

![]()
ご覧いただきありがとうございます。ソリトンシステムズのセキュリティ分析チームです。
Google Colaboratoryにアカウントをお持ちの方は、上の「Open in Colab」と書かれた青いボタンを押せば直接notebookをColabで開けます。ぜひ動かしてみてください。
過去の記事も含め、全てのコードをGithubで公開しています。
今までGo, Rustとやってきましたが、処理効率を考えるとCと比較しないわけにはいきません。そこでCでも同様のことをやってみました。
64bit整数の8バイト配列化
まずは愚直な方法
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
for (int i = 0; i < SIZE; i += 1) {
vs[i] = rand();
}
uint8_t buf[SIZE][8];
// 計測開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx < SIZE; idx++) {
uint64_t v = vs[idx];
for (uint8_t j = 0; j < 8; j++) {
buf[idx][j] = v >> (8 * j);
}
}
}
end_clock = clock();
// 計測終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
for (int i = 0; i < 8; i++) printf("%d ", buf[0][i]);
printf("\n");
uint64_t total = 0;
for (size_t i = 0; i < SIZE; i += 1) {
for (size_t j = 0; j < 8; j += 1) {
total += buf[i][j];
}
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
34.356244 sec
103 69 139 107 0 0 0 0
44595596
Goでは138秒、Rustでは8秒ですから、Goよりは速いですが、Rustより相当遅い。オプティマイザの性能の違いでしょうか。
それでは定石通り、内側のfor文を展開しましょう。
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
for (int i = 0; i < SIZE; i += 1) {
vs[i] = rand();
}
uint8_t buf[SIZE][8];
// 計測開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx < SIZE; idx++) {
uint64_t v = vs[idx];
uint8_t *p = (uint8_t*)&buf[idx];
p[0] = v;
p[1] = v >> 8;
p[2] = v >> 16;
p[3] = v >> 24;
p[4] = v >> 32;
p[5] = v >> 40;
p[6] = v >> 48;
p[7] = v >> 56;
}
}
end_clock = clock();
// 計測終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
for (int i = 0; i < 8; i++) printf("%d ", buf[0][i]);
printf("\n");
uint64_t total = 0;
for (size_t i = 0; i < SIZE; i += 1) {
for (size_t j = 0; j < 8; j += 1) {
total += buf[i][j];
}
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
34.478777 sec
103 69 139 107 0 0 0 0
44595596
Goはこれで40秒にまで改善されましたが、Cでは改善されませんでした。
さて、Goではポインターを使うことで8秒、Rustではライブラリを使って4秒まで短縮されました。Cではどうでしょうか。ポインターを使ってみます。
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
for (int i = 0; i < SIZE; i += 1) {
vs[i] = rand();
}
uint8_t buf[SIZE][8];
// 計測開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx < SIZE; idx++) {
*(uint64_t*)&buf[idx] = vs[idx];
}
}
end_clock = clock();
// 計測終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
for (int i = 0; i < 8; i++) printf("%d ", buf[0][i]);
printf("\n");
uint64_t total = 0;
for (size_t i = 0; i < SIZE; i += 1) {
for (size_t j = 0; j < 8; j += 1) {
total += buf[i][j];
}
}
printf("%ld\n", total);
return 0;
}
Writing main.c
!clang -Ofast main.c
!./a.out
3.662140 sec
103 69 139 107 0 0 0 0
44595596
Rustと同程度の速度です。ぎりぎりCの面目を保った感じです。
ちなみに、gccでコンパイルするとこうなります。
!gcc -Ofast main.c
!./a.out
3.713717 sec
103 69 139 107 0 0 0 0
44595596
8バイト配列から64bit整数への変換
まずは素朴な実装
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
uint8_t buf[SIZE][8];
srand(0);
for (int i = 0; i < SIZE; i += 1) {
for (int j = 0; j < 8; j += 1) {
buf[i][j] = (uint8_t)rand();
}
}
// 計測開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx < SIZE; idx++) {
uint8_t *b = (uint8_t*)&buf[idx];
uint64_t v = 0;
for (int j = 0; j < 8; j += 1) {
v += ((uint64_t)b[j] << (8 * j));
}
vs[idx] = v;
}
}
end_clock = clock();
// 計測終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
printf("%ld\n", vs[0]);
uint64_t total = 0;
for (size_t i = 0; i < SIZE; i += 1) {
total += vs[i];
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
23.260235 sec
-1420042007188224409
3501406831367042067
Goで172秒、Rustで12秒ですから、微妙です。
あまり期待できませんが、念の為、内側のfor文を展開します。
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
uint8_t buf[SIZE][8];
srand(0);
for (int i = 0; i < SIZE; i += 1) {
for (int j = 0; j < 8; j += 1) {
buf[i][j] = (uint8_t)rand();
}
}
// 計測開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx < SIZE; idx++) {
uint8_t *b = (uint8_t*)&buf[idx];
uint64_t v = (uint64_t)b[0];
v += (uint64_t)b[1] << 8;
v += (uint64_t)b[2] << 16;
v += (uint64_t)b[3] << 24;
v += (uint64_t)b[4] << 32;
v += (uint64_t)b[5] << 40;
v += (uint64_t)b[6] << 48;
v += (uint64_t)b[7] << 56;
vs[idx] = v;
}
}
end_clock = clock();
// 計測終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
printf("%ld\n", vs[0]);
uint64_t total = 0;
for (size_t i = 0; i < SIZE; i += 1) {
total += vs[i];
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
23.236868 sec
-1420042007188224409
3501406831367042067
やはり変わりません。ちなみにGoでは39秒、Rustでは19秒でした。Rustでは展開したほうが遅くなりました。
それでは本命のポインターによる実装です。
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
uint8_t buf[SIZE][8];
srand(0);
for (int i = 0; i < SIZE; i += 1) {
for (int j = 0; j < 8; j += 1) {
buf[i][j] = (uint8_t)rand();
}
}
// 計測開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx < SIZE; idx++) {
vs[idx] = *(uint64_t*)&buf[idx];
}
}
end_clock = clock();
// 計測終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
printf("%ld\n", vs[0]);
uint64_t total = 0;
for (size_t i = 0; i < SIZE; i += 1) {
total += vs[i];
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
3.847355 sec
-1420042007188224409
3501406831367042067
さすがC。Goで13秒、Rustで6秒でしたから、相当速い。
ただ、同様にポインターを使用したRustが遅いのが気になります。Rustの実装は、
*(buf[idx].as_ptr() as *mut u64)
なのですが、as_ptr()の呼び出しに何らかのコストがかかっていると思われます。なにかもっといい方法があるかもしれません。
40bit整数の5バイト配列化
まずは素朴な実装
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
for (int i = 0; i < SIZE; i += 1) {
vs[i] = rand() & 0xFFFFFFFFFF;
}
uint8_t buf[SIZE][5];
// 計測開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx < SIZE; idx++) {
uint64_t v = vs[idx];
uint8_t *b = (uint8_t*)buf[idx];
for (uint8_t j = 0; j < 5; j++) {
b[j] = v >> (8 * j);
}
}
}
end_clock = clock();
// 計測終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
for (int i = 0; i < 5; i++) printf("%d ", buf[0][i]);
printf("\n");
uint64_t total = 0;
for (size_t i = 0; i < SIZE; i += 1) {
for (size_t j = 0; j < 5; j += 1) {
total += buf[i][j];
}
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
21.758302 sec
103 69 139 107 0
44595596
8バイトの時は34秒でしたから、5バイトに減った分だけ順当に短縮されています。ちなみにGoでは90秒、Rustでは22秒でした。
それでは少し工夫してmemcpy()を使ってみましょう。
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#include <string.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
for (int i = 0; i < SIZE; i += 1) {
vs[i] = rand() & 0xFFFFFFFFFF;
}
uint8_t buf[SIZE][5];
// 計測開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx < SIZE; idx++) {
memcpy((void*)&buf[idx], (void*)&vs[idx], 5);
}
}
end_clock = clock();
// 計測終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
for (int i = 0; i < 5; i++) printf("%d ", buf[0][i]);
printf("\n");
uint64_t total = 0;
for (size_t i = 0; i < SIZE; i += 1) {
for (size_t j = 0; j < 5; j += 1) {
total += buf[i][j];
}
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
11.055892 sec
103 69 139 107 0
44595596
だいぶ速くなって、Rustで関数を利用した時と同程度になりました。Rustでも関数内部でmemcpy()を使っているのかもしれません。
ちなみにGoの最速も同程度です。
次に、5バイトを4バイトと1バイトに分けて複製する方法を実装します。4バイトをuint32_tとして一命令で複製できるのが強みです。
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#include <string.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
for (int i = 0; i < SIZE; i += 1) {
vs[i] = rand() & 0xFFFFFFFFFF;
}
uint8_t buf[SIZE][5];
// 計測開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx < SIZE; idx++) {
uint64_t v = vs[idx];
uint8_t *b = (uint8_t*)buf[idx];
*(uint32_t*)b = *(uint32_t*)&v;
b[4] = ((uint8_t*)&v)[4];
//b[4] = (uint8_t)(v >> 32);
}
}
end_clock = clock();
// 計測終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
for (int i = 0; i < 5; i++) printf("%d ", buf[0][i]);
printf("\n");
uint64_t total = 0;
for (size_t i = 0; i < SIZE; i += 1) {
for (size_t j = 0; j < 5; j += 1) {
total += buf[i][j];
}
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
10.291578 sec
103 69 139 107 0
44595596
速くなりました。これは同様の処理をRustで実装した場合と同程度です。ただ、64bit整数の8バイト配列化が4秒程度ですから、cpuネイティブのビット幅と異なる整数の取り扱いにはそれなりのコストがかかることが分かります。
5バイト配列から40bit整数への変換
素朴な方法
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
uint8_t buf[SIZE][5];
srand(0);
for (int i = 0; i < SIZE; i += 1) {
for (int j = 0; j < 5; j += 1) {
buf[i][j] = (uint8_t)rand();
}
}
// 計測開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx < SIZE; idx++) {
uint8_t *b = (uint8_t*)&buf[idx];
uint64_t v = b[0];
v += (uint32_t)(b[1]) << 8;
v += (uint32_t)(b[2]) << 16;
v += (uint32_t)(b[3]) << 24;
v += (uint64_t)(b[4]) << 32;
vs[idx] = v;
}
}
end_clock = clock();
// 計測終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
printf("%ld\n", vs[0]);
uint64_t total = 0;
for (size_t i = 0; i < SIZE; i += 1) {
total += vs[i];
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
19.377722 sec
349828662887
54993386919705396
8バイトの時が23秒でしたから、それなりに短縮されています。Goでは24秒、Rustでは10秒でした。
次に、uint64_tで取得してから0xFFFFFFFFFFでマスクすることで5バイト化する方法です。
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
uint8_t buf[SIZE][5];
srand(0);
for (int i = 0; i < SIZE; i += 1) {
for (int j = 0; j < 5; j += 1) {
buf[i][j] = (uint8_t)rand();
}
}
// 計測開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx < SIZE; idx++) {
vs[idx] = ((*(uint64_t*)&buf[idx]) & 0xFFFFFFFFFF);
}
}
end_clock = clock();
// 計測終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
printf("%ld\n", vs[0]);
uint64_t total = 0;
for (size_t i = 0; i < SIZE; i += 1) {
total += vs[i];
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
5.493084 sec
349828662887
54993386919705396
相当速い。ただ、64bitでは4秒でしたので、マスク処理にそれなりのコストがかかっています。ちなみに、Goの最速が14秒、Rustが7秒です。
マスクではなく、4バイトと1バイトに分ける方法を試してみます。
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
uint8_t buf[SIZE][5];
srand(0);
for (int i = 0; i < SIZE; i += 1) {
for (int j = 0; j < 5; j += 1) {
buf[i][j] = (uint8_t)rand();
}
}
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx < SIZE; idx++) {
uint8_t *b = buf[idx];
vs[idx] = (*(uint32_t*)b) + (((uint64_t)b[4]) << 32);
}
}
end_clock = clock();
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
printf("%ld\n", vs[0]);
uint64_t total = 0;
for (size_t i = 0; i < SIZE; i += 1) {
total += vs[i];
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
6.296989 sec
349828662887
54993386919705396
遅くなりました。この処理ではマスクの方が有効です。
40bit整数の配列の5Nバイト配列化
10万個の整数を5バイトずつのバイト配列にします。まずは素朴な実装。
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
for (int i = 0; i < SIZE; i += 1) {
vs[i] = rand() & 0xFFFFFFFFFF;
}
uint8_t buf[SIZE * 5];
// 測定開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx< SIZE; idx++) {
uint64_t v = vs[idx];
size_t idx5 = idx * 5;
uint8_t *b = (uint8_t*)(buf + idx5);
for (uint8_t j = 0; j < 5; j++) {
b[j] = v >> (8 * j);
}
}
}
end_clock = clock();
// 測定終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
for (int i = 0; i < 5; i++) printf("%d ", buf[i]);
printf("\n");
uint64_t total = 0;
for (size_t i = 0; i < SIZE * 5; i += 1) {
total += buf[i];
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
21.700678 sec
103 69 139 107 0
44595596
Goが104秒、Rustが21秒ですから、Rustと同等程度です。
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
for (int i = 0; i < SIZE; i += 1) {
vs[i] = rand() & 0xFFFFFFFFFF;
}
uint8_t buf[SIZE * 5];
// 測定開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx< SIZE; idx++) {
uint64_t v = vs[idx];
size_t idx5 = idx * 5;
uint8_t *b = (uint8_t*)(buf + idx5);
b[0] = v;
b[1] = v >> 8;
b[2] = v >> 16;
b[3] = v >> 24;
b[4] = v >> 32;
}
}
end_clock = clock();
// 測定終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
for (int i = 0; i < 5; i++) printf("%d ", buf[i]);
printf("\n");
uint64_t total = 0;
for (size_t i = 0; i < SIZE * 5; i += 1) {
total += buf[i];
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
21.771300 sec
103 69 139 107 0
44595596
Goが16秒、Rustが21秒ですから、Rustと同程度です。CやRustといえど工夫無くしてはGoに負けることがあるようです。
次に下図の戦略での実装。
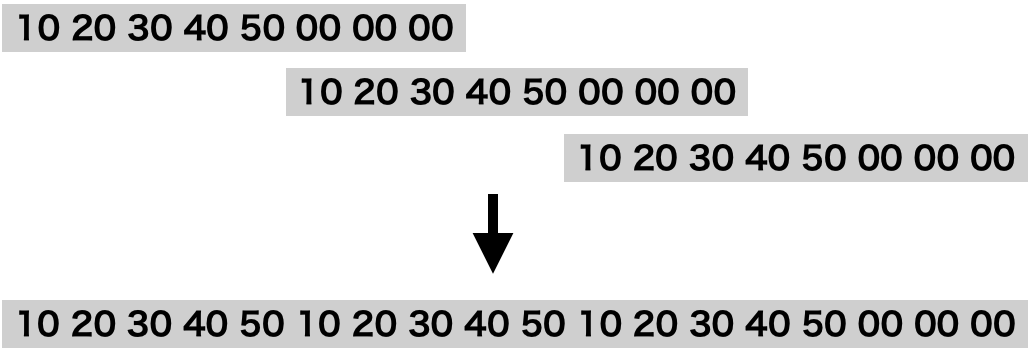
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
for (int i = 0; i < SIZE; i += 1) {
vs[i] = rand() & 0xFFFFFFFFFF;
}
uint8_t buf[SIZE * 5 + 3];
// 測定開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx < SIZE; idx++) {
*(uint64_t*)(buf + idx * 5) = vs[idx];
}
}
end_clock = clock();
// 測定終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
for (int i = 0; i < 5; i++) printf("%d ", buf[i]);
printf("\n");
uint64_t total = 0;
for (size_t i = 0; i < SIZE * 5; i += 1) {
total += buf[i];
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
6.865956 sec
103 69 139 107 0
44595596
Goが12秒、Rustが8秒ですので、Rustより少し速い程度です。
5Nバイト配列から40bit整数の配列への変換
5バイトずつのバイト配列から10万個の整数を読み出します。素朴な実装は以下になります。
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
uint8_t buf[SIZE*5];
srand(0);
for (int i = 0; i < SIZE*5; i += 1) {
buf[i] = (uint8_t)rand();
}
// 測定開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx < SIZE; idx += 1) {
size_t idx5 = idx * 5;
uint8_t *b = buf + idx5;
uint64_t *v = vs + idx;
*v = b[0];
*v += (uint64_t)(b[1]) << 8;
*v += (uint64_t)(b[2]) << 16;
*v += (uint64_t)(b[3]) << 24;
*v += (uint64_t)(b[4]) << 32;
}
}
end_clock = clock();
// 測定終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
printf("%ld\n", vs[0]);
uint64_t total = 0;
for (size_t i = 0; i < SIZE; i += 1) {
total += vs[i];
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
15.463057 sec
349828662887
54993386919705396
Goが23秒、Rustが8秒ですので、間ぐらい。
0xFFFFFFFFFFによるマスクの方法。
%%writefile main.c
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define COUNT 10000000000
#define SIZE 100000
int main(int argc, char **argv)
{
uint64_t vs[SIZE];
uint8_t buf[SIZE*5];
srand(0);
for (int i = 0; i < SIZE*5; i += 1) {
buf[i] = (uint8_t)rand();
}
// 測定開始
clock_t start_clock, end_clock;
start_clock = clock();
for (size_t i = 0; i < COUNT/SIZE; i++) {
for (size_t idx = 0; idx < SIZE; idx += 1) {
vs[idx] = *(uint64_t*)(buf + idx * 5) & 0xFFFFFFFFFF;
}
}
end_clock = clock();
// 測定終了
printf("%f sec\n", (double)(end_clock - start_clock) / CLOCKS_PER_SEC);
printf("%ld\n", vs[0]);
uint64_t total = 0;
for (size_t i = 0; i < SIZE; i += 1) {
total += vs[i];
}
printf("%ld\n", total);
return 0;
}
Overwriting main.c
!clang -Ofast main.c
!./a.out
5.527128 sec
349828662887
54993386919705396
Goの最速が12秒、Rustが6.4秒ですから、Cが一番速くなりました。
結論
整数を5バイトに押し込む簡単なお仕事に関してはCとRustは同程度、Goは約半分の速度。






コメント