
経緯
とある勉強会の内容の復習&整理
タイトル
- インストール・アーキテクチャ基礎編
- レプリケーション編 ←今回はこちら
- バックアップ編
- チューニング基礎編
レプリケーション編 アジェンダ
- レプリケーションとは
- レプリケーションの仕組み
- レプリケーションの種類
- レプリケーションの設定方法
- バイナリログの管理方法
- その他の考慮事項
- 参考情報
1. レプリケーションとは
1.1. 基礎知識
- データの複製(レプリカ)を別のサーバにモテる機能
- MySQLの標準機能で、多数のWebサイト等で利用されている
- シンプルな設定で利用可能
- マスター → スレーブ構成
1.2. マスタースレーブ構成
- サーバはマスター、スレーブまたは両方になれる
- マスターサーバ
- データを変更
- 変更内容をスレーブに転送
- マスターは複数のスレーブを持てる
- スレーブサーバ
- マスターでの変更内容を受け取る
- 変更内容をデータベースに反映
- スレーブは1つのマスターのみ持てる
1.3. レプリケーションの利点
- 参照性能の向上
参照処理の負荷が高い場合は、スレーブサーバを追加することで、負荷分散による性能向上が実現できる
- 高可用性構成の実現
マスターの障害時に、スレーブをマスターに昇格することで高可用性を実現可能
- 地理的冗長性の実現
地理的に離れた場所に、災害対策サイトを構築可能
NW経由で離れたロケーションでマスタースレーブ構成を構築可能
- バックアップサーバとしての利用
スレーブサーバでバックアップを取得することで、マスターサーバに影響を与えずにバックアップを取得可能
-例)マスターサーバは常時かどうさせつつ、スレーブサーバでDBを停止してコールドバックアップを取得する
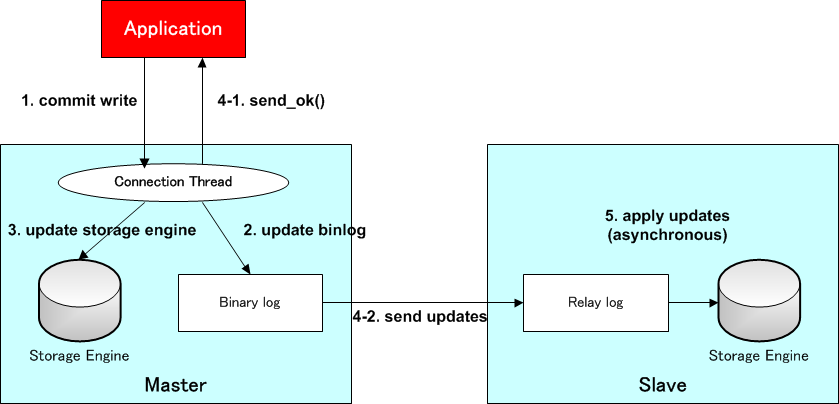
2. レプリケーションの仕組み
2.1. 仕組み
- マスターサーバでの全ての変更点をバイナリログに記録し、バイナリログの内容をスレーブに転送し、実行することで実現
- スレーブがレプリケーションの開始をマスターにリクエスト
- マスターがレプリケーションデータをスレーブに転送
- リレーログの内容をスレーブに適用
log-slave-updatesを設定している場合、スレーブでもバイナリログを出力(多段構成のレプリケーション時必須)
2.2. バイナリログ
- 発行されたクエリのうち、更新系のSQL文のみを記録しているログファイル
- クエリ実行日時などのメタデータも記録
- トランザクションのコミット時に同期的に記録(sync_binlog=1)
- バイナリ形式で記録
-
mysqlbinlogコマンドにてテキスト化が可能
- 起動オプションを指定して、出力する
-
--log-bin[=file_name]
- 通常の運用時には利用することを推奨
- データディレクトリとは別のディスクに出力することを推奨
- ログファイル名の拡張子に通し番号を記録
- 例)
file_name_bin.001, file_name-bin.002, etc.
- 現在利用中のログ番号はインデックスファイルに記録(file_name.index)
2.3. スレーブ上に存在するファイル、スレッド
- ファイル
| ファイル名 | 説明 |
|---|---|
| リレーログファイル | マスターから受信した変更点を記録したファイル |
| バイナリログファイル | スレーブで実行した変更点を記録したファイル(log-slave-updatesを有効にしている場合のみ出力) |
| master.info | マスターへの接続に必要な情報や、読み取りを開始するバイナリログのいち情報(バイナリログファイル名とポジション)が記録されているOS上のファイル(MySQL5.6からテーブル内に格納可能) |
| relay-log.info | リレーログをどこまで適用したかを記録しているOS上のファイル(MySQL5.6からテーブル内に格納可能) |
- スレッド
| スレッド名 | 説明 |
|---|---|
| I/Oスレッド | マスターから受信したバイナリログをリレーログファイルとして保存 |
| SQLスレッド | リレーログファイル内の更新内容をDBへ反映する |
- イメージ図

3. レプリケーションの種類
3.1. バイナリログ記録方式
3.1.1. バイナリログ記録方式による違い
| フォーマット | 説明 | バイナリログサイズ | Non-deterministic | スレーブトリガー動作可否 |
|---|---|---|---|---|
| SBR(Statement Based Replication) | SQL文がそのままバイナリログに記録される | 小 | × | 動作する |
| RBR(Row Based Replication) | 更新されたデータそのものが記録される | 大 | ○ | 動作しない(トリガーにより変更された行の変更は伝搬される) |
| MBR(Mixed Based Replication) | SBRとRBRを状況に応じて切り換える | 小 | ○ | SBRは動作するがRBRは動作しない |
3.1.2. Non-deterministicとは
- 非決定性なSQL文=実行する度に結果が変わる可能性があるSQL文
UUID()
UUID_SHORT()
USER()
FOUND_ROWS()
LOAD_FILE()
SYSDATE()
GET_LOCK()
RELEASE_LOCK()
IS_FREE_LOCK()
IS_USED_LOCK()
MASTER_POS_WAIT()
SLEEP()
VERSION()
ソートなしのLIMIT句
UDF
非決定性のストアドプロシージャ/ファンクション
INFORMATION_SCHEMAの参照
READ-COMMITTED
READ-UNCOMMITTED
3.2. 同期方式
3.2.1. 非同期
- デフォルトの設定
- 変更点を非同期で転送
- メリット
準同期よりもマスターサーバの更新処理のレスポンスタイムがいい
- デメリット
マスターサーバに障害が発生した場合、障害発生直前の更新内容がスレーブに伝搬されていない可能性がある
- 負荷分散向き
障害発生直前の更新データを保護する必要がある場合は、別途アプリケーション側での対応が必要
3.2.2. 準同期
- MySQL5.5から追加された機能
- 変更点を同期で転送し、非同期でDBに反映
- メリット
マスターサーバに障害が発生した場合、障害発生直前の更新内容もスレーブに伝搬されている
- デメリット
非同期よりもマスターサーバの更新処理のレスポンスタイムが悪い
- 高可用性目的に向く
障害発生直前の更新データもDBの側で保護する必要がある場合
3.2.3. イメージ
- 非同期レプリケーション
- 準同期レプリケーション

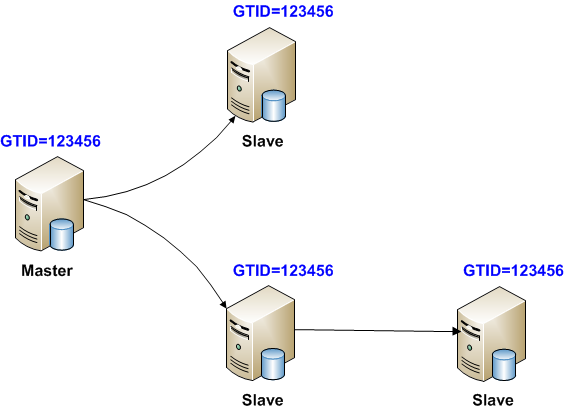
3.3. GTID
3.3.1. GTIDについて
- GTID (Global Transaction ID)
- MySQL5.6で追加された機能
- 複数台のレプリケーション環境でも容易にトランザクションの追跡/比較が可能
トランザクションをグローバルで(レプリケーションを構成するMySQLサーバ全てにおいて)一意に識別できる識別子をバイナリログに記録
3.3.2. GTIDを使用する/しないによる違い
- 使用する場合、レプリケーションの運用方法が従来の方式とは変わる
- レプリケーション開始時にポジションを自動認識
- フェイルオーバーの為に、最も最新のスレーブを自動認識
- 多段構成のレプリケーションが容易に
3.3.3. GTIDのメリット
- バイナリログのポジションを自動認識してくれるため、指定する必要が無い
マスターに障害が発生してフェイルオーバーする場合など、障害発生時のポジションを確認せずにフェイルオーバー処理を実現できる
- MySQL Utilities内の
mysqlfailoverを使用して自動フェイルオーバーを実現できるなど、以下のGTIDに依存した機能が使える
| 機能 | 説明 |
|---|---|
| mysqlfailover | レプリケーション環境の自動フェイルオーバー |
| mysqlpladmin | レプリケーション環境の管理(一部機能のみGTIDに依存) |
| mysqlplms | ランドロビン接続によるマルチソースレプリケーション |
| mysqlrplsync | レプリケーションの同期状況を確認 |
| mysqlslavetrx | スレーブでトランザクションをスキップ(MySQL Utilities1.6にて追加予定) |
3.3.4. GTIDのデメリット
- 以下の制限事項がある
- マスター/スレーブ共に、InnoDB以外のストレージエンジンは使えない
(トランザクションに対応したストレージエンジン以外は使えない)
-CREATE TABLE ... SELECTが使用できない
-CREATE TEMPORARY TABLE及びDROP TEMPORARY TABLEをトランザクションの中で使用できない
(トランザクションを使わない場合は、使用可能)
-sql_slave_skip_counterはサポートされない
(トランザクションをスキップしたい場合は、gtid_executed変数を利用する必要がある)
- 全スレーブでバイナリログを出力する必要がある
- レプリケーションのフィルタリングと併用することが困難である
フィルタリングすると、GTIDに欠番が出来るため運用が非常に複雑になる
- GTIDを有効にするためには、全サーバを一度停止してからGTIDモードに行こうする必要があるため、既存環境をGTIDモードに移行しづらい(1サーバずつGTIDモードを有効にできない)
- 現在開発中のMySQL5.7では1サーバずつGTIDモードを有効にできる
4. レプリケーションの設定方法
4.1. GTID無効の場合
4.1.1. 設定概要(GTID無効)
- レプリケーション用のパラメータを設定
- マスターサーバにレプリケーション用ユーザを作成
- マスターサーバのバックアップを取得して、スレーブサーバにリストア
- バックアップ取得時のバイナリログファイルのファイル名とポジションを記録しておく
- スレーブサーバで
CHANGE MASTER TOコマンドを実行 - スレーブサーバで
START SLAVEコマンドを実行
4.1.2. レプリケーション用のパラメータ設定(GTID無効)
- マスター:下記オプションを設定して起動
server-id
log-bin
datadir *
- スレーブ:下記オプションを設定して起動
server-id
datadir *
port *
socket *(Linux系のOSのの場合)
read_only(必須ではないが、設定を推奨)
- *は、テスト目的で1台のサーバ内でマスター、スレーブを作成する場合に必要な設定
4.1.3. マスターサーバにレプリケーション用ユーザを作成(GTID無効)
-
REPLICATION SLAVE権限を付与してユーザを作成
CREATE USER 'repl'@'localhost' IDENTIFIED BY 'repl';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'localhost';
4.1.4. バックアップを取得してスレーブサーバへリストア(GTID無効)
- コールドバックアップを取得してリストアする
-
mysqldumpでバックアップを取得してリストアする
【注意事項】
データの整合性を保つ為に、バックアップ取得中は、テーブルに関するDDL文を実行しないこと
$ mysqldump --user=root --password=root --master-data=2 --socket=/usr/local/mysql/data/mysql.sock --hex-blob --default-character-set=utf8 --all-databases --single-transaction > mysql_bkup_dump.sql
4.1.4.1. mysqldumpのオプション
| オプション | 説明 |
|---|---|
| --master-data=2 | バックアップ取得のバイナリファイル名とバイナリファイル内の位置(Position)をコメントとしてバックアップファイルに記録 |
| --hex-blob | バイナリ型(BINARY, VARBINARY, BLOG)とBIT型のデータを16進数表記で出力 |
| --default-character-set |
mysqldumpがデフォルトで利用するキャラクタセットを指定。通常はMySQLサーバのシステム変数default-character-setと同じものを指定すれば良い |
| --all-databases | 全てのデータベースをバックアップ |
| --lock-all-tables | 全てのテーブルをロックしてバックアップを取得する |
| --single-transaction | InnoDBがサポートしているトランザクションの仕組みを利用して、InnoDBテーブルに限り一貫性のとれたバックアップを取得する |
4.1.5. スレーブサーバでCHANGE MASTER TOコマンドを実行(GTID無効)
-
CHANGE MASTER TOコマンドを実行
CHANGE MASTER TO MASTER_HOST='localhost',
-> MASTER_USER='repl',
-> MASTER_PASSWORD='repl',
-> MASTER_LOG_FILE='bin.000001', #バックアップ取得時に記録したファイル名を指定
-> MASTER_LOG_POS=1790; #バックアップ取得時に記録したポジションを指定
4.1.6. スレーブサーバでSTART SLAVEコマンドを実行(GTID無効)
-
START SLAVEコマンドを実行
START SLAVE;
MySQL5.6の場合、セキュリティ向上のために
CHANGE MASTER TO時にMASTER_USER,MASTER_PASSWORDを指定せずに、START SLAVE時に指定することも可能。
(master.info内にユーザ名/パスワードが保存されることを防ぐ)
4.2. GTID有効の場合
4.2.1. 設定概要(GTID有効)
- レプリケーション用のパラメータを設定
- マスターサーバにレプリケーション用ユーザを作成
- マスターサーバのバックアップを取得して、スレーブサーバにリストア
- バイナリログファイルのファイル名とポジションを記録する必要無し
- スレーブサーバで
CHANGE MASTER TOコマンドを実行 - スレーブサーバで
START SLAVEコマンドを実行
4.2.2. レプリケーション用のパラメータ設定(GTID有効)
- マスター:下記オプションを設定して起動
server-id
log-bin
datadir *
gtid-mode=on
enforce-gtid-consistency=on
log-slave-updates
- * は、テスト目的で1台のサーバ内でマスター、スレーブを作成する場合に必要な設定
- GTIDモードにする場合は、太文字のパラメータをマスター/スレーブの両方で指定する
- スレーブ:下記オプションを設定して起動
server-id
log-bin
datadir *
port *
socket *(Linux系OSの場合)
read_only(必須ではないが、設定を推奨)
gtid-mode=on
enforce-gtid-consistency=on
log-slave-updates
- * は、テスト目的で1台のサーバ内でマスター、スレーブを作成する場合に必要な設定
- GTIDモードにする場合は、太文字のパラメータをマスター/スレーブの両方で指定する
4.2.3. マスターサーバにレプリケーション用ユーザを作成(GTID有効)
-
REPLICATION SLAVE権限を付与してユーザを作成
CREATE USER 'repl'@'localhost' IDENTIFIED BY 'repl';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'localhost';
4.2.4. バックアップを取得してスレーブサーバへリストア(GTID有効)
- コールドバックアップを取得してリストアする
- datadir配下の`auto.cnfを削除しておく
(マスターとスレーブでserver-uuidを一意にするため(※))
※GTIDのフォーマットにはserver-uuidが含まれているため、server-uuidを一意にしておく必要あり
-
mysqldumpでバックアップを取得してリストアする
【注意事項】
データの整合性を保つ為に、バックアップ取得中は、テーブルに関するDDL文を実行しないこと
Warning発生を防ぐために、以下のオプションも指定
--triggers
--routines
--events
※GTIDモードで取得したmysqldumpには、SET @@GLOBAL.GTID_PURGED='XXX';が含まれる
$ mysqldump --user=root --password=root --master-data=2 --socket=/usr/local/mysql/data/mysql.sock --hex-blob --default-character-set=utf8 --all-databases --single-transaction --triggers --routines --events > mysql_bkup_dump.sql
4.2.5. スレーブサーバでCHANGE MASTER TOコマンドを実行(GTID有効)
-
CHANGE MASTER TOコマンドを実行
CHANGE MASTER TO MASTER_HOST='localhost',
-> MASTER_USER='repl',
-> MASTER_PASSWORD='repl',
-> MASTER_AUTO_POSITION=1;
4.2.6. スレーブサーバでSTART SLAVEコマンドを実行(GTID有効)
-
START SLAVEコマンドを実行
START SLAVE;
MySQL5.6の場合、セキュリティ向上のために
CHANGE MASTER TO時にMASTER_USER,MASTER_PASSWORDを指定せずに、START SLAVE時に指定することも可能。
(master.info内にユーザ名/パスワードが保存されることを防ぐ)
5. バイナリログの管理方法
- 管理用コマンド一覧
| コマンド | 説明 |
|---|---|
| SHOW MASTER STATUS | 現在使用中のバイナリログファイル名とポジションを確認 |
| SHOW MASTER LOGS | コマンドで全てのバイナリログファイル名を列挙 |
| FLUSH [BINARY] LOGS | ログのローテーション(または再起動で実現可能) |
| PURGE MASTER | 特定の時点までのバイナリログを削除 |
| RESET MASTER | 全てのバイナリログを削除 |
| SHOW BINLOG EVENTS | バイナリログファイルの中身を確認 |
- バイナリログは溜まり続けるファイルであるため、運用の中で定期的に削除が必要
(expire_logs_daysを設定して、指定した日数を肥えたものを自動削除することも可能)
- リレーログは自動的に削除される
(デフォルトでrelay_log_purge=1になっている)
- レプリケーション管理のためのコマンド(スレーブ側)
| コマンド | 説明 |
|---|---|
| START SLAVE [SLAVE_TYPE] | スレーブ起動 |
| STOP SLAVE [SLAVE_TYPE] | スレーブ停止 |
- トランザクションスキップ
- 運用中に何かしらの原因でレプリケーションエラーが発生した場合、状況を確認後、特定のトランザクションをスキップすることで回避する場合、などに使用
- GTIDモードの場合は、この方法は使用できない
STOP SLAVE;
SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
START SLAVE;
6. その他の考慮事項
6.1. MySQLレプリケーション単独では用意されていない機能
- 高可用性構成としての利用時にフェールオーバーさせる仕組み
- MySQL5.6にて、自動フェールオーバーできるスクリプト
MySQL Utilitiesを提供
※要GTIDモード
- 更新と参照の処理を振り分ける仕組み、スレーブ間でのロードバランスの仕組み
-
Connector/J(Java)やmysqlnd_ms(PHP)などで制御可能
-MySQL Fabricでも制御可能
6.1.1. Connector/J (MySQLのJDBCドライバ)のロードバランス/フェイルオーバー機能
- 接続URLを以下の形式で指定することで、各種機能を利用可能
jdbc:mysql://primary,failover-1,failover-2...
- 通常利用するサーバが停止すると、他のサーバにフェイルオーバーする
jdbc:mysql;replication://master,slave1,slave2...
- レプリケーション構成において、更新処理はマスターにて実行され、参照処理はスレーブ間で分散する
jdbc:mysql:loadbalance://server1,server2...
- MySQL Cluster(NDB)やマルチマスターレプリケーションの構成の場合、参照更新処理を全てのノードに分散する
- プロパティの補足
autoReconnect=true
- 接続が切れた時に再接続を行う
(接続が切れた状態でクエリ実行した場合、クエリは実行されずにSQLExceptionがスルーされる)
failOberReadOnly=false
- 別のノードに接続先を変更した場合に、読み取り専用モードにするか否かを制御する
roundRobinLoadBalance=true
- 障害発生時(フェイルオーバー時)に次のサーバから接続を試みる
(前項の例ではprimaryとの接続が切れた場合に、再度primaryへ接続することなく、failover-1へ接続を試みる)
6.1.2. mysqlnd (MySQL native driver for PHP) の拡張機能
mysqlnd_ms(Master Slave)
-
mysqlndのプラグインで、ロードバランスやマスター/スレーブの振り分け、フェイルオーバーに対応可能
6.1.3. MySQL Fabric1.5 高可用性&シャーディング
- OpenStackとの統合
- 高可用性
- サーバの監視、スレーブの自動昇格と透過的なレプリケーション切替
- シャーディングによる拡張性
- アプリケーションがシャードのキーを提供
整数型、日付型、文字列型
- レンジまたはハッシュ
- シャード再構成可能
- Fabric対応コネクタ利用
- Python, Java, PHP, .NET, C(labs)
- プロキシを使わないので低レイテンシ、ボトルネック無し
6.2. 設計
- 一度に大量の更新処理を実行しない(トランザクションを細かく分割する)
- スレーブの遅延を防ぐための工夫
- マスターのトランザクションがコミットされてから、その内容がスレーブに転送されるため、トランザクション実行に時間がかかる場合は、その分スレーブへの反映も遅くなる
6.3. 監視
SHOW SLAVE STATUSの結果から、主に以下の点を監視
- I/Oスレッド、SQLスレッドが稼働しているか?
- I/Oスレッド:
Slave_IO_Running
- SQLスレッド:Slave_SQL_Running
- レプリケーション遅延が起きていないか?また、起きている場合の詳細状況の確認
- レプリケーション遅延の有無の確認
Seconds_Behind_Master
- バイナリログをどこまで転送しているかの確認
Master_Log_File
Read_Maser_Log_Pos
- リレーログの実行状況
Relay_Master_Log_File
Exec_Master_Log_Pos
- ネットワーク遅延の確認
- マスターで
SHOW MASTER STATUSの実行結果にて下記を確認
Master_Log_FileとRead_Master_Log_Posを比較
その他の監視項目
- スロークエリログの監視
- 遅延の原因となり得る長時間実行されるクエリを確認
- マスター、スレーブのディスク空き容量
- 特にスレーブのディスク空き容量が減っている場合は、リレーログが削除されていない(レプリケーションが停止している)危険性あり
- マスター、スレーブのサーバリソース使用状況(CPU、メモリ、I/O量、ネットワークトラフィック)
- MySQL5.6以降で実装されているマルチスレッドスレーブを使わない場合、スレーブでの更新処理はシングルスレッドで実行されることにも注意
7. 参考情報
7.1. 主なレプリケーションパラメータオプション(MySQL5.6以降)
| レプリケーション関連設定 | 概要 |
|---|---|
| binlog_row_image=minimal | 行イメージを全て保持するのではなく、最低限のカラムの情報だけ保持するように、バイナリログのフォーマットを変更可能です。full,minimal,noblob
|
| slave_parallel_workers=n | スレーブ側でのしょりをマルチスレッド化できるため、スレーブの遅延を改善できる可能性があります(スキーマ単位) |
| relay_log_info_repository=TABLE | ポジションの情報をInnoDB上のテーブルに記録する為、クラッシュセーフになりました。(relay_log_recovery=ONも合わせて設定) |
| relay_log_recovery=ON | リレーログに問題があった時に、マスターから自動的に読み直します。 |
| binlog_checksum=NONE | バイナリログチェックサム(デフォルト:CRC32) |
| binlog_rows_query_log_events=ON | SQL文に関する情報をバイナリログに追加可能。レプリケーションの追跡や問題発生時のデバッグに役立つ(mysqlbinlog -vv) |
| MASTER_DELAY=N |
CHANGE MASTER実行時に指定。遅延させたい時間を秒単位で指定。 |
| MASTER_BIND |
CHANGE MASTER実行時に指定。スレーブサーバが複数のNICOLEを持っている場合、マスターとの接続に使用するNICを明示的に指定できるようになりました。 |
7.2. レプリケーションのフィルタリング
- スレーブ側で受け取ったバイナリログから適用する内容を設定できる(my.cnfに記入)
| パラメータ | 概要 |
|---|---|
| replicate-do-db=db_name | 指定したDB(スキーマ)だけをレプリケーション対象にする |
| replicate-do-table=db_name.tbl_name | 指定したテーブルだけをレプリケーション対象にする |
| replicate-ignore-db=db_name | 指定したDB(スキーマ)をレプリケーション対象から除く |
| replicate-ignore-table=db_name.tbl_name | 指定したテーブルをレプリケーション対象から除く |
7.3. MySQLの高可用性構成
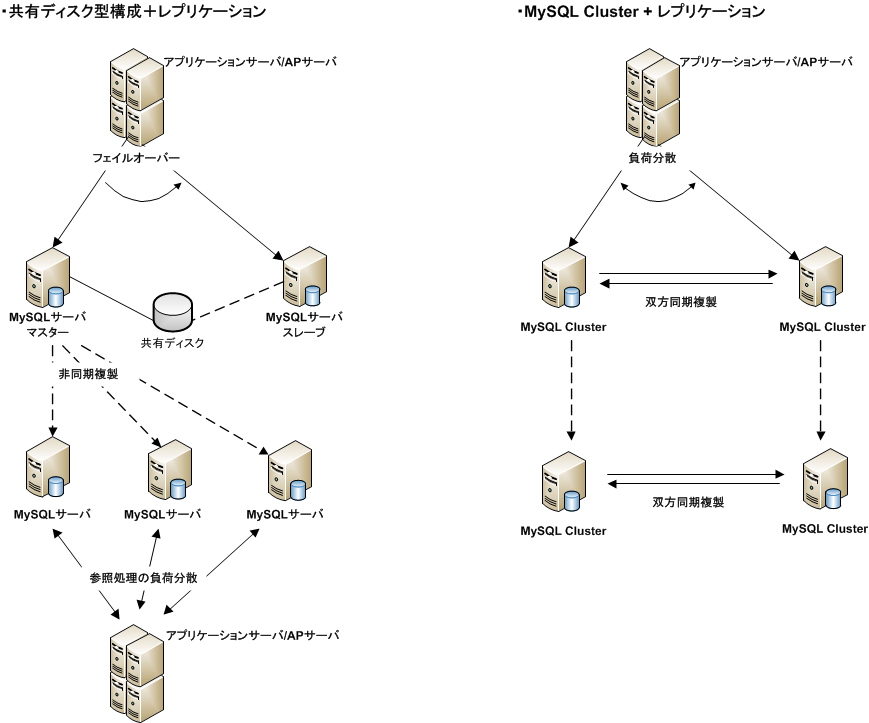
7.3.1. 構成パターン例
- 高可用性構成パターン例

- 複合型の高可用性構成パターン例
7.3.2. 各高可用性構成パターンのメリット/デメリット
7.3.2.1. レプリケーションによる高可用性構成
- メリット
- MySQLの標準機能だけで実現でき、共有ディスクや特別なソフトウェアも不要であるため、共有ディスクを使った方式に比べH/Wコスト、ソフトウェアコストを低く抑えられる
- 参照処理の負荷分散と高可用性構成を同じ仕組で実現できる
(スレーブを参照処理でも活用すれば、H/Wリソースの有効活用にも繋がる)
- デメリット
- フェイルオーバー処理を別途実現する必要があるなど、運用時の考慮事項が多い
・障害発生時にどのようにしてフェイルオーバー処理を実行するか
・フェイルオーバーによってMySQLサーバの構成が変わった場合、
アプリケーションからMySQLサーバへの接続先を切り換える必要がある
・(MySQL5.5以前の場合)すればがクラッシュセーフではないため、
スレーブに障害が発生するとスレーブを再構築しないといけない場合がある
- デメリットに対する改善機能
- フェイルオーバー処理の自動化
・GTIDモードでレプリケーションを構成すると、MySQL Utilities内容mysqlfailoverを
使用することで、自動フェイルオーバーが可能になる
(mysqlfailoverの実態はPythonスクリプト)
- アプリケーションからの接続先切替の必要性
・MySQL Utileties内のMySQL Fabricを使用することで、
フェイルオーバー処理を自動化でき、フェイルオーバー後にも
アプリケーションからの接続先変更が不要になる
(内部的に、GTIDのモードによるレプリケーションを使用)
- MySQL5.5以前でクラッシュセーフではない事への改善機能
・MySQL5.6で以下のパラメータを設定することで、クラッシュセーフなスレーブが実現可能
relay_log_recovery=ON
relay_log_info_repository=TABLE
※マスター/スレーブ共に、InnoDBを使用する必要がある
7.3.2.2. MySQL+DRBDによる高可用性構成
- メリット
- 共有ディスクが不要であり、共有ディスクを使用した高可用性構成に比べてH/Wコストを抑えられる
- デメリット
- フェイルオーバー処理を別途実現する必要があるなど、運用時の考慮事項が多い
・障害発生時に、どのようにしてフェイルオーバー処理を実行するか
-DRBDで同期しているディスク領域と同期していないディスク領域が混在することにも注意が必要
・プライマリ/スタンバイで同期が取れなくなった場合の対応
-MySQL以外に、DRDBについても知識が必要
- スタンバイ機は完全なスタンバイ機となる
(レプリケーションでスレーブを参照処理に利用する場合に比べ、H/Wリソースを有効活用できない)
7.3.2.3. 共有ディスク+クラスタウェア(Oracle Clusterwareなど)を使った高可用性構成
- メリット
- フェイルオーバー処理をクラスタウェアで自動制御できるため、運用負荷が低い
- 共有ディスクにデータがあるため、プライマリ/スタンバイでデータの不整合が起きない
- デメリット
- 共有ディスクやクラスタウェアを用意する必要があり、コストがかかる
▶Oracle Clusterwareを使用することで、ソフトウェアコストを削減可能
- スタンバイ機は完全なスタンバイ機となる
(レプリケーションでスレーブを参照処理に利用する場合に比べ、H/Wリソースを有効活用できない)
7.3.2.4. MySQL Clusterによる高可用性構成
- メリット
- SPOFがなく、フェイルオーバー時間も極めて短いため、可用性が非常に高い
- Active-Active構成のため、スタンバイ機を用意する場合に比べリソースを有効活用できる
- 参照処理だけでなく、更新処理についても負荷分散できる
- SQLだけでなく、豊富なNoSQLインターフェースも持っている(両方の利点を活かせる)
※MySQL Clusterは、元々NoSQLのデータストアでした
- デメリット
- 通常のMySQLサーバとはアーキテクチャが異なる(データの持ち方が異なる)為、
アプリケーションの処理内容によって向き、不向きがある
・主キーやユニークインデックスベースの処理が得意
・スキャン系の処理は上記に比べるとオーバヘッドが大きい
- 運用方法が、通常のMySQLサーバと異なる(MySQL Clusterの知識が別途必要)
- 必要なサーバ台数が多くなる(最小構成で3台から)
後記
かなりのボリュームになってしまいました。










コメント @GrassfieldK
@GrassfieldK1  @Tocyuki
@Tocyuki0
アーキテクチャ、どういうフローでレプリケートされているか、というところがいまいち理解できていなかったのですが、
こちらと公式ドキュメントを交互に読んでいくことで、だいたい飲み込めました。
とても参考になりました。ありがとうございます。
こういった勉強会、機会があればどんどん参加していきたいですね…
@gtemacomp ありがとうございます!最近全然勉強会参加できていないのでモチベーション上げねば