0. はじめに
2020年9月7日にAtCoder公式のアルゴリズム集 AtCoder Library (ACL)が公開されました。
私はACLに収録されているアルゴリズムのほとんどが初見だったのでいい機会だと思い、アルゴリズムの勉強からPythonでの実装までを行いました。
この記事ではsccをみていきます。
ACLでは scc と internal_ecc が存在し、internal_scc が本体、scc がインターフェイスのようになっています。これは、scc のアルゴリズムを他(twosat)でも使うためです。なので、ACLの実装を見たい場合はinternal_scc.hppを見てください。
対象としている読者
- sccってなに?という方。
- sccを理解し自分で実装できるようにしたい方。
- ACLのコードを見てみたけど何をしているのかわからない方。
- C++はわからないのでPythonで読み進めたい方。
参考にしたもの
DFS tree について
lowlink について
1. 前提知識
本記事を読む上での前提知識を確認しておきます。詳しい説明は各自調べてください。
有向グラフ
辺が向きを持つグラフです。
DAG
DAG は有向グラフのうち、サイクルを持たないグラフです。
有向非巡回グラフ(Directed Acyclic Graph: DAG)。
DFS, DFS tree
DFS はグラフを探索するためのアルゴリズムの1つです。深さ優先探索(Depth First Search: DFS)。
DFS を行ったときに通った辺のみを残すと木(森)になり、これを DFS tree と呼びます。
トポロジカルソート
DAG の頂点を1列に並べたとき、全ての辺が同一方向になるように頂点を並べることです。
グラフが DAG ならば必ずトポロジカルソート可能です。
CSR
疎行列のデータを保持する方法の1つです。ACL ではグラフの辺集合を保持するために使っています。
【internal_csr編】AtCoder Library 解読 〜Pythonでの実装まで〜で説明しています。
2. SCC とは
まず、SCCとは何かを見ておきます。
2.1. SCC
SCC は Strongly Connected Component の略で日本語では強連結成分と呼ばれます。
有向グラフにおいて、次の条件を満たす部分グラフを強連結であると呼びます。
- 任意の頂点
つまり、どの2頂点も互いに行き来できるグラフです。
そして、強連結かつ極大な部分グラフを強連結成分と呼びます。
具体例として下図のようなグラフを考えます。

頂点集合
が存在するので強連結であり、かつ極大なので強連結成分です。
また、頂点集合
が存在するので強連結であり、かつ極大なので強連結成分です。
一方、頂点集合
頂点
このグラフの強連結成分は下図のようになります。

このように、有向グラフを強連結成分に分解することを強連結成分分解と言います。
また、各強連結成分を1つの頂点とみなしてできるグラフを本記事では縮約されたグラフと呼ぶことにします。
縮約されたグラフは DAG になります。

2.2. ACLのSCC
ACL の SCC は与えられた有向グラフを強連結成分分解し、さらに頂点を、縮約されたグラフでトポロジカルソートした結果を返します。
今回の例では
[[2, 0, 1], [4], [3], [6, 5, 7, 8], [9, 10]]
のような結果になります。(トポロジカルソートが一意でない場合にはそのうちのどれかになりますし、各強連結成分内での頂点の順序は未定義です。)
3. 強連結成分を求めるアルゴリズムたち
強連結成分を求めるアルゴリズムには有名なものが2つあります。
Kosarajuのアルゴリズム
まず、1回DFSを行い、その後、辺を逆向きにしたグラフでもう1回DFSを行うことで強連結成分を求めます。
詳しくは強連結成分分解の意味とアルゴリズム | 高校数学の美しい物語などを見てください。
Tarjanのアルゴリズム
ACLの実装であり、本記事で見ていくアルゴリズムです。1回のDFSで強連結成分を求めることができます。
4. Tarjanのアルゴリズム
では具体的な方法を見ていきます。
ここからは具体例として以下のグラフを考えることにします。

Tarjanのアルゴリズムの目的は、各頂点にその頂点が所属する強連結成分固有の値(SCC idと呼ぶことにします)を割り振ることです。
また、SCC id の昇順に強連結成分をたどると、縮約されたグラフでトポロジカルソートされた順序になっているようにします。
今回の例では下図のように SCC id を付与することを目標とします。

4.1. DFS tree
まずはこのグラフを DFS して、DFS tree を構築します。
DFS の仕方によってDFS tree は変わりますが、ここでは頂点

4.2. 辺の分類
今後の説明のため、全ての辺を特徴に合わせて以下の4つに分類し、名前をつけて呼ぶことにします。
1. tree edge
DFS に使われた辺を tree edge と呼びます。例えば、頂点
2. forward edge
tree edge でない辺のうち、頂点
3. back edge
tree edge でない辺のうち、頂点
4. cross edge
tree edge でない辺のうち、頂点

4.3. 頂点の特徴づけ①
頂点番号はただのラベルであり、グラフの構造には関係ないので、強連結成分を求めるのには役に立ちません。そこで、構築した DFS tree に固有の特徴づけを行います。
具体的には、DFS で初めて訪問した順(いわゆる行きがけ順)に頂点に値を付与します。この値を order と呼ぶことにします。
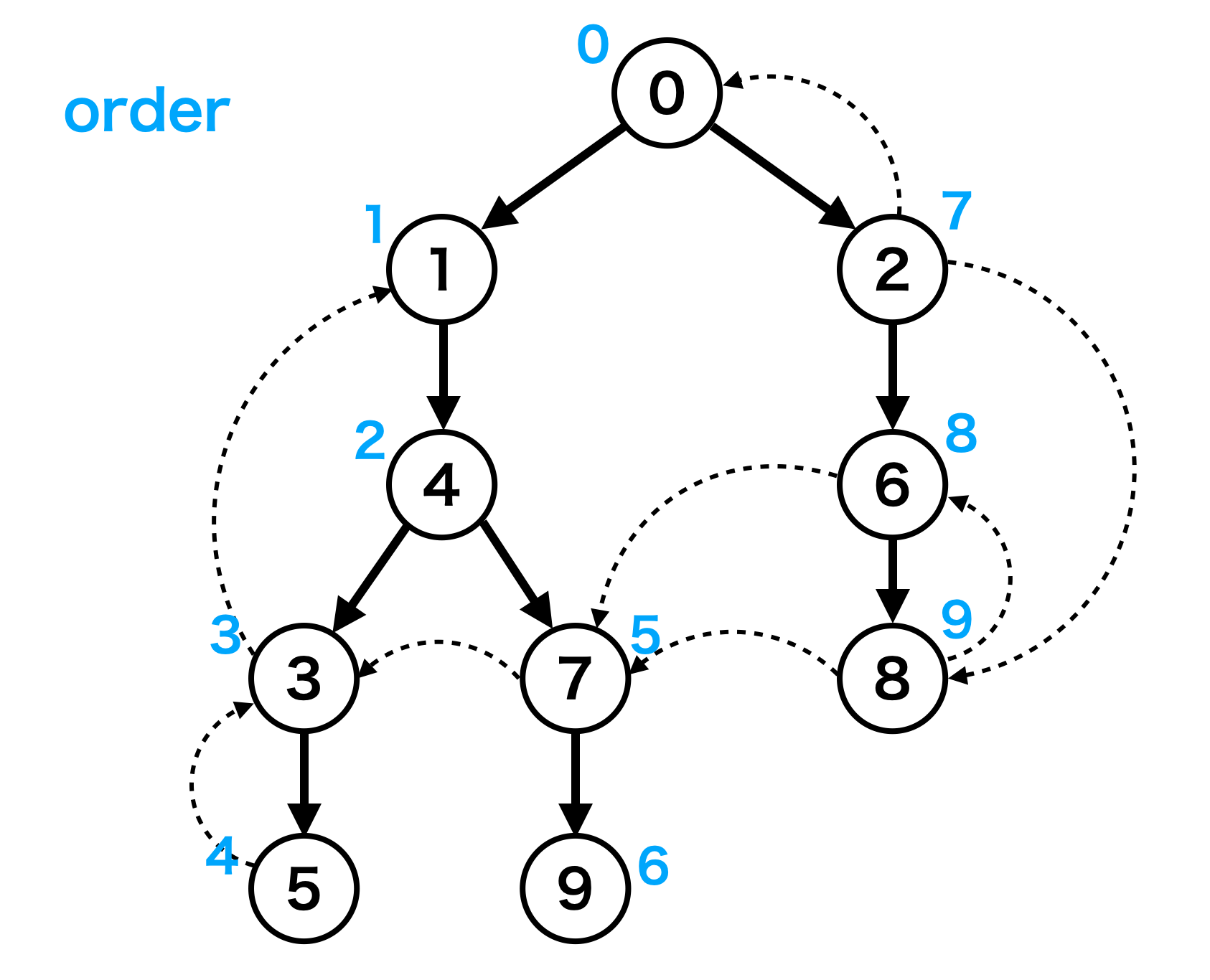
このような特徴づけを行うと次の性質が見えてきます:
頂点
なぜなら、もしそのような辺が存在するならばその辺は DFS で使われる (tree edge である)はずだからです。
4.4. SCCの観察
さて、先ほど定義した order と強連結成分分解の結果を重ねてみると下図のようになります。

これを観察すると次のことが見えてきます:
各強連結成分はその成分内で order の最も小さい頂点を根とした木構造になっている
これが正しいかどうかを確認します。
- DFS tree が1つの強連結成分から構成される
- 頂点数が 2 以下
- 全ての強連結成分は 1 つの頂点で構成される
のいずれかを満たす場合は明らかなので、そうでない場合を考えます。
頂点
ここで、これらは以下の条件を満たすようにします。
条件
すると、上の主張は DFS tree において下図の左の構造しかあり得ないということになります。

パターン1の場合
条件
パターン2の場合
条件
これで、DFS tree における SCC の構造がわかりました。
4.5. 頂点の特徴づけ②
グラフを DFS tree で表すと各 SCC はそれぞれ、order の最も小さい頂点を根とした根付き木になっていることがわかったので、この根を特別視し、scc_root と呼ぶことにします。

ここまでくると、このアルゴリズムの方針が見えてきます。
DFSの道順を考えると scc_root の帰りがけ(下図の★)の時点で、この scc_root を根とする部分木のうち、SCC id が未確定の頂点たちが、1つの強連結成分を構成していることがわかります。
また重要な点として、この方法では DFS tree の葉に近い方から SCC id が確定していくことが見て取れます。これはトポロジカル順序の逆順に SCC id が付与されていくことを意味しています。
したがって、最後に SCC id を逆転させることで縮約されたグラフでのトポロジカルソートを達成できます。
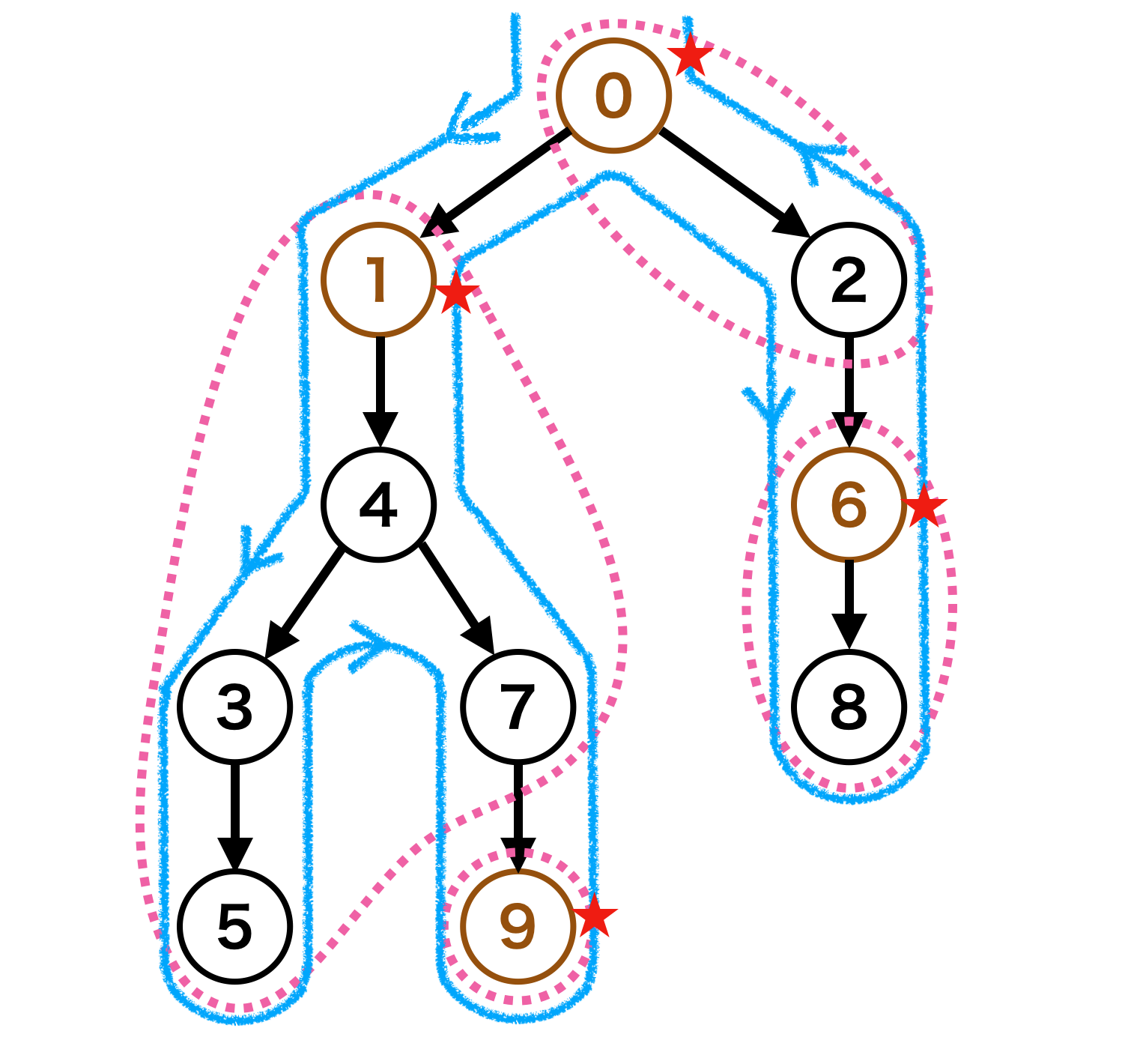
あとは、ある頂点の帰りがけの時点でその頂点が scc_root かどうかを判定できれば良いことになります。
そのために、scc_root である頂点、そうでない頂点を観察してみます。

まず分かるのは、頂点
次に cross edge について考えてみます。頂点
まず、頂点
頂点
最後に tree edge について考えてみます。現在 DFS で頂点
一方、SCC id が未確定の子孫は全て
まとめると、頂点
- back edge が出ている
- 帰りがけ時点で未確定の頂点への cross edge が出ている
- 帰りがけ時点で未確定の子孫のうち、
のうち少なくとも1つを満たすとなります。
このような条件から、各頂点について次のように定義される lowlink と呼ばれる値を導入します:
頂点
- tree edge を任意の回数使用する
- back edge もしくは cross edge を高々1回使用する
この特徴量を導入することで
と条件を簡潔に記述できます。
4.6. より一般的なグラフの場合
本記事では簡単のため、具体例として自己ループ、多重辺のない連結なグラフを扱いました。また、DFSを開始する頂点は縮約されたグラフをトポロジカルソートした際に先頭に来るように選びました。
ここではこのような作為的な設定をしなくてもアルゴリズムがうまくいくことを確認します。
自己ループが存在する場合
自己ループをたどっても order の小さい頂点へ行くことはできないので lowlink に影響せず、問題ありません。
多重辺が存在する場合
多重辺のうち lowlink の計算に影響するのは高々 1 本であり、その他の辺は何も影響しないので、辺が 1 本の場合と変わらず多重辺が存在しても問題ありません。
グラフが非連結な場合
ある連結成分内の頂点と別の連結成分内の頂点は当然非連結であるので、SCC を求める際には互いに影響することなく、それぞれ独立に考えることができます。また、非連結な頂点間にはトポロジカル順序が定まらないので、どの連結成分から SCC を求めても良いことが分かります。
トポロジカル順序で先頭でない頂点から始めた場合
下図は今回扱った例の縮約されたグラフです。

ここでは最も頂点番号の大きい頂点
次に SCC id が未確定の頂点のうち最も頂点番号の大きい頂点
最後に未確定の頂点のうち最も頂点番号の大きい頂点
これで頂点

このように、どの頂点を DFS の始点に選んでも必ずトポロジカル順序の逆順に SCC id が決定されます。
したがって、SCC id が未確定の頂点がある限り、そのような頂点から 1 つ選んで DFS するのを繰り返すことで望んだ結果が得られることが分かりました。
4.7. 実装方法
これで、Tarjan のアルゴリズムは以下の手続きによって強連結成分分解を行うことがわかりました。
while (全ての頂点の SCC id が確定するまで){
未確定の頂点からDFS
DFSの最中に以下のことを行う:
* 行きがけに order を付与
* lowlink を計算
* 帰りがけにその頂点が scc_root の場合は
DFS tree におけるその頂点の部分木のうち
未確定の頂点に SCC id を付与
}
SCC id を逆順にすることで縮約されたグラフでのトポロジカルソートを達成する
これで ACL の SCC を実装する準備が整いましたが、実装する上でのつまづく可能性のあるポイントを挙げておきます。
1. scc_rootが見つかったとき
一番難しいのは、「ある頂点
実はこれは stack を使うとうまく実装できます。(stack は末尾への append、末尾の pop が高速なデータ構造です。Python ではリストで代用できます。)
DFS の行きがけに頂点を stack に追加していくと、頂点
2. lowlinkの計算(辺の種類)
lowlinkの定義では 高々1回使えるのは back edge と cross edge のみで、forward edge は使いませんでした。しかし、forward edge は order が大きくなる方向への辺であり、lowlink の定義は最小値なので forward edge を使ったとしても lowlink の計算には影響しません。
したがって、DFS で辺をたどる際はその辺が tree edge かどうかだけ見れば良いです。これは辺をたどった先の頂点が訪問済みかどうかと同値なので、 辺をたどった先の頂点に order が付与されているかどうかを見ればわかります。
3. lowlinkの計算(頂点の種類)
lowlink を更新する際には SCC id が未確定の頂点のみについて行う必要があります。これをそのまま実装しても構いませんが、 ACL では少しの工夫でより簡潔に DFS を記述できるようにしています。
頂点
まず辺が tree edge の場合を考えます。tree edge は何回でも使えるので
lowlink[v] = min(lowlink[v], lowlink[u])
と更新されます。
次に辺が tree edge でない場合を考えます。tree edge でない場合は 1 回しか使えないので、使うとしたら最後になります。(tree edge での移動は必ず order が大きくなるので back/cross edge での移動の後にやる意味はありません。)
したがって
lowlink[v] = min(lowlink[v], order[u])
と更新されます。back edge や cross edge は order が小さい頂点と結ばれることがあるため、頂点
そこで SCC id が確定した際に、その頂点の order を min の演算に影響しない ∞ に置き換えることで、SCC id が確定した頂点を実質的に除外することができます。
アルゴリズムを視覚化したものを併せてみると分かりやすいかもしれません。
5. 実装
では Python で実装します。変数名等はできるだけ ACL に合わせます。
この記事の冒頭でも述べたように ACL の SCC では
-
internal_scc: アルゴリズムの実体 -
scc: internal_scc を使うためのインターフェイス
のような形になっています。
5.1. internal_scc
まずはinternal_scc.pyから実装していきます。
この実装に必要な、internal_csr.py はすでに実装しているものとします。
まず、クラス_SCC_graph を作成し、コンストラクタを記述します。初期化に必要な値は頂点数のみです。Tarjan のアルゴリズムは再帰関数で実装するので再帰上限を変更しておきます。
また、頂点数を返すメソッドnum_vertices()と辺を追加するメソッドadd_edge()も実装します。
import sys
from internal_csr import csr
class _SCC_graph:
def __init__(self, n):
self._n = n
self.edges = []
sys.setrecursionlimit(max(2*n, sys.getrecursionlimit()))
def num_vertices(self):
return self._n
def add_edge(self, frm, to):
"""
from -> to の辺を追加
Args:
frm (int): 追加する辺の始点
to (int): 追加する辺の終点
"""
self.edges.append([frm, to])
次に今回の心臓部である Tarjan のアルゴリズムを実装します。
def scc_ids(self):
"""
Tarjan のアルゴリズムでグラフの強連結成分分解を行う
Returns:
group_num (int): グラフの強連結成分数
ids (List[int]): 各頂点が属する強連結成分のid
"""
# 辺をcsr形式に変換
start, elist = csr(self._n, self.edges)
# 探索した頂点数, 見つかったSCCの数
now_ord, group_num = 0, 0
# 探索済みかつidが未確定の頂点を管理するstack
visited = []
low = [0] * self._n # lowlink
ord_ = [-1] * self._n # order (-1は未探索を表す)
ids = [0] * self._n # SCC id
def dfs(v):
nonlocal now_ord, group_num, visited, low, ord_, ids
# 行きがけ:
# * orderを付与
# * lowlinkをorderで初期化
# * stackに追加
low[v] = ord_[v] = now_ord
now_ord += 1
visited.append(v)
for i in range(start[v], start[v+1]):
to = elist[i]
# 行き先が未探索の場合(この辺はtree edge)
if ord_[to] == -1:
dfs(to)
# tree edgeは何回でも使えるので
# vのlowlink<=toのlowlink
low[v] = min(low[v], low[to])
# 探索済みの場合 (この辺はtree edgeでない)
else:
# tree edgeでない辺は1回しか使えないので
# 行き先のorderでlowlinkを更新
low[v] = min(low[v], ord_[to])
# 帰りがけ:
# * vがscc_rootのときstackのv以降にSCC idを付与
# * orderをn(無限大と同等)に変更しこれ以降
# lowlinkの計算に使われないようにする
if low[v] == ord_[v]:
while True:
u = visited.pop()
ord_[u] = self._n
ids[u] = group_num
if u == v: break
group_num += 1
for i in range(self._n):
# 未探索の頂点からDFSを行う
if ord_[i] == -1:
dfs(i)
# SCC id はトポロジカル順序の逆順に付与されているので反転する
for i in range(self._n):
ids[i] = group_num - 1 - ids[i]
return group_num, ids
最後にscc_ids()で決まった SCC id から頂点を SCC 毎にまとめて返すメソッドscc() を実装します。
def scc(self):
"""
強連結成分分解の結果を整形して返す
Returns:
groups (List[List[int]]): 各リストがそれぞれSCCに対応。
縮約されたグラフでのトポロジカルソートがされている
"""
group_num, ids = self.scc_ids()
groups = [[] for _ in range(group_num)]
for i in range(self._n):
groups[ids[i]].append(i)
return groups
まとめると以下のようになります。
import sys
from internal_csr import csr
class _SCC_graph:
def __init__(self, n):
self._n = n
self.edges = []
sys.setrecursionlimit(max(2*n, sys.getrecursionlimit()))
def num_vertices(self):
return self._n
def add_edge(self, frm, to):
self.edges.append([frm, to])
def scc_ids(self):
start, elist = csr(self._n, self.edges)
now_ord, group_num = 0, 0
visited = []
low = [0] * self._n
ord_ = [-1] * self._n
ids = [0] * self._n
def dfs(v):
nonlocal now_ord, group_num, visited, low, ord_, ids
low[v] = ord_[v] = now_ord
now_ord += 1
visited.append(v)
for i in range(start[v], start[v+1]):
to = elist[i]
if ord_[to] == -1:
dfs(to)
low[v] = min(low[v], low[to])
else:
low[v] = min(low[v], ord_[to])
if low[v] == ord_[v]:
while True:
u = visited.pop()
ord_[u] = self._n
ids[u] = group_num
if u == v: break
group_num += 1
for i in range(self._n):
if ord_[i] == -1: dfs(i)
for i in range(self._n):
ids[i] = group_num - 1 - ids[i]
return group_num, ids
def scc(self):
group_num, ids = self.scc_ids()
groups = [[] for _ in range(group_num)]
for i in range(self._n):
groups[ids[i]].append(i)
return groups
5.2. scc
次にインターフェイス部分であるscc.pyを実装します。
こちらはinternal_sccのメソッドを呼び出すだけなので全部まとめて実装します。
from internal_scc import _SCC_graph as internal
class SCC_graph:
def __init__(self, n):
self._n = n
self._scc_graph = internal(n)
def add_edge(self, frm, to):
assert 0 <= frm < self._n
assert 0 <= to < self._n
self._scc_graph.add_edge(frm, to)
def scc(self):
return self._scc_graph.scc()
6. 使用例
今回扱ったグラフで実際に使用してみます。
from scc import SCC_graph
# 本記事で扱った具体例
n = 10
E = [
[0, 1],
[0, 2],
[1, 4],
[2, 6],
[2, 0],
[2, 8],
[3, 5],
[3, 1],
[4, 3],
[4, 7],
[5, 3],
[6, 8],
[6, 7],
[7, 9],
[7, 3],
[8, 6],
[8, 7],
]
scc_graph = SCC_graph(n)
for a, b in E:
scc_graph.add_edge(a, b)
groups = scc_graph.scc()
print(groups) # [[0, 2], [6, 8], [1, 3, 4, 5, 7], [9]]
7. verify用の問題
verify用の問題が AtCoder Library Practice Contest にあります。
AtCoder Library Practice Contest G-SCC
考察要素はないのでそのまま使うだけです。
n, m = map(int, input().split())
# 頂点数nで初期化
scc_graph = SCC_graph(n)
# 辺の追加
for _ in range(m):
a, b = map(int, input().split())
scc_graph.add_edge(a, b)
# SCCを求める
groups = scc_graph.scc()
# 答えの出力
n_scc = len(groups)
print(n_scc)
for i in range(n_scc):
g = groups[i]
print(len(g), ' '.join(map(str, g)))
制限時間
また、PyPy は再帰関数が苦手と言われていますが、この問題では十分高速に実行されました。
ちょっとした高速化
Pythonではmin()関数のコストが結構大きいので if 文で代用すると少し高速化できます。また、internal_scc を直接扱うことでも若干の高速化ができます。
8. おわりに
今回は Tarjan のアルゴリズムによる強連結成分分解を見てきました。
説明の間違いやバグ、アドバイス等ありましたらお知らせください。
コメント
いいね以上の気持ちはコメントで