

Dreambooth-LoRA
最終更新:ID:lJVL/qKRwg 2023年02月18日(土) 02:44:12履歴

概要 
Low-rank Adaptation for Fast Text-to-Image Diffusion Fine-tuning
簡単に言えば「省メモリで高速に学習できて容量も小さくて済む追加学習法」。作成方法はいろいろある。

他の学習法とどう違うねん? reddit民によればこんな感じのイメージらしい。
https://www.reddit.com/r/StableDiffusion/comments/...
kohya_ss版sd-scriptsの登場以来、sd-scripts及びそれの派生ツールが人気となっている。
このページではsd-scripts関連の情報について雑に書いてある
簡単に言えば「省メモリで高速に学習できて容量も小さくて済む追加学習法」。作成方法はいろいろある。
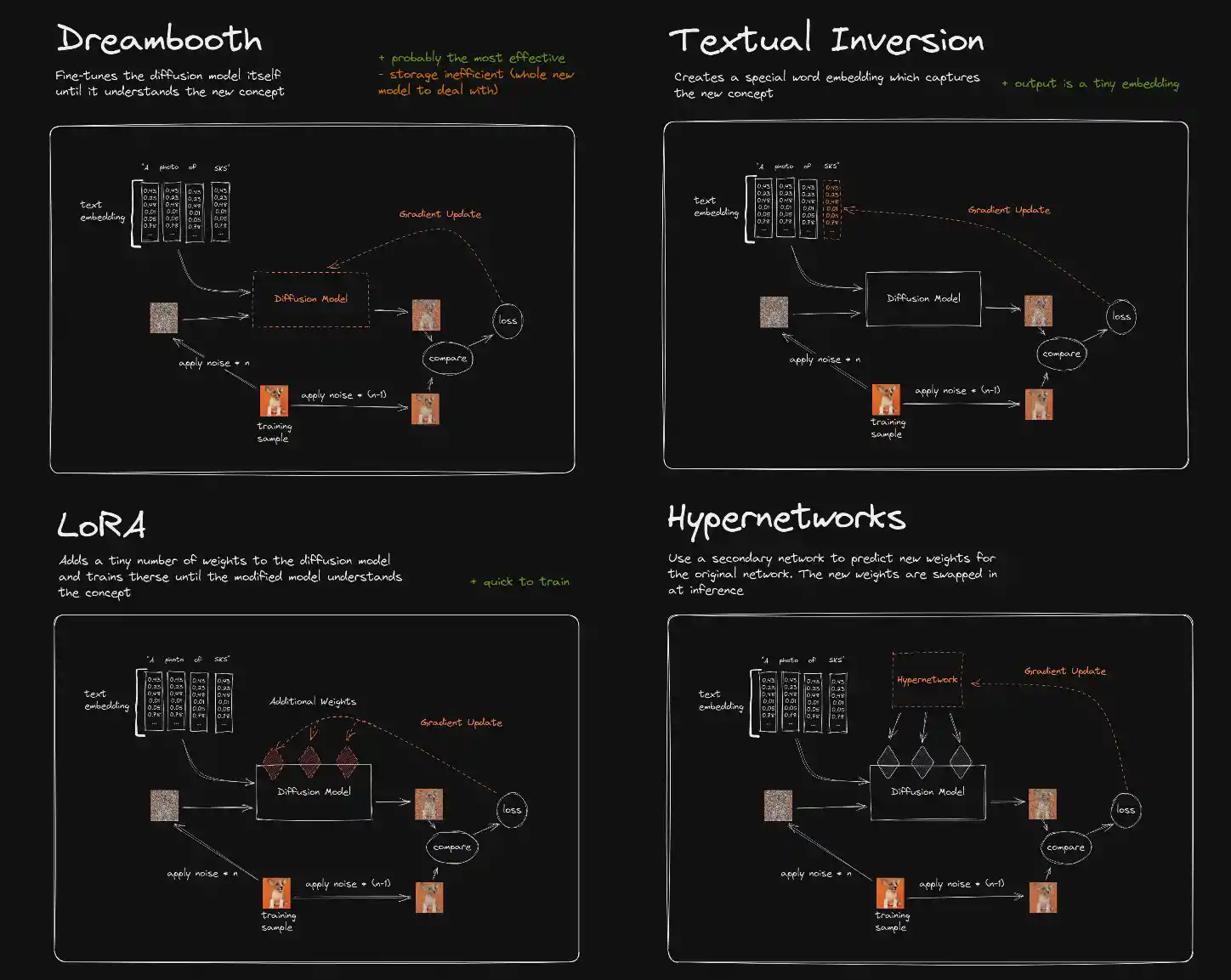
他の学習法とどう違うねん? reddit民によればこんな感じのイメージらしい。
https://www.reddit.com/r/StableDiffusion/comments/...
kohya_ss版sd-scriptsの登場以来、sd-scripts及びそれの派生ツールが人気となっている。
このページではsd-scripts関連の情報について雑に書いてある
公式情報
sd-scripts (kohya)
一番はじめは作者が詳しく書いてくれている公式READMEを見よう!話はそれからだ!
- ★公式LoRAガイド:sd-scripts/train_network_README-ja.md at main · kohya-ss/sd-scripts | https://github.com/kohya-ss/sd-scripts/blob/main/t...
- 公式タグ付けガイド:sd-scripts/fine_tune_README_ja.md at main · kohya-ss/sd-scripts | https://github.com/kohya-ss/sd-scripts/blob/main/f...
- 公式DreamBoothガイド:sd-scripts/train_db_README-ja.md at main · kohya-ss/sd-scripts | https://github.com/kohya-ss/sd-scripts/blob/main/t...
参考資料・スレ住民による学習ガイド
LoRA Training Guide https://rentry.org/lora_train
- 4chan有志によるLoRAトレーニング法ガイド(英語)
- スレ住民によるLain・よしなが先生・野原ひろしLoRA作成者によるLoRAガイド(日本語)
更新:2023-02-09|低リソース学習(NIKKE)、低dim学習(ゆるキャン 犬山あおい)などを追加しました。
- スレ住民によるマルゼン式(ふたば有志のタグ付け手法の1つ)で作成したLoRA作成記録(日本語)
- スレ住民によるkohya-ss氏制作のSDスクリプト(https://github.com/kohya-ss/sd-scripts )で次のキャラのLoRAを作成した。ポップアップ版使用。(日本語)
- lora training tagging faq(英語)
- スレ住民によるキャラクター学習のタグ付け一例(日本語)
- スレ住民によるLoRAでのキャラ学習素材の検証
- 全然スレに書き込めないけどけなげに頑張っている
- クラウドGPUを使う場合はリンク先の下の方に Colab Instructions がある
- フォルダ命名方法に気をつけて、自前のファイルは半角スペース一切入れないようにすれば無料Colabでも回せる。頑張れ。
他人の作ったモデルを使いたい。
最新版のWEBUIが既に使用可能な状態ならセットアップ不要→LoRAの使用方法へ
インストール、初回セットアップ編
1.LoRA_Easy_Training_Scripts Installers
下記の学習の手順ので使うEasyTrainScriptsの人が作った簡易インストールスクリプト
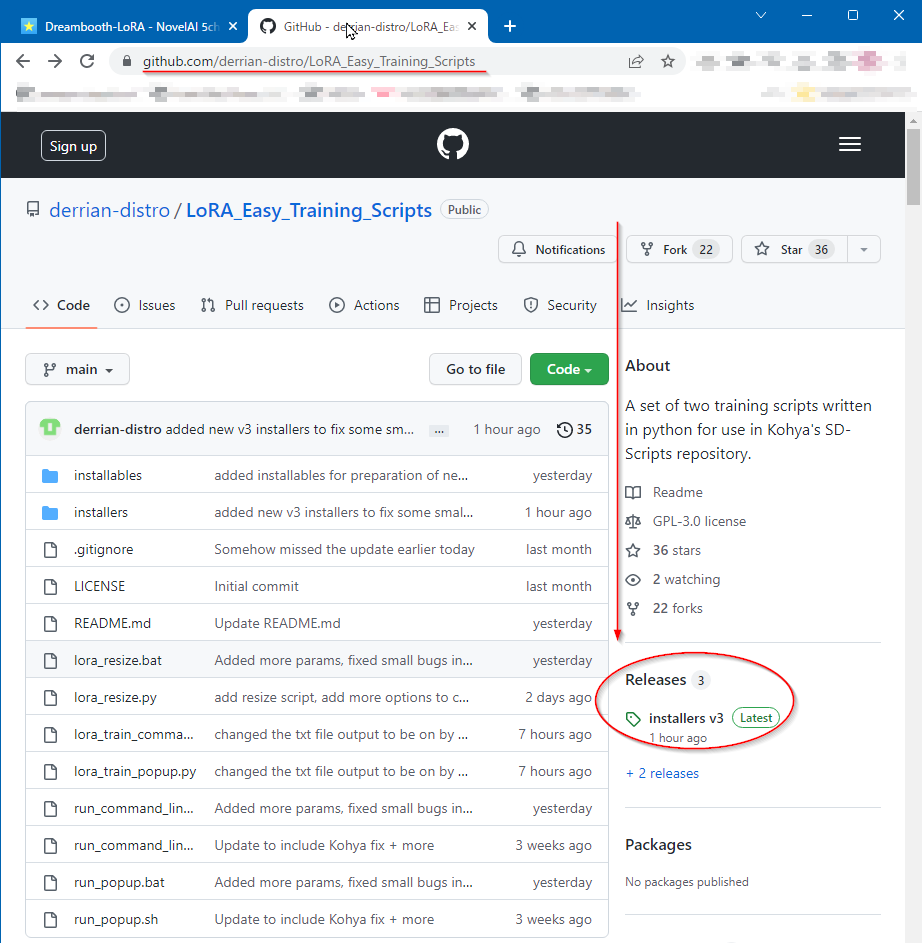
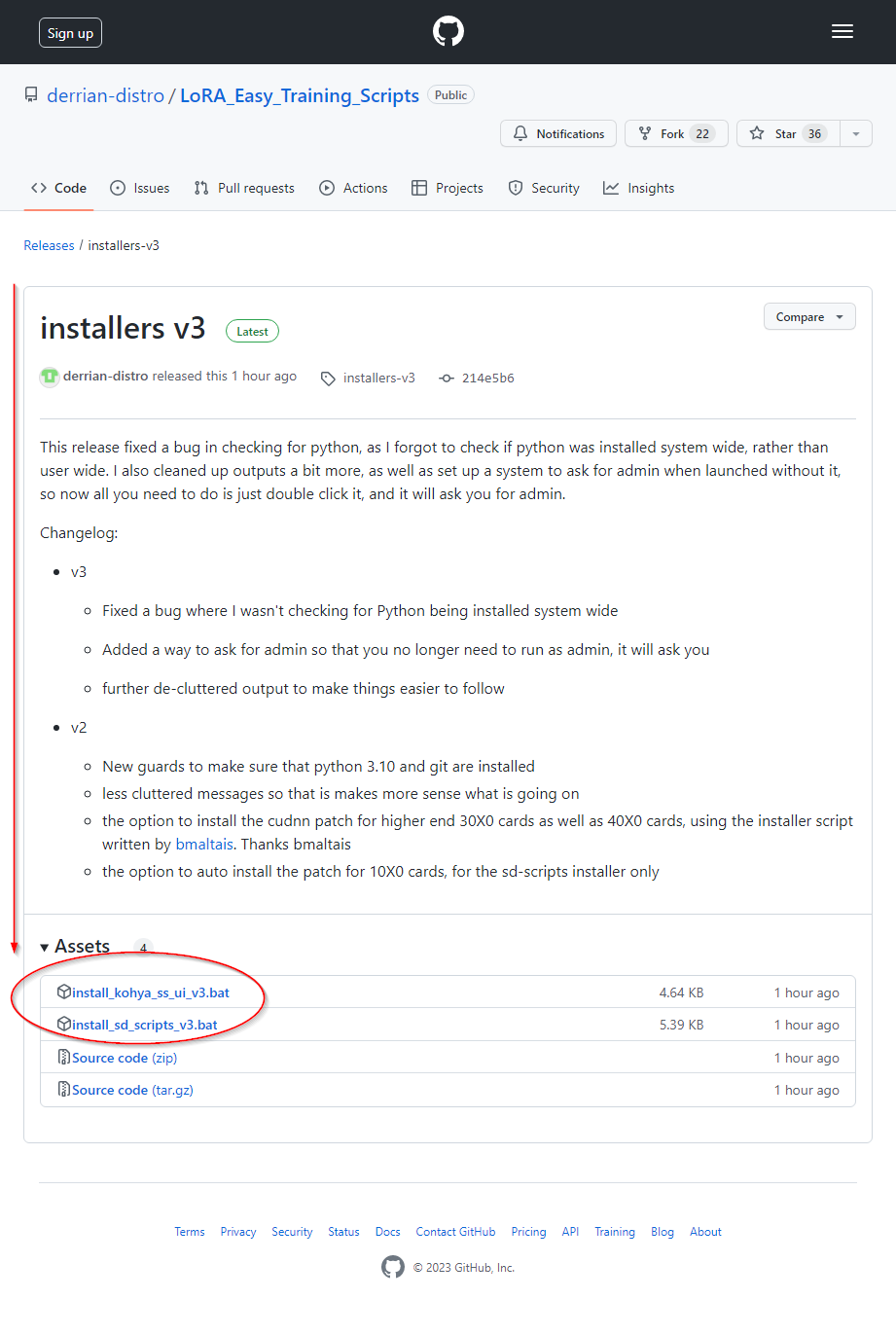
画面右の Releases の下の Installers をクリック > 下にスクロールして install_sd_scripts_v3.bat をダウンロードする
右クリックして 管理者として実行すると
sd-scripts本体とEasy_Train_Scriptsの両方をインストールして、インストール後の初期設定までやってくれる。
うまくいかなかったら Gitをインストール してリトライ
わからないとき用画像↓
画面右の Releases の下の Installers をクリック > 下にスクロールして install_sd_scripts_v3.bat をダウンロードする
右クリックして 管理者として実行すると
sd-scripts本体とEasy_Train_Scriptsの両方をインストールして、インストール後の初期設定までやってくれる。
うまくいかなかったら Gitをインストール してリトライ
わからないとき用画像↓
2.あかちゃんLoraインストーラー
あかちゃんインストーラーで1111を入れた人向けにPYTHONとGITのPATHをいじってあるやつ
start.batと同じフォルダに入れて実行してください
3.GUI
GUIといっても作者のsd-scriptsにパラメータを渡すだけや。性能は変わらん。一部パラメータ非対応のこともある。
4.その他補助スクリプト
としあきbatや4chan製のスクリプトがある
kohya-ss/sd-scripts を自分でインストールできるなら
kohya-ss/sd-scripts を自分でインストールできるなら
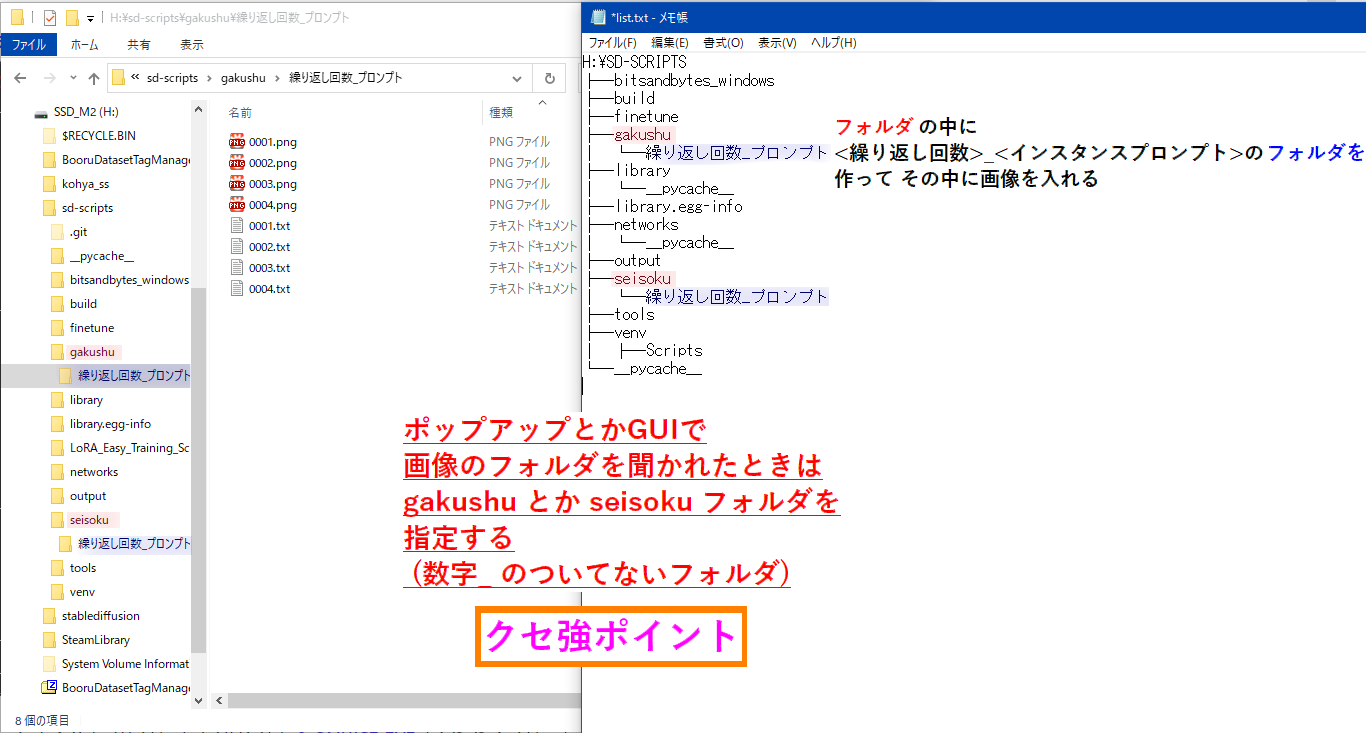
学習用画像を置くフォルダの配置
- フォルダの配置例:
※要するに<繰り返し回数>_<インスタンスプロンプト>にリネームした学習画像データのフォルダは直接指定しないでねって話
例えば↓こういうこと
❌E:\kohya_ss\TrainDatas\001\img\40_kdy 1girl
🟢E:\kohya_ss\TrainDatas\001\img
間違うと画像が見つかりませんと怒られる

例えば↓こういうこと
❌E:\kohya_ss\TrainDatas\001\img\40_kdy 1girl
🟢E:\kohya_ss\TrainDatas\001\img
間違うと画像が見つかりませんと怒られる
- 同時に10まで概念を学習できるが、少なくとも1つはフォルダが必要。
- フォルダの名前は <繰り返し回数>_<インスタンスプロンプト>
- <繰り返し回数> 繰り返し回数×学習用画像の枚数を1セット(1 epoch)として学習する
- <インスタンスプロンプト> クラス 呼び出し用のキーワード クラスは英単語にない意味のないワードがよい
- 上記kohya氏のサンプルだと「20_sls frog」 脳死で真似するなら 繰り返し回数_意味のないワード WEBUIでプロンプトとして書きたい単語 で設定しておく
- キャプション ファイルは必須です。そうでない場合、LoRA は概念名をキャプションとして使用してトレーニングを行います。
- キャプションについては以下
キャプション・タグを付ける
- 作者の詳しい画像付き説明 https://github.com/kohya-ss/sd-scripts/blob/main/f...
- 学習用の素材画像それぞれに内容を説明するテキストファイルを作る。このテキストファイルには画像生成時のプロンプトと同じようにタグを記載する。
- テキストエディターやメモ帳で1つずつ作っても良いのだが、WD1.4Tagger等のツールを使えば一気に自動生成できて捗る
WD1.4 Taggerで作成
先に学習用画像を連番にリネームしておく (01.png, 02.png, ...など)
Web UI に拡張機能 stable-diffusion-webui-wd14-tagger https://github.com/toriato/stable-diffusion-webui-...をインストール
「Tagger」タブの「Batch from directly」
Interrogateを押すと学習用画像のフォルダにタグの付いた .txt ファイルが生成される
画像
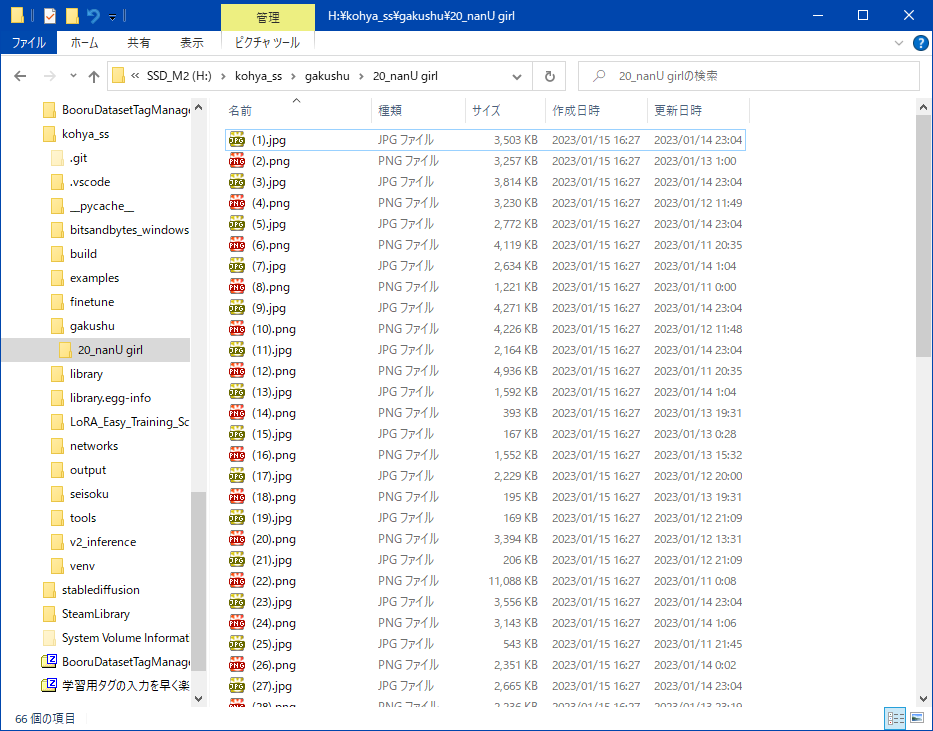
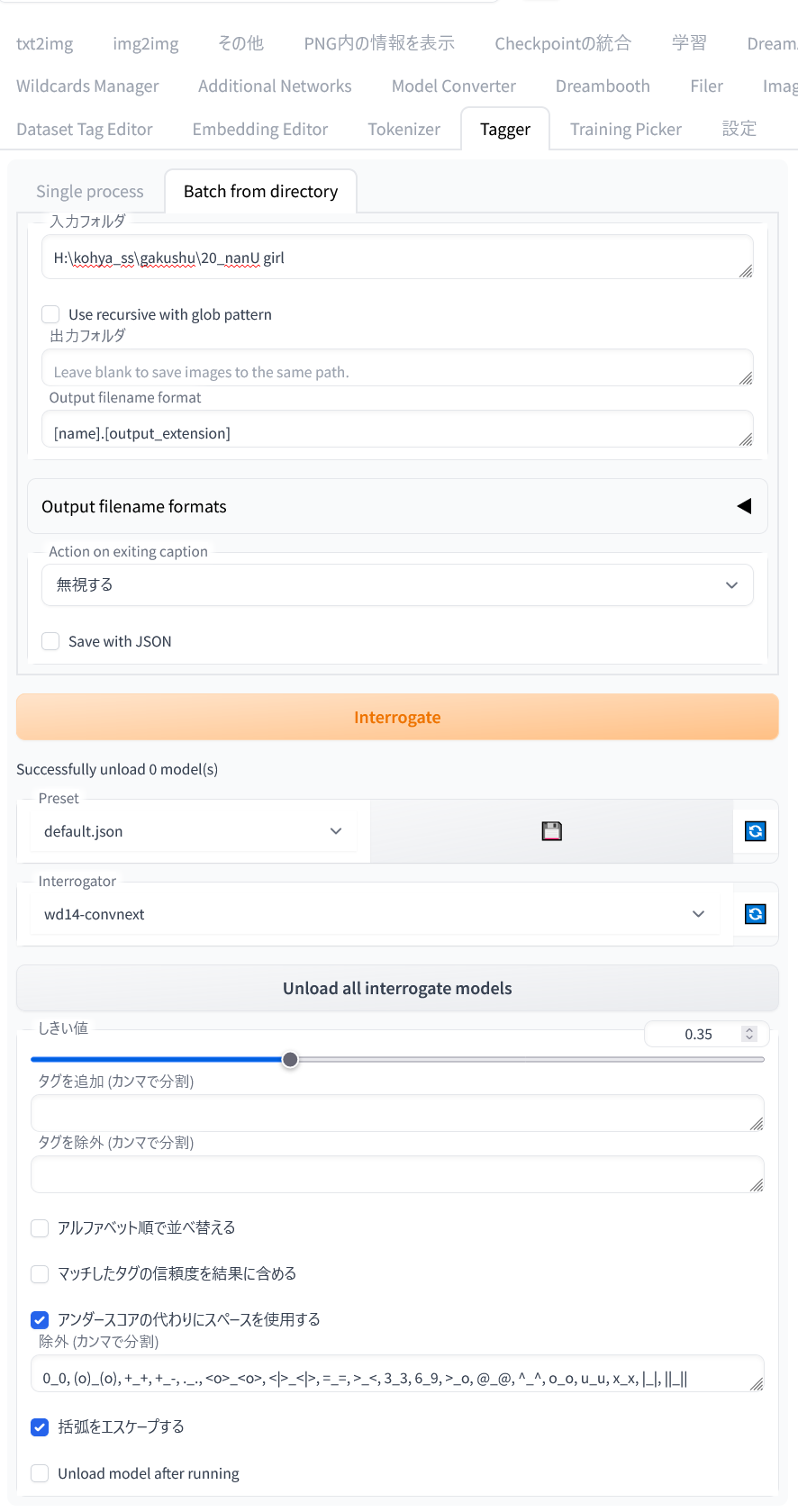
「Tagger」タブの「Batch from directly」
- 入力ファイル:学習用画像の入っているフォルダ
- Interrogator:wd-14convnext
- アンダースコアの代わりにスペースを使用する:オン
- 括弧をエスケープする:オン
画像
画像
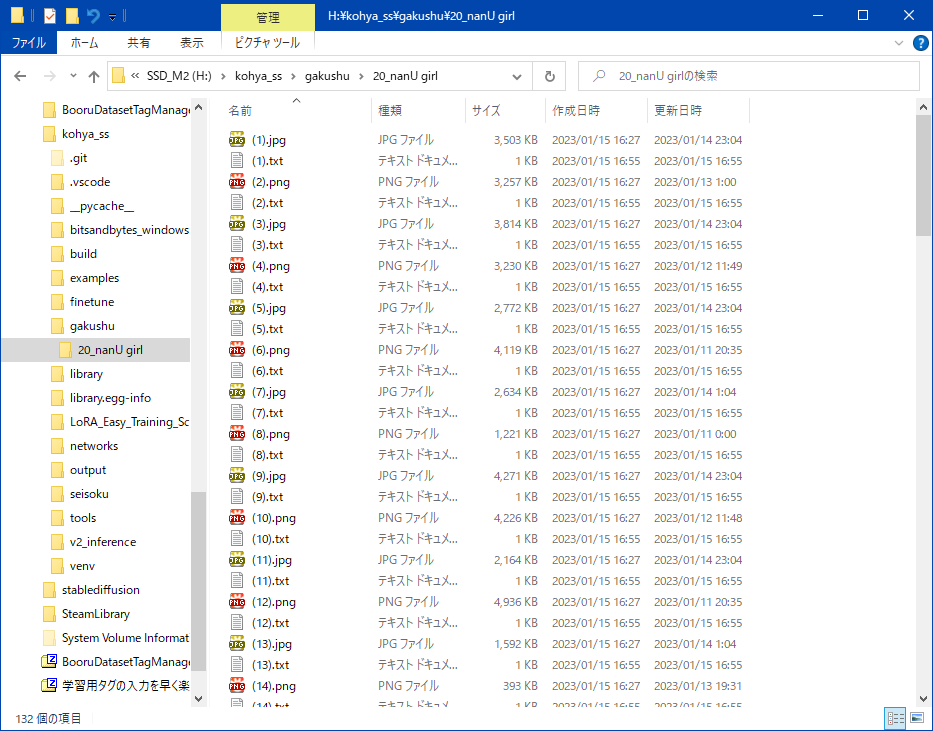
キャプション・タグの編集
- タグは順序に影響を受けるので、一番最初に有効化したいタグを記述する
- WD1.4Tagger等で自動生成したファイルには不要なタグが含まれたり誤認識されたタグが記載されたりするので編集する。
- BooruDatasetTagManager https://github.com/starik222/BooruDatasetTagManage...
- 学習用タグの入力を速く楽にするやつ →ローカルの「ツール」 https://uploader.cc/s/rdw0k6qd2766czgdwwwjtn2xtmhi...
- taggerで生成したタグの順序のままでも構わないが、重要なタグだけ各ファイルの先頭の方に記載する。例えばコマンドライン版(lora_train_command_line.py )の場合、
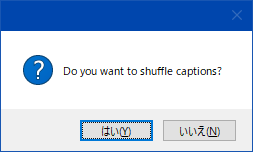
self.shuffle_captions: bool = True # OPTIONAL, False to ignore上記のように設定すれば先頭から3つのタグは順序固定として残りはタグの適当にシャッフルして学習できる。
self.keep_tokens: Union[int, None] = 3 # OPTIONAL, None to ignore
キャプションの付け方・考え方の参考サイト
英語サイトだがブラウザの翻訳で読もう
実例を挙げての解説
一言で言えば「呼び出しキーワード」+「学習から外したいもの」をタグに書く
一言で言えば「呼び出しキーワード」+「学習から外したいもの」をタグに書く
そもそも学習用画像ってどうやって加工するの
- 本文で説明している kohya_ss 版のLoRAではトリミングはしなくていい(画像のサイズ別に学習が行われる)
- 背景の切り抜きは・・・画像の大きさが揃ってないとめんどくさいなどうしよう・・・
- キャラの切り出しだけやったら3Dペイント(Win10なら標準、11では標準からリストラされたけどストアにおるで)のマジック選択でええ感じに切り抜きやすいからそこからgimpなりで微調整。
- 一枚一枚やんのめんどくさい言うんやったらABG_extension言うのが出たんでつこてみたらええんとちゃうかな…?しらんけど
ABG_extension
https://github.com/KutsuyaYuki/ABG_extension
WEBUI公式extension 背景を自動で除去します。アニメ画像用に微調整されたonnxモデルを使用。GPUで動作します。
katanuki
https://github.com/aka7774/sd_katanuki
WEBUI用exntension anime-segmentation を 1111 で使えるようにしたやつ。画像の背景を透過したり白背景にしたりマスク画像を出力する
正則化画像
- ChatGPTたん曰く「過学習を抑えるためのもの」
- キャプションつけたらそのプロンプトで学習させるモデルを使って(適当なネガティブプロンプトをつけて)作成すればいい・・・のだが詳しくはわからないので誰か書いてクレメンス
- 間違っとる可能性大なのやが、例えばAIちゃんが知らない「鳥獣戯画のカエルちゃん」のイメージを教えるとする。学習用画像には「鳥獣戯画のカエルちゃん」画像を用意する。正則化画像にはありふれた「蛙の画像」を用意する。これでAIちゃんには「鳥獣戯画のカエルちゃん覚えようね!でも正則化画像フォルダにある普通の蛙とかは違うやつやから覚えなくていいよ」という感じで伝わる。イメージを覚えてもらうのに言葉では説明しづらいから画像で説明する感じ?多分。知らんけど。
- 他所のノートブックを利用しているので確かな事は言えないが、正則化画像を同じような画像で学習させすぎると正則化画像につけたクラストークンで正則化画像の内容を生成するようになる。これは上の「普通の蛙は覚えなくていいよ」というよりも、単に「学習画像と正則画像を二つとも学習する」という挙動のように思われる。
- 正則化画像は必須ではないので用意しなくても学習はできる。とりあえず一度学習動かしてみたいとかなら用意しなくてもいい。透明正則化も効果は不明瞭(良い影響があるとしても悪影響がないとも言えない)なので面倒ならやらなくてもいい。
透明のpngを正則化画像にする
Web UI に拡張機能をインストールする https://github.com/hunyaramoke/Generate-Transparen...
Generate TransparentIMG タブで
出力フォルダ:正則化画像の保存先
number_of_generation:作成する枚数
を入力して実行
Generate TransparentIMG タブで
出力フォルダ:正則化画像の保存先
number_of_generation:作成する枚数
を入力して実行
画像
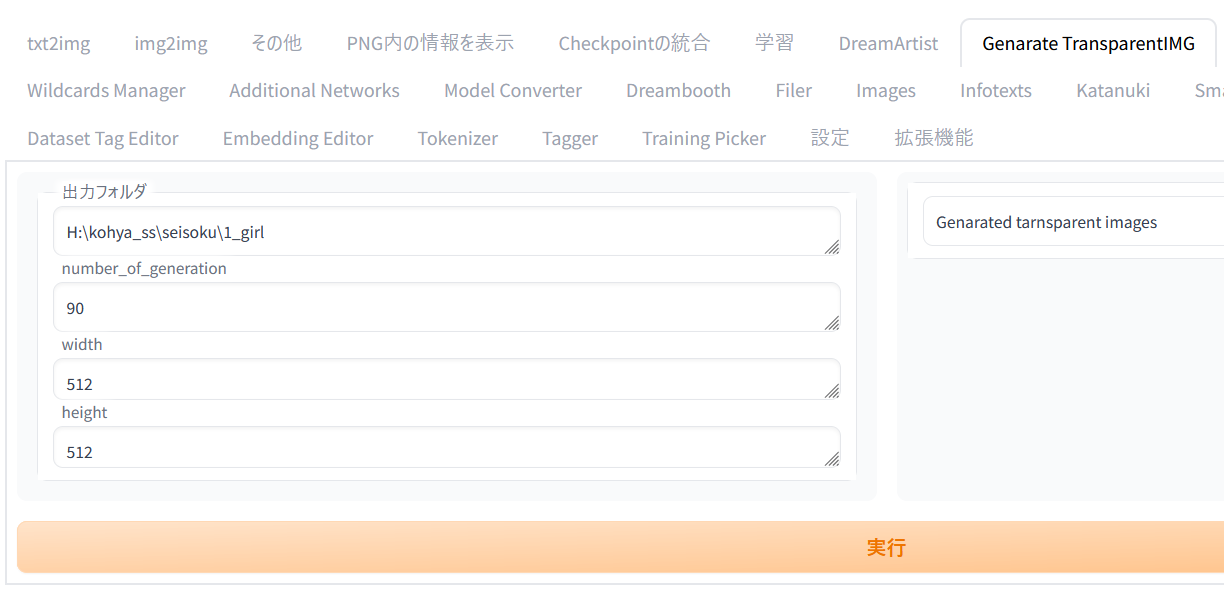
学習の手順
Windowsの場合
ポップアップ版を使う場合
- run_popup.batを実行
- ポップアップにパラメーターを入力する
- 出来上がりを待つ
コマンドライン版を使う場合
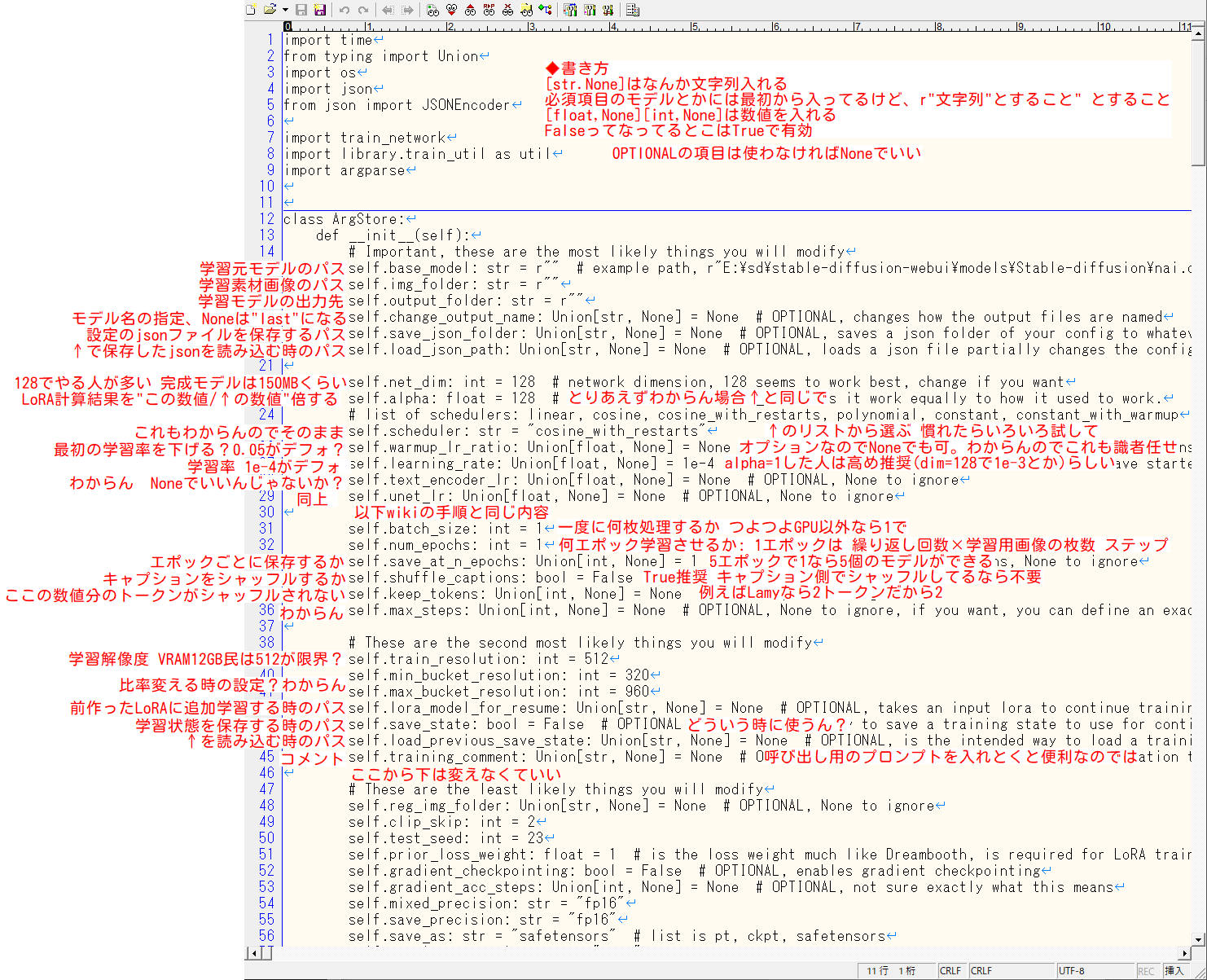
1. lora_train_command_line.py にパラメーターを書く

設定を書き込むのはlora_train_command_line.pyの最初の方あたり。学習ベースになるモデル、学習素材フォルダの場所、出力先は必ず設定する。わからんところはそのままにしとく。
以下lora_train_command_line.py冒頭あたりの設定部分の雑な日本語訳
2. run_command_line.batを実行
3. 出来上がりを待つ
設定を書き込むのはlora_train_command_line.pyの最初の方あたり。学習ベースになるモデル、学習素材フォルダの場所、出力先は必ず設定する。わからんところはそのままにしとく。
以下lora_train_command_line.py冒頭あたりの設定部分の雑な日本語訳
3. 出来上がりを待つ
Linux(wslやクラウドGPUニキ)の場合
ポップアップ版を使う場合
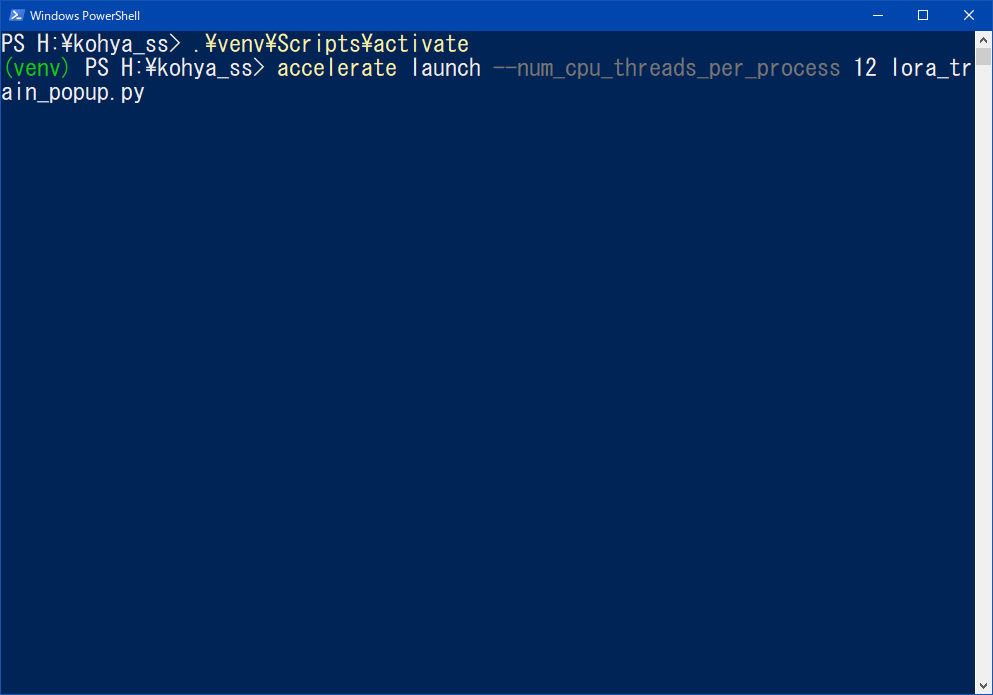
- source venv/bin/activate と入力
- accelerate launch --num_cpu_threads_per_process 12 lora_train_popup.py と入力
- ポップアップにパラメーターを入力する
- 出来上がりを待つ
コマンドライン版を使う場合
- lora_train_command_line.py にパラメーターを書く
- source venv/bin/activate と入力
- accelerate launch --num_cpu_threads_per_process 12 lora_train_command_line.py と入力
- 出来上がりを待つ
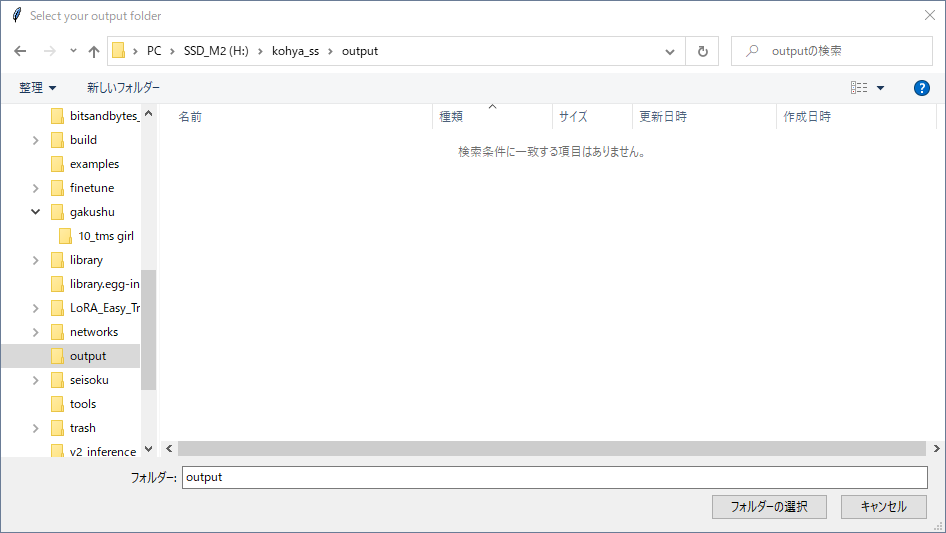
Lora作成手順の画像 (ポップアップ版) 参考程度 (2023-1-16時点)
クリックして展開 アップデートなどで内容は変わる
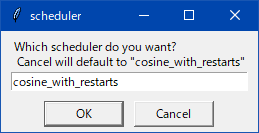
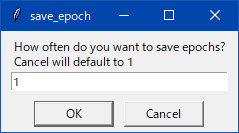
わからんパラメータが出たらcancelを押しとけばデフォルト値が入る。抜けがあったらスレで質問よろ。
動画(2023-01-30) すぐにアプデで役に立たなくなるが一応
字幕がめんどいのでそのうちテキストで書く・・・とおもう
わからんパラメータは キャンセルでデフォルト値が入る
ポップアップの質問と答えの例
わからんパラメータが出たらcancelを押しとけばデフォルト値が入る。抜けがあったらスレで質問よろ。
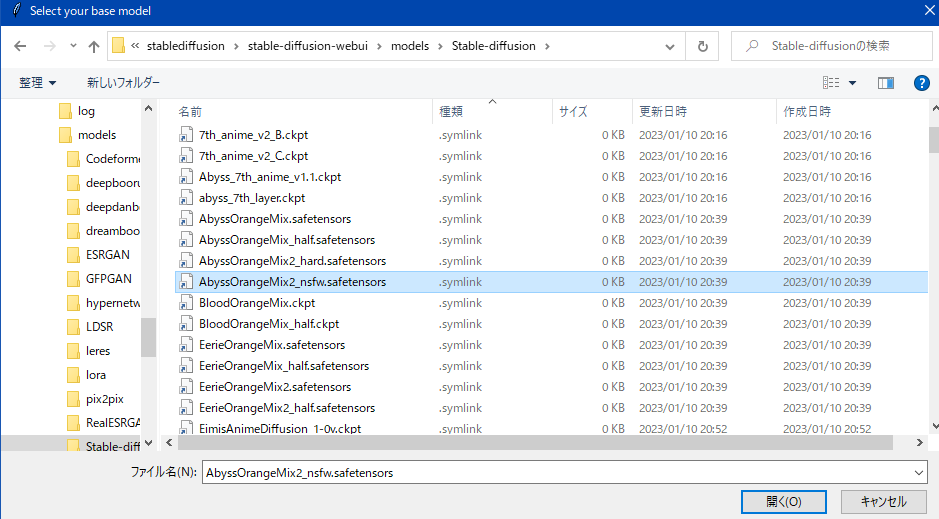
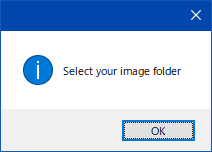
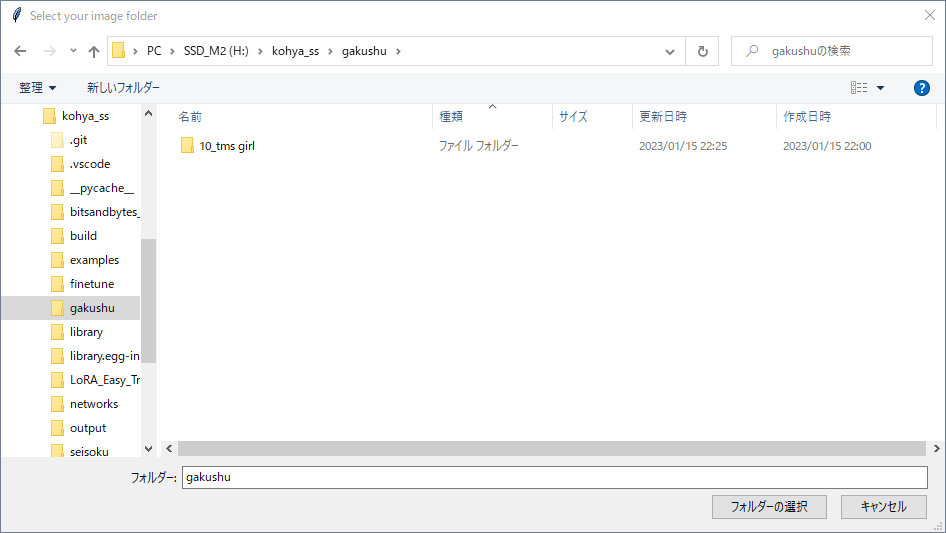
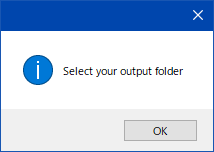
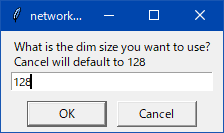
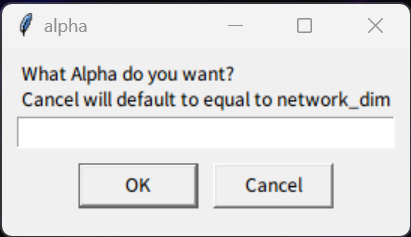
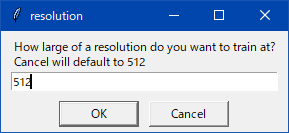
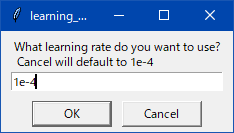
字幕がめんどいのでそのうちテキストで書く・・・とおもう
わからんパラメータは キャンセルでデフォルト値が入る
使い方その1 WebUIに拡張機能をインストールして使う
- 「拡張機能」タブの「URLからインストール」に https://github.com/kohya-ss/sd-webui-additional-ne... を入力してインストール )
(Web UI の 「設定」> 「Additional Nerwork」タブでフォルダの場所を追加出来る)
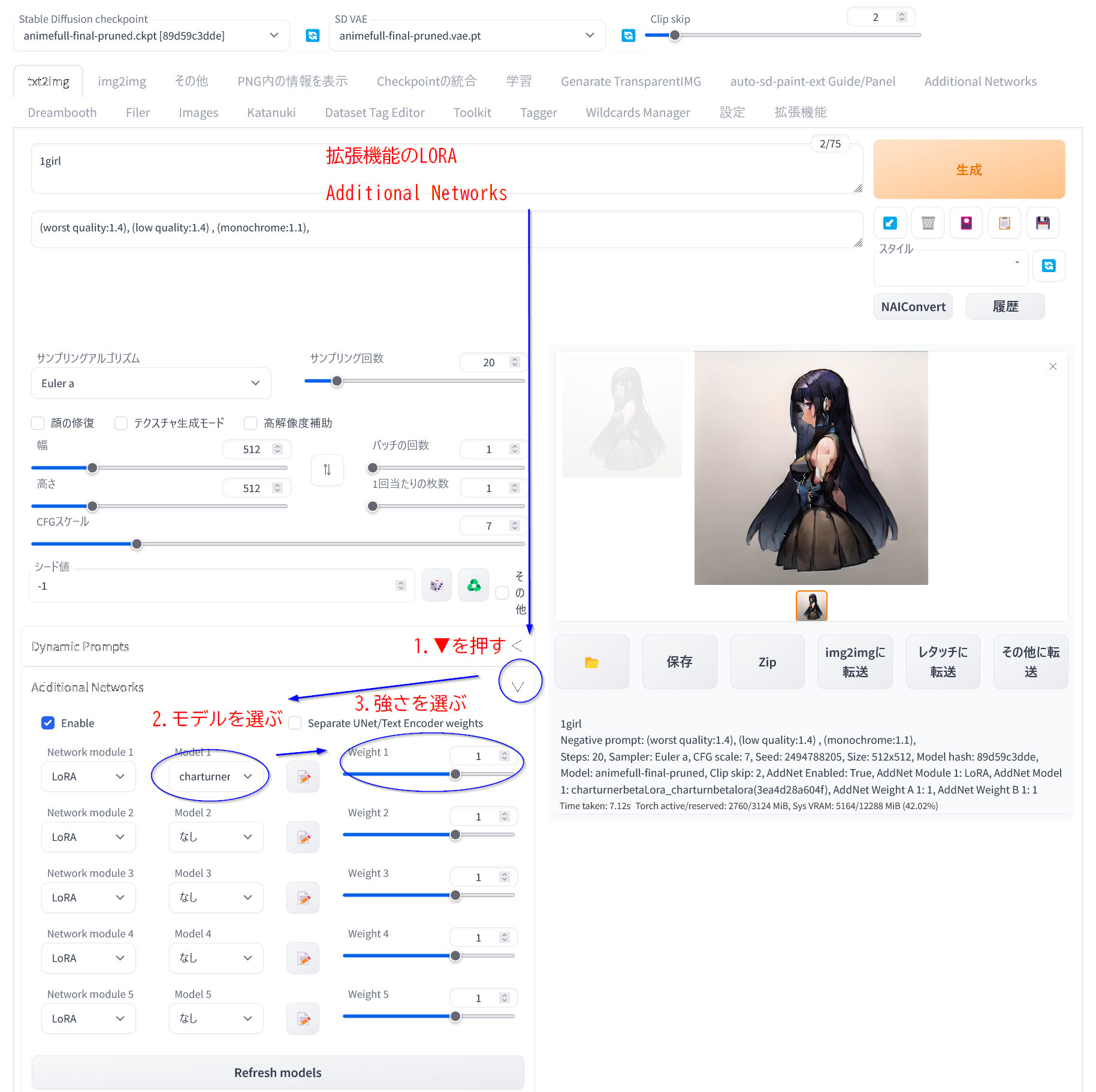
「txt2img」や「img2img」の画面の左下の方に「Additional Networks ▼」が追加されているので
Enable を押してmodelを選びmerge倍率をweightのスライダーで調整する
わからんとき用画像
使い方その2 WebUIの本体機能のみで使う
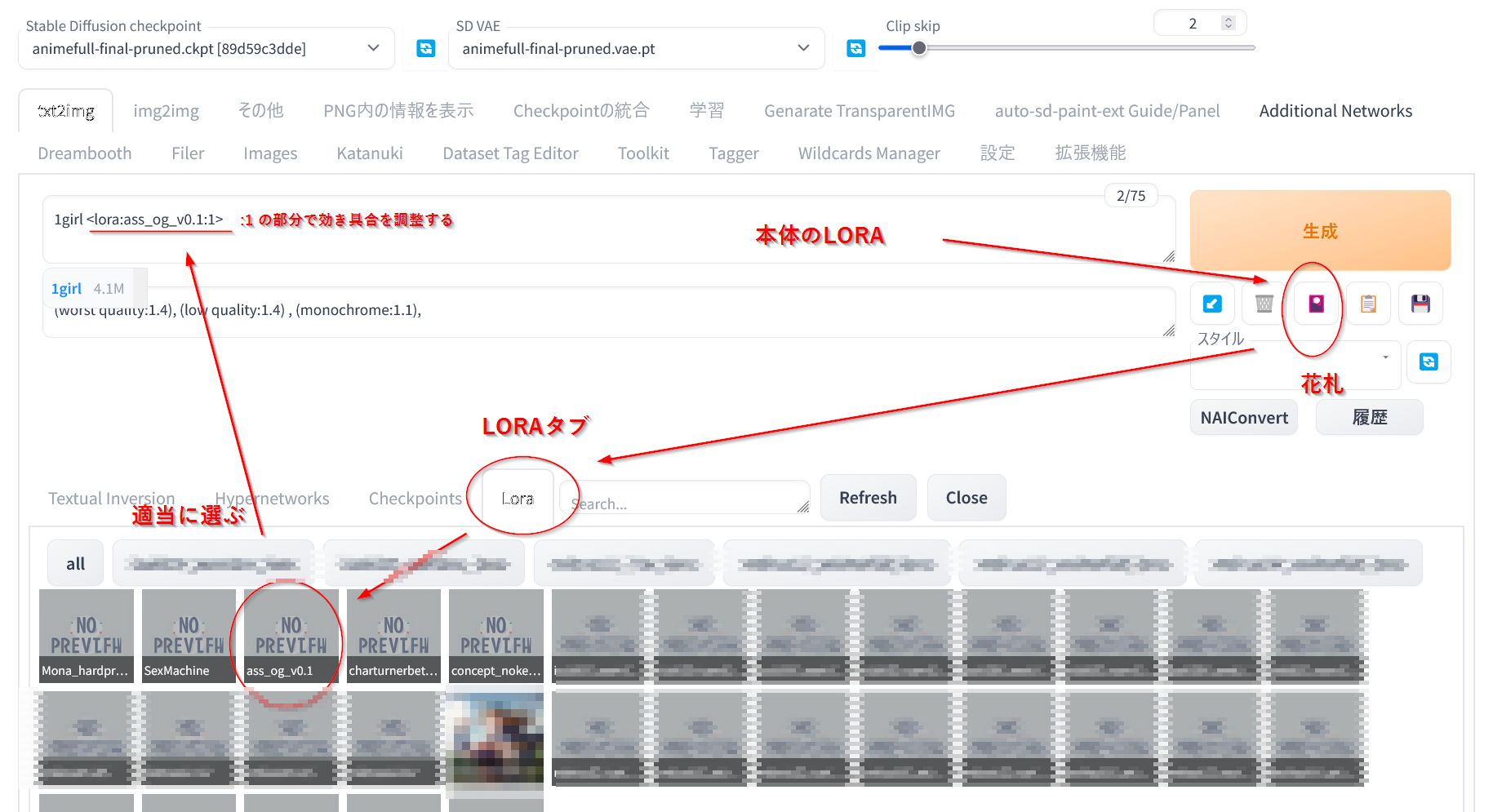
- stable-diffusion-webui\models\lora に拾った .pt や .safetensorsをコピーする
Texutual Inversion, Hypernetworks, Lora の3つのタブが出るので Lora を選択して
一覧から選ぶと <lora:ファイル名:倍率>みたいなタグがプロンプトに追加される
むかーしに作られたloraは動かんことがある
わからんとき用画像
注意点やで
- 基本的にLoraは元々「DreamBoothみたいに学習した差分ファイルをモデルにマージするための差分パッチみたいなもんとして使う」事が前提で作られとるから、今の個別適用は元々の設計と違う使い方なんや、なんで色々制限事項がある。
- Loraは原則「作ったモデルと同じ系統(SD-v1.x系 or SD-v2.x)」でしか適用できへんで。要するにAnyとかで作ったLoraはWD1.4以降とかには使われへんし、その逆もしかりや。
- よく似た使い方するHyperNetworkは系統またいでも一応反映はされとるみたいやで?しらんけど。
- また、Loraを複数1倍で重ねて使うと絵が崩壊しやすくなる。適用したい階層が違う場合、階層適用出来るエクステンションとかでずらしたらええんとちゃうかなしらんけど。
- 先にも書いた通り基本的に差分パッチみたいなもんやからモデルごとに最適な倍率はちゃうかったりするで。あっちのモデルでは1倍でちょうどよかったんがこっちのモデルでは絵が崩壊するとかも普通にあるで。倍率は適度に変えや。
- 基本的に配布されとるんはkohya氏による拡張版Loraやけど元々の実装版のLoraもDreamBoothエクステンションとかで作れたりするから作った際にはごっちゃにせんようにな?
- 拡張機能の方はkohya氏による拡張版Loraのみが対応や。本体機能の方は元々の実装版でも行けるんとちゃうかな?しらんけど。
- Loraは原則「作ったモデルと同じ系統(SD-v1.x系 or SD-v2.x)」でしか適用できへんで。要するにAnyとかで作ったLoraはWD1.4以降とかには使われへんし、その逆もしかりや。

このページへのコメント
GUIのを使ってるのですがことあるごとにterminal見るとtritonがねーよって言われるんです。
調べるとwindowsではtritonが使えない?と言われてて無くても動くし動作変わらないって聞いてますけどepoch間に5回連発で出るのは鬱陶しいので何とかなりませんか?
BooruDatasetTagManagerってどうやって起動するんですか?
何か見落としてるのか解らんとです・・・
LORAファイルを使いたいだけの者なのですが他の人も指摘してる通り狙い通りの出力結果が反映されてないことが多々あります
また効きが良いモデルと一切効かないモデルの差が激しいのですがこれは何が原因なのでしょうか…
プロンプトをよそから持ってくる(
[PNG内の情報を表示] [Images] からtxt2imgに送る) と
Addtional Networks や loraの<lora:~~~:1> の設定が上書きされるんで
もう一回 Additional Networks と プロンプトの設定をやり直すとええで多分
少し前のWebUIのバージョンで、LoRAによってはログの方に↓
activating extra network lora with arguments [<modules.extra_networks.ExtraNetworkParams object at ***>]: ValueError
とか出てて、表向き画像は出力できているが、LoRAは全く効いていない?パターンはあった
あと、本頁「使い方その2」ならトリガープロンプト入れ忘れとか?ぱっと思いつくのは
アドバイスありがとうございます
トリガープロンプトを入れても反応しないことがあるのですがとりあえずプロンプトの設定からやり直してみます
あとはwebUIを長いことアプデしてないことに気づいたのでたぶんそれも原因にありそうです
インストールだけでクソ長だからページ分ける?
めちゃめちゃ苦労したので
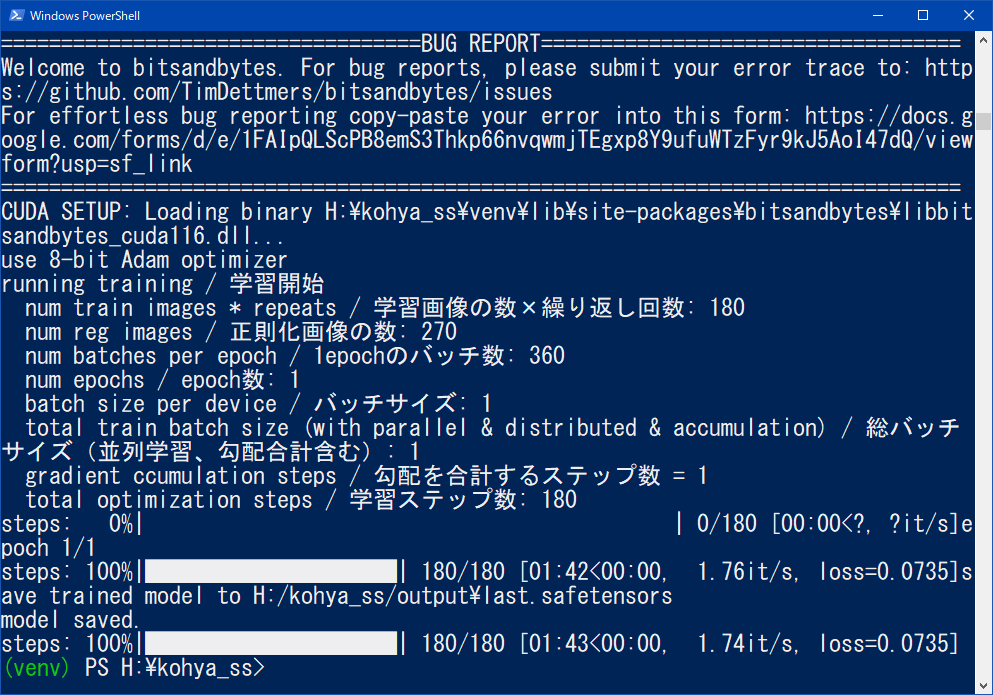
自分がエラー対応してたらうまくいったやつを書いておきます。
windows power shellでの下記の部分でエラーが出ました。
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
accelerate config
cp~の以下の3つはフォルダが自動作成されていない?ようだったので、手動でフォルダ作成することで動きました。
ただ、手動作成した場合は最後の
accelerate configでエラーとなり対処できず。
調べても見当たらないので困ったんですが、
一度sd-scriptsフォルダ削除して再度最初から実施し(特に最初からやらなくていいかもです)
pip~から始まる3つを実施後(cp~をやる前)下記をコピペ
【pip install accelerate】
これをやったうえでcp以下を進めたらエラーが出ませんでした。
他にもいろいろ同時にやってましたので、これで治るかは不明ですが、参考になれば…。
(正直なぜ治ったのかわかりません)
あとしょぼいところですが、
lora_train_command_line.pyは右クリックからedit with IDLEで編集で書き換えられます。
さっきなぜか同じ現象が起きて全く同じ対処法を試してた
あと3時間早く知ってたら・・・
自分の場合上記の方法では解決せず、一回全部消して別のドライブで試したら解決できました