
0. はじめに
バイクの長距離ソロツーリングに行ってきたのですが、正直独りだと道中かなり暇で、話し相手が欲しくなりました。というわけで、紲星あかりちゃんと対話できるシステムを作りたいなと思いました。
「アプリ」ではなく、「システム」と記載しているのは、VOICEROIDのライセンスやwindows OSでしか使用できない(はず)という特性上、いわゆるAndroidなどのアプリ化は難しいかなと思ったからです。本気出せばいけるけどね。
そういうわけで、OSはWindows10、Pythonなんかの環境構築はできている前提で話を進めます。
なお、筆者はPythonに入門して1時間程度の素人なので、Pythonのお作法はあまり知らないです。ソースに違和感があったらすまん。
1. VOICEROIDをインストール&起動する
今回は紲星あかりちゃんにに喋ってほしいので、VOICEROID2を購入してインストールします。このページまで来ている人がVOICEROIDを知らないことはないだろうと思いつつ、一応リンクを貼っておきます。

インストール手順などは公式を参照のこと。
インストールが完了したら、VOICEROID2を起動しておく。
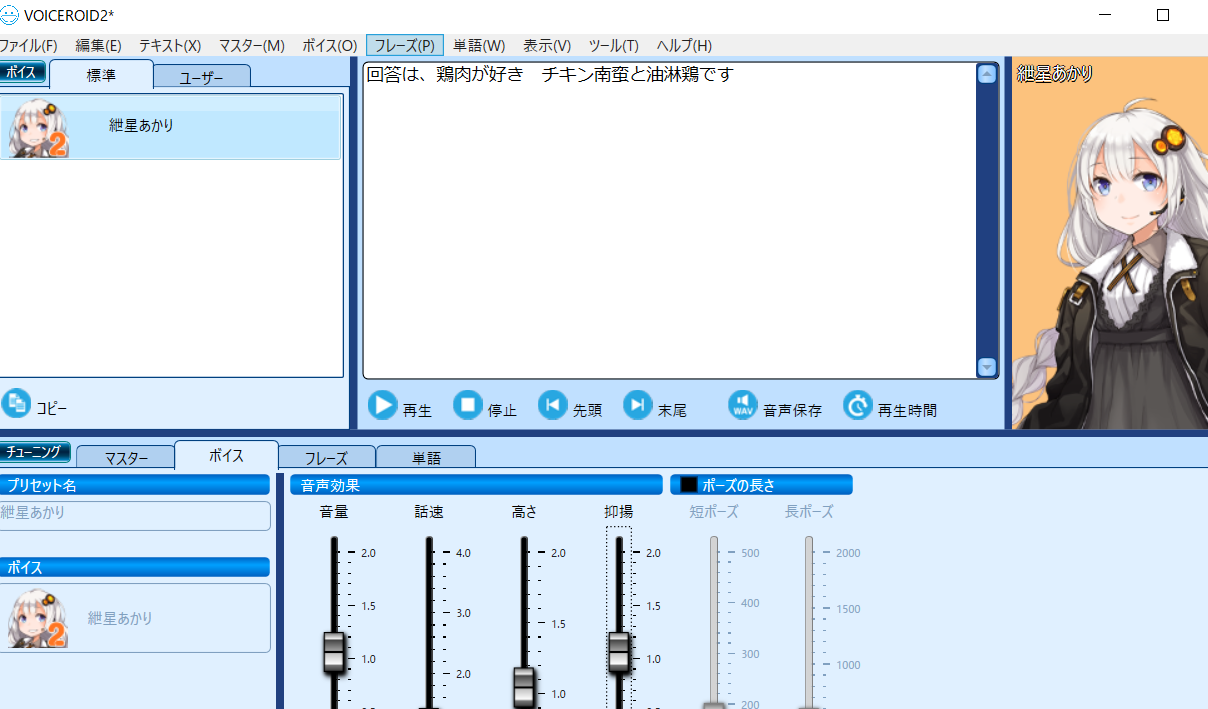
2. VOICEROIDをプログラムから喋らせられるようにする(AssistantSeikaを使う)
さて、VOICEROIDのインストールが出来たら、次は...GUI以外からなんとかVOICEROIDを発話させられるようにしていきます。
残念ながら、VOICEROIDはそれ単体ではGUIからしか使えず、Pythonなどので作ったアプリケーションとの連携はできません。
というわけで、なんとかしていきます。
AssistantSeikaをセットアップ
PythonでGUIのVOICEROIDアプリケーションのウインドウを取得すれば何とでもできるかなとは思いつつ、少しググると流石に先駆者の方がいらっしゃるようで、そちらを使わせて頂くことにしました。
AssistantSeikaという、VOICEROIDシリーズをコマンドラインなどで発話可能にしてくれるという素晴らしいツールです。
執筆時点(2022/04/03)時点では、「assistantseika20220327u2.zip」(2022/03/27 公開)が最新のようだったので、上記リンクからzipをダウンロード&展開。
展開後フォルダ直下に「AssistantSeikaSetup.msi」があるので、起動してインストーラに従ってインストールしていく。
インストールすると、下記のようにAssistantSeikaがひっそりと出来ているので、右クリック→管理者として実行で起動する。
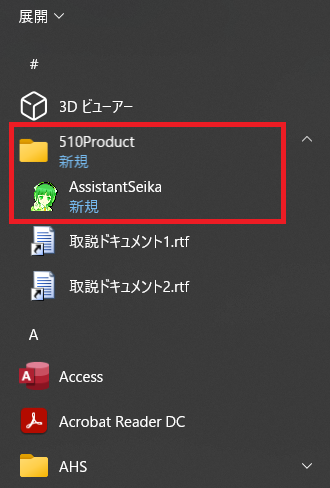
「管理者として実行」しないと、その後の発話にてどうにもエラーになったので必須っぽい。
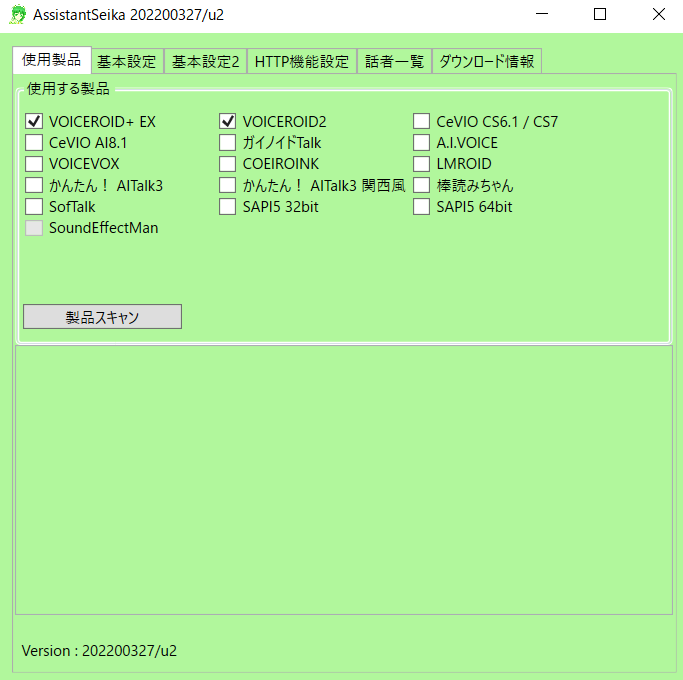
初回起動では、どの製品を使うかなどの設定があるが、VOICEROID2にチェックを入れて製品スキャンしておけばOKと思う。
コマンドラインからVOICEROIDが発話できることを確認しておく
AssistantSeika公式にコマンドラインからの叩き方が記載されているので、その通りにコマンドを叩いてVOICEROIDが発話してくれるかを確認する。
VOICEROIDのアプリが起動していること、AssistantSeikaが起動していること(管理者権限)、を確認したのち、コマンドプロンプト(PowerShellでもok)を起動し、例えば下記のコマンドを叩く。実行時は、AssistantSeikaのzip展開後フォルダの\SeikaSay2\配下(SeikaSay2.exe があるパス)で。
SeikaSay2.exe -cid 2004 -t "これはテストです"
これで、あかりちゃんが「これはテストです」と発話してくれればAssistantSeikaのセットアップはOKです!
ちなみに、-cid 2004の部分は、紲星あかりなら2004ですが、ほかのキャラクターだと値が変わるので注意。公式に記載あり。
筆者はこの時、管理者権限で実行していないことによるエラーや、VOICEROID2を起動せずにAssistantSeikaのみ起動してエラーが発生したりなどのうっかりで怒られた。
一応、Pythonからも叩けるよねを確認しておく
import subprocess
request_msg = "これはテストです"
subprocess.run("SeikaSay2.exe -cid 2004 -t \"{msg}\"".format(msg=request_msg))
3. 会話エンジンを作る(meboを使う)
さて、今度はVOICEROIDが発話する内容自体を考えるブレインの部分を作っていきます。
最初は、とりあえずネットに公開されている日本語会話データセット(あるか知らないけど)をもとに学習&モデル作成しようかと思っていたが、Python入門後1時間のワイには厳しいと判断し、既存のチャットボットサービスを使用することとした。
mebo(SaaS)の設定を行ってAPI公開する
このあたりは、考えてくれる系のモノなら何でも良いと思う。今回は、meboを使用させてもらうことにしました。チャットボットを作ってくれるSaaSで、今回のQA(自身のQに対してAを返して欲しい)目的では最適かなと思った次第。API公開にも対応しているようだったので採用。他との比較はしていないので、よりよいSaaSがあったら是非教えてほしい。
無料プランでも1カ月あたり1000会話?程度はできるようなので、ブレイン部分以外の動作確認のためには十分だろうと判断しました。
本サービス自体の設定は、上記リンクから結構しっかりと解説が書かれていて、実際私もそれにならってAIチャットボットの作成&API公開までこぎつけることができた。
APIコールのためのプログラムを書く
やっとプログラムらしいプログラムを書いていく。といってもAPIコールするだけの簡単なお仕事。ざっくり下記のような感じ。
from urllib import request
import requests
# APIをたたく
def sendRequest(msg_q):
url = 'https://api-mebo.dev/api'
item_data = {
"api_key":"<YOUR-APIKEY-HERE>",
"agent_id":"<YOUR-AGENTID-HERE>",
"utterance":msg_q,
"uid":"<YOUR-UID-HERE>"
}
return requests.post(url, headers={}, json=item_data)
# Answerをいい感じに捌く
def getAnswerMsg(msg_q):
res = sendRequest(msg_q)
res_json = res.json()
return res_json["bestResponse"]["utterance"]
sendRequestはAPIを叩く層、getAnswerMsgはメッセージを編集して返す層みたいなイメージ。(それぞれがどんな方法をとろうが影響少なくするように一応切ってる)
getAnswerMsgを叩くことで、meboのチャットボットAPIにRequest飛ばしてQへのAnswer部分を取り出して返却してきます。
20行もかかずしてブレインが出来ました。頼れるところは外部サービスを使うぜ!(まあ、SaaSの理解やセットアップのために時間は使うけどね)
4. 音声からテキスト変換する部分を作る(SpeechRecognitionを使う)
口(VOICEROID本体とAssistantSeika)が出来て、脳(mebo(チャットボット))が出来たので...あとは、耳ができればこのシステムとしては一応動くことになります。
というわけで、ユーザ(わたし)からの音声を入力とし、テキストに変換してVOICEROIDに食わせるためのロジックを組んでいきます。
SpeechRecognitionを入れる
英語の音声認識のためのライブラリは多々あるのですが、日本語となると殆ど選択肢がなく...できればオフラインが良かったのですが、いったんオンラインのGoogle Speech Recognitionを使用し、日本語音声データをテキストに変換していきます。
そのためのロジックを自前で組む必要はなく、やはり先駆者がライブラリにしてくれているので、それを使用します。下記Qiita記事でもまとめられてます。私も参考にさせて頂きました。
本家Gitは下記。
他にも色々な音声認識の方法がありますが、今回はGoogle Speech Recognition一択でとりあえず良しとしようと思った。いったんシステムを完成させた後に、部分部分の改良をしていこうと思っている。
pip installしてやればOKかと思っていたが...それだけではだめで、「PyAudio」を別途入れる必要がある。mac osなんかだとコマンドライン1つで全てうまくいけるらしいが...windowsではだめかもしれない。下記を参考にした。
speech_recognitionの他の音声認識方法を使用する場合は、さらに別の何かを入れる必要がありそうだったが、google...の音声認識ではいったんこれで大丈夫だった。
音声認識のためのコードを書く
spech recognition公式にexamplesにも記載があるが、音声認識のためのコードを一応書いておく。こんな感じ。
import speech_recognition as sr
import subprocess
def main():
r = sr.Recognizer()
with sr.Microphone() as source:
r.adjust_for_ambient_noise(source)
print("あかりちゃんへの質問を喋ってね:")
audio = r.listen(source)
msg = ""
try:
msg = r.recognize_google(audio, language='ja-JP')
print("-----------detect!----------\n", msg)
except sr.UnknownValueError:
print("Could not understand audio")
except sr.RequestError as e:
print("Could not request results; {0}".format(e))
if msg != "":
print("あなたが喋ったのは " + msg)
else:
print("聞き取れなかったみたいです...")
if __name__ == "__main__":
main()
今回は日本語なので、examplesにはなかったが r.recognize_googleの部分でlanguage='ja-JP'を指定しておく。
半信半疑で実行してみたが...ちゃんと音声がテキストになって表示された。感動した。
5. 発話/思考/音声変換 を全て繋げて会話システムとする
今まで作ってきたすべてを連結して、ざっくり下記のようにした。
フォルダ構成は、下記。
/
main.py
voiceroid_speaks.py
voiceroid_speaks.pyは、引数として渡された質問テキストをAPIに投げてVOICEROID発話する部分までを担当、
main.pyは音声認識&voiceroid_speaks.pyキックといった感じ。
切り方が汚いはすまん。
import speech_recognition as sr
import subprocess
def main():
r = sr.Recognizer()
with sr.Microphone() as source:
r.adjust_for_ambient_noise(source)
print("あかりちゃんへの質問を喋ってね:")
audio = r.listen(source)
msg = ""
try:
msg = r.recognize_google(audio, language='ja-JP')
print("-----------detect!----------\n", msg)
except sr.UnknownValueError:
print("Could not understand audio")
except sr.RequestError as e:
print("Could not request results; {0}".format(e))
if msg != "":
subprocess.run("py voiceroid_speaks.py {msg}".format(msg=msg))
else:
print("聞き取れなかったみたいです...")
if __name__ == "__main__":
main()
import sys
import subprocess
from urllib import request
import requests
# APIをたたく
def sendRequest(msg_q):
url = 'https://api-mebo.dev/api'
item_data = {
"api_key":"<YOUR-APIKEY-HERE>",
"agent_id":"<YOUR-AGENTID-HERE>",
"utterance":msg_q,
"uid":"<YOUR-UID-HERE>"
}
return requests.post(url, headers={}, json=item_data)
def getAnswerMsg(msg_q):
res = sendRequest(msg_q)
res_json = res.json()
return res_json["bestResponse"]["utterance"]
# MAIN LOGIC
def main():
PATH_TO_SEIKASAY2EXE = "C:\\hogefoobar\\assistantseika\\SeikaSay2\\SeikaSay2.exe"
args = sys.argv
# 第一引数をQとしておく
request_msg = args[1]
print("request_msg: " + request_msg)
if request_msg != "":
# 回答を用意する(とりあえずv1は外部APIを使う)
response_msg = getAnswerMsg(request_msg)
print("response_msg: " + response_msg)
# VOICEROIDに喋らせる
subprocess.run("{exe_path} -cid 2004 -t \"回答は、{msg}\"".format(msg=response_msg, exe_path=PATH_TO_SEIKASAY2EXE))
else:
subprocess.run("{exe_path} -cid 2004 -t \"質問が聞き取れなかったみたいです\"")
if __name__ == "__main__":
main()
これで、あかりちゃんと会話することに成功した。感動した。完成後の様子を載せたいが、gifだと何も伝わらない(音声が出ない)が、Youtubeにアップするには内容の毛色が違い過ぎるので...どうしようか悩んでいる。
今後は、ブレインの部分を自前で作成し、よりナチュラルな会話ができるようにブラッシュアップしていきたい。



コメント