0. はじめに
2020年9月7日にAtCoder公式のアルゴリズム集 AtCoder Library (ACL)が公開されました。
私はACLに収録されているアルゴリズムのほとんどが初見だったのでいい機会だと思い、アルゴリズムの勉強からPythonでの実装までを行いました。
この記事ではSegtree(セグメント木)をみていきます。
対象としている読者
- セグメント木ってなに?という方。
- セグメント木を理解し自分で実装できるようにしたい方。
- ACLのコードを見てみたけど何をしているのかわからない方。
- C++はわからないのでPythonで読み進めたい方。
参考にしたもの
関連する数学の参考記事です。
maspyさんのセグメント木に関する記事です。
1. セグメント木とは
セグメント木とは完全二分木の構造を利用することで列(「数」列や、「文字列」列など)に対して以下の2種類のクエリ
を高速に行うことができるデータ構造です。(「積」は掛け算に限らず演算の結果を表すこととします。)
もしこの段階で、「クエリってなに?」、「なんで木を使うと高速化できるの?」、「何言ってるか全然わからん」と感じた場合は先にFenwick_Tree編(の1〜2章)を読んでから戻ってくると良いかもしれません。
1.1. ACLのセグメント木
ACLのセグメント木は非再帰・抽象化セグメント木です。
- 非再帰:再帰呼出しを用いずに実装します。
- 抽象化:要素間の演算を固定せず、使用時に指定できるように実装します。
これに倣い、本記事では具体的な演算に特定せず、演算は演算として扱うこととします。(理解のために具体的な演算で例示することはします。)
1.2. 本記事における用語、記号の定義
まず、本記事における用語、記号の意味を確認しておきます。
集合
クエリの対象となる列
例)
もちろん1番目の例で
二項演算
集合
です。
例1
-
演算として足し算を考えると
-
-
「文字列
例2
-
-
例1の1つ目で見た、「自然数全体上での足し算」は積も自然数全体という集合に属します。また、例2の1つ目で見た、「空でない文字列全体上での各1文字目の連結」という演算も、積は空でない文字列全体という集合に属します。このように、「積全体が属する集合」が「演算が定義された集合」に含まれる場合、演算
一方、例1, 2の2つ目の演算は閉じていません。演算が閉じていないと扱いが難しいので本記事では閉じた演算を考えることにします。もっとも、整数全体の集合上での足し算、掛け算、最大値、最小値などは閉じているので、あまり気にしなくても良いかもしれません。
2. セグメント木の仕組み
ではセグメント木の仕組みを見ていきます。
ここからはクエリの対象となる列として長さ
また、前章で述べたように、この列の要素が属する集合を
2.1. 完全二分木
1.セグメント木とはで書いたように、セグメント木は完全二分木の木構造です。すなわち、葉以外の全てのノードが2つの子ノードを持ち、全ての葉は同じ深さを持ちます。
いま、
葉以外の各ノードには子ノードの積を格納します。つまり、子ノードが

さて、ここで2つの問題が現れます。
1つ目は上図の上から2段目に現れるかっこについてです。いま、取得クエリとして
を取得することを考えます。上図をみてみるとちょうど
は必ず成り立つとは限らないということです。
例えば、要素として
左辺はかっこの部分を先に計算し、
です。一方右辺は左から順番に計算し、
となり、等号は成り立ちません。
一方、演算として足し算
このように、演算によっては計算する順序が重要になる場合があります。ですが、計算する順序によって値が異なる演算の場合にはセグメント木の「事前に2つずつの積を保持しておく」という操作が無意味になってしまうので計算する順序を変えても値が変わらない演算のみを考えることにします。
具体的には任意の要素
という関係が成り立つ演算のみを考えます。この関係を結合法則(結合律)といいます。
注意 交換法則について
本記事の実装では演算が交換法則を満たすことを要求しません。
交換法則とは
という関係です。これを要求しないということは
2つ目の問題は上図の"?"の部分です。完全二分木の葉の数は 2 のべき乗個ですが、対象の列の要素が常に 2 のべき乗個とは限りません。空いている部分には何を入れれば良いでしょうか?
ここでも、取得クエリを考えてみます。
実は、? の部分は使わずに取得クエリを処理することができます。なので、? には
しかし、ACLのセグメント木ではある特別な値を入れています。この特別な値を用意することで
-
全要素の総積が
- セグメント木の初期化方法が柔軟になる
- 実装が容易になる
といったメリットがあります。
ここでは「全要素の総積を
全要素の総積が
が入っていることになります。ここから下段の ? を逆算していきます。まず、1つ下の段は左側が
なので右側の ? には
が入ることがわかります。さらにこの下を見ると次の ? は
であることがわかります。さて、これはどういうことでしょうか。この
ということです。いま、
具体的には、葉ノードの ? には次のような値
任意の
を満たす。
このような
例をみてみましょう。
任意の要素
任意の要素
このように単位元は集合
ここまでをまとめると、(ACLの実装で)セグメント木を構築するには次の条件を満たしている必要があることがわかりました。
- 演算
これらの条件を満たす組
ここからはこれらの条件を満たしている場合を考えます。
するとセグメント木の各ノードは下図のようになります。

2.2. 木を1次元配列で表現する
次に、木を1次元配列で表現することを考えます。木構造で重要なのはノードの親子関係が決まっていることです。言い換えれば、あるノードからそのノードの親や子にアクセスさえできれば、形として木になっている必要はありません。セグメント木は完全二分木という整った構造のため、適切に各ノードにindexを振ることで親子のアクセスを容易にすることができます。
具体的にはdataという長さ size と呼ぶことにします。本記事の例では size=8 です。

では、1次元配列dataに対するアクセスをみていきます。
まず、クエリ対象の列の要素にアクセスする方法です。例えば、data[8]、data[11]とアクセスすれば良いです。より一般的には、data[i + size]へのアクセスをすれば良いことがわかります。
次に子ノードへアクセスする方法です。いくつかみてみると、
-
data[1]の子はdata[2]とdata[3] -
data[2]の子はdata[4]とdata[5] -
data[5]の子はdata[10]とdata[11]
となっています。一般的には
-
data[i]の子はdata[2 * i]とdata[2 * i + 1]
であることがわかります。
最後に親ノードへのアクセスです。
-
data[8]の親はdata[4] -
data[9]の親はdata[4] -
data[6]の親はdata[3] -
data[7]の親はdata[3]
となっていて、一般的に
-
data[i]の親はdata[i // 2]
であることがわかります。
これで親子へのアクセス方法がわかったので木を1次元配列で表現することができました。
ここからは構築、クエリ処理の具体的な方法をみていきます。
2.3. セグメント木の構築
ではセグメント木の構築方法からみていきます。
手順としては
- セグメント木の大きさを決める
- 葉に対象の列を入れる
- 葉以外のノードに区間の演算結果を入れる
となっています。
擬似コードは以下のようになります。配列のスライスアクセス[l:r]は右開区間[l, r)です。
セグメント木の構築 (入力: 列A, 演算op, 単位元e){
N = Aの長さ
size = N以上で2のべき乗となる最小の数
data = 長さ(2 * size)、初期値eの配列
// 葉に入力の列を格納
data[size:size + N] = A
// 葉以外のノードを更新
for i = ((size - 1) to 1){
data[i] = op(data[i]の左子ノード, data[i]の右子ノード)
}
}
葉以外のノードを更新する際には
- 葉に近い部分から更新する必要がある
- 演算の左右を入れ替えてはいけない
という点に注意が必要です。
2.4. 更新クエリ
更新クエリ:
を処理する方法を考えます。
いくつか具体例をみてみます。

①
まず、data[2 + size] = b_2とすればいいです。
ここから、
data[5] = op(data[10], data[11])data[2] = op(data[4], data[5])data[1] = op(data[2], data[3])
とすればいいです。
②
まず、data[6 + size] = b_6とします。
次に data[7]を更新しますが、data[7]の中身は実際には
data[7] = op(data[14], data[15])
とすればいいことがわかります。その後
data[3] = op(data[6], data[7])data[1] = op(data[2], data[3])
と更新します。
より一般的には以下のようになります。
更新クエリ(入力: i, x){
// 葉に移動し更新
i += size
data[i] = x
//関係する場所を更新
while (True){
iをdata[i]の親のindexに変更
data[i] = op(data[i]の左子ノード, data[i]の右子ノード)
もしiが根(=1)なら終了
}
}
2.5. 取得クエリ
取得クエリ:
を処理する方法を考えます。
いくつか具体例をみてみます。
①
区間が右開区間であることに注意します。
なので
②
なので4ヶ所を見れば良いことがわかります。
ではこのような操作を機械的に行うにはどうすれば良いでしょうか。様々な例をみてみると次のことがわかります:
「図の各段においてみるべき場所は、区間
なぜなら、区間

擬似コードにすると次のようになります。右開区間であること、演算の左右は入れ替えられないことに注意します。
取得クエリ(入力: l, r){
// 最下段(葉ノード)に移動
l += size
r += size
左の結果 = e(単位元)
右の結果 = e
while (未計算の区間がなくなるまで){
data[l]を使う場合:
左の結果 = op(左の結果, data[l])
data[r-1]を使う場合:
右の結果 = op(data[r-1], 右の結果)
l, rを一つ上の段の適切なノードに移動
}
return op(左の結果, 右の結果)
}
ここからはこの方針に基づき、左右それぞれの場合に、
- ノードの値を使う条件
- 次にみるノードへの移動の仕方
をみていきます。
1. 左側の場合
ノードを使うかどうかは「今いるノードが親ノードにとって左子ノードか右子ノードか」によって判断できます。
いま、data[l]は左子ノードだったとします。このとき、data[l]の親は
data[l]-
data[l]より右の要素であるdata[l+1]
を含んでいるので、data[l]を使うメリットはありません。(data[l]の親を使うことでdata[l]を使うよりも広い区間を一度に求めることができるからです。)
一方、data[l]が右子ノードだった場合はどうでしょうか。このとき、data[l]の親は
data[l]-
data[l]より左の要素であるdata[l-1]
を含んでいます。したがって、data[l]の親を使うことはできないので、data[l]は使わなければならないことがわかります。

また、次の段への遷移としては
- 左子ノードの場合
data[l]の親へ移動 - 右子ノードの場合
data[l+1]の親へ移動
とすれば良いことがわかります。
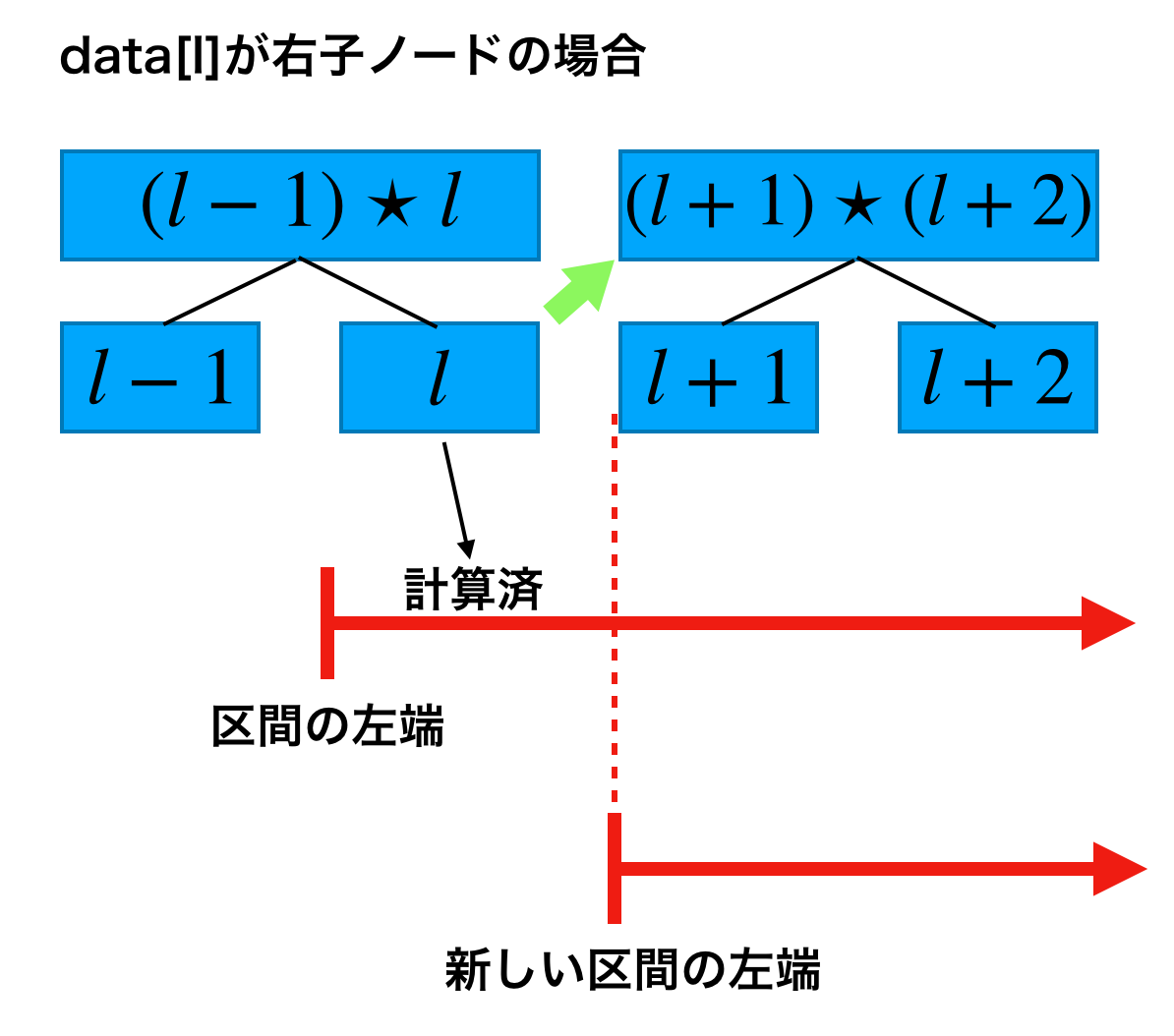
2. 右側の場合
右側も考え方は左側と同じですが、区間
dara[r]が右子ノードの場合、区間の右端はdata[r-1]であり、data[r-1]の親は
data[r-1]-
data[r-1]より右の要素であるdata[r]
を含むのでdata[r-1]を使う必要があります。
一方data[r]が左子ノードの場合、data[r-1]の親はdata[r-1]より広範囲を一度に求められるのでdata[r-1]を使うメリットはありません。

また、次の段への遷移としては
- 左子ノードの場合
data[r]の親へ移動 - 右子ノードの場合
data[r-1]の親へ移動
とすれば良いことがわかります。(
これを未計算の区間がなくなるまで繰り返します。つまり、終了条件は
以上をまとめると取得クエリの擬似コードは次のようになります。
取得クエリ(入力: l, r){
// 最下段(葉ノード)に移動
l += size
r += size
左の結果 = e(単位元)
右の結果 = e
while (l < r){
data[l]が右子ノードの場合:
左の結果 = op(左の結果, data[l])
l -> l + 1 に移動
data[r]が右子ノードの場合:
r -> r - 1に移動
右の結果 = op(data[r], 右の結果)
l, rをそれぞれ親に移動
}
return op(左の結果, 右の結果)
}
実際にこのアルゴリズムが正しく動作することを確認しておきます。
例1.
- 葉に移動:
-
data[9]は右子ノードなので使用し、lに -
data[13]は右子ノードなのでrからdata[12]を使用: - l, rを親に移動:
-
data[5]は右子ノードなので使用し、lに -
data[6]は左子ノードなので使用しない - l, rを親に移動:
return
例2.
-
葉に移動:
-
data[10]は左子ノードなので使用しない -
data[11]は右子ノードなのでrからdata[10]を使用: -
l, rを親に移動:
-
return
3. セグメント木の実装
ではPythonで実装していきます。変数名、関数名は出来るだけACLに合わせて実装します。
また、各メソッドについて時間計算量を記します。ただし、クエリ対象の列の要素数を
3.1. コンストラクタ
まず、クラスSegTreeを作成し、コンストラクタを実装します。コンストラクタは2.3. セグメント木の構築に相当します。
引数は演算op、単位元e、対象の列の要素数n、対象の列vです。e、opは関数オブジェクトです。vはデフォルトでNoneとしており、vを与えない場合は全てのノードが単位元のセグメント木が構築されます。_dがこれまでの説明の
ACLでは_log(atcoder/internal_bitにceil_pow2()というものを定義していますが、Pythonではbit_length()メソッドを使うことで求められるのでこれで代用します。
例:
class SegTree:
def __init__(self, op, e, n, v=None):
self._n = n
self._op = op
self._e = e
self._log = (n - 1).bit_length() # 2^(_log) >= n となる最小の整数
self._size = 1 << self._log
self._d = [self._e()] * (2 * self._size)
if v is not None:
# 葉に対象の列を格納
for i in range(self._n):
self._d[self._size + i] = v[i]
# 葉に近い場所から順に更新
for i in range(self._size - 1, 0, -1):
self._update(i)
def _update(self, k):
self._d[k] = self._op(self._d[2 * k], self._d[2 * k + 1])
時間計算量は
-
vを与える場合、 -
vを与えない場合、
です。
3.2. 更新クエリ
更新クエリ:
を実装します。
def set(self, p, x):
assert 0 <= p < self._n
# 葉に移動
p += self._size
self._d[p] = x
# 関連する場所を更新
for i in range(1, self._log + 1):
self._update(p >> i)
更新する場所は木の高さ分あるので時間計算量は
3.3. 取得クエリ
取得クエリ: 区間
を実装します。自身が右子ノードかどうかはindexの偶奇で判断できます。本実装ではindexが奇数の場合自身は右子ノードとなるので、
def prod(self, l, r):
assert 0 <= l <= r <= self._n
# 左の結果、右の結果
sml, smr = self._e(), self._e()
l += self._size
r += self._size
# 未計算の区間がなくなるまで
while l < r:
# 自身が右子ノードなら使用
if l & 1:
sml = self._op(sml, self._d[l])
l += 1
if r & 1:
r -= 1
smr = self._op(self._d[r], smr)
# 親に移動
l >>= 1
r >>= 1
return self._op(sml, smr)
みる場所は木の高さ分あるので時間計算量は
3.4. その他のメソッド
全要素の総積を取得するメソッドを実装します。3.1. 完全二分木で述べたように、全要素の総積は根に入っているのでこれを取得すれば良いです。
def all_prod(self):
return self._d[1]
時間計算量は
def get(self, p):
assert 0 <= p < self._n
return self._d[p + self._size]
時間計算量は
3.5. まとめ
まとめたものを載せておきます。
class SegTree:
def __init__(self, op, e, n, v=None):
self._n = n
self._op = op
self._e = e
self._log = (n - 1).bit_length()
self._size = 1 << self._log
self._d = [self._e()] * (2 * self._size)
if v is not None:
for i in range(self._n):
self._d[self._size + i] = v[i]
for i in range(self._size - 1, 0, -1):
self._update(i)
def set(self, p, x):
assert 0 <= p < self._n
p += self._size
self._d[p] = x
for i in range(1, self._log + 1):
self._update(p >> i)
def get(self, p):
assert 0 <= p < self._n
return self._d[p + self._size]
def prod(self, l, r):
assert 0 <= l <= r <= self._n
sml, smr = self._e(), self._e()
l += self._size
r += self._size
while l < r:
if l & 1:
sml = self._op(sml, self._d[l])
l += 1
if r & 1:
r -= 1
smr = self._op(self._d[r], smr)
l >>= 1
r >>= 1
return self._op(sml, smr)
def all_prod(self):
return self._d[1]
def _update(self, k):
self._d[k] = self._op(self._d[2 * k], self._d[2 * k + 1])
3.6. 実行速度の改善
ACLはC++で書かれており、コンパイラによる最適化がなされることが前提になっているため、アルゴリズムの記述の仕方も真似して書くとPythonのようなインタープリタ言語では実行速度が想定以上に遅くなってしまいます。
例えばABC185-F Range Xor Queryは先ほど実装したセグメント木を用いて解くことができますが Python(3.8.2)での提出はTLEでした。
解決手段としては
- PyPyやNumbaを用いてコンパイルする
- 遅くなる原因を探し改善を頑張る
があると思います。特にPyPyで実行することによるコンパイルは手軽であり、多くの人が使っている手法だと思います。
ここでは以下の2つを(汎用性を損なわずに)改善し ABC185-F Range Xor Query をPython(3.8.2)でACできるようにします。
① 関数呼び出しを減らす
Pythonでの関数の呼び出しはコストが大きいのでこれを減らします。先ほどの実装ではコンストラクタとsetメソッドで共通して行う処理として_updateメソッドを作りましたがこれをコンストラクタおよびsetメソッド内に直接書くことにします。
② assert文をなくす
ACLではassert文が多用されていますがPythonの場合AtCoder上での実行時にassertの条件式が(おそらく)評価されてしまうのでこれをなくすことで若干の改善ができると思います。
これらを行うと以下のようになります。
class SegTree:
def __init__(self, op, e, n, v=None):
self._n = n
self._op = op
self._e = e
self._log = (n - 1).bit_length()
self._size = 1 << self._log
self._d = [self._e()] * (self._size << 1)
if v is not None:
for i in range(self._n):
self._d[self._size + i] = v[i]
for i in range(self._size - 1, 0, -1):
self._d[i] = self._op(self._d[i << 1], self._d[i << 1 | 1])
def set(self, p, x):
p += self._size
self._d[p] = x
while p:
self._d[p >> 1] = self._op(self._d[p], self._d[p ^ 1])
p >>= 1
def get(self, p):
return self._d[p + self._size]
def prod(self, l, r):
sml, smr = self._e(), self._e()
l += self._size
r += self._size
while l < r:
if l & 1:
sml = self._op(sml, self._d[l])
l += 1
if r & 1:
r -= 1
smr = self._op(self._d[r], smr)
l >>= 1
r >>= 1
return self._op(sml, smr)
def all_prod(self):
return self._d[1]
この実装でABC185-F Range Xor Queryに提出してみると 2912ms でACすることができました。
元の実装では 3300msだったので400ms(あるいはそれ以上)の改善ができました。
もちろんPyPyやNumbaを使えばより高速化でき1000ms未満でACできます。
4. 使用例
ABC185-F Range Xor Queryを実装したセグメント木(実行速度改善ver)を使って解いてみます。
問題文
長さの整数列 があります。
あなたは今からこの数列について個のクエリを処理します。
番目のクエリでは、 が与えられるので、以下の処理をしてください。
のとき
を で置き換える のとき
を出力する
ただしは と のビット単位 xor を表します。
では実際に解いていきます。
まず、セグメント木の使用条件を確認します。
条件は
- 演算
でした。
この問題では制約から
です。Pythonでの対応する演算子は ^ です。また、この演算における単位元は
したがって、
- 集合
- 演算
- 単位元
とすると全ての条件を満たしていることが確認できます。(各自確認してください。)
よってセグメント木が使えることがわかりました。
セグメント木のコンストラクタは引数に演算、単位元を関数オブジェクトとして与える必要があるのでこれを作成しセグメント木を構築します。
def op(x, y):
return x ^ y
def e():
return 0
seg = SegTree(op, e, n, A) # nはAの長さ, Aはリスト
あとは各クエリを処理するコードを書けば終わりです。
t, x, y = map(int, input().split())
x -= 1
if t == 1:
seg.set(x, seg.get(x) ^ y)
else:
print(seg.prod(x, y))
これでこの問題を解くことができました。
提出例
5. セグメント木の補足
5.1. 単位元が存在しないとき
状況によっては集合
こうしてできた
例
そこで
def op_prime(a, b):
if a == 0 :
return b
elif b == 0:
return a
else:
return a + b
とすることでセグメント木を使用できます。
(もちろん
5.2. 完全二分木にする必要性
本記事の実装では葉の数を2のべき乗として、空いている部分には単位元を入れる実装をしましたが、実はクエリ対象となる長さ data を用意し data[N:] = A とすれば 同じコードで正常に動作します。
ただし、演算が非可換の場合には根には全要素の(正しい順序での)総積が入らないといった違いがあります。
詳しくはmaspyさんのページにありますのでそちらを参考にしてください。
6. セグメント木上の二分探索
セグメント木自体は実装できましたが、ACLのセグメント木には他にもmax_right、min_leftというメソッドが用意されています。ここからはこれらのメソッドをみていきます。
6.1. 新たなクエリ
先ほどまでの更新クエリ、取得クエリに加えて以下の新たなクエリを考えます。
以降、
右探索クエリ
ある整数
このクエリを
左探索クエリ
ある整数
このクエリを
右探索クエリと左探索クエリは向きが違うだけなのでここからは右探索クエリのみを考えることにします。
まずは具体例をみてみます。
クエリ対象の列
とし、演算
①
したがって、
②
したがって、
③
したがって、
6.2. 探索クエリの時間計算量
このクエリの時間計算量を考えてみます。なお、ここでは条件式
まず、ナイーブな解法としては先ほどの具体例でみたように、
ここで、条件式
ある整数
に対し、 であるとき、任意の整数 について である。また、 である。
これは
6.3. セグメント木上の二分探索とは
二分探索の解法では、
このとき、セグメント木はあくまでも

さて、今の状況をセグメント木の立場に立って考えてみましょう。するとこの状況は、「セグメント木の外で
ここでセグメント木の内部に目を向けてみると、「同じノードの参照や同じノード間の演算を何度も行う」という無駄が発生していることが分かります。

この無駄は、セグメント木が
そして実際にこれは可能であり、セグメント木上の二分探索と呼ばれています。
セグメント木上の二分探索は先ほど見た無駄を無くしたものであり、時間計算量は
7. セグメント木上の二分探索の仕組み
では、セグメント木上の二分探索の仕組みを見ていきます。
7.1. 概要と通常の二分探索との違い
まず、セグメント木の外で二分探索を行う解法との違いを時間計算量の面から見ておきます。
前章で述べたように、セグメント木の外で二分探索を行う解法では時間計算量は
です。
一方、セグメント木上の二分探索では時間計算量は
となります。
- 答えの大まかな位置を探す :
- そこから徐々に細かく見ていき正しい答えを求める :
という手順を踏んでいるからです。もう少し細かくいうと、
- 最後の2倍をする前の
というように探索を行います。そして、条件式
では、
STEP1 : 答えの大まかな位置を探す
STEP2 : 徐々に細かく見ていき正しい答えを求める
に分けて具体的な仕組みを見ていきます。
7.2. STEP1:答えの大まかな位置を探す
前節で述べたとおり、

まず、+size)。また、確定した区間の積を保持するための変数を用意しておきます。
そしてここから、
- 自身が左子ノードの時は親ノードが自身とより右のノードを共に含む
- 自身が右子ノードの時は親ノードが自身より左のノードを含む
なので自身が右子ノードの時のみ、そのノードを使用します。
擬似コードにすると次のようになります:
右探索クエリ(大まかな位置を求めるまで) (入力:探索の始点 l, 条件式 f){
l += size //葉に移動
sm = e //fがTrueとなることが確定した区間の積
while (True){
data[l]が右子ノード(もしくは根)になるまで{
親に移動
}
f(op(sm, data[l]))がTrueの場合{
sm = op(sm, data[l]) //確定した区間に加える
l += 1 //1つ右に移動
}
f(op(sm, data[l]))がFalseの場合{
終了(STEP2に続く)
}
f(prod(l, N))=Trueが確定した場合{
終了(max_rightはNで確定)
}
}
}
葉からスタートし各深さ(段)で一回の判定を行うので参照と演算の回数は
7.3. STEP2:徐々に細かく見ていき正しい答えを求める
STEP1での最後の2倍がやりすぎだということがわかっているので1.5倍はどうか?、1.25倍(もしくは1.75倍)はどうか?...という具合に答えの範囲を絞っていきます。別の言い方をすれば、最後の1倍〜2倍の範囲で二分探索をします。

セグメント木の部分木もまた二分木になっているので、この二分探索は、今いるノードから葉ノードまで移動することに対応します。

具体的には、
- 左子ノードへ移動
- 今いるノードまで使って
という操作を繰り返します。上図を例にとれば、
となります。
STEP1と合わせて擬似コードは次のようになります:
右探索クエリ(入力:探索の始点 l, 条件式 f){
l += size //葉に移動
sm = e //fがTrueとなることが確定した区間の積
while (True){
data[l]が右子ノード(もしくは根)になるまで{
親に移動
}
f(op(sm, data[l]))がFalseの場合{
//STEP2
葉ノードになるまで{
l <<= 1 //左子ノードに移動
f(op(sm, data[l]))がTrueの場合{
l += 1 //1つ右に移動
}
}
return l - size //終了
}
sm = op(sm, data[l]) //確定した区間に加える
l += 1 //1つ右に移動
f(prod(l, N))=Trueが確定した場合{
return N //終了(max_rightはNで確定)
}
}
}
STEP2ではあるノードから葉ノードまで移動するだけなのでノードの参照、演算の回数は
8. セグメント木上の二分探索の実装
では先ほどに擬似コードに沿って実装します。引数の条件式fはbool値を返す関数オブジェクトとして与えます。
STEP1において f(op(sm, self._d[l])) = True となった場合です。l が +1される(下記コードの下から3行目)ことを考えるとlが2のべき乗になった場合に
lが2のべき乗であることは「lの'1'の最下位ビットがlと等しい」ことと同値なのでこれで判断します。
例)
8ビットの2の補数表現で考えます。
①
②
def max_right(self, l, f):
assert 0 <= l <= self._n
assert f(self._e())
if l == self._n: return self._n
l += self._size # 葉に移動
sm = self._e() # 確定した区間の積を保持する変数
while True:
while l % 2 == 0: l >>= 1 # 右ノードになるまで
if not f(self._op(sm, self._d[l])):
# STEP2
while l < self._size:
l <<= 1
if f(self._op(sm, self._d[l])):
sm = self._op(sm, self._d[l])
l += 1
return l - self._size
sm = self._op(sm, self._d[l])
l += 1
if l & -l == l: break # f(prod(l, N))=Trueが確定
return self._n
左探索クエリを処理するメソッドmin_leftも同様に実装します。ただし、区間 max_rightと異なることに注意します。
def min_left(self, r, f):
assert 0 <= r <= self._n
assert f(self._e())
if r == 0: return 0
r += self._size
sm = self._e()
while True:
r -= 1
while r > 1 and r % 2: r >>= 1 # 左子ノードになるまで
if not f(self._op(self._d[r], sm)):
# STEP2
while r < self._size:
r = 2 * r + 1 # 右子ノードに移動
if f(self._op(self._d[r], sm)):
sm = self._op(self._d[r], sm)
r -= 1
return r + 1 - self._size
sm = self._op(self._d[r], sm)
if r & -r == r: break
return 0
9. 使用例
ここまで実装したものを使ってAtCoder Library Practice Contest J - Segment Treeを解いてみます。
問題文
長さの整数列 があります。
この数列に対して、個のクエリを処理してください。 番目のクエリでは、まず整数 が与えられます。 その後、 に応じて以下の操作を行ってください。
: 整数 が与えられる。 を で置き換える。
: 整数 が与えられる。 の中での最大値を求める。
: 整数 が与えられる。 を満たす最小の を求める。そのような が存在しない場合、 と答える。
制約(一部抜粋)
まず、セグメント木が使えるか条件を確認します。
集合
1. 閉じているか
2. 結合法則は満たすか
(i)
(ii)
3. 単位元は存在するか
整数
を満たすので単位元となります。が、後の事を考えて集合
以上より
- 集合
- 演算
- 単位元 e :
とすると、
セグメント木が使えることが分かったので、構築します。
def op(x, y):
return max(x, y)
def e():
return -1
n, q = map(int, input().split())
A = list(map(int, input().split()))
seg = SegTree(op, e, n, A)
各クエリを処理するコードを書きます。
t, a, b = map(int, input().split())
a -= 1
if t == 1: # 更新クエリ
seg.set(a, b)
elif t == 2: # 取得クエリ
print(seg.prod(a, b))
else: # 探索クエリ
...
整数
が与えられる。 を満たす最小の を求める。そのような が存在しない場合、 と答える。
でした。これが右探索クエリとなるように条件式
この問題では
なので条件式を
と定義することで右探索クエリに落とし込むことができます。
ここで、
1. 単位元の入力に対して True を返すか
単位元は
です。ここが、単位元を
2.
以上より、定義した条件式
あとはこれをコードにすれば解決です。
t, a, b = map(int, input().split())
a -= 1
if t == 1: # 更新クエリ
seg.set(a, b)
elif t == 2: # 取得クエリ
print(seg.prod(a, b))
else: # 探索クエリ
f = lambda x: x < b
print(seg.max_right(a, f) + 1)
これでこの問題を解くことが出来ました。
提出例
10. セグメント木上の二分探索の補足
10.1. 条件式が単調でない場合
条件式
を満たす
これは、通常の二分探索で解が複数ある場合を考えればわかると思います。
11. おわりに
今回はセグメント木をみてきました。
セグメント木はよく聞くデータ構造で応用の幅も広そうなので使いこなせるようになりたいですね。
説明の間違いやバグ、アドバイス等ありましたらお知らせください。
コメント
いいね以上の気持ちはコメントで