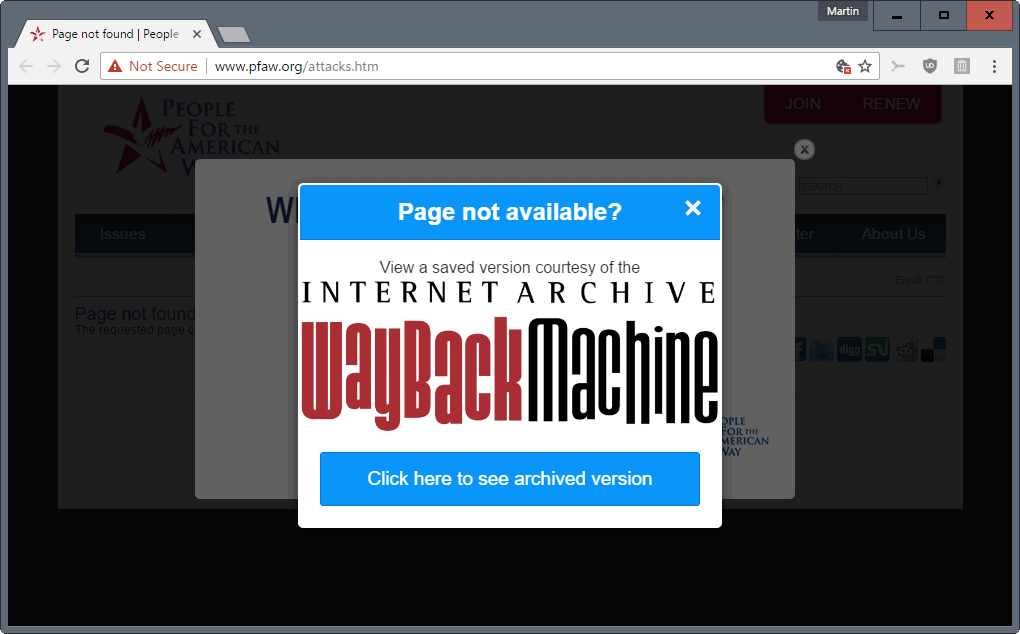
Page not found? Load archived copies with Wayback Machine for Chrome
Wayback Machine is a new browser extension for Google Chrome that detects page error codes to suggest to access archived copies of the page.
There is a saying that the Internet won't forget a thing, and that it is difficult to impossible to remove content from the Internet completely.
While that is the case, it is no rare occurrence that Internet users encounter deleted, redirected or temporarily unavailable pages or entire sites.
The most common error is probably 404 page not found, but there are plenty of other errors and codes that users may encounter (called HTTP status codes).
It can be quite the frustrating experience if a resource is no longer available. Maybe because it holds the solution for a computer issue that you are researching, has the answer to a question you have, or because it is the download page of a program that you want to download.
Wayback Machine for Chrome (and Firefox)
Note: Wayback Machine was released only for Google Chrome. Firefox users can install the extension in their browser however using the Firefox add-on Chrome Store Foxified. The extension works just fine in the browser when that is done.
One of the better ways to deal with dead or temporarily unavailable pages is to use the Wayback Machine. The Wayback Machine is an Internet resource that holds copies of web pages.
You can head over to the official website right away to start using it. The archive provides you with access to more than 279 billion web pages currently, and the number is growing.
While that is one way to deal with it, it is cumbersome if you encounter dead or unavailable pages regularly.
That's where the Google Chrome extension Wayback Machine comes into play. The official extension detects a bunch of relevant error codes -- 404, 408, 410, 451, 500, 502, 503, 504, 509, 520, 521, 523, 524, 525, and 526 -- to suggests to load an archived version of the page on the Wayback Machine website.
All you need to do then is to click on the "click here to see archived version" button to do that. This is easier obviously than having to open the site manually, pasting in the URL of the page, and waiting for the results to be returned to you.
It needs to be noted that there are limitations to the process:
- This works only if an archived copy of the page is available.
- The page needs to throw one of the supported error codes, and not handle errors in another way. For instance, if a page displays a custom error page, Wayback Machine may not work correctly.
The second limitation is a bit unfortunate, One way to get around this would be to add the look up functionality to the extension icon in Chrome. This is not the case right now, but it would be highly beneficial if the developers would add the option to the extension.
The developers have added the feature. You can click on the Wayback Machine icon now to make it retrieve the most recent or oldest entry of the page you are on regardless of error status.
Another feature that got added recently is the option to save pages directly to the Wayback Machine using the "save page now" command.
It is interesting to note that Mozilla is testing the functionality right now in one of Firefox's Test Pilot projects. No More 404s acts specifically on pages that return 404 not found error codes however. Firefox users may use third-party add-ons like Resurrect Pages instead as well which offer improved functionality.


As a long-time and grateful user of the WayBack Machine, I wonder if this extension takes the Internet Archive timeline into account. They scan for, capture and archive old web pages repeatedly, not just once. For any given web page, there may be dozens or hundreds of older versions available, laid out on a time scale day by day for many years. Whatever you are looking for might be on a saved version of an obsolete page that is ten or 100 layers back.
Example:
https://www.ghacks.net
Saved 2,124 times between October 26, 2005 and January 15, 2017.
Interesting historical info:
https://en.wikipedia.org/wiki/Wayback_Machine
Instead of installing yet another add-on, one can also (at least on Firefox) set up a bookmarklet or a bookmark with a keyword and the %s trick.
That’s what I do.
Same here. Since years I have wayback in my search engines, so I only need to paste the offending url there and see what the machine returns. Often times the latest samples of defunct web sites are themselves defunct or crippled, making it necessary to manually look for the latest working version of a web page or site. Like you, I wouldn’t entrust an add-on with such a delicate operation -:)
Or you Lumpy Gravy, could you please reply with the Bookmarklets or the thing Jomy was talking about “bookmark with a keyword and the %s trick”? Unless they’re the same thing.
Okay, thank you guys for your help. i now have 4 Javascript Bookmarklets for Wayback and archiving. i got the rest from that Wikipedia Link you posted Lumpy. Thanks again. i Love these Javascript Bookmarklets. They’re so convenient and can reduce the need for add-ons.
Opens First Wayback Archive In New Tab – javascript:(function(){window.open(‘http://web.archive.org/web/20080706114831/’+location.href);})();
Opens Year of Most Recent Wayback Archives In New Tab – javascript:void(window.open(‘https://web.archive.org/web/*/’+location.href));
Opens Year of Most Recent Wayback Archives In Same Tab – javascript:location.href=’https://web.archive.org/web/*/’+document.location.href;
Saves Currently Viewed Website on Wayback Archive In New Tab – javascript:void(window.open(‘https://web.archive.org/save/’+location.href));
2 Bonus Javascript Bookmarklets, i got 1 from Tom Hawack, user on this site. Both these following 2 will only work if that website has HTTPS available.
Makes Current URL HTTPS – javascript:((function(){window.location=location.href.replace(/^http/i,”https”).replace(/^http\w{2,}/i,”http”);})()); – Clicking it again will make it go back to HTTP
Makes Current URL HTTP – javascript:((function(){window.location=location.href.replace(/^https/i,”http”).replace(/^http\w{2,}/i,”http”);})());
i just saw Martin posted another article on Wayback Archiving. i think i’ll copy and paste most of this reply in that new article to help other users out.
Here’s one for Archive.is
Saves Currently Viewed Website to Archive.is In New Tab – javascript:void(open(‘https://archive.today/?run=1&url=’+encodeURIComponent(document.location)))
Jomy, could you please reply with the Bookmarklet or the “bookmark with a keyword and the %s trick”? Unless they’re the same thing.
For a bookmarklet, add this to your bookmarks:
javascript:location.href=’https://web.archive.org/web/*/’+document.location.href;
When you are on a webpage you want to check on Wayback machine, stay on that page, and click on the bookmarklet. That will lead you to the corresponding page on Wayback machine.
It may not work if you have the NoScript add-on, since this is Javascript. The %s works even with NoScript, but characters like / and : in the URL are transformed into safe characters for security reasons. Wayback Machine is the only site I know that fails to understand that the safe characters are actually : and /, so it doesn’t recognize the URL you want to search, and so it’s the only site that won’t work with %s out of the box.
PS: Be careful when adding bookmarklets proposed by strangers. The one I give you is easy to understand so you know it’s safe, but people can make you execute code that you didn’t expect.
Have a look here, Rick.
I do not use bookmarklets but I just tried it out with these dead web sites …
http://tuxdeluxe.org/
https://web.archive.org/web/20160111084143/http://tuxdeluxe.org/
http://www.zinelibrary.info/
https://web.archive.org/web/20131205224907/http://www.zinelibrary.info/
http://www.donmartinshrine.com/
https://web.archive.org/web/20130113040659/http://www.donmartinshrine.com/
… and found that tuxdelux and zinelibrary work with this method (although for zinelibrary you need to go back 3 years to get a working sample of the web site) but donmartinshrine doesn’t work because the current owner (occupier, hijacker) of the domain alters the url and thus makes it useless in wayback machine. This happens quite often with unused or dead domains which is why I prefer to use the wayback machine in my search engines.
P.S.:
%s isn’t a trick. It’s just a place holder for a value that’s passed to a url, e.g. in the search engines of your browser.
I’ve been using Resurrect Pages for Firefox for years. You can use the Wayback Machine, Google (full page or text only), Archive.is, or Webcite.
Chrome’s finally catching up to Firefox? LOL…
Resurrect Pages for Firefox allows you to look up *any* page’s cached versions with a right-click (and adds itself to Firefox’s “Page Not Found” page automatically). Hopefully it will be upgraded to Web Extensions (since it doesn’t use XUL code).
Like those above, I’ve also been using Resurrect Pages for years, originally in FireFox and now in Pale Moon. Very useful.