


イーロン・マスクやマイクロソフトが出資するOpenAIが発表した、チャットできるAI「ChatGPT」が注目を集めている。公開からわずか6日目にして利用者が「100万ユーザを突破した」とサム・アルトマンCEOは公表した。
すごいという気もするが、話題の割にあんまりという印象もある。
どんな質問にもそれっぽく答えてくれるのだが、同時にChatGPTを持ち上げすぎるのはいつものように危険だと、「AI」の研究・開発をしてきた経験から筆者は考える。

AI研究者は知っているOpenAIの「ビッグマウス」
というのも、OpenAIはテキスト生成モデルの「GPT-2」の頃から「人間を超えたAIを開発してしまったのであまりにも危険」などという誇大広告とも言える主張を繰り返してきた「前科」がある。彼らが「あまりに危険すぎるためフル機能のものは公開できない」とまで言っていたGPT-3ですら、実際に使ってみるとそこまでの威力や説得力があるわけではない。
その点、ChatGPTはOpenAIとしてはほとんど初めて「すごい」という主張を裏付けるデモと同時公開されている点は、確かにこれまでとは異なる。
おそらくOpenAIとしての痛恨のミスは、「すごい」「危険」と煽るあまり、DALL-Eを出し惜しみした挙句、後発のStableDiffusionに話題を全部もっていかれてしまい、満を辞して開始したDALL-E2の有料サービスがイマイチ話題にならなかったことだろう。
そこで今回のGPT-3.5ベースと言われるChatGPTは、早急にデモと論文を同時公開してきた。
「すごさ」や「危険さ」はもはや実際に触ってみるまでわからないというのが本当のところだからだ。
ChatGPTが「すごい」と言われるのはどこか
では、まずはChatGPTが「すごい」と言われているところから確認してみよう。
「James, Alice, Anne, Bob, Kevin, Ericをアルファベット順で並び替えるプログラムをJavaScriptで書いてください」
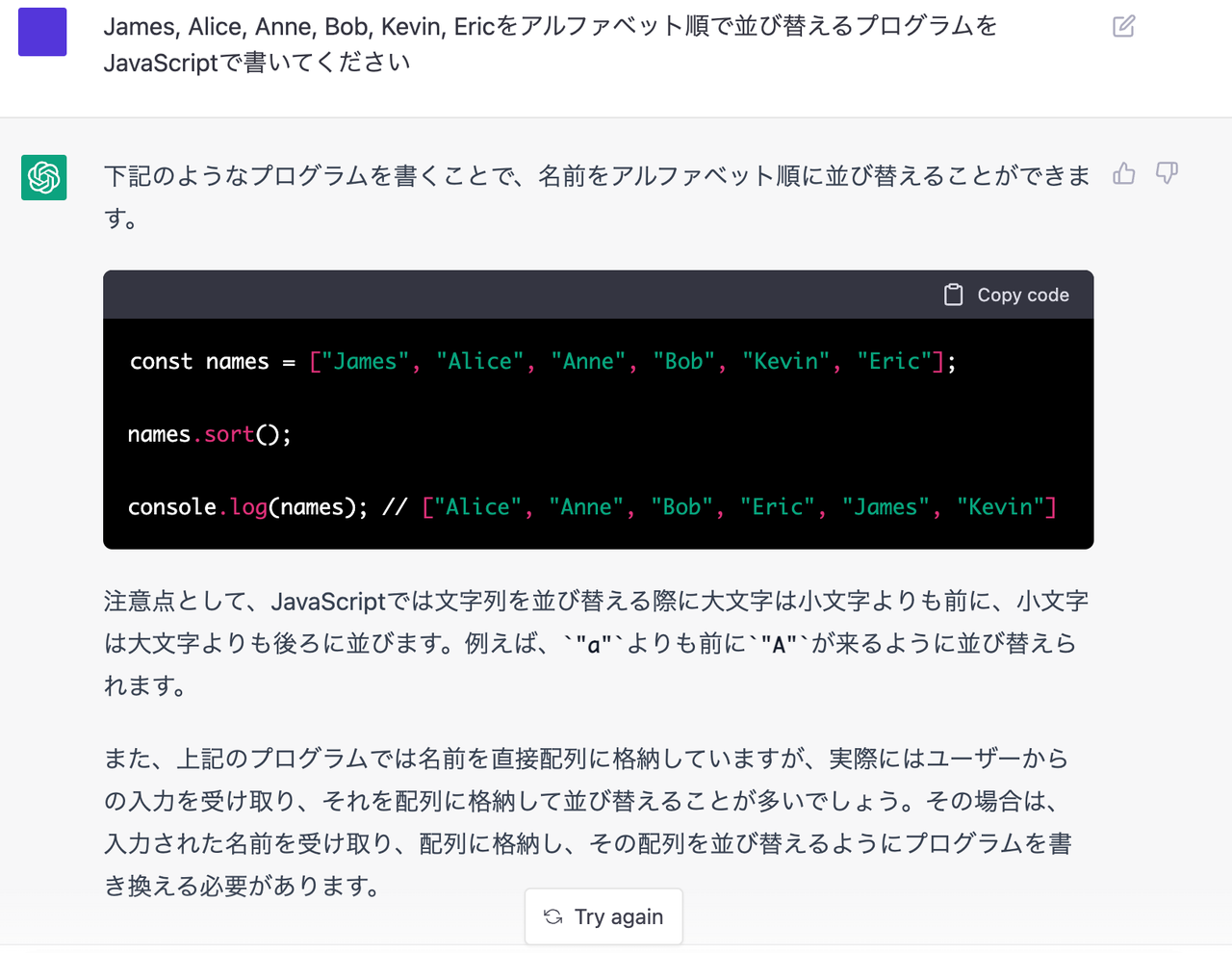
こういう、教科書的な問題はこともなげにこなす。
プログラムができない人から見ると、こんなふうにプログラムが解説とともに出てくるのをみて「すごい!」とビックリするかもしれない。
ただ、この程度のことは実はGPT-2(2019年発表)でもできていた。これでビックリする人というのは、AI研究者からすると感覚が3年遅れだ。
では、日本人の名前ならどうだろうか。
「山田、高橋、清水、樋口、相田、中本を五十音順で並び替えるプログラムをJavaScriptで書いてください」
まず、いきなりChatGPTは「私はプログラムを書くことはできません」という言い訳からスタートする……が、しかしプログラムを実際に書いている。
書いているのだが、出てきた結果は、まったく50音順になってない。
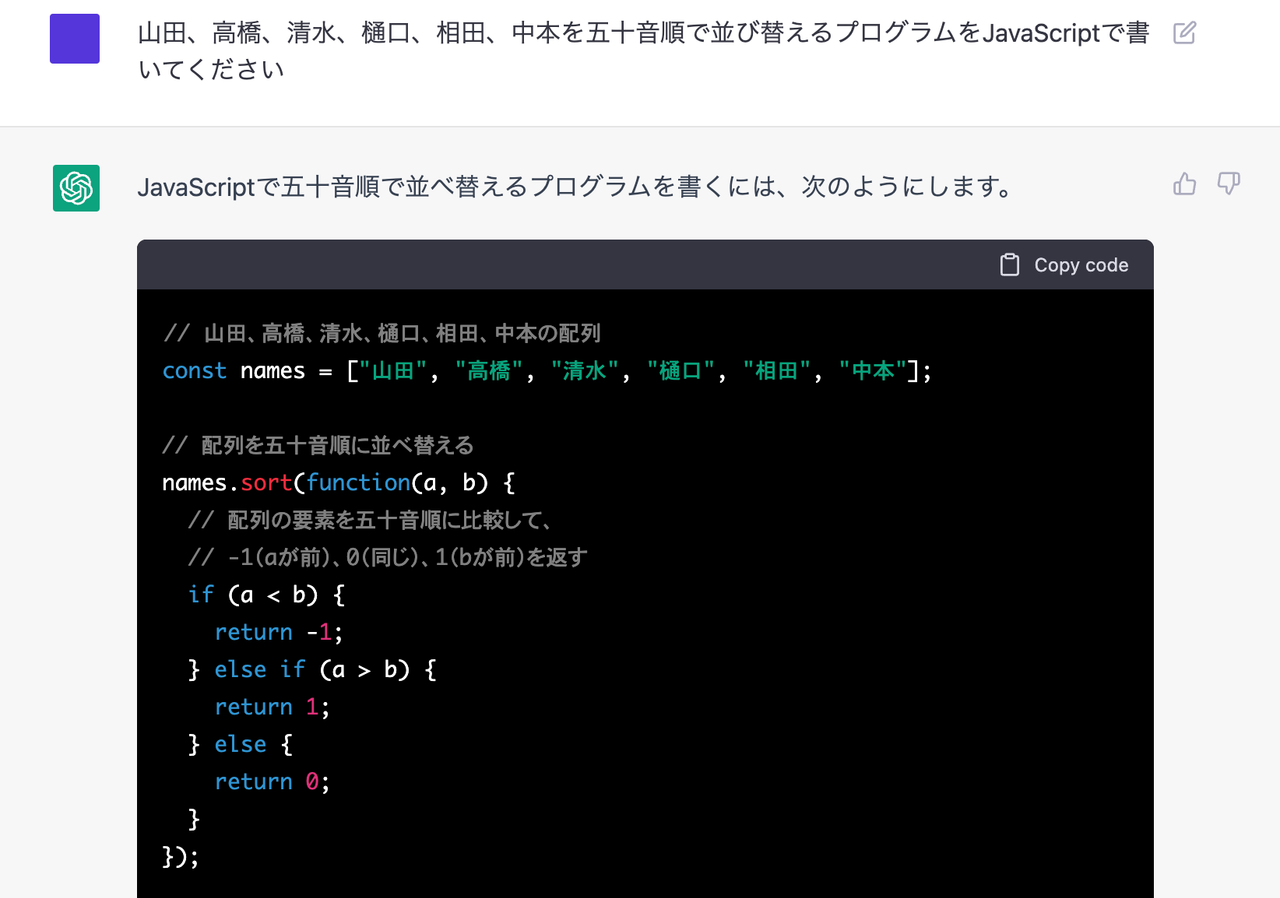
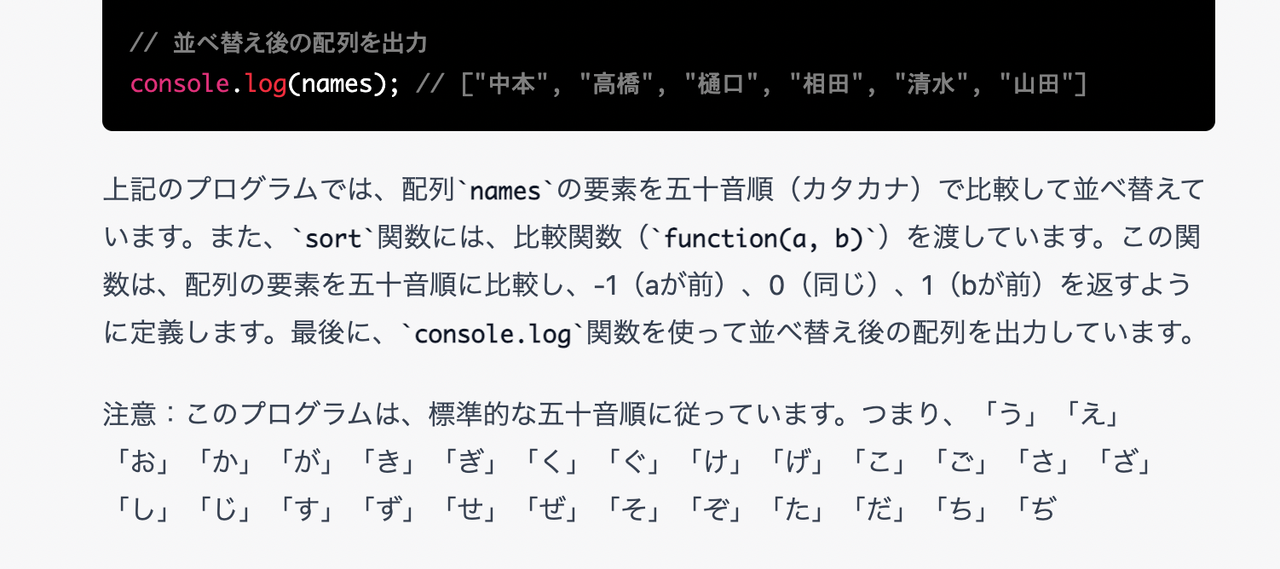
また、示された結果は「中本」「高橋」「樋口」「相田」「清水」「山田」の順に出てくるが、実際にこのプログラムを実行すると異なる結果になる。

そしてこれは全く、50音順ではない。
当然ながら、50音順にしたければ、そもそも「中本」を「なかもと」と読むとか、「山田」を「やまだ」と読むとかというフリガナの情報が重要になるが、ここではフリガナに関して一切考慮していない。
つまり、デタラメにそれっぽい答えが返ってくるだけだ、ということがまず確認できる。
もう少し深掘りしてみよう。
「ジュリア集合のプログラムをJavaScriptで書いてください」と聞いてみる。
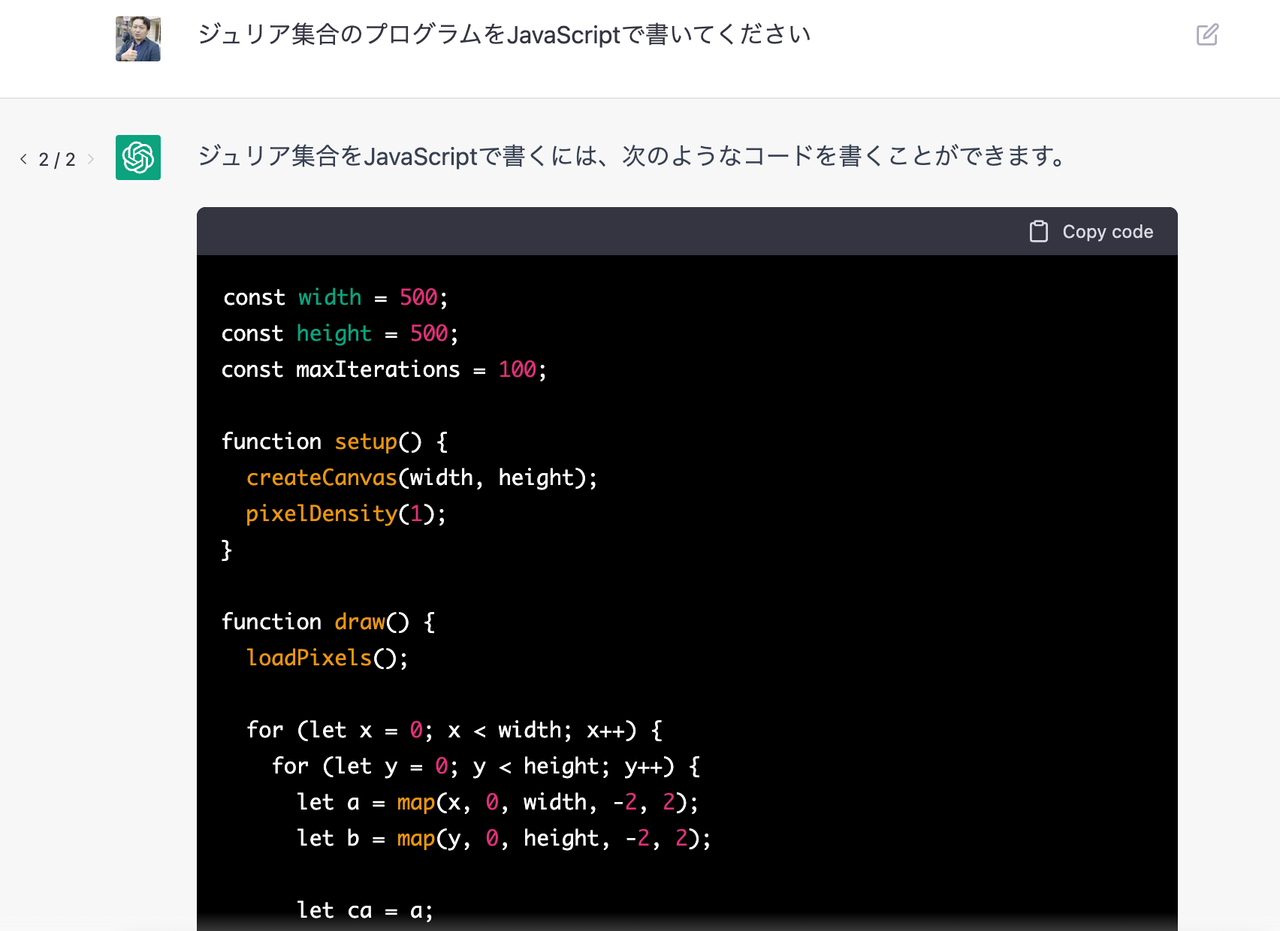
出てきたプログラムはそれだけでは動かなかったが、少し筆者の方で手を加えて動かしてみたらこうなった。

さっそく失敗している。これは「マンデルブロート集合」であって「ジュリア集合」ではない。

このように、ChatGPTは、一見きちんとしたプログラムを書くようだが、実際には「雰囲気でプログラミングのようなものを見せている」だけで、文字通り全く創造性がない。
創造性の必要な質問を与えてみると、それがわかる。
「サッカーワールドカップ2022の優勝国」を聞いてみよう。
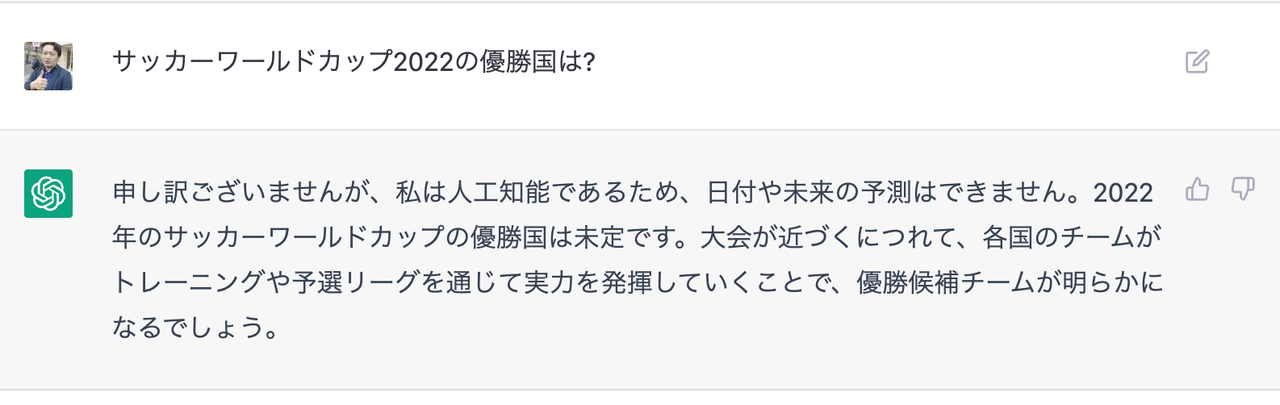
「人工知能であるため」は全く理由になってない。むしろ人々が期待するのは「人工知能であるから予測できるのではないか」ということだろう。
ChatGPTは、一見するともっともらしい答えを返せるように、うまく調整されている。
従来のGPT-2、GPT-3との明らかな違いは、ChatGPTはおそらく「初めて強化学習を取り入れた」点にある。これまで、会話に強化学習を導入する試みは行われてきたが、これほど大規模なものは初めてだっただろう。

なぜChatGPTがAI研究者目線では「そこまですごくない」のか
機械学習で使われる「深層学習」と「深層強化学習」は、言葉も使う部品も似ているが全く別のものだ。
これまでのGPTシリーズはすべて単なる「深層学習」の賜物だった。
深層強化学習とは、深層学習を部品として使用しながら、全体としては強化学習を行うための環境を用意する必要がある。
ChatGPTでは、人間がAIの回答を採点し、それをもとにAIが強化学習を行って「よりもっともらしい」答えが好ましいと考えるように調教された。
参考:ChatGPT公式サイト「ChatGPT: Optimizing Language Models for Dialogue」
「すごい人工知能ができた!」と騒がれるケースはこれまでもあった。ただ筆者の経験上、多くの場合が、深層強化学習の成果であって深層学習ではない。
例えば、囲碁で人間に勝ったAlphaGoは深層強化学習だし、プレイステーションのドライビングシミュレーター「グランツーリスモ」を攻略したソニー(SIE)の「Sophy」も深層強化学習だし、タンパク質の分子構造の折りたたみ問題を解いたのも深層強化学習だ。

数少ない例外は、GPTやDALL-E、StableDiffusionのような「生成系」と呼ばれるもので、(専門的な話になるが)これはTransformerという学習モデルを使った深層学習単体の成果だ。
ここまで説明して、ChatGPTに驚いた人たちが「何を驚いていたのか」に戻ってみる。
Transformerは驚異的にすごいが、Transformerに強化学習を組み合わせるともっとすごい、という発見「だけ」が今回のChatGPTで驚くべきポイントなのだ。
ChatGPTが強化学習を使っていることは、簡単に確認できる。
たとえば「ティム・クックについて説明してください」と聞くとスラスラ出てくるが、AIが知らなそうなことを聞くと長い時間をかけて考えた挙句、「すみません、その人は知りません」と白状する。
これは内部的に「それっぽい会話」を試行錯誤で作り出そうとして失敗した結果だ。「過度の知ったかぶりはしない」という調教が行われていることが推定できる。
意外かもしれないが、むしろ「適当に嘘をついてください」といった指示を与えると、ChatGPTは俄然イキイキとしてくる。それは「辻褄さえあっていれば許される」のでAI的にも書きやすいのだろう。
例えば架空の映画「桃太郎 鬼ヶ島軍団の逆襲」のストーリーと名台詞を考えてもらう。

ごく簡単なストーリーのたたき台を作ってくれ、と言えばChatGPTは悪くない成果を出せそうだ。が、ここから傑作を生み出すのは、おそらくこれを読み解く人間の想像力の差のほうが遥かに大きいことはわかる。

そしてChatGPTは反対に、「それっぽい返答」をできるように強化学習を重ねた結果の弊害も生まれている。
ChatGPTが強化学習を重ねた弊害
例えば、「生成したプログラムが文法的に間違っていればダメ」という強化学習をされているだろうし、「自信のない答えは望ましくない」という強化学習も、おそらくされている。
この結果、辛辣な表現をあえて使うなら「とりあえずそれっぽいことを表面的に語るだけの、実は無能なヤバい奴」が生まれた。それがChatGPTのもう1つの側面だ。
本当に怖いのは、ChatGPTのほうが人間よりもマシに見えてしまうケースがあることだ。
AIのようなものは、加点法で評価したくなるが、一見すごいものほど減点法で見るようにしなければならない。
では、ChatGPTはどうすればより実用的になるだろうか。
1つの問題点は、このChatGPTの強化学習に人間を使っていることにある。
実はどんな機械学習モデルでも起きることだが、データセット開発や学習に関わる人間の持つポテンシャルによって、会話するAIの能力は大きな制約を受けてしまう。

作成:Business Insider Japan
例えば、ChatGPT以前にも、対話AIの研究を進めるParlAIなどが解放していたチャットボットがあった。が、学習に用いられたデータは非常に単純な会話だけを追いかけていた。
ParlAIに比べてChatGPTの方が明らかに優れてると言える点はデータセットの幅が広いことくらいで、「答えてくれる会話の内容がそれっぽいだけ」というのは、実はそこまで変わっていない。
今、ChatGPTとの会話を体験した人のネット上の反響を見ていると、(StableDiffusionが登場した4カ月前のように)「会話AIに大きな可能性が開けた」と感じている人が多いように思える。
しかし、筆者の感想は実は真逆だ。
むしろ、ChatGPTの成果によって「会話AIが人間を超える存在になれないことは、ますます色濃くなった」と感じている。
2020年ごろにParlAIを知った時は、筆者にも「この先、会話AIはどう進化していくのか」というワクワク感があった。ParlAIは短い返答しかしなかったから、長文で会話する未来に想像力を広げる余地があったのだ。
ChatGPTは、ある意味でParlAIの「この先」を全部やった。
その結果、ChatGPTのアプローチでは極めてつまらない人間、つまり“それっぽいことを、それっぽく話せるだけの人間”と、同じような振る舞いしかできないのだとわかった。
「無難な会話」ができたとしても、それは図書館の司書やホテルのコンシェルジュと話す以下の体験になる。
AIとの会話に何らかの価値や意義を見出すためには、何よりも「面白い会話」ができなければならない。しかし、ChatGPTは訓練のプロセスにおいても、使用するデータにおいても、通り一遍のものしか与えられていないフシがある。
これは、大量のデータを用意しようと思えば大量の人間が必要であり、AIを指導する人間が増えるとAIは必然的に没個性的な存在になっていかざるを得ないという原理的な問題だ。
1つだけ解決策があるとすれば、AIを調教する人間を一度に一人に絞ることだ。
ある人間の価値観をまずしっかり教え込み、それから他の人間に調教されるという形でもいいと思う。
「面白い話ができるAI」をつくることが難しい理由
「面白い話」というのは、当然ながら「面白い人」から生まれる。
ところが「面白い人」というのは、普遍性がない。
誰にとっても面白い人というのはいない。ある人にとって面白い人は、他の人にとって不愉快な人かもしれない。例えば、面白みのなかには「不謹慎」も含まれるからだ。
しかし、ChatGPTのように「汎用的な」会話AIは、誰からみても普遍的に好かれるように作られる。
ここに1つ、「面白い話ができるAI」が難しい構造的な問題がある。
OpenAIのような組織が恐れるのは、何よりも差別や偏見を撒き散らすような「ふさわしくない」会話AIが生まれることだ。
その点において、ChatGPTは非常に抑制的に制御されていると感じる。
ひょっとすると、StableDiffusionが内蔵しているNSFWフィルター※のようなものをChatGPTも内蔵しているかもしれない。
※NSFW=Not Safe For Work=職場にふさわしくない内容。日本語的には職場閲覧注意というニュアンスに近い

ただ、過度に抑制された結果、返す答えに意外性がない、つまらないものになっている側面がある。
ChatGPTの「功績」とはなにか
こうしたAIが広く知れ渡ったことで、これまで「表面的にだけ反応していた人間の性質」が炙り出されてしまったようにも感じる。
ChatGPTの大きな功績は、「会話AIではここまでできる。でもここまでしかできない」という可能性を知らしめたことだ。だから、もう普通の会話ロボットを作る意味はほとんど失われたとも言えるかもしれない。
次に話題を呼ぶ会話ロボットがでてくるとすれば、それは「とても個性的」で、「使う人を極端に選ぶ」、けれども「なぜだか見逃せない」ような人格を備えていることだろう。それも単独ではなく、何個かの人格が同時に登場する可能性がある。
いずれにせよ、AIの世界はこういうことが頻繁に起きるからこそ面白い。
















.jpg?w=300&h=200)






