
概要
強化学習のシミュレーション環境「OpenAI Gym」について、簡単に使い方を記載しました。
類似記事はたくさんあるのですが、自分の理解のために投稿しました。
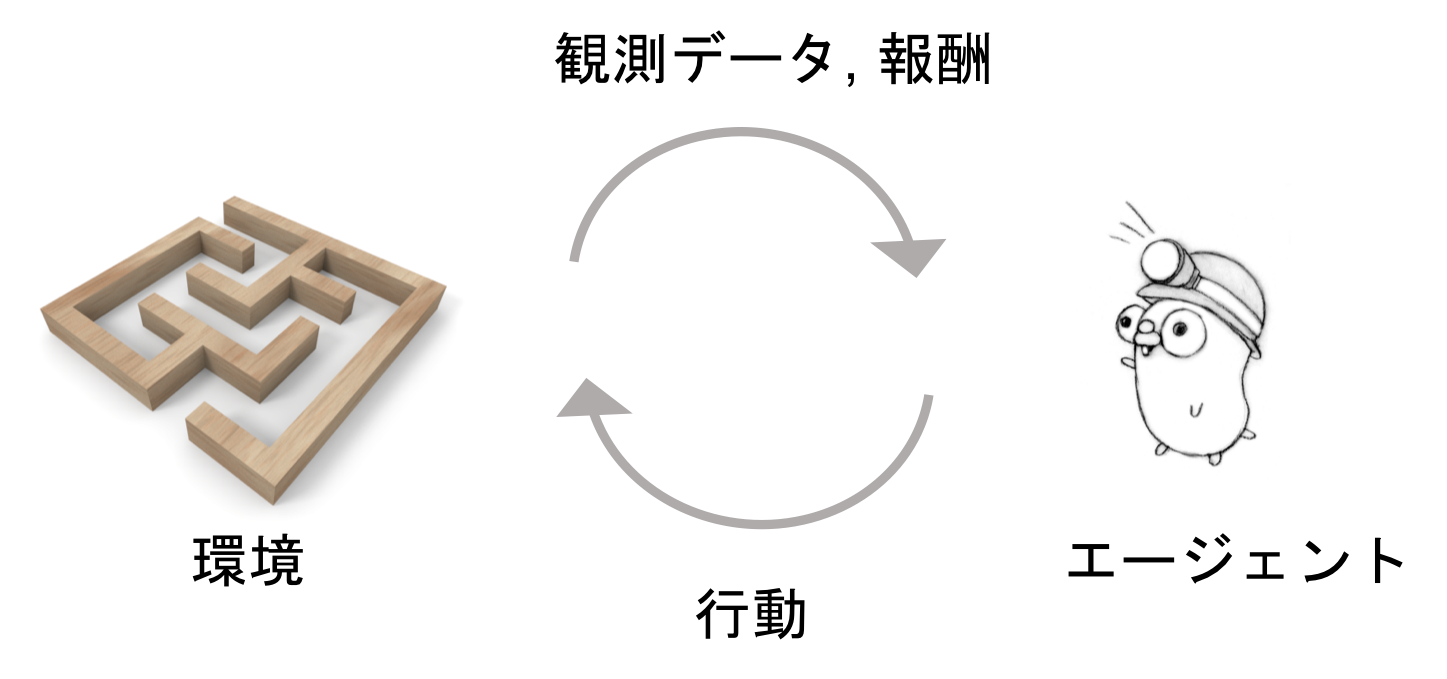
強化学習とは
ある環境において、自律エージェントが状況を観測しながら行動することを繰り返し試行し、目的を達成するための最適な意思決定を学習する、機械学習の方法。
教師あり学習とは違い、環境から得られる報酬を元に、行動の良し悪しを評価する。
The Go gopher was designed by Renée French.
OpenAI Gym とは
人工知能を研究する非営利企業 OpenAIが作った、強化学習のシミュレーション用プラットフォーム。
オープンソース https://github.com/openai/gym
OpenAI Gym インストール方法
1. 基本パッケージのインストール
pip install gym
2. 依存ライブラリインストール
OSX:
brew install cmake boost boost-python sdl2 swig wget
Ubuntu 14.04:
apt-get install -y python-numpy python-dev cmake zlib1g-dev libjpeg-dev xvfb libav-tools xorg-dev python-opengl libboost-all-dev libsdl2-dev swig
3. Atari社のGameを動かすライブラリをインストール
pip install 'gym[atari]'
※ その他、全環境ライブラリ
pip install 'gym[all]'
OpenAI Gym 使い方
基本的な使い方
エージェントを動かす環境
makeの引数に環境名(ゲーム名)を指定し、環境インスタンスenvを生成
import gym
env = gym.make('MountainCar-v0')
生成できる環境の一覧は以下で取得できる。
from gym import envs
envids = [spec.id for spec in envs.registry.all()]
それぞれが何の環境かは公式サイト[*]に記載されている
環境を初期化する
observation = env.reset()
reset()にて、初期状態の観測データobservationが取得できる。
現在の環境を描画
env.render()
観測データ
MountainCar-v0(山登り)の場合、以下のような配列が観測データとして取得できる。
それぞれの意味はGitHub wikiに記載されている。
print(observation)
>> [-0.56957656 0. ]
| 内容 | Min | Max | |
|---|---|---|---|
| 0 | 車の位置 | ||
| 1 | 車の速度 |
観測データの最小値と最大値は以下で取得。
# 観測データの最大値
print(env.observation_space.high)
>> [0.6 0.07]
# 観測データの最小値
print(env.observation_space.low)
>> [-1.2 -0.07]
環境ごとに観測データが何を示すかは異なるため、それぞれ公式ドキュメント[*]を参照。
観測データの配列次元は以下で調べられる。
print(env.observation_space)
>> Box(2,)
エージェントを動かす
環境インスタンスenvのstep()関数の引数にアクションデータを設定する。
MountainCar-v0(山登り)の場合、アクションの値はそれぞれ以下の通り。
| 値 | 内容 |
|---|---|
| 0 | 左へ押す |
| 1 | 何もしない |
| 2 | 右へ押す |
GitHub wikiに記載されている。
# 左
action = 0
observation, reward, done, info = env.step(action)
行動を実施した戻り値として、行動後の観測データ・報酬・ゲーム終了フラグ・詳細情報が得られる。
山登りの場合、詳細情報はなく、報酬は各ステップごとにと固定。
環境ごとの行動の値は以下で調べられる。
print(env.action_space)
>> Discrete(3)
Discrete(3)は、3つの離散値[0, 1, 2]
まとめ
- 環境を生成
gym.make(環境名) - 環境をリセットして観測データ(状態)を取得
env.reset() - 状態から行動を決定 ⬅︎ アルゴリズム考えるところ
- 行動を実施して、行動後の観測データ(状態)と報酬を取得
env.step(行動) - 今の行動を報酬から評価する ⬅︎ アルゴリズム考えるところ
- 3~5.を繰り返す
Q-Learningで山登りをクリアする
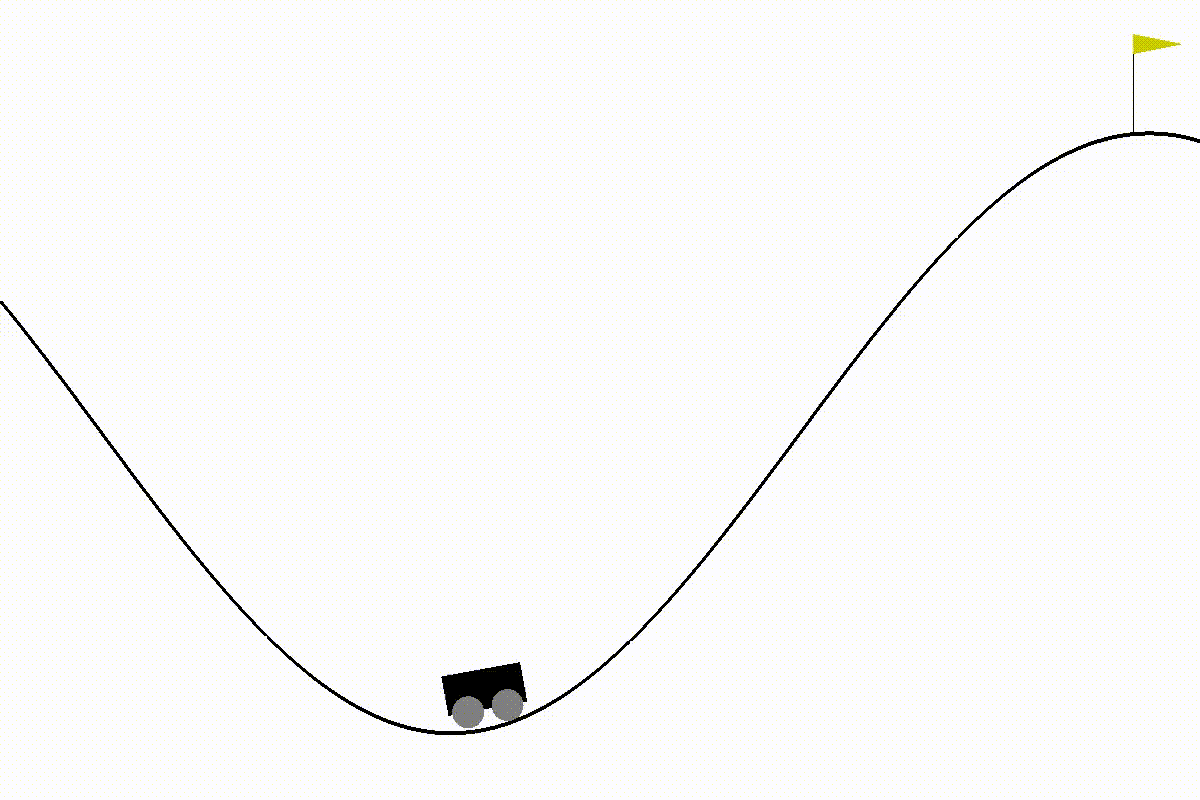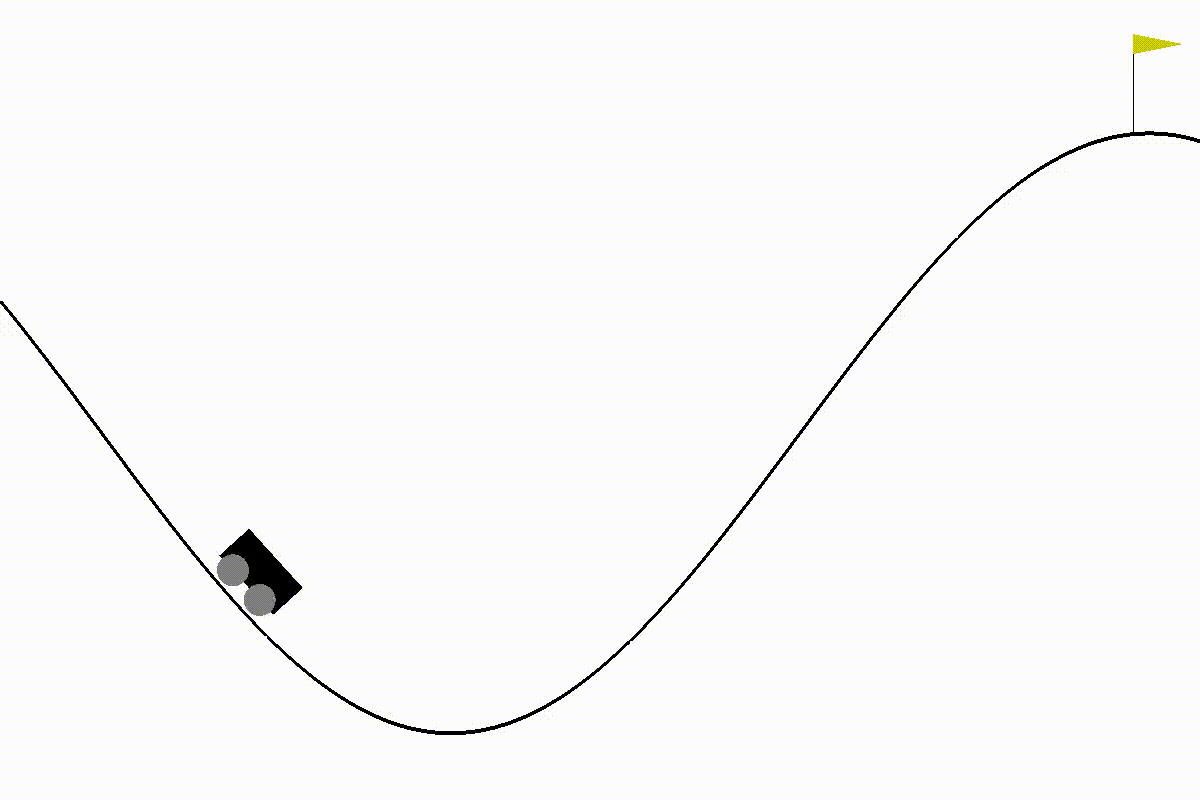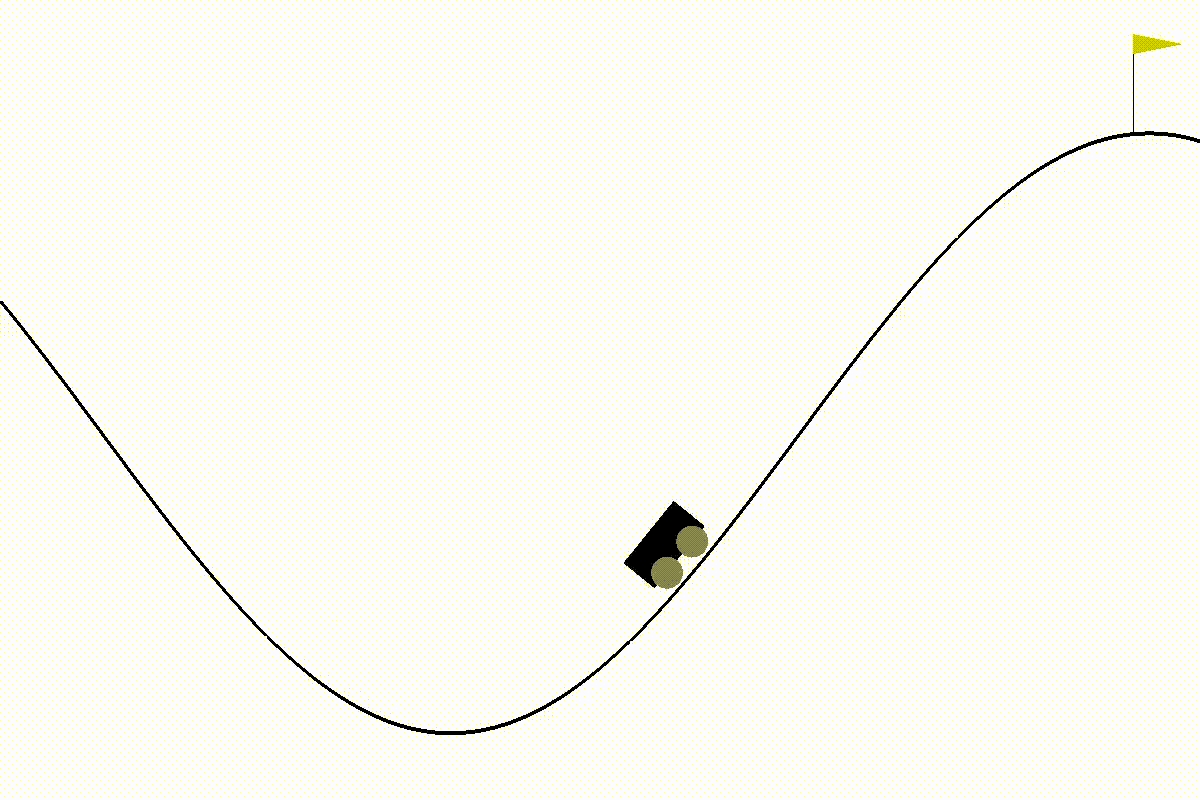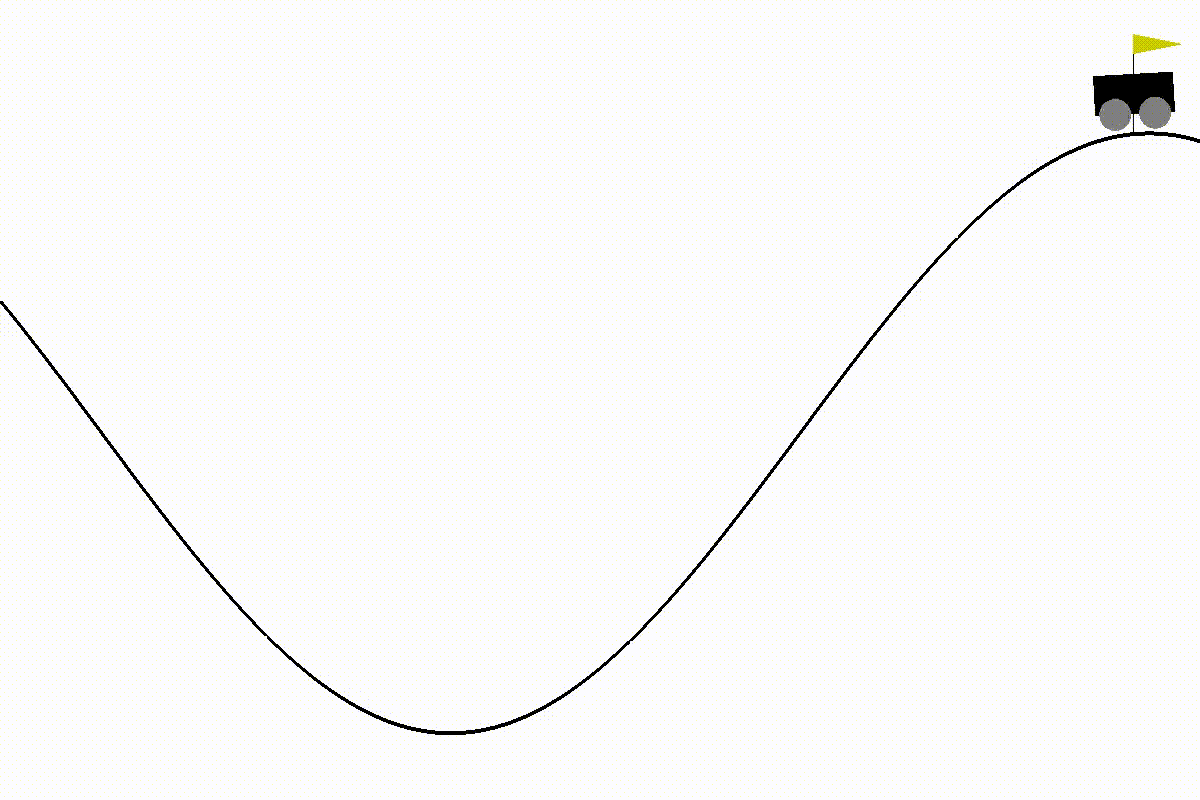
観測データ(状態)から行動を決定し、車を山の頂上の旗まで動かすことをゴールとして、学習を行う。
これは未学習状態で、プレイしたところ。
200ステップを超えてしまうか、旗までたどり着いたら終了(1エピソード終了)。
Q-Learningアルゴリズム
各状態における、各行動の行動価値を定めた関数を行動価値関数といい、であらわし、以下のアルゴリズムでを更新する。
- を適当に定めて初期化
- 以下を繰り返す
2-1. を初期化()
2-2. 以下を繰り返す
2-2-1. からε-グリーディ法で行動を選択する。
2-2-2. 行動を行い、報酬と次状態を観測する。
2-2-3. を更新する
※が終端状態の場合、は
2-2-4.
2-2-5. が終端状態なら、繰り返し終了。
詳細はこちら参照。
Qiita: DQN(Deep Q Network)を理解したので、Gopherくんの図を使って説明
実装
状態の取得
観測データから取得される、車の位置と速度は連続値であるため、離散値に変換する必要がある。
40個(適当)の離散値に振り分けることとする。
def get_status(_observation):
env_low = env.observation_space.low # 位置と速度の最小値
env_high = env.observation_space.high # 位置と速度の最大値
env_dx = (env_high - env_low) / 40 # 40等分
# 0〜39の離散値に変換する
position = int((_observation[0] - env_low[0])/env_dx[0])
velocity = int((_observation[1] - env_low[1])/env_dx[1])
return position, velocity
Qテーブルの定義
車の位置(0, 1,..., 39) × 車の速度(0, 1,..., 39) × 行動(0, 1, 2)の多次元配列を作成し、行動価値の値を格納する。
shapeは(40,40,3)
初期値は全部の要素をとする
q_table = np.zeros((40, 40, 3))
Qテーブルの更新
以下のようにQテーブルを更新する。
def update_q_table(_q_table, _action, _observation, _next_observation, _reward, _episode):
alpha = 0.2 # 学習率
gamma = 0.99 # 時間割引き率
# 行動後の状態で得られる最大行動価値 Q(s',a')
next_position, next_velocity = get_status(_next_observation)
next_max_q_value = max(_q_table[next_position][next_velocity])
# 行動前の状態の行動価値 Q(s,a)
position, velocity = get_status(_observation)
q_value = _q_table[position][velocity][_action]
# 行動価値関数の更新
_q_table[position][velocity][_action] = q_value + alpha * (_reward + gamma * next_max_q_value - q_value)
return _q_table
ε-グリーディ法の実装
基本的にはQテーブルを参照して、行動価値が最大になる行動を選択するが、一定の確率でランダムに行動するようにする。
def get_action(_env, _q_table, _observation, _episode):
epsilon = 0.002
if np.random.uniform(0, 1) > epsilon:
position, velocity = get_status(observation)
_action = np.argmax(_q_table[position][velocity])
else:
_action = np.random.choice([0, 1, 2])
return _action
メイン処理
if __name__ == '__main__':
env = gym.make('MountainCar-v0')
# Qテーブルの初期化
q_table = np.zeros((40, 40, 3))
observation = env.reset()
rewards = []
# 10000エピソードで学習する
for episode in range(10000):
total_reward = 0
observation = env.reset()
for _ in range(200):
# ε-グリーディ法で行動を選択
action = get_action(env, q_table, observation, episode)
# 車を動かし、観測結果・報酬・ゲーム終了FLG・詳細情報を取得
next_observation, reward, done, _ = env.step(action)
# Qテーブルの更新
q_table = update_q_table(q_table, action, observation, next_observation, reward, episode)
total_reward += reward
observation = next_observation
if done:
# doneがTrueになったら1エピソード終了
if episode%100 == 0:
print('episode: {}, total_reward: {}'.format(episode, total_reward))
rewards.append(total_reward)
break
結果
10000回学習後の車の動き。
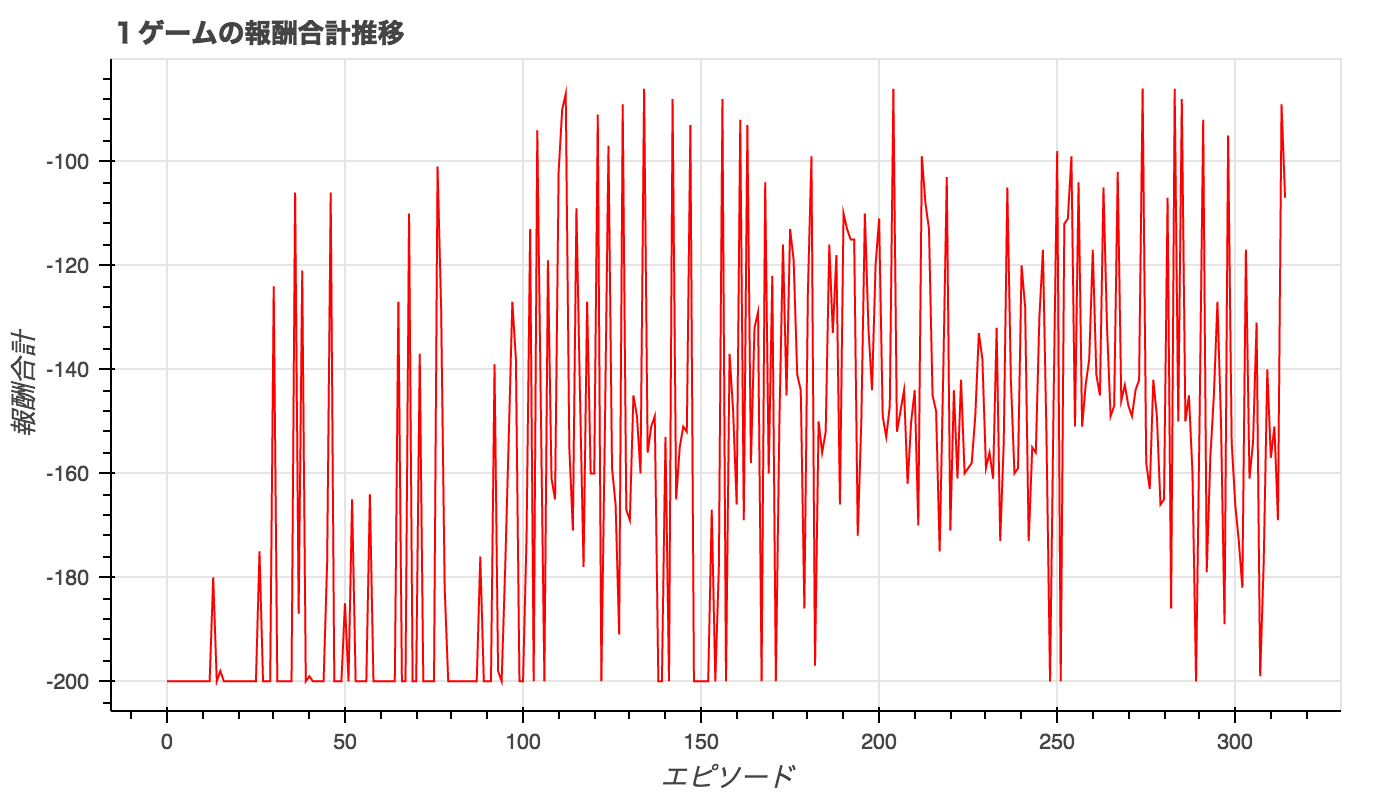
エピソードごとのトータル報酬の推移。
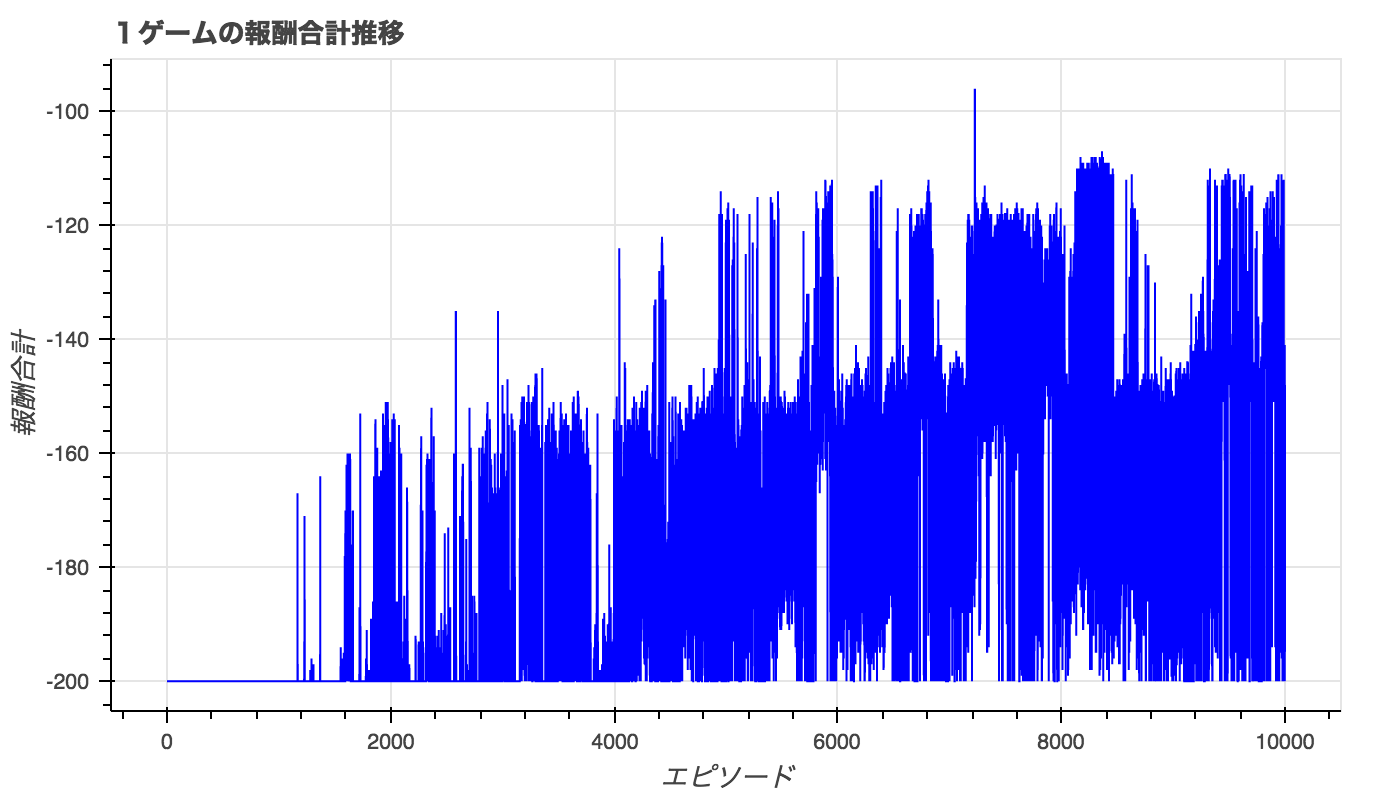
トータル報酬が-200より大きいと、山登りをクリアしていることになる。
1500エピソード以降は頻繁にクリアするようになっているが、必ずクリアできている訳ではない。
DQNで山登りをクリアする
DQNでは行動価値関数をネットワーク化させて、学習します。
を教師データと考えてを更新することとします。
詳細はこちらQiita: DQN(Deep Q Network)を理解したので、Gopherくんの図を使って説明
DQNの実装
Keras-RLというKerasで書ける、強化学習+ディープラーニングのライブラリがあるので、これを使いました。keras-rl GitHub
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten
from keras.optimizers import Adam
import gym
from rl.agents.dqn import DQNAgent
from rl.policy import EpsGreedyQPolicy
from rl.memory import SequentialMemory
env = gym.make('MountainCar-v0')
nb_actions = env.action_space.n
model = Sequential()
model.add(Flatten(input_shape=(1,) + env.observation_space.shape))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(nb_actions))
model.add(Activation('linear'))
memory = SequentialMemory(limit=50000, window_length=1)
policy = EpsGreedyQPolicy(eps=0.001)
dqn = DQNAgent(model=model, nb_actions=nb_actions,gamma=0.99, memory=memory, nb_steps_warmup=10,
target_model_update=1e-2, policy=policy)
dqn.compile(Adam(lr=1e-3), metrics=['mae'])
history = dqn.fit(env, nb_steps=50000, visualize=False, verbose=2)
dqn.test(env, nb_episodes=1, visualize=True)
DQNの結果
Q-learningよりずっと少ないエピソードで攻略できてますね。
なぜか、ちょっと悔しいです。
おわり
強化学習のシミュレーションが、ものすごく簡単にできて興奮しました。
理論だけで終わらせず、実装まですることで、より理論の理解が深まるなぁと思ったので、OpenAI Gymを使ってどんどん試していきたいです。
参考
Qiita : ゲームでAIをトレーニングするジム「OpenAI Gym」の環境構築手順 on Mac OS X
GitHub : sezan92/ReinforcementOpenA
*gymのGitHubには公式サイトがOld linksと記載されているので、今後はGitHub上で情報が更新されるのかもしれません。




コメント