
背景(誰のための記事?)
JavaScriptプログラマのみなさまこんにちは。
最近のお仕事の傾向として、マイクロサービス化といいいますか、オブジェクト指向の延長といいますか、MVVM化といいますか、下回りは速度&効率重視でC++で構築し、中間は保守(メンテ)&書きやすさ+ちょっぴり速度も重視で node.js JavaScript、上位のUIはなるべく広範囲で使えるように考慮して HTML+CSS 、という3層構造
・上層:HTML + CSS
・中層:JavaScript
・下層:C++
が流行っていまして、今回の事件は中層の node.js スクリプトの部分で発生した問題でした。しかも、下層で生成された巨大なデータを中層で処理し、上層で表示しようとするとある条件で遅延が発生し、表示がカクつくという問題で、その「ある条件」が長期間に渡って特定できない、、、といった難問でした。いや、もうホントに大変でした。
最終的には、中層の JavaScript 内で計算していた「ヒストグラムの算出コードがピンポイントでバグっていた」ってことで決着したのですが、これ↓が該当する JavaScript コードなんですが、どこにバグがあるかわかりますか?
わからない人、あなたが対象の読者です。
const histogram256 = Array(256).fill(0)
for ( const u16 of uint16_array )
{
histogram256[ parseInt( u16 / 256 ) ] ++
}
やっていることは、単純に、Uint16 (0~65535) のデータ頻度を 256 段階のヒストグラム表でカウントしているだけなんですけどね😋。
本題: parseInt() の罠、しかも2つ!!
JavaScript で実数を整数に変換したいシチュエーションは割と頻繁にあります。他の言語にある、いわゆる型変換(キャスト)に近い使い方です。
JavaScript には、実数を整数に変換するやりかたはいくつか用意されていて「どれを選ぶのがよいか」普通に悩みます。「悩むくらいなら、速度とコードの読みやすさを優先すればいい」と思い、速度的にも、記述的にも、問題のなさそうな(無難そうな) parseInt() を選択したのですが、ハマった。見事にハマった。しかも、2パターン!!もう使わない💢
さて、実数の整数化(小数点以下切り捨て)でよく見かけるこのコード。
const i = parseInt( r ) // 小数以下切り捨て
ここに問題があります。しかも2つも!!
・1, 変換速度の問題
・2, 期待通りに変換されない問題
罠1,変換速度の問題
いろいろ調査していくと、parseInt() には「ある条件」で時間がかかっていることがわかりました。その「ある条件」ってのが曲者で、普通に計測してもわからないのです。
その「ある条件」がわかるよう書いた計測コードがこちらです。
0.0 ~ 5.0 をループの回数(百万)で分割して、実数から整数に変換しています。
const { performance } = require('perf_hooks');
const p = (...a) => console.log( ...a )
const loop = 1000000 // 百万回
const m = 5 // 0.0 ~ 5.0 まで
const time = _f =>
{
const tm = Array(m).fill(0.0)
for ( const k of Array(loop).keys() )
{
const v = k / loop * m // 0.0 ~ 5.0 を生成
const s = performance.now()
const i = _f( v )
const e = performance.now()
tm[i] += ( e - s )
}
p( tm, 'ms.' ) // 測定結果を表示
}
//---------------------------------------------------
p( 'JavaScript parseInt() と Math.floor() のその速度比較' )
p( '--------' )
p( 'parseInt( v ) の速度を計測' )
time( v => parseInt( v ) )
p( '--------' )
p( 'Math.floor( v ) の速度を計測' )
time( v => Math.floor( v ) )
p( '--------' )
p( 'Math.trunc( v ) の速度を計測' )
time( v => Math.trunc( v ) )
p( '--------' )
p( 'v | 0 の速度を計測' )
time( v => v | 0 )
p( '--------' )
p( '結論 -> parseInt は 0付近のみ異常に遅い')
p( process.versions ) // node.js の version を表示
手元の PC での動作結果。
> node a.js
JavaScript parseInt() と Math.floor() のその速度比較
--------
parseInt( v ) の速度を計測
[
58.30886514484882,
9.344345089048147,
8.635206025093794,
8.61915310844779,
8.612711075693369
] ms.
--------
Math.floor( v ) の速度を計測
[
12.951601061969995,
9.484790936112404,
8.923886973410845,
8.971577974036336,
11.075583156198263
] ms.
--------
Math.trunc( v ) の速度を計測
[
9.280376160517335,
8.596518969163299,
10.931750077754259,
9.853166952729225,
8.850848948583007
] ms.
--------
v | 0 の速度を計測
[
9.219559032469988,
8.488848010078073,
10.57026295363903,
8.928800100460649,
9.20000709220767
] ms.
--------
結論 -> parseInt は 0付近のみ異常に遅い
{
node: '12.18.3',
v8: '7.8.279.23-node.39',
uv: '1.38.0',
zlib: '1.2.11',
brotli: '1.0.7',
ares: '1.16.0',
modules: '72',
nghttp2: '1.41.0',
napi: '6',
llhttp: '2.0.4',
http_parser: '2.9.3',
openssl: '1.1.1g',
cldr: '37.0',
icu: '67.1',
tz: '2019c',
unicode: '13.0'
}
>
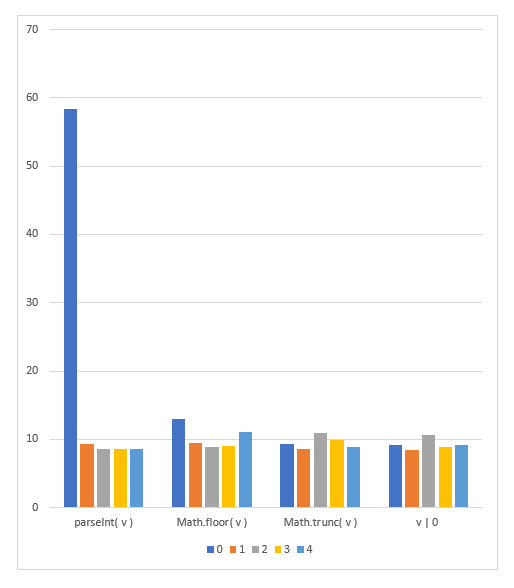
グラフにすると parseInt() の '0' のみ突出して遅いのがよくわかります。やく5倍の違いがあります。
最初のヒストグラムのコードで言うと、'0' 付近、すなわち、なにも入っていない配列データを入れると5倍遅くなります。例えば、データが入っていれば1秒間隔でヒストグラムが表示されていたのに、ゼロばかりのデータのときは5秒間隔になる!という💢
ちなみに、むりやり論理演算 v | 0 に突っ込んで整数化の高速化を試みてもぜんぜん早くないし、意図がわかりにくい、バグの元だし、メンテ不可になるのだけなのでまったくオススメしません。
'0'付近のみ遅い理由(推測)
そもそも、parseInt() は「文字列」を整数に変換する関数です。ですので、「実数」など文字列以外の値を渡した場合は「文字列に変換されてから」parseInt() に渡り、その後、整数に変換されます。ここが最初に注意するポイントでした。
そして、parseInt() は '0x' で始まる16進数の文字列の変換をサポートしています。'0'で始まる文字列の場合のみ16進数への変換が可能かどうか、その切り分け処理に時間がかかるのではないかと推測しています。
罠2,期待通りに変換されない問題
上の問題に盛大にハマりましたが、深刻度としてはこっちのほうが大きい(凶悪である)と思います。
まずは以下を見てください。Chrome DevTool の Console での動作確認時のキャプチャです。
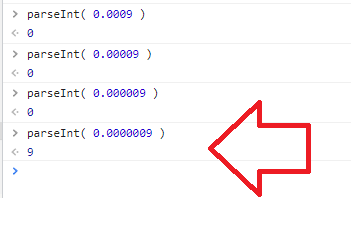
「9!!!!」
この動き。これはみなさんの期待通りに変換されていると言えますか?この動きで大丈夫ですか?
このバグにしか見えない parseInt() の動きですが「仕様の通り」のようです。
「どんな仕様だよ!!💢」と言う前に、先程も書きましたが、parseInt() は「文字列を整数に変換する関数」です。
ではどのような文字列がparseInt() に渡っているのか確認してみましょう。
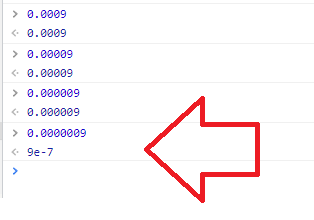
😱
おわかりでしょうか。'e'表記になっています。e表記はparseInt()のサポート外なのです。
結論 Math.floor() を使え
「実数」を整数に変換したいのなら Math.floor() or Math.trunc() を使うこと。
parseInt() は「文字列を」整数に変換したいときのみ使うこと。
以上です。
それではみなさま、引き続きプログラミングライフをお楽しみください。
参考

追記
node.js のバージョンが古かったので、2022-01-06 時点での最新 node.js 16.13.1 で再計測してみましたが、結果に大きな違いはありませんでした。










コメント @yamazaki3104
@yamazaki3104リンクをコピー このコメントを報告 0 サービス利用規約に基づき、このコメントは削除されました。 サービス利用規約に基づき、このコメントは削除されました。 サービス利用規約に基づき、このコメントは削除されました。  @fujitanozomu
@fujitanozomuリンクをコピー このコメントを報告
[Wandbox]三へ( へ՞ਊ ՞)へ ハッハッ https://wandbox.org
[Wandbox]三へ( へ՞ਊ ՞)へ ハッハッ https://wandbox.org
0  @fujitanozomu
@fujitanozomuリンクをコピー このコメントを報告
実行結果
0  @fujitanozomu
@fujitanozomuリンクをコピー このコメントを報告
実行結果
[Wandbox]三へ( へ՞ਊ ՞)へ ハッハッ https://wandbox.org
0  @error_401
@error_401リンクをコピー このコメントを報告 11  @fujitanozomu
@fujitanozomuリンクをコピー このコメントを報告 2  @MYAO
@MYAOリンクをコピー このコメントを報告 2  @fujitanozomu
@fujitanozomuリンクをコピー このコメントを報告 0  @error_401
@error_401リンクをコピー このコメントを報告 0  @fujitanozomu
@fujitanozomuリンクをコピー このコメントを報告 - JITコンパイラによって生成された機械語からparseInt()に相当する関数が呼ばれる
- parseInt()が機械語に展開される
- 簡単なところは機械語に展開され、面倒なところは下請けの関数を呼ぶ
- 条件によりparseInt()に相当する関数が呼ばれることもあれば機械語に展開されることもある
- インタプリタで実行し得られた統計情報により最適なコード生成を行う
- 処理内容を確認して条件分岐の組み合わせ等与える条件を複数用意する
- 処理時間を計測してくれるプロファイリングツール等を使用して遅くなる条件を特定する
0  @chuntaro
@chuntaroリンクをコピー このコメントを報告 0  @fujitanozomu
@fujitanozomu(編集済み) リンクをコピー このコメントを報告 0
@yoshi389111 ご指摘!ありがとうございました!
typo? by yoshi389111 2022/01/07 12:56
記事の計測コードをWandboxでNode.js 14.0.0を使用して実行してみたところでは
こんな結果でした。
計測コードの
↑の部分を
に変更し、予め文字列にしてから
parseInt()に渡すようしてみたところこんな感じで満遍なく遅くなりました。
「'0'で始まる文字列の場合のみ16進数への変換が可能かどうか、その切り分け処理に時間がかかるのではないか」の説に従えば文字列に変換して
parseInt()を呼んだ場合でも'0'付近では遅くなりそうですがそうはならなかったということです。parseInt()に数値を渡して内部で文字列化されるのと、数値を文字列化してparseInt()を呼ぶのとではコストは大して違いがなさそうな気がしますが、1.0以上の値ではparseInt()に数値を渡した場合の方が明らかにコストが小さいので、parseInt()の内部で1.0以上の数値が渡された場合には文字列化しないで整数化するような実装になってるのではないかと思いました。計測コードの
と
をそれぞれ
と
に変更して計測したところ
という結果となりました。
https://wandbox.org/permlink/tKl0ML6IrtN6bj5n
32bit整数の最大値を超えると(?)文字列化をサボらなくなるのか遅くなるみたいです。
.toFixed(100)でもしときゃ多分大丈夫さHAHAHA!
※ すげえ効率悪いのでオススメしません
誰も書かないのでコメントします。
実数から整数への変換に parseInt() を使ってはいけない理由は、parseInt()は実数から整数に変換するのが目的の関数ではないからです。
parseInt()は文字列を引数に取り、その機能は関数名が表している通り、引数の文字列をparseしてintに変換するための関数です。
目的に合った関数を使うのは可読性を上げるににも重要で、parseInt()のことを知っている人がparseInt(x)というコードを見ると、「ああ、ここは文字列処理中でありxは文字列なんだろうな」と想像します。その想像を裏切るコードは良くありません。
ここからちょっと辛口になりますが、参考リンクに上げているページの内容くらい読んでから記事を書きましょう。
あなたの「推測」も使ってはいけないケースも全部MDNのページにかかれています。
それから、0の場合になぜそんなに遅いのか具体的理由を知りたいなら、nodejsやv8のコードを読めば載ってます。あれこれ試して推測する必要はありません。
JITコンパイルする処理系についてコードを読めば載ってますは本気で言ってるのか判断に困るな。
パフォーマンスチューニングが本題だと思うので、少々脇道に逸れたコメントになりますが、誰も突っ込まないので気になったのでコメントします。
そもそもJSなので、数値は(BigInt除くと)倍精度浮動小数点数なので、型変換を考えるという認識は変だと思います。
あと、さらに脇道にそれますが、実数という表現が本文でもコメントでもありますが、個別の実数とたまたま一致することや、ある種のメンタルモデルを指していることは分かりますが、この記事のようなプログラミング言語の仕様についての誤謬による失敗を避けるためにも浮動小数点数を扱っているということを意識する方が良いかと思います。
話を戻して、小数点以下に0でない値を持つ数から整数への所謂丸め操作は、複数考えられるので、その辺りのことを考慮しても、バリエーションの無い(つまり変換前後のある種の型のみで決定される)操作を用いることは不適当であるというような気付きも、紹介されているような処理を書く時に気をつける方が良いのではないかと思います。
(ここでは結果としては、個別の関数の仕様のパフォーマンスについての話になっていたのかとは思いますが、そもそも自然な操作は各プログラミング言語制作者も最適化を施そうとしている可能性が高いことは期待されるので)
浮動小数点型を実数型と言うのは(正確ではないにしろ)歴史的に普通に行われてきたことで、浮動小数点型を表すキーワードが
realな言語も存在します。MDN Web Docsにも
とあったりするので、要はツッコむところはそこじゃないってことです。
@fujitanozomu さん
コードを読んで実行時間の見積もりをするということではなくて、実際に数倍の実行時間がかかったということがわかっているので、コードを読めばそこに書かれている処理に時間がかかっていると分かると思います。
@error_401 さん、
JITコンパイルされる処理系についてparseInt()がどのように実行されるか不明という前提では
色々な可能性は考えられると思いますが、
「そこ」とは何を指していますか? ソースを読めばすぐわかる程度の話には私には思えません。
また、「あれこれ試して推測する必要はありません」ということでしたが、この手の問題の確認は
厳密には以上のような方法を採ることになると思います。あれこれ試すことも推測することも必要で、コードを読めばわかる程度のことは私には思えないのですが、@error_401さんが本気で言ってるということは理解しました。
既にコメントに有る様に、実数→整数にするのにparseIntを使ってて最初???が浮かんだw
それと普通どの言語でも、実数→整数にするのはtruncate系を使うだろう。その方が直感的な結果になる。(JavaScriptの場合はMath.trunc)
@yamazaki3104さん、
記事中で挙げられてる
以上の 2つは使ってはいけない「理由」ではなくて誤ったparseInt()の使用により起こり得る「弊害」で、@error_401さんが挙げられているコードを読んだ人がparseInt()の引数を文字列と推定するということもまた弊害のひとつだと思います。
使ってはいけない理由は「parseInt()は文字列の引数を解析し整数値を返す処理であり、実数から整数への変換を行うものではない」辺りがまあ妥当なところではないかと思いますがいかがでしょうか。