年末キワキワに出てくるとは。。。
導入
ELYZA社からLlama2 13Bベースの日本語LLMが公開されました。
日本語ベンチマーク ELYZA Tasks 100において、GPT-3.5(text-davinci-003)を越える性能を発揮しています。
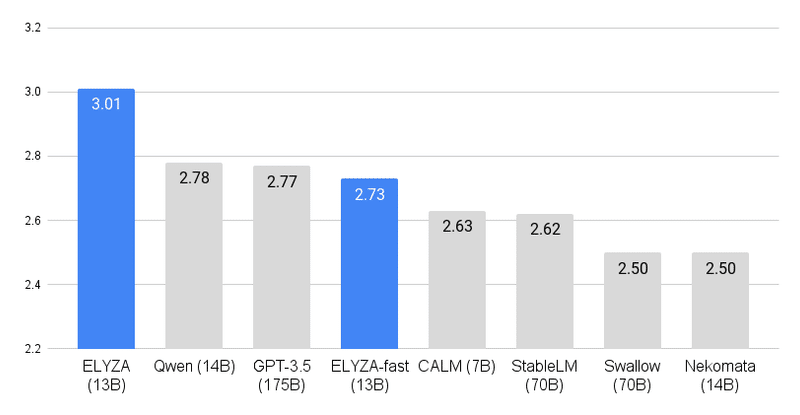
既に以下のようにいろんな方が試されていますが、以前、7Bが公開されたときも試したので、今回もDatabricks上で動かしてみます。
ELYZA-japanese-Llama-2-13Bはベースモデル含めていくつかの種類が公開されていますが、今回はelyza/ELYZA-japanese-Llama-2-13b-instructを試用します。(非fastモデル)
なお、DBRは14.1ML、クラスタタイプ g5.xlarge(AWS)で確認しました。
Step1. パッケージのインストール
ハマったポイント。
transformersが最新バージョン(0.46.2)だとTokenizerのロードでエラーが出たので、モデルのconfig.json内に記載のバージョンを指定してインストールします。
%pip install "transformers==4.34.1" accelerate bitsandbytes sentencepiece
dbutils.library.restartPython()
Step2. モデルのダウンロード
モデルのスナップショットをダウンロードし、Unity Catalog Volumes内に保管。
from typing import Optional
def download_model(model_id:str, revision:Optional[str]=None):
import os
from huggingface_hub import snapshot_download
UC_VOLUME = "/Volumes/training/llm/model_snapshots"
rev_dir = ("--" + revision) if revision else ""
local_dir = f"/tmp/{model_id}{rev_dir}"
uc_dir = f"/models--{model_id.replace('/', '--')}"
snapshot_location = snapshot_download(
repo_id=model_id,
revision=revision,
local_dir=local_dir,
local_dir_use_symlinks=False,
)
dbutils.fs.cp(f"file:{local_dir}", f"{UC_VOLUME}{uc_dir}{rev_dir}", recurse=True)
model_id = "elyza/ELYZA-japanese-Llama-2-13b-instruct"
download_model(model_id)
Step3. モデルのロード&推論
モデルをロードして、推論実行。
bitsandbytesで8bit量子化するように指定しています。
(VRAM使用量は最終的に13.7GBくらいでした)
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "/Volumes/training/llm/model_snapshots/models--elyza--ELYZA-japanese-Llama-2-13b-instruct"
B_INST, E_INST = "[INST]", "[/INST]"
B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n"
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。"
text = "クマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説を書いてください。"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
use_cache=True,
device_map="auto",
low_cpu_mem_usage=True,
load_in_8bit=True,
)
model.eval()
prompt = "{bos_token}{b_inst} {system}{prompt} {e_inst} ".format(
bos_token=tokenizer.bos_token,
b_inst=B_INST,
system=f"{B_SYS}{DEFAULT_SYSTEM_PROMPT}{E_SYS}",
prompt=text,
e_inst=E_INST,
)
with torch.no_grad():
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
temperature=0.5,
max_new_tokens=256,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1) :], skip_special_tokens=True
)
print(output)
承知しました。クマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説を以下に作成します。
クマは、ある日のこと、森の奥深くにある穴から出てきました。
「今日も一日、何もない日だな」
クマはため息をつき、森を歩き始めました。
森を歩いていると、海が見えてきました。
「あ、海だ」
クマは、海の方へと歩き始めました。
海辺に着くと、クマは砂浜を歩き始めました。
「あ、何か足がつっちゃった
アザラシ登場前に切れてしまいましたが、プロット通りの内容を書いてくれました。
推論部分を関数にラップして、他にもいろいろ指示してみます。
# 関数ラップ
def generate_batch(instruction:str):
prompt = "{bos_token}{b_inst} {system}{prompt} {e_inst} ".format(
bos_token=tokenizer.bos_token,
b_inst=B_INST,
system=f"{B_SYS}{DEFAULT_SYSTEM_PROMPT}{E_SYS}",
prompt=instruction,
e_inst=E_INST,
)
with torch.no_grad():
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
temperature=0.5,
max_new_tokens=256,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1) :], skip_special_tokens=True)
return output
架空の生き物をデザインし、その特徴や能力について説明してください。
generate_batch("架空の生き物をデザインし、その特徴や能力について説明してください。")
架空の生き物「レインボーライト」をデザインします。
レインボーライトは、雨bowの光をまとった生き物です。そのため、体の大部分は光で覆われており、その光を操ることができます。
レインボーライトの光は自在に変化することができ、敵に見破られないようにするために色を変えたり、光の強度を変えたりすることができます。また、光で弾かれた物体を自在に操ることもできます。
レインボーライトは、光を操る能力を用いて、敵を翻弄したり、逃げたりすることができます。また、光を集中させ
ランダムな10個の要素からなるリストを作成してソートするコードをPythonで書いてください。
generate_batch("ランダムな10個の要素からなるリストを作成してソートするコードをPythonで書いてください。")
以下はPythonを使ってランダムな10個の要素からなるリストを作成してソートするコードです。
```
import random
# ランダムなリストを作成
random_list = [random.randint(1, 10) for _ in range(10)]
# リストをソート
random_list.sort()
```
このコードでは、`random.randint(1, 10)`を10回繰り返すことで、ランダムな数を生成しています。また、`random_list.sort()`を実行することで、ソートを行っています。
実行させてみると、ちゃんと正しく動くコードでした。
東京、名古屋、大阪、京都、福岡の特徴
generate_batch("日本国内で観光に行きたいと思っています。東京、名古屋、大阪、京都、福岡の特徴を表にまとめてください。列名は「都道府県」「おすすめスポット」「おすすめグルメ」にしてください。")
承知しました。以下が観光に関する情報をまとめた表です。
| 都道府県 | おすすめスポット | おすすめグルメ |
|:---:|:---:|:---:|
| 東京 | 東京スカイツリー | すき焼き |
| 名古屋 | 名古屋城 | みそかつ |
| 大阪 | 通天閣 | お好み焼き |
| 京都 | 京都御苑 | たこめし |
| 福岡 | 福岡城 | 明太子 |
7Bに比べると、出力がシンプルになった気がします。
まとめ
ELYZA-japanese-Llama-2-13BをDatabricksで試用してみました。
インストールするパッケージのバージョンのみご注意ください。
今回ぐらいの推論だと、13Bの性能をあまり活かせてないですね。
引き続き量子化やQA・RAGでの性能を試してみたいと思います。

コメント
いいね以上の気持ちはコメントで