こんにちは、ぐぐりら(@guglilac)です。
久しぶりのブログ更新です。 論文紹介記事です。
今回は少し古めですが、BPR: Bayesian Personalized Ranking (BPR)を読みました。
購買データやclickデータといったimplicit feedbackからランキングを学習する手法です。
3行まとめ
implicit feedbackでpersonalized ranking(item recomendation)を行うためのlossとしてBPR-OPTを提案。 rankingの指標であるAUCを近似したlossを直接最適化することでランキング作成を学習する。またbootstrap samplingを用いた勾配法である学習法としてLEARN-BPRを提案。従来のuser/item-wiseのupdateを行う勾配法より高速。
問題設定とこれまでの手法
implicit feedback(購買履歴とかclickデータ)のみからranking学習をする。
logにはpositive labelのみ存在するため、 logに出ていないitemとuserの組み合わせは
- ほんとうに興味がない
- 興味はあるけどまだ買ってない
の二つが混ざっている。 そのためこの未観測データをそのまま負例として扱う従来の手法では筋が悪い。
これまでの手法では、 観測できないデータをサンプルしてきてnegative labelとして扱って分類するので、 興味はあるけどまだ買ってない(user x item)を0と予測する。これではうまくいかない
BPRの気持ち
BPRでは、 履歴に出てきたitem Aとuser Bの組 履歴にないitem C とuser Bの組
については、「user Bが item Aを item Cより好む」 と仮定する。
出てきていない者同士、出てきた者同士はどちらをより好むかはわからないとする
user Bが item Cを少しは好んでいてまだ買っていない状態だとしても、item Aよりは好みの度合いが小さい、みたいなことを表現できている。つまり未観測の組み合わせについて、全てnegativeと捉えるのではなく、観測データ同士、未観測データ同士に濃淡をつけることができるということ?
ということで、BPRは
現時点ではどちらをより好むかがわからないpairに関して順序を予測する予測するためのモデル
と解釈した。
(論文中には、BPRの利点のところに、未観測のitem同士の優劣を学習できる、と書いてあったけど、観測されたデータ同士の優劣も学習できるのでは。)
BPRの説明
上で書いた気持ちをそのままベイズで書くとBPR-OPTというlossが作れる。 (user,item1,item2)の三つ組をもらって、userがどちらのitemをより好むか判定するモデルを学習する。
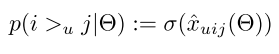
itemとuserの組に何らかのスコアを出して、その差をsigmoid関数に通すことでuser1がuser2より好まれる確率を出力する、という感じ。
これを使ってlossを作る
尤度がこうなって

loss(BPR-OPT)が次のようになる。

このように作ったBPR-OPTは、AUCを微分可能にした近似になっている。
学習方法(LEARN-BPR)
全データを一度に見て勾配法をするのはデータが多すぎてしんどい
SGDは、user-wiseやitem-wiseのように同じitemやuserを連続して渡すとskew problemがあって収束が遅くなるらしい。
Learn BPRアルゴリズムとして、bootstrap samplingをする方法を提案。ランダムにとってきてSDGするというだけ。
BPRの疑問点
BPRの背後にある仮定は、 userに関して何らかの正解itemランキングがあって、implicit feedbackによって私たちが観測するのは そのランキングの上位のみ、というものだと思う
5つitemがあって、clickされたのが2つあったとして、それらは好みの順で言えば1位と2位であるという仮定。 clickされていないデータが実は1位でした、みたいなことはないですよ、という仮定
これを実際に使うとなると、rankingの指標で評価するわけなので、 implicit feedbackしか得られないけどrankingの評価ってどうやるんだろう、という気持ち。
一般的に、rankingの評価は正解ratingから計算するものと、binaryのlabelが与えられてprecision@Kみたいにやるものがあるけど、今回は後者でやらないといけない。
今回の実験では、 評価はAUCで行っている。 AUCは、正例と負例を比較して正しく順序付けられた割合。

みたいなもので、これ自体はrankingを評価するのによく使われる評価指標ぽいけど、 (userごとにAUCだして平均とる)
今回の実験では正例を観測データ、負例を未観測データ全体としていて、(もちろん観測データも未観測データもtestの場合はtrainには含まれない者を使用。userごとに1つのpositive なitemをtest用に切り出しているらしい)
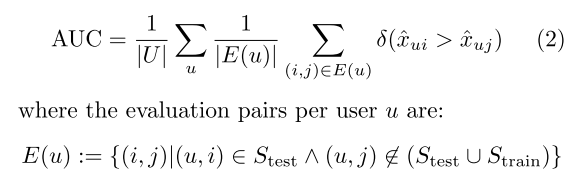
のだが、未観測データを負例として扱って評価しているのって間違ってね? 本研究のやりたいこと、で
未観測データ同士の優劣を予測したい
みたいなことが書かれていたのに、これではそこの評価ができないよね? implicit feedbackだけでは本当に最適化したいAUCが計算できないのでは。
BPRのlossはAUCの近似(微分可能な関数での置き換え)なわけで、このように計算したAUCで評価したらそりゃ強いけど、本当にやりたいことってそこだったの?という疑問が湧いた。
極端な話、このAUCで評価すると、観測データを正例、未観測データを負例としてclassifierをloglossで最適化しても、(完全にfitできたら)結果は同じAUCになるんじゃない?と思った。
観測データか未観測データかを完全に判定できたら、それでもAUCは1になるよね、という。
じゃあどうやれば本当に評価したかった部分が示せるか、と言われると
例えば、 ratingがわかっているデータセットを持ってきて、userごとに上位のitemのみimplicit feedbackとして観測されるようにデータセットを作り、implicit feedbackを使って学習したBPRモデルで全順序がつくのでランキングが予測でき、rating経由で作ったランキングと比較、とか?でもratingが全itemについている必要があるか。。
人工データでならこの方法で試せそう。
今回のようにimplict feedbackしか得られない状況でランキングの良さを評価するとなると、
precision@k とか recall@kとかがいいのかな?
これで評価すれば、loglossを最小化したものと比較してもいい結果になることは理解できる。 逆にAUCで評価している場合、普通に観測データを1、未観測データを0としてloglossで学習するのでも最適解は同じになるような気がしていて、いまいち良さがわからないなと思った。
おわりに
結局、
観測データどうし、未観測データどうしの濃淡をimplicit feedbackから作れる、ってところが売りなのかと思ったら、評価はimplicit feedbackから計算したAUCで行っていて、これだとBPRとloglossの最適した結果でどう違うのかがよくわからなかった。
ただ評価方法さえ作れれば使えそうなので使ってみたい。
ありがとうございました。
















コメント失礼します。
返信削除元論をあまり読み込めていないので、とんちんかんな質問でしたらすみません。
最適な行列分解を求めた後は、どのようにランク付けするのでしょうか?
得られたembeddingの内積をとって、その値でsortしてランク付けするのだと思います。
削除ありがとうございます。
削除