この記事は、競プロ Advent Calendar 2022 18日目の記事です。
この記事は再帰自体を全否定する趣旨ではありません。
両方の良さを理解した上で非再帰で書きたいと思ったときの参考にしていただければと思います。
まだ再帰関数書いてるの?
再帰関数はプログラミング言語の有用な機能で、深さ優先探索をベースとする様々なアルゴリズムの実装として有用です。
その一方で、関数呼び出しはオーバーヘッドが大きく、定数倍が弱くなります。また、JavaやPythonなどのスタック領域の制限が厳し目の言語では深すぎる再帰のせいでRuntime Errorが発生する場合があります。
C++などのコンパイル言語ではインライン展開によって関数呼び出しのオーバーヘッド解消されることもありますが、再帰関数は中でもインライン展開の難易度が高く、深い再帰ではそのまま実行せざるを得ない状況になります。
ところが、再帰関数は生のスタックを自分で用意するなどして非再帰に書き直すことができます。(「停止する再帰的処理は常に同じ時間・空間計算量の非再帰処理に書き換えられる」、真っぽいのですが厳密な証明が見つけられなかったのでもしかしたら反例があるかもしれません。どなたか証明/反例を提供してくださると助かります…)
そしてこの書き換えは慣れてしまえば多くの場合それほど大変ではありません。
再帰って本当に重いの?
関数呼び出しはオーバーヘッドが大きいという話をしましたが、本当にそうなのか示していないので軽く検証しておきます。
C/C++の各オペレーションにCPUクロックを何サイクル要するか推定した資料があります。この記事の図はいい目安になっていると思うので定数倍高速化を気にする競プロerの皆さんは頭に入れておいて損がないと思います。
この中では、「C function direct call」には15-30サイクルかかるとされています。
足し算などの「"Simple" register-register op」は<1サイクル、掛け算「Multiplication」は1-7サイクルで計算できることを考えると、関数呼び出しは遅いです。(ちなみに割り算「Integer division」は15-40サイクルと遅いです。MOD 998244353などを取りたいときにむやみに割りまくるのが遅いことは頭に入れておいたほうが良いです)
また、関数呼び出しでは引数やローカル変数などをスタック領域に押し込むため、メモリ効率も悪いです。
あまり深い再帰をやっているとスタック領域不足でStack Overflow Error(Segmentation Fault)を引き起こします。
実際に実験してみましょう。
AtCoder(GCC)のコードテストを用いてコードを実行し、実行時間と使用メモリを確認します。
ここでは、0からn=50000000までの整数のXORを求める計算を再帰と非再帰で比較します。
(余談ですが、足し算だとコンパイラによる最適化で真面目に計算しなくなるので検証には使えませんでした。Cコンパイラは偉い)
以下が再帰でのコードです。
#include <iostream>
const int n = 50000000;
int op(int n) {
if(n == 0) return 0;
return n ^ op(n-1);
}
int main() {
std::cout << op(n) << '\n';
}
そして以下が非再帰のコードです。
この計算なら配列を用意しなくても求めることができますが、再帰と似たような条件で自分で配列を用意したほうが省メモリなことを示したいのでstd::vectorを使っています。
#include <iostream>
#include <vector>
const int n = 50000000;
int op(int n) {
std::vector<int> dp(n + 1);
dp[0] = 0;
for(int i = 1; i <= n; i++) dp[i] = i ^ dp[i-1];
return dp[n];
}
int main() {
std::cout << op(n) << '\n';
}
結果は以下のようになりました。
| C++,n=5e7 | 実行時間 | 使用メモリ |
|---|---|---|
| 再帰 | 882 ms | 783992 KB |
| 非再帰 | 150 ms | 196128 KB |
5倍以上実行速度が変わることがわかります。
必要なメモリも4倍近く違っていて、n=100000000にすると再帰ではセグフォってしまいます。
一応Pythonでも検証しました
Pythonは再帰上限がデフォルトで1000しかないので、sys.setrecursionlimit(10**9)しています。
n=50000000はPythonでは流石にスタック領域的に厳しいので1000000に落としました。
| Python,n=1e6 | 実行時間 | 使用メモリ |
|---|---|---|
| 再帰 | 698 ms | 824372 KB |
| 非再帰 | 137 ms | 26640 KB |
| PyPy,n=1e6 | 実行時間 | 使用メモリ |
|---|---|---|
| 再帰 | 1353 ms | 972844 KB |
| 非再帰 | 76 ms | 33192 KB |
有名な事実なので詳しくは触れませんが、特にPyPyは再帰が苦手です。
以上から、再帰を乱用することは競プロでは時に死活問題であることがわかったと思います。
再帰アルゴリズムの構造
再帰アルゴリズムを非再帰に書き直すために、再帰が非再帰の視点から見てどのような順番で計算を行っているかを見ます。
引数の組み合わせをノードとしたグラフを張ります。
このグラフで引数Xに対応するノードから引数Yに対応するノードに辺が張られる必要十分条件を、「f(X)を計算する際にf(Y)が必要になってYを引数としてfを呼び出すこと」とします。
このグラフがループを持つ場合はf(X)の計算にf(X)が必要になってしまうため、一般に再帰アルゴリズムが成立するには上で定義したグラフがDAGであることが必要です。
ただし、ループが持っていても方程式
さて、再帰アルゴリズムは、
- 各ノードからの辺を張りながら深さ優先探索を行う
- できたDFS木をもとに、その帰りがけ順に計算する
と表現できます。
例として、パスカルの三角形の性質を利用して二項係数
再帰アルゴリズムを定義する漸化式は以下のようになります。
このアルゴリズムに対応するグラフは以下のようになります。
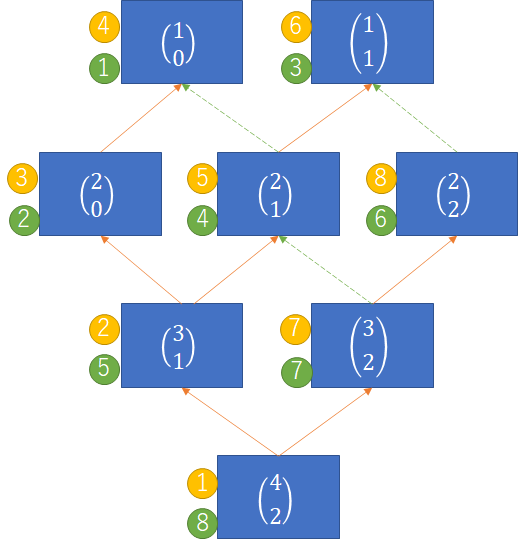
黄色の丸数字は行きがけ順です。この順に関数が呼び出され、深さ優先探索を行います。矢印はグラフの辺で、そのうち橙色の矢印がDFS木を構成しています。
緑色の丸数字は帰りがけ順で、この順番に二項係数が計算されます。
非再帰への書き換え(1) 行きがけだけでいい場合
帰りがけに計算するものがない場合、非再帰への書き換えは特に容易なのでまずはこれから押さえておきましょう。
例に使うのは、グラフの連結成分ごとの色分けです。
再帰だと以下のようなコードになります。
#include <vector>
void dfs(const std::vector<std::vector<int>>& graph, std::vector<int>& colors, int u, int c) {
for(int v : graph[u]) {
if(colors[v] != -1) continue;
colors[v] = c;
dfs(graph, colors, v, c);
}
}
std::vector<int> color(const std::vector<std::vector<int>>& graph) {
int n = graph.size();
std::vector<int> colors(n, -1);
int c = 0;
for(int i = 0; i < n; ++i) {
if(colors[i] != -1) continue;
colors[i] = c;
dfs(graph, colors, i, c++);
}
return colors;
}
非再帰だとこんな感じです。
#include <stack>
#include <vector>
std::vector<int> color(const std::vector<std::vector<int>>& graph) {
int n = graph.size();
std::vector<int> colors(n, -1);
int c = 0;
for(int i = 0; i < n; ++i) {
if(colors[i] != -1) continue;
colors[i] = c;
std::stack<int> stk;
stk.push(i);
while(!stk.empty()) {
int u = stk.top();
stk.pop();
for(int v : graph[u]) {
if(colors[v] != -1) continue;
colors[v] = c;
stk.push(v);
}
}
}
return colors;
}
一緒やろ???
そうなんです。一緒なんです。
DFSの関数の開始の代わりにスタックからポップするだけです。
DFSの関数呼び出しの代わりにスタックにプッシュするだけです。
それがわかってしまえば非再帰化なんて数行書き換えるだけなんですね。
これでだいぶん抵抗はなくなってきたと思います。
非再帰への書き換え(2) 返り値を使って計算したい場合
(1)では行きがけの探索だけで済む例を示しましたが、一般に再帰関数では返り値や呼び出し先で作成したデータを使って呼び出し元でさらに計算をすることがあります。
この場合は行きがけに加えて帰りがけのための情報もスタックにプッシュすることになります。
再帰の構造の説明に使った二項係数の計算を非再帰でやってみましょう。
木のDFSがスタックを用いて形式的に行うことができるのは先程示しました。
ここで帰りがけのタイミングでも計算を行いたい場合、通った頂点をスタックに積むときに先に帰りがけ用の情報もスタックに積んでおくことで実現できます。
行きがけのノードがスタックのトップから消えたとき、トップに帰りがけのノードが用意されていればそれをもとに戻ってくることができます。
具体的に実装例を見たほうが早いかと思うので、コードを与えます。
#include <stack>
#include <utility>
#include <vector>
int binomial(int N, int R) {
std::stack<std::pair<int, int>> stk;
stk.emplace(~N, R);
stk.emplace(N, R);
std::vector<std::vector<int>> table(N+1, std::vector<int>(N+1, -1));
while(!stk.empty()) {
auto [n, r] = stk.top(); stk.pop();
if(n >= 0) {
// 行きがけの処理(DFS木の作成)
if(r == 0 || r == n) continue;
int nr_list[] = {r-1, r};
for(int nr : nr_list) {
if(table[n-1][nr] != -1) continue;
stk.emplace(~(n-1), nr);
stk.emplace(n-1, nr);
}
} else {
// 帰りがけの処理 (計算)
n = ~n;
if(r == 0 || r == n) table[n][r] = 1;
else table[n][r] = table[n-1][r-1] + table[n-1][r];
}
}
return table[n_][r_];
}
スタックに積むデータの行きがけ用と帰りがけ用を区別するため、帰りがけ用はfirstをビット反転しています。
これは非再帰DFSではよくあるテクニックです。
ノードが非負整数で表されるとき、ビット反転を用いることで負の数もノード番号として活用することができ、行きがけと帰りがけの両方の情報を1つの整数で表すことができます。
余談ですが、スタックに詰める順番を工夫することでスタックの最大サイズ(再帰では最大深さ)が変動する場合もあります。
例えばフィボナッチ数列を計算するとき、
結構どうでもいいですがいつか役に立つかもしれません。
あるノードの先を探索し終わったときに動的に追加で辺が張られる場合も考えられますが、その場合は帰りがけ情報の代わりに通りがけ情報を詰めながら毎回スタックを見直す実装にする必要があります。
(そんなややこしい再帰アルゴリズムはめったにないと思いますが…)
非再帰への書き換え(3) トポロジカル順序が自明な場合
先程の例では再帰に比べて少し煩雑な実装になっていまいましたが、実際には自明な更新順があることが多いのでここまで面倒なことはならないことが多いです。
再帰アルゴリズムでは必ずDFS木の帰りがけ順に処理しますが、実際にはもとのDAGの辺を逆にしたものに対して、そのトポロジカル順序で更新すれば問題がないため、より高い自由度を持っています。
二項係数を求めるときのグラフの逆にも、自明なトポロジカル順序があります。
二項係数の漸化式では、1項目
したがって、逆辺では必ず1項目が真に大きくなるようになっています。
ここから、逆辺からなるグラフには、「1項目の小さい順(1項目が等しいものについて2項目の順番は問わない)」という自明なトポロジカル順序があることがわかります。
したがって、一項目の小さい順に計算すれば正しく計算できます。
少し考えれば使用するノードは
int binomial(int N, int R) {
std::vector<std::vector<int>> table(N+1, std::vector<int>(N+1));
for(int n = 1; n <= N; n++) {
for(int r = 0; r <= n; r++) {
if(r == 0 || r == n) table[n][r] = 1;
else table[n][r] = table[n-1][r-1] + table[n-1][r];
}
}
return table[N][R];
}
はい、とてもシンプルになりました。
まあどう見ても一般的な動的計画法なんですが、メモ化再帰の一般化とも言われる動的計画法の構成にこんな裏があったことを実感してもらえれば「どういう場合に動的計画法が組めるのか」の理解も深まるかなーと思います。
非再帰への書き換え(4) 複数の関数が組み合わさっている場合
発展問題として、複数の関数が組み合わさった再帰アルゴリズムの例も見ておきましょう。
いい例が構文解析です。
ここでは1桁の整数と+ * ()が混じった計算式の計算を例に見ます。
BNFで書くとこんな感じです。
<expression> ::= <term> | <expression> "+" <term>
<term> ::= <factor> | <term> "*" <factor>
<factor> ::= <number> | "(" <expression> ")"
<number> ::= "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9"
典型的な再帰での
#include <string>
using It = std::string::const_iterator;
int num(It&);
int factor(It&);
int term(It&);
int expr(It&);
int num(It& s) {
return *s++ - '0';
}
int factor(It& s) {
if (*s == '(') {
int ret = expr(++s);
++s;
return ret;
}
return num(s);
}
int term(It& s) {
int ret = factor(s);
while(*s == '*') {
++s;
ret *= factor(s);
}
return ret;
}
int expr(It& s) {
int ret = term(s);
while(*s == '+') {
++s;
ret += term(s);
}
return ret;
}
さて、これを素直に非再帰に書き換えるとどうなるでしょうか。
#include <cassert>
#include <stack>
#include <string>
#include <utility>
using It = std::string::const_iterator;
int expr(It& s) {
std::stack<std::pair<std::string, int>> stk;
stk.emplace("expr_first", 0);
while(1) {
auto [state, n] = stk.top();
if(state == "num") {
n = *s++ - '0';
stk.pop();
if(stk.top().first == "factor_return") stk.top().second = n;
else assert(0);
} else if(state == "factor") {
stk.top().first = "factor_return";
if(*s == '(') {
++s;
stk.emplace("expr_first", 0);
} else {
stk.emplace("num", 0);
}
} else if(state == "factor_return") {
stk.pop();
if(stk.top().first == "term_first" || stk.top().first == "term") stk.top().second *= n;
else assert(0);
} else if(state == "term_first") {
stk.top().first = "term";
stk.emplace("factor", 0);
} else if(state == "term") {
if(*s == '*') {
++s;
stk.emplace("factor", 0);
} else {
stk.pop();
if(stk.top().first == "expr_first" || stk.top().first == "expr") stk.top().second += n;
else assert(0);
}
} else if(state == "expr_first") {
stk.top().first = "expr";
stk.emplace("term_first", 1);
} else if(state == "expr") {
if(*s == '+') {
++s;
stk.emplace("term_first", 1);
} else {
stk.pop();
if(stk.empty()) return n;
if(stk.top().first == "factor_return") {
stk.top().second = n;
++s;
} else assert(0);
}
} else {
assert(0);
}
}
}
いやいやいやいや複雑すぎだろ!!!!!!!!!! と感じたそこのあなた、お使いの感覚は正常です。
一応軽く解説しておきます。
複数の関数があり、その関数の中で他の関数を呼び出す方法も複数種類あるものもあります。
再帰との対応は以下の感じです。
| state | 再帰アルゴリズムでの対応する状態 | nの値の意味 |
|---|---|---|
| number | number()が呼ばれたとき | 使用しない |
| factor | factor()が呼ばれたとき | 使用しない |
| factor_return | factor()からexpr()またはnumber()を呼び出して帰ってきた状態 | expr()やnumber()の結果が格納される |
| term_first | termの最初のfactorを読み出す状態 | factor()の結果が格納される |
| term | termの2つ目以降のfactorを読み出す状態 | factor()の結果が乗算されていく |
| expr_first | exprの最初のtermを読み出す状態 | term()の結果が格納される |
| expr | exprの2つ目以降のtermを読み出す状態 | term()の結果が加算されていく |
このようにスタックを持っておいて、実際に関数を呼び出すときのようにスタックのトップのnに結果を反映させながら読んでいきます。
同じアルゴリズムを非再帰の手続きに書き直すことができました。
まあ、さすがにここまでくると再帰のほうが楽ですよね。
構文解析は再帰でやるのが普通っぽいので再帰想定で作られた問題がほとんどなんじゃないかと思います。
どうしても非再帰じゃないとパフォーマンスが足りないとか言うときのために、力でねじ伏せることにも慣れておくといいとは思いますが…
余談ですが、私はJOI 2019/2020 2次予選-Eに出くわしたとき、「構文解析」という言葉すら知らないし「BNF」も「term」も聞いたことないというような状態でしたが、今のような非再帰スタック実装で殴っちゃいました。
やっぱりパワー系プログラミングに慣れておくことも重要ですね☆
おまけ:書き換えでなくとも、非再帰に優れたアルゴリズムが存在する場合
再帰という表現にはわかりやすくアルゴリズムを記述できるというメリットがあります。
その一方で再帰で書けるというのは束縛でもあって、その制約から離れることでよりシンプルなアルゴリズムになる場合があります。
以下は拡張ユークリッドの互助法のよくある再帰実装です。
(コードをけんちょんさんの記事からお借りしました。いつもありがとうございます。)
// 返り値: a と b の最大公約数
// ax + by = gcd(a, b) を満たす (x, y) が格納される
long long extGCD(long long a, long long b, long long &x, long long &y) {
if (b == 0) {
x = 1;
y = 0;
return a;
}
long long d = extGCD(b, a%b, y, x);
y -= a/b * x;
return d;
}
このアルゴリズムは高校数学の教科書にあるような一次不定方程式の解き方をまさに体現しています。
しかし非再帰実装では以下のようにも書けます。
#include <tuple>
#include <utility>
long long extgcd(long long a, long long b, long long &x, long long &y) {
x = 1, y = 0;
long long nx = 0, ny = 1;
while(b) {
long long q = a / b;
std::tie(a, b) = std::make_pair(b, a % b);
std::tie(x, nx) = std::make_pair(nx, x - nx*q);
std::tie(y, ny) = std::make_pair(ny, y - ny*q);
}
return a;
}
このアルゴリズムの詳しい説明は省きますが、概要は以下のとおりです。
最初に引数に与えられていたaをbを
セオリー通りユークリッドの互除法の手順で(a,b)->(b,a%b)を繰り返します。
このとき
互助法を進めると、最終的に
詳しくは熨斗袋さんの記事を見てください。
このようにアルゴリズムを工夫することで帰りがけの計算すら省略することができることもあります。
まとめ
再帰は全部非再帰に書き直せます。
この記事では構文解析のような複雑な例も敢えて紹介しましたが、単にグラフを探索したり木DP/全方位木DPをするだけのときは関数定義の部分の数行をスタック出し入れに書き換えるだけで非再帰にできることがほとんどです。
非再帰にするとメイン関数の中に堂々と書けますしパフォーマンスも出るので、非再帰に簡単に直せそうなら普段から非再帰で書くほうが安全です。
この記事を読んだ競プロerたちがよりよい非再帰ライフを送れることを切に願ってここで締めさせていただきます。

コメント