
はじめに
前回までにAttentionを整理したので、論文「Attention Is All You Need」=Transformerに挑戦しようと思います。ベクトル(行列)、コーディングレベルでの整理はできていません( ;∀;)
本文中では「Attention Is All You Need」で説明しているモデルをTransformerと記載します。Attentionが分かる前提で記載しておりますので、Attentionを知りたい方は過去分を読んでいただけると嬉しいです。
過去分
過去分はコチラ↓
①【Source Target Attention】
「Attentionを理解するためにRNN、Word2Vec、LSTM、Seq2Seq、Attentionの順に整理してみた」
https://qiita.com/ta2bonn/items/c645ecbcf9dabd0c4778
②【Self Attention】
「Self-Attention(+MultiHead)を図・ベクトル(行列)の両方で整理してみた。 」
https://qiita.com/ta2bonn/items/60601d18db57bd98d142
参考元
論文「Attention Is All You Need」
https://arxiv.org/pdf/1706.03762.pdf
Qiita「計算量オーダーについて」
https://qiita.com/asksaito/items/59e0d48408f1eab081b5
概略
過去のRNN、Encoder・Decoderモデル(過去分①参照)は、単語を逐次的に処理するため並列処理ができず、計算量が膨大になっていました。計算量を押さえようとすると(例:RNN⇒CNNにする)、長文の単語依存関係を捉える事が難しくなるという課題があり、その課題を解決するために登場したのがTransformer。
Self Attentionを使うことで計算量を抑え(※)、かつ長文の単語依存関係も表現する事が可能になりました。
(※)今までの時間計算量O(N)またはO(logN) ⇒ O(1)に短縮
ちょっと寄り道(時間計算量「O」)
よく混乱してしまうので、ここで整理しておきます。備忘的な位置づけなので飛ばしてもらって問題ございません。整理にあたり、Qiita「計算量オーダーについて」https://qiita.com/asksaito/items/59e0d48408f1eab081b5 をめちゃくちゃ参考にさせていただきました。
説明
時間計算量を表す記票方法をO記法という。O記法とは特定のアルゴリズムでの計算が、どれくらい掛かるかを表した記号であり、処理時間が短い順(性能が良い順)に以下のとおり。

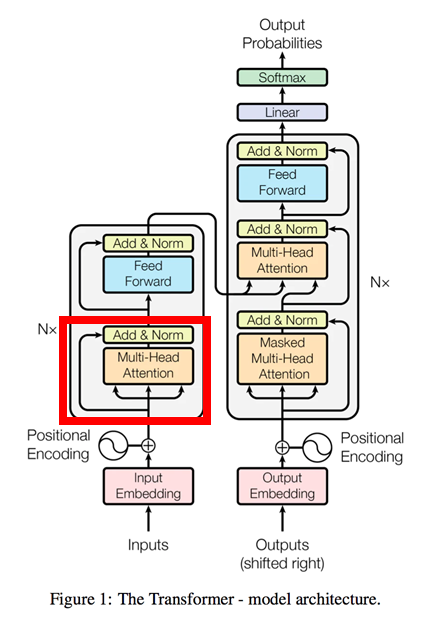
Transformer全体構成
以下のとおりです。これを順番に見ていきます。
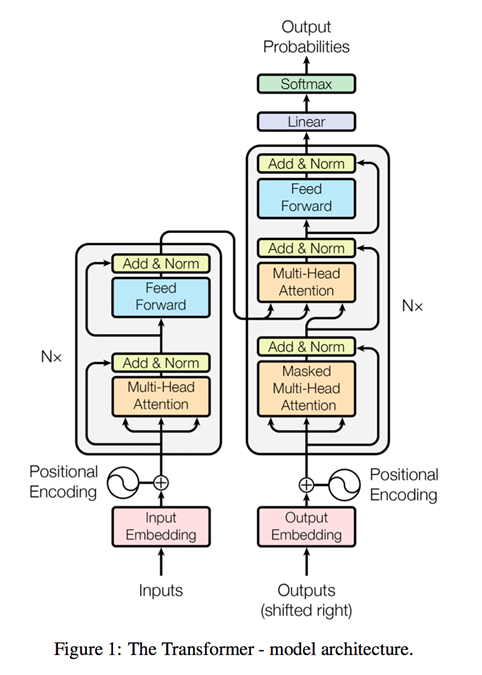
【ポイント】
Transformerのポイントは以下の4点だと思っています。複雑なので読みほどく中で説明していきます。
① 全体構成はEncoder-Decoderモデル(左がEncoder、右がDecoder)
② Positional_Encodingによる文章の順序把握
③ 3種類の縮小付Attention(※)を活用
全体構成:Source-Target_Attention
Encoder:Self_Attention
Decoder:Masked-Self_Attention
(※)縮小付Attentionについては後述します。
④ Encoder、Decoder共に6層構造
Encoder(左側の部分)
1.Positional_Encoding(位置エンコード)
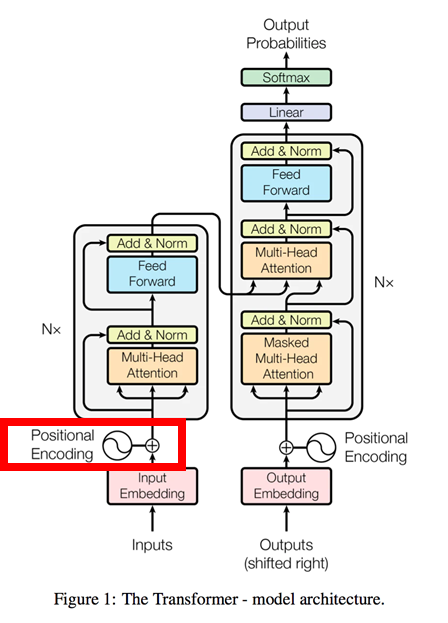
Attentionは単語の順番(位置関係)を認識できないので、文章の意味(文脈)を正確に解釈できないという問題があります。よって、TransformerではPositional_Encoding(位置エンコード)を使用する事でこの問題を解決しています。
仕組みは、単語の分散表現(Input Embedding)に単語の位置情報(一意の値)を加算するというもの。
Transformerは、この単語の位置情報(一意の値)にsin関数とcos関数を使っており、このsinとcosの波形を学習する事で単語の位置関係を把握しています。論文中の数式は以下のとおりですが、難しいので「位置エンコードの考え方」でもう少し詳しく書きます。
<式> pos:位置、 i :次元
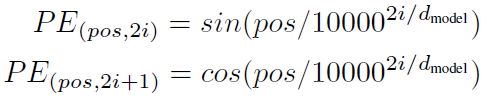
位置エンコードの考え方
以下を参考にさせていただきました。
■位置エンコーディングについて
https://scrapbox.io/nishio/%E4%BD%8D%E7%BD%AE%E3%82%A8%E3%83%B3%E3%82%B3%E3%83%BC%E3%83%87%E3%82%A3%E3%83%B3%E3%82%B0
■ベクトルの回転
https://www.buildinsider.net/small/bookkinectv2/0803
上記を元に整理します。
位置エンコードを表現する際にsin、cosを使用することで、位置表現を「回転行列」で表すことができ、異なる回転周期をいくつも入れることで単語間の曖昧さを許容できるようになるとのこと。参考元を引用させていただき、2次元で整理します。
① まず下のようなベクトルvがあるとします。
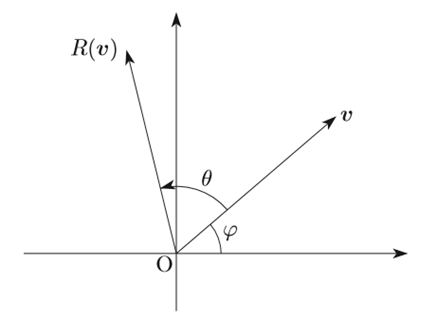
② vをcos、sinで表現すると

③ このvをθだけ回転(1行目のφ ⇒ φ+θ)させるとベクトルR(v)は三角関数の加法定理から以下のとおり(2行目の変換)。
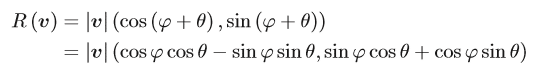

④ これを行列で表現すると
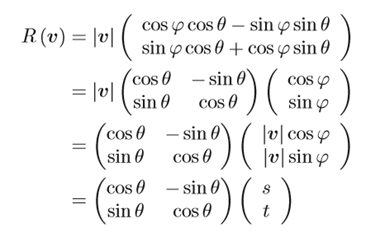
⑤ よってvをθだけ回転させた行列R(v)(=求めるべき(学習するべき)行列)は以下のとおりとなる。

⑥ 最後にこのベクトルを位置情報としてInput_Embeddingに加算する。
⇒concatではなく加算で上手くいくらしい。
2.Multi-Head_Attention(Self_Attention)
やりたい事
input文章に対する単語間の依存関係をSelf_Attentionで表現させ、単語の位置情報を含めて正規化する。
詳細
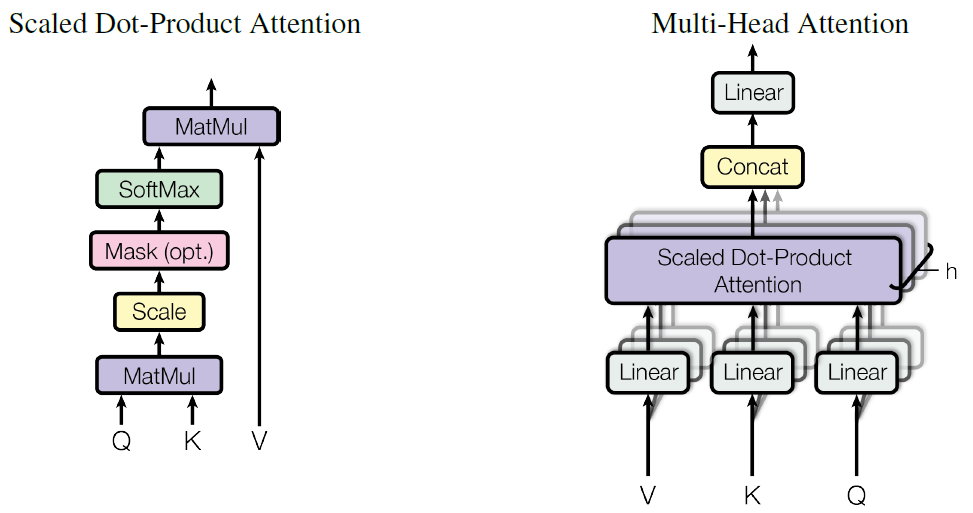
「Multi-Head Attention」の仕組みは前回(過去分の②【Self Attention】)で説明しているので割愛します。Transformerに内臓するSelf-Attentionを論文では「Scaled Dot-Product Attention」=縮小付内積Attention と呼称しています。
Scaled Dot-Product Attentionは、query、keyの次元をd_k、valueの次元をd_vとした時、下記の式で表される。
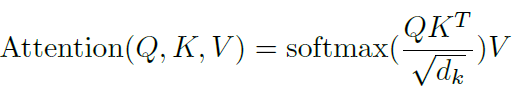
つまり、通常はqueryとkeyの内積(Attention_Weight)を計算する際、そのままの次元数で計算するが、Transformerではqueryとkeyの内積(Attention_Weight)算出時に√d_kで割る(縮小する)というもの。さらに、論文中にhead=8との記載があるので、Multi_Headのhead数を8つとしてquery,key,valueの重みを使い算出している。式は以下のとおり。重ねてになりますが、MultiHeadの詳細は「過去分の②【Self Attention】」を参照いただければと思います。

Add & Norm
TransformerのNormalizationは「Layer Normalization」を使用しており、inputの1文単位に正規化している(1文が100単語の場合、100単語で正規化)。Positional_Encodingの結果を『E』、Multi-Head_Attentionを『M』とするとLayer Normalization『L』は以下のとおり。
L= Layer Normalization(E+M)
3.Feed_Forward

Feed_ForwardはPosition-wise 順伝播ネットワーク。
Position-wiseの意味は「単語毎にニューラルネットワークがある」という意味で、ニューラルネットワーク内では他単語との干渉はありません。ただし、計算に使用する「重み」は全単語共通のものを使用しています。なお、2層のニューラルネットワークになっていて、活性化関数はReLUを使用しています。式は以下のとおり。
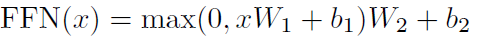
Add & Norm
Feed_Forwardを『F』とすると、Feed後のLayer Normalization『FL』は以下のとおり。
FL= Layer Normalization(L+F)
Decoder(右側の部分)
4.Positional_Encoding(位置エンコード)

Encoderと同様なので説明を割愛します。
5.Masked Multi-Head_Attention(Self_Attention)
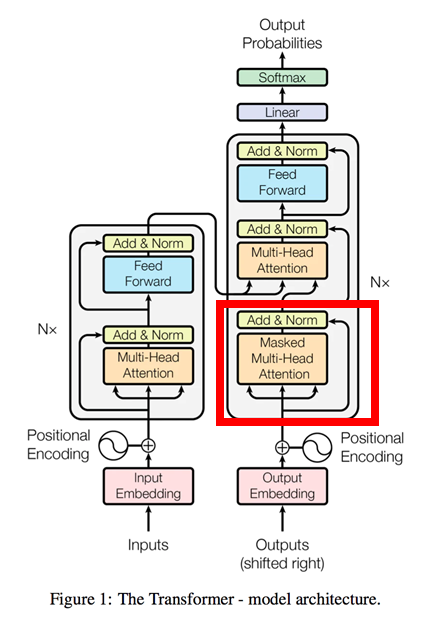
通常のMulti-Head_Attentionと基本的には同じ。ただし、decoderでは学習のカンニングを防ぐため、自単語より先(文章の右側)の情報をマスキングして(隠して)学習させる。
6.Multi-Head_Attention( Source Target Attention )
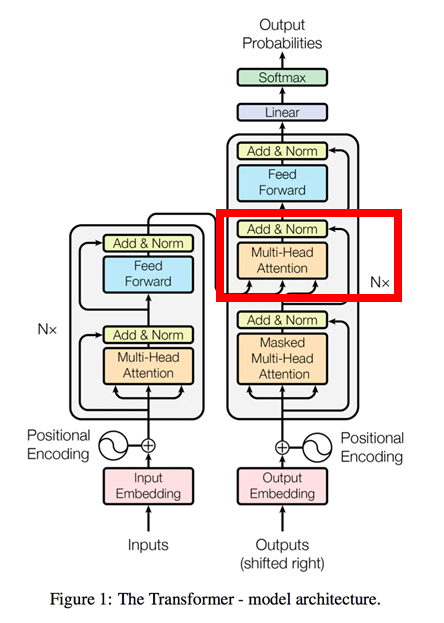
ここはSource Target Attention。t時刻の文字からt+1時刻の文字を導出。
quary ⇒ Outputs(Decoder)から入力するベクトル(行列)
key, value(memory) ⇒ Inputs(Encoder)から入力するベクトル(行列)
7.Feed_Forward
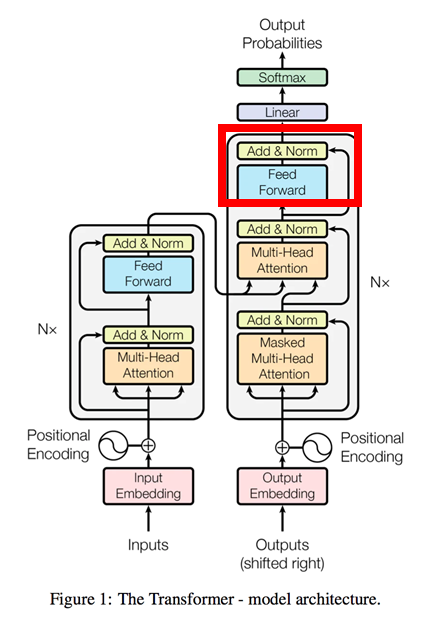
Inputs(Encoder)と同様。ただしFeedForward層のニューラルネットワークに使用する重みWは、モデルの最下段にあるEmbeddingに使用する重みと同一のものを使用します。
8.Output
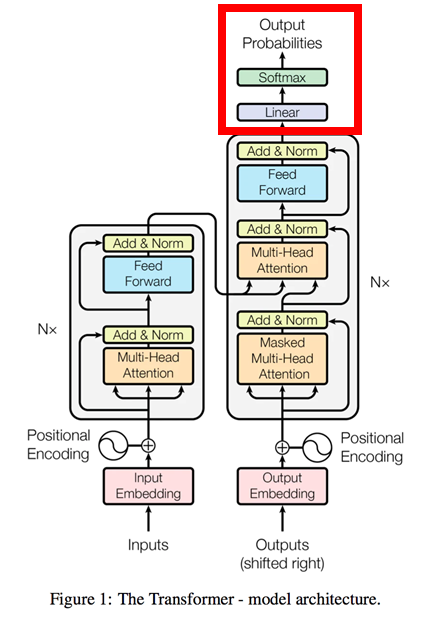
FeedForward層のニューラルネットワークから出力した単語をSoftmaxで計算し、最も確率の高い単語を出力します。原理はseq2seqと同様。
Transformer全体構成(再び)
今まで説明してきた機能を一つの流れとして、コレをEncoder、Decoder共に6層構成でやったものが真のTransformerです。
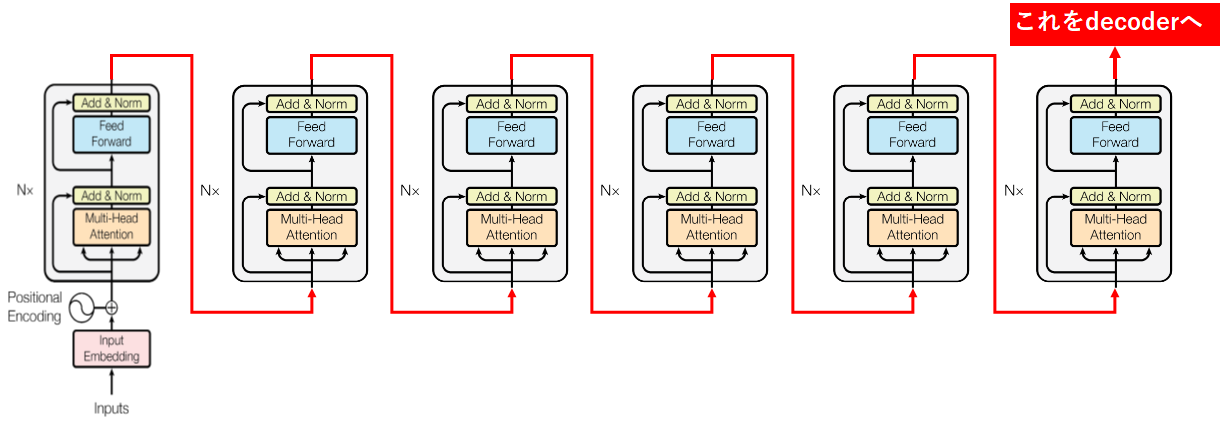
Encoderの6層構造
まずはEncoderです。
Decoderの6層構造
次にDecoderです。
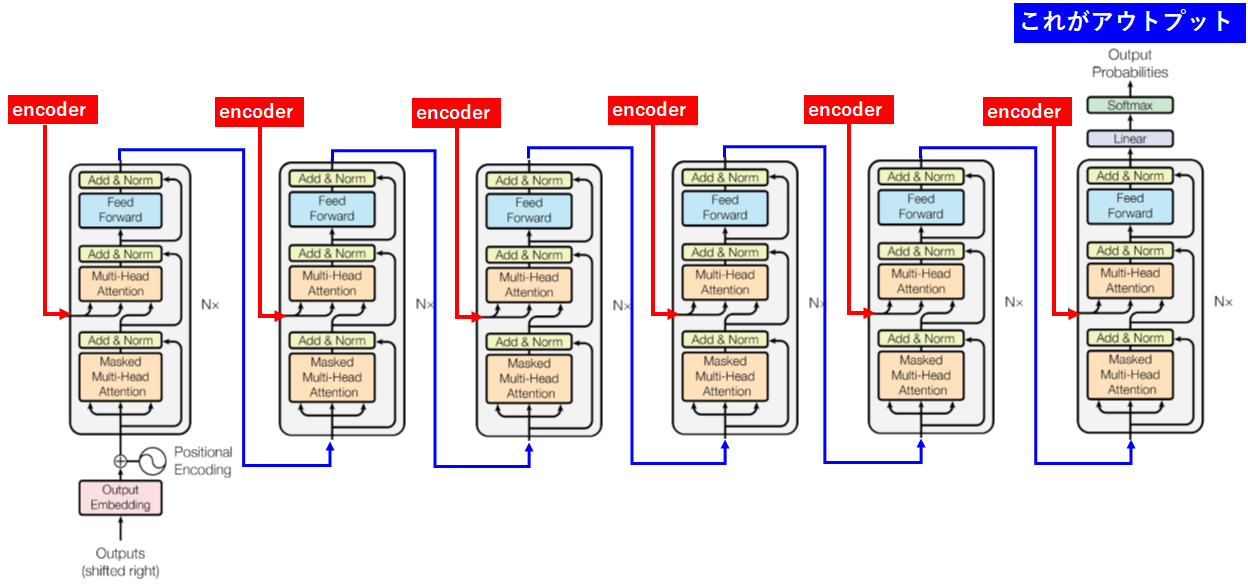
ここまで複雑にする事で、精度を向上させていると思われます。スゴイ。
次回
BERTの論文に挑戦したいなぁ。






コメント @norihitoishida
@norihitoishidaリンクをコピー このコメントを報告 0  @ta2bonn
@ta2bonnリンクをコピー このコメントを報告 0
記事ありがとうございます。「Transformer全体構成(再び)」で6層構造について、Position Encoderが入るのはEncoder1層目およびDecoder1層目の前だけだと思います。
ご指摘ありがとうございます!
おっしゃる通りですね。雑に図をつなげてしまいました。すぐに修正いたします。