.nbytes, stream)
まとめ
Cupyを用いてメモリの非同期転送を行うためには、
- コピー元の
np.ndarrayをcupy.cuda.alloc_pinned_memoryとして確保しておく -
cupy.cuda.Streamを用いる の2つがポイントのようです。
Cupy は非常にお手軽にGPU計算を実行できるのですばらしいですが、ドキュメントやコード例が充実するのはもう少し先になりそうです。
コメント
いいね以上の気持ちはコメントで