
Attentionを理解するために、学習した事を整理します。
参考文献
①「深層学習による自然言語処理」 講談社 坪井祐太 海野裕也 鈴木潤 著
②「ゼロから作るDeep Learning2 自然言語処理編」 オライリー 斎藤康毅 著
■RNN(recurrent neural network)
文献①によると、再帰ニューラルネットワーク(RNN)は可変長の入力列を扱うことに優れたネットワーク構造で、前の時刻の隠れ状態ベクトルと現時刻の入力ベクトル(または下層の隠れ状態ベクトル)を使って、現在の隠れ状態ベクトルを更新するとのこと。
う~ん、分かりにくいので絵にしてみました。
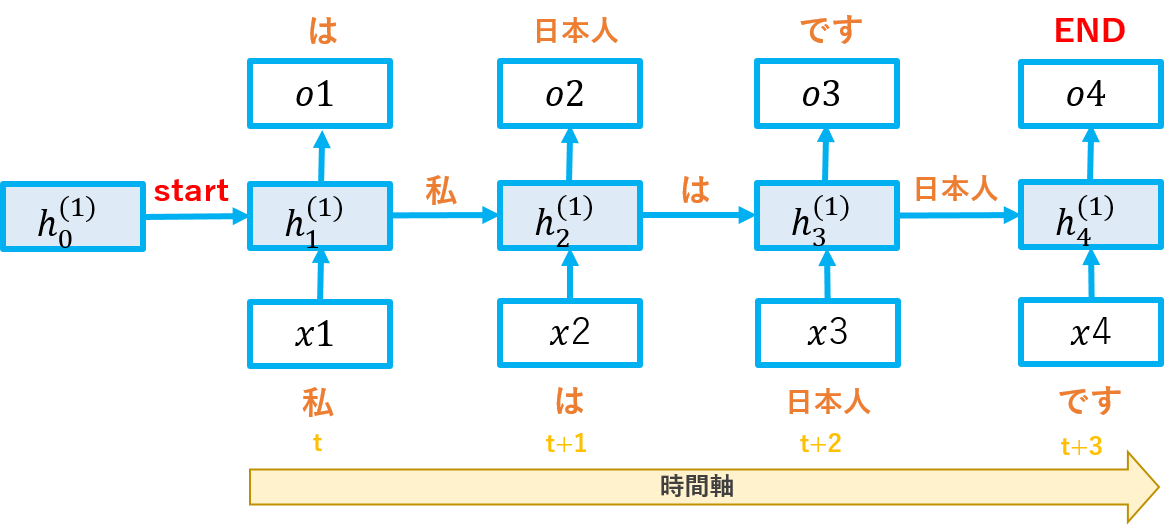
上図のxは入力、hは隠れ層です。時刻tでインプットした文字を使って、h1を更新し、h2に渡すイメージです。
イメージは何となく分かったので、RNNのレイヤをもう少し詳しく整理します(時刻tで整理)。
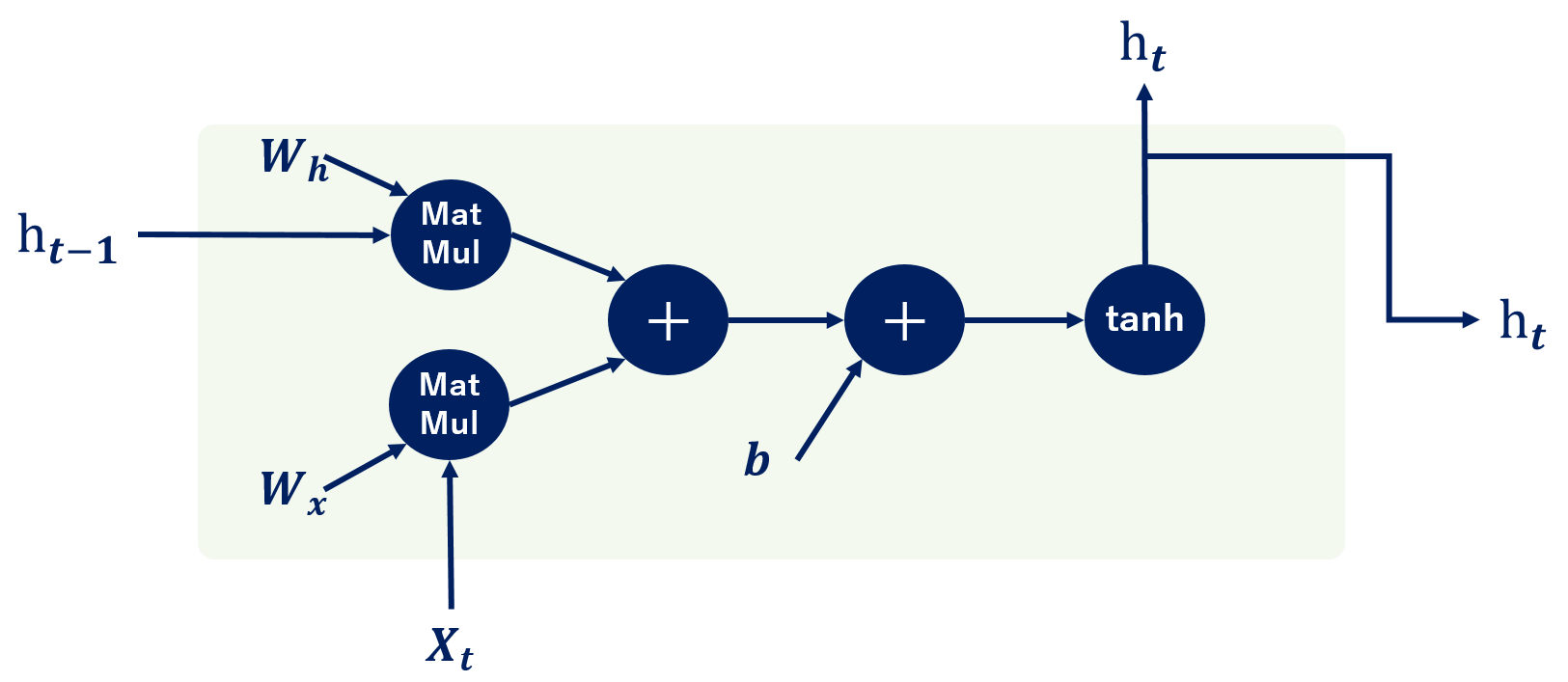
RNNでは、インプットXに対して重みW(x)を掛けた行列と、隠れ層h(t-1)に対して重みW(h)を掛けた行列を足しあわせ、さらにバイアス(b)を足し込み、ハイパボリックタンジェント(tanh)を使用して-1~1の範囲の数字に変換します。これを次時刻のインプットとして活用します。
要は上図のレイヤを繋ぎ合わせて、W(x)、W(h)をイイ感じに学習させることで、文脈を理解させようってことだと思っています。
RNNの課題
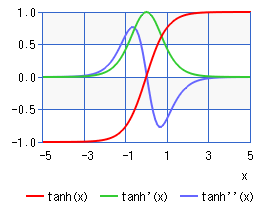
①tanhの微分は1-𝒚^𝟐であり下図の緑の線になります。
よって、値が0~1の値になり時間軸が長い学習だと0.xxの掛け算を繰り返すので、勾配が消失します。
※Reluに置き換えると勾配消失を抑えることが可能なので、もはや課題ではないのかもしれません。
論文「Improving performance of recurrent neural with relu nonlinearity」で性能向上を達成済。
②MatMulの逆伝搬ではdhW(h)による行列の積で勾配を計算します。これを時系列データのサイズ分繰り返しますが、この時、毎回同じ重みW(h)を使うため、重みによって勾配消失、勾配爆発が発生しちゃいます。

③分散表現を取得するために使用すると、計算コストが大きくなります。
■Word2Vec(ちょっと寄り道)
RNNの分散表現取得の課題(RNN_課題_③)を解決するために分散表現の取得に特化したモデルがWord2Vec。Word2Vecは総称で正確にはskip-gramとCBOWの2種類の技術を指します。
ということで両者がどうやって分散表現を獲得しているか整理します。
skip-gram
まず、学習の仕組みはニューラルネットと全く同じなので省略するとして、考え方と各層のベクトル(行列)状態を整理します。
skip-gramは、文章中の1単語から前後の単語を予測するように学習する仕組みです。↓に全体像を記載します(転置等は無視して書きます)。

コーパスを「you say goodbye and I hello .」とします。
◎入力層
「say」を入力層(インプット)とした時、重みW(in)を掛け合わせて中間層に渡します。W(in)の列数(次元数)はハイパーパラメータです。いきなり言ってしまうとこのW(in)が分散表現になります。
◎中間層
図は1層にしてあります。ここで出力層に出すための重みW(out)を掛け合わせ「say」の前後の文字として2個のベクトルを出力します。
◎出力層
中間層から受け取った情報を元に、softmaxで正規化し正解データを突き合わせます。
⇒この結果の誤差を最小にするようW(in),W(out)を学習し、W(in)を分散表現として獲得します。
CBOW
skip-gramと同様、学習の仕組みはニューラルネットです。CBOWは文章中の2つの単語から間にある単語を予測するように学習する仕組みです。↓に全体像を書きます(転置等は無視して書きます)。

◎入力層
「you」「goodbye」を入力層(インプット)とした時、重みW(in)を掛け合わせて、それぞれの単語の結果を足しあわせて平均を取り、中間層に渡します(W(in)の列数(次元数)はハイパーパラメータ)。CBOWでもこのW(in)が分散表現になります。
◎中間層
skip-gram同様、図は1層にしてあります。ここでも出力層に出すための重みW(out)を掛け合わせます。CBOWでは「say」を予測文字としてベクトルを出力します。
◎出力層
中間層から受け取った情報を元に、softmaxで正規化し正解データを突き合わせます。
⇒この結果の誤差を最小にするようW(in),W(out)を学習し、W(in)を分散表現として獲得します。
分散表現の獲得について
分散表現はskip-gramの方が良いらしい。
※参考文献「ゼロから作るDeeplearning②」に以下の記載があります。
CBOWモデルは前後の単語から推察するのに対し、skip-gramは1単語から推察するため、推察の候補がCBOWより複雑で大量の問題に取り組んでいると考えられる。これによりskip-gramの方が優れた分散表現を獲得できるのではないかと考えられる。
分散表現のW(in)について
W(in)とW(out)ではW(in)の方が分散表現として適しているらしい。
※参考文献「ゼロから作るDeeplearning②」に以下の記載があります。
文献Tying Word Vectors and Word Classifiers: A Loss Framework for Language Modeling(2016)によると、Word2Vecのskip-gramモデルにおけるW(in)の分散表現としての有効性が実験によって示された。
Word2Vecの苦手な所
Word2Vecでは文脈の単語の並びを意識できないので、言語モデルとして活用できない。
(元々分散表現の獲得が目的なので、当たり前と言えば当たり前)
■LSTM(Long short-term memory)
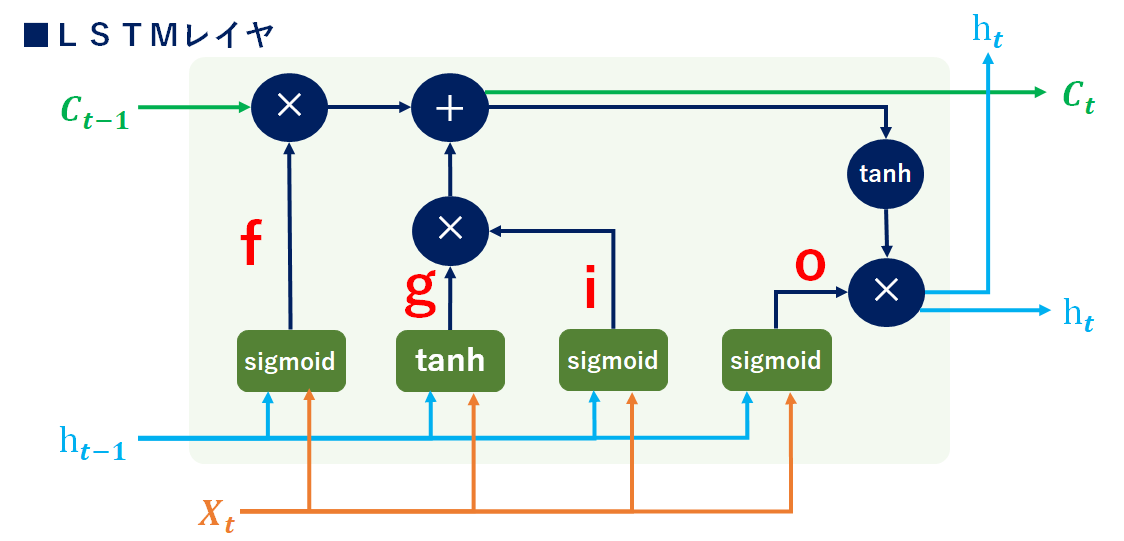
RNNの勾配消失問題を解決すべく登場したのがLSTM。LSTMは「C(t)(記憶セル)」という専用の記憶部を持ち、C(t)には過去から時刻tまでのLSTMの記憶(情報)が全て格納されていて、C(t)はLSTM内部でのみ使用しています。外部出力はh(t)のみです。では全体像を↓に書きます。
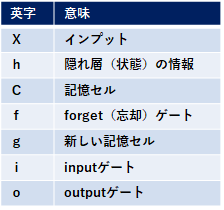
複雑なので順番に書いていきます。
LSTM_forgetゲート
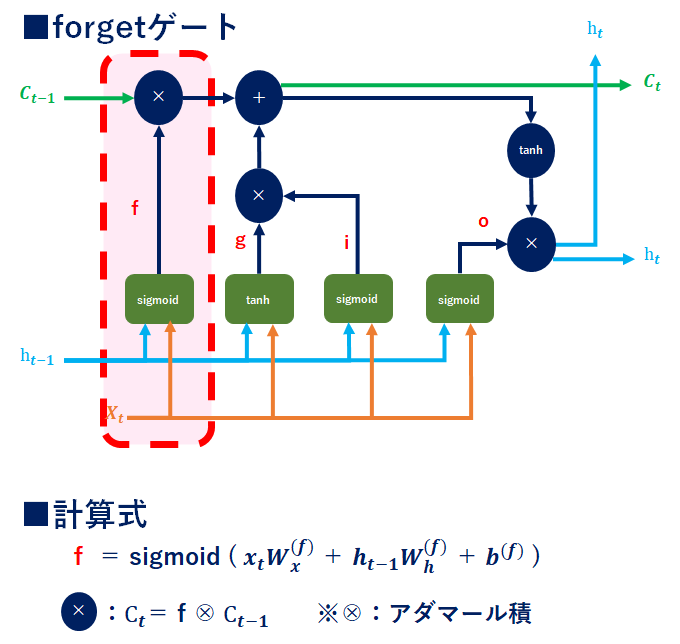
インプットX、hに対して専用の重みを付与(0~1にsigmoid化)し、前回の記憶C(𝒕−𝟏)とのアダマール積を計算することで、C(𝒕−𝟏)の残すべき情報と忘れるべき情報を分けます(0に近い程忘れることになる)。
【補足】
〇tanh
tanhの出力は-1.0~1.0で、この数値には何らかのエンコードされた「情報」に対する強弱(度合い)が表されていると解釈できます。
〇sigmoid
sigmoidの出力は0.0~1.0で、この数値はデータをどれだけ通すかの割合を表しています。
そのため、ゲートではsigmoid、実質的な情報を持つデータにはtanhを使用します。
LSTM_新しい記憶セル、Inputゲート
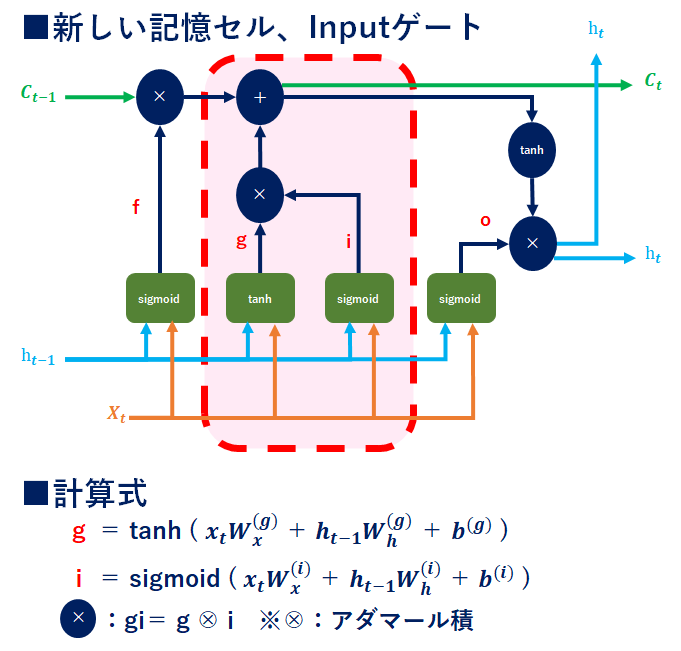
【g】
記憶セルから忘れたい情報を削除したので、次に新しい記憶を付与します。ここでもインプットX、hに専用の重みを付与し、記憶セルに追加しています。新しい情報を付与するために活性化関数は-1~1のtanhを使用します。
【i】
gで追加する情報(各要素)の価値を判断するための情報。要はInputゲートによって、重みづけを実施しています。
⇒gとiのアダマール積を取り、記憶セルに追加することで、重要度が反映されたインプット情報を記憶セルに追加できます。
LSTM_outputゲート
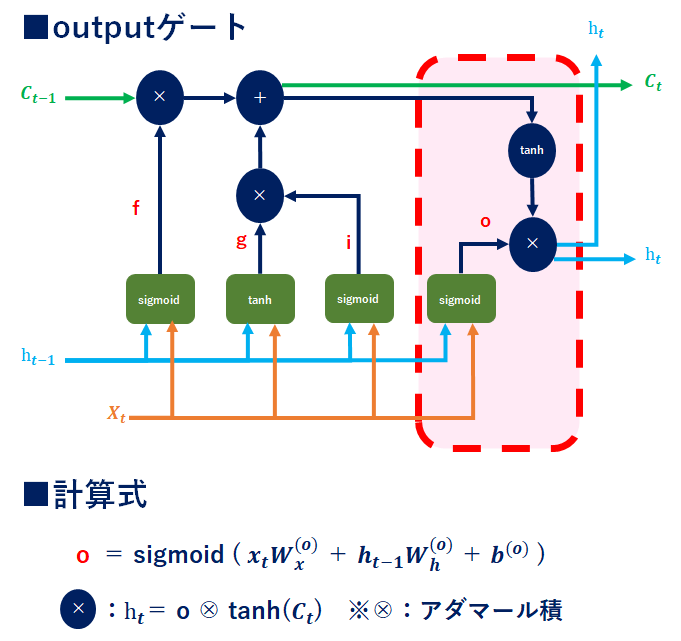
outputゲートは「C(t)(記憶情報)が次時刻の隠れ状態としてどれだけ重要か」を調整するもの。outputゲートの開き具合(=重み付け具合)で次時刻へ何%の情報を繋げるかを示しています。
■Seq2Seq
まず全体像を↓に書きます。やりたい事は日本語を英語に翻訳する事だと思ってください。
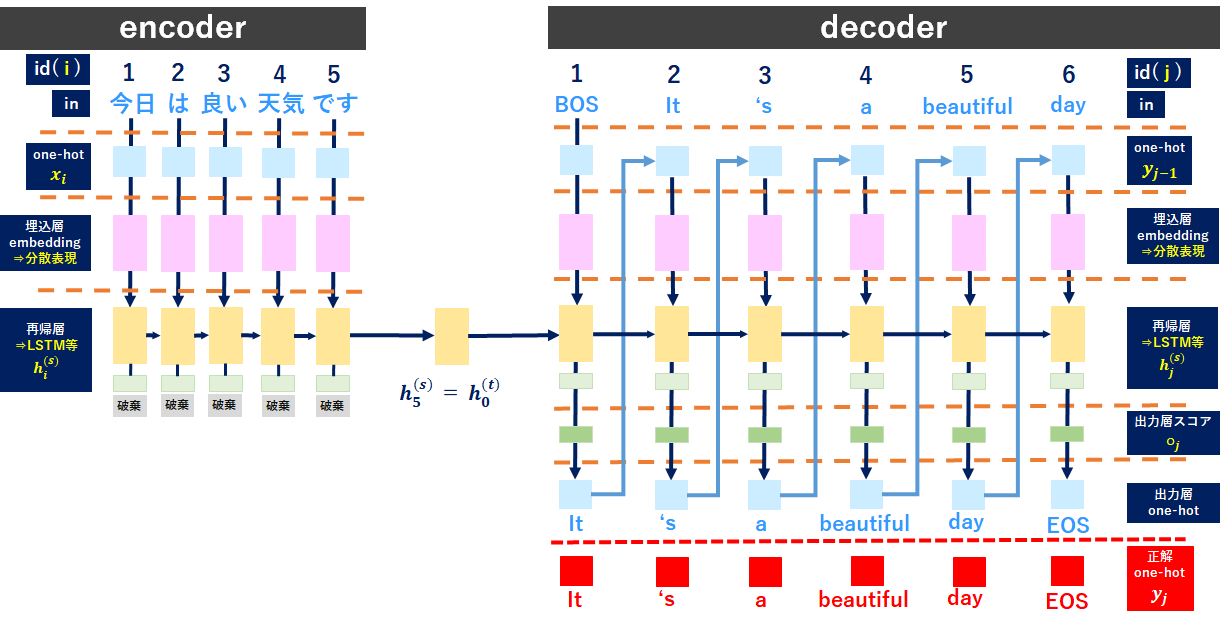
処理の順序ですが、ざっくりこんな感じです。
①「encoder」で文章を学習する。
⇒文章はone-hotベクトル化
⇒分散表現化
⇒LSTM等で学習
②上記①をdecoderに繋げる
③「BOS」をdecoderに読み込ませる(上記①と同様に学習)。
④予測文字を次のインプットとする。
⑤正解単語と予測単語で損失を計算する。
⑥上記④、⑤を繰り返して、トータル損失を小さくするよう学習する。
順番に整理していきます。
Seq2Seq_encoder
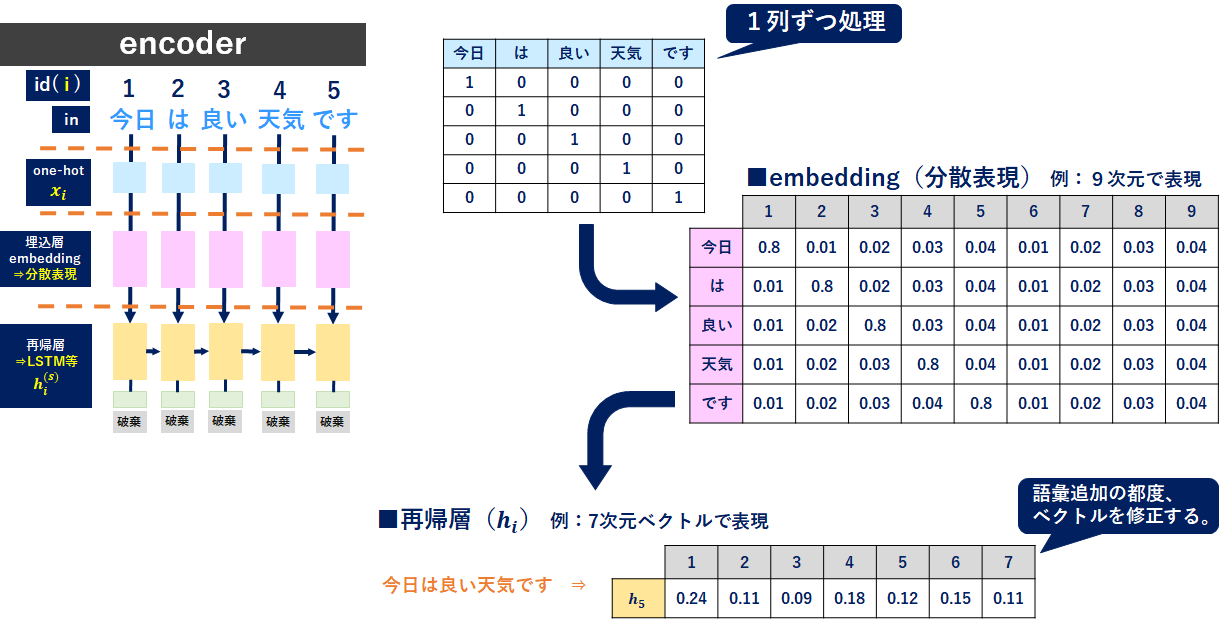
まずencoderのインプット文章をone-hot表現にします(水色)。次に分散表現を獲得(ピンク色)し、再帰層(LSTM等)で学習します(黄色)。この再帰層の最後の時刻(図では5列目の黄色)で「今日は良い天気です」の文字をイイ感じにベクトル表現できているはずです。これを使って英語に翻訳していきます。
Seq2Seq_decoder

再帰層まではencoderと基本的には同じですが、decoderの再帰層ではインプットに予測文字(最初はBOS)とencoderの隠れ状態ベクトルを使用することで、文脈を理解した上で翻訳を行うようにしています。
出力層にも専用の重みW(o)があるので、再帰層、出力層で学習しながら精度を高めていくイメージです。
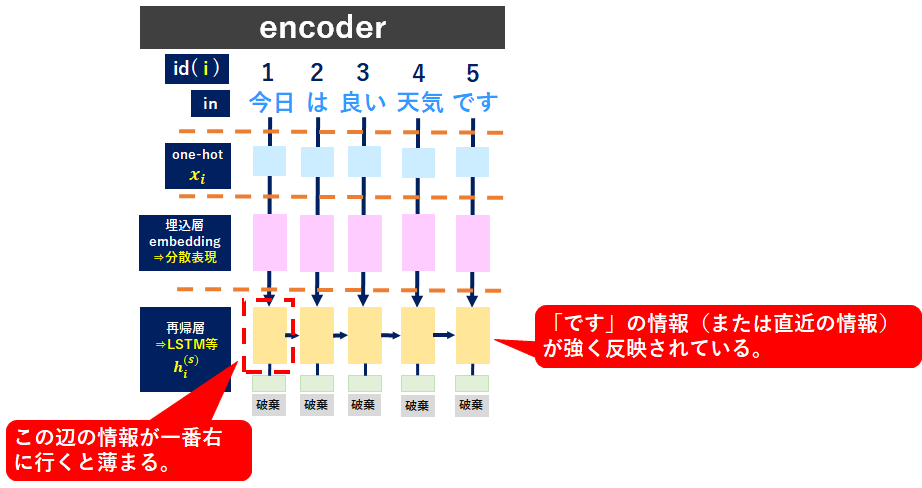
Seq2Seq_課題
decoderに連動する再帰層の出力情報は常に一定(固定)のベクトルになります。短文、長文に関わらず固定のベクトルを使用すると、長文では全ての文字情報が格納しきれず、情報が欠落してしまう。⇒特に最初の語彙情報が薄れてしまう。
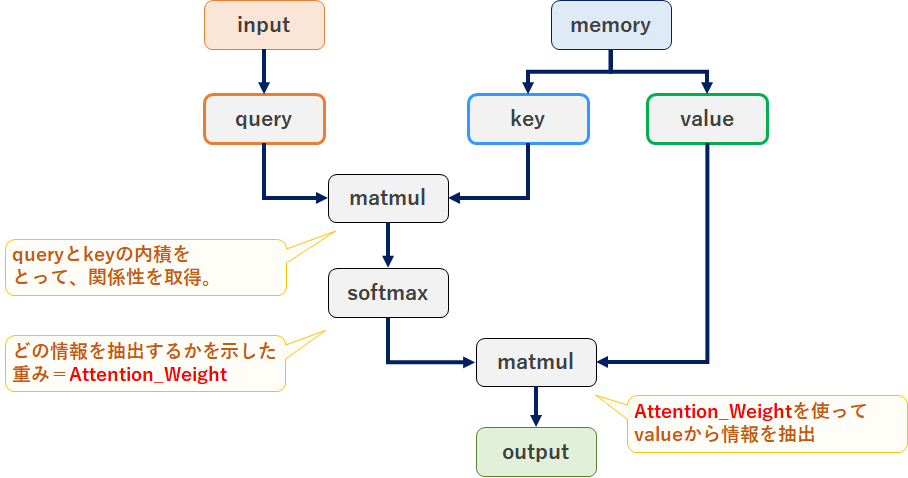
■Attention(Source Target Attention)
やっと来ましたAttention。ここではSource Target Attentionを書きますので以降「Attention」はSource Targetを示していると理解ください。まずはAttentionの概要から書きます。
Attention(source target attention)概要
Attentionではinputとなる「query」からmemoryの情報を引き抜くことで情報を取得します。具体的にはmemoryを「key」と「value」に分け、「query」と「key」で引き抜くmemory情報を決定し「value」から情報を抽出します。文章だと良く分からないのでイメージを書きます。
Attention(source target attention)をseq2seqに適用する
seqtoseqで考えると「最後の隠れ状態(h)」では最初の情報が薄いため、それぞれの語彙における隠れ状態(h)をmemoryとしてdecoderに連動することで必要な情報を必要な時に使用できるようにします。
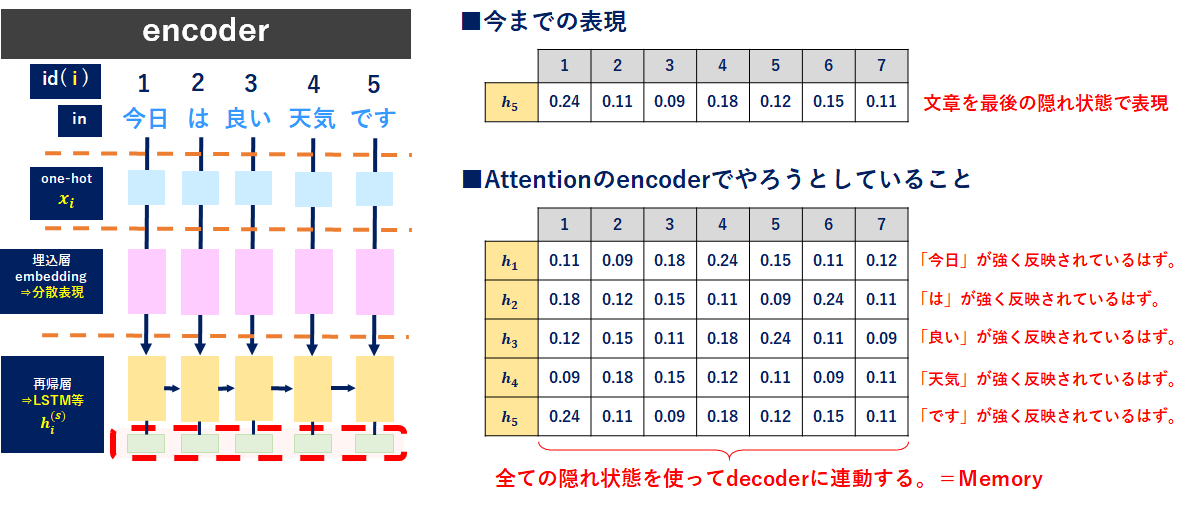
decoderを含めた全体像は↓のとおりになります。

ちょっと表現しきれなくなってきたのですが、青字の個所がAttentionです。decoderに注目して更に書きます。
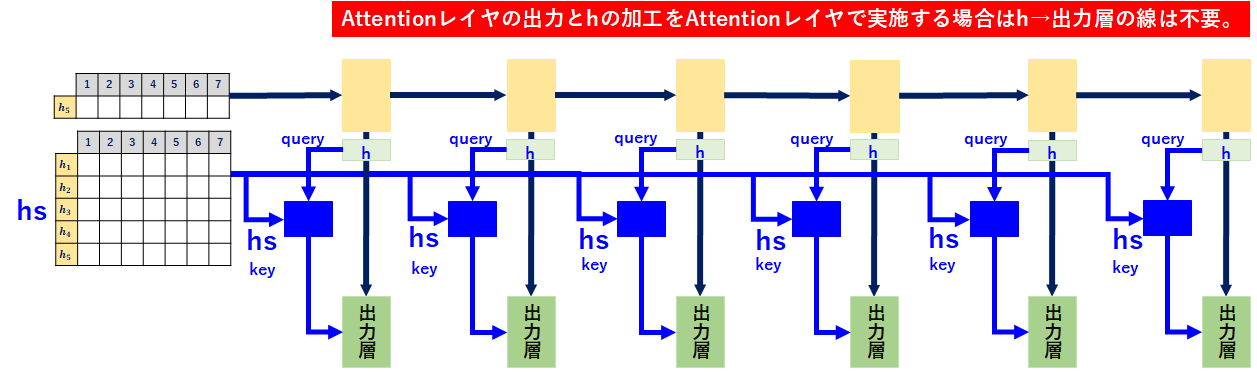
処理順序は以下のとおりです。
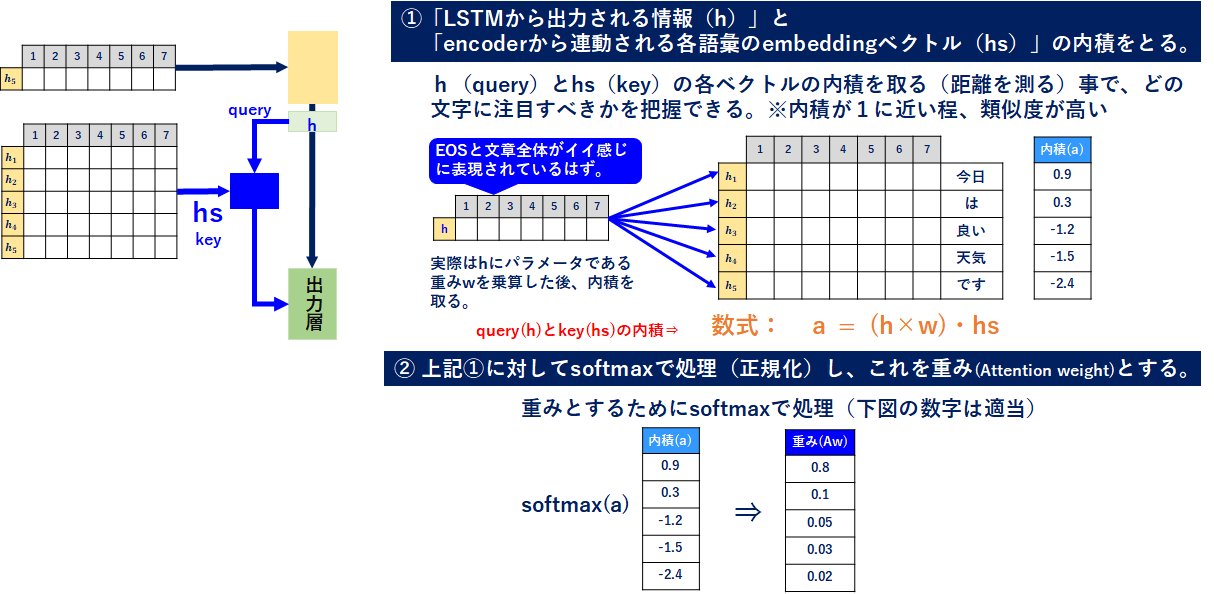
①「LSTMから出力される情報(h)=query」と「encoderから連動される各語彙のembeddingベクトル(hs)=key」の内積をとる。
②上記①に対してsoftmaxで処理(正規化)し、これを重みとする(Attention_Weight)。
③上記②と「encoderから連動される各語彙のembeddingベクトル(hs)=value」をそれぞれ掛け合わせ、情報を抽出。
④上記③のそれぞれのベクトルを足しあわせる。
⑤上記④を出力層に連動する。
文章だと分かりづらいので、これも順番に書いていきます。
まず、①と②は↓のとおりです。
【数式補足】
①に書いた数式の重みwはh(query)に掛けていますが、queryに掛けたいという意味ではないです。本来queryとkeyのそれぞれに重みを持たせるべきで、h(query)×w・hs(key)×wだと思います。ですがqueryとkeyの内積を取った時,次のように式変形が可能ですquery∙key = (hw)(hsw) = hhsww(転置Tは一旦無視してます)。wwは結局重みなので、纏めて一つのwで置くとquery∙key=hwhsという形で表すことができるので、上式としています。
次に③、④、⑤を一気に書きます。
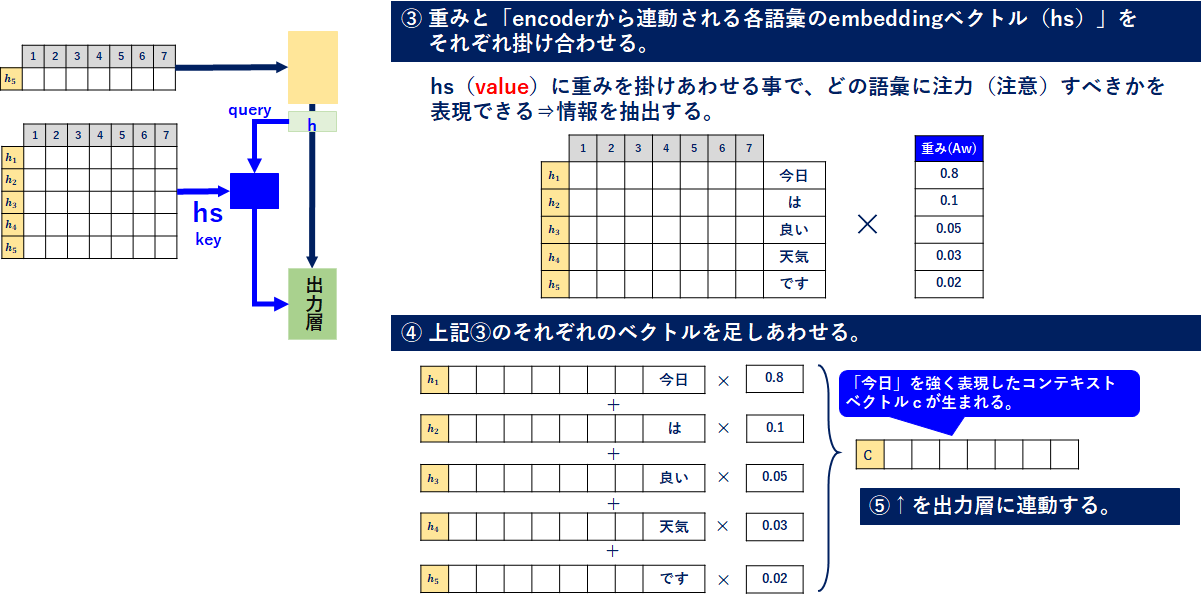
最後にこのベクトルを出力層に繋げます。↓の感じですね。

ここで、上記の加工(cベクトル、hベクトルの加工)をAttentionレイヤで実施してもOKだと思っています。そうすると、「h→出力層」の線は不要になります。
この仕組みを使うことで、どの文字に注目しているかを明確にした状態で文字を生成できます。これにより、長文に強く、より精度の高いモデルが構築できます。
Attentionは色んな切り口があるようなので、完璧ではないかもしれませんが、今回整理した事は以上です。
引き続き、Self-Attention、Transformerを整理していきます。







コメント @ta2bonn
@ta2bonnリンクをコピー このコメントを報告 0
@shiracamus ご指摘ありがとうございます!
タグ修正(カンマ不要。タグをクリックすると同類記事を読めます) by shiracamus 2020/01/19 16:08