
概要: Rustの Arc 型の実装は宝の宝庫です。そこで、これを隅から隅まで解説してみます。
第2回「Rcを読む基本編」では、 Arc のシングルスレッド版である Rc のソースコードを読み、 Rc の基本的なライフサイクルを掴みます。
- 第1回 Arc/Rcの基本
- 第2回 Rcを読む基本編
- 第3回 Rcを読む発展編
- 第4回 アトミック変数とメモリ順序
- 第5回 Arcを読む
はじめに
「Arc を読む」というタイトルですが、実際にいきなり Arc を読むと多くの関心事を同時に理解する必要があり大変です。 Arc のシングルスレッド版である Rc を先に読むことで、ある程度段階的に理解することを目指します。
まとめ
-
RcとWeakはどちらも同じヒープ領域に対するポインタで、ヒープ領域には「強参照カウンタ」「弱参照カウンタ」「実体」の3つが乗っている。 - 参照カウンタは共有書き換えの対象のため、内部可変性コンテナである
Cell<T>で囲まれている。 -
Rcの参照先にアクセスするために単項の*演算子がオーバーロードされている。この操作のコストはとても低い -
Rc自身の基本ライフサイクルは new(カウンタ1)→clone(カウンタ増)→drop(カウンタ減) である。 -
Weakの基本ライフサイクルは downgrade(弱カウンタ増)→upgrade(強カウンタ増) および clone(弱カウンタ増)/drop(弱カウンタ減) である。 -
Rcからの影響をわかりやすくするために、弱カウンタはデフォルトで1多くカウントされている。 - 「参照カウンタが1である」という条件のもとで動く
try_unwrap/get_mut関数と、それを活用したmake_mut関数がある。
ソースコード
以下の1.39.0の実装を読んでいきます。

Rcの基本構造
まずは基本構造である Rc, Weak, RcBox の定義 (簡略版) を見てみます。
pub struct Rc<T: ?Sized> {
ptr: NonNull<RcBox<T>>,
}
pub struct Weak<T: ?Sized> {
ptr: NonNull<RcBox<T>>,
}
struct RcBox<T: ?Sized> {
strong: Cell<usize>,
weak: Cell<usize>,
value: T,
}
公開されている型は Rc と Weak の2つですが、内部的な型として RcBox という構造体も導入されています。 強参照カウンタ, 弱参照カウンタ, 実体 の3つをヒープ上に並べて確保し、それを Rc と Weak で共有していることがわかります。
T: ?Sized
型引数 T には ?Sized がついています。これは自動的につけられる T: Sized という制約を明示的に剥がすためのものです。これにより、被参照型としてサイズ不定型 (dyn, str, [T] など) を使えるようになります。たとえば、
Arc<dyn Fn() -> i32>Arc<dyn Any>Arc<str>Arc<[T]>
など (Rc でも同様) が使えるのはこのためです。
サイズ不定型をサポートするための処理はあとでまとめて解説します。
Cell<usize>
参照カウンタには usize, つまりそのプラットフォームのポインタ型や size_t と同じ大きさの整数型を使うことがわかります。(32bitに統一するよう提案している人もいますが、当面実現することはないでしょう)
では、 Cell はなんでしょうか?これは、共有メモリ領域の書き換えをするのに必要なマーカーです。
Rustでは、最適化のために、共有されているメモリ領域の書き換えを原則禁止しています。通常不可能なようにAPIが設計されていますが、それだけではありません。 unsafe を使えば一見そのような処理を書くことができますが、それが期待通りに動く保証はないということです。最適化によって予想もしないような動きをする可能性もあるので、絶対にやってはいけません。
もし、共有されているメモリ領域の書き換えが必要な場合は、内部可変性 (interior mutability)コンテナを使ってこのルールをオプトアウトする必要があります。 Cell<T> はそのような内部可変性コンテナの一種で、シングルスレッドでシンプルな共有読み書きだけ必要な場合に便利です。
Rc/Weak の参照カウンタは複数の Rc/Weak 間で共有しながら書き換えを行うので、 Cell で囲う必要があるというわけです。
NonNull
NonNull は「nullではない」という保証のついた生ポインタ型です。「nullではない」という点を除けば単なるポインタサイズの整数で、malloc/freeを含め余計なことをしないのが特徴です。
Rc, Weak では以下のように NonNull が使われています。
pub struct Rc<T: ?Sized> {
ptr: NonNull<RcBox<T>>,
}
pub struct Weak<T: ?Sized> {
ptr: NonNull<RcBox<T>>,
}
ここで2つの疑問が生じます。(生じなかったかもしれませんが、生じたつもりになればOKです)
- 通常の生ポインタ、つまり
*const RcBox<T>ではだめなのか? - スマートポインタ、つまり
Box<RcBox<T>>ではだめなのか?
通常の生ポインタではだめな理由
つまり、以下のようにしてはだめなのか?という理由です。
pub struct Rc<T: ?Sized> {
ptr: *const RcBox<T>,
}
pub struct Weak<T: ?Sized> {
ptr: *const RcBox<T>,
}
答えは、 Option<Rc<T>> を最適化したいからです。Rustでは、0やnullでない保証のある特別な型 (Box<T>, NonNull<T>, NonZeroU32 など) を Option で包んだときに None をnullと同一視することでサイズを削減する最適化が実装されています。 Rc もヒープポインタなのでnullになることはありません。そのため、その性質を活かしてより効率的なコードを書けるほうがいいわけです。
Box ではだめな理由
つまり、以下のようにしてはだめなのか?という理由です。当該ポインタはヒープを指しているので、一見正しそうに見えます。
pub struct Rc<T: ?Sized> {
ptr: Box<RcBox<T>>,
}
pub struct Weak<T: ?Sized> {
ptr: Box<RcBox<T>>,
}
しかし、これには以下の問題があります。
-
Rc,Weakが解放されたからといって、その参照先であるヒープ領域やその中身が不要になったとは限らない。他に同じ領域を共有しているRc,Weakがいるかもしれないからである。ところが、上のように書いてしまうとBoxのデストラクタが必ず呼ばれてしまう。これをキャンセルするにはManuallyDrop<Box<RcBox<T>>>と書く必要があり、かえって手間になってしまう。 -
Boxには追加の仮定がある。具体的には「参照先を専有していること (noalias)」と「参照先が有効であること (dereferenceable)」が仮定されてしまう。前者はRc,Weakに関しては本質的に正しくないし、後者はWeakのみが参照しているヒープ領域に対しては正しくない。(参照先のdataはすでにdropした後なので)
ですから、 NonNull<T> という生ポインタで構造体には入れておいて、手動で確保・解放・参照の取得をするのが最適ということになります。
Deref 実装
Rc はスマートポインタなので、参照を辿るための仕組みが必須です。そのために Rc は Deref トレイトを実装しています。これは単項の * 演算子をオーバーロードするためのトレイトです。 (以下のソースコードは簡略版)
impl<T: ?Sized> Deref for Rc<T> {
type Target = T;
fn deref(&self) -> &T {
&self.inner().value
}
}
impl<T: ?Sized> Rc<T> {
fn inner(&self) -> &RcBox<T> {
unsafe {
self.ptr.as_ref()
}
}
}
&self は self: &Self の略記で、上の例では Self は Rc<T> です。またlifetime elision規則により、上のようなケースでは入出力のライフタイムは同じものとして推定されます。つまり、この deref は &'a Rc<T> から &'a T を作る関数です。
Deref が実装されているとき、 *x は必要に応じて *Deref::deref(&x) (今回の例でいうと *Rc::deref(&x) に脱糖されます。つまり、
let rc = Rc::new(42);
let x = *rc;
の2行目は
let x = *Rc::deref(&rc);
// ^^^ &Rc<i32>
// ^^^^^^^^^^^^^ &i32
// ^^^^^^^^^^^^^^ i32
という風に脱糖されます。
Deref のコスト
Deref のコード自体は単純です。 Rc に保管されているポインタを辿って返すだけです。ここで注目すべきなのはむしろ、「何をやっていないか」でしょう。特に、 Rc の Deref 実装は参照カウントの読み書きを一切していないという事実は注目に値します。シンプルにポインタを読み、オフセットを計算しているだけです。しかも、Rustの強いエイリアシング規則により、Derefの結果を再利用するような最適化が可能です。たとえば以下のようなコードをコンパイルしてみます。 (Rc でも同様です)
use std::sync::Arc;
pub fn f(p: &Arc<i32>) -> i32 {
let x = **p;
let y = **p;
x + y
}
これをCompiler Explorerでコンパイルすると以下のようになりました。 https://godbolt.org/z/49_w-B
example::f:
mov rax, qword ptr [rdi]
mov eax, dword ptr [rax + 16]
add eax, eax
ret
最初の mov は &Arc<i32> の値を読み取って NonNull<ArcInner<i32>> を取得しています。さらに次の mov でここから i32 を読み取っています。最後に読み取った値を2倍して返しています。Deref の操作は1箇所にまとめられていることがわかります。
こう考えると次に疑問に上がりそうなのは、「なぜ Rc<i32> ではなく &Rc<i32> を渡すのか」ということです。 Rc<i32> を直接渡したほうが mov の回数が1回減らせそうです。Deref のインターフェースがそうだから仕方ないというものありますが、それ以外に2つの理由があります。
第一の理由は「ムーブしたくないから」です。Rustではメモリコピーによって値を渡した場合それは「ムーブ」、つまり所有権の譲渡として扱うことになっています。そうすると、呼ばれた側は受け取った Rc を消費する (参照カウントを1減らす) か Rc を戻り値に含めて返却するしかありません。前者はコストの観点から却下です。後者はまあ mov のコストとどっちが勝つか次第(ただし、インターフェースとしてのわかりやすさをハンデとして考える)ですかね。そこでもうひとつの理由が出てきます。
第二の理由は「インライン化で間に合うから」です。たとえば先ほどの例でも、 Arc::deref の呼び出しは完全にインライン化されていました。 f そのもののアセンブリを出力させたため、 &Arc<i32> を辿る処理がアセンブリに含まれていますが、さらに f を含む関数をコンパイルした場合、 f もインライン化されて &Arc<i32> を辿る処理は消滅する公算が高いです。
ですから、Rustの「コピーしたら所有権の譲渡」「参照を渡したら一時的な利用権の貸与」というルールを、高速化のために破る必要は基本的にないと考えられます。
DerefMut
もう1つ、この場にないものとして重要なのが DerefMut 実装です。これは名前通り、 Deref の &mut 版です。もし DerefMut 実装があったとすると以下のような実装になると考えられます。
// !!! 実際にはこのような実装はない !!!
impl<T: ?Sized> DerefMut for Rc<T> {
// Target はDerefのものが使われるので、ここでは定義しない
fn deref_mut(&mut self) -> &mut T {
&mut self.ptr.as_mut().value
}
}
この実装がないという事実は、以下のコードがコンパイルできないことと関係しています:
use std::rc::Rc;
fn main() {
let mut rc = Rc::new(42);
*rc = 42; //~ERROR cannot assign to data in an `Rc`
}
これをコンパイルしようとすると以下のようなエラーが出ます。
error[E0594]: cannot assign to data in an `Rc`
--> src/main.rs:5:5
|
5 | *rc = 42; //~ERROR cannot assign to data in an `Rc`
| ^^^^^^^^ cannot assign
|
= help: trait `DerefMut` is required to modify through a dereference, but it is not implemented for `std::rc::Rc<i32>`
ヘルプ: 参照先を書き換えるには
DerefMutトレイトが必要ですが、std::rc::Rc<i32>には実装されていません
そして、前回も説明したように、 Rc/Arc の先を書き換えられないのは意図的です。Rc/Arc の参照先は他の所有者と共有されているため、明示的に RefCell や Mutex などの排他制御の仕組み(内部可変性)を挟まない限りは書き換えてはいけないことになっています。これを守らないと即時の未定義動作となり、プログラマーには予想もつかないような不思議な最適化によって全く予期しない結果になる可能性がありますから、当然 DerefMut を実装することはないわけです。
Deref を実装することの正当性
では、 Deref のほうは、実装して問題ないのでしょうか。具体的には、参照カウントを全く読み書きしていないのに、実体への参照 &T を与えてしまって大丈夫なのはなぜでしょうか。
ここでRustのライフタイムが出てきます。lifetime elision規則により、Derefの実装には実際には以下のようなライフタイムがついているとみなされています。
impl<T: ?Sized> Deref for Rc<T> {
type Target = T;
fn deref<'a>(&'a self) -> &'a T {
&self.inner().value
}
}
この 'a というのは未来のある時刻を指す想像上の変数 (あるいは、その時刻に false になるフラグのようなもの) だと考えるとよいでしょう。 &'a ... というのは、その時刻までは有効な共有参照という意味です。
この deref は &'a Rc<T> から &'a T を返す関数です。この &'a Rc<T> は当然どこかにある Rc<T> を指しているのですが、「時刻 'a まではその Rc<T> は同じ場所にあり、解放あるいは変更されていない」ということは仮定していいことになります。つまり、その時刻 'a までは参照カウントは絶対に1以上 (当該 Rc<T> が人頭に含まれるので) です。であれば、その間実体 T への参照は生き続けると考えて問題ありません。結局、参照カウントが正であることを保証するのは Rc<T> を所有している側の責務 (責務といってもコンパイラが調べてくれます) で、deref側はそれを信用してただ参照を返すだけで済んでいるわけです。
実際、 deref した値を、もとの Rc<T> よりも長く使おうとするとちゃんとエラーになります。
use std::rc::Rc;
fn main() {
let rc = Rc::new(42);
let r: &i32 = &*rc;
drop(rc);
eprintln!("r = {}", r);
//~^ERROR cannot move out of `rc` because it is borrowed`
}
このように、参照カウンタである Rc/Arc を使う場合でも、ライフタイムは非常に役に立っています。ほとんどの場面では deref を(暗黙に)使い、本当に必要な場面でだけ clone で参照カウントを操作するという使い方ができるため、他の言語での参照カウンタに比べても低いコストで使えると考えられます。
Weak の Deref 実装
さて、 Rc は強参照カウントを握っているため、 &Rc<T> が生きている間は &T も生きていると考えてよいというのが前小節の結論でした。一方 Weak は強参照を握っていないので、 &Weak<T> があっても &T が生きているとは言えません。そもそも Weak<T> の参照先はもともと生きていない可能性があるので、何らかのチェックが必要です。
そのため、 Weak は Deref 実装を持たず、まず Rc への昇格 (Weak::upgrade) を試みてから中身を取得する必要がある、という風に設計されています。これも「ない」ことが重要なもののひとつといえます。
強参照のライフサイクル
前節では Deref の実装を見ましたが、まだ参照カウンタには触れていません。ここから参照カウンタを中心にした Rc/Weak のライフサイクルを見ていきます。
弱参照のことはあとで考えることにして、まずは強参照だけがある状況で Rc の基本的なライフサイクルを読んでいきます。基本的なライフサイクルとは以下の3つです。
- new ... まだ共有されていない状態の
Rcを作成する。 - clone ... 参照カウントを増やす。
- drop ... 参照カウントを減らし、必要なら掃除をする。
new
Rc::new の実装を簡略化すると以下のようになります。
impl<T> Rc<T> {
pub fn new(value: T) -> Rc<T> {
Self {
ptr: Box::into_raw_non_null(box RcBox {
strong: Cell::new(1),
value,
}),
}
}
}
強参照カウンタを1にしてヒープ領域に値を確保しています。ここで Box を経由する必要は必ずしもないですが、 alloc を直接呼ぶよりも便利なのでそうしていると思われます。実際、この時点ではヒープ領域は専有されており、参照先も有効な値が入っているので問題ありません。
clone
Rc は、「当該ヒープを指している Rc<T> の所有権の個数 = 強参照カウント」となるように管理されます。 Rc::clone は同じヒープを指す Rc<T> の所有権を複製する処理なので、参照カウントを増やすのが主な仕事です。
以下が clone の実装と inc_strong の実装の簡略版です。
impl<T: ?Sized> Clone for Rc<T> {
fn clone(&self) -> Rc<T> {
self.inc_strong();
Self { ptr: self.ptr }
}
}
impl<T: ?Sized> Rc<T> {
fn inc_strong(&self) {
let strong = self.inner().strong.get();
// We want to abort on overflow instead of dropping the value.
// The reference count will never be zero when this is called;
// nevertheless, we insert an abort here to hint LLVM at
// an otherwise missed optimization.
if strong == 0 || strong == usize::max_value() {
unsafe { abort(); }
}
self.inner().strong.set(strong + 1);
}
}
「参照カウンタを増やす」→「同じポインタの入った Rc<T> をもう1つ作って返す」です。簡単ですね。 clone の前後で、先ほど書いた不変条件が保たれるのもほぼ明らかです。
ひとつだけ興味深いのが、1を足す前の if 分岐です。 0 だった場合と usize::MAX だった場合はabort, つまり全てのスレッドを巻き込んでプロセスごと強制終了しています。これはなぜでしょうか。
参照カウントが 0 だった場合
これはコード中のコメントに記載があります。まず、 Rc が正しく使われている限り、この場所で参照カウントが 0 になることはありません。その上で、この行以降では参照カウントが 0 ではありえないということをこの分岐で明示することで、より最適化の助けになるだろうとしています。何やらそれなりにありそうな話ですね。 unreachable_uncheckedのようなより強力な表明にしない理由は不明ですが、ここまで細かいことを気にしても仕方ないかもしれません。 abort するほうが安全ですしね。
参照カウントが usize::MAX だった場合
さて、そもそも参照カウントが usize::MAX に到達する可能性はあるのでしょうか。 Rc<T> はそれ自体が2バイト以上 (Rustはポインタサイズが2バイト以上のプラットフォームのみ扱う) あるので、最大でも usize::MAX/2 個くらいの Rc<T> しか同時に存在できないような気もします。
しかし、前回述べたように、Rustではメモリリークは「安全」(メモリリークが起きないようにするための仕組みは整備されているが、絶対ではない)と見なされており、意図的にメモリリークを起こすための std::mem::forget という関数が用意されています。これを使うと以下のようなコードが書けます。
use std::mem;
use std::rc::Rc;
fn main() {
let rc = Rc::new(42);
loop {
// 複製しては捨てる……を繰り返す
// どんどん参照カウントが増える
mem::forget(rc.clone());
}
}
64bitプラットフォームだったら何百年~何千年もかかるので実質永遠ですが、32bit, 16bitプラットフォームなら現実的にこの状況を引き起こせそうです。また、まともなプログラムとしては起こりえないが、こういうバグを踏むこと自体はありえそうです。バグでも何でもこういう状況になる可能性はあるので、未定義動作を踏むような形で対処するのは良くなさそうです。
このとき、巡回して参照カウントを0にしてしまうとまずいことはわかるかと思います。0のときにどう対応するか(実際の実装は上に書いたようにabort)にもよりますが、仮に0が許容されていてmax→0→1→0というライフサイクルを辿った場合、大量の不正な Rc<T> が残ることになってしまいます。
ではどうすると良いでしょうか。主に4つの方法が考えられます。
- 参照カウントを飽和させ、drop時は普通にデクリメントさせる
- 参照カウントを飽和させ、drop時も減らさない
- panicする
- プログラムを異常終了させる (abort)
実のところ、どれでも安全性は確保できる可能性が高いです。特に最初の「参照カウントを飽和させ、drop時は普通にデクリメントさせる」はかなり際どいですが、実際にメモリ上に存在している Rc<T> の個数は限られているので、問題はないのではないかと思います。ただ、そういった際どい方法よりも、異常終了させるほうが考えることも少ないし、コンパイラの最適化もより期待できると思います。デメリットとしては、ごくごくレアケースとはいえ実際に遭遇したときの解決がやや困難になることですが、デバッガを使えば発生箇所の特定は可能でしょうし、レア度を考慮すると abort で十分そうです。
drop
弱参照のことを一旦忘れると、drop時にやるべきことは以下の3つです。
- 参照カウントを減らす。
- 参照カウントがゼロになったら、内容物を捨てる。 (
Tのデストラクタを呼ぶ) - 参照カウントがゼロになったら、ヒープ領域を解放する。
このことに注目して、 Drop の実装を簡略化したのが以下のコードです。
impl<T: ?Sized> Drop for Rc<T> {
fn drop(&mut self) {
unsafe {
self.dec_strong();
if self.strong() == 0 {
ptr::drop_in_place(self.ptr.as_mut());
Global.dealloc(self.ptr.cast(), Layout::for_value(self.ptr.as_ref()));
}
}
}
}
impl<T: ?Sized> Rc<T> {
fn dec_strong(&self) {
self.inner().strong.set(self.strong() - 1);
}
}
参照カウントを減らして、0になったら「中身のdrop」と「ヒープ領域の解放」をこの順番にやっているだけですね。かなりシンプルです。
Clone の実装と異なり、参照カウントの値が異常だったときの対応は深く考えられていないようです。まあ、あまり深い意味もないでしょう。
drop_in_place
drop_in_place はRustに組み込みの関数で、指定した型のデストラクタ (Drop::drop) を再帰的に呼んでくれます。たとえば、
ptr::drop_in_place::<i32>(p);
は実際には何もしません。一方、
ptr::drop_in_place::<Box<String>>(p);
であれば、 p の指す先 (Box) の指す先 (String) の指す先のヒープを解放したあと、 p の指す先 (Box) の指す先のヒープを解放します。
通常Rust はフィールドのデストラクタを自動的に呼んでくれるのですが、 Rc は構造体としては NonNull<RcBox<T>> という単なる生ポインタからなるので、その参照先を自動で破棄してくれません。(というよりも、参照先のデストラクタを呼ぶ条件を手動で制御したいから NonNull を使ったと言ったほうが正しいかもしれません。) ですから代わりに、 drop_in_place を使って明示的に再帰的なデストラクタ呼び出しを行っています。
Global.dealloc
Global.dealloc は不安定機能ですが、 dealloc で書き換えることができます。
// 同じ
Global.dealloc(self.ptr.cast(), Layout::for_value(self.ptr.as_ref()));
dealloc(self.ptr.cast().as_mut(), Layout::for_value(self.ptr.as_ref()));
dealloc を呼ぶのではなく、 Box を経由して捨てることもできます。ただ、 Rc::new ではヒープ領域とその中身の両方を同時に初期化していたので Box::new で作ることができましたが、drop時は別々に捨てるのでヒープ領域だけ捨てるようにうまく記述する必要があります。
弱参照を含めたライフサイクル
ここまでで、弱参照がない場合の基本的なライフサイクルを確認しました。これを踏まえて、弱参照を含めた場合にどう複雑化するかを追ってみます。
Rc::new
Rc::new の初期化コードは注目に値します。
impl<T> Rc<T> {
pub fn new(value: T) -> Rc<T> {
// There is an implicit weak pointer owned by all the strong
// pointers, which ensures that the weak destructor never frees
// the allocation while the strong destructor is running, even
// if the weak pointer is stored inside the strong one.
Self::from_inner(Box::into_raw_non_null(box RcBox {
strong: Cell::new(1),
weak: Cell::new(1),
value,
}))
}
}
なんと、初期化時点で弱参照カウントを1にしています。その理由はコメントにきちんと書いてあります。全ての強参照を代表して、1個の仮想的な弱参照が存在するとみなしているのです。このようなルールにした理由は次の Rc::drop の実装を見るとわかります。
Rc::drop
あらためて、弱参照の部分を省かずに Rc::dropの実装を見てみます。
impl<T: ?Sized> Drop for Rc<T> {
fn drop(&mut self) {
unsafe {
self.dec_strong();
if self.strong() == 0 {
// destroy the contained object
ptr::drop_in_place(self.ptr.as_mut());
// remove the implicit "strong weak" pointer now that we've
// destroyed the contents.
self.dec_weak();
if self.weak() == 0 {
Global.dealloc(self.ptr.cast(), Layout::for_value(self.ptr.as_ref()));
}
}
}
}
}
「強参照を減らす→0になったら中身をdropする」「弱参照を減らす→0になったらヒープ領域を解放する」という2段構えになっています。これなら、カウンタとリソースの対応関係が明白ですね。このことはあとで Arc の実装を考える上でも重要になってきます。
Rc::downgrade, Weak::clone
これを踏まえて、 Weak のライフサイクルを見ていきます。まず Weak を作るための主要な方法である Rc::downgrade は以下のようになっています。
impl<T: ?Sized> Rc<T> {
pub fn downgrade(this: &Self) -> Weak<T> {
this.inc_weak();
// Make sure we do not create a dangling Weak
debug_assert!(!is_dangling(this.ptr));
Weak { ptr: this.ptr }
}
fn inc_weak(&self) {
let weak = self.weak();
// We want to abort on overflow instead of dropping the value.
// The reference count will never be zero when this is called;
// nevertheless, we insert an abort here to hint LLVM at
// an otherwise missed optimization.
if weak == 0 || weak == usize::max_value() {
unsafe { abort(); }
}
self.inner().weak.set(weak + 1);
}
}
また Weak::clone の実装 は簡略化すると以下のようになっています。
impl<T: ?Sized> Clone for Weak<T> {
fn clone(&self) -> Weak<T> {
self.inner.inc_weak();
Weak { ptr: self.ptr }
}
}
inc_weak の実装は inc_strong の実装と同じで、理屈も同じです。弱カウンタを増やして、対応する Weak の所有権を生成して返しているだけなので、 Rc::clone と理屈はほぼ同じですね。
downgrade は引数として Rc<T> ではなく &Rc<T> を取っているので、実際には「引数を降格する」のではなく「引数を降格した新しい Weak<T> を返す」という操作だといえます。そのため、 downgrade は弱参照カウンタを増やしはするものの強参照カウンタを減らす処理は行いません。 (元々の Rc<T> が捨てられる場合は、そこで強参照カウンタが減らされます。)
Weak::upgrade
弱参照に欠かせないのがWeak::upgradeです。これは Weak から中身を取得する唯一の方法で、まだ中身が生きている場合に Weak を Rc に昇格します。
impl<T: ?Sized> Weak<T> {
pub fn upgrade(&self) -> Option<Rc<T>> {
let inner = self.inner()?;
if inner.strong() == 0 {
None
} else {
inner.inc_strong();
Some(Rc::from_inner(self.ptr))
}
}
}
基本構造は Rc::clone に似ていますが、強参照カウントが0かどうかで分岐している点が特徴です。強参照カウントは Rc の個数なので、 Weak から見たときはこのカウントが0になる可能性があります。この場合もう参照先の中身は捨てられてしまっているので、 Rc への昇格はできません。
Rc::downgrade と同様、 Weak::upgrade も Weak<T> ではなく &Weak<T> を引数に取っているので、弱参照カウンタを減らす処理はありません。
Weak::drop
Weak::dropは Rc::drop の後半部分と同じです: (以下のソースは簡略版)
impl<T: ?Sized> Drop for Weak<T> {
fn drop(&mut self) {
self.inner().dec_weak();
// the weak count starts at 1, and will only go to zero if all
// the strong pointers have disappeared.
if self.inner().weak() == 0 {
unsafe {
Global.dealloc(self.ptr.cast(), Layout::for_value(self.ptr.as_ref()));
}
}
}
}
この部分が共通になることが、弱参照カウントを1から始めることの理由といってもいいでしょう。どちらも「ヒープ領域」という同じリソースに依存しており、 Rc<T> 側のdropが起因でヒープ領域が不要になることもあれば Weak<T> 側のdropが起因になることもあります。ということは、どちらも同じカウンタ、同じフローでdropできるのが自然で堅牢だといえます。
別の言い方をすると、 Rc<T> はヒープ領域を直接所有しておらず、 T がヒープ領域に依存しているという構造だと見ることもできます。
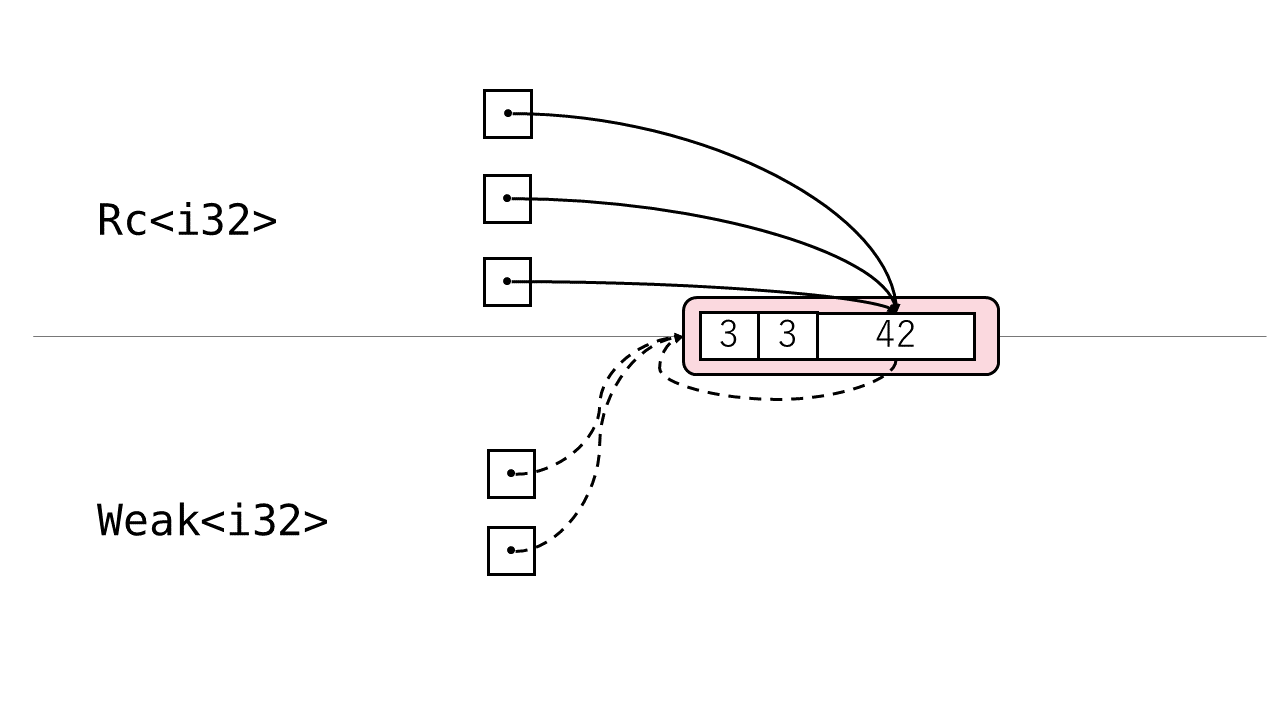
上の図では、実線の個数が強参照カウント、破線の個数 (Weak からの依存 + 中身からの依存) が弱参照カウントと説明できます。
ここで強参照カウントがなくなると Rc の中身はdropされます。その結果弱参照カウントが1減るというのは以下のような図で説明がつきます。
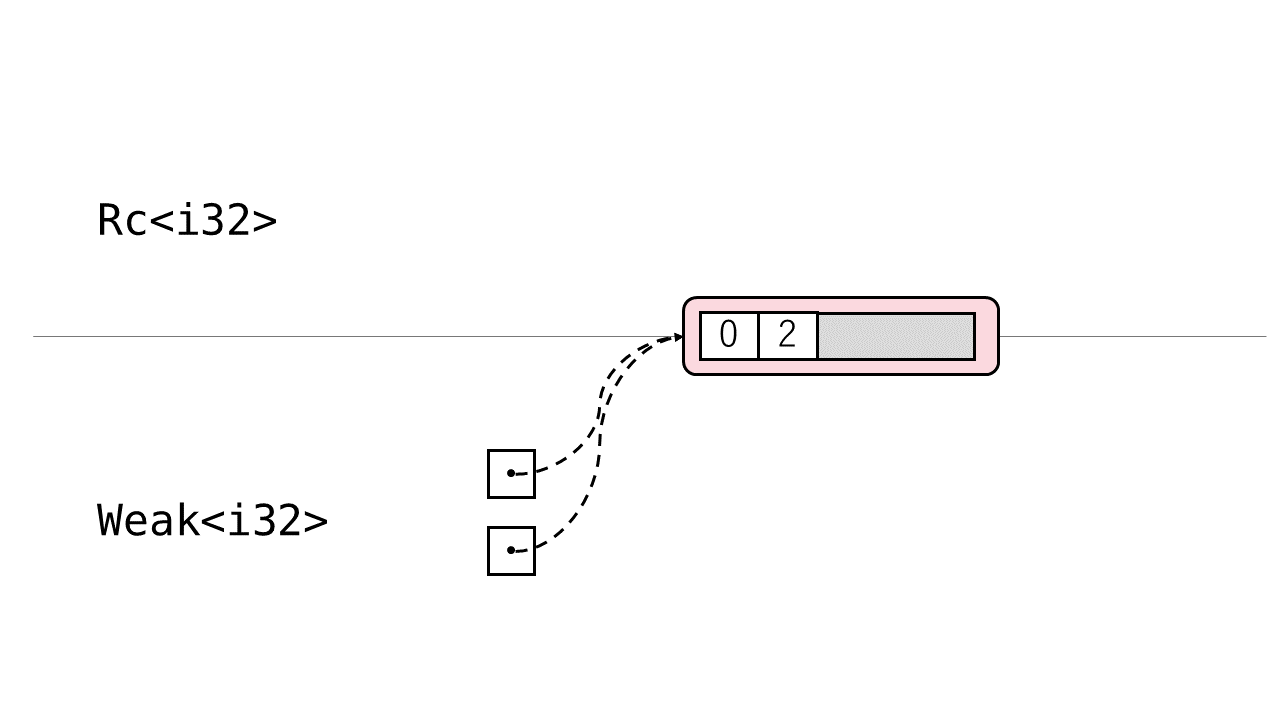
CoW機能
Rc には try_unwrap, get_mut, make_mut という3つのCoW (copy on write)機能があります。これも Rc のライフサイクルを考える上では欠かせません。
impl<T> Rc<T> {
pub fn try_unwrap(this: Self) -> Result<T, Self> {
if Rc::strong_count(&this) == 1 {
unsafe {
let val = ptr::read(&*this); // copy the contained object
// Indicate to Weaks that they can't be promoted by decrementing
// the strong count, and then remove the implicit "strong weak"
// pointer while also handling drop logic by just crafting a
// fake Weak.
this.dec_strong();
let _weak = Weak { ptr: this.ptr };
forget(this);
Ok(val)
}
} else {
Err(this)
}
}
}
impl<T: ?Sized> Rc<T> {
pub fn get_mut(this: &mut Self) -> Option<&mut T> {
if Rc::is_unique(this) {
unsafe {
Some(Rc::get_mut_unchecked(this))
}
} else {
None
}
}
fn is_unique(this: &Self) -> bool {
Rc::weak_count(this) == 0 && Rc::strong_count(this) == 1
}
pub unsafe fn get_mut_unchecked(this: &mut Self) -> &mut T {
&mut this.ptr.as_mut().value
}
}
impl<T: Clone> Rc<T> {
pub fn make_mut(this: &mut Self) -> &mut T {
if Rc::strong_count(this) != 1 {
// Gotta clone the data, there are other Rcs
*this = Rc::new((**this).clone())
} else if Rc::weak_count(this) != 0 {
// Can just steal the data, all that's left is Weaks
unsafe {
let mut swap = Rc::new(ptr::read(&this.ptr.as_ref().value));
mem::swap(this, &mut swap);
swap.dec_strong();
// Remove implicit strong-weak ref (no need to craft a fake
// Weak here -- we know other Weaks can clean up for us)
swap.dec_weak();
forget(swap);
}
}
// This unsafety is ok because we're guaranteed that the pointer
// returned is the *only* pointer that will ever be returned to T. Our
// reference count is guaranteed to be 1 at this point, and we required
// the `Rc<T>` itself to be `mut`, so we're returning the only possible
// reference to the inner value.
unsafe {
&mut this.ptr.as_mut().value
}
}
}
どちらも「参照カウントが1なら専有できる」という理屈は共通していますが、詳細はそこそこ異なります。
try_unwrap
try_unwrap は、強参照カウントが1のときに Rc<T> を T に変換する機能です。取り出した T はもはやもとのヒープ領域とは無関係なので、ヒープ領域を管理している弱参照カウントのことは気にしなくていいわけです。
手順
実際の手順は以下の4手順からなっています。
let val = ptr::read(&*this);
まず、 read を使って目的の値 T を読み出しています。この read はunsafeです。なぜなら、本来1個しか存在してはいけない所有権が読み出し元と読み出し先の両方に存在してしまうからです。そのままreturnやpanicによって呼び出し元に返ってしまうと、本来1回分しか呼ばれてはいけない T のdropが2回分呼ばれることになってしまいます。そのため、うっかりpanicしてしまわないように気をつけながら、ここの整合性を回復する必要があります。
this.dec_strong();
ここは強参照カウントを1減らしています。もともと1であることを確認しているので、これは0を代入するのと同じですが、わかりやすさのために dec_strong を使っていると思われます。
これでもう1つ整合性が崩れることになります。というのも、本来強参照カウントは Rc の個数と対応づけて管理されるからです。 Drop 内でもないのに dec_strong を呼んでしまうと、この対応が崩れてしまいます。したがって、このあとで整合性を回復する必要があります。
forget(this);
順番を入れ替えて、先に4つめの操作を説明します。この行では第一引数である this: Rc<T> を forget で捨てています。この forget はデストラクタを呼ばずに所有権を破棄する関数です。つまり、本来 Rc<T> を捨てるごとに呼ばれるべき次の4つの処理が1回分実行されなくなります。
- (A) 強参照カウントを1減らす。
- (B) 強参照カウントが0になったら、
Tのデストラクタを呼ぶ。 - (C) 強参照カウントが0になったら、弱参照カウントを1減らす。
- (D) 弱参照カウントが0になったら、ヒープ領域を解放する。
この(A) (B) には見覚えがないでしょうか。そうです。これは1個目と2個目の操作で発生した不整合のちょうど逆にあたります。つまり、これで前半の不整合はうまく打ち消せたことになります。
しかし、 (C) (D) でまた新たな不整合が生じた状態になってしまいますね。そこで3番目の操作に遡ります。
let _weak = Weak { ptr: this.ptr };
この3番目の操作では Weak を新規作成しています。作ること自体は単なるstructの組み立てで、特に効果があるわけではありません。目的は、この作った Weak のデストラクタを呼ぶことにあります(_weak という変数に保存されているので、デストラクタは forget よりも後に呼ばれます)。 Weak のデストラクタは以下のことをしていました。
- (C) 強参照カウントが0になったら、弱参照カウントを1減らす。
- (D) 弱参照カウントが0になったら、ヒープ領域を解放する。
これは、まさに forget で新たに発生した不整合とちょうど対応しますね。これでちょうど不整合が解消されたことになります。
Result
try_unwrap は Option ではなく Result を返します。
通常 Option と Result の使い分けは「エラー時にエラーハンドリングの必要があるかどうか」で判断されますが、このケースは異なります。単に「エラーケースでも値を返す必要があるから」だといえます。では返すべき値とはなにかというと、元々の Rc<T> です。
借用と異なり、所有権は一度渡してしまうと明示的に取り戻さない限りはそれっきりなので、このような失敗する可能性のある所有権ベースの変換では、失敗時に元の値を返す慣習があります。
弱参照はどうなるか
Rc::try_unwrap が成功すると、当該ヒープ領域への強参照 Rc は0個になります。なので当然、 Weak はupgrade不可能な状態になります。
get_mut
get_mut は、強参照カウント・弱参照カウントともに1のときに &mut Rc<T> を &mut T に変換する機能です。ある意味では、 条件つきの DerefMut ということもできます。
実装は簡単です。「強参照カウント・弱参照カウントともに1」をチェックした上で、中身への &mut 参照を返しています。
正当性
&'a mut T は、時刻 'a までの間当該メモリ領域を専有してよいという保証つきの参照です。
&'a mut Rc<T> は T に対する参照の参照なので、&'a mut 部分 と Rc 部分の両方が時刻 'a までの間専有されていることが保証されていれば十分です。
前者は定義そのまま明らかです。後者はどうでしょうか。強参照カウントと弱参照カウントがともに1なので、 get_mut が呼ばれた時点ではエイリアスがないことは保証されています。ということは今ある唯一の Rc<T> から新しいエイリアスができないかだけ考えばいいわけですが、そもそもこの唯一の Rc<T> の時刻 'a までの専有権が get_mut に渡されているわけですから、他者がこの期間に Rc<T> に対して何かをすることはできません。なので問題ないというわけです。
&Self ではだめな理由
&Self にしてしまうと、 get_mut を呼んだ後にエイリアスを作成することができてしまいます。
use std::rc::Rc;
// もし get_mut が &self を取る仕様だった場合、これが動いてしまう
fn main() {
let rc = Rc::new(42);
let p = Rc::get_mut(&rc).unwrap();
let rc2 = rc.clone();
eprintln!("{}", rc2); // 42
*p = 53;
eprintln!("{}", rc2); // 53
// rc2の参照先が知らないうちに書き変わっている。これは未定義動作
}
実際には get_mut は &mut Self を取るわけですが、以下の修正版コードもきちんとエラーになります。
use std::rc::Rc;
fn main() {
let mut rc = Rc::new(42);
let p = Rc::get_mut(&mut rc).unwrap();
let rc2 = rc.clone();
//~^ERROR cannot borrow `rc` as immutable because it is also borrowed as mutable
eprintln!("{}", rc2); // 42
*p = 53;
eprintln!("{}", rc2); // 53
}
弱参照カウントを調べる必要がある理由
弱参照を許してしまうと、 get_mut を呼んだ後に弱参照を昇格することでエイリアスを作成できてしまいます。
use std::rc::Rc;
fn main() {
let mut rc = Rc::new(42);
let weak = Rc::downgrade(&rc);
let p = Rc::get_mut(&mut rc).unwrap(); // ここで実行時エラーになるので問題ない
let rc2 = weak.upgrade().unwrap();
eprintln!("{}", rc2); // 42
*p = 53;
eprintln!("{}", rc2); // 53
}
上のコードで、後半のコードに到達できてしまうと未定義動作になってしまいますが、実際には get_mut が None を返すため問題ありません。
Option
try_unwrap は Result を返しますが、 get_mut は Option を返します。
get_mut に失敗しても、渡した &mut Rc<T> の有効期限が切れれば Rc<T> は再使用になるため、エラー時に所有権を返却するようなインターフェースにする必要はありません。
make_mut
get_mut はcopy-on-writeパターンを実装するのに便利です。つまり、専有されていればそのまま書き換え、共有されていたら新しい Rc に乗り換えてそこでデータを書き換えるということができます。このためには以下のようなパターンを書くことになります。
// たとえば以下のような `rc` があったとする
let mut rc: Rc<String>;
// copy-on-writeで新しい文字列を作る
if let Some(s) = Rc::get_mut(&mut rc) {
// 専有されていたので、その場で書き換える
s.push_str(" world!");
} else {
// 文字列バッファは共有されていたので、複製する
let mut s = (*rc).clone();
// 書き換える
s.push_str(" world!");
rc = Rc::new(s);
}
ところで、 get_mut に失敗しても try_unwrap には成功する可能性があります。したがって (ムーブ検査の機微の問題でおそらくそのままでは通りませんが)気持ち的には以下のような分岐を書くことができるはずです。
// たとえば以下のような `rc` があったとする
let mut rc: Rc<String>;
// copy-on-writeで新しい文字列を作る
if let Some(s) = Rc::get_mut(&mut rc) {
// 専有されていたので、その場で書き換える
s.push_str(" world!");
} else {
// 完全にユニークではなかったが、強参照は1個しかないかもしれないので試す
match Rc::try_unwrap(rc) {
Ok(mut s) => {
// 弱参照しかなかったので、所有権を盗む
s.push_str(" world!");
rc = Rc::new(s);
}
Err(rc) => {
// 文字列バッファは共有されていたので、複製する
let mut s = (*rc).clone();
// 書き換える
s.push_str(" world!");
rc = Rc::new(s);
}
}
}
このパターンをまとめてひとつにしたのが Rc::make_mut です。
make_mut は、参照が共有されていたときは実体である T を複製するので、 T: Clone を要求します。
make_mut はさらにこのパターンへの最適化をしていますが、その仕組みについては省きます。
まとめ
-
RcとWeakはどちらも同じヒープ領域に対するポインタで、ヒープ領域には「強参照カウンタ」「弱参照カウンタ」「実体」の3つが乗っている。 - 参照カウンタは共有書き換えの対象のため、内部可変性コンテナである
Cell<T>で囲まれている。 -
Rcの参照先にアクセスするために単項の*演算子がオーバーロードされている。この操作のコストはとても低い -
Rc自身の基本ライフサイクルは new(カウンタ1)→clone(カウンタ増)→drop(カウンタ減) である。 -
Weakの基本ライフサイクルは downgrade(弱カウンタ増)→upgrade(強カウンタ増) および clone(弱カウンタ増)/drop(弱カウンタ減) である。 -
Rcからの影響をわかりやすくするために、弱カウンタはデフォルトで1多くカウントされている。 - 「参照カウンタが1である」という条件のもとで動く
try_unwrap/get_mut関数と、それを活用したmake_mut関数がある。
第2回では、Rc の参照カウンタのライフサイクルと借用に注目しながら Rc のソースコードを読みました。
まだ Rc には多くの知見が宿っているので、第3回では Rc の細部を読んでいきます。







コメント