※2015.2.22に「変換プログラム開発」を追記しました
ゲームラボ2015年3月号54~59ページにおいて
『ドラクエ1に含まれているテキスト情報を抽出する方法』
=テキストコンバータを解説しています。
当コンテンツはそのアシストも含めて、これから挑んでみたい
初心者の方向けにテキストコンバータの作り方を解説します。
是非ともえりかとさとるの夢冒険くらい超ド級の
隠しメッセージが新たに見つかることを願います。
<あらかじめ覚えておくべきこと>
①ファミコンなどの旧作ゲームに格納された文章は変換が必要
PC用文字コード(シフトJISなど)は「半角”A”が16進数0x41」
「全角”あ”が16進数0xA082」のように共通仕様になっていますが、
ファミコンやスーパーファミコンなどの旧ハードでは独自仕様に
なっていることが多いため、大抵は解析しなければテキストを読めません。
②ゲームソフトが新しすぎるとテキスト変換がそもそも不要
PS2あたりになると普通にPCと同じ文字コードだったりします。
③暗号がかかっているとアウト
排他的論理和(XOR)マスク程度で外せる軽度なものなら大丈夫ですが、
シフトを組み合わせた高度なものやGZ圧縮などには太刀打ちできません。
ただし、エミュレータでゲームを走らせながらemuhasteなどでメモリダンプして
平文になった状態のデータを解析すると行ける場合があります。
④身につけた知識があらゆるゲームソフト解析の基礎になる
テキスト変換に成功し、アイテムリストやモンスターリストを生成できたら、
それを元にアイテムの売買価格リストやモンスター能力値リストも作れます。
攻略本または攻略サイト、TAS動画を作りたい人は学んでおいて損はありません。
<必要なもの>
①解析したいゲームソフト
元となるゲームが無ければそりゃムリでしょう。
②ゲームソフトをPCで読むための機器類
FCは「Kazzo」や「FC USB Adapter」。
SFCは「Superufo pro 8」あたりでROM吸い出し。
プレステやサターンはCDからファイルコピーで行けます。
③テキストコンバータ支援ツールGCCODE2
ウチのダウンロードページから落とせます。
④プログラミング環境
個人的にはVisual Studio(Visual C++)あたりがオススメですが、本項ではあえて
苦Cさんの学習用C言語開発環境 Ver 0.0.9.0「インストール不要なZIP版」を
使う想定で説明します(設定不要なのが楽で良いですね)。
<試しにSFCドラクエ5をGCCODE2で開いてみる>
gccode2を実行したらF1キーを押してDQ5のROMイメージを開く。
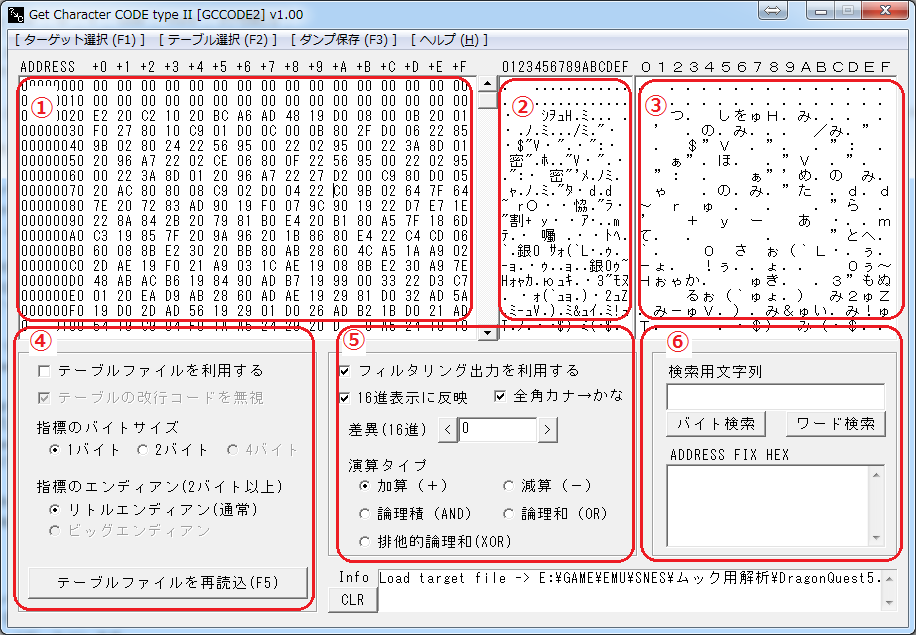
GCCODE2は6つの表示エリアから構成されており、それぞれを組み合わせて
テキスト情報を解析する仕組みですが、実際には3と6ばっかり使います。
①ヘキサダンプ
ROMイメージなどのデータを16進数表示するエリア。バイナリエディタ代わりに。
②アスキーダンプ
ヘキサダンプと同じアドレスにある情報をテキスト表示します。
③アスキー変換ダンプ
アスキー情報を半角→全角、カナ→かな変換して表示します。
④フォントテーブル設定
F2キーを押して後述の「テーブルファイル」を読み込んだ時のみ使います。
基本的にココを直接触ることはほとんどありません。
⑤フィルタリング出力設定
「フィルタリング出力を利用する」をチェックすると、②と③のテキスト枠が
ユーザ操作に基づいてリアルタイムに変動します。
「16進表示に反映」をチェックすると①のヘキサダンプの内容が変動します。
GCCODE2では「差異」と「演算タイプ」の組み合わせでテキスト変換を
実現しており、この項目がテキストコンバータの中核と言えますが、
実はユーザ自身で操作することはほとんど無いです。
⑥テキストサーチ機能
ゲーム中に表示されるメッセージ(テキスト)の一部を入力して検索すると、
その文字列の法則性を元にデータを解析し、差異を求めます。
操作の9割以上はココを触ることになります。
<SFC版ドラクエ5のモンスターリストを生成してみる>
SFC版ドラクエ5は独自文字コードを採用しており、ROMファイルを
バイナリエディタなどで開いてもサッパリ内容が読めません。
GCCODE2のテキストサーチ機能で差異情報を抽出すれば
ある程度読めるのですが、手順は下記の通りです。
①GCCODE2の検索用文字列に半角カナで「スライム」と入れて「バイト検索」
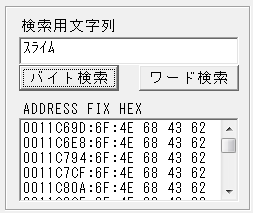
いくつか該当するので、一番上の 0011C69D の候補をダブルクリックする。
②運良く一発で「スライム」らしき情報がヒット
一番右上(Dの真下)に「すらいむ」が見つかり、差異6Fに自動でセットされる。
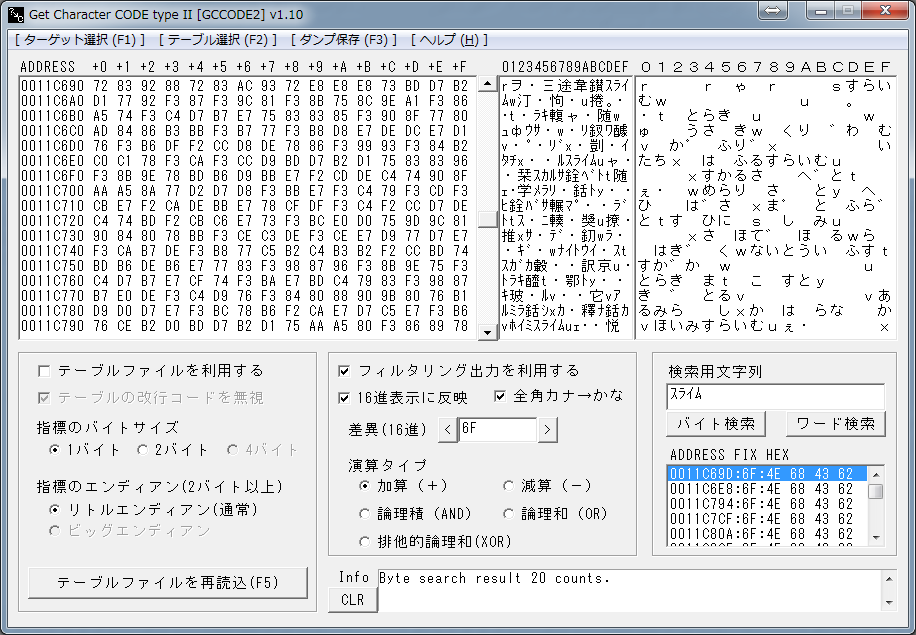
そのままだと読みづらいので「全角カナ→かな」のチェックを外して、
「すらいむ」→「スライム」のまま表示させてあげてもOK。
 こんな感じ。
こんな感じ。
~備考~
GCCODE2では検索単語を「文字同士の差」で検出しています。
シフトJISの半角カナ「スライム」を16進数表記すると BD D7 B2 D1 ですが、
この4つの値の差を求めると…
BD – D7 = -F6
D7 – B2 = +25
B2 – D1 = -E1
スライムは「4文字の間の3つの差が-F6、+25、-E1である」と見なします。
先ほどスライムを検索してヒットしたアドレスは0011C69Dですが、
16進表示に反映のチェックを外してこのアドレスの値を見ると…
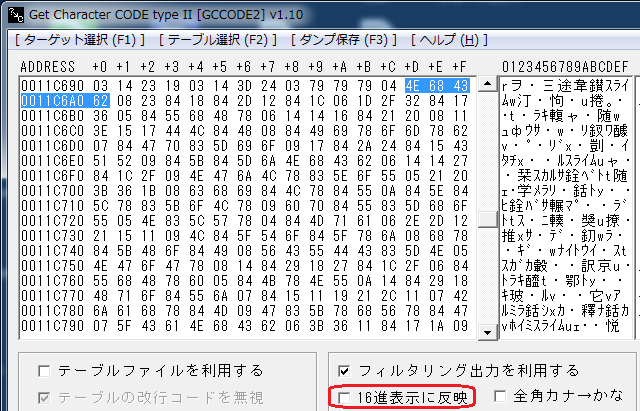
“4E 68 43 62″…これがDQ5における「スライム」の文字列データです。
先ほどと同じように差を求めてみると…
4E – 68 = -E6
68 – 43 = +25
43 – 62 = -E1
シフトJISのBD D7 B2 D1も、DQ5の4E 68 43 62も、
異なる数列(文字コード)ではあるけど、同じ意味を持つ、
と考えます。
そして、シフトJISの1文字目BDと、DQ5の1文字目4Eの差を求めると…
BD – 4E = 6F
これが先ほど「スライム」で検索した時に自動的にセットされた「差異6F」。
検索結果をダブルクリックすると、ヘキサダンプやアスキーダンプに
表示されるはずの内容に6Fを加算して出力するので、
「本来表示できないはずのDQ5の文字列が読める」のです。
(備考おわり)
③検索結果を見て少し考える
検索結果を見ると「バブルスライム」が「_ハ_フルスライム」になっていたり、
「スカルサーペント」が「スカルサ__ヘ゛ト」になっています。
(※スペースをアンダーバーで表現)
スライムとドラキー(トラキ)の間に不自然なスペースがありますが、
本来そこには「とげぼうず」と「せみもぐら」が入ります。
・「_ハ_フルスライム」になる理由
シフトJIS半角カナでは「ハ゛フ゛ルスライム」(濁点で1バイトを使う)になりますが、
DQ5は先に「次の文字に濁点を付与する(濁点のデータが文字より先」
という処理コードで表現され、濁点は16進数0x84で表現されています。
・「スカルサ__ヘ゛ト」になる理由
こちらもバブルスライムと同様に半濁点「゜」が0x83で表現されていますが、
「サーペント」の「横棒(ー)」とカタカナの「ン」の並びがシフトJISと
互換性が無いため、数値の差を求めても文字化けしてしまっています。
ちなみに横棒は0x78、カタカナの”ン”は0x6Fが割り当てられていました。
・「とげぼうず」と「せみもぐら」が見つからない理由
GCCODE2で検索した結果は、あくまで「シフトJISの半角カナとDQ5のカタカナ」
の差だけに過ぎません。
シフトJISには「半角ひらがな」は存在しないため、そちらは個別に
検索してやる必要があります。
④ついでに「ひらがな」も探してみる
先ほど「濁点のデータが文字より先」と特定できていますので、
「とげぼうず」は「と゛け゛ほう゛す」になると推測されます。
早速、GCCODE2にこの文字列を…入れられません。
DQ5はひらがなを1バイトで表現していますが、前述の通り
シフトJIS(PC)には1バイトでひらがなを表現する規格は無いです。
しかし、GCCODE2は「あくまで文字同士の差」で検索しますので、
ひらがなを調べるのにひらがなを使う必要はありません。
「と゛け゛ほう゛す」を調べるには半角カナ「ト゛ケ゛ホウ゛ス」で良いのです。
ただし濁点の文字コードもシフトJISと互換性が無いので、
ワイルドカード(半角ハテナ”?”)で「濁点を無視して検索」します。
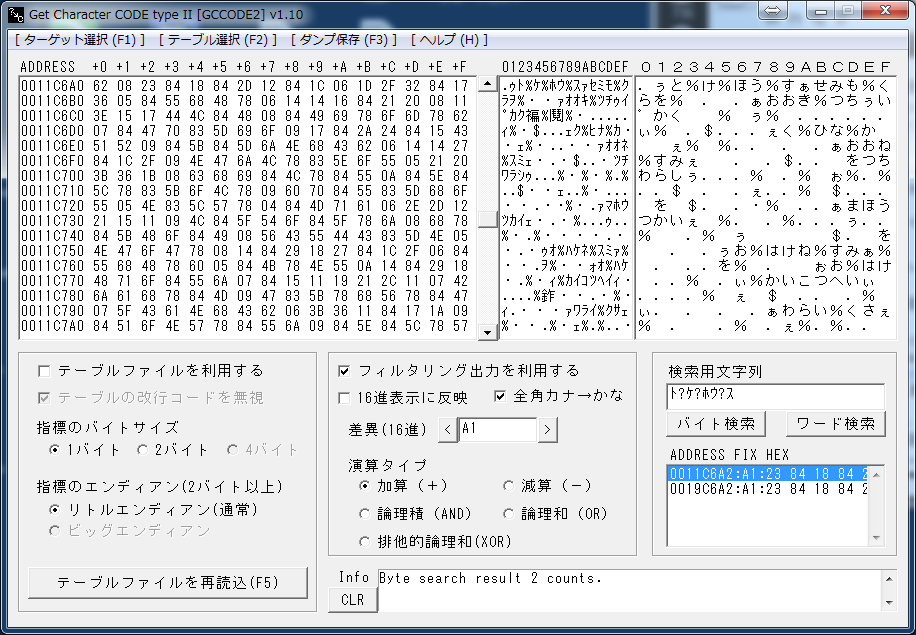
半角カナで「ト?ケ?ホウ?ス」。
この書式で「バイト検索」すれば、DQ5の濁点を無視して調べることができ、
上記結果では「アドレス0011C6A2に”差異A1″」で計算したものが、
DQ5のひらがな→シフトJISの半角カナ変換になります。
「全角カナ→かな」のチェックを入れておくとアスキー変換ダンプ出力が
「全角かな」に変換され、「と%け%ほう%す」と表示されています。
※こちらも濁点の差異がシフトJISと互換性が無いため”%”に化けてます。
ちなみに「互換性が無い文字を”?”で飛ばす」という考え方は、
GCCODE2ではあらゆるシーンに応用できます。
濁点・半濁点だけでなく「わをん」「やゆよ」「っゃゅょゎ」などの文字や、
記号、制御文字などを”?”で飛ばすことにより、ヒット率を高められます。
~備考~
プレステやサターンからはメモリ容量が潤沢になり「2バイト文字」を
使っている可能性が高くなります。
例えばプレステのモンスターファームは「あ=01 00、い=02 00…」
といった感じですね。
そこで注意が必要なのは、2バイト文字の検索時に
「ワード検索」を使ってもヒットしない場合がある、という点です。
GCCODE2のワード検索は「シフトJISの全角と互換性がある文字」を探すので
2バイト文字で「あいうえお…」と定義されている場合はヒットしません。
(シフトJISは「ぁあぃいぅうぇえぉお」の順で定義されています)。
GCCODE2で「独自2バイト文字」を検索したいのであれば
「スライム」なら、半角で「ス?ラ?イ?ム」と検索することで
「2バイト文字の2バイト目をワイルドカードで無視する」
といった対応が必要になります。
(備考おわり)
<フォントテーブルを作る>
これまで説明したように「差異」を用いれば多くの文字を変換できますが、
ワイルドカードで飛ばさなければならない文字を個別に処理するのは
かなり面倒です。
GCCODE2で差異変換した文字を見ていると、DQ5の場合は
「あ」が16進数0x10、「い」が0x11…と連続していることに気づきますが、
この0x10や0x11をテーブルの番地として使うという考え方があります。
イメージはこんな感じ。
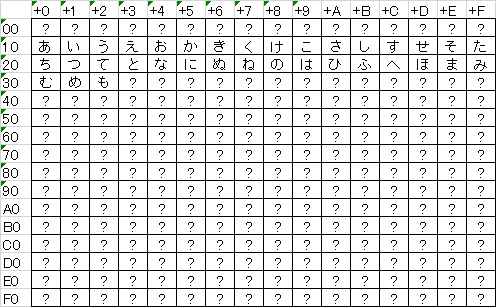
0x00~0x0Fの内容は不明ですし、「や行」以降のレイアウトもこの段階では
不確定なので「ま行」までしか入っていませんが、
DQ5で”0x10″が出てきたら、上の表から「あ」を拾って表示する…
このような処理を行うのがGCCODE2の「テーブルファイル機能」です。
フォントテーブルのファイル書式は「単に文字を並べるだけ」です。
1文字目は0x00、2文字目は0x01、3文字目は0x02…を意味するので、
上のフォントテーブルの場合は0x00~0x0Fの16文字を全角「?」で埋めて
17文字目から「あいうえおかきくけこさしすせそたちつてと…」と並べて、
「も」から先の0x33~0xFFの204文字分の全角「?」で埋めればOK。
ただし上記のように「?」で埋めると後々の解析が大変なので、
本気でフォントテーブルを完成させたい場合は、
どの文字が入るか分からない場所に16進数2桁で番地を書きます。
DQ5では0x00~0x0Fが不明なので
“000102030405060708090A0B0C0D0E0Fあいうえお…”
といった感じです。
よくわからない人は下記ファイルをダウンロードして下さい。
Download : dq5_a-mo.txt (右クリックして保存する)
GCCODE2でF1キーを押してDQ5のROMを開いたら、検索などを行わずに
F2キーを押してテーブルファイル読み込みで dq5_a-mo.txt を開き、
試しに「とげぼうず」が該当したアドレスに移動してみると…
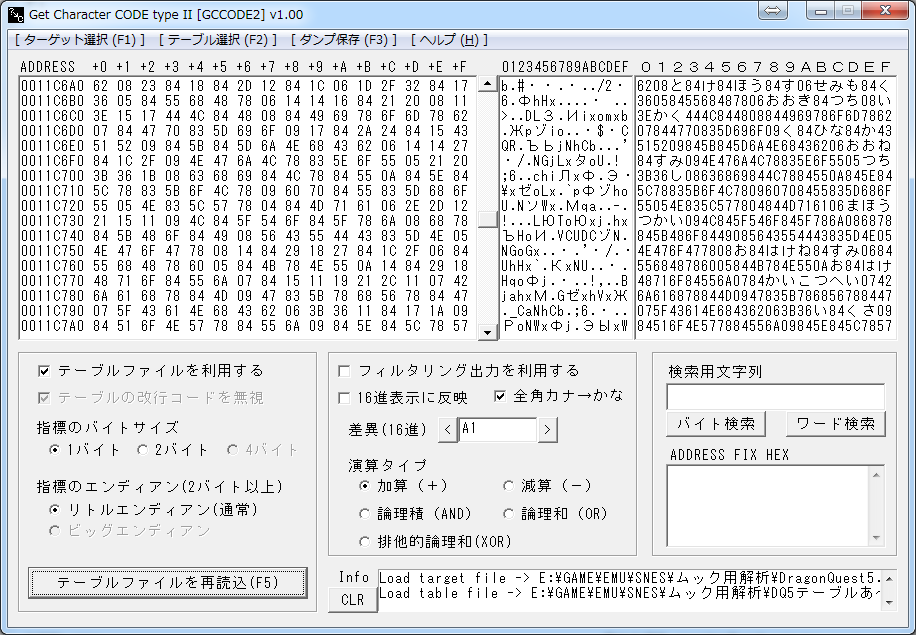
こんな感じ。フォントテーブルの不確定文字に番地名を入れておくことで、
と84け84ほう84す(とげぼうず) … 濁点は0x84。
と84くうせ3Dし(どぐうせんし) … 「ん」は0x3D。
くさ3Eたしたい(くさったしたい) … 「っ」は0x3E。
さま35う353Aい(さまようよろい) … 「よ」は0x35、「ろ」は0x3A。
このように絞り込みながらフォントテーブルの不明箇所を穴埋めします。
実用レベルになるまで穴埋めを繰り返したのが下記テーブルファイルです。
Download : dq5table.txt (右クリックして保存する)
これをF2キーでロードするとこんな感じ↓

モンスターの直前に2桁の数字がありますが、これは文字ではなく
「モンスター名の文字数」を表しています。
ここまで解析が進めば次のステップに移行しても良いでしょう。
<実際にテキストコンバータを作る>
これまでの解析で、SFC版DQ5の場合は…
「モンスター名はアドレス0011C69Cから始まる」
「濁点や半濁点は文字よりも先」
「モンスター名の直前に文字数が入る」
などの法則性と共にフォントテーブルも出来上がっている状態です。
ということは
「アドレス0011C69Cからモンスター名の文字数+モンスター名を読み込み、
フォントテーブルと照らし合わせて変換後のモンスター名を出力」
できれば、テキストコンバータ完成となります。
~ここから2015.2.22追記~
ここで登場するのが
開発環境 : 学習用C言語開発環境 Ver 0.0.9.0
テキストコンバータ完成品 : sfcdq5mon.zip
はい出来上がり!!!
…というのは冗談で、下記手順でコンパイル可能な状態まで進行しましょう。
1.「学習用C言語開発環境」のzip版を展開して EasyIDEC フォルダを生成。
AD広告が嫌いな人は Softad.dllをこの時点で削除しておく。
2.SFC版DQ5モンスターリスト生成プログラム sfcdq5mon.zip を展開。
3.EasyIDECフォルダ内にあるprojectフォルダに展開したsfcdq5monフォルダをコピー。
4.開発環境EasyIDEC.exeを実行。
5.「プロジェクト」のタブから sfcdq5mon をダブルクリック→OK。
↓これで、こんな感じでソースコードが開きます。
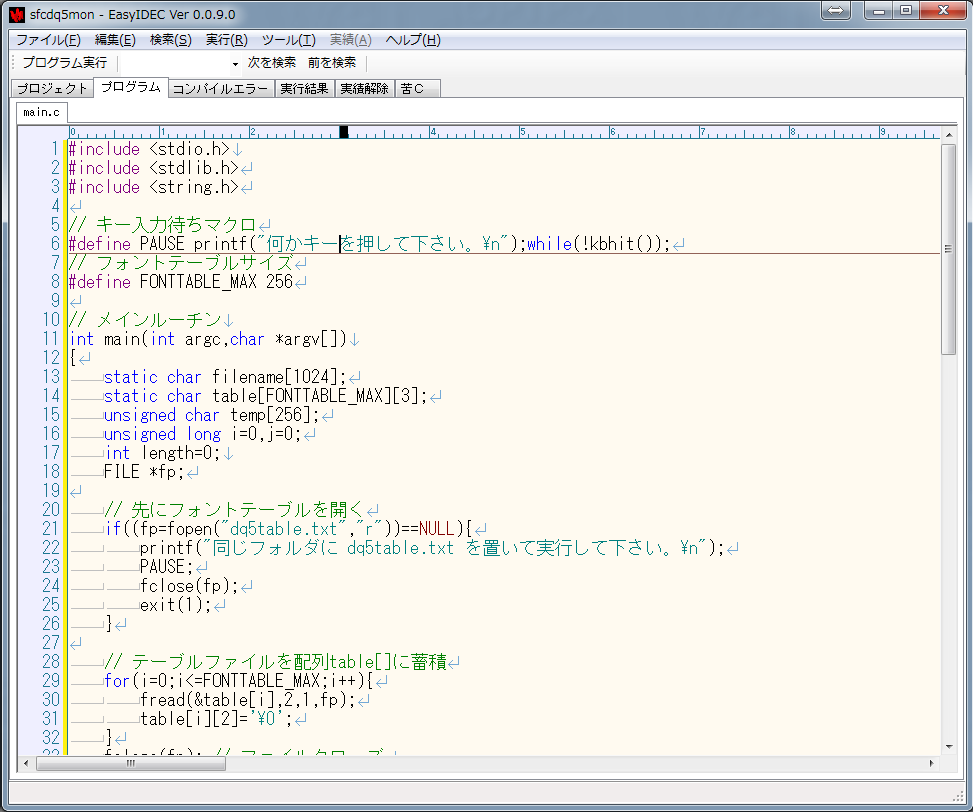
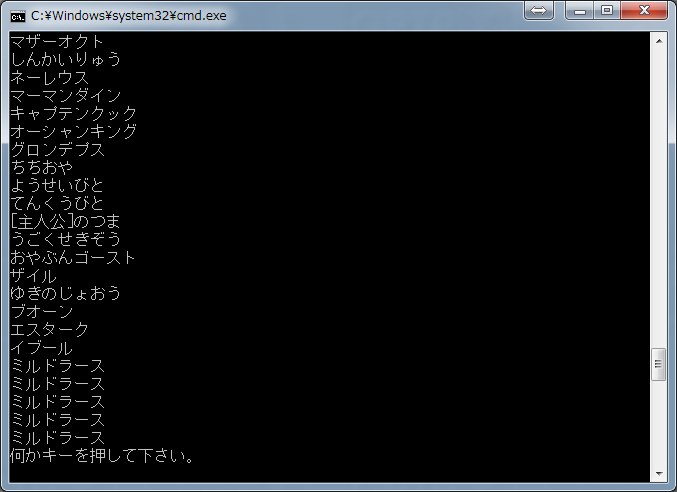
これでF5キーを押せばプログラムが起動するのでコマンドプロンプト画面に
DQ5のROMイメージを投げ込めばテキストアウトでモンスター名が出力されます。
<ソースコードについて解説>
SFC版DQ5をテキスト変換ターゲットとしているものの、実質「テンプレート」に近いです。
大多数のテキストコンバータに流用出来るはずなので
「こんなクソ汚いコード使えるか!」という人以外はご活用下さい。
・プリプロセッサ
// キー入力待ちマクロ
#define PAUSE printf(“何かキーを押して下さい。\n”);while(!kbhit());
// フォントテーブルサイズ
#define FONTTABLE_MAX 256
とりあえずソースコードでPAUSE;を書く都度にキー入力待ちする仕様に。
サイズも自動検知ではなく文字数を手動指定で。
・フォントテーブルを開く
if((fp=fopen(“dq5table.txt”,”r”))==NULL){
printf(“同じフォルダに dq5table.txt を置いて実行して下さい。\n”);
PAUSE;
fclose(fp);
exit(1);
}
同フォルダに dq5table.txt が無ければエラー終了する仕様。
・開いたテーブルを配列にロード
for(i=0;i<=FONTTABLE_MAX;i++){
fread(&table[i],2,1,fp);
table[i][2]=’\0′;
}
fclose(fp); // ファイルクローズ
二次元配列table[0][]~table[255][]まで全角文字を256回ロードします。
本来はfread()の返り値を読んで終端検知したほうが安全です。
この段階でテーブルファイルを閉じます。
・プログラムをそのまま実行した場合はscanf()でROMファイル名を入力させる
if(argc==1){
printf(“SFC版DQ5のROMファイルをココにドロップしてENTERキーを押す:”);
scanf(“%s”,filename);
}else{ // 引数指定の場合はargv[1]からコピー
strcpy(filename,argv[1]);
}
ドロップして~…と書いているのは、コマンドプロンプトが
「ファイルをドロップしたらフルパスを入力してくれる仕様」
なのであえてそう表記しています。
・ROMファイルを開く&指定アドレスへの移動
if((fp=fopen(filename,”rb”))==NULL){
printf(“DQ5のROMファイルを開けません。\n”);
PAUSE;
fclose(fp);
exit(1);
}
// モンスター情報のアドレスに移動
fseek(fp,0x11C69C,SEEK_SET);
先ほど引数指定またはドロップしたファイルを開き、失敗したらエラー終了。
テキスト格納アドレスまでfseek()で移動します。
・モンスター236匹分をテキストコンバート
for(i=0;i<=235;i++){
length = getc(fp); // モンスター名の文字数
fread(temp,length,1,fp); // モンスター名をリード
for(j=0;j<length;j++){
// リードした内容に応じて処理を切り替え
switch(temp[j]){
case 0x7A:
printf(“[主人公]”);
break;
case 0x83: // 半濁点
j++; // 次の文字に進めて
// シフトJISの濁点は+2なので2バイト目を+2して出力
printf(“%c%c”,table[temp[j]][0],table[temp[j]][1]+2);
break;
case 0x84: // 濁点
j++; // 次の文字に進めて
// シフトJISの濁点は+1なので2バイト目を+1して出力
printf(“%c%c”,table[temp[j]][0],table[temp[j]][1]+1);
break;
default:printf(“%s”,table[temp[j]]);break;
}
}
printf(“\n”); // モンスター名ごとに改行
}
もし文字変換だけであればもっとシンプルなプログラムになりますが、
大抵のゲームは「テキスト以外の数値」が含まれており、個別処理が必要です。
SFC版DQ5の場合は「濁点0x84や半濁点0x83が先」「主人公名もコード0x7Aで処理」
などの個別処理が必要であるため、switch()による分岐を行っています。
<他のゲームにソースコードを流用する場合>
許可は要らないのでガンガン改造して流用して頂いてOKです。
他にゲーム用に修正しなければならない箇所は大体下記の通り。
1. フォントテーブルサイズ FONTTABLE_MAX 256 の文字数。
2. テーブルファイル名”dq5table.txt”を修正。
3. “SFC版DQ5のROMファイルをココにドロップ~”のメッセージを変更。
4. “DQ5のROMファイルを開けません。”のメッセージを変更。
5. fseek(fp,0x11C69C,SEEK_SET)のアドレスを変更。
6. 「モンスター236匹分」を適切な回数に変更。
7. switch()の分岐条件の値を変更。
今回はテスト出力なので単なるprintf()でモンスター名を吐いていますが、
もっとちゃんと出力するのであれば別のファイルポインタを定義して
テキストファイルに出力するなどの対処が必要です。
◇◇◇
残念ながら日本国内におけるテキストコンバータの需要は極めて少ないうえ、
その資料もほとんどありません。
当コンテンツを見た人の中から、チャレンジャーが現れることを期待しています。
ピンバック: テキストコンバータをつくろう2015先行公開 | Irregular child 2nd
ピンバック: GCCODE2 Ver 1.10 & テキストコンバータ追記 | Irregular child 2nd