
はじめに
勾配ブーストを用いた決定木(GBDT)によるクラス分類や回帰はデータ分析コンペでも非常によく使われています。
その中でも2016年に出されたXGBoostはLightGBMと並びよく使われている手法です。
性能が良いことで有名なXGBoost, LightGBMですが、モデル内部でどのような処理が行われているかよくわかっていなかったので論文を読んでみました。
式変形の省略が多く、またイメージしづらい箇所もあり、読みづらかったのですが
一度イメージできれば割とあっさり理解できます。
その体験を踏まえて、イメージ図を多く取り入れながらXGBoostの論文を(途中まで)丁寧に解説します。
XGBoost: A Scalable Tree Boosting System

この記事で述べること
- データの入出力
- XGBoostの木構造
- 損失関数とboosting
- 木構造の学習(split手法)
この記事で述べてないこと
- 実装のフロー
- パラメータチューニングのTips
- メモリ削減のための近似手法
- 大規模データのためのスケール手法(ここが肝)
文量が多くなったので、第1回とします。
(結構疲れました、もしいいねがたくさんもらえたら次回以降も書こうかと。。。)
(追記)
第2回書きました。
XGBoost論文を丁寧に解説する(2): ShrinkageとSubsampling
参考記事
XGBoost: A Scalable Tree Boosting System:原著
XGBoost 公式ドキュメント: 論文よりも平易に解説されています。
XGBoostのお気持ちを一部理解する: みんな大好き@kenmatsu4 さんの記事。この記事を理解されていたら本記事は不要です。
XGBoost論文の解説
XGBoostの構造
データの入出力
入力データ:
縦(下)方向にサンプル、横(右)方向にデータの属性(特徴量)が並ぶテーブル型のデータ構造を考えます。
サンプル数はn、データの次元数はmとします。また、特定のサンプルを表すインデックスをiとします。
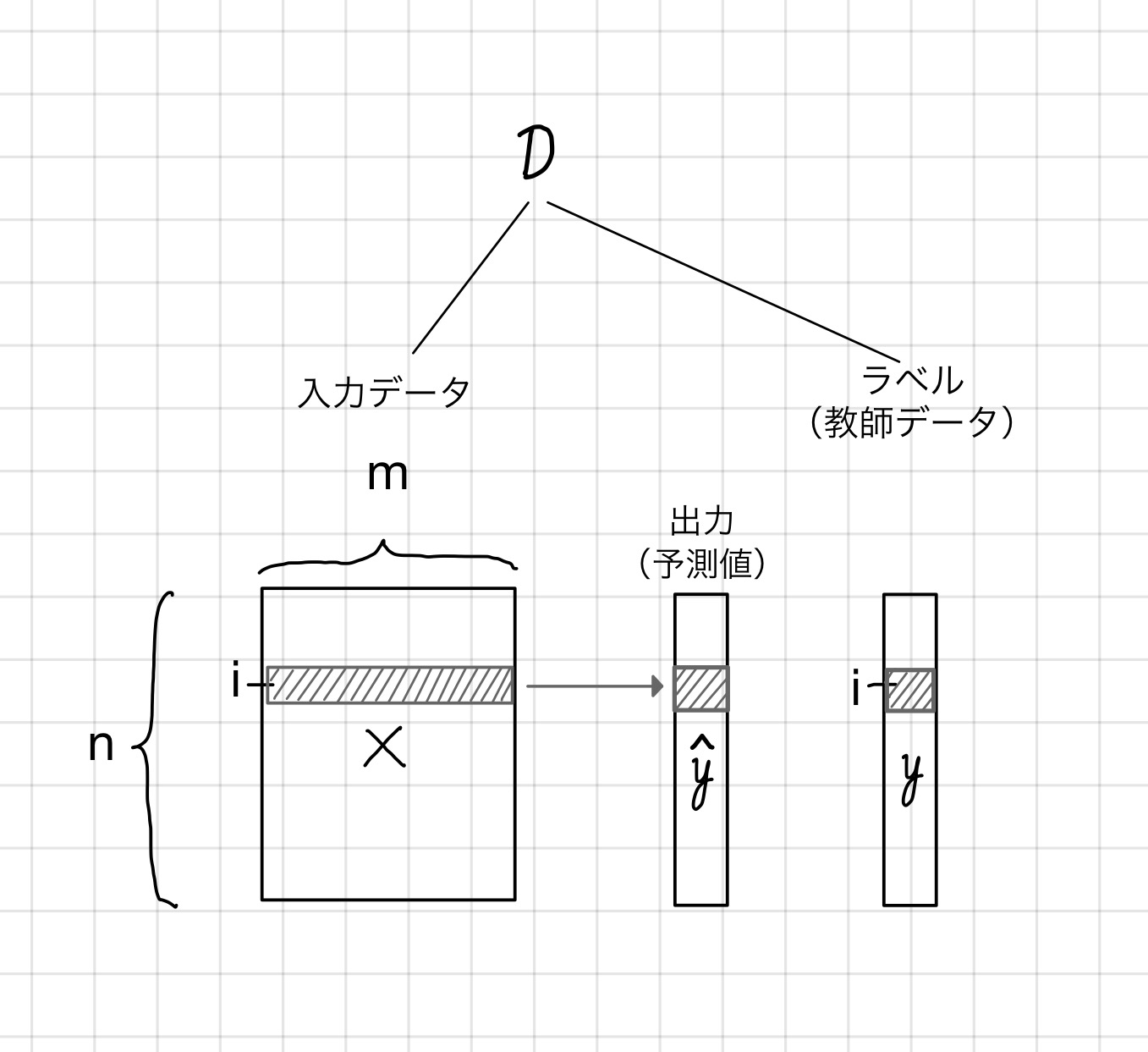
このとき、
i番目のサンプル、XGBoostによる出力値(予測値)、ラベル(教師データ)をそれぞれ
と表記します。
XGBoostの木構造
決定木の構造
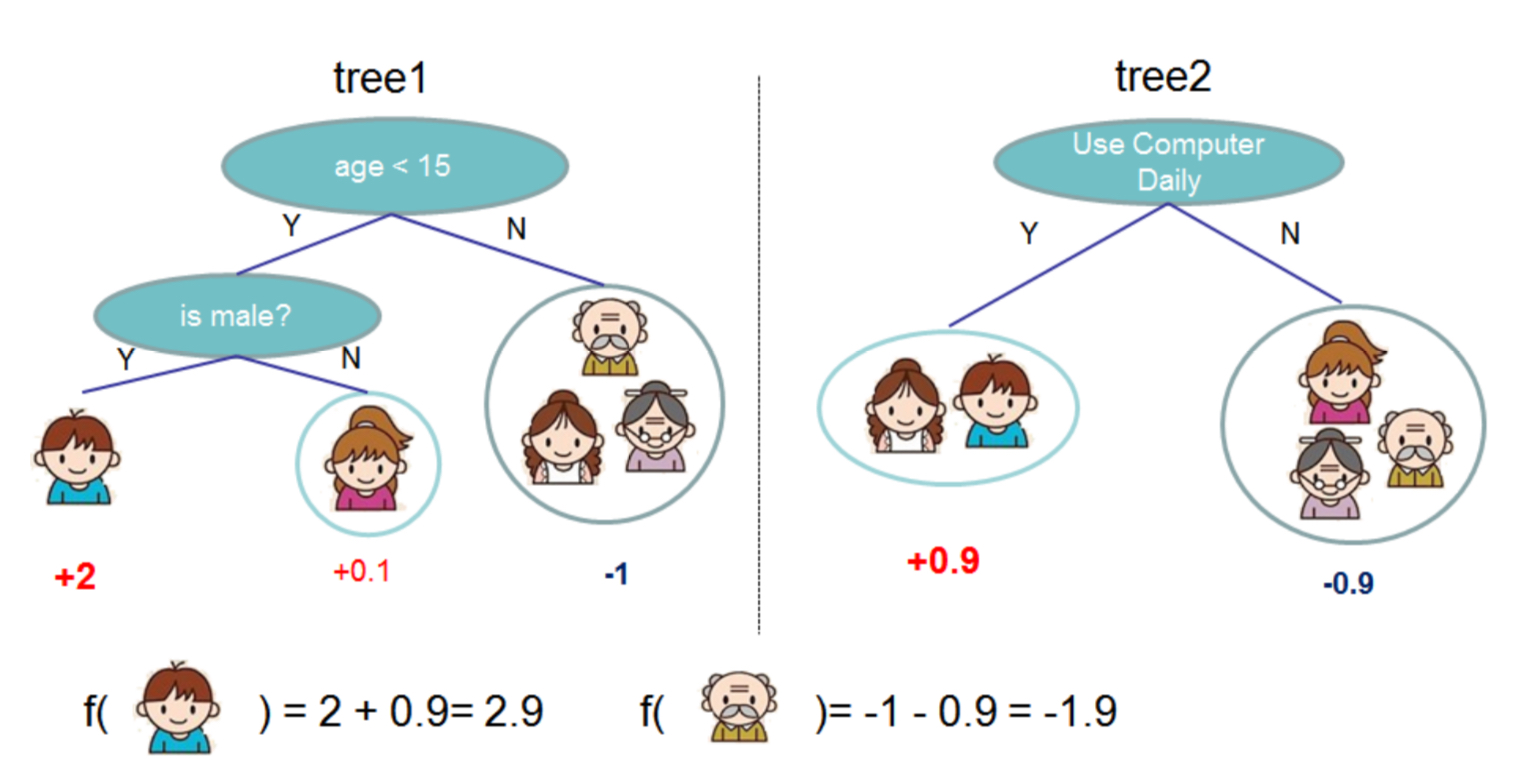
論文のFig.1(抜粋)を使って説明します。
5人の家族がコンピュータゲームを好きかどうかを予測する場合を考えます。(それぞれのコンピュータゲーム好き度を定量化すると言い換えましょう)
家族に与えられた情報(年齢、性別、PCの使用頻度など)を用いて振り分けのルールを作りサンプルを振り分けていくのが木ベースの考え方です。例えば上図のtree1では、
- 年齢が15歳未満か?
- 性別が男か?
といったルールでサンプルを振り分けていきます。ルールにしたがって最終的にたどり着いた木の末端を葉ノード(leaf node)と呼びます。振り分けられた葉ノードに基づいてサンプルを分類するのが決定木によるクラス分類の基本的な考え方です。
木の並列化(アンサンブル)
単一の木を使う場合、データに含まれるノイズに影響を受ける場合があります。そこで、決定木を複数用意して並列化し(アンサンブル)、出力結果をロバストにすることを考えます。
人間でも、一人の人間の決断に従うとときに過激な行動に出ることがありますね。それを避けるために多数決を取るイメージです。
並列化を取り入れた決定木として有名なのはランダムフォレスト(Random Forest)でしょう。サンプルをランダムに繰り返し抽出して、ノイズに強い決定木(群)を作り出します。
上の図では、tree1のほかにtree2を用意しています。出力結果を平均化することにより、最終的な予測を得ます。それぞれの重みを等しくすれば単なる多数決になりますが、一票に重みを付けることを考えます。
XGBoostの構造
さて、ここからXGBoostの構造とデータの入出力について定式化していきます。
XGBoostも並列化された複数の決定木を用います。それぞれの結果をアンサンブルすることで予測値を出力します。下図を基に説明します。
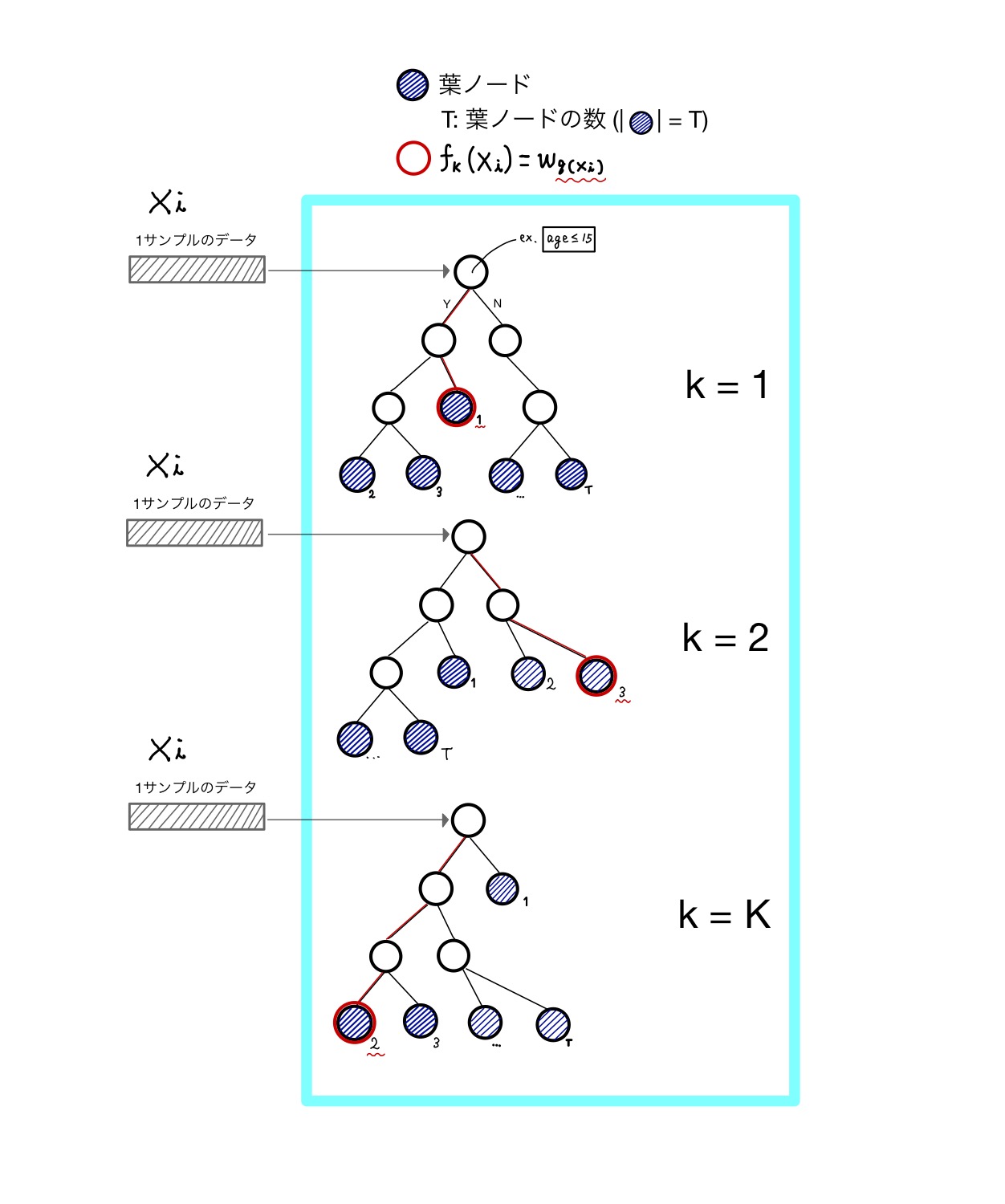
並列化された木の数をKとします。入力データ中の1サンプルデータ()はそれぞれの木の振り分けルールに従い、最終的な葉ノードに落ち着きます。
それぞれの木にあるT個の葉ノードをまとめてみましょう。
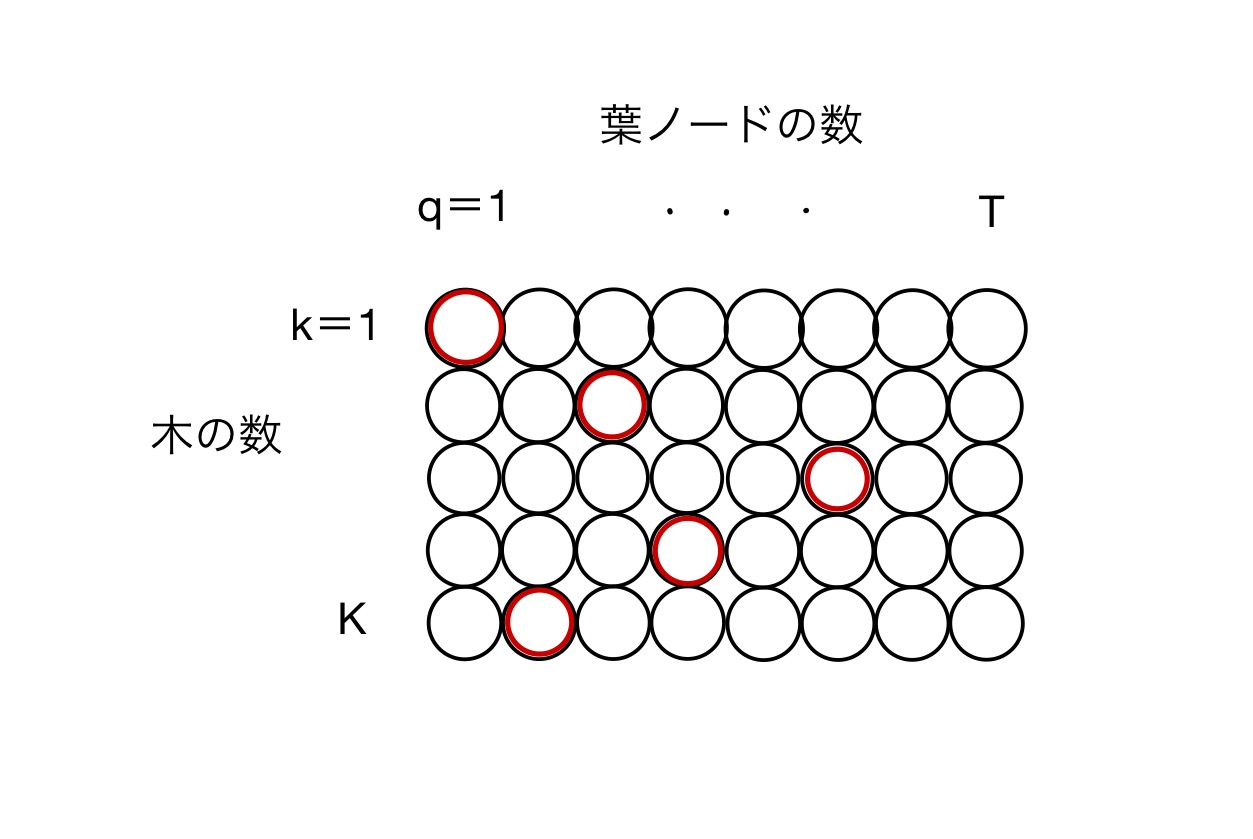
行番号kが木の数、列番号qがそれぞれの木の葉ノードの数を表しています。
このノードに格納されている値がXGBoostの重み、そして学習する値になります。
注
この図では全ての木について同じ葉ノードの数Tを持っていますが、実際にはそれぞれの木が同じノード数を持つとは限りません。ここでのTは葉ノードの最大数とお考えください。
ここまでに様々な記号が出てきましたが、それぞれがどのような入出力関係になっているか整理してみましょう。
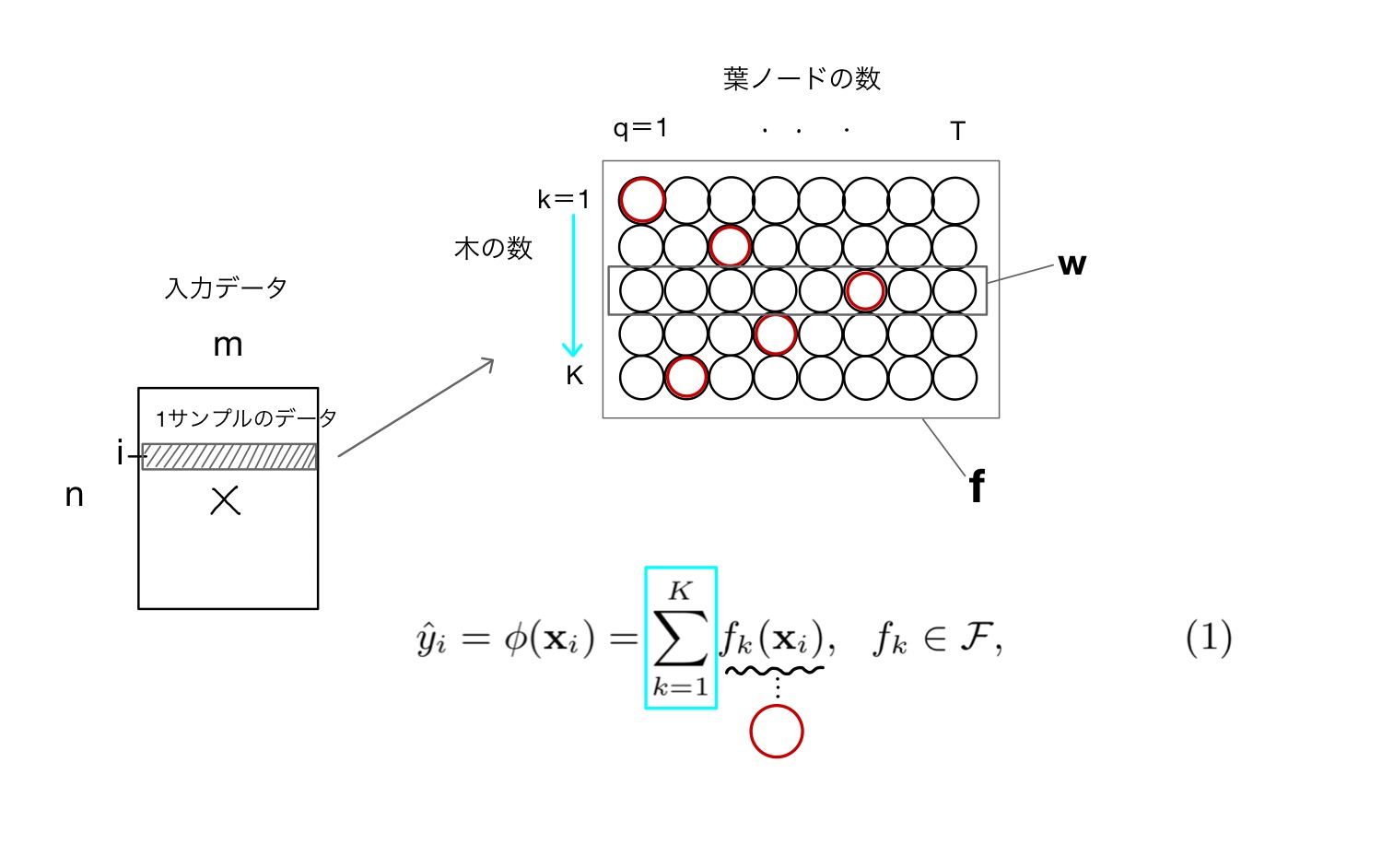
- 1サンプルの入力データを XGBoostのモデルに与える
- それぞれの木(k)に対して対応する葉ノードの番号qが決まる
- kおよびqから対応する重みが決まる
3の重みを各kに対する1次元ベクトルとして表記しているのが論文中のw、kを含めた2次元ベクトルとして表しているのがfになります。いずれにせよ
のデータフローをイメージしておいてください。
これでそれぞれの木に対する重みが決定します。最終的な出力()はそれぞれの木の対応する重みを総和したものになります(式(1))
補足:正確には重み×learning rateになります。learning rateに関するテクニックは、その2で解説する予定です。
正則化項付きの損失関数
損失関数を式(2)に示します。
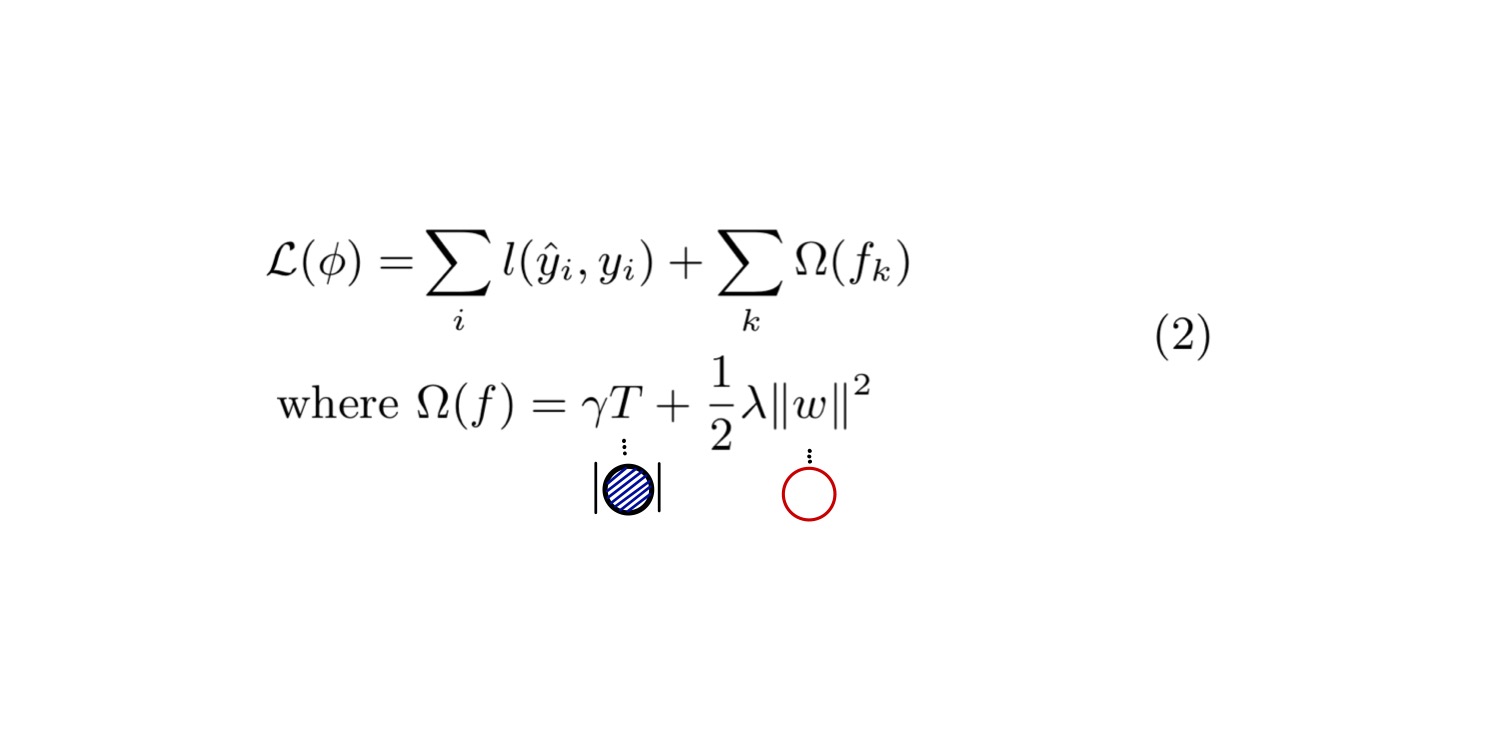
損失関数()には、残差二乗平均のような微分可能な凸関数を用います。
各サンプルに対して予測値と教師データとの間の残差をで表現し、全てのサンプルに対して総和します。
さらに、第2項目にXGBoostに特有の正則化項があり、それぞれの木に対するの寄与を総和します。
正則化項はさらにとに分解できます。
(葉ノードの数)が大きくなるほど損失関数が大きくなるため、木の構造を複雑化するのを抑える効果があります。
は重みのL2ノルムであり、これも過学習を抑える効果があります。
およびはそれぞれの正則化項のバランスを調整するパラメータです。
Gradient Tree Boosting
ここからはXGBoostの学習について見ていきます。
XGBoostのモデルを決定するには
- 木の構造を決定する
- 各葉ノードの出力(もしくは)を決定する
必要があります。2から見ていきましょう。
損失関数(式(2))を最小化するような重みもしくはを求めたいのですが、これらの変数はサンプルに依存する値(つまり関数)であるので、通常の最適化手法(例えば確率的勾配降下法)を使うことができません。
そこで、勾配ブースティングでは論文中で”Additive manner”と呼ばれる方法で学習を行い、を更新して損失関数を下げていきます。下図で説明します。
勾配ブースティングにおける漸化式
注
(2018.08.09)
勾配ブースティングではK=1(単一の木構造)から始まり、ラウンド毎に木の数を増やしていくとのコメントをいただきました(2019.08.09)。この図では初めからK個の木構造があることになっています。確認して図と文を修正予定です。
(2018.08.10)
図と文を修正しました(以下)
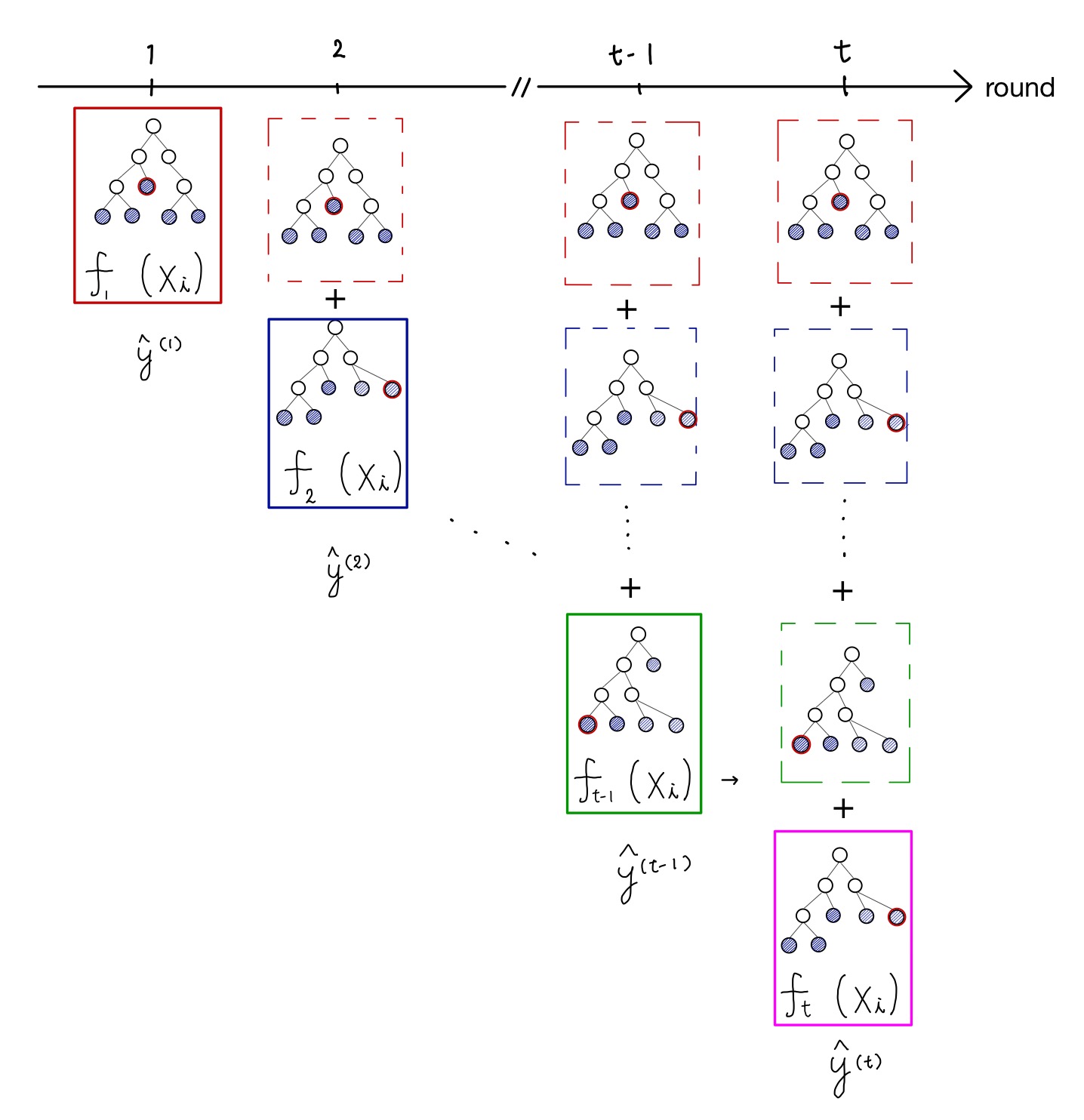
初期状態()では、単一の決定木のみが存在します(赤枠)。
1ステップ進めt=2の時に、新しい木を追加することを考えます。
最終的な出力は一つ前の出力に新しく追加された木を加えます。
つまり、以下の式が成り立ちます。
この時、新しい木は真の値とのギャップを埋めるものを採用します。
以下のイメージ図を見たほうが早いでしょう。
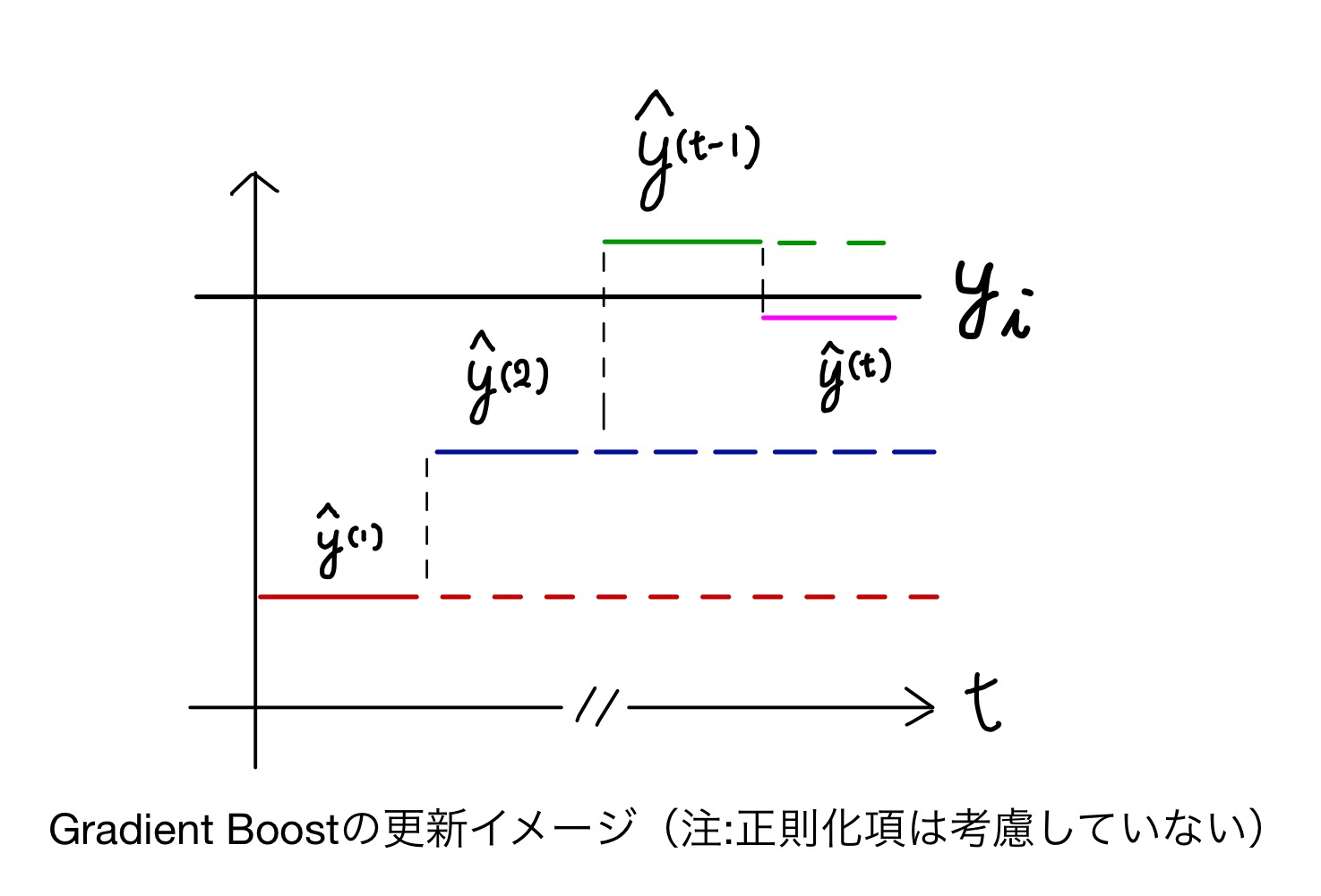
このようにして、反復を繰り返しながらモデルの出力値を真の値に近づけていきます。
損失関数(勾配ブースティング版)
XGBoostの出力値を真の値に近づけるためにをに関する漸化式の形で表しました。
この漸化式を用いて損失関数を書き直すと
となります。
注
前出の損失関数に対して、漸化式版の損失関数ではに対する総和の記述がなくなっています。
論文中これに対する言及は特にないので推測に過ぎませんが、漸化式版の損失関数ではそれぞれの木に対する損失関数を見ていると考えられます(間違っていたら教えてください)
とにかく、今後の議論では決定木の数に対する総和は考えずに議論が進みます。
(2019.08.09) コメントいただきました。ありがとうございます。
(中略)Boostingでは各ラウンドtごとに木をどんどん増やしていきます. そのため, 現在のラウンドtに付随する変数のみが学習すべき対象となります.
したがってで学習すべき変数, 最適化したい変数は, (tラウンド目での木の情報)であって,
tラウンドにおいてはw_1...w_(t-1)は定数扱いとなります. なので正則化項の∑kのうちtのみ考えれば良い, という流れだと思います.
勾配ブースティングの最適解
テイラー展開
こうして得られた損失関数(*)を見ると、関数 の中に最適化したい変数(関数)が入っています。
このをの外にくくり出すことを考えます。
関数のの周りのテイラー展開を2次の項まで近似すると
になります。を、を、をと置き換えると、
を得ます。ただし
です。
ここで、は に依存しない関数なのでの中で定数項としてみなせます。
この定数項を無視した損失関数を再定義することで
を最終的に得ます。
総和の変換トリック
さて、数式が出てきました。頭がゴチャゴチャしてきましたね。ラップアップしましょう。
- XGBoostの出力および損失関数をステップ数に関する漸化式で書き直す
- テイラー展開により最適化したい変数を損失関数(の中の関数)からくくり出す
- 定数項を無視したシンプルな損失関数を新たに得る
こんなに式をこねくり回す目的は何だったかというと、最適化したい変数のためです。
端的に言えば変数の最適解を得ることです。
それを念頭においてもう少し進みましょう。
式(3)の正則化項を定義通りに書き換えます。
右辺第1項には、第3項にはの記号がありますね。
この記号の意味を図で示します。
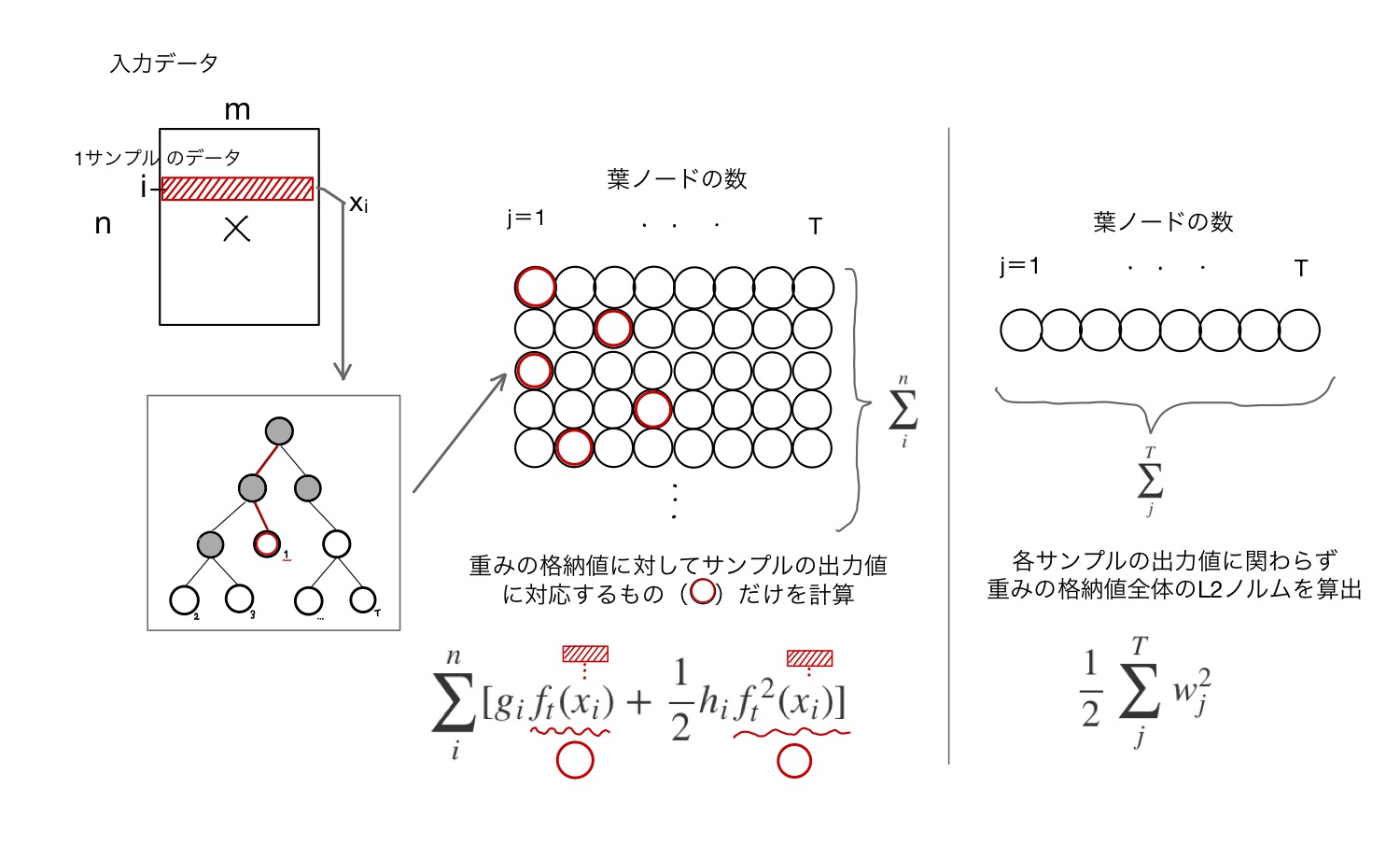
まずは第1項目
1サンプルのデータを単一の決定木に入力したとき、T個ある葉ノードのうちの一つの出力値が対応します(図の赤丸)。
その出力値に対してやを掛けたり、2乗したりした後に全サンプルの総和を取ったものになります。
つぎに第3項目
この項は正則化項の一部です。サンプルの出力値とは関係なく、対応する木のT個の葉ノードの出力値(重み)の総和の総和を取ります。
注
左の図で表した丸()と、右の図で示した丸()は記号が違うが同じものです。もし忘れていたら上の方の説明を読み返してください。あとで使います。
第1,3項目で総和の方向(変数)が違いますね。これを意識してください。
ここで一つトリックを使います。総和の方向を揃えます。
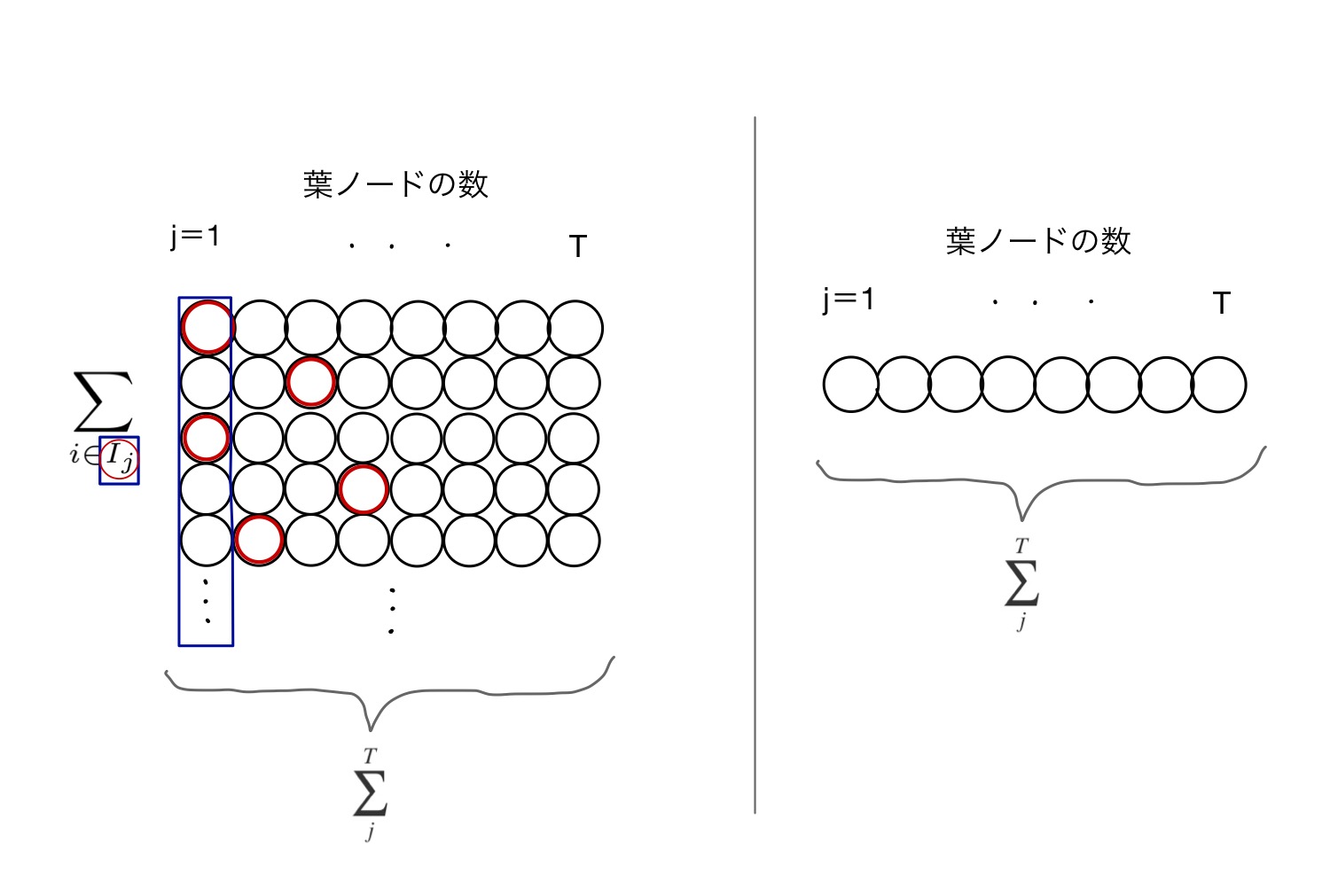
右辺第1項(上図の左)に関して、サンプル方向(下方向)に足していった総和をやめて、第3項(上図右)のように横方向(ノード方向)の総和に変えます。
図で囲まれた青枠の値を横方向に総和していくイメージです。
ただし、青い長方形の中の実際に出力されたノード(赤丸)のみを足す必要があります。
これを表現するために、j列目の全サンプル集合から実際に出力されたサンプルの部分集合(つまり青長方形中の赤丸全体)をと表します。
そしてこの赤丸だけの総和をとることをと表します。
この形式で損失関数を書き直してみましょう。
出力値をで書き換え、式を変形します。
の方向を揃えたことで、最適化したい変数について括ることができます。
最適解の導出
式(4)を使って、固定された決定木(つまりに対して対応する葉ノードが変化しない)場合の、j番目の葉ノードの最適解を求めます。
損失関数(微分可能な凸関数)の最小値を求めるために、損失関数を微分してゼロとおきます。
よっての最適解
を得ます。ようやくたどり着きました。
ここまでを一言でまとめましょう。
固定された木構造におけるXGBoostの最適解の近似値は解析的に求まり、その値は式(5)である。
最適解における損失関数
最適解における損失関数の値を得るために式(4)にを代入します。
式(6)により、固定された構造における損失関数の最小値が求まりました。この値は一種の基準となります。
つまり、構造を変えた後のスコアが構造を変える前のスコアより良ければ(低ければ)変えた後の構造の方が良い構造である、と言えます。
決定木の構造を変えるアプローチが見えてきましたね。
木構造の学習
ノードの分割
前章までで、ノードに対する損失関数の最小値が求まりました。これにより、木の構造を変化させた前後の損失関数の値の差を見ることで構造変化を採用するかを決めることができます。
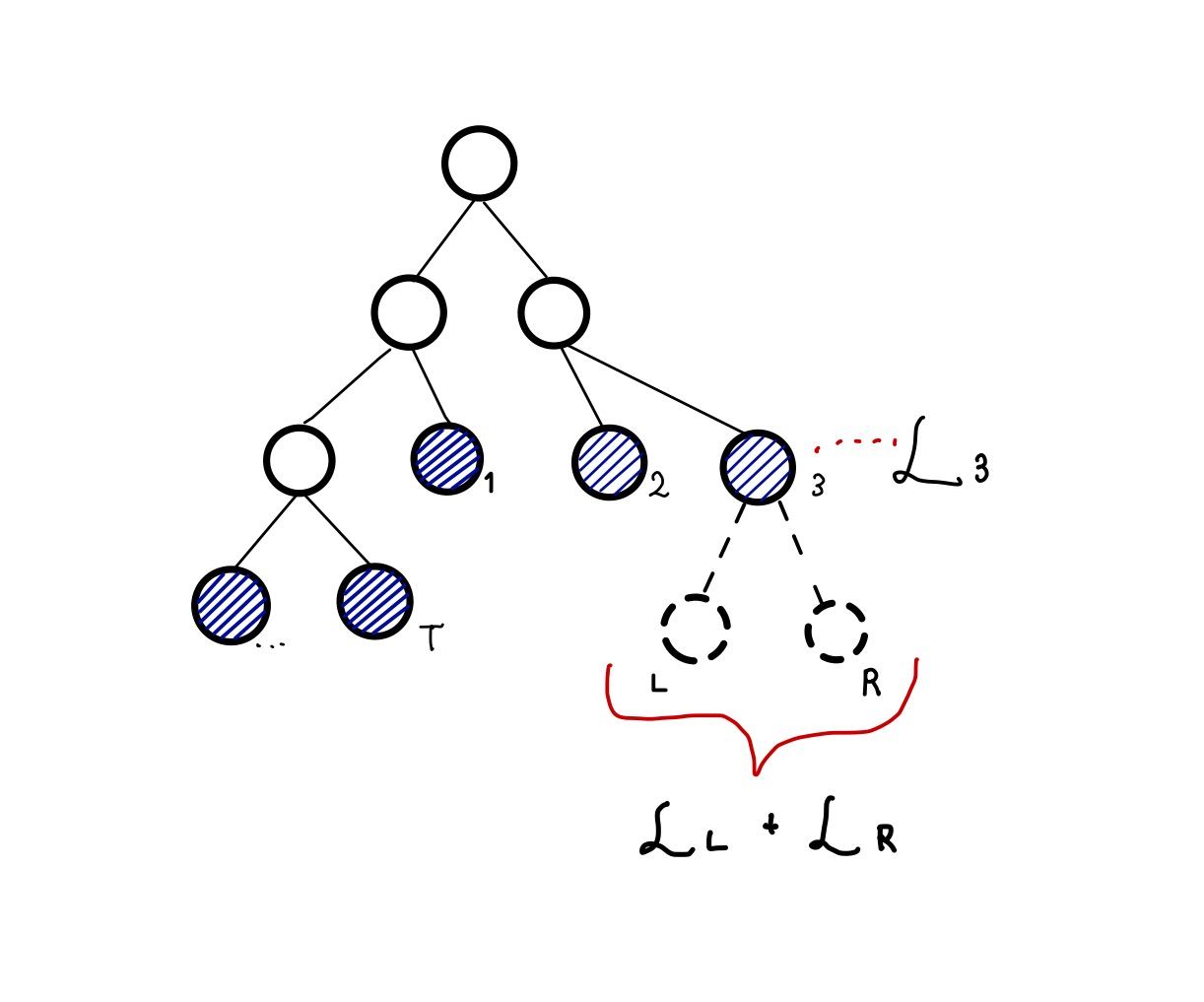
上図のような木構造があるとして、3番目の葉ノードをさらに分割するべきかどうかを考えます。
分割しなかった時の損失関数を、分割した後のノードをそれぞれ、, として、分割前後の損失関数の差をで定義します。符号に注意して
を得ます。
, , , の関係をエネルギー準位図で表すと以下のようになります。
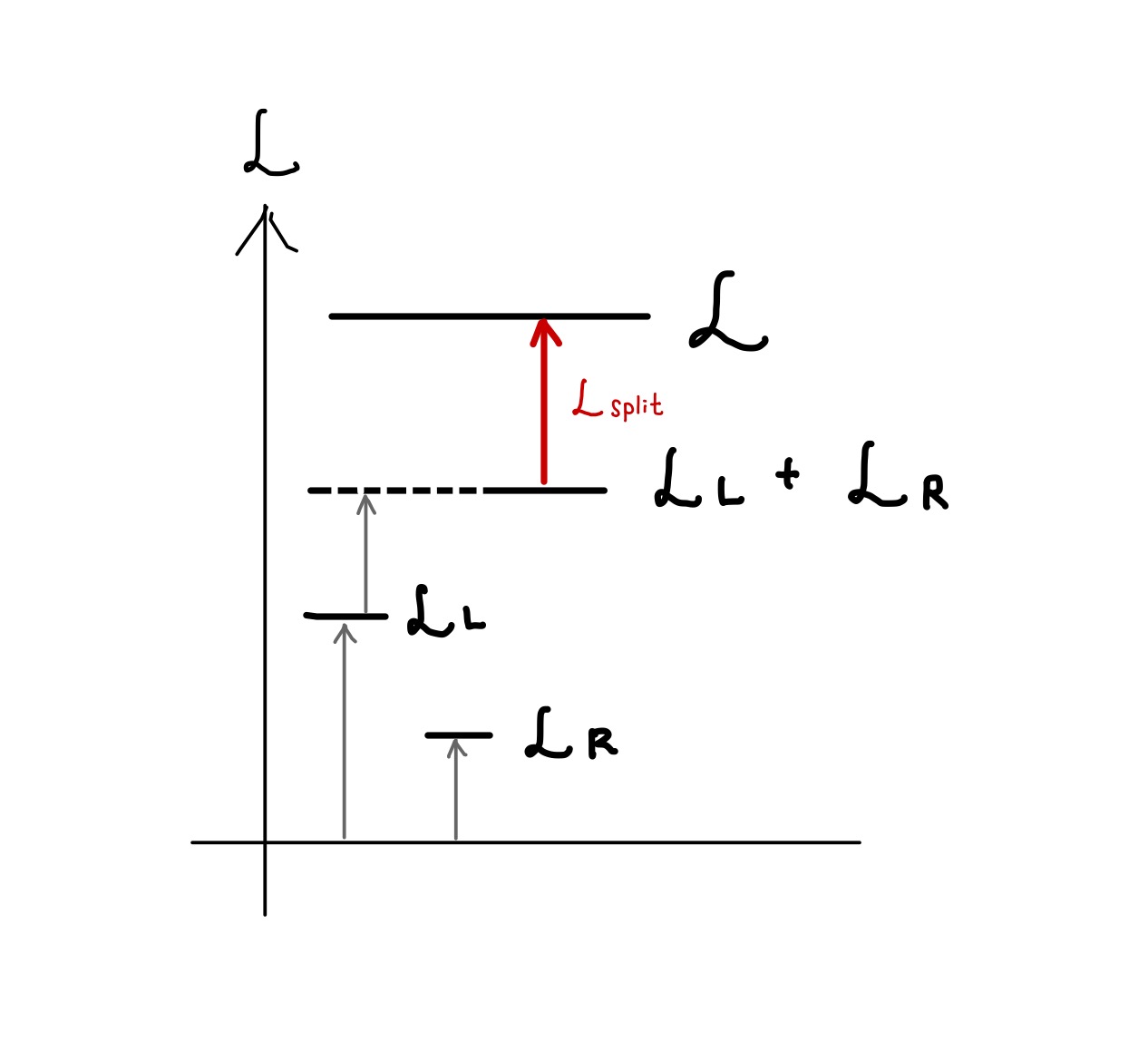
は分離後から分離前のエネルギー変化を表してますから、この値が正になる時が分割が有効な時です。
このようにして得られたの値を評価することで、木の構造を変化させることができます。
次回
ここまでで、XGBoostの基本的な考え方をまとめました。
長くなったので、一度ここで切ります。
次回は実装のフローの解説や、大規模データスケールさせるための工夫について解説する予定です。




コメント