概要
この記事は データ構造とアルゴリズム Advent Calendar 2019 の11日目の記事です。
この記事では、
参考文献
高度合成数に関するlotzさんの素晴らしい記事があります。列挙アルゴリズムも複数紹介されています。
以下で紹介するアルゴリズムのうち、アルゴリズム1についてはlotzさんの記事およびinamoriさんの記事1 記事2 記事3 を参考にしています(本記事では枝刈り関数の変更などでさらなる高速化を達成しています)。
アルゴリズム2はdario2994さんのコード(gist)を読み解いて解説したものです。
高度合成数の定義
自然数で、それ未満のどの自然数よりも約数の個数が多いものを高度合成数といいます。
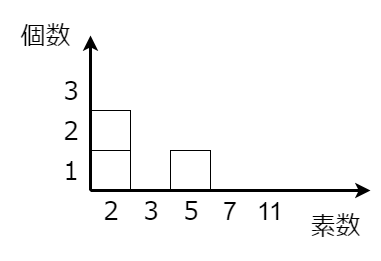
たとえば、以下の表を眺めると、
| 自然数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 約数の個数 | 1 | 2 | 2 | 3 | 2 | 4 | 2 | 4 | 3 | 4 | 2 | 6 |
競技プログラミングでの使われ方の例
たとえば
よって、
解きたい問題
#ナイーブなアルゴリズム
number_of_div[n] += 1」とすると調和級数により
このアルゴリズムではすべての
考察
自然数
が成り立ちます。よって、自然数
なので自然数
たとえば、
さらに、以下のように指数表記を図で表します。タイル表記としておきましょう。
以下の例は
重要な枝刈り
指数表記と約数の個数に対応がついたので、枝刈りができるようになります。
たとえば、
アルゴリズム1: 枝刈り最良優先探索
高度合成数の列挙に有効な、heapq(優先度つきキュー)を使う最良優先探索を以下に示します。
- heapq には、
- 以下を繰り返す。
- heapq から最小元
- heapq から最小元
ここで大事なのは近傍の取り方です。次の性質をみたす近傍がとれるとよいです。
- 近傍の元のほうがもとの元よりも大きい
- すべての元がちょうど1回ずつheapqに入るようにする
- (上の2つの条件でアルゴリズムが正しい解を返すことが保証される)
- 加えてよい枝刈りができるなら、探索空間をグッと小さくすることができます。
ここでは、横積みと縦積みという、2種類の近傍の取り方を考えます。(下の図を参照)
両方とも、
1-1 縦積み
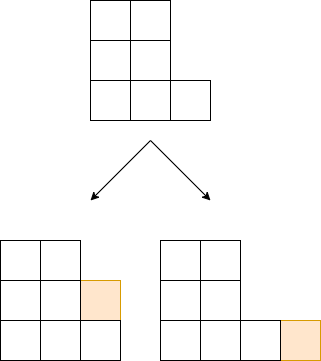
縦積みでの近傍は上のタイル表記のように、右端の列を縦に伸ばす or 横に新しい列を増やす です。
つまり
(逆にこの必要条件がない場合、
このアルゴリズムでは、
なお、縦積みの場合も横積みの場合(次節参照)と同様にさらなる枝刈りができますが、1割程度しか高速化できなかったので詳細は割愛します。
1-2 横積み
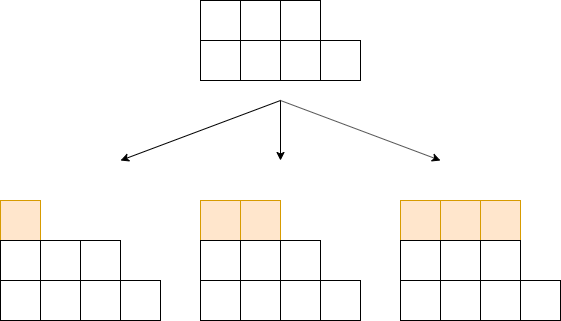
横積みでは、
横積みの場合、近傍は上図のように、上に行を増やします。
つまり、
ただし、
枝刈りをしない場合でも、横積みは縦積みよりも効率的です。
なぜなら、横積みでの近傍になる自然数のほうが縦積みでの近傍になる自然数よりも小さいからです。
今回の問題では縦積みより
さらなる枝刈り
枝刈りをするためには、「元
- とある数に負けた数は絶対に高度合成数にはならない
ここから次の枝刈り定理が導けます。
枝刈り定理
このとき
とくに横積みの場合、そのような数はすべて枝刈りできる(つまりそのような数から近傍をたどっていける任意の数は高度合成数でない)。
枝刈りできる条件
では
がわかります。これなら左辺を前計算できるので、判定も
この枝刈りの効果は劇的で、
def hcn_heapq(N): #N以下の高度合成数を列挙したリストを返す
from heapq import heappop,heappush
from math import log
prime = [2,3,5,7,11,13,17,19,23,29,31,37,41,43,47,53,59,61,67,71,73,79,83,89,97,101,103,107,109,113,127,131,137,139,149,151,157,163,167,173,179,181,191,193,197,199,211,223,227,229,233,239,241,251,257,263]
lim = [[2*int(log(p,q)) for q in prime] for p in prime] #枝刈り用配列
# 初期状態
q = [(2,2,[1])] # (n,nの約数の個数、nの指数表記)を保存する heapq
res = [(1,1,[])]
while q and q[0][0] <= N:
n,val,lst = heappop(q)
if val > res[-1][1]: #条件をみたすなら答に追加
res.append((n,val,lst[:]))
L = len(lst)
e0 = lst[0]
#全部1なら新しい素数で横に伸ばせる
if e0 == 1:
heappush(q,(n*prime[L],val*2,[1]*(L+1)))
#最上段の上を横方向に積む
for i in range(L):
if e0 > lst[i]: break #段差があると、もう伸ばせない
if e0 >= lim[L][i]: break #枝刈り(重要)
n *= prime[i]
if n <= N:
lst[i] += 1
val = val//(e0+1)*(e0+2)
heappush(q,(n,val,lst[:]))
return res
N = 10**100
res = hcn_heapq(N)
print(len(res)) #N以下の高度合成数の個数
print(res[-1]) #N以下の最大の高度合成数
アルゴリズム2: 素因数DP
上述の通り、このアルゴリズムはdario2994さんのコードを読み解いて解説したものです。本アルゴリズムも、
この種の問題に対しては、「
本問題では、集合
重要な性質として、
つまり、
よって
あとは
が証明できるので、対偶をとって
となります。上式右辺の集合は
その他のアルゴリズム
「ちょうど
https://shreevatsa.github.io/site/assets/hcn/hcn-algorithm.pdf
lotzさんの記事で言及されており、Haskellでの実装があります。きちんとした比較はしていませんが、パフォーマンスの面では本記事で紹介したアルゴリズムで十分という感触があります。
まとめ
本記事では高度合成数を高速に列挙する
ちなみに

コメント
いいね以上の気持ちはコメントで