
MySQLのEXPLAIN(実行プラン)について、まとめます。
EXPLAINは、クエリがどのように実行されるかを確認できます。
例えば、昨日まで1sだったクエリが、今日は10sかかる。という経験はないでしょうか。
EXPLAINを確認すると、意図しないIndexが使われいて、遅くなっていた。ということがあります。
はじめに
MySQL 5.6.3以降では、EXPLAIN に使用できる説明可能なステートメントは、SELECT、DELETE、INSERT、REPLACE、UPDATE です。MySQL 5.6.3より前では、SELECT が唯一の説明可能なステートメントです。
今回は、MySQLのバージョンは5.7で試します。
EXPLAIN確認方法
クエリの先頭に EXPLAIN をつけて実行します。
EXPLAIN SELECT * FROM users WHERE id = 1
結果
Keyが PRIMARY のため、users テーブルのプライマリキーを使ったことがわかります。
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | users | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
各項目の説明
| 項目 | 内容 |
|---|---|
| id | 実行順序 |
| select_type | SIMPLE: 単純な SELECT (UNION やサブクエリーを使用しません) PRIMARY: もっとも外側の SELECT UNION: UNION 内の 2 つめ以降の SELECT ステートメント DEPENDENT: UNION 内の 2 つめ以降の SELECT ステートメントで、外側のクエリーに依存します UNION RESULT: UNION の結果。 SUBQUERY: サブクエリー内の最初の SELECT DEPENDENT SUBQUERY: サブクエリー内の最初の SELECT で、外側のクエリーに依存します DERIVED: 派生テーブル SELECT (FROM 句内のサブクエリー) MATERIALIZED: 実体化されたサブクエリー UNCACHEABLE SUBQUERY: 結果をキャッシュできず、外側のクエリーの行ごとに再評価される必要があるサブクエリー UNCACHEABLE UNION: キャッシュ不可能なサブクエリーに属する UNION 内の 2 つめ以降の SELECT |
| table | 対象テーブル |
| partitions | テーブルパーティション |
| type | system: テーブルに1行しかない const: プライマリキー、ユニークキーのルックアップによるアクセス eq_ref: joinにおいてのconstと同義 ref: constでないインデックスを使って等価検索 range: indexを用いた範囲検索 index: フルインデックススキャン ALL: フルテーブルスキャン fulltext: FULLTEXTインデックスによる検索 ref_or_null: refに追加でNULL値でも検索する index_merge: インデックスマージ最適化を使用 unique_subquery: 効率化のため、サブクエリーを完全に置き換える単なるインデックスルックアップ関数 index_subquery: 働きは、unique_subqueryと同様。サブクエリー内の一意でないインデックスに対して機能する |
| possible_keys | optimizerがテーブルのアクセスに利用可能だと判断したインデックス |
| key | 実際にoptimizerによって使用されたキー |
| key_len | 選択されたキーの長さ |
| ref | 定数の場合: const JOINを使用している場合: 結合する相手側のテーブルで検索条件として利用されているカラムが表示される |
| rows | 対象テーブルから取得される行の見積もり |
| filtered | テーブル条件によってフィルタ処理される行の推定の割合 |
| Extra | optimizerがどのような戦略を立てたかを知ることが出来る |
typeがALL(テーブルフルスキャン)または、index(フルインデックススキャン)は、注意が必要です。
データ量が少ないテーブルであれば問題ありませんが、データ量が多いテーブルでフルスキャンをしてしまうと、パフォーマンスに影響します。(例えば、1件対象データを探す場合でも、フルスキャンした場合は、テーブル内の全データから探そうとします)
参考
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-join-types
バインド変数を使ったクエリのEXPLAIN
バインド変数(プレースホルダ)次のように確認します。
SET @num=1;
EXPLAIN SELECT * FROM users WHERE id = @num;
バインド変数を使った場合と、直接リテラルを指定するのとで、EXPLAIN結果に差がでる場合があります。
実際と同じクエリでEXPLAINを実行してください。
参考:https://teratail.com/questions/299162
実行中のクエリを調べてEXPLAIN
実行中のクエリは、show processlistで確認できます。
SHOW PROCESSLIST;
+----+--------+------------------+--------+---------+------+----------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+--------+------------------+--------+---------+------+----------+------------------+
| 1 | root | 172.0.0.1:62456 | NULL | Query | 0 | starting | show processlist |
+----+--------+------------------+--------+---------+------+----------+------------------+
3 rows in set (0.01 sec)
Infoにクエリが表示されます。ただし、全文表示されない場合があります。
その場合は、show full processlistを実行してください。
SHOW FULL PROCESSLIST\G
クエリが表示されたらEXPLAINEで確認できます。
5.7からはEXPLAIN FOR CONNECTIONが使えるようになりました。PROCESSLISTのIdを指定するだけで、EXPLAINEが取得できます。また、自分自身のプロセスに対してEXPLAIN FOR CONNECTIONを発行してしまうと無限LOOPのような挙動になります(無限にコネクションが増えていく)。指定するIdを間違えないように注意してください。
EXPLAIN FOR CONNECTION <Id>
統計情報
EXPLAINはmysqlのオプティマイザにより生成されます。
オプティマイザは、クエリを解析して、最適な実行プランを立ててくれます。問い合わせの最適化を行う機能です。
では、どのようにオプティマイザは考えるのでしょうか。
一つはDBに保存されている統計情報を元に考えています。
テーブルやインデックスに、どのようなデータが入っているか。の統計です。
テーブルの統計情報
select * from mysql.innodb_table_stats;
+---------------+----------------------+---------------------+--------+----------------------+--------------------------+
| database_name | table_name | last_update | n_rows | clustered_index_size | sum_of_other_index_sizes |
+---------------+----------------------+---------------------+--------+----------------------+--------------------------+
| test | users | 2021-02-07 10:41:28 | 0 | 1 | 0 |
+---------------+----------------------+---------------------+--------+----------------------+--------------------------+
- last_updateは、最後に行を更新した日付(統計を取り直した日付)
- n_rowsは、テーブル内の行数
- clustered_index_sizeは、プライマリキーのサイズ(ページ数)
- sum_of_other_index_sizesは、プライマリキー以外のインデックスのサイズ(ページ数)
補足
テーブルの件数とn_rowsが合わないことがあります。n_rowsは統計情報を更新したときのテーブル件数です。
例えば、1月1日にn_rowsが10だとして、1月2日に3件登録があり、合計13件になったとします。この場合、統計情報が更新されなければ、n_rowsは10のままです。更新されると13になります。
インデックスの統計情報
select * from mysql.innodb_index_stats;
+---------------+----------------------+-------------------------------------------+---------------------+--------------+------------+-------------+------------------------------------+
| database_name | table_name | index_name | last_update | stat_name | stat_value | sample_size | stat_description |
+---------------+----------------------+-------------------------------------------+---------------------+--------------+------------+-------------+------------------------------------+
| test | users | PRIMARY | 2021-02-07 10:41:28 | n_diff_pfx01 | 0 | 1 | id |
| test | users | PRIMARY | 2021-02-07 10:41:28 | n_leaf_pages | 1 | NULL | Number of leaf pages in the index |
| test | users | PRIMARY | 2021-02-07 10:41:28 | size | 1 | NULL | Number of pages in the index |
+---------------+----------------------+-------------------------------------------+---------------------+--------------+------------+-------------+------------------------------------+
- last_updateは、最後に行を更新した日付(統計を取り直した日付)
- stat_nameは、stat_value カラムに値がレポートされている統計の名前
- stat_valueは、stat_name カラムで名前が指定されている統計の値
- sample_sizeは、stat_value カラムに示されている推定値のサンプリングされるページの数
- stat_descriptionは、stat_name カラムで名前が指定されている統計の説明
stat_name、stat_value
stat_name、stat_valueが何かわかりにくいので、少し詳しくみていきます。
size
stat_name=sizeである場合、stat_value カラムには、インデックス内のページの総数が表示されます。DBはページという単位でデータが格納されます。つまり、ページが多いほどインデックスの容量が大きくなります。今回は1件しか入っていないテーブルなので、「1」と表示されています。
n_leaf_pages
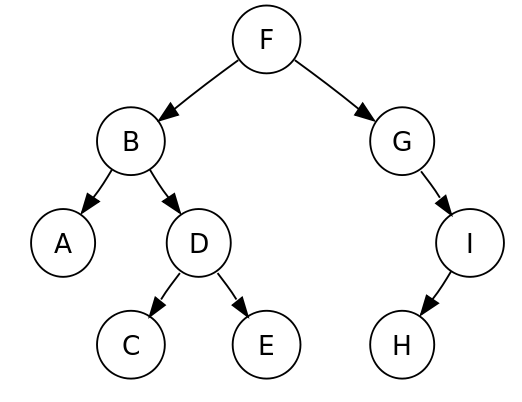
stat_name=n_leaf_pages である場合、stat_value カラムには、インデックス内のリーフページの数が表示されます。
インデックスは下図のように上からデータをたどる構造になっています。末端のことをリーフといいます。(下図だとA,C,E,H)
n_diff_pfxNN
stat_name=n_diff_pfx01である場合、stat_descriptionに書かれているカラムのデータの種類(カーディナリティ)がstat_valueカラムに入ります。
例えば
- id:1だけテーブルに登録されていた場合、stat_valueは、1
- id:1〜5の5件がテーブルに登録されていた場合、stat_valueは、5
- id:1が5件テーブルに登録されていた場合、stat_valueは、1 (※idを重複ありのインデックスと考えた場合)
さらに、n_diff_pfx01がn_diff_pfx02、n_diff_pfx03と連番で登録されることがあります。
これは複数カラムを一つのインデックスにした場合です。
例えば、first_nameとlast_nameを一つのインデックスにしたカラムがあったとします。
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| 鈴木 | 太郎 |
| 鈴木 | 次郎 |
+------------+-----------+
n_diff_pfx01とn_diff_pfx02の統計情報が作成されます。
n_diff_pfx01のstat_descriptionには、first_name。
n_diff_pfx02のstat_descriptionには、first_name、last_nameと登録されます。
n_diff_pfx01のstat_valueは鈴木で「1」です。
n_diff_pfx012stat_valueは(鈴木、太郎)、(鈴木、次郎)で「2」です。
sample_size
sample_sizeは、統計情報作成にあたり、どの程度データを調べるかです。
100ページあるデータの、1ページだけを見て統計を作成するのか、50ページ見て統計を作成するのかでは、精度が違います。
たくさんのページを見た方が精度はあがりますが、DBの時間とリソースを使います。
参考
https://dev.mysql.com/doc/refman/5.6/ja/innodb-persistent-stats.html
統計情報の更新タイミング
テーブル内のデータが大幅に変更されたあとは、InnoDB によって自動的に永続的統計が再計算されます。現在(5.6以降)のしきい値は、テーブル内の行の 10% です。
統計情報が更新される理由
例えば、稼働当初、「鈴木」というデータが10件登録されていました。
統計情報では、n_diff_pfx01のstat_valueは1と登録されます。一ヶ月後、たくさんの人が登録し名字の種類が佐藤、斎藤など、100種類に増えました。統計情報が更新されないと、DBは「鈴木」の1l種類しか存在しないと考え、1種類を探すのに最適な実行をします。しかし、実際には100種類あるので、DBが考えたプランは最適ではないのです。
これにより、インデックスを使ってほしいのに、使われない。スキャンして欲しいのにフルスキャンしてしまう。ということが発生します。更新されるテーブルに対しては定期的に統計情報更新が必要です。
参考
https://dev.mysql.com/doc/refman/5.6/ja/innodb-parameters.html#sysvar_innodb_stats_auto_recalc
手動での統計情報更新
統計情報を手動で更新できます。例えば、1億件あるテーブルは、1千万件データが更新されないと、統計情報が自動で再取得されません。実際には300万更新されたタイミングで取得したい場合などがあります。
ANALYZE TABLE <テーブル名>;
オプティマイザトレース
ここまでで、実行プランの確認方法、統計情報やオプティマイザの役割について説明しました。
さらに踏み込んで、どのように実行プランが作成されるのかを確認してみます。
オプティマイザが考えた実行プラン生成の詳細を取得してみます。
手順は4つ
- オプティマイザトレースを有効化する
- クエリを実行する
- トレースを表示する
- トレースを無効化にする
まず、トレースを有効にします。
SET optimizer_trace="enabled=on";
クエリを実行します。
select * from users where id = 1;
トレースを表示します。
SELECT * FROM information_schema.optimizer_trace\G
※結果が長いので後述
トレースの無効化
SET optimizer_trace="enabled=off";
トレース結果
EXPLAINをより詳細にした結果が得られました。
*************************** 1. row ***************************
QUERY: select * from test.users where id = 1
TRACE: {
"steps": [
{
"join_preparation": {
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `test`.`users`.`id` AS `id`,`test`.`users`.`name` AS `name` from `test`.`users` where (`test`.`users`.`id` = 1)"
}
]
}
},
{
"join_optimization": {
"select#": 1,
"steps": [
{
"condition_processing": {
"condition": "WHERE",
"original_condition": "(`test`.`users`.`id` = 1)",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "multiple equal(1, `test`.`users`.`id`)"
},
{
"transformation": "constant_propagation",
"resulting_condition": "multiple equal(1, `test`.`users`.`id`)"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "multiple equal(1, `test`.`users`.`id`)"
}
]
}
},
{
"substitute_generated_columns": {
}
},
{
"table_dependencies": [
{
"table": "`test`.`users`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
]
}
]
},
{
"ref_optimizer_key_uses": [
{
"table": "`test`.`users`",
"field": "id",
"equals": "1",
"null_rejecting": false
}
]
},
{
"rows_estimation": [
{
"table": "`test`.`users`",
"rows": 1,
"cost": 1,
"table_type": "const",
"empty": false
}
]
},
{
"condition_on_constant_tables": "1",
"condition_value": true
},
{
"attaching_conditions_to_tables": {
"original_condition": "1",
"attached_conditions_computation": [
],
"attached_conditions_summary": [
]
}
},
{
"refine_plan": [
]
}
]
}
},
{
"join_execution": {
"select#": 1,
"steps": [
]
}
}
]
}
MISSING_BYTES_BEYOND_MAX_MEM_SIZE: 0
INSUFFICIENT_PRIVILEGES: 0
以上になります。





コメント