はじめに
Discord上で動く音声アシスタントをリリースした。
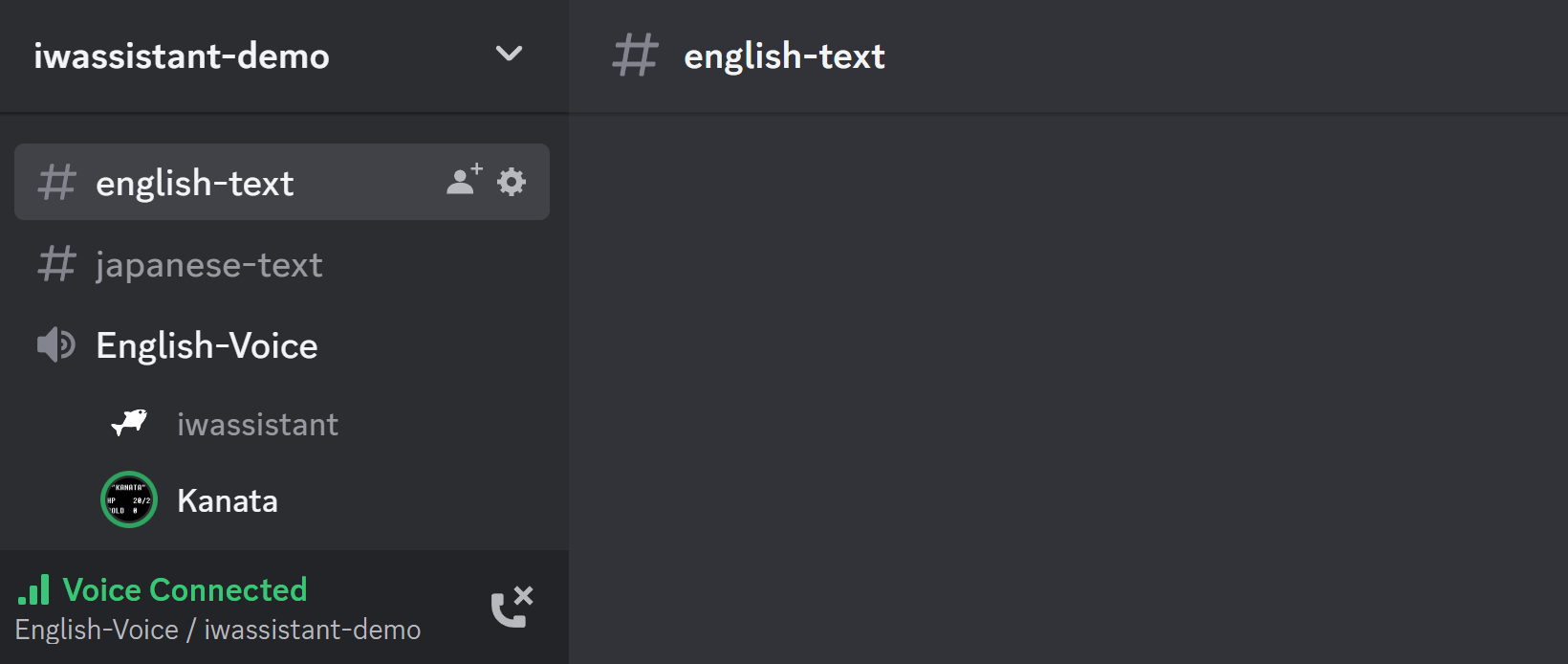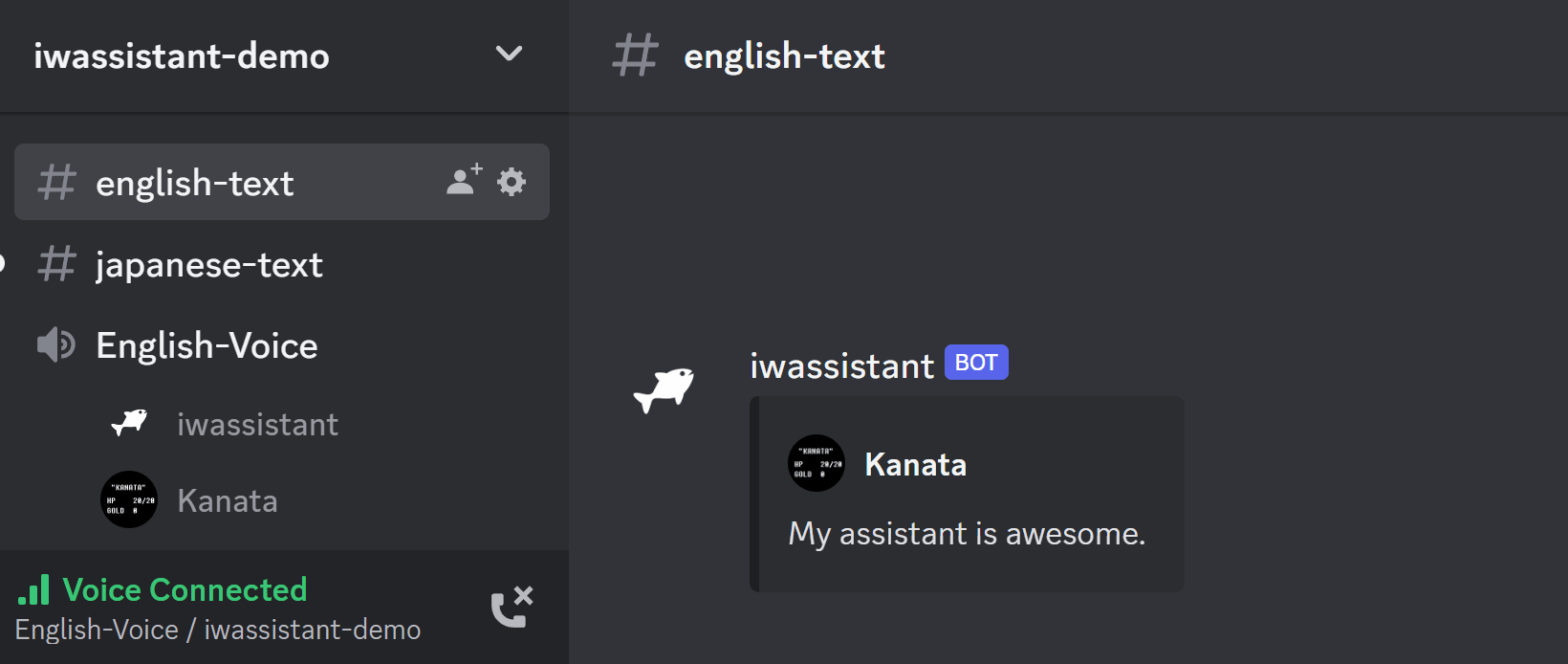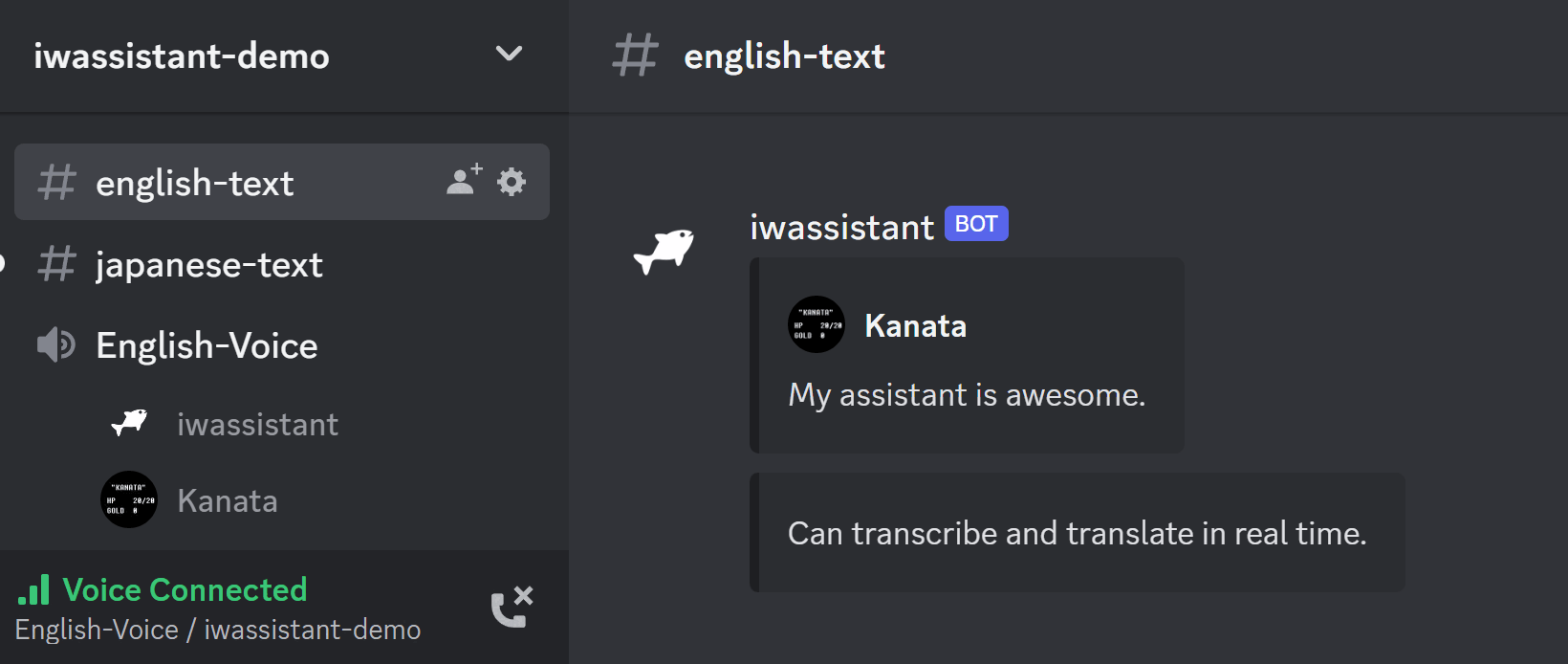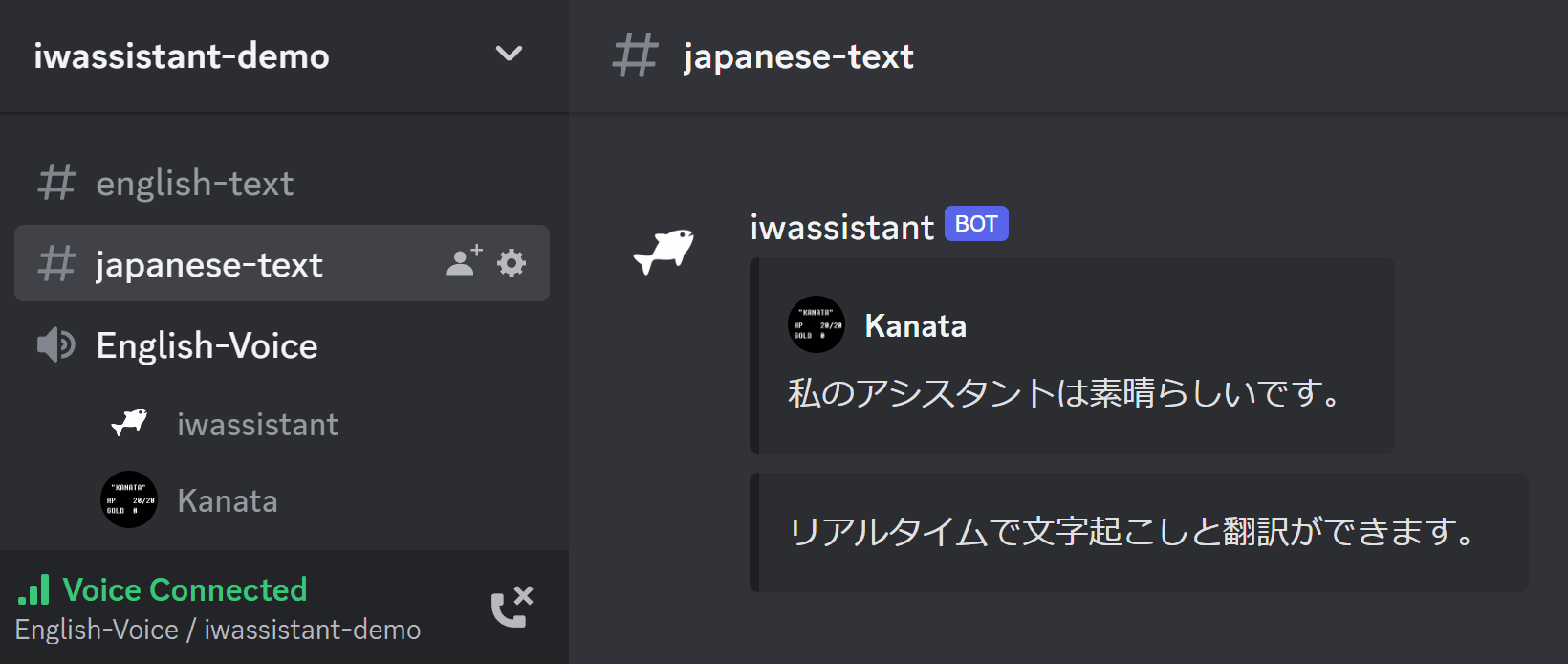
主な機能:
- ボイスチャットでの読み上げ/音声認識/コマンド実行
- リアルタイム議事録/翻訳
- 多言語対応
- 音声認識50言語以上
- 読み上げ50言語以上
- 翻訳100言語以上
- ビルトインコマンドは日英中に対応
- 簡単にコマンドを拡張可能なプラグインシステム
記憶が鮮明なうちに開発メモをまとめておこうと思う。事前学習や技術選定のときに何を考えていたか。設計時や実装時になぜその選択をしたのか。未来の自分が同じ轍を踏まないように。そして、似たようなことを試みている誰かの役に立つように。
モチベーション
前提として、僕はこれまでにもいくつか音声BOTを作っている。ひとつは、VRChatのようなボイスチャットアプリを介して、インターネット越しに動作する音声アシスタント。
これはブラウザ上で動くウェブアプリケーションだ。音声認識を含め、ほぼすべての機能がChrome上で動いているが、そこに起因する不具合がいろいろと生じていて、ブラウザ主体ではなくNode.js主体に改修しなければならないなと思っていた。ブラウザの機能を利用するのは音声認識のみにして、Node.js上で起動したWebSocketサーバーを介してブラウザと通信し、音声データとその認識結果を交換する形にするのだ。しかし相当に大きな改修になることはわかっていたので、ずっと着手できずにいた。
もうひとつは、今回作ったiwassistantの前身となるDiscord読み上げBOT。
これは単なる読み上げBOTなので音声認識機能はないが、テキストチャンネルに音声コマンドっぽいメッセージ(e.g. OK アシスタント、ヘルプを表示して)が投稿されたとき、その文字列をパースして指定のコマンドを実行する機能を持っている。ここに、前述したような仕組み(Chromeの音声認識機能をWebSocket経由で利用する)を組み込めば、Discordのボイスチャットで音声コマンドを実行できるようになるな、と思っていた。しかしもちろんこれも大幅な改修になる。さらに以下のような理由が重なって、なかなか着手できずにいた。
- Discord.jsをv12からv14にアップグレードしたい
- 仕様が大幅に変更されているので対応がつらい
- 特にボイスチャット関連は全面的な書き直し必須
- TypeScriptで書き直したい
- どうせ書き直すならきっちりと基礎から学んだあとに着手したい
うーん、どう考えてもやることが多すぎる。気が重い。モチベーションがわいてこない。このままではいつまでたっても「未着手」という結果しか得られないだろう。それならもう、一緒くたにしてしまえばいいのではないか、と思った。両者を統合してしまうのだ。「Chromeの音声認識機能をWebSocket経由で利用する」という機能を、ローカルの音声デバイスからでも、Discordのボイスチャットからでも利用できるようにすればいい。こう考えただけですごく気が軽くなった。モチベーションがわいてきた。そしてきっと、モチベーションがわいてくる方向が、正しい方向なのだ。少なくとも「未着手」ではなくなるんだから。
プロットのプロット
方向性は決まった。ここからは「どう落とし込むか」を考えていこう。
まずは規模を予想する。前身プロジェクトのコード量から考えれば、今回のコード量はおそらく5000行(LOC)~1万行の範囲だろう。個人開発としてはそこそこの規模だ。この規模なら「プロットのプロット」が必要だと思った。
プロットは長文を書くときに必要なものだ。100字くらいの短文であれば頭に浮かんだ言葉を書き留めるだけでいい。1000字でも文章全体の構造なんてたいして気にしなくていいだろう。しかし1万字となるとどうか。このあたりからプロットが必要になってくる。勢いに任せて書き殴っても破綻する可能性が高いからだ。文章全体がひとかたまりのメッセージとして機能せず、「結局この筆者は何が言いたいの?」となってしまう。それを回避するために、主旨(何が言いたいのか?)を事前にきっちりと言語化し、結部を確定した上で、そこへちゃんと着地できるように骨子を固めておく必要がある。
では、さらに桁を上げて、10万字ならどうだろう? この規模になってくると「自分が何を言いたいのか?」すらわからない状態がスタートラインであることが多い。つまりそれは、着地すべき地点がわからない、ということだ。着地点が見えないならプロットを立てることはできない。だからいつまでたっても着手できない。こうして、モチベーションはあるが何もできずに焦りだけが募っていく、というお決まりの状況が発生する。しかしこれはとても普通のことだろう。人は自分が何を言いたいのか、自分が何を求めているのかさえ、たいていの場合よくわかっていないのだから。少なくとも僕には「自分の考え」なんてぜんぜんわからない。
「考え[thought]」とは最初から自分の中にあるものではない。「考え[think]」たその結果として過去形になったものが「考え[thought]」である。文章を書きながら「考え[think]」て、それを過去形の「考え[thought]」に変えようとする試み、この「試み」をフランス語でエッセーという。エッセーとは完成された文章のことだけを指すのではない。これまで世界のどこにも存在していなかった言葉、自分の中にすら存在していなかった真新しい言葉を世界に顕現させる試みそれ自体なのである。
— プレシオスの鎖を解く旅路
上に引用した拙稿はまさに、自分が何を言いたいのかさえわからなかったから書いた文章だ。言葉にならないものを言葉にするための言葉。そういう試み(エッセー)。そのエッセーによって、自分はこういうことが言いたかったのか、と初めて気づく。身も蓋もない言い方をすれば、レトロスペクティブにつじつまが合わされるのだ。人間の言葉・思考、人間が付与する意味・価値・目的なんて、そういう「つじつま合わせ」のものでしかない。
抽象的な話をしすぎた。本題に戻そう。いま具体的に問題となっているのは、それなりの規模のものを作るにはプロットが必要だが、着地点が見えなければプロットを立てることができず、その着地点はレトロスペクティブにしかわからない、ということだ。始めるためにはまず終わらせなければならないという矛盾。過去と未来のデッドロック。こういうときに必要なのが「プロットを立てるためのプロット」だと思う。着地点が見えない、自分の考えがわからない、自分が何を作りたいのか言語化できないのであれば、それを言語化できるようにすればいい。そのための計画(プロット)を立てるのだ。
今回の場合は、全体の設計が可能になるところまでの計画を立てる。現状では完成形がどうなるか薄ぼんやりとしか見えていない。その輪郭をはっきりさせるにはどうしたらいいか、何が視界を阻んでいるのかを考え、その障害をひとつひとつ取り除いていくのがよさそうだ。
まずいちばんの不安要素は、Chromeの音声認識はUbuntu Server上で使えるのか? ということだ。自分のサーバー上で使えなければ、今回やろうとしていることの意義が根本からなくなってしまう。開発の中盤で「やっぱり無理でした」なんてなるのは致命的すぎるし、ここの検証をいの一番にやるべきだろう。
ついでに、Discordボイスチャットの音声データをストリーム処理できるかどうかも調査しておこう。ローカルストレージにオーディオファイルを作成してから音声認識にかけるのと、ストリームデータをリアルタイムに処理するのでは、仕様・実装ががらりと変わってしまうからだ。ストリーム処理が不可能ということはないにしても、実際にどういう形になるのか、ある程度クリアにしておきたい。
次の不安要素はTypeScriptだ。動的型付けであるJavaScriptに型を提供するものであることは知っているが、どうもそれだけではなさそうだ。TypeScriptをちゃんと理解し、自分の手になじませてからでなければ、全体の設計はできないだろう。逆に言えば、TypeScriptを自分のものにできれば、その時点で全体の構造はだいぶ見えてくるのではないだろうか。
Discord.js v14についても事前にざっと目を通しておいた方がいいかもしれない。新しい機能がいろいろと増えているので、頭の中の索引を更新しておかなければ、仕様検討の際に最適解を導き出せないだろう。たとえば、音声コマンド(ボイスチャットからの入力)とスラッシュコマンド(テキストチャットからの入力)をどのように統合するか、事前にある程度見通せていなければ、プラグインシステム(コマンド拡張)の設計ができないはずだ。
致命的なもの、全体への影響が大きいものはこれくらいだろうか。これらの不安要素を解消したあとにさらにまた不安要素が出てきたら、そのときはそのとき考えればいい。現時点での「プロットのプロット」の精度・粒度はこれくらいでいいだろう。まとめると以下のようになる。
- 技術検証
- Chromeの音声認識をUbuntu Server上で使う
- Discordボイスチャットの音声データをストリーム処理する
- 事前学習
- TypeScript
- Discord.js v14
- 全体設計
- ここが(とりあえずの)着地点
- 設計後に具体的なタスクを洗い出し、完成に向けた計画(プロット)を組む
それではさっそく手を動かしていこう。自然言語での言語化も大事だが、プログラム開発はプログラミング言語で言語化しなければ、何も始まらないから。
技術検証
Chromeの音声認識をUbuntu Server上で使う
まずはChromeの音声認識をシンプルに利用してみる。
<script>
const stt = new webkitSpeechRecognition();
stt.lang = 'ja-JP';
stt.continuous = true;
stt.interimResults = true;
stt.onstart = () => {
console.log('Start');
};
stt.onend = () => {
console.log('End');
stt.start();
};
stt.onresult = (event) => {
let transcript = '';
for (let i = event.resultIndex; i < event.results.length; i++) {
transcript += event.results[i][0].transcript;
}
if (transcript.length === 0) return;
const isFinal = event.results[event.results.length - 1].isFinal;
const message = `Result: ${isFinal ? '*' : '-'} ${transcript}`;
console.log(message);
window.log?.(message); // 後述のPuppeteer用
};
stt.start();
</script>
このHTMLファイルをChromeで開くと音声認識が自動で始まるので、マイクの利用を許可し、適当にしゃべってみる。するとデベロッパーツール(F12で起動)のコンソールに認識結果が出力される。ただ、ローカルのHTMLファイルを直接開くと、音声認識開始のたびにマイクの利用許可を求められてしまう。Node.jsでHTTPサーバーを立てて、そこからHTMLを配信する形にしよう。
const { readFileSync } = require('fs');
const { createServer } = require('http');
const server = createServer((_, response) => {
response.writeHead(200, { 'Content-Type': 'text/html' });
response.end(readFileSync('chrome-stt.html', 'utf8'));
});
server.listen(3000);
このプログラムをNode.jsで起動し、Chromeで http://localhost:3000/ を開く。最初にマイクの利用許可を求められるが、ブラウザをリロードしてもダイアログはもう出ない。
しかしこれをそのままUbuntu Serverに持っていっても、GUIがないのでChromeのデベロッパーツールから音声認識結果を確認することができない。ターミナルにログを出力するために、Puppeteer(ブラウザ自動化ツール)を使うことにした。
npm i puppeteer-core
PuppeteerではNode.js側からブラウザ側にグローバル関数を登録することができるので、これを利用してブラウザ側からNode.js側にログを流し込む。
const { readFileSync } = require('fs');
const { createServer } = require('http');
const { launch } = require('puppeteer-core');
const server = createServer((_, response) => {
response.writeHead(200, { 'Content-Type': 'text/html' });
response.end(readFileSync('chrome-stt.html', 'utf8'));
});
server.once('listening', async () => {
const browser = await launch({
channel: 'chrome',
headless: false,
args: ['--use-fake-ui-for-media-stream'],
});
const page = await browser.newPage();
await page.goto('http://localhost:3000/');
await page.exposeFunction('log', (message) => {
console.log(message);
});
console.log('Ready');
});
server.listen(3000);
とりあえず手元のGUI OS(Windows)で実行し、Chromeが自動で起動したあと、適当にしゃべってみる。Node.jsを起動したターミナルを確認すると、ブラウザから流し込まれたログが出力されている。これでUbuntu Serverでも音声認識結果を確認できるようになった。
Ubuntu Serverでの作業に入る前にもうひとつ確認しておくことがある。仮想オーディオデバイスだ。いまやっている技術検証の最終的な目的は、Discordボイスチャットの音声をChromeで音声認識させることだが、ボイスチャットの音声データを直接録音デバイスに流し込むことはできない。いったん「再生」し、ループバックし、「録音」する必要がある。仮想オーディオデバイスはそれを仮想的に(ハードウェアなしで)実現するものだ。WindowsやmacOSならVB-CABLE Virtual Audio Deviceが、LinuxならPulseAudioがオススメだ。
仮想オーディオデバイスをインストールしたら、対となる再生デバイス/録音デバイスをそれぞれOSのデフォルトデバイスに設定する。たとえばWindowsでVB-CABLE Virtual Audio Deviceを使っているなら以下のようにする。
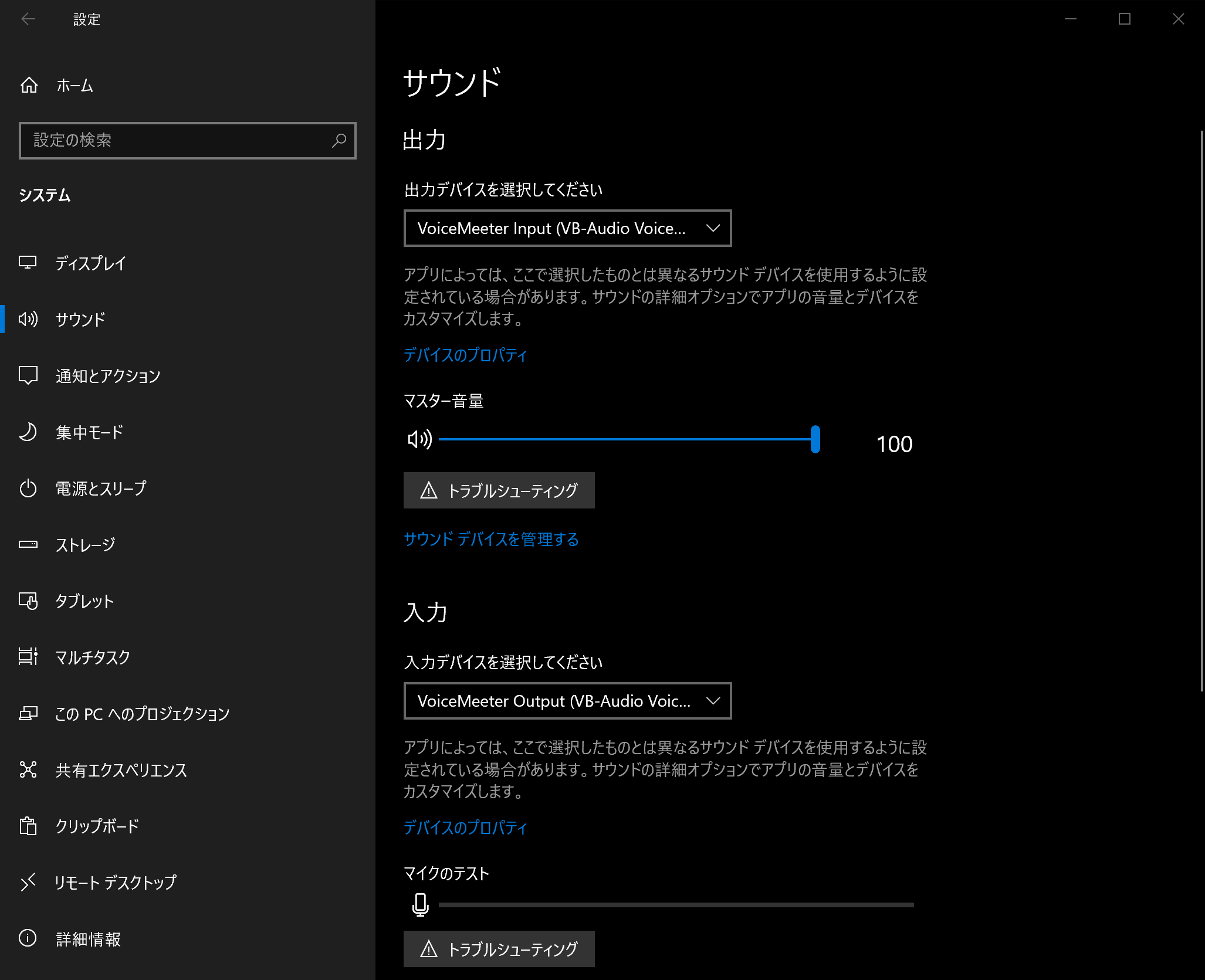
この状態で適当なYouTube動画を再生すると、さっきのプログラムが動画の内容を書き起こしてくれる。このとき起こっていることを簡潔にまとめると以下のようになる。
- YouTube動画を再生する
- 音声が仮想再生デバイスに流し込まれる
- 仮想録音デバイスにループバックする
- Chromeが音声認識する
- 認識結果をNode.js側に渡す
- ログ出力される
ここからは環境をUbuntu Serverに変えて検証していく。ちなみにUbuntuのバージョンは22.04を前提としているので、別のバージョンだと以下のセットアップ手順はうまく動かない可能性がある。
まずは必要なパッケージをインストールする。
# rootになる
sudo -i
# Chromeのインストール準備
curl -fsSL https://dl-ssl.google.com/linux/linux_signing_key.pub | gpg --dearmor -o /etc/apt/trusted.gpg.d/google.gpg
sh -c 'echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list'
# パッケージをインストールする
apt update
apt install -y xvfb pulseaudio google-chrome-stable
# ユーザーに戻る
exit
次に、仮想オーディオデバイスを設定する。
# 設定ディレクトリを作成
mkdir -p ~/.config/pulse/
# デフォルト設定をコピー
cp /etc/pulse/default.pa ~/.config/pulse/
# 仮想オーディオデバイス設定を追記
cat <<EOF >> ~/.config/pulse/default.pa
load-module module-null-sink sink_name="v-input-1" sink_properties=device.description="v-input-1"
load-module module-remap-source master="v-input-1.monitor" source_name="v-output-1" source_properties=device.description="v-output-1"
set-default-sink v-input-1
set-default-source v-output-1
EOF
# PulseAudioを再起動する
systemctl --user restart pulseaudio
# v-input-1が登録されていることを確認
pacmd list-sinks
# v-output-1が登録されていることを確認
pacmd list-sources
これで準備は完了した。さっきのプログラムを起動してみよう。
node chrome-stt.js
しかし普通に起動するとエラーになる。なぜか? Chromeの音声認識はヘッドフルモード(ヘッドレスの逆)でないと動作しないが、ヘッドフルモードはGUI前提なのだ。だからXvfb(仮想ディスプレイサーバー)を介して起動する。
xvfb-run node chrome-stt.js
今度はうまくいった。これを起動した状態で、日本語のスピーチ音声を再生してみよう。
# 音声資源コンソーシアムからサンプル音声をダウンロード
wget https://research.nii.ac.jp/src/sample/JNAS/NM001001.wav
# ダウンロードした音声ファイルを再生
paplay NM001001.wav
Node.jsを起動しているターミナルに以下のように出力された。成功だ。
Ready
Result: - まだ
Result: - まだ正
Result: - まだ正式
Result: - まだ正式に
Result: - まだ正式に決
Result: - まだ正式に決まった
Result: - まだ正式に決まったわけ
Result: - まだ正式に決まったわけで
Result: - まだ正式に決まったわけでは
Result: - まだ正式に決まったわけではない
Result: - まだ正式に決まったわけではないの
Result: - まだ正式に決まったわけではないので
Result: * まだ正式に決まったわけではないので
これでChrome音声認識の技術検証が完了した。当然ながら最終的な形はもっと複雑になるが、この段階で必要だったのは「最悪の場合でも最低限の機能は実現できると確認すること」だったので、技術検証としてはこれで十分だと判断した。
Discordの音声データをストリーム処理する
次はDiscordの検証をしていこう。さっきの検証では音声ファイルを事前に用意して、それを paplay コマンドで再生したが、この音声再生の部分をDiscordボイスチャットからのリアルタイム入力に置き換えられるか? という検証だ。こちらの検証はそう難しくなかった。Discord.js公式がいい感じのサンプルリポジトリを用意してくれていたからだ。
この中にあるRecorder Botは、Discordボイスチャットの音声データをストリーム処理し、oggファイルとして逐次保存していくというものだ。これを参考にすればすぐできそうだと思った。
まずは必要なパッケージをインストールする。
# 失敗する場合はspeakerパッケージのビルドに必要なものが不足している可能性が高い
# Windows: Node.jsインストール時にTools for Native Modulesにチェックを入れておく
# Ubuntu: apt install build-essential libasound2-dev
npm i discord.js @discordjs/voice @discordjs/opus ffmpeg-static sodium-native speaker
とりあえず音声処理は後回しにして、起動時に特定のボイスチャンネルに入室するだけのシンプルなプログラムを書いてみる。
const { Client, GatewayIntentBits } = require('discord.js');
const { joinVoiceChannel } = require('@discordjs/voice');
// 各IDはボイチャURL https://discord.com/channels/1111/2222 でわかる
const config = {
token: 'xxxx',
guildId: '1111',
channelId: '2222',
};
const client = new Client({
intents: [GatewayIntentBits.Guilds, GatewayIntentBits.GuildVoiceStates],
});
client.once('ready', (client) => {
console.log('Client ready');
const guild = client.guilds.cache.get(config.guildId);
if (!guild) return;
const connection = joinVoiceChannel({
guildId: config.guildId,
channelId: config.channelId,
adapterCreator: guild.voiceAdapterCreator,
});
connection.once('ready', () => {
console.log('Connection ready');
});
});
client.login(config.token);
実行するとちゃんと入室できている。これを改造して、ボイスチャットの音声データを再生デバイスに流し込むようにしてみよう。
const { Client, GatewayIntentBits } = require('discord.js');
const { joinVoiceChannel, EndBehaviorType } = require('@discordjs/voice');
const { OpusEncoder } = require('@discordjs/opus');
const Speaker = require('speaker');
const config = {
token: 'xxxx',
guildId: '1111',
channelId: '2222',
};
const opus = new OpusEncoder(48_000, 2);
const speaker = new Speaker({ channels: 2, bitDepth: 16, sampleRate: 48_000 });
const client = new Client({
intents: [GatewayIntentBits.Guilds, GatewayIntentBits.GuildVoiceStates],
});
client.once('ready', (client) => {
console.log('Client ready');
const guild = client.guilds.cache.get(config.guildId);
if (!guild) return;
const connection = joinVoiceChannel({
guildId: config.guildId,
channelId: config.channelId,
adapterCreator: guild.voiceAdapterCreator,
});
connection.once('ready', () => {
console.log('Connection ready');
connection.receiver.speaking.once('start', (userId) => {
console.log(`Subscribe: ${userId}`);
const subscription = connection.receiver.subscribe(userId, { end: { behavior: EndBehaviorType.Manual } });
subscription.on('data', (chunk) => {
console.log(`Chunk: ${chunk.length}`);
speaker.write(opus.decode(chunk));
});
});
});
});
client.login(config.token);
ボイスチャンネル内で誰かがしゃべり始めたらその配信をサブスクライブし、以降のチャンクを逐次デコードしながら再生デバイスに流し込むようにした。このプログラムを起動した状態でボイスチャンネル内でしゃべってみると、自分の声がそのままエコーとなって再生される。成功だ。
さっき検証した音声認識プログラムと同時に動かしてみると、自分のしゃべった内容が音声認識にかけられていることも確認できる。このプログラムでは最初にしゃべり始めた人しか音声認識にかけられないし、リアルタイムに流し込んでいるのでノイズが混じったりすることもあるが、いまの段階では十分だろう。
これで技術的な不安要素はすべて解消した。
事前学習
TypeScriptを理解する
'90年代、JavaScriptは「ウェブページをちょっとインタラクティブにするためのもの」くらいでしかなかった。ページ内の文言をアクセス時刻によって変化させる、とか、マウスカーソルに謎のアイコンを追尾させる、とか、その程度の使われ方しかしていなかった。'00年代半ば、GmailとGoogle Mapsの登場で「あれ? これ意外と使えるな?」と(おそらく)誰もが思った。prototype.jsやjQueryが登場したことで、ブラウザ間の差異を気にせず、SPAっぽいものを簡単に作れるようになった。しかし大規模な開発をするにはまだまだつらい部分が多かった。JavaScriptという言語に対する市場の要求と、言語仕様のズレが、しだいに大きくなっていった。言語自体の進化はES2015でようやく果たされるが、その手前の段階、'10年代前半に、JavaScript言語を生成するための言語、altJS(e.g. CoffeeScript)が流行したのは必然だった。
ここまでの流れは7年前に投稿した記事にも書いたことだ。時が流れて2023年現在、いまはもうaltJSという言葉はほとんど使われていない。altJSが廃れたから、ではない。TypeScriptの興隆によって、altJSという「カテゴリ」がもはや不要になったからだ。
TypeScriptの興隆はずっと肌で感じていて、何年か前から「そろそろ勉強しないとなー」と思ってはいたものの、仕事ではGo言語ばかり書いていたので、なかなか手を付けられずにいた。今回のプロジェクトはスクラッチ開発だし、いまの状況でTypeScriptを選択しない理由はないだろう。ようやく重い腰を上げる理由ができた感じだ。
プログラミングに限らず、新しい物事を学ぶとき僕はいつも以下のようなことを心がけている。
- 全体を網羅したわかりやすい解説(サイトor本)があれば2つ以上を比較参照する
- 筆者の考え方が偏っている場合があるので
- 複数を照らし合わせればその分野のデファクトスタンダードな手法・考え方がなんとなく見えてくる
- わからないところはわからないままにしておく
- 「それってつまりこういうことでしょ?」と自分の言葉に置き換えて(既存の世界観に当てはめて)理解しても、たいていどこか間違っているので、結果的に遠回りになることが多い
- なかなか咀嚼できなくても自分の中に「腹落ち」させるまでは口の中に含んだままにしておく(その心地悪さに耐える)
今回は以下のサイトで勉強した。
「サバイバルTypeScript」はプログラミング初級者向け、「Deep Dive」の方は、昔のJavaScriptは知っているが最近のJavaScriptの書き方は知らない浦島太郎向け、だと思った。既知の部分は斜め読みしつつ、いちおう全ページに目を通した。この2つのサイトと公式ドキュメントチラ見でなんとなく全体像はつかめた。頭の中に白地図ができた。しかしそれは白地図なので、肝心なところは空白のままだ。そして、その空白部分こそが、TypeScriptの核心部分であるような気がした。
いちばん腑に落ちなかったのはユニオン型だ。
// 文字列も数値も代入できる型
type StringOrNumber = string | number;
const str: StringOrNumber = 'var'; // ✅
const num: StringOrNumber = 1; // ✅
const bool: StringOrNumber = true; // ❌
これができることで何が嬉しいのか、サンプルコードを読んでもいまいちピンと来ない。腹落ちしない。
さらにはこういう定義もできる。
// 'success' か 'failure' の文字列しか代入できない型
type Status = 'success' | 'failure';
const success: Status = 'success'; // ✅
const failure: Status = 'failure'; // ✅
const forbidden: Status = 'forbidden'; // ❌
// 1 か 2 の数値しか代入できない型
type OneOrTwo = 1 | 2;
const one: OneOrTwo = 1; // ✅
const two: OneOrTwo = 2; // ✅
const three: OneOrTwo = 3; // ❌
なんてことないコードのように見えるが、僕は最初、この仕様に強烈な違和感を覚えた。従来の静的型付け言語に慣れている人は、おそらく誰もがここで違和感を覚えるのではないだろうか。その違和感の正体は、実行時のメモリがどうなっているかまでコンパイラの関心対象になっていること、だろう。
コンパイラが機械語を吐く静的型付け言語を書いている人は、型の定義が物理的なメモリ領域に強烈に結びついているようなメンタルモデルを形成している人が多いのではないだろうか。少なくとも僕はそうだ。多くのコンパイラは実行時にメモリのビットがどうなっているかなんて関知しない。たとえば、符号なし整数型(uint)と符号付き整数型(int)は、同じ量のメモリを使い、同じ量の数値範囲を表現できるが、符号付きが表現する範囲は負の方向にズレる。8ビット整数なら、符号なし0~255、符号付き-128~127、といった具合に。メモリのビットの並びがまったく同じであったとしても、型が違えばまったく違う数値として扱われる。型は「メモリのここからここまでのビットの並びを、こういうふうに扱います」という約束事だ。実行時にそれがどういう並び方をしているかなんて、コンパイラがコンパイル時に気にすることはない。
TypeScriptの「型」は、このメンタルモデルから大きく外れてしまう。たしかにTypeScriptは動的型付け言語であるJavaScriptのコードを生成するためのものでしかなく、物理的なメモリからは遠く離れている。だからこういうのもありなんだろう。それはわかっている。いやしかし。うーん……。わかるけどわからない。腑に落ちない。もしかしたら、これまでまったく静的型付け言語をさわったことがない人の方が、すんなりとTypeScriptを習得できるのではないだろうか。それくらいこの違和感は強烈だ。こういうときこそ「アンラーニング」しなければならないんだろう。
そうして違和感を抱えながらも、今回のプロジェクトの骨組みになりそうな短いコードを書いてみたり、他人のコードを読んだりしていくうちに、少しずつ咀嚼できてきた。なるほど、これはものすごくプラグマティック(実用的、実際的)な言語なのだな、と思えてきた。
たとえば、TypeScriptでは複数のオブジェクトに同じ型のプロパティ(メソッド含む)があれば、インターフェイスがあるかのように振る舞う。以下のようなコードは、TypeScriptを知らなくても、他の言語をある程度やっている人なら難なく読めるだろう。 Assistant.player は Playable インターフェイスを実装していることが保証されているので、 play メソッドが使える。
interface Playable {
play(): boolean;
}
class SimplePlayer implements Playable {
play(): boolean {
return true;
}
}
class StoppablePlayer implements Playable {
play(): boolean {
return true;
}
stop(): boolean {
return true;
}
}
class Assistant {
player: Playable;
constructor(player: Playable) {
this.player = player;
}
speak(): boolean {
return this.player.play();
}
}
TypeScriptではインターフェイスなしでも同じように書ける。
class SimplePlayer {
play(): boolean {
return true;
}
}
class StoppablePlayer {
play(): boolean {
return true;
}
stop(): boolean {
return true;
}
}
class Assistant {
player: SimplePlayer | StoppablePlayer;
constructor(player: SimplePlayer | StoppablePlayer) {
this.player = player;
}
speak(): boolean {
return this.player.play();
}
}
Assistant.player は SimplePlayer と StoppablePlayer のユニオン型なので、両者のうちどちらかが代入されることは保証されているが、どちらが代入されるかはわからない。そして、どちらのクラスも implements なしの完全に独立したクラスだ。なのに this.player. までタイプしたとき play メソッドがサジェストされる。どちらもこのメソッドを持っているからだ。インターフェイスを実装しているわけでもないのに、インターフェイスを実装しているかのように振る舞っている。もちろんインターフェイスを使う方が行儀はいいが、「そこまでするレベルじゃないんだよなあ」みたいな場面は多々ある。そういうときにすごく便利そうだと思った。厳格にすることもできるが、ルーズにすることもできる。とてもプラグマティックだ。
そしてユニオン型は、絞り込み(Narrowing)と組み合わせることで、その本領を発揮する。上のコードに少し追加してみよう。
const assistant = new Assistant(new StoppablePlayer());
assistant.player.play(); // ✅
assistant.player.stop(); // ❌
if (assistant.player instanceof StoppablePlayer) {
assistant.player.stop(); // ✅
}
Assistant のコンストラクタに StoppablePlayer のインスタンスを渡していることは、コードを書いているプログラマの視点からは明白だが、TypeScriptコンパイラの視点では「どちらが入っているかはわからない状態」なので、そのままでは stop メソッドが使えない。しかし、if文で StoppablePlayer のインスタンスであることが確定した「後」であれば使える。VSCode上でも assistant.player. までタイプしたときに、 play と stop の2つのメソッドがサジェストされる。各行で player プロパティをマウスオーバーしてみると、if文までは SimplePlayer と StoppablePlayer のユニオン型だが、if文の後では StoppablePlayer に確定していることがわかる。
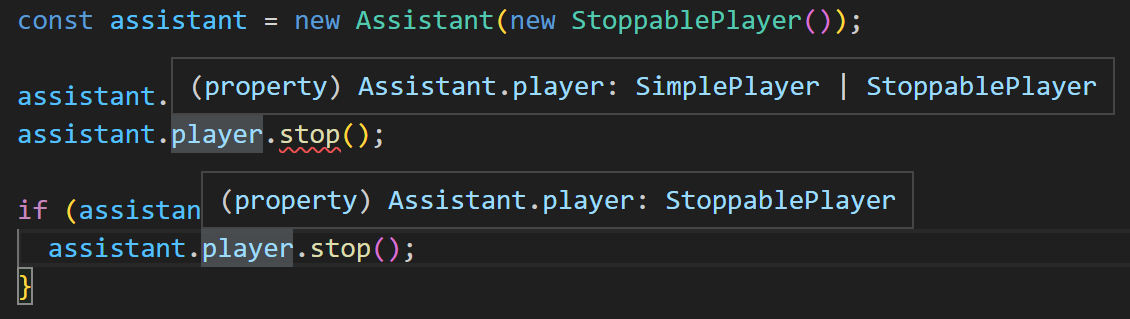
おおこれはすごい、と思った。型のレイヤーとランタイムのレイヤー(実行時の処理)が、見事に組み合わさって、とてつもなく開発者フレンドリーになっている。これまでも、GoLand(Go言語のIDE)が「ここnilになりえるけどチェックしなくて大丈夫?」みたいな警告を出してくれたときに「ありがてえー」とか思ったりしたが、それの超すごい版という感じだ。あらゆる型、あらゆるシチュエーションで使えるんだから。
よしよしだいぶわかってきたぞ、とか喜んだのも束の間、もうひとつ大きな壁にぶつかった。「型のレイヤーでのプログラミング」だ。
定義した型を基にコードを書くだけならTypeScriptは他の静的型付け言語とさして変わらない。この言語のもうひとつの本領は、その「型の定義方法」の多彩さにある。ジェネリクスは他の言語にもあるが、これを変数として使い、Conditional Typesを条件分岐に、Mapped Typesを繰り返し処理に使えば、「型のレイヤーでのプログラミング」が可能になる。そして、TypeScriptを使い倒そうと思ったら、ここは避けて通れない道なのだ。ひとつひとつ追っていこう。
今回のプロジェクトでもプラグインシステムを組み込む予定なので、ジェネリクスを使ってそれっぽいコードを書いてみる。
type Plugin<T extends object> = {
name: string;
config: T;
};
const musicPlugin: Plugin<{ volume: number }> = {
name: 'music',
config: {
volume: 50,
},
};
ここではジェネリクスを使ってプラグイン作成者が自分のプラグインの設定値を型定義できるようにしている。設定値がないプラグインの場合は空オブジェクトとして定義すればいいのだが、少し格好が悪い。そもそも config プロパティが不要だからだ。そんなときにConditional Typesを使う。
type Plugin<T extends object | undefined> = {
name: string;
} & (T extends object
? {
config: T;
}
: {});
const musicPlugin: Plugin<{ volume: number }> = {
name: 'music',
config: {
volume: 50,
},
};
const pingPlugin: Plugin<undefined> = {
name: 'ping',
};
Conditional Typesという「型のレイヤーの条件分岐」を利用し、引数(ジェネリクス)によって型定義を変えることに成功した。試しに pingPlugin の方に config プロパティを追加してみると、Type '{ name: string; config: {}; }' is not assignable to type '{ name: string; }'. というエラーになる。いい感じだ。
今度はコマンドを追加してみよう。
type Plugin<T extends object | undefined, U extends string> = {
name: string;
command: {
[P in U]: string;
};
} & (T extends object
? {
config: T;
}
: {});
const musicPlugin: Plugin<{ volume: number }, 'play' | 'stop'> = {
name: 'music',
command: {
play: 'play music',
stop: 'stop music',
},
config: {
volume: 50,
},
};
Plugin 型の第二引数(ジェネリクス)のユニオン型をMapped Typesで繰り返し処理し、 command プロパティにすべてのコマンドを定義しなければならないようにした。簡単のため今回は文字列のユニオン型にしたが、第二引数をオブジェクトにしてそのキーをコマンド名にしたいならKeyof Type Operatorを使えばいいし、やりようはいくらでもある。
以上が、ジェネリクス(変数)とConditional Types(条件分岐)とMapped Types(繰り返し)を使った「型のレイヤーのプログラミング」のあらましだ。
なんてことないように見えるが、これがまた意味不明に難しい。普段プログラミングで使っている脳みその部分とは明らかに違う部分を使っている感じがするのだ。メタ領域でずっと空中戦をやっているような感覚。地に足がつかない感覚。型のエラーはエディタに即時反映されるのに、そこで起こっている状況を頭の中に展開できない。この難しさは何に起因しているのだろう、と考えていて、ふと気づいた。型のレイヤーには時間軸がないのだ、と。
通常のプログラミングには時間軸がある。コードは上から下へ、過去から未来に向かって進む。それは開発者の現実感覚と合致している。非同期プログラミングが難しいのは、「いま現在(GitでたとえるならHEAD)」があちこちに飛ぶからだ。これを開発者の現実感覚に合致させるために、async/awaitのような構文が生まれたのだと思う。しかしここでも時間軸それ自体はある。スレッドだろうとイベントループだろうと、CPUとメモリが現実世界にある限り、プログラムは過去から未来に向かって進む。その途中のどの時点を切り出しても、変数の中身は一意に確定している。変数aの中身が0である可能性もあるし1である可能性もある、なんてことは量子コンピュータでも使わない限りありえない。「型のレイヤーでのプログラミング」は、この前提が通じない。時間軸がないからだ。そして時間が存在しない世界では、複数の可能性が並列に存在できる。実際のところは評価の順序等あるかもしれないが、そう捉えた方がしっくりくるのだ。
たとえばさっきのコードの [P in U] の部分。引数(ジェネリクス)の U extends string で文字列型であることが確定していることはわかるが、文字列型に対して in とはどういうことだろう? 僕はこう考えた。ここでの U 、ひいては string 型とは「あらゆる文字列である可能性」の型であり、量子的(?)存在なのだ、と。だからこの引数(ジェネリクス)には 'play' | 'stop' のような文字列の可能性(ユニオン型)を渡すことができる。この引数(ジェネリクス)によって、「あらゆる文字列である可能性」から「playかstopのどちらかである可能性」に可能性が絞り込まれる。 in 演算子はそこからそれぞれの可能性を取り出しているのだ。数値も真偽値も、ユーザー定義のクラスでも、同じことが言える。ユニオン型を「可能性が多重化された存在」だと捉えたとき、ようやくエディタ内で起こっていることと自分の中のメンタルモデルを合致させることができた。こうしてようやくTypeScriptを「腹落ち」させることができた。
Discord.jsの新機能
Discord.jsの最新バージョンはv14だ。v12からの最大の変化は、ボイスチャンネル関連機能のパッケージ切り出しだろう。以前は discord.js パッケージのみインストールでよかったのが、ボイスチャンネル関連機能を使う場合は @discordjs/voice を別途インストールしなければならなくなった。これに関連するプルリクエストに👎が付いていたりするのだが、気持ちはわからなくもない。変更がドラスティックすぎるからだ。しかしDiscord.js側の事情もわかる。
まず、プロジェクト全体の規模が肥大化していたこと。各機能を別パッケージに切り出さなければ開発が追いつかなくなっていたのだろう。パッケージ切り出しは当初、マルチレポで進めていたようだが、いまはモノレポになっている。たとえば、discordjs/voiceはすでにアーカイブ化されていて、最新のコードはdiscordjs/discord.js/packages/voiceにある。
そもそもDiscord.jsがなぜそんなにドラスティックな変更をしなければならないかというと、大元のDiscordがAPIにガンガン変更をかけているからだ。そしてこれにも理由がある。Discordの規模と使われ方が、ここ数年でガラリと変わったからだ。数年前は数千人のメンバーがいれば「大きなコミュニティーだなー」と感じていたが、最近はもう数千人なんて驚きもしない。Fortnite公式Discordなんて100万人超。もはや「チャットルーム」の域をはるかに超えている。50人に満たないコミュニティーでゲームしながら雑談する、みたいな使われ方も依然多いと思うが、開発側は当然、数万人・数十万人レベルの超巨大なコミュニティーを前提しなければならない。数百人・数千人のコミュニティーを前提していたころとは、仕様もアーキテクチャもドラスティックに変化して当然だ。直近でも、ユーザー名の抜本的な変更がアナウンスされたばかりなので、Discordユーザーであれば誰でもこの変化は感じ取れるだろう。
前置きが長くなったが、「この変化は誰にもどうしようもないものなのだ」という納得感を得られたので、さっそくDiscord.jsの変更点を追っていこう。
ボイスチャンネル関連はガイドを読めばだいたい把握できた。以前は VoiceChannel.join で入室していたが、別パッケージ化されたことでクラスのメソッドではなくなり、 joinVoiceChannel という単体の関数になっている。さらに、音声の再生は VoiceConnection.play で再生していたのが、 createAudioPlayer 関数でオーディオプレイヤーを作成し、それを VoiceConnection.subscribe でサブスクライブする形になっている。より汎用的に、より多様なシチュエーションに対応できるようになった感じだ。
おもしろいなと思ったのは entersState 関数だ。これは await entersState(connection, VoiceConnectionStatus.Ready, 5000) のように使う。この例では、コネクションが5秒以内にReady状態になったら次の行へ、ならなかったら例外を投げる。async/awaitが構文として導入されたことで、プログラマはようやく非同期処理におけるコールバック地獄から開放されたが、まだ非同期処理でしんどいシチュエーションはある。状態遷移の管理だ。状態がaになったときにこうする、bになったときにこうする、と独立しているなら特に問題ない。aからbになったとき、bからcになったとき、aからcになったとき、この状況ではn秒待って、cにならなければエラーに……とか考えていると、頭がこんがらがってくる。 entersState はこれをすべて解決するようなものではないが、使えそうなシチュエーションがあれば使ってみたいな、と思えるパターンだ。実際、ガイドの中のHandling disconnectsに出てくるコードは、この関数がなければかなり煩雑なコードになるだろう。
余談だが、僕は以前、Discord.jsのバグを踏み抜いてしまい、GitHubにissueを立てたことがある。BOTが音声を再生できなくなるというバグなのだが、ボイスチャンネルに長期間(数日~数週間)接続しっぱなしでなければ発生しない(つまりDiscordボイチャ廃人でないと遭遇しない)のと、debugイベントをlistenしていなければエラーを拾えないというのが重なって、誰も気づいていなかったのだと思う。このときの調査で「コネクションの状態管理つらいなー」とは思っていたので、上記のHandling disconnectsセクションからにじみ出る「つらさ」がわかる。状態遷移の管理、ほんまつらい。
もうひとつの大きな変更点は、スラッシュコマンドだ。以前からDiscord公式のスラッシュコマンドはあったが(e.g. /tableflip)、その機能がBOT開発者に対しても開放されたのだ。こちらに関してもガイドを読めばだいたい把握できた。ただ、このガイドでは、コマンドごとに .js ファイルを用意するような、一般的なプロジェクトを想定している。今回のプロジェクトではプラグインシステムを介してコマンド登録する予定なので、そのあたりは読み替える必要があった。簡潔に言えば、以下のような流れでコマンドが使えるようになるようだ。
- Discord.jsの
SlashCommandBuilderでコマンドを作成- 名前や説明を設定するだけでOK
- コマンド引数の設定等、複雑なこともビルダーを使えば簡単にできる
- このビルダーがDiscord APIに投げるJSONを生成する
- Discordにコマンドを登録
- ギルドごとのコマンドは即時反映される
- グローバルなコマンドは反映までに時間がかかる
- ユーザーがコマンドを使用したとき
interactionCreateイベントが発生するので、そのコンテキストにしたがって、何らかの処理を行う
その他の部分もざっと目を通したが、全体設計に影響しそうな大きな変更はなさそうだった。事前学習はこのくらいで十分だろう。
全体設計
ようやくプロットのプロットで設定した着地点にたどりついた。想定通り、最終的な完成形は見え始めているが、どうするか迷っている部分もある。プラグインシステムだ。
前身となるプロジェクトでは、読み上げエンジンやデータストアをプラグインで切り替えられるようにしていた。データストアの場合は、ローカルにJSONで保存するか、Firestoreに保存するか、もしくは自分でプラグインを書いて独自のデータストアを使うかを選べる。しかしこの仕様には違和感があった。しばらく考えて、これはプラグインという枠組みの中でやることではないな、という結論に達した。プラグインはコマンドの拡張や、機能の追加をする役割に限定して、プラグインシステムと同等の枠組み、エンジン(を切り替えられる)システムを作ることにした。エンジンの種類は、データストア、読み上げ、音声認識、翻訳の4種類があればいいだろう。各種エンジンはインターフェイスの実装を必須とすれば、型安全にエンジンの切り替えが可能だ。これでかなりすっきりした。
迷いが晴れたところで全体像を掘り下げていってみよう。まずは最上位にアプリケーションクラス。アプリケーションは、プラグインやエンジンの準備をしたあと、Discordクライアントを起動し、それぞれのギルド(Discordサーバーの方が一般的だが開発者向けにはギルドという名称が使われるので本稿もそれにしたがう)に対して、アシスタントを作成する。アシスタントはアプリケーションから渡されたプラグインにしたがって、各種コマンド・イベントを処理する。これらのアシスタントとは別にアプリケーション直下にはホームアシスタントがいる。ホームアシスタントもまたアプリケーションから渡されたプラグインにしたがって、ホーム用の各種コマンド・イベントを処理する。ギルドアシスタントとの違いは、Discordボイスチャットで動作するか、実行環境のローカルで動作するかだ。ホームアシスタントは後者。つまり一般的なスマートスピーカーとして振る舞う。ざっくりこんな感じだろうか。
今度はこれを具体的なプロジェクト構成に落とし込む。
- __tests__/: テストコード
- assets/: アセットファイル(コマンド実行時のエフェクト音等)
- dist/: ビルド後の生成ファイル
- docs/: ドキュメント
- examples/: ユーザープラグイン・ユーザーエンジンのサンプル
- scripts/: タスク用スクリプト(ビルドせず直接実行する)
- secrets/: アカウントファイル等
- src/: ソースファイル
- app/
- builtin/
- engines/: ビルトインエンジン
- store-*.ts
- stt-*.ts
- translator-*.ts
- tts-*.ts
- plugins/: ビルトインプラグイン
- guild-*.ts
- home-*.ts
- engines/: ビルトインエンジン
- classes/: プロジェクト全体で使うクラス
- App.ts
- GuildAssistant.ts
- HomeAssistant.ts
- ...
consts/: プロジェクト全体で使う定数(実際には不要だった)- enums/: プロジェクト全体で使うEnum
- types/: プロジェクト全体で使う型
- utils/: プロジェクト全体で使う関数
- index.ts: エントリポイント
- builtin/
- env/: 設定ファイル
- default.ts
- user/:
- engines/: ユーザーエンジン
- iwassistant-engine-store-*/
- iwassistant-engine-stt-*/
- iwassistant-engine-translator-*/
- iwassistant-engine-tts-*/
- plugins/: ユーザープラグイン
- iwassistant-plugin-guild-*/
- iwassistant-plugin-home-*/
- engines/: ユーザーエンジン
- app/
- tmp/: 一時ファイル
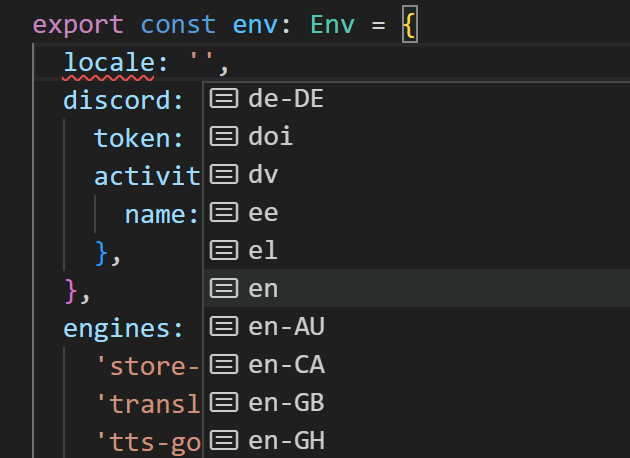
一般的な構成だと .env みたいな環境変数ファイルは最上位にあることが多いが、今回のプロジェクトでは設定が複雑な構造になるし、 TypeScriptの型チェックとVSCode上でのサジェストを利用したい(たとえば以下のようにロケールリストが出てほしい)ので、設定ファイルのパスは src/env/*.ts にした。設定値を変更したら毎回ビルドが必要になるのがネックだが、開発中はビルドなしで起動できるようにするつもりだし、それほど問題にはならないだろう。一般的な意味の「OS環境変数を上書きするもの」ではなく「プログラム設定」なので、名前は config の方がしっくりくるような気もするが、そちらはエンジンとプラグインの「設定」に使いたかったので、切り分けのために env にした。初見の人を混乱させてしまう可能性はあるが、ここはコーディング時のわかりやすさを優先しよう。
プロジェクトの骨組みを作ったら一気にそれっぽくなった。最終的な着地点が見えたので、今度こそ「プロット」を立てよう。
- 環境構築
- エンジンシステム構築
- プラグインシステム構築
- 多言語対応
- Discord対応
- アシスタント実装
- ビルトインエンジン実装
- ビルトインプラグイン実装
- ドキュメンテーション
- リリース
エンジンシステムやプラグインシステムはとりあえずモックが動くようにしておく。それを利用する形で多言語対応やDiscord対応をしつつ、アシスタント機能を実装する。この時点で本体部分はほぼ完成だ。あとはそれを利用する形でビルトインエンジン・ビルトインプラグインを実際に作っていく。そのときに「こうした方がいいかも」みたいな要求が出てくるはずなので、工程を戻ってエンジンシステム・プラグインシステムを改善し、それを実際に利用してみて……というイテレーションで全体をブラッシュアップしていこう。
環境構築
環境構築はプロジェクトの最初にしかやらないので、ツールチェインについて学習する機会が少なく、「どの組み合わせが標準的か」すらわからない状態から始めるのはとても骨が折れる。今回の作業はChatGPT登場前だったので自力でやったが、いまなら確実にChatGPTと新しいBingを駆使しているだろうなと思う。LLMはHallucination(幻覚、でっちあげ)も多いが、こういった「自分がよく知らない領域のデファクトスタンダードをざっくり説明してもらう」のような使い方は非常に有用だ。加えて、プログラミングは抽象→具象、具象→抽象を行き来することが多いが、そこで重要となる名付け作業のアシスタントとしてもLLM(大規模言語モデル)は有能だ。最近はコードを書いていて名付けに迷ったときは、「こういう感じの変数に名前を付けたいんだけど~」と毎回相談している。開発のあり方、検索という行為のあり方、ひいてはインターネットのあり方がドラスティックに変わってきているなと感じる。
Visual Studio Code
閑話休題。まずエディタはVSCodeを使う。Go言語を書くときはGoLandが便利すぎて離れられないが、JavaScript/TypeScriptならVSCode一択だ。拡張は以下をインストールしている。
最近はOSSでも .vscode/ ディレクトリをGitの管理対象に含めているのをよく見かけるようになった。 settings.json で設定が共通化され、 extensions.json で拡張も共通化される(インストールを推奨されるだけなので無視することもできる)。たとえば、スペルチェッカーを使っていると「この単語は一般的じゃないけどプロジェクト内でよく使うから下線を入れてほしくない」みたいなときに辞書登録をすることになるが、その辞書データも settings.json で共有できる。
{
"cSpell.words": ["iwassistant"]
}
Dev Containersの利用を前提として .devcontainer/ をGitリポジトリに含めれば完全に開発環境を同一にできるが、個人開発だしtoo muchかなと思って今回の導入は見送った。
TypeScript
TypeScriptは既存のJavaScriptプロジェクトへの段階的な導入を可能とするために型チェックの厳しさを選べるようになっている。今回はスクラッチ開発なので最も厳格な設定にした。
{
"ts-node": { "swc": true },
"compilerOptions": {
// Type Checking
"strict": true,
"exactOptionalPropertyTypes": true,
"noFallthroughCasesInSwitch": true,
"noImplicitOverride": true,
"noImplicitReturns": true,
"noPropertyAccessFromIndexSignature": true,
"noUncheckedIndexedAccess": true,
"noUnusedLocals": true,
"noUnusedParameters": true,
// Modules
"module": "CommonJS",
"moduleResolution": "Node",
"resolveJsonModule": true,
// Emit
"newLine": "lf",
"outDir": "./dist/",
// Interop Constraints
"esModuleInterop": true,
"forceConsistentCasingInFileNames": true,
// Language and Environment
"lib": ["ES2022"],
"target": "ES2022",
"useDefineForClassFields": true
},
"include": ["./src/**/*.ts", "./__tests__/**/*.ts", "./scripts/**/*.ts"]
}
ts-node は素のまま使うと重いのでトランスパイラをRust製のSWCにしている。公式にサポートされているので tsconfig.json に一行追加するだけでいい。型チェックされなくなってしまうが、体感ではっきりわかるほどに速度が変わる。開発時は正確性より「コードを書く→実行する」というイテレーションの速さの方が重要だ。型のエラーはたいていの場合、エディタ上でリアルタイムにわかるし、最終的な安全性の確保はコミット前にできればいい。
module は NodeNext にした方がいいかなと思ったが、いろいろと面倒なことになりそうだったので旧来通りの CommonJS にしておいた。ここはまたあとで見直したい。
リント対象にするためにテストコードとタスク用スクリプトもコンパイル対象に含めているが、このまま tsc コマンドを実行すると dist/ にそれらのファイルも出力されてしまう。これを回避するため、ビルド用の設定ファイルを用意する。
{
"extends": "./tsconfig.json",
"include": ["./src/**/*.ts"],
"exclude": ["./src/**/*.test.ts"]
}
これで tsc --project ./tsconfig.build.json とすれば src/ 以下のファイルのみが dist/ に出力されるようになった。
ESLint
リンターはデファクトスタンダードであるESLintを使う。最初は標準的な設定で、開発中に「ここはチェックしてほしい、ここはチェックしてほしくない」みたいに調整していったら、最終的に以下のようになった。
{
"root": true,
"extends": [
"eslint:recommended",
"plugin:@typescript-eslint/recommended",
"plugin:@typescript-eslint/recommended-requiring-type-checking",
"plugin:unicorn/all",
"plugin:jest/recommended",
"plugin:jest/style",
"prettier"
],
"parserOptions": { "project": "./tsconfig.json" },
"ignorePatterns": ["**/*.js", "coverage/", "dist/", "tmp/", "examples/"],
"rules": {
"curly": ["error", "multi-line"],
"eqeqeq": "error",
"no-console": "warn",
"no-lone-blocks": "error",
"no-return-await": "error",
"prefer-template": "error",
"quotes": ["error", "single", { "avoidEscape": true }],
"@typescript-eslint/ban-types": ["error", { "types": { "{}": false, "Function": false } }],
"@typescript-eslint/consistent-type-imports": "error",
"@typescript-eslint/explicit-function-return-type": ["error", { "allowExpressions": true }],
"@typescript-eslint/no-empty-function": "off",
"@typescript-eslint/no-empty-interface": "off",
"@typescript-eslint/no-unnecessary-condition": "error",
"@typescript-eslint/promise-function-async": "error",
"unicorn/filename-case": "off",
"unicorn/no-array-push-push": "off",
"unicorn/no-keyword-prefix": "off",
"unicorn/no-null": "off",
"unicorn/no-useless-promise-resolve-reject": "off",
"unicorn/no-useless-undefined": "off",
"unicorn/prefer-event-target": "off",
"unicorn/prefer-module": "off",
"unicorn/prefer-top-level-await": "off",
"unicorn/prevent-abbreviations": "off"
},
"overrides": [
{
"files": ["./scripts/**"],
"rules": { "no-console": "off" }
},
{
"files": ["**/*.d.ts"],
"rules": { "@typescript-eslint/consistent-type-imports": "off" }
}
]
}
eslint-plugin-unicornはあまり一般的ではないかもしれないが、import { join } from 'node:path'; のnodeプロトコルを必須にできないかな、と思って調査したときに見つけたプラグインだ。他にも有用なルールが多かったのでとりあえず全部有効にして、不要なものを明示的に外している。
import文のソートもESLintでやりたかったがこれは諦めた。VSCodeでクラス名や関数名を途中までタイプし、サジェストされた候補をタブキーで確定すると、必要なimport文が自動で追加される。他の言語同様、JavaScript/TypeScript界隈でも、import文を手作業で管理する時代は終わっている。どんな環境でも npm run lint npm run format でリントとフォーマットをかけられるようにしているので、import文ソートもこの中に組み込みたかったが、VSCodeのソートと同等のことができるプラグインが見つからず、ここはエディタ依存になってしまっている。あとで再検討したい。
{
"editor.codeActionsOnSave": ["source.organizeImports"]
}
TypeScript前提のESLintをしばらく使ってみて、数年前に比べてものすごく進化したなと感じた。たとえばno-floating-promisesルール。Promiseが登場して以後しばらく UnhandledPromiseRejection というエラーに悩まされた人は多いのではないだろうか。以下のJavaScriptコードをNode.jsで実行すると、「1 2 4」と表示されそうに思えるが、2の直後にプロセスが不正終了してしまう(Node.js v14までは警告のみだったが、v15以降は不正終了する)。
const promise = new Promise((_, reject) => {
console.log(1);
setTimeout(() => {
console.log(2);
reject(3);
}, 1000);
});
setTimeout(() => console.log(4), 2000);
promise.then();
これを期待通りに動かすにはPromiseを適切に catch しなければならない。
promise.then().catch(console.log);
コーディング時に気づきにくい上に、不正終了時にどこで失敗したかを教えてくれないので非常にデバッグしにくい。この「宙に浮いた」Promiseを教えてくれるのがno-floating-promisesルールだ。このルールがいつできたかまでは追っていないが、これがあることで UnhandledPromiseRejection エラーに悩まされる人が激減したことは容易に想像できる。
Prettier
フォーマッター、Prettierの設定は以下のようにした。
{
"printWidth": 120,
"singleQuote": true,
"trailingComma": "all",
"endOfLine": "lf"
}
'10年代前半は、リンターでのチェックは「あった方がいい」くらいの感じで、フォーマッターに関しては、導入しているプロジェクトがほとんどなかったように記憶している。ところがいまは両者を導入していないプロジェクトの方が珍しい。この変化はいつごろ生じたのだろう? '10年代半ばくらいだろうか? 自分がGo言語好きだからこういう史観になるのかもしれないが、と前置きした上で僕の考えを述べると、Go言語が標準でリンターとフォーマッターを完備していたのが大きいように思う。「こういうのでいいんだよこういうので」みたいな感じで誰もがそれを使った結果、プロジェクトごとにコーディングスタイルがバラバラになることなく、どんなプロジェクトでもスタイルが統一されている、というのはすばらしい開発者体験だった。
JavaScript/TypeScriptのリンターとフォーマッターはESLintとPrettierがデファクトスタンダードとなっている。これらも開発者体験をものすごく良好にしてくれると感じた。「雑に書いても後で修正されるからいいや」という心構えでコードを書くのがこんなに楽だとは。どこかからコピってきた文字列リテラルがシングルクオートだろうとダブルクオートだろうと関係ない。オブジェクトリテラルの最後の要素のカンマがあろうがなかろうが関係ない。リンターのautofixかフォーマッターのどちらかが直してくれる。そういう前提があれば、細かいコーディングスタイルに思考領域を奪われることなく、本質的な問題にすべてのリソースを割り当てられるのだ。
Jest
テスティングフレームワークは、デファクトスタンダードとまでは言えないかもしれないが、Jestが頭ひとつ抜き出ているようなのでこれを選択した。設定はデフォルトからほとんど変えず、以下のようにした。速度重視でこちらでもSWCを使っている。
{
"transform": { ".ts": "@swc/jest" },
"collectCoverageFrom": ["./src/**/*.ts"]
}
今回はDiscordとやりとりする機能がメインなので、きっちりテストを書こうとするとモックを用意するのがしんどそうだな、という予想もあり、テストコードはほとんど書いていない。修正時に何度も手作業でテストしたくないところと、TypeScriptで検知できないが安全性・整合性を保っておきたいところ、くらいだろうか。
時間を見つけてぼちぼち書いていきたいなとは思っているが、最近のLLMの進化を見ていると、プロジェクト内の全コードを読んだ上で、カバレッジ100%かつあらゆるパターンを網羅したテストコードをAIが一瞬で書いてくれる未来がすぐそこまで来ているようにも思える。僕がテストコードを書き終わるよりも、その日が来るのが早いかもしれない。早く来てほしい。
lint-staged
TypeScriptの節で「最終的な安全性の確保はコミット前にできればいい」と書いたが、lint-stagedはそれを実現するためのツールだ。名前通り、ステージされた( git add された)ファイルに対してリント(やフォーマット)をかける。これを後述のhuskyと組み合わせて使えば、コミット時( git commit 時)にコードをチェックし、問題があったときにコミットを拒否できる。lint-stagedのREADME.md最初の2文字「🚫💩」がすべてを言い尽くしている。たった2文字でこれだけのメッセージを伝えられるEmojiの偉大さよ。
設定ファイルは以下のようにした。
const { readdirSync, readFileSync } = require('node:fs');
const { join } = require('node:path');
function getFiles(dir) {
return readdirSync(dir, { withFileTypes: true })
.map((entry) => {
const path = join(dir, entry.name);
return entry.isDirectory() ? getFiles(path) : path;
})
.flat();
}
const tsconfig = JSON.parse(readFileSync('./tsconfig.json', 'utf8').replaceAll(/^\s*\/\/.*$/gm, ''));
const options = Object.entries(tsconfig.compilerOptions).map(([key, value]) => `--${key} ${value}`);
const dtsFiles = getFiles('./src/').filter((name) => /\.d\.ts$/.test(name));
module.exports = {
'*': 'prettier --write --ignore-unknown',
'./{src,scripts,__tests__}/**/*.ts': [
'eslint --fix',
`tsc --noemit ${options.join(' ')} ${dtsFiles.join(' ')}`,
'jest --bail --passWithNoTests --findRelatedTests',
],
};
単純なJSONファイルでない理由は、少し複雑なのだが、本稿は自分用のメモの意味合いも大きいので解説を残しておく。
あまり深く調べていないので間違っているかもしれないが、そもそもlint-stagedがどのように動作しているかというと、ステージされたファイルのパスを、指定されたコマンドに引数として渡しているだけだ(と思う)。 eslint コマンドや jest コマンドはその引数のファイルをリント/テストしているのだ。 tsc コマンドも同様のことができるが、そのファイルの中でグローバル定義の型が使われていた場合、import文がないのでTypeScriptコンパイラが解決できず(必要な *.d.ts がステージ中のファイルに含まれている場合は問題ない) tsc コマンドに「そんな型はない」と怒られてしまう。 *.d.ts でのグローバル定義をやめれば解決するが、「 src/user/ 以下にファイルを置くだけでユーザーエンジン・ユーザープラグインのインストールが完了する」という仕様を実現するには *.d.ts でのグローバル定義が必要だ。これについてはあとで詳しく解説する。
ステージ中のファイルのみがコンパイル対象になっていることが原因であるなら、lint-stagedではなくhuskyのプレコミットイベントに tsc --noemit を直接書けばいいように思える。しかしこれもまた問題がある。プロジェクト全体がコンパイル対象になってしまうのはしかたないとしても、この方法だと以下の手順を踏んだ場合に、問題を含んだコードがコミットされてしまう。
- 問題を含んだコードをステージする
- コードを修正する(しかしこれはステージしない)
- コミットする
- プロジェクト内のコードは問題ないのでコミット成功する
- 問題を含んだコードがコミットされる
長く開発を続けていれば普通にありえるシナリオだろう。CIという最終防波堤でカバーできなくもないが、今回は個人開発なのでCIを導入する予定はないし、ローカルブランチではコミットできてしまうという状況がなんだか気持ち悪い。問題の原因は必要な *.d.ts がコンパイル対象から外れていることなので、 src/ 以下の *.d.ts ファイルを全検索して、読み込み対象に毎回含めてしまうことにした。
これで解決のように思えるがもうひとつ問題がある。対象ファイルを引数で指定する場合、 tsconfig.json の設定は無視されてしまうのだ。かといって --project オプションで設定ファイルを指定すると error TS5042: Option 'project' cannot be mixed with source files on a command line. というエラーになってしまう。 tsconfig.json の設定を使いつつ include の部分のみを引数で上書きすることはできない。デフォルト設定の型チェックでかまわない場合は tsconfig.json を読み込む必要がないので問題ないが、 tsconfig.json と同じ設定で型チェックしたい場合は問題だ。これを解決するため、自力で tsconfig.json から設定値を取り出し、すべてのオプションを引数として渡すようにした。これで tsconfig.json と同じ設定で型チェックできるようになった。
husky
プロジェクトをGit管理している場合、.git/hooks/ 以下にスクリプトファイルを置けば、特定のタイミングでフックをかけられるようになる。たとえば、コミット前に何らかのチェックをしたいなら .git/hooks/pre-commit にスクリプトを書けばいい。しかし .git/ ディレクトリはGit管理対象外なので、他の人と共有できない。この問題を解決してくれるのがhuskyだ。具体的には以下のようなことをやってくれる。
- Gitフックディレクトリを
.husky/に変更- これをGit管理対象にしておけばフックを共有できる
-
package.jsonのscriptsに"prepare": "husky install"を追加- リポジトリをクローンした人が
npm iしたときに実行されるタスク -
npm iするだけでプロジェクトを最初に環境構築した人と同じ構成になる
- リポジトリをクローンした人が
コミット時にlint-stagedを実行したい場合は .husky/pre-commit を以下のようにする。
#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
npx lint-staged
commitlint
lint-stagedとhuskyは最近のJavaScript/TypeScriptプロジェクトでの導入率はかなり高いが、コミットメッセージのリンターはまちまちかなという感じがする。僕も開発終盤までは入れていなかったが、完成が見えてきて、「ここからは意味のあるコミット単位にした方がいいな」と思ったときに試験的に導入してみた。npmにパッケージはいろいろあるが、開発がいまでも活発そうなcommitlintにした。ルールもいろいろあるが、特にこだわりはないので公式のGetting Startedのコマンドそのまま、 @commitlint/config-conventional をインストールした。設定ファイルはそれを読み込むだけだ。
{
"extends": ["@commitlint/config-conventional"]
}
commitlintもhuskyと組み合わせて使う。
#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
npx --no -- commitlint --edit ${1}
これで、ルールに違反したメッセージでコミットしようとしたとき、コミットが拒否されるようになった。
@commitlint/config-conventional のルールは type(scope?): subject だ。typeは以下のように定義されている。これ以外は受け付けない。
- build
- chore
- ci
- docs
- feat
- fix
- perf
- refactor
- revert
- style
- test
scopeはコミットが対象とする範囲(省略可能)。subjectは具体的な内容。
僕もまだ使いこなせているとは言えないが、これを導入したことによって、コミットの粒度をかなり意識するようになったなと思う。これを導入する前は、ふわっとしたコミットメッセージを書きがちで、1コミットの粒度もふわっとしがちだったが、導入後は「このコミットは何を意図したものか」をはっきりと意識するようになった。チーム開発ではチームの文化がそれぞれにあるので導入すべきかどうかは場合によるとしか言えないが、自分の個人開発では今後も継続して使っていきたいと思う。
旧来の技術・考え方に慣れていると、新しい技術・考え方の習得に億劫になりがちだが、TypeScriptにせよ、他のツールにせよ、今回ちゃんと使ってみて「たしかにこれはいいものだ」と思うことしきりだった。10年前と比べて、いや5年前と比べてさえ、開発効率が格段に上がっている。余計なことを考えずに、問題解決それ自体にリソースを割り当てられるようになっている。コミットメッセージのリンターが「コミットの粒度を正しくするもの」という、ただの文法チェッカーをはるかに超えた役割を果たしてることからもわかる。制約と束縛は、人を自由にするのだ。
package.json
最終的な(記事執筆時点での) package.json は以下のようになった。
{
"name": "iwassistant",
"version": "1.0.0-alpha.0",
"description": "A Discord bot that speaks, listens, and runs commands, like a smart speaker",
"author": "Kanata",
"license": "MIT",
"private": true,
"scripts": {
"build": "del-cli ./dist/ && cpy ./src/** !**/*.ts ./dist/ && tsc --project ./tsconfig.build.json",
"start": "node ./dist/app",
"dev": "ts-node ./src/app",
"debug": "ts-node ./src/app --debug",
"lint": "prettier --check . && eslint . && tsc --noemit",
"format": "prettier --write . && eslint --fix .",
"test": "jest",
"coverage": "jest --collect-coverage",
"prepare": "husky install && ts-node ./scripts/prepare.ts"
},
"dependencies": {
"@discordjs/opus": "^0.9.0",
"@discordjs/voice": "^0.16.0",
"@google-cloud/firestore": "^6.5.0",
"@google-cloud/speech": "^5.4.1",
"@google-cloud/text-to-speech": "^4.2.2",
"@google-cloud/translate": "^7.2.1",
"discord.js": "^14.11.0",
"ffmpeg-static": "^5.1.0",
"sodium-native": "^4.0.1"
},
"devDependencies": {
"@commitlint/cli": "^17.6.3",
"@commitlint/config-conventional": "^17.6.3",
"@swc/core": "^1.3.56",
"@swc/jest": "^0.2.26",
"@types/jest": "^29.5.1",
"@types/node": "^20.1.0",
"@typescript-eslint/eslint-plugin": "^5.59.2",
"@typescript-eslint/parser": "^5.59.2",
"cpy-cli": "^4.2.0",
"del-cli": "^5.0.0",
"eslint": "^8.40.0",
"eslint-config-prettier": "^8.8.0",
"eslint-plugin-jest": "^27.2.1",
"eslint-plugin-unicorn": "^47.0.0",
"husky": "^8.0.3",
"jest": "^29.5.0",
"lint-staged": "^13.2.2",
"prettier": "^2.8.8",
"ts-node": "^10.9.1",
"typescript": "^5.0.4"
}
}
エンジンシステム構築
準備が整ったので実際にコードを書いていこう。まずはエンジン定義の仕様を考える。データストアのユーザーエンジンを作る場合、以下のような感じになるだろうか。
export type Config = {
limit: number;
};
export const engine: IEngine<Config> = {
name: 'store-memory',
description: 'Memory store',
config: {
limit: 100,
},
createStore({ config }) {
const data: Record<string, object> = {};
return {
get(key) {
return data[key];
},
set(key, value) {
if (Object.keys(data).length > config.limit) return false;
data[key] = value;
return true;
},
};
},
};
name はプログラム内でのIDとなる文字列。 description は機能の簡潔な説明。 config は設定のデフォルト値。アプリケーション側から上書き可能。 createStore はエンジン作成のための関数。インターフェイスを実装したオブジェクトを返す。最初はインターフェイスを実装したクラスを定義して、そのインスタンスを返す形にしていたが、「これ別にクラスいらないな?」ということに気づき、この形になった。 createStore でコンテキストを受け取って、そのコンテキストを元に必要な「関数群」を返す。その「関数群」で共有する変数・定数は return の前に宣言すればいいだけだ。わざわざクラスを定義する必要はない。
今度はこれを実現する IEngine 型を考える。
type IStore = {
get(key: string): object | undefined;
set(key: string, value: object): boolean;
};
type IEngine<T extends object> = {
name: string;
description: string;
config: T;
createStore(context: { config: T }): IStore;
};
ここでは簡単のため、エンジンの設定値もストアに保存する値も object 型にしているが、文字列・数値・真偽値・それらの配列・それらのオブジェクトのみを許可したい場合は、以下のように再帰的な型定義をすればいい。
type BasicValue = string | number | boolean | BasicValue[] | { [p: string]: BasicValue };
type BasicObject = Record<string, BasicValue>;
次に、エンジン設定をアプリケーション側から書き換える方法を模索する。全体設計では src/env/default.ts で設定を書き換えられる仕様にしていた。それをいまのまま実現しようと思ったら以下のようになる。
import type { Config } from '../user/engines/iwassistant-engine-store-memory';
type Env = {
engines: {
'store-memory': Config;
};
};
export const env: Env = {
engines: {
'store-memory': {
limit: 500,
},
},
};
これは煩雑すぎる。設定ファイルでは1行目でいきなり本題に入りたい。できれば src/user/ 以下にファイルを置いた時点で Env 型が自動的に書き換わってほしい。最悪の場合はプレビルド的な処理で型を寄せ集めて……みたいな感じで考えていたが、全体設計の前に軽く調査したときに、「あ、このやり方でいけそうだな」という目星はついていた。いまからそれを検証しよう。
まず前提として、TypeScriptでは *.d.ts 内で定義した型はグローバルな扱いになる。同じプロジェクト内でその型を使う場合、import文は必要ない。
type Env = {
locale: string;
};
export const env: Env = { // ✅
locale: 'ja',
};
Env 型はグローバルなので src/env/default.ts 内ではimport文が不要になっている。しかし src/app/types/env.d.ts 内でimport文を使うとグローバルでなくなってしまう。
import { Config } from '../../user/engines/iwassistant-engine-store-memory';
type Env = {
engines: {
'store-memory': Config;
};
};
export const env: Env = { // ❌ 未定義エラー
engines: {
'store-memory': {
limit: 500,
},
},
};
この問題は import() を使うことで解決する。
type Env = {
engines: {
'store-memory': import('../../user/engines/iwassistant-engine-store-memory').Config;
};
};
export const env: Env = { // ✅
engines: {
'store-memory': {
limit: 500,
},
},
};
この仕様はTypeScript公式ドキュメントで非常に見つけにくく、以下のStackOverflowの回答がなければたどりつけなかったと思う。
現状でも十分動くが、このままではエンジンが増えるごとに本体側の src/app/types/env.d.ts を書き換えなければならない。TypeScriptインターフェイスのオープンエンドと宣言マージを利用して、これを解決しよう。
interface AvailableEngines {
'store-memory': import('.').Config;
}
type Env = {
engines: AvailableEngines;
};
ユーザーエンジンディレクトリ内に extend.d.ts というファイルを作成し、そこで AvailableEngines インターフェイスを拡張するようにした。別のユーザーエンジンを追加したい場合も同じようにする。つまり各ユーザーエンジンごとに extend.d.ts がある形だ。 Env 型はそのインターフェイスを参照するだけなので、エンジンが増えるごとに本体側の型定義を書き換える必要はない。これで、エンジンのインストールは src/user/ 以下にファイルを置くだけで済むようになった。
ここまで来ればあとは早い。エンジンを動的にimportするModuleLoaderクラスを作り、各種エンジンを管理するEngineManagerクラスを作り、エンジンのモックが動くところまで実装した。
プラグインシステム構築
プラグインシステムも基本的な仕組みはエンジンシステムと同じだ。
export type Config = {
prefix: string;
};
export const plugin: IPlugin<Config> = {
name: 'guild-echo',
description: 'Message echo',
config: {
prefix: '',
},
setupApp({ config }) {
return {
onReady() {
console.log('App ready');
console.log(`Prefix: ${config.prefix}`);
},
};
},
setupGuild({ config }) {
return {
onReady() {
console.log('Guild Ready');
},
onMessageCreate(message) {
message.reply(`${config.prefix}${message.content}`).catch(console.error);
},
};
},
};
interface AvailablePlugins {
'guild-echo': import('.').Config;
}
type IPlugin<T extends object> = {
name: string;
description: string;
config: T;
setupApp(context: { config: T }): {
onReady(): void;
};
setupGuild(context: { config: T }): {
onReady(): void;
onMessageCreate(message: import('discord.js').Message): void;
};
};
エンジンは「作成する」ので createStore としたが、こちらはコンテキストを元に「組み立てる」ので、 setupGuild としている。 return で「関数群」を返すのは同じだが、それらが集まってひとつの機能になるエンジンとは違い、プラグインが必要とするのは個別のイベントハンドラとなっている。
この追加仕様に合わせて src/app/types/env.d.ts と src/env/default.ts も書き換える。
type Env = {
engines: AvailableEngines;
plugins: AvailablePlugins;
};
export const env: Env = {
engines: {
'store-memory': {
limit: 500,
},
},
plugins: {
'guild-echo': {
prefix: 'OK ',
},
},
};
さらにコマンド機能を追加してみよう。
export type Options = {
config: {
prefix: string;
};
command: 'start' | 'stop';
};
export const plugin: IPlugin<Options> = {
name: 'guild-echo',
description: 'Message echo',
config: {
prefix: '',
},
command: {
start: 'start echo',
stop: 'stop echo',
},
setupApp({ config }) {
return {
onReady() {
console.log('App ready');
console.log(`Prefix: ${config.prefix}`);
},
};
},
setupGuild({ config }) {
let active = false;
return {
onReady() {
console.log('Guild Ready');
},
onMessageCreate(message) {
if (!active) return;
message.reply(`${config.prefix}${message.content}`).catch(console.error);
},
commandStart() {
active = true;
},
commandStop() {
active = false;
},
};
},
};
interface AvailablePlugins {
'guild-echo': import('.').Options;
}
type IPlugin<T extends { config: object; command: string }> = {
name: string;
description: string;
config: T['config'];
command: {
[P in T['command']]: string;
};
setupApp(context: { config: T['config'] }): {
onReady(): void;
};
setupGuild(context: { config: T['config'] }): {
onReady(): void;
onMessageCreate(message: import('discord.js').Message): void;
} & {
[P in T['command'] as `command${Capitalize<P>}`]: () => void;
};
};
type Env = {
engines: AvailableEngines;
plugins: {
[P in keyof AvailablePlugins]: {
config: AvailablePlugins[P]['config'];
command: Record<AvailablePlugins[P]['command'], string>;
};
};
};
export const env: Env = {
engines: {
'store-memory': {
limit: 500,
},
},
plugins: {
'guild-echo': {
config: {
prefix: 'OK ',
},
command: {
start: 'echo start',
stop: 'echo stop',
},
},
},
};
IPlugin 型のジェネリクス T は階層をひとつ深くして { config: object; command: string } とする。 T['config'] は前と同じく config プロパティに設定。 T['command'] の方は「文字列の可能性」を受け取っているので、それを展開して command プロパティを追加。さらにTemplate Literal Typesを利用して、 commandStart のようにコマンドハンドラの名前としても使っている。 src/env/default.ts でコマンド文字列を上書きできるように Env 型も少し変更した。
こちらもここまで来ればあとは早い。さっき作ったModuleLoaderクラスを使ってプラグインを動的にimportし、プラグインを管理するPluginManagerクラスを作り、プラグインを適用するためのPluginAdapterクラスを作り、プラグインのモックが動くところまで実装した。
多言語対応
多言語対応はこれまでも何度かやってきたが、やり方に正解はない、と思っている。プロジェクトの性質に応じて、最適な方法をその場で見つけていくしかない。今回はTypeScriptなので、型を使った方法を探っていこう。
まず言語コードはユニオン型で以下のように表現すればよさそうに思える。
type Language = 'en' | 'ja' | 'zh-CN' | 'zh-TW';
type Env = {
lang: Language;
};
const env: Env = {
lang: 'ja',
};
これで lang にセットできるのは英語/日本語/簡体字中国語/繁体字中国語のみになった。しかしこれは簡易的な多言語対応だろう。英語と一口に言っても、アメリカ英語とイギリス英語はかなり違いがある。たとえば、 "color" と "colour" のような綴りの違い。 "gas" と "petrol" のような単語の違い。どちらであっても意味は通じるが、日本語ネイティブが簡体字中国語フォントで漢字を読むような心地悪さはどうしてもつきまとう。だから本当にきっちりと多言語対応するなら、「言語」ではなく、特定の地域で使われる言語という意味で「ロケール」を使わなければならない。
type Locale = 'en-US' | 'en-GB' | 'ja-JP' | 'zh-CN' | 'zh-TW';
type Env = {
locale: Locale;
};
const env: Env = {
locale: 'ja-JP',
};
しかしこれはこれでtoo muchな感じがする。実際のところ、言語指定で済む場面の方が多いのだ。折衷案で以下のようにした。
type Language = 'en' | 'ja' | 'zh';
type RegionLocale = 'en-US' | 'en-GB' | 'zh-CN' | 'zh-TW';
type Locale = Language | RegionLocale;
type Env = {
locale: Locale;
};
const env: Env = {
locale: 'ja',
};
Language 型は言語それ自体。 RegionLocale 型は特定の地域で使われる言語。 "region" も "locale" も似たような意味なので「頭痛が痛い」みたいな感じになってしまっているが、 これ以上いい名前は思いつかなかった。 "locale" の方をプロジェクト全体で使う名前にしたかったのでしかたない。その Locale 型は Language 型と RegionLocale 型の合成なので、中身は 'en' | 'ja' | 'zh' | 'en-US' | 'en-GB' | 'zh-CN' | 'zh-TW' となっている。 ja-JP のように言語が単一のロケールしか持たない場合は RegionLocale 型には含めない。 ja があれば十分だからだ。
Locale 型に en のような「言語それ自体」が含まれていることに違和感を覚えなくもないが、違和感よりも利点を優先した。 en があることで、「一般的な英語」の枠ができるのだ。たとえば辞書データを扱うときのことを考えてみよう。 アメリカ英語用の en-US やイギリス英語用の en-GB を定義した上で、 en に「一般的な英語」も定義しておけば、 en-IN のような辞書にないロケールが参照されたとき、適切にフォールバックできる。プログラム的には「 en-** の最初の定義にフォールバックする」みたいなこともできるし、実際そうしているのだが、辞書データ作成時に「一般的な英語の枠がある」というのが重要なのだ。
仮に、 Locale 型が 'en-US' | 'en-GB' のみだったとしたら、ビルトインプラグインの辞書データを作成するとき、「英語」の指定に en-US か en-GB のどちらかを選ばなければならない。適切にフォールバックするからどちらを指定してもいいのだが、まあなんというか、気持ちの問題だ。僕はそこで「どちらがスタンダードな英語か」を表明したくないのだ。だから「一般的な英語」としての en ロケールが必要で、上のような仕様になった。
言語は民族意識やアイデンティティに強く結びついている。言語を雑に扱うことは誰かの自尊心を傷つけることにつながる。特に政治的に難しい状況に置かれている人々にとっては「自分の言語がどのように扱われるか」は切実な問題だ。だから基本的に言語と国は分けて考えなければならない。Discordの言語設定画面にある国旗アイコンはダメな例だろう。僕がこういったことを知識からの判定ではなく「実感」するようになったのは、VRChatやDiscordでいろんな言語圏、いろんな文化圏の人と交流するようになったことが大きく寄与していると思う。今回のプロジェクトの多言語対応では、コードを書いているとき、「あの人がこのプログラムを使ったらどう思うだろう?」みたいなことを常に考えていた。もちろんすべてを拾えるわけではない。個人の言語能力には限界がある。だけどいまの自分が納得できる程度の多言語対応はできたかなと思っている。
Discord対応
Discord上で発生するイベントのほとんどは、Discord.jsのClientクラスで補足できる。このクライアントはBOTが所属するすべてのギルドにまたがっているので、ギルドごとにイベント処理を変えたい場合は、イベントハンドラの中で振り分け作業が必要になってくる。
client.on('messageCreate', (message) => {
switch (message.guildId) {
case '1111': {
// ...
break;
}
case '2222': {
// ...
break;
}
}
});
さっき構築したプラグインシステムは setupGuild の戻り値として onMessageCreate のようなイベントハンドラを定義する仕様だ。つまりギルドごとに振り分けられた「後」のイベントハンドラになっている。この手前の段階の振り分け作業を行うDiscordManagerクラスを作る。
class DiscordManager {
client = new Client({ intents: [] });
setup(): void {
this.client.on('messageCreate', (message) => {
if (!message.inGuild()) {
console.log('Direct message');
return;
}
console.log(`Guild message: ${message.guildId}`);
});
}
}
これはモックだが、 console.log のところで、各プラグインのイベントハンドラを呼び出すようにすればいいだけだ。
上のコードでわかるように、現在のDiscord.jsは、 Client クラスのインスタンス生成時に intents を必須としている。IntentsについてはDiscord.jsのガイドがわかりやすい。簡単に言うと「どんなイベントを受け取りたいか、最初に教えてね」というものだ。以前は不要だったが、大元のDiscord APIの仕様変更にともなって必須となっている。Discordの規模と使われ方が大きく変わってきたこと、個人情報の扱いに対して世間の目が厳しくなってきたこと(特にケンブリッジ・アナリティカ事件以降)が影響しているのだと思う。
どの intents を有効にするか、 src/env/default.ts の設定項目に含めようかなと考えていたが、必須項目は少ない方がいいので、自動で算出することにした。
type IPlugin = {
setupGuild(): {
onMessageCreate?(): void;
onMessageReactionAdd?(): void;
};
};
const plugin: IPlugin = {
setupGuild() {
return {
onMessageReactionAdd() {},
};
},
};
const eventNames = [...plugin.setupGuild.toString().matchAll(/on([A-Za-z]+)/g)].map(([, name]) => name);
console.log(eventNames);
// 実行結果: [ 'MessageReactionAdd' ]
簡略化したコードだが、やりたいことはこれで実現できる。 plugin 直下のプロパティとして onMessageReactionAdd が存在するなら単純にオブジェクトのキーを見ればいいだけなので簡単だが、今回のプラグイン仕様では setupGuild がイベントハンドラの「関数群」を返す形になっている。何が返されるかは setupGuild を実行してみなければわからない。if文等で return が複数あるかもしれないからだ。しかし、 intents の指定はDiscord APIへの接続「前」に必要なので、 setupGuild の実行「前」に判明していてほしい。これを解決するため、 setupGuild 関数を文字列化し、正規表現でイベント名を検索している。 setupGuild の外でイベント名を書かれてしまうと正常に動作しなくなってしまうが、それは仕様ということにした。
あとはイベントに対応する intents を自動で算出すればいいだけだ。たとえば、 onMessageReactionAdd が存在するプラグインを使っている場合は GuildMessageReactions を有効にする、といったように。
ロガーとイベントエミッター
このあとはアシスタント機能の実装に入る予定だったが、その前に「あった方がいいやつ」を先に作っておくことにした。ロガーとイベントエミッターだ。
まずロガー。今回は「できるだけ依存パッケージを少なくする」という方針を立てていたので自作した。何の変哲もない「ログレベルによって出力を変えるロガー」でしかないが、少し工夫した部分がある。わりと有用な実装パターンだと思うので紹介しよう。以下は普通のロガーを普通に使ったサンプルコード。
class Logger {
#level: number;
constructor(level: number) {
this.#level = level;
}
debug(...args: unknown[]): void {
if (this.#level > 0) return;
console.log(...args);
}
error(...args: unknown[]): void {
if (this.#level > 1) return;
console.log(...args);
}
}
{
const log = new Logger(1);
log.error('1: エラー情報'); // 出力される
log.debug('1: デバッグ情報'); // 出力されない
}
{
const log = new Logger(0);
log.error('0: エラー情報'); // 出力される
log.debug('0: デバッグ情報'); // 出力される
}
このロガーを次のように使うシチュエーションはよくあるが、問題が発生してしまっている。
function dump(target: unknown): unknown {
console.log('なんか重い処理');
return target;
}
const log = new Logger(1);
log.error('エラー情報');
log.debug(dump('デバッグ情報'));
期待通り「デバッグ情報」は出力されていないが、 dump 関数が実行されてしまっているのだ。これが非常に重い処理だった場合、本番環境でのパフォーマンスに影響を与えてしまう。「謎のパフォーマンス低下」の原因としてたまに見かけるやつだ。 if (process.env['DEBUGGING']) log.debug(dump('デバッグ情報')) のようにして解決してもいいが、それではせっかくのログレベルが台無しになってしまう。
次の実装パターンはこの問題をエレガントに解決してくれる。
class Logger {
#level: number;
debug?: (...args: unknown[]) => void;
constructor(level: number) {
this.#level = level;
if (level === 0) this.debug = (...args) => console.log(...args);
}
error(...args: unknown[]): void {
if (this.#level > 1) return;
console.log(...args);
}
}
function dump(target: unknown): unknown {
console.log('なんか重い処理');
return target;
}
{
const log = new Logger(1);
log.error('1: エラー情報');
log.debug?.(dump('1: デバッグ情報'));
}
{
const log = new Logger(0);
log.error('0: エラー情報');
log.debug?.(dump('0: デバッグ情報'));
}
ポイントは debug メソッドをオプショナルにしているところだ。ログレベルが 0 でない場合、 debug メソッドが存在しないため、log.debug? の時点で undefined として評価され、その先の .(dump(... 以降は無視される。だから引数の箇所まで進むことがなく、 dump 関数が実行されない。
これは、ES2020で導入されたオプショナルチェーンによって可能になった実装パターンだが、素のJavaScriptでは「 ? の付け忘れが怖すぎる……」というのが一般的な感覚だろう。オプショナルなプロパティに ? なしでアクセスしようとしたらTypeScriptがすぐに教えてくれる、という状況があって初めて「使える」ようになった実装パターンだと言えるかもしれない。
次はイベントエミッター。こちらもTypeScriptをフル活用する。Discord.jsを使っていて client.on('') のようにタイピングしたとき、 Client クラスのイベント名がサジェストされ、イベント名を指定後、そのイベントハンドラの型まで教えてくれるのが便利すぎたので、自分のプロジェクト内でも実装することにした。
とりあえずシンプルなコードを書いてみる。
import { EventEmitter as BuiltinEventEmitter } from 'node:events';
class EventEmitter<T extends Record<string, unknown[]>> {
#emitter = new BuiltinEventEmitter();
on<P extends keyof T>(eventName: P, listener: (...args: T[P]) => void): this {
this.#emitter.on(eventName as string, listener as (...args: unknown[]) => void);
return this;
}
emit<P extends keyof T>(eventName: P, ...args: T[P]): boolean {
return this.#emitter.emit(eventName as string, ...args);
}
}
type AudioPlayerEvents = {
start: [time: Date];
end: [time: Date, reason: string];
};
class AudioPlayer extends EventEmitter<AudioPlayerEvents> {
play(): boolean {
this.emit('start', new Date());
setTimeout(() => {
this.emit('end', new Date(), 'timeout');
}, 1000);
return true;
}
}
const player = new AudioPlayer();
player.on('start', (time) => {
console.log('Start:', time);
});
player.on('end', (time, reason) => {
console.log('End:', time, reason);
});
player.play();
this.emit('') でも player.on('') でも、イベント名がサジェストされ、イベント名を指定後は、 AudioPlayerEvents にしたがって型が確定している。
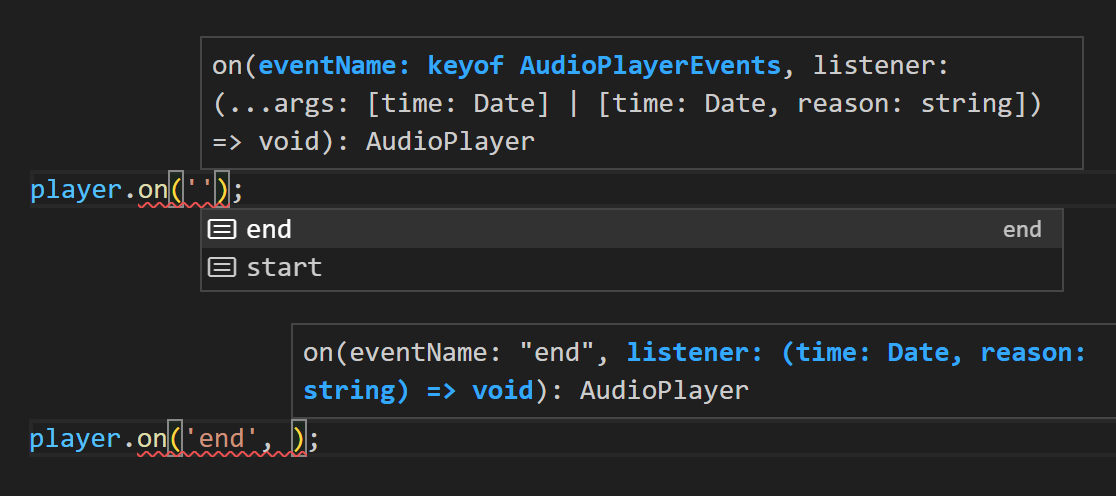
初期のNode.jsはPromiseを前提していなかったので、イベントハンドラに async 関数をセットした場合、エラーハンドリングが通常とは異なっていて対応が面倒だったりする。イベントの型絞り込みに対応しつつ、そのあたりを吸収したカスタムイベントエミッタークラスを作り、今回のプロジェクトでイベントを扱う場面ではすべてこちらを使うことにした。
アシスタント実装
基本的な部品は揃った。あとはそれを組み立てるだけだから簡単かな、と楽観的に考えていたが、実際にアシスタントの実装に取り掛かってみると、まだ考えなければならないことが多いことに気づいたので、ホームアシスタントは今回の開発のスコープから外してしまうことにした。とりあえずモックだけ作っておいて、実装はリリース後にぼちぼちやっていけばいい。今回はギルドアシスタントに注力する。こちらが完成すれば、ホームアシスタントの形も見えてくるはずだ。
まずはアシスタントの責務の範囲を考える。普通に考えれば、テキストチャンネルの内容をボイスチャンネルで読み上げる、みたいな機能はアシスタントが持っているべきのように思える。しかし「どう読み上げたいか」は状況によってだいぶ変わってくる、というのは数年間BOTを実際に運用して感じたことだ。その多様な状況にすべて対応しようと思ったら、アシスタントの中身が煩雑になる。「どう読み上げるか」をアシスタントではなくプラグインの責務にしてしまえば、「ビルトインプラグインの読み上げ仕様が気に入らなかったら自分でプラグインを書いて」で済む話になる。アシスタントの中身もシンプルになる。アシスタントは「しゃべる」という機能だけを持っていればいいからだ。その機能を提供することがアシスタントの責務。プラグインの責務はその機能を使って「しゃべらせる」こと。よし、こんな感じでいこう。
大枠が見えたので実際の構成を考える。
| コードの範囲 | 責務の範囲 |
|---|---|
| EventEmitter | イベントを処理する |
| PluginAdapter | プラグインを処理する |
| Assistant | コマンドを解釈する |
| GuildAssistant | しゃべれる/聞ける/コマンド実行できる |
| プラグイン | しゃべらせる/聞かせる/コマンド定義 |
クラスは GuildAssistant extends Assistant extends PluginAdapter extends EventEmitter の関係だ。プラグインも含めて俯瞰すれば、抽象から少しずつ具象に向かっていき、最終的に現実的な「行動」になっている。まあまあいい感じだ。最初は Assistant クラスの責務の範囲がもっと広かったのだが、開発を進めるにつれ GuildAssistant の方へ責務が移されていき、現在の形になった。 Assistant と GuildAssistant および HomeAssistant の関係性は、ホームアシスタント実装の際に再検討したい。
アシスタントには音声の再生と受信を請け負う audioPlayer と audioReceiver を持たせた。ホームアシスタントの場合は、実行環境の再生・録音デバイスにつながっているイメージだ。ギルドアシスタントの場合は、どちらもボイスチャンネルにつながることになるが、受信が少し複雑になるため、 GuildVoiceChannelとは別に、GuildAudioReceiverを作った。
GuildAudioReceiver はボイスチャンネルの音声フレームをすべて VoiceAudioCreator に流し込む。 VoiceAudioCreator は認識可能な音声 RecognizableAudio を作成する。Discordのボイスチャンネルでは、たまにゴミフレームがポツポツと送られてくることがあるので、一定量のフレームが連続して送られてきたときに RecognizableAudio を作成し、 create イベントを emit し、以降の音声フレームをストリーム処理する。一定時間無音が続いたら null を流し込んでストリーム処理を完了し、また待ち受け状態に戻る。これの繰り返し。create イベントはアシスタント側で受け取り、アシスタントがまた自身のイベントとして listen イベントを emit する。そのイベントをプラグインが onListen で受け取り、 RecognizableAudio を音声認識にかける。流れはだいたいこんな感じだ。
ビルトインエンジン実装
全体設計で決めたエンジンの種類は4つ。データストア、読み上げ、音声認識、翻訳。どうするかひとつずつ検討していこう。
まずデータストアはJSONが保存できればなんでもいいので、ローカルストレージに保存できるものを作る。音声認識は技術検証で確認したようにChromeのものが使える。翻訳はGoogle翻訳のAPIが叩けるのでこれでいこう。試しにGoogle翻訳の読み上げAPIも叩いてみたら使えたので、読み上げもGoogle翻訳のものを使うことにした。この読み上げAPI、以前は制限がかかっていた記憶があるが、仕様が変わったのだろうか?
とりあえずはエンジン全種類を無料で使えるようにできそうだが、APIを叩きまくっていると一定時間BANされることがある。本プロジェクトが想定しているのは小さなコミュニティー内で動かす個人用BOTなので問題にはならなそうだが、公式に開放されているわけではないAPIを叩いている後ろめたさ解消のためにも、「ちゃんと使いたいならGoogleにお金を落としておくれ」という意味を込めて、エンジン全種類、Google Cloud版のものをビルトインとして用意することにした。
| エンジン名 | 無料 |
|---|---|
| store-local | ✔️ |
| store-firestore | |
| translator-google-translate | ✔️ |
| translator-google-cloud | |
| tts-google-translate | ✔️ |
| tts-google-cloud | |
| stt-google-chrome | ✔️ |
| stt-google-cloud |
stt-google-chrome は、OS側での音声デバイス指定を不要にするために「Chrome上で再生した音声をChrome自身が聞く」という仕組みにしたり、依存パッケージを減らすためにPuppeteerのコードを読んで必要な部分のみを取り込んだり、いろいろと調べながらやっていたので実装に手間取ったが、それ以外のエンジンはサクサク開発できた。 store-local なんて50行にも満たない。事前にエンジンシステムを構築しておいてよかったと思う。
ビルトインプラグイン実装
アシスタントは何もしない、何かをするのはプラグイン、と決めた。最後にこの「行動」の部分を実装しよう。いよいよ大詰めだ。
ひとりのDiscord廃人として必要な機能を実装していったら、以下のようになった。
| プラグイン名 | 機能 |
|---|---|
| guild-help | すべてのコマンドを表示する |
| guild-config | サーバー設定、チャンネル設定、ユーザー設定 |
| guild-tts | 読み上げ機能 |
| guild-stt | 音声認識機能 |
| guild-translate | 翻訳機能 |
| guild-summon | ボイスチャンネルへの入室・退室コマンド |
| guild-follow | ボイスチャンネルに自動で入室する |
| guild-announce | ボイスチャンネル内で誰かが入室・配信開始したときに音声で知らせる |
| guild-notify | メッセージにリアクションが付けられたときにDMで知らせる |
| guild-react | 自動返信・自動リアクション |
guild-config を除き、だいたい100行程度で完結するシンプルなプラグインなので、こちらもサクサク開発できた。少し悩んだのは data の扱いだろうか。 setupGuild のコンテキストとして受け取れる data は、プロパティに値をセットすることで、自動でデータストアに保存される。以下のサンプルはモックにすぎないが、プラグインとして実際に動くコードだ。
export type Options = {
data: {
guild: {
state: boolean;
};
};
};
export const plugin: IPlugin<Options> = {
name: 'guild-switch',
description: 'Switch mock',
setupGuild({ data }) {
return {
onMessageCreate(message) {
switch (message.content) {
case 'on': {
data.state = true;
break;
}
case 'off': {
data.state = false;
break;
}
}
},
};
},
};
このプラグインを有効にした状態でテキストチャンネルに "on" と投稿すると、1分後もしくはプログラム終了時に、データストアに以下のように保存される。
{
"guild-switch": {
"state": true
}
}
プログラム起動時にこのデータを読み込むので、data は永続化されていると言える。ちなみにこの機能の実装はDatastoreクラスにある。Proxyを使ったよくあるパターンだ。
この機能は、ユーザーからの入力を元に何らかの設定値を保存するようなシチュエーションを想定している。基本的に各プラグインは独立して動作することを想定しているので、上記のようにできればほとんどのシチュエーションでは十分だと思うが、このデータに別のプラグインからアクセスしようと思うと少し面倒なことになる。 setupGuild にコンテキストとして渡される data はプラグインによって違うからだ。
サーバー設定/チャンネル設定/ユーザー設定を、それぞれひとつのコマンドで済ませようと考えると、コマンドをどのプラグインに持たせるべきか、という問題が発生する。たとえば読み上げ設定なら guild-tts に持たせるべきかもしれないが、「ユーザー設定コマンド」を guild-tts に持たせるのは違和感がある。解決策として、設定コマンド群は guild-config の責務の範囲とし、そこで data に保存した値を他のプラグインから assistant.data.get('guild-config') のような形で参照できるようにした。あまり綺麗な実装ではないが、機能ごとに設定コマンドがたくさんある状況よりも、こちらの方がユーザーフレンドリーなはずだ。
guild-config の設定項目は可変ではないので、これを超えるような設定をしたい場合は、別の設定コマンドを別プラグインで定義するか、もしくは guild-config を外して guild-custom-config のような設定プラグインを作ってそちらを代わりに使うか、のような形になるだろうか。何にせよ、 src/env/default.ts でビルトインプラグインをすべて外せば「何の機能も持たないアシスタント」にできる。そこからどんな改造も可能だ。
2024-01-07追記: guild-configプラグインが持つ各種コマンドの設定項目を他プラグインからセットできるようにして上記問題は解決した
ドキュメンテーション
個人開発でいちばんしんどいのはリリース準備、特にドキュメンテーションじゃないかと思う。環境構築から実装まですべてひとりでやっている個人開発者は、ここに至った時点ですでに気力を使い果たしていることが多い。今回の僕も例に漏れずそんな感じで、「ドキュメント書かないとなー」と思いつつもやる気が出ず、BOTの試験運用と称してDiscordで雑談しながらゲーム実況していたら、いつのまにか1か月が過ぎていた。
ドキュメンテーションの難しさは、特定のゲームをやり込んだ人間だけが持つ感覚を、そのゲームをやったことがない人に伝えようとする難しさに似ている。たとえば、僕が最近ハマっているNoitaというゲームのコミュニティーでは「ゲームオーバー」の意味で "get noita'd" という言い回しがよく使われる。Noitaはローグライトゲームだ。ゲームオーバーですべてを失う。お金もアイテムも持ち越せない。持ち越せるのはプレイヤーのリアルな経験値のみだ。その上で「こんなんどうしようもないやん……」みたいな死に方が非常に多い。ただ理不尽すぎるかというとそうでもない。プレイヤーの工夫次第で回避できる(かもしれない)絶妙なバランスだ。このなんとも言えないニュアンスは "die/death" では言い表すことができず、タイトルをそのまま使った "get noita'd" という言い回しが生まれたのだと思う。死にゲー好きならこの説明でもなんとなく伝わるとは思うが、実際にNoitaで数百回死んだ経験がないと、 この "get noita'd" という言い回しの微妙なニュアンスは汲み取れないんじゃないかと思う。やり込んでいる人はニュアンスを汲み取る感覚 sensor を持っているので「わかる make sense」が、やり込んでいなければ感覚 sensor がないので「わからない make no sense」になってしまう。
ドキュメントは「わからない make no sense」を「わかる make sense」に変えるもの、最短距離で感覚 sense を形成 make するものであるべきだと思う。開発者は必然的に自プロジェクトの「やりこみ勢」になってしまうので、ドキュメンテーション時はセーブデータを新規作成し、「わからない make no sense」状態にしてから、「わかる make sense」に戻れるようなチュートリアルを書く必要がある。異なるセーブデータを同時進行しなければならない難しさ。これがドキュメンテーションのしんどさの原因なのだと思う。常にメタ視点を持ち続けるのはとても大変だ。しかしこれをやらなければ誰にも使ってもらえない。思ってるだけでは伝わらない。なんて面倒くさい生き物でしょう、人間というのは。あ~あ~、ハロ、ハワユ。
今回のドキュメンテーションでは、この「最短距離」を心がけた。最初に概要。次にプログラムを起動するまでの最短手順。 stt-google-chrome のセットアップ手順は煩雑なので後回しに。それに合わせて src/env/default.ts の初期値は音声認識エンジンの箇所をコメントアウトしておく。それから基本的な機能の説明、プラグインとエンジンの説明、と少しずつ掘り下げていく構成にした。これが最適かどうかはわからないが、そこそこ読みやすいドキュメントになったんじゃないかと思う。マルチエンジン(読み上げ/音声認識/翻訳エンジンは複数を同時に扱える)、マルチクライアント(e.g. 日本語用BOTと英語用BOTを同時に存在させる)、エンジン開発・プラグイン開発あたりは、気力がもう尽きかけていたので後回しにした。そのうち書く。
リリース
どうにか他人が使える形にはなったのでひとまずリリース。まだまだやることは多いのでバージョンは 1.0.0-alpha.0 にしている。正式にバージョン番号を振っていくのはホームアシスタント実装後にする予定だ。
おわりに
自由度の高いゲームはおもしろい。だけど自由すぎると何をしていいのかわからない。難しいゲームもおもしろい。だけど難しすぎると何もできなくてつまらない。そんなとき人は、何をすればいいのか、どうするのが最適なのか、攻略情報に頼ってしまう。それは別に悪いことじゃない。ゲームをやめてしまうよりは、攻略を見ながらでも楽しんだ方がずっといい。しかし攻略情報はときに、ゲームをスポイルしてしまう。楽しむためにやっていたはずのゲームを、ただの作業に変えてしまう。そして現代人なら誰もが罹患している「倦怠」という名の病が進行する。
このからくりは、現代に生きる誰もが気づいていながら、誰も逃れられない。ゲームをやることに本来、意味も価値も目的もないはずなのに、レトロスペクティブにしか決定されないそれらを、人はどうしようもなく、プロスペクティブに求めてしまう。最高の体験を、最適な手順でなぞるだけの、簡単な作業。そしてつぶやく。自分は何がしたかったんだっけ……。
おそらくこういうときに必要なのは攻略情報ではなく「ゲーム実況」なのだ。かつて「友達の家に集まってダラダラと雑談しながらゲームする」という非常にローカルな文化だったそれは、いまはDiscordとTwitchとYouTubeによってグローバルな文化となった。この文化が世界中で急速に興隆したのは、これが現代人の宿痾に対するカウンターとして有効だから、なのだと思う。
本稿を書き終えて気づいた。僕がやりたかったのは、この「ゲーム実況」なのだ。プログラミングという、この世で最も自由度の高いゲームの、凡庸なプレイヤーの凡庸なプレイ記録。右往左往しながらこのオープンワールドの大地を踏みしめていくさまは、攻略情報ではなく「ゲーム実況」だ。これが誰かにとってスポイラー(つまらなくするもの)ではなく、プログラミングというゲームをおもしろくするものになっていてほしいと思う。
巷には「人生の攻略情報」が溢れている。それらに人生というオープンワールドゲームをスポイルされている気がしてきたら、Discordでゲーム配信しながら、くだらない話でもしよう。意味も価値も目的もない、不協和で、たわいもない話を。
"Hello, how are you?"
「こんにちは。調子はどう?」

コメント
いいね以上の気持ちはコメントで