

人手で競馬予想を行うのは限界があるため、機械学習を利用したい。
収集したデータの前処理の方法と特徴量の生成方法を教えて欲しい。
こんなお悩みを解決します。
前回は、データの収集方法について解説しました。
前回の記事を確認していない方は、以下の記事を参考にデータ収集を行っておいてください。
-


【Python】機械学習を用いた競馬予想【データ収集編】
続きを見る
今回は、前処理の方法と特徴量の生成方法について解説します。
実際にPythonの実装結果もあわせて記載していくので、興味がある方はぜひご覧ください。
効率良く技術習得したい方へ
短期間でプログラミング技術を習得したい場合は、経験者からフォローしてもらえる環境下で勉強することをおすすめします。
詳細は、以下の記事をご覧ください。
-


【比較】プログラミングスクールおすすめランキング6選【初心者向け】
続きを見る
今回の実装結果
今回の実装結果は、GitHubに掲載しています。
一部省略している箇所もあるため、全体像を把握したい方は、以下のリンクにアクセスしてください。
https://github.com/yuruto-free/machine-learning-keiba/tree/v0.3.0
また、Preprocess.pyだけは、以下を参照してください。
注意点・お詫び
今回は、前処理だけを記載しますが、先行してlightGBMという機械学習アルゴリズムを用いて学習・評価もしています。
しかしながら、結果は散々なもので、期待した性能は出ていません。
以降の内容は、実装時の備忘録として残しておきますが、期待する効果を出すためには、前処理の方法を考える必要があることが分かりました。
具体的な評価内容・評価結果を以下に掲載しておきます。項目 内容 機械学習手法で解く問題 1着から3着の馬を当てる 学習時の条件 各レースのうち、1着から6着までの馬の情報(当日のコースや過去の成績など)を用いる。
※学習時のデータのバランスを考慮し、7着以降は参照しないようにしています。
※動作確認のため、テストデータに対しても、候補を絞った上で予測させています。機械学習手法 lightGBMによる2値分類 学習用データ、評価用データ ・学習用データ:1884レース分(総レコード数:11306件≒1884[レース]*6[頭/レース])
・評価用データ:1010レース分(総レコード数:6058件≒1010[レース]*6[頭/レース])評価結果 再現率(正解ラベルが1着から3着となっている馬のうち、実際に1着から3着に入ると予測できた数の割合):50%
→勘で当てている状態(6頭のうち3頭を適当に当てているのと同じであるため)
このため、今回の内容は、実装時の参考程度の情報となります。
前処理の概要
今回は、以下のステップで前処理を行っていきます。
- レース結果、レース情報、払い戻し結果、馬の過去成績、血統情報に対し、情報抽出や無効値の処理などの整形処理を行う。
- レース結果・レース情報・血統情報をマージ後、各馬に対し、過去成績の集計結果を付与する。
- カテゴリ変数をラベルエンコーディングし、機械学習の入力に用いる特徴量を生成する。
各ステップの実施結果(参考)
各ステップにより得られた結果を以下に示します。
また、前回のスクレイピング結果と比較できるように、処理前後の画像を掲載します。
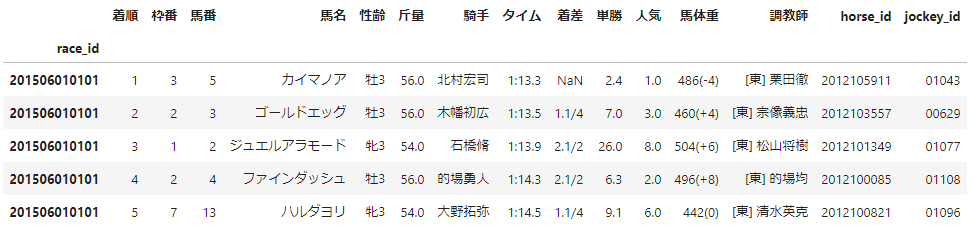
【整形処理】レース結果
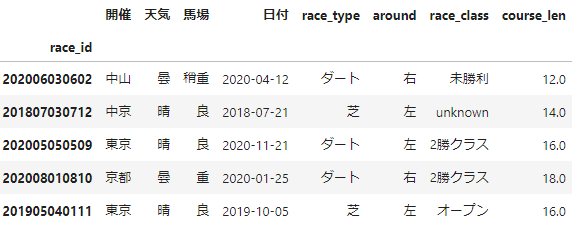
【整形処理】レース情報

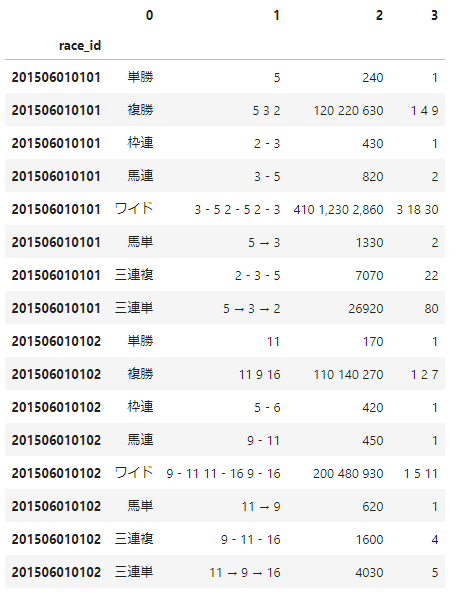
【整形処理】払い戻し結果
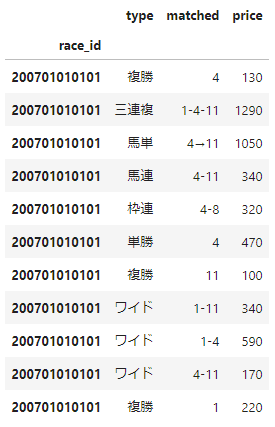
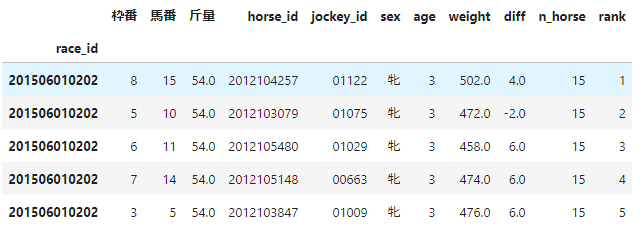
【整形処理】馬の過去成績


【整形処理】血統情報
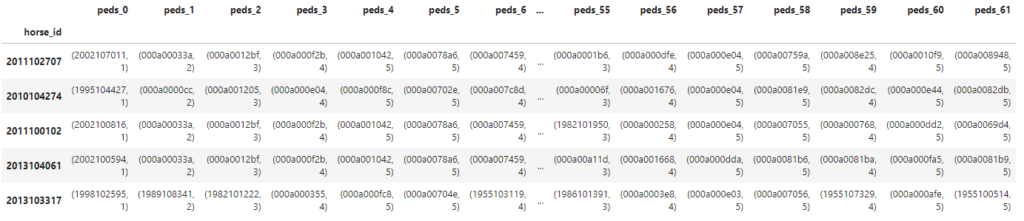
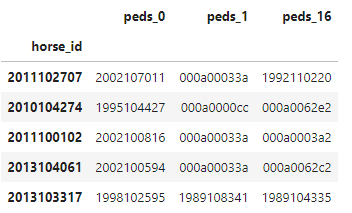
【マージ処理】レース結果・レース情報・血統情報の結合と馬の過去成績の集計結果のマージ
こちらは、新たに作成したデータとなるため、マージ処理後の結果のみ掲載します。

また、columnの情報は以下のようになります。

【特徴量生成】カテゴリ変数のラベルエンコーディング実施
今回は、lightGBMという決定木ベースのアルゴリズムを利用するため、カテゴリ変数の処理のみ行い、正規化等のスケーリング値処理は行いません。
実際に入力として利用する特徴量は以下のようになります。
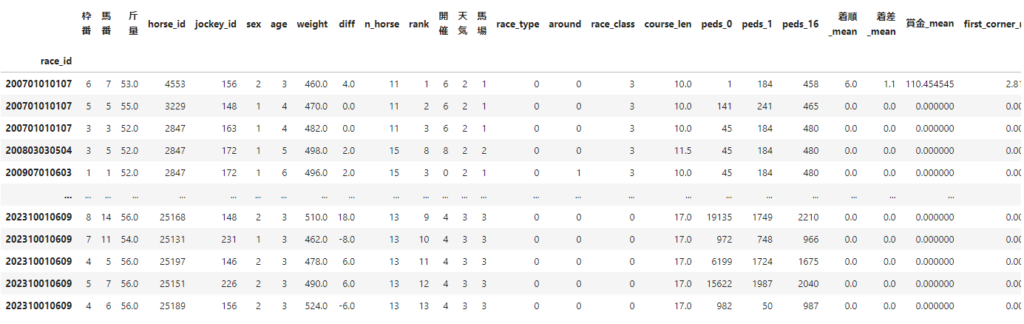
また、columnの情報は以下のようになります。

ディレクトリ構成
以降では、Pythonを用いて前処理を行うためのプログラムについて解説します。
まず、該当するプログラムを追加した後のディレクトリ構造は、以下のようになります。
以降では、処理の全体の流れを解説後、実装例と共に処理内容を解説したいと思います。
処理全体の流れ
まず、処理の全体の流れについて説明します。
別ファイルに分けている内容もあるため、参照する段階であわせて紹介します。
最初の7行目でインポートしているUserParams.pyは、以下のような内容であり、個別に設定する情報を定義しています。
また、Preprocess.py、DataManger.py、FeatureEngineering.pyの構成は、それぞれ以下のようになります。
Preprocess.py
DataManager.py
FeatureEngineering.py
整形処理
次に、整形処理について解説します。
レース結果に対する整形処理
レース結果に対しては、以下の4点の処理を行います。
- 着順の無効値の削除と降着判定された場合も扱えるようにする。
- 性齢を性別と年齢に分割する。
- 体重を馬体重と体重変化に分割する。
- 処理に必要なcolumnを抽出する。
ここで、体重のcolumnは、以下のような形式となっているため、正規表現を利用することでデータを抽出できます。馬体重 486(-4) 460(+4) 504(+8)
pandasには、extractというメソッドが用意されており、対象のcolumnを正規表現のパターンに従って分割することができます。
具体例としては、以下のようになります。
先程例示した「体重の構成例」に対し、上記を実行すると、以下のようなDataFrameが生成されます。weight diff 486 -4 460 +4 504 +8
同様に、正規表現を用いることで、着順のうち、不適切なものを削除したり、降着判定されたものも正しく扱えるようになります。
また、1レースに出場する馬の数も重要な情報になると考えられるため、整形処理時に情報を追加します。
これは、race_idの数を数えることで実現でき、実装例は以下のようになります。
以上を踏まえてレース結果の整形処理を行った結果は以下のようになります。
【23/3/4追記】上記の処理の一部に問題が合ったため、修正いたしました。
修正内容は以下のようになります。
レース情報に対する整形処理
レース情報は、「-」区切りの1行の文字列として保存しているため、文字列から該当する情報を抽出する必要があります。
ここでは、_Extractorというクラスを作成し、このクラス内で抽出処理を行うような構成としました。
まず、_Extractorクラスの実装を以下に示します。
このクラスは、以下のような構成となっています。項目 内容 __name extractメソッドで抽出した際のDataFrameのcolumn名 __pattern 抽出時に用いる正規表現のパターン __callback 抽出後にDataFrameに対して実行する処理 extract 与えられた文字列に対し、抽出処理を行うメソッド
次に、_Extractorクラスを用いて、レース情報のDataFrameを構築していきます。
スクレイピング結果のレース情報は、以下のようになっているため、これに対して正規表現を割り当てていきます。
上記の例を用いて、抽出したい情報、該当箇所、正規表現パターンの例、callbackの例を以下に示します。抽出したい情報 該当箇所 正規表現パターンの例 callbackの例 開催場所 中山 '札幌|函館|福島|高知|佐賀|荒尾|' - 天気 曇 '晴|曇|小雨|雨|小雪|雪' - 馬場状態 稍重 '良|稍重|重|不良' - 日付 2020年4月12日 '\d+年\d+月\d+' 年or月を「-」に置換 レースタイプ ダート '芝|ダ|障' 「ダ」を「ダート」に置換 コースの回り方 右 '右|左|直線|障害' - レースクラス 未勝利 '新馬|未勝利|1勝クラス|2勝クラス|3勝クラス|オープン|障害' - コースの長さ 1200m '\d+m' 末尾の「m」を削除・スケーリング値
正規表現パターンに示した情報は、Constants.pyに定義しているため、この情報を用いることで必要な情報を抽出できます。
以上を踏まえた実装例は以下のようになります。
払い戻し結果に対する整形処理
払い戻し結果は、ワイドと複勝が文字列結合された状態で保存されているため、分解して扱えるように整形する必要があります。
スクレイピング結果と整形後のイメージは、以下のようになります。(race_idは省略しています)0 1 2 3 単勝 5 240 1 複勝 5 3 2 120 220 630 1 4 9 枠連 2 - 3 430 1 馬連 3 - 5 820 2 ワイド 3 - 5 2 - 5 2 - 3 410 1,230 2,860 3 18 30 馬単 5 → 3 1330 2 三連複 2 - 3 - 5 7070 22 三連単 5 → 3 → 2 26920 80 type matched price 単勝 5 240 複勝 5 120 複勝 3 220 複勝 2 630 枠連 2-3 430 馬連 3-5 820 ワイド 3-5 410 ワイド 2-5 1230 ワイド 2-3 2860 馬単 5→3 1330 三連複 2-3-5 7070 三連単 5→3→2 26920
上記の処理は、「複勝・ワイド」だけ個別に処理し、最後に結合すれば実現できます。
実装例は以下のようになります。
【23/3/4追記】上記の処理の一部に問題が合ったため、修正いたしました。
修正内容は以下のようになります。
馬の過去成績に対する整形処理
馬の過去成績は、以下に示すように、レース結果と似たような処理を行います。
- 着順の無効値の削除と降着判定された場合も扱えるようにする。
- 性齢を性別と年齢に分割する。
- 体重を馬体重と体重変化に分割する。
- 無効値を削除する。
- 「通過」情報からコーナーを算出する。
- 処理に必要なcolumnを抽出する。
ここでは、新規に登場した「通過」情報について解説します。
「通過」情報は、以下のようなフォーマットになっています。(horse_idは省略しています。)通過 13-14 14-14-12 10-10-9-8
馬の過去成績によって、フォーマットが異なるため、ここでは「最初の通過順位」、「最後の通過順位」、「通過順位の平均」の3つを算出します。
上記の例で集計した結果を以下に示します。最初の通過順位 最後の通過順位 通過順位の平均 13 14 13.5 14 12 13.3 10 8 9.25
上記を踏まえた実装例は以下のようになります。
【23/3/4追記】上記の処理の一部に問題が合ったため、修正いたしました。
修正内容は以下のようになります。
血統情報に対する整形処理
血統情報に関しては、遠い祖先の遺伝子情報は現世に大きな影響を与えないと仮定して処理を行います。
具体的には、何親等まで対象とするかを決めておき、該当する箇所のみ残す、という処理を行いました。
今回は、ヒューリスティックに定義し、2親等まで残すことにしております。
何親等になるかは、スクレイピング結果を格納する際に合わせて定義しているため、その定義結果を参照する構成となっています。
上記を踏まえた実装例は以下のようになります。
マージ処理
次に、マージ処理について解説します。
マージする際のステップとしては、以下のようになります。
- レース結果とレース情報を結合する。
- horse_idを基準に1.の結果と血統情報を結合する。
- horse_idとレース開催日ごとに、該当する馬の過去成績を集計し、集計結果を結合する。
1.と2.は、pandasのmergeメソッドを用いることで実現できますが、3.に関しては、自前で実装する必要があります。
このため、ここでは、馬の過去成績の集計方法について解説します。
馬の過去成績に対する集計処理
集計は、以下の手順で実施します。
- horse_idとレース開催日をグループ化する。
- 馬の過去成績から、該当するhorse_idとレース開催日以前の情報を取得する。
- 事前に与えた条件(下記参照)に従い、集計する。
条件:UserParams.pyのTARGET_COLUMNSとGROUP_COLUMNS
例えば、2023年1月28日の東京で開催されたレース結果(race_id: 202305010111)を参照すると以下のようになっています。(一部省略、一部説明のため情報を追加)開催 race_type course_len horse_id jockey_id rank 東京 芝 2000m 2019105207 05339 1 東京 芝 2000m 2019104896 00666 2 東京 芝 2000m 2019100596 01115 3 東京 芝 2000m 2018104579 05386 4 東京 芝 2000m 2016104319 01179 5 東京 芝 2000m 2018104788 05212 6 東京 芝 2000m 2015104724 01122 7 東京 芝 2000m 2016103730 01092 8 東京 芝 2000m 2016100550 01043 9
今回は、このうち、7着目の「2015104724」に着目して解説します。
horse_idが2015104724の馬に対し、過去の成績を取得すると、以下のようになります。(一部省略、一部説明のため情報を追加)日付 開催 馬場 着順 着差 上り 賞金 race_type course_len first_corner final_corner mean_corner 2023-01-28 東京 良 7 0.8 34.1 0.0 芝 2000m 10 9 9.33 2022-10-30 阪神 良 13 1.0 33.8 0.0 芝 1800m 15 11 13.00 2022-08-14 小倉 良 15 3.1 37.6 0.0 芝 2000m 4 14 7.50 2022-07-24 小倉 良 9 0.5 34.2 0.0 芝 1800m 11 10 11.75 2022-06-18 阪神 良 14 1.5 34.9 0.0 芝 1600m 15 15 15.00 2022-05-07 新潟 良 5 0.5 32.6 250.0 芝 1600m 11 11 11.00 2022-03-06 阪神 良 7 1.1 35.1 0.0 芝 1800m 6 6 6.00 2022-02-20 小倉 稍重 8 0.8 36.3 0.0 芝 1800m 6 5 5.75 2021-12-05 阪神 良 1 -0.3 34.0 1838.2 芝 1800m 6 6 6.00 2021-11-13 阪神 良 8 1.0 36.5 0.0 芝 2000m 6 5 5.75
過去の成績を集計する際は、2023年1月28日以前の結果を取得する必要があります。
今回の場合、上記のテーブルの2行目以降が集計対象となります。
集計対象が定まったら、後は、以下の表にある情報を対象に集計(平均値の算出)を行います。
| 対象・区分 | Pythonスクリプトでの変数名 | DataFrame上での名称 |
| 集計対象のcolumn | LAST_TIME | 上り |
RANK | 着順 | |
RANK_DIFF | 着差 | |
PRIZE | 賞金 | |
first_corner | first_corner | |
final_corner | final_corner | |
mean_corner | mean_corner | |
| グループ化して集計する対象 | race_type | race_type |
course_len | course_len | |
PLACE | 開催 |
また、今回は、以下の2パターンで集計しています。
- 「集計対象のcolumn」で指定したcolumnのすべての範囲に対し、平均値を算出する。
- 「グループ化して集計する対象」で指定したそれぞれのcolumnに対し、今回と同じケースに限定して平均値を算出する。
1つ目の集計方法
このケースでは、「集計対象のcolumn」に挙がっている項目をそれぞれ集計していきます。
上記のケースでは、以下のように平均値を算出できます。集計対象のcolumn(DataFrame上での名称) 平均値 上り 35.00 着順 8.889 着差 1.022 賞金 232.022 first_corner 8.889 final_corner 9.222 mean_corner 9.083
2つ目の集計方法
2つ目の集計方法は、馬の過去成績に対して集計範囲がさらに限定された状態で集計することになります。
まず、2023年1月28日の情報から、「グループ化して集計する対象」は以下のように対応付けられます。グループ化して集計する対象 内容 race_type 芝 course_len 2000m PLACE 東京
上記に対して、フィルタリングした上で集計することで、地形や距離に応じた得意・不得意を特徴として表現できると考えました。
例えば、race_typeであれば、「芝」となっているものだけをフィルタリングした後、1.と同様にすべての範囲に対して平均値を算出します。
提示したデータの都合上、ここではcourse_lenに対して、集計する例を示します。
馬の過去成績のうち、該当する箇所は以下の2か所となります。日付 開催 馬場 着順 着差 上り 賞金 race_type course_len first_corner final_corner mean_corner 2022-08-14 小倉 良 15 3.1 37.6 0.0 芝 2000m 4 14 7.50 2021-11-13 阪神 良 8 1.0 36.5 0.0 芝 2000m 6 5 5.75
上記の表に対して、「集計対象のcolumn」に対する集計を行うと、以下のようになります。集計対象のcolumn(DataFrame上での名称) 平均値 上り 37.050 着順 11.500 着差 2.050 賞金 0.000 first_corner 5.000 final_corner 9.500 mean_corner 6.625
少し長くなりましたが、これらを踏まえた集計処理の実装例は以下のようになります。
特徴量生成
最後に、特徴量生成について解説します。
特徴量生成では、カテゴリ変数(性別、開催場所、天気など)をラベルエンコーディングという方法を用いて数値情報に変換します。
また、horse_idをラベルエンコーディングする場合、血統情報も考慮する必要があるため、別途処理を分けています。
今回実装したメソッドの一覧を以下に示します。メソッド名 内容 備考 drop 指定したcolumnを削除する。 DataFrameのdropのラッパー dumminize 指定したcolumnをダミー変数化する。 今回は利用しない encode_jockey_id jockey_id をラベルエンコーディングする。 対応関係をmaster以下に保存 encode_horse_id horse_id をラベルエンコーディングする。 対応関係をmaster以下に保存 label_encoding 指定したcolumnをラベルエンコーディングする。 -
対応する実装結果は、以下のようになります。
上記の処理を呼び出すためには、以下のように呼び出し関係のテーブル(functions)を作成した上で、get_featuresメソッドを呼び出します。
functionsのフォーマットは、以下のようになります。
今回は、以上の操作を行って得られた結果を特徴量としました。
まとめ
今回は、機械学習を用いた競馬予想を行うための前処理の方法について解説しました。
機械学習に入力する情報となるため、特徴量の良し悪しが予測結果に大きく影響します。
このため、試行錯誤を繰り返して、有効な特徴量を定義していく必要があります。
以降では、機械学習手法まで一通り解説した後に、特徴量の見直しを行っていきたいと思います。
効率良く技術習得したい方へ
今回の話の中で、プログラミングについてよく分からなかった方もいると思います。
このような場合、エラーが発生した際に対応できなくなってしまうため、経験者からフォローしてもらえる環境下で勉強することをおすすめします。
詳細は、以下の記事をご覧ください。
-

【比較】プログラミングスクールおすすめランキング6選【初心者向け】
続きを見る
続きの記事を執筆しました。
-


【Python】機械学習を用いた競馬予想【モデル構築・評価編】
続きを見る

 HELP
HELP