こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
この記事では最近のAIブームの火付け役になったGPTシリーズについて簡単にまとめていきたいと思います。
目次 [非表示]
GPTとは
GPTとはGenerative Pretrained Transformerの略であり、Transformerをベースにした事前学習生成モデルのことです。
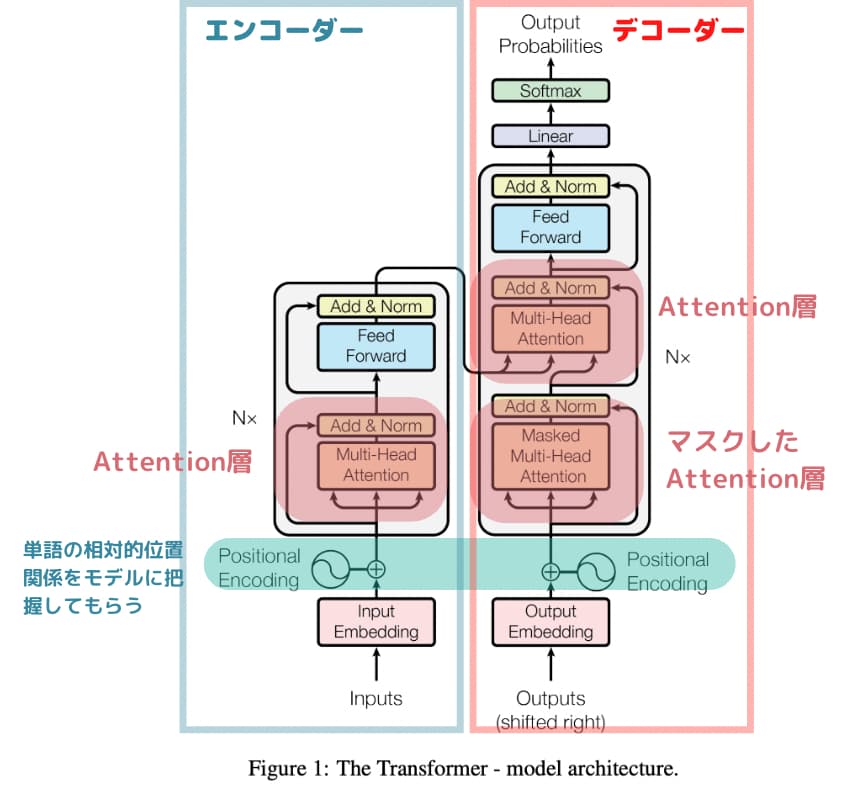
昨今のAIの進化は2017年に登場したTransformerをベースにしており、話題のGPTもご多分に漏れずTransformerベースなんです。
Transformerは「Attention層という層だけを使う」という、当時としては画期的なアプローチで世間を驚かせました。
詳しく知りたい方はぜひ以下の記事を参考にしてみてください!
そしてそれから1年後、GPTの初期モデルであるGPT-1が登場したのが2018年。
GPT-1は、イーロン・マスクとサム・アルトマンが2015年に設立したOpenAIによって発表されました。
OpenAIは、オープンなAIの研究開発を目的としてイーロン・マスクやサム・アルトマンらによって作られた非営利組織です。
GPTは初期タイプが2018年に発表され、2019年にはGPT-2、2020年にはGPT-3、そして2022年にGPT-3.5にあたるChatGPT、2023年にGPT-4が発表されました。
現在は、Micosoftから多額の出資も受け営利組織も運営しておりますが、基本理念は人類の生活を豊かにするAIを研究開発し普及させていくことです。
GPT-3までは一般ユーザーが利用できるようなユーザーインターフェースで提供されていませんでしたが、GPT-3.5にあたるChatGPTの登場で多くの人が触れるインターフェースになり広く普及しました。
AI自体の精度もさることながら、このUX面でのブレークスルーが広く世間に普及した大きな要因になっています。
GPTのアルゴリズム
それでは、具体的にGPTとはどのようなアルゴリズムになっているのでしょうか?
簡単に見ていきましょう。
GPTの論文はOpenAIから2018年に発表されました。
we explore a semi-supervised approach for language understanding tasks using a combination of unsupervised pre-training and supervised fine-tuning. Our goal is to learn a universal representation that transfers with little adaptation to a wide range of tasks.
引用元:“Improving Language Understanding by Generative Pre-Training”
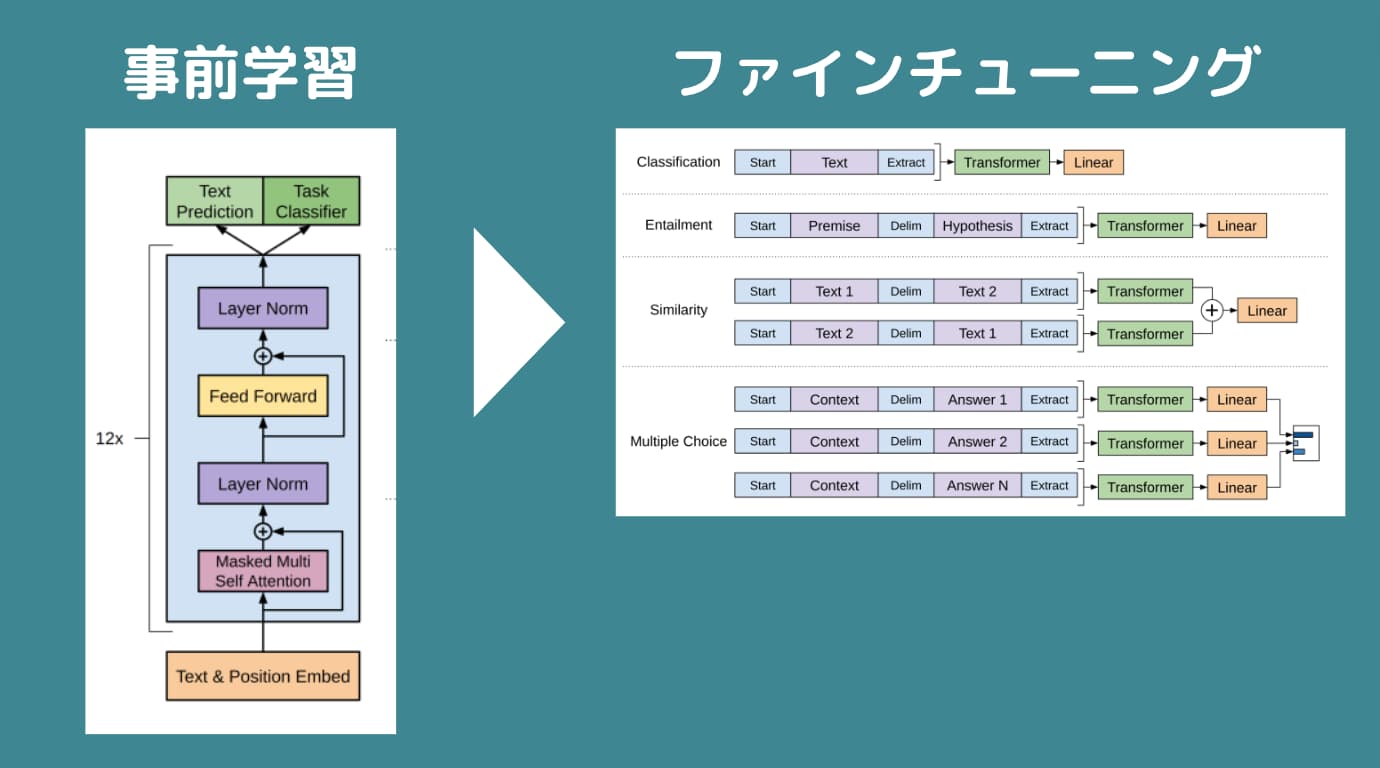
GPTは、大規模なテキストデータを事前学習した後にファインチューニングと呼ばれる各タスクに適した学習をしていく2段階のモデルです。
まず最初の事前学習の構成は以下になります。
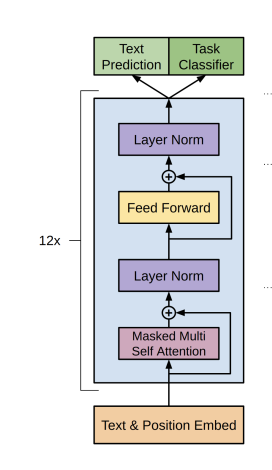
これはデコーダーと呼ばれていて、若干図は違いますが構造的には以下のTransfomerの右側のデコーダーとほぼ一緒です。
Transfomerでは、例えば翻訳で英語から日本語に訳したり、テキストを画像に変換したり入力と出力が対の関係になった上で学習していきます。
これは教師あり学習にあたります。
そして、GPTでは先ほどのデコーダーによる事前学習をした後に2段階目である各タスクに合わせたファインチューニングを行います。
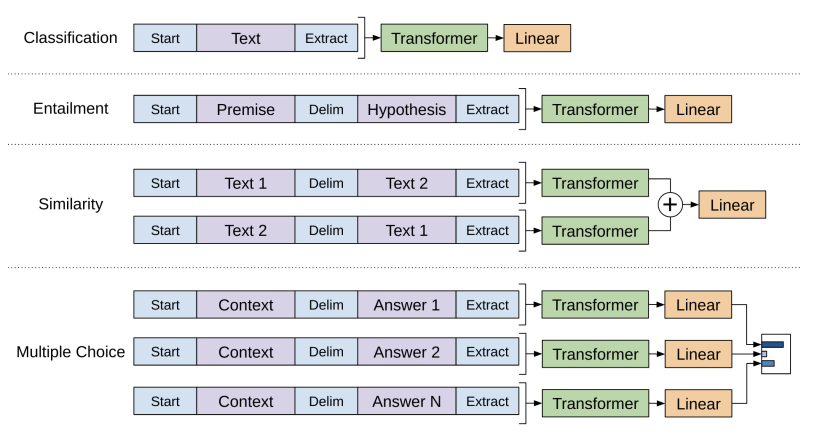
これが教師あり学習にあたります。
つまり、従来のモデルでは入力に対して出力ラベルがついた教師データを大量に用意してそれをエンコーダー・デコーダーモデルにインプットする必要があったのですが、GPTではまず事前学習モデルでラベル付与なく教師なし学習をして、その後に特定タスクに合わせてファインチューニングすることで大規模データの学習を可能にしたのです。
事前学習における教師なし学習とファインチューニングによる教師あり学習が混ざっているので半教師あり学習と呼ぶこともあります。
ちなみになぜ事前学習は教師なし学習になるのでしょう?
例えば、英語を日本語に変換する場合。
Apple > りんご
のような特定の入力に対して出力のラベル付けをした教師データを用意する必要があります。
しかし、事前学習段階のテキストデータは、
私はりんごが好き
的な文章を入れてあげて、
単語分割した後にそれぞれの単語をマスクして
私/ は/ りんご/ が/ ()
みたいなことをやって学習してくれるので人間がラベル付けをする必要がなく大量のテキストデータを与えてあげればいいのです。
それゆえ教師なし学習といえます。
GPTが事前学習に使用したのはBookCorpusと呼ばれる様々なジャンルの7000冊のテキストデータであり容量にして4.5 GB。
パラメータ数は、1億1700万個でした。
当時は画期的でしたが、今となってはGPT-1は序章に過ぎませんでした。
ここから数年で飛躍的な進化を遂げるのです。
GPT-1からGPT-2で何が進化した?

続いてGPT-1からGPT-2で何が進化したのか見ていきましょう!
GPT-2が登場したのはGPT-1登場から1年後の2019年。
論文は以下です。
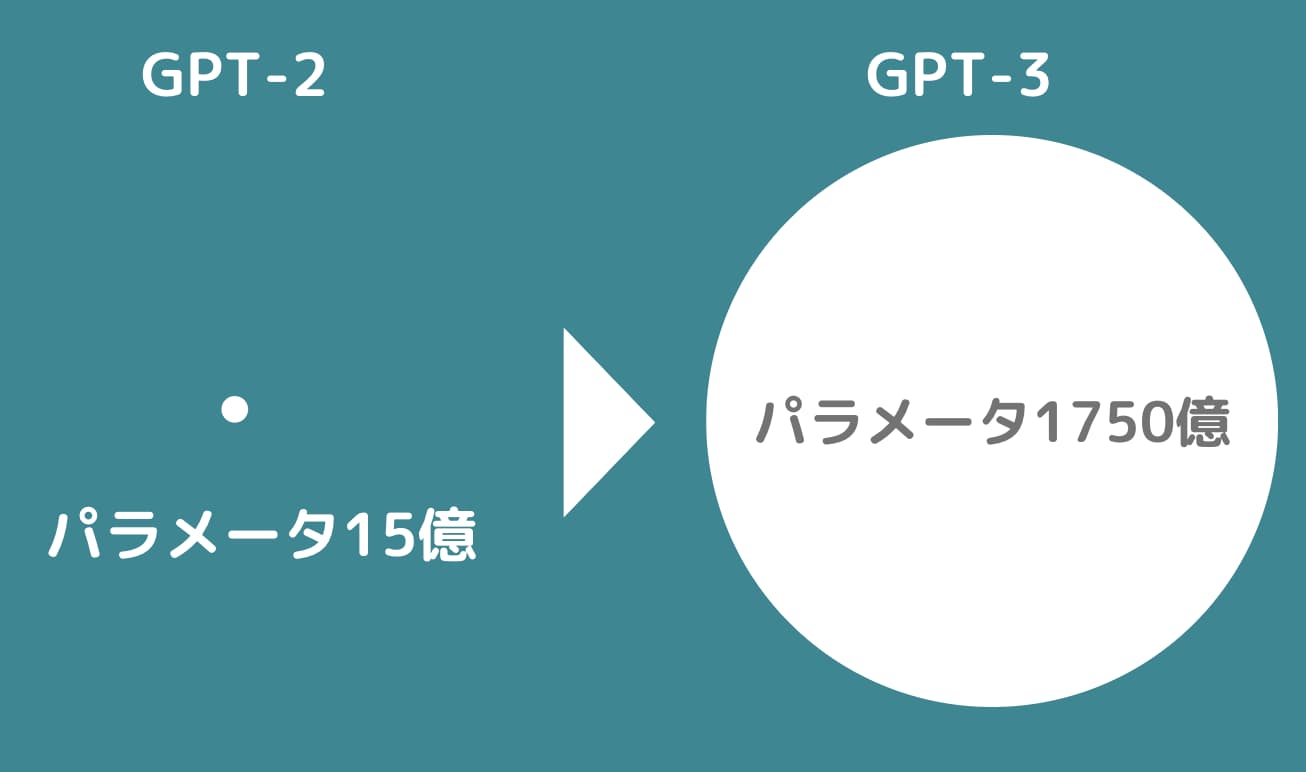
GPT-2ではGPT-1と構造は変わらず、パラメータ数と学習に使うデータ量が変わりました。
| GPT-1 | GPT-2 |
|---|---|
| パラメータ数 | |
| 1億1700万個 | 15億個 |
| 2行目見出し | |
4.5GBのテキスト(様々なジャンルの書籍7000冊から構成) | 40GBのテキスト(大量のウェブページから構成) |
これにより格段に精度が上がり、OpenAIは当初発表2019年2月時点では悪用される恐れがあるとして当初GPT-2のソースコードの公開を拒否していました。
しかし悪用の恐れがなくなったとのことから2019年11月に公開に踏み切っています。
この時点でもかなりの精度でしたが、長文の返答精度にはまだまだ難ありの状態でした。
GPT-2からGPT-3で何が進化した?
ここからさらにGPT-3で大きな進化を遂げて2020年に発表されました。
論文は以下です。
GPT-3はGPT-2からさらにパラメータ数と学習に使うデータ量が増えています。
| GPT-2 | GPT-3 |
|---|---|
| パラメータ数 | |
| 15億個 | 1750億個 |
| 2行目見出し | |
40GBのテキスト(大量のウェブページから構成) | 570GBのテキスト(様々なWeb上の情報源) |
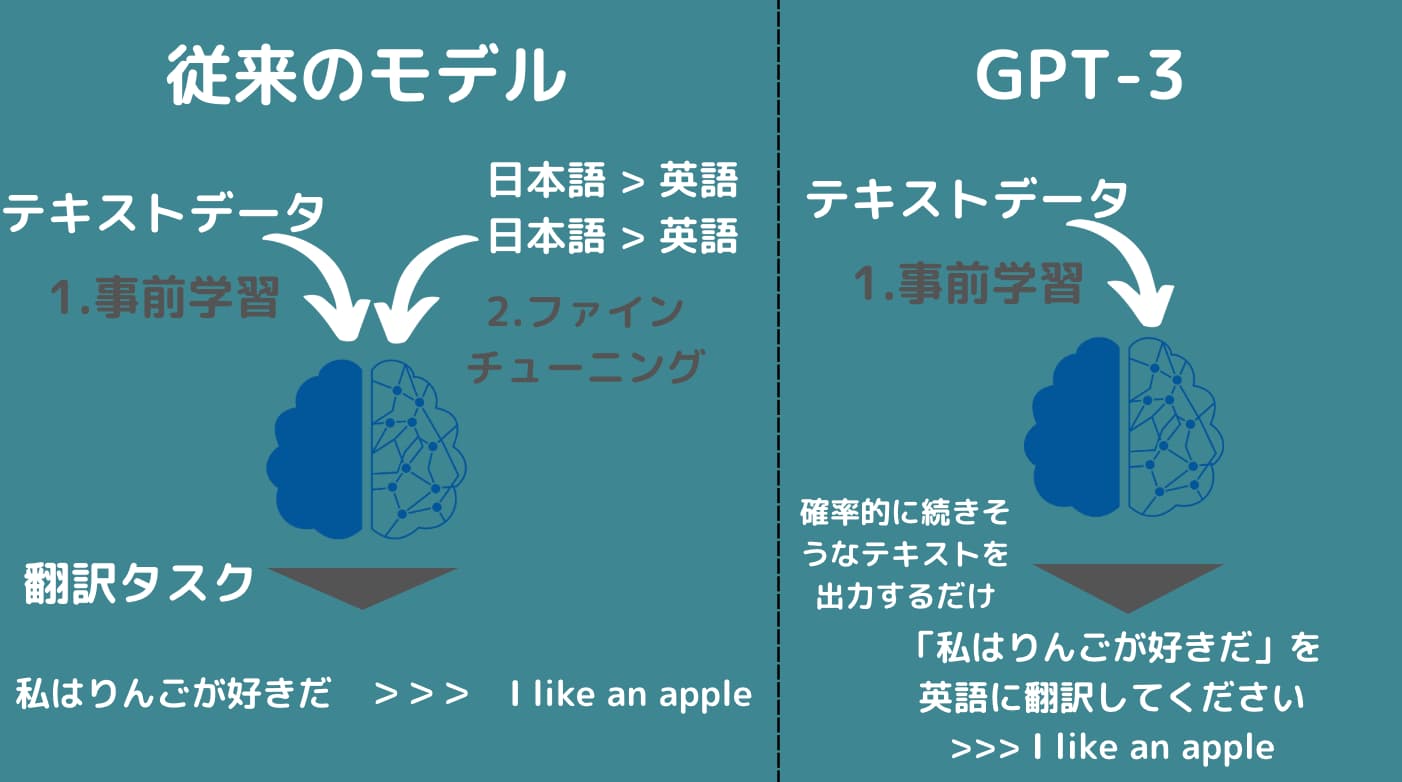
これまではまだまだファインチューニングしないと特定タスクに対して問題があったのですが、GPTの進化により「事前学習モデルを利用して次に来る単語を確率的に並べるだけでそれっぽい文章が作成できるようになってしまった」これが画期的なのです。
翻訳タスクでは通常、日本語と英語の文章の組み合わせを用意してそれらを教師あり学習で学習していく必要がありました。
しかしあまりにも大量のテキストデータから学習した事前学習モデルであれば、「英語に翻訳して」という文章の後に確率的に近づく言葉をつないでいったら翻訳タスク的なことができるようになったのです。
GPT-3の状態ではまだまだ世間の一般認知は取れていませんでしたが、業界は震撼しました。
GPT-3が出力したテキストはもはや人間との区別がつかないくらい高精度になっていました。
GPT-3からGPT-3.5(ChatGPT)への進化
さらにここからChatGPTの登場に繋がります。
ChatGPTは2022年11月30日に発表されました。
ChatGPTの内部で動いているモデルはGPT-3.5と呼ばれパラメータ数は3550億個。
GPT-3と比較してそれほど劇的なスペックの進化はありませんが、なんと言ってもChatというインターフェースで誰でも簡単に利用できるようなUIUXにしたのが画期的です。
私自身も日々ChatGPTをヘビロテしています。
もし使っていないのであれば是非OpenAIのサイトから登録して使ってみましょう!
ChatGPTを使わない生活にはもう戻れなくなるでしょう!
そしてGPT-3.5からGPT-4へ
そしてさらなる進化がGPT-4です。
GPT-4は2023年3月14日に公開されました。
とにかく精度が劇的に上がったのは確かなのですが、GPT-4は安全性のリスクから詳細の設計は非公開とされています。
ただ、司法試験や大学入試テストなどの数々の試験で合格レベルの点数を叩き出しており、飛躍的に精度が上がったことが伺えます。
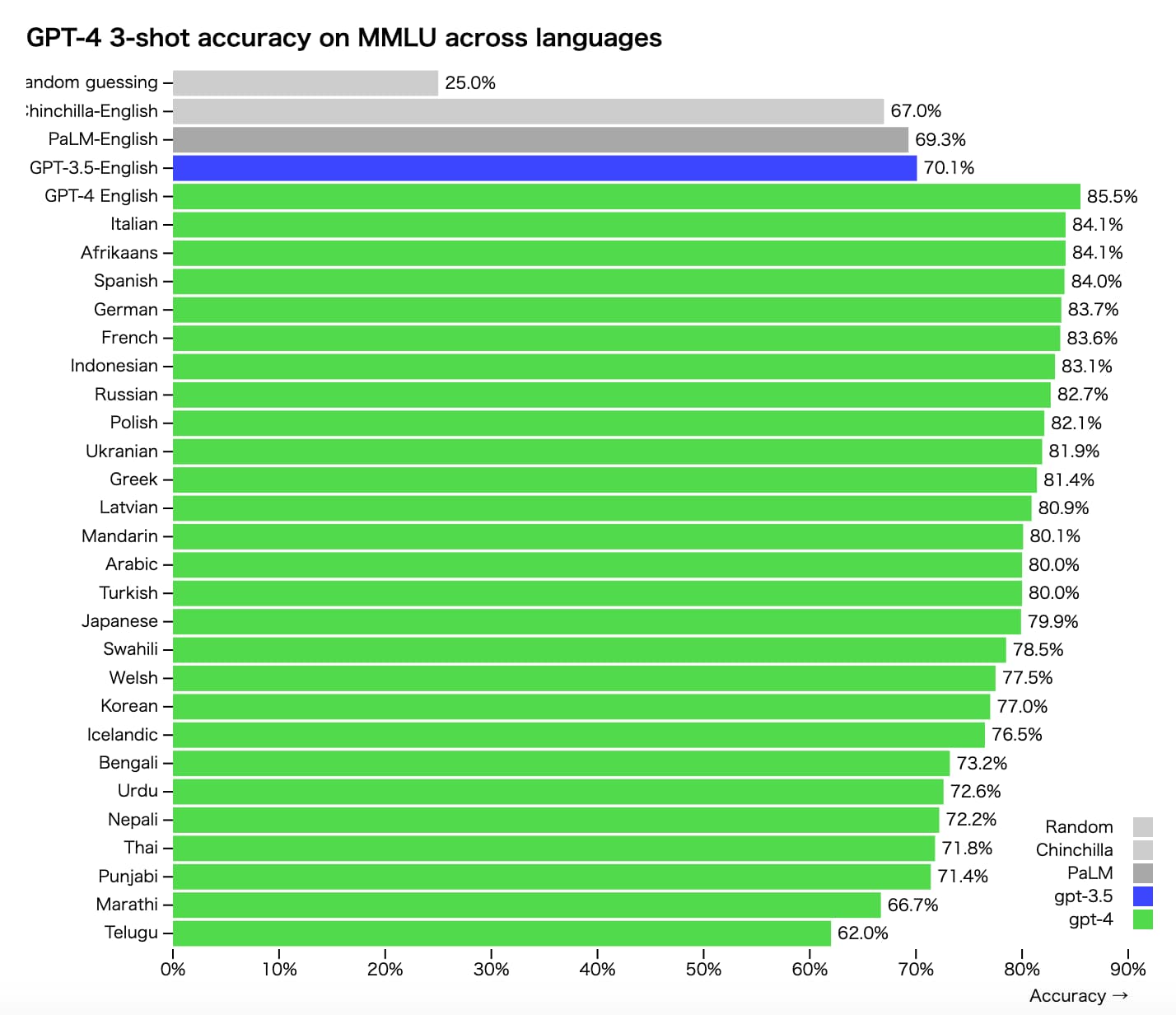
GPT-4のパフォーマンスに関しては以下のOpenAIのページに詳しいです。
確かに、以下を見るとGPT-3.5から劇的にGPT-4になって精度が劇的に上昇していることが分かります。
またマルチモーダルの処理にも対応していることが画期的と言われるゆえんの一つになります。
以下のように画像と一緒に画像の面白いところを説明してとテキストでインプットするとちゃんと説明してくれます。

このように画像×テキストのようなマルチモーダルインプットにも対応しているのがすごいです。
GPTの進化の軌跡について
ここまででGPTについて簡単にまとめてきました!
ここまでは、それぞれのモデルがどのように進化してきたのか、どんな仕組みなのか、見てきましたが、ザックリ理解した後は実際に手を動かしながらガシガシ使ってみることが大事です。
PythonでGPT-2やGPT-3.5を利用する方法を知りたい方は当メディアが運営するスタアカの以下のコースを是非チェックしてみてください!
スタアカは業界最安級のAIデータサイエンススクールです。

| 【価格】 | ライトプラン:980円/月 プレミアムプラン:98,000円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
AIデータサイエンスを学んで市場価値の高い人材になりましょう!
データサイエンスやAIの勉強方法は以下の記事でまとめています。


 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!