






2016.05.01
道具を使わず一瞬で離れた場所との距離を知る方法
時間がない人のためのまとめ

二足直立歩行の適応によって手が解放された人間にとって、道具は人体の感覚器官や運動器官の延長であり、拡張であった。「はかる」行為も同様であり、その道具は、まずもって人体寸法を基準に創りだされた。
古代オリエントにおける長さの基礎はひじの長さに始まるキュビト(約50cm)で、のちにイギリスのキュービット cubitに引き継がれ、またその2倍に相当する単位(イギリスのエル ell、ドイツのエルレElle など)やさらに2倍に相当する単位(イギリスのファゾム fathom、ドイツのクラフテル Klafter、フランスのブラッス brasse など)をもたらした。
他にも、4本の指を並べた幅(日本のつか、イギリスのパーム palm)、親指の幅(中国の寸、ドイツのダウメン Daumen、オランダのドイムduim )、人差指または中指の幅(イギリスのディジット digit、フィンガー finger など)、げんこつの大きさ(ドイツのファウスト Faust)を元にするものがあり、さらに指を広げて事物にあてがうという動作から、イギリスのスパン span、ドイツのシュパンネ Spanne、中国の尺、日本のあた(咫)などの単位が生まれた。
特に指の幅に由来する身体尺は、古代エジプトではdjeba、メソポタミアではubānu、古代ギリシアではδάκτυλοςと呼ばれ、ローマのdigitusを経て、ディジットdigitとなり、10本の指が算術の指=数字の呼び名ともなる。
自然物による度量衡の標準とするメートル法が席巻して久しいが、今回はどんな原始的な測定器も持たずに、この身一つで離れた場所との隔たりを測る技を思い出すことにする。
手の分度器で天を測る
天体観測の経験のある人なら、腕をいっぱいに伸ばした時の、手や指の幅がつくる角度がどれくらいか知っているだろう。
もちろん、おおよそだが
・親指一本分の幅が2度(小指なら1度)
・握りこぶしの親指から小指までの幅が10度
・親指と人差し指をいっぱいに開いた幅が15度
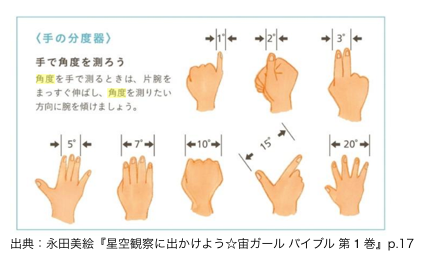
である。
星や星座の位置を大まかに伝えるのに「地平線から20度、つまり握りこぶし2つ分上がったところ」といった具合に使うことができる。
北斗七星が、こぶし3つ分=角度でいって30度の大きさがある、なんてことが言えるようになる。
星座盤で分かった角度を使って、空を探すのにも、もちろん利用できる。
この方法の利点は、道具いらずで簡便なところ、そして腕の長さと手/指の幅の比率をつかっているので、一応は体の大きさに関わらず使えるところだ。
これは「体の大きな人は、その分腕は長くて、手も大きいだろう」という、大らかな前提に基づく。
もちろん指や手の大きさ、腕の長さ、そしてその比率は個人差があるが、それ以外の原因からくる誤差の方が大きいので、そこにこだわっても見返りが少ない。
という後ろ向きな理由から、一応は体の大きさに関わらず使えるのである。
手の分度器で地上を測る
正確さを求めない用途であれば、この「手の分度器」は他にも利用できる。
たとえば、川向こうに乗用車が止まっている。腕を伸ばして人体分度器をやってみると、ちょうど指一本(の幅)で車の全長が隠れた、とする。
乗用車の大きさは、もちろん車種によって異なるが、いまの文脈に照らしてお雑把に言うと、おおよそ全長4m、正面から見た幅は2m、高さは1.5mである。
1/tan 2° = 28.63……だから、大雑把にいって4m×30=120m離れたところに、その車はあることが分かる。
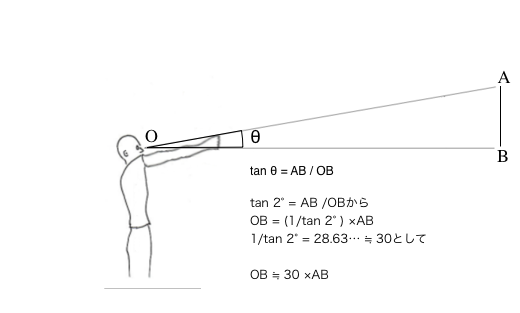
この方法の欠点は、誤差が大きい(桁数と四捨五入した最初の数字くらいが分かる程度、と思っておけば腹も立たない)という最大のものを除くと、対象の実際の長さを知っていないと距離を導けないところだが、逆に言えば、街でよく目にするものについていくつか覚えておきさえすればいい、とも言える。
細かい数字は必要ない(どうで誤差のなかに掻き消える)のと、こういう遊びを何度か実際にやってみると、意外と覚えていられるものだ。
街で見かけるものの大雑把な長さと、指・手の幅に対応させた、〈手の距離計・早見表〉を挙げておこう。
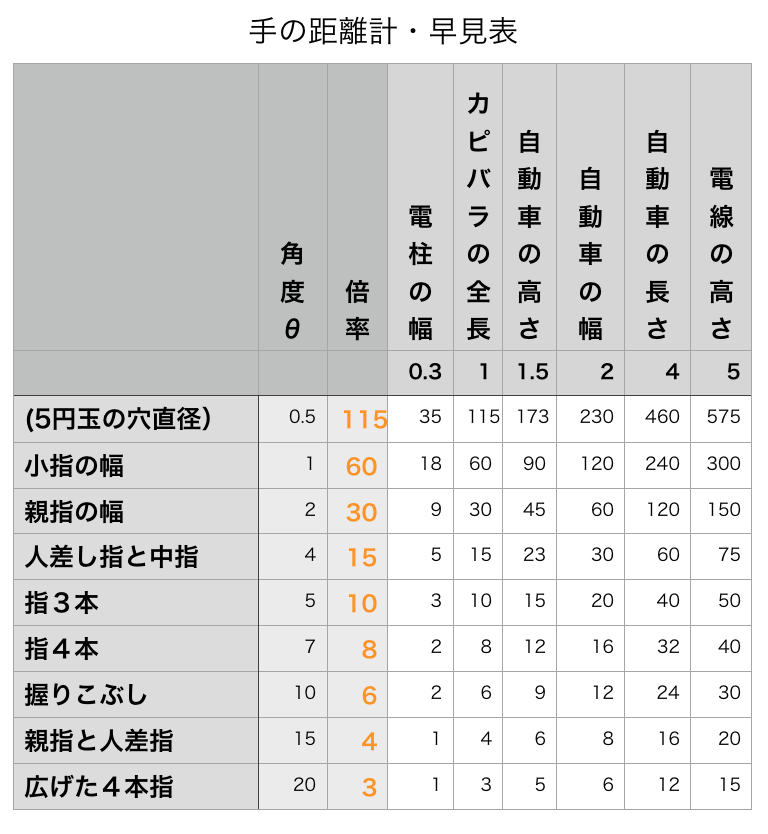
対象までの距離(単位:m) = 対象の大きさ(単位:m) × 倍率
例えば、電柱がちょうど親指一本分の幅なら、大雑把に言って0.3m×30=9mぐらい離れたところに、その電柱はあることになる。
早見表で言うと、「親指の幅」の行と「電柱の幅」の列がクロスしたところ「9」(m)が、対象との距離である。
同じく、電線の高さがちょうどこぶし一つ分なら、大雑把に言って5m×6=30mぐらい離れたところにある。
早見表で言うと、「にぎりこぶし」の行と「電線の高さ」の列がクロスしたところ「30」(m)が、対象との距離である。
ふたたび天の仰ぎ見る
もう少し遠くのものについても、手の距離計で測ってみよう。
月の直径は、この方法だと小指のちょうど半分ぐらいに見える(五円玉の穴とちょうど同じくらい)。
月の直径は約3500kmだから、115倍すると、ざっと40万kmとなる。
地球の中心と月の中心との間の平均距離は38万4400kmというから、正確ではないが、絶望するほどひどい結果ではない。
手の分度器の軍事利用
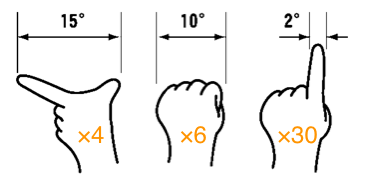
ご存じの方はうずうずしているはずだから申し添えておくと、主として軍事関係で使われるmil(angular mil)という角度の単位を、手や指の幅で測る方法がある。
mil(angular mil)は、円周を6400に分割した角度単位で、1milは、ほぼ1km先の1m幅の物体を見るときの角度(視角)にあたる(もう少し正確には1kmで0.982mほど)ので、距離を計算するのに便利である。次の式で計算できる。
対象までの距離(単位:km) = 対象の大きさ(単位:m) ÷ mil
先ほどと違って、割り算であることと、対象までの距離と対象の大きさで単位が違っていることに注意。
ライフルスコープや軍事用/海事用の双眼鏡等には、Mil-Dotというmilを目で測るための目盛り(reticle)がついている。
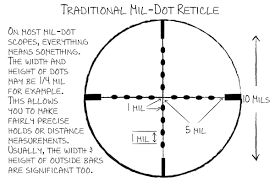
身長180cmの人をスコープで見るとこんな感じになる。
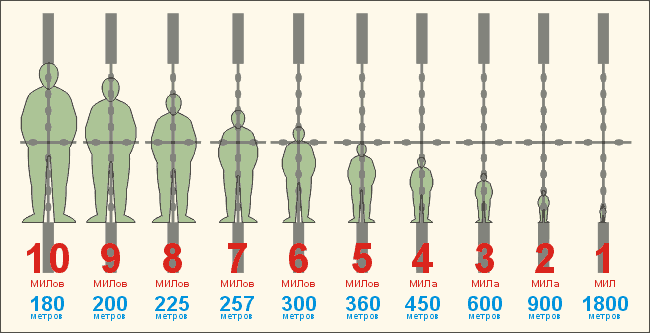
しかし、こうしたものが手元になくても、腕を伸ばして指や手の幅を使うやり方が使える。
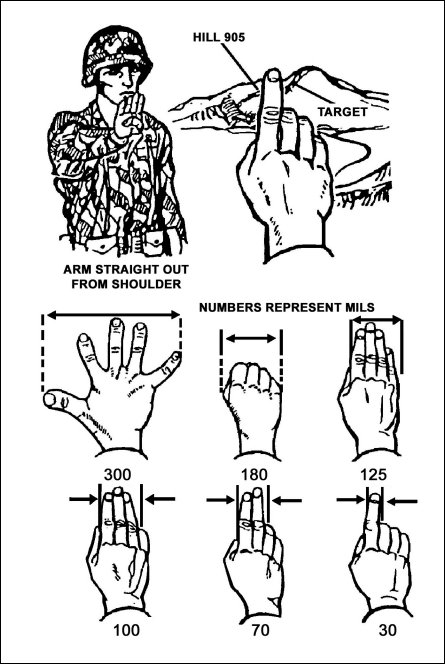
(出典)Figure 8-7. Hand and fingers used to determine deviation. in Army Field Manuals
FM 3-21.94 The Stryker Brigade Combat Team Infantry Battalion Reconnaissance Platoon
CHAPTER 8 COMBAT SUPPORT
同じものが https://commons.wikimedia.org/wiki/File:Mil_estimation.jpg にあり。
これで先程の例である、川向うの乗用車(全長4m)が指1本の幅だった場合の距離について再び計算すると
4m ÷ 30mil(指1本の場合) ≒ 0.133kmで、およそ130mということになる。
 | 星空観察に出かけよう☆ 宙ガールバイブル 永田 美絵, 双葉社 売り上げランキング : 334744 Amazonで詳しく見る |
 | Illustrated Guide to Astronomical Wonders (Diy Science) Robert Bruce Thompson,Barbara Fritchman Thompson O'Reilly Media 売り上げランキング : 1178508 Amazonで詳しく見る |
 | Ultimate Guide to U.S. Army Combat Skills, Tactics, and Techniques Department Of The Army Skyhorse Publishing 売り上げランキング : 386651 Amazonで詳しく見る |
 | The Science of Measurement: A Historical Survey Herbert Arthur Klein Dover Publications 売り上げランキング : 864395 Amazonで詳しく見る |


2014.10.18
今さらだがフェルミ推定というかオーダー推定についてまとめてみた
「フェルミ推定」というと、なんだか就職面接向けの難問奇問パズルのような扱いだけれど※、元々は手早く(もちろん楽に)大まかな結果を出す話だったのでは、という趣旨で、この記事を書く。
※Google人事部のシニア・バイス・プレジデントであるLaszlo Bockが、「雇う側からすると、brainteasers(パズルなどの難問奇問)は完全に時間のムダだった。飛行機にゴルフボールをいくつ詰め込むことができますか?マンハッタンにはガソリンスタンドはいくつありますか?完全に時間のムダ。候補者の能力を何も予測できない。もっぱら面接官を賢い気分にさせるのに役立っただけ。」といったことを、ニューヨーク・タイムスのインタビューで言っている。それで結局1970年代くらいから行われてる構造化行動面接に戻したらしい。がんばれ。
http://www.nytimes.com/2013/06/20/business/in-head-hunting-big-data-may-not-be-such-a-big-deal.html
"brainteasers"(脳をtease(じらす、からかう、悩ます)もの)という言い方が微苦笑を禁じ得ないが、今回の記事ではオーダー推定を、ゆるく楽して数量を扱うやり方として取り上げる。
手間がかかる精確な計算は後回しに、大まかな計算に基づいて、モデルや推論を評価したり、議論をすすめたりすることは、科学者や技術者のコミュニティで古くから行われてきた(著名な最古の例はアルキメデスの『砂の計算者』にみられる)。例えば物理学には、そこらへんの紙切れに(例えば封筒の裏に)さっと走り書きして概算で問題を考えることを指す“Back-envelope physics(封筒裏の物理学)”というステキな言い回しがある。
大雑把な計算は、その分手早くできるので、科学や工学の分野では、次のようなご利益がある。
・仮説やモデルからどんな結論が出てくるか、時間やコストをかけず大まかな予想を得ることができる
・精確な計算の結果について手早く検算することができる
・精確な答えを出すには情報が足りない場合でも、見当をつけることができる
・精密に測れないようなものについても、何らかの定量的な推測・評価を行うことができる
・未開拓の分野や問題について予測に使える理論が不整備な場合にも定量的な推測・評価を行うことができる
・代替案をつくる上で、どの範囲におさまっていればいいかという境界条件を導くのに使える
では科学者でもなんでもない一般人には(頭の体操や時間つぶし以外に)どんなご利益があるだろうか。
1.数を扱うスキルというか感覚を磨くことになる。特に億とか兆の付く数字、ナノやピコがつく数量がどの程度のものであるか、実際に扱うことで数覚とでもいうべきものが身につく。
2.数量を含む主張や議論を自分でチェックできるようになる。またはチェックする習慣が身につく。
3.意思決定を助ける。問題外の選択肢を詳しく検討する前に取り除いたり、ろくでもないアイデアをふるい落とすフィルターとして使える
4.問題解決に必須のメタスキル、Divide and conquer (D&C)(分割して征服せよ)の手ごろな練習になる。問題を「重複なく・漏れなく」分割すること、分割して推定した結果を掛け算という簡易で誰でもできる方法で統合すること、最終的に一つの数値を結論として出すことなど、手続き・得られる成果ともに明快でわかりやすい。
それでは、やり方を説明し、推定の例を示すことにしよう。
(時間がない人のためのまとめ)
1 桁数が推定できればOK
2 問題を分割し(Divide and conquer の原則)、推定構造図をつくる
3 分からない数値は上限と下限から考えて、幾何平均(相乗平均)を取る
4 分割した推定を掛け合わせて答えを出す
5 推定結果をチェックする(単位は合っているか、宇宙全体より大きくないか等)
1 桁数を推定する
今回取り上げる、大雑把に数量を求める方法をオーダー推定order-of-magnitude estimateという。
日本語で「指標」というと、〈指=ゆび・さす〉と〈標=しるし〉、普通の意味では「(物事の見当をつけるための)めじるし」程度の意味だが、やや専門的な意味に「正数の常用対数を整数と正の小数の和として表したときの整数部分」というのがある。
この意味でいう「指標」にあたる英語が“order of magnitude”であり、この“order of magnitude”を推定する(estimate)のがオーダー推定order-of-magnitude estimateである。
単なる「おおよその数」を推定しようというのではなく、要するに桁数を当てるのである。
ぶっちゃけ正解の1/10~10倍の範囲におさまればいい、という乱暴さだ。
この「桁数が分かればいい」というのをわざわざ強調するのは、この大前提からオーダー推定の次のような方針・アプローチが導き出されるからである。
・精確な数にこだわらず、計算しやすいように細かい数字は捨てる。
・モデル化にも計算しやすい仮定をどんどん使う
・間の数字を決めるには幾何平均を使う
◯指数表記のご利益
数字をm×10n(m掛ける10のn乗)の形で表すことを指数表記という。
仮数部:mの部分で有効数字をあらわす、1以上10未満の数字
指数部:nの部分で指数を表す→ぶっちゃけ桁数を表す
mの部分を、1 ≦ m < 10となるようにする(正規化)
例)
6.2×103 = 6200
3×108 = 300000000
6.77×10-11 = 0.0000000000667
これは科学的記数法scientífic notátion とも呼ばれて、科学・工学ではお馴染みの数値の表し方だ。
なんとなれば、科学・工学で取り扱うとても大きな数値や小さな数値を扱うのに便利な表し方だからである。
たとえば「300000000」の「3」を「4」と間違えてもせいぜい1.33倍ぐらいの誤差だが、0をひとつ付けそこなうと10倍の違いになってしまう。そして「3」を「4」に書き間違える人はあまりいないが、「0」が一つ多かったり少なかったりすることはとても生じやすい。
「300000000」を「3×108」を書くことにすれば(「8」を「7」や「9」と間違うことはそうない)こうしたミスは起こりにくくなる。
今の話は、オーダー推定の根っこにあるものでもある。
指数表記(m×10n:m掛ける10のn乗で表す)した場合、mの仮数部が違っていても大きな違いはない(最大でも1/10~10倍の違い)が、nの指数部が違っているなら最低でも1/10~10倍、まさにケタ違いの差になる。
なので、mの仮数部の数値が違っているのは許容するとして、せめてnの指数部の数値については当てたい、というのがオーダー推定である。
◯指数表記で掛け算が楽になる
オーダー推定では後述のように、問題を分解して推定し結果を掛け合わせて統合するから、掛け算が必須である。指数表記すると、この掛け算が簡単になる。
am × an = a(m+n)
という指数法則を思い出しておこう。
指数表記では数はすべてm×10nという形にしているから、掛け算といっても、重要な指数部を求めるには、足し算で済む。
加えて、nの指数部の数値がわかればいいオーダー推定ならば、最低限、mの仮数部は1桁に四捨五入して丸めても構わない(つまり最上位の1桁だけわかればいい)。これなら暗算でもいける。
例)6870×213= 1463310 =1.46331×106
例)6.9×103 × 2.1×102 = 14.28 × 10(3+2) = 1.4 × 106
例)7×103 × 2×102 = (7×2)×10(3+2) =14 × 105 = 1.4×106
「6870×213」が暗算で苦しい人でも、「7×2」なら大丈夫だろう。
あとは指数部の「3」と「2」を加えて「5」とすれば、14 × 105 と答えが出る。上の例で比べて分かるようにちゃんと計算した結果と、あまり変わらない。
◯幾何平均(相乗平均)で中を取る
オーダー推定では桁数を重要なので、二つの値の中間を求めたい時は、足して2で割る算術平均ではなく、掛けて平方根を求める幾何平均(相乗平均)を使う。
これは必要だ分からない数値について、上限と下限を考えてその中間を求めるアプローチで頻用する。
また複数のアプローチで導いた異なる推定値から、平均を求める場合にも用いる。
つまり下限1~上限100の間の数字を得るとき、算術平均(1+100)/2= 50.5ではなく幾何平均 √(1×100) = 10 (√(100×102) =101)を使うということだ。
ルートを計算するのが面倒、せっかくなので電卓など使わずできるように、さらに簡略な方法を述べると
・桁が二桁異なっているなら、ただその間の桁数にすればいい。1(=100)と100(=102)なら10(=101)ということだ。
・桁が一桁異なっているなら、下の桁を採用して3を掛ける。たとえば10と100なら30になる。本当は10=3.16227766だから、√(10×100) = √(101×102) =√(10)×101=31.62…くらいになるのだが、最上位の一桁だけわかればいいという方針だから30でいい。
三桁以上異なっている場合も上記に準ずる。つまり、
偶数桁の異なる場合は「二桁異なる場合」と同様、桁数の算術平均をとる。10(=101)と100000(=105)なら、(1+5)/2=3桁となり、1000(=103)となる。
奇数桁異なる場合は「一桁異なる場合」を参考に、10(=101)と10000(=104)だと、(1+4)/2=2.5だから、低い方の2桁を採用して、3を掛ける、つまり300(=3×102)となる。
2 問題を分割する
いわゆるDivide and conquer (D&C)(分割して征服せよ)の原則が用いられる。
取り付く島のない問題も、分割していくことで取り扱うことができるようになる。
手順として書き出せば、
(1)問題に関係ありそうな事実を書き出す
(2)一つかできればそれ以上の推定の方針をつくる
(3)問題を分割して推定の階層構造をつくる
(4)知らなければならない質問をリストアップする
という感じになる。
みんなが大好きな問題「シカゴにピアノの調律師は何人いるか?」を例にして、各ステップを説明しよう。
(1)問題に関係ありそうな事実を書き出す
関係ありそう、というかど真ん中にある事実はまず「ピアノの調律師はピアノを調律する」ことである。当たり前だ。
さらに「ピアノ」には所有者がいる。家庭にあるものもあれば、学校や(シカゴなら)教会にあるものも有るだろう。これらがピアノの所有者になりそうな人(組織)だ。
今回は、どれもシカゴという大都市にいる/ある「ピアノの調律師」「ピアノ」「家庭」「学校」「教会」について考えればいい。

(2)一つかできればそれ以上の推定の方針をつくる
「ピアノの調律師の人数」と「ピアノの台数」を結びつけることはできるだろうか?
→ピアノの調律師が一人でどれくらいのピアノを調律するか分かれば、結び付けられそうだ。
「ピアノの台数」はどうすれば分かるだろうか?
「家庭の数」と「ピアノの台数」を結びつけることはできるだろうか?
「学校の数」と「ピアノの台数」を結びつけることはできるだろうか?
「教会の数」と「ピアノの台数」を結びつけることはできるだろうか?
→これらを全部足すとシカゴに有る「ピアノの台数」がわかりそうだ。
何からシカゴの「家庭の数」は分かるだろうか?→1世帯平均の人数が分かれば何とかなりそう。
何からシカゴの「学校の数」は分かるだろうか?→子供の数と1校あたりの平均的な生徒数が分かれば。
何からシカゴの「教会の数」は分かるだろうか?→よく分からない。今回は無視して計算しよう。
上記は「ピアノ台数」と「調律に必要な時間」から考えるアプローチだが、他にも、シカゴ全体で調律に支払われる代金総額からそれで食っていける調律師の数を割り出すなど、いくらもアプローチがあり得る。
(3)問題を分割して推定の階層構造をつくる
(2)でうだうだ考えたことを樹形図にまとめてみるとこんなふうになる。

(クリックで拡大)
実際の作業は、(2)の段階を今回はアウトラインプロセッサーの上に問いと答えを順不同で書き出してから、(3)の作業として、並べ替えたり階層付けしたりして、上位下位関係を整理していった。
上の図は、「Tree」という通常のアウトライン表示とツリー(樹形樹)表示を切り替えられる、Mac用アウトラインプロセッサで整理したものを〈ツリー表示〉して作成した。
(4)知らなければならない質問
知らなくてはならないのは、推定階層図の先っぽ、葉に当たる部分の数値である。
これを埋めるために「3 分かる数値・知識をつかう」や「4 分からない数値は上限と下限を考える」へ進む。
◯推定階層図(樹形図)のメリット
正直、ピアノの調律師の数を計算する程度のシンプルな問題だと、わざわざ推定階層図を書くのは面倒くさい。
「5分で答えろ」といった就職面接のシーンだと書いていられないというのもある。
しかしせっかく就職面接用brainteasersという悪用から解放されたのだから、すこし丁寧にやってみたい。
推定階層図を書くと、まずどんな具合に推定を組み合わせたか、自分にも他人にも分かりやすい。
どこが根拠が弱い・根拠を欠いた推定かも、すぐ分かる。
いい加減に問題を分割した場合や、乱暴な決め付けで済ませた部分も明確に残る。
時間をおいて推定を見直した場合も、何をやっていたか分かりやすい。
時間をおくと弱点(乱暴な決め付けなど)にも気付きやすい。
思考の跡が残るということは、経験が蓄積しやすい・上達しやすいということでもある。
そして複雑な問題になっても、何をどこまで分解したか、常に把握しながら進められる。
試行錯誤しても、その過程が無駄にならない。
ワーキング・メモリを余計なところで消耗することを防ぎ、問題解決そのものに認知リソースを回しやすい。
とくに複数のアプローチをとる場合は、それだけ推定構造は大規模化・複雑化するから、推定階層図が助けになる。
3 分かる数値・知識をつかう
推定階層図が(ちゃんと書き出すか、頭の中だけでやるかは別にして)できれば、あとは推定階層図の先っぽ、葉に当たる部分の数値を埋めていけば、最終的な答え(推定)は出るはずである。
数値が分からないところは、さらに問題を分割して、推定階層図の枝を広げていくべきかもしれない。
後で触れることだが、この宇宙を量的に把握しようとすれば、宇宙の諸相をあらわす様々な数量は互いに連関していることが分かる。
このおかげで、ある数量(たとえば原子の大きさが概ね10-10mであること)が分かれば、それに関連する様々な数量を推定することができるようになる。
多くの物理定数は、そうした数量間の関連の結束点であると見なすことができる。
しかし、もし手がかりになる数量を知らなければ、資料など外部リソースがなければ、どれだけ分割しても分かる数値に行きつけない場合も多い。
そういう場合はもう手がないのだろうか? いろんな数値をあらかじめ知っておかなくては結局、推定なんてできないのだろうか?
たとえば「シカゴの人口」が分からないと、先の「ピアノの調律師の数」を推定する問題は解けないのだろうか?
否、否、三たび否。
4 分からない数値は上限と下限を考える
そのものずばりの数値は分からなくても「さすがに多すぎる」「いくらなんでも少なすぎる」と分かることは多い。
今の「シカゴの人口」だと、確かに何人かは分からないが、しかしシカゴはどこかの寒村ではなく、結構な大都市であることは、何となく分かる。
こうした場合、我々がおぼろげながら知っていることを、間違ってはいない程度に正しい数量に落とし込む方法がある。
分かる範囲でその上限と下限を考えてみるのである。
我々が知りたいのは、つまるところ桁数であったことを思い出そう。
「シカゴの人口」の例を続けよう。
まず下限を考える。シカゴの人口が、何十万人(=105)というのは、どうにも少なすぎる。というのも、何十万人では、いくらもある普通の地方都市レベルだからだ。
次に上限を考える。桁違いな数字を考えて、何千万人(=107人)ではどうか? いや、これは多すぎる。これだと世界にいくつかしかない屈指の都市レベルになってしまう。
そこで下限と上限を設定し、シカゴの人口は100万人~1000万人の間にある、と仮定しよう。
我々は桁数に関心があるから、100万と1000万の間をとるのに幾何平均を使う。
√(106×107)を計算するわけだが、先ほど触れた簡易法をつかってざっくり300万人だとしても、我々が求める精度では問題ない。
これでシカゴの人口が、極めて大雑把にだが見積もれた。
この方法は、桁数が分かればいい、という割り切りから導き出されるものだが、とても活用範囲が広い。
基本となる数値がわからないときは、多くの場合、この方法で切り抜けられる。
そして、分からない数量をエイヤッとダイレクトにあてずっぽうするよりも、慎重かつシステマティックであり、実際もましな概数値が得られることが多い。
さらに「シカゴのピアノ調律師」の例をつづけると、たとえば1世帯あたりの平均人数が分からないとする。
今の方法を用いるなら、
下限:1人(単身者世帯ってある。それもけっこうある)
上限:10人(何十人って家族はいまどきは珍しい。都市だともっと珍しい)
1と10の幾何平均をとって3人を平均世帯数として採用する。 (√(1×10)≈3)。
5 分割した推定を掛け合わせて答えを出す
こうして推定階層図に数値を入れていくと、次のようになる。

(クリックで拡大)
結局、シカゴには200人のピアノの調律師がいると推定した。
学校の数を500校と推測したが、学校にあるピアノの台数(1500台=3台/校×500校)は、今回、家庭が持っている台数に比べて、我々が知りたい精度でいうと、無視できるくらい少なかった。最初からピアノを持っているのは家庭だけと考えるアプローチも今回のような目的なら十分あり得るといえる。
もちろん家庭が持っている数がずっと少ないと、学校や教会が持っているピアノの台数も無視できなくなってくる。
当初の推定階層図から変更したのは、1日8時間労働として、全ての調律師が切れ間なく調律し続けるってのはどうだろうと思ったので(調律してない時間って結構あるんじゃないだろうか)、そこのところを追加した。
結局、8時間労働の内、忙しい人も暇な人も合わせて平均すると4時間ぐらいだろうとしたが、もしフルタイム可動だと推定は100人になる(推定階層図があるので、変更してどうなるかもすぐ分かる)。
1~2×102人だから、オーダー推定的には大した差ではない。
6 推定をチェックする
推定結果は、最後にチェックしておきたい。
(1)単位のチェック
単位付きで計算しておくと計算過程でもミスしにくい(ミスしても気づきやすい)が、それだけでなく、最後に求めたかった単位が出てくるかどうかで、推定の階層構造がおかしくないか最低限のチェックができる。
(2)上限下限のチェック
たとえば、今回の場合だと、最後に出てくる調律師の人数が、シカゴ全体の人口を超えていたりすると、どう考えてもおかしい。
そこまで行かなくても、ピアノ台数より調律師の数が多くなったりすれば、調律師は1年に1台の調律で食っていく訳で、その料金は年収レベルになるか調律師はみな他の商売で食っているかになるから、これもおかしいことになる。
先に触れた「調律料金~養える調律師の数」を考えるアプローチも合わせて行っていれば、こうした別アプローチが推定の妥当性のチェックの役割も担ってくれる。
複数アプローチをお勧めするのは、こうした理由からである。
最後に実際の数字を紹介しておこう。
シカゴの人口271万人、公立学校数は638校、ピアノ調律師は分からなかったが、すこし広げてmusical instrument repaires and tuners だと290人だった。
オーダー推定的には1/10~10倍の誤差は許容範囲だが、今回はちょっと出来過ぎた結果となった。
(おまけ)オーダー推定の例
ピアノ調律師やマンホールの数ばかり考えても仕方がないから(脈絡なく鉄球の落下速度を計算させられる授業がつまらないように)、趣向の違った例題を見てみよう。
科学や工学の分野で取り組まれてきた方法だから、ほんの少し科学や工学の知識を使うだけで、取り組める問題の幅は一気に広がる(逆に言うと、面接試験のはこの辺を削ぎ落とすから、空虚な数当てゲームに限定されてしまうともいえる)。
科学教育の分野で用いられるのは、そうした例が多い。
たとえば物理定数や公式など、暗記してもらおうとしても埒が明かないが、それらを使ってちょっとした問題を解いてもらうと忘れられなくなる。
科学は世界を量と量の関係として捉えることで発展した。科学が扱う様々な数量は互いに連関しあっていて、他の量と無関係に変動したりしない。だからこそ、数量の間の連関を辿って、我々は定量的に予測したり評価したりすることができる。
オーダー推定は、大股歩きではあるが、そうした量の相互関連をたどっていく体験である。
◯人の細胞中にDNAをつなげると何メートルになるか?
我々より小さな大きさで、知っておくと適用範囲が広がる数量が登場する例を取り上げよう(一度やっておくと原子の大きさや細胞の大きさを忘れなくなるので)。
原子の直径は、1~5×10-10 mである(注)。オーダーで言えば、10-10 mである。
(注)こういうことを調べるにはもってこいのサイトThe Physics Factbookから、「Diameter of an Atom」のページを見た。
これを元にして、人の細胞の中にあるDNAをつなげるとどれくらいになるかを推定したい。
(1)問題に関係ありそうな事実を書き出す
あなたがDNAについて知っていることは、それほど多くない。しかし何も知らないわけではない。
以下のような事実を知っている(前提にできる)としよう。
・人の体は細胞が集まって出来ている
・細胞はその中に核をもっている
・DNAは核の中に収められている
・DNAは塩基対が集まって出来ている
・塩基対は、原子が集まって出来ている
まとめて書くと「人間>細胞>核>DNA>塩基対>原子」という感じである。
(2)一つかできればそれ以上の推定の方針をつくる
何とかわかりそうなのは、大きい方と小さい方、すなわち人間の大きさ(体積)と原子の大きさである。
なので、トンネルを両側から掘るように、最大のものと最小のものの両側から挟み込むようにアプローチする。
(3)問題を分割して推定の階層構造をつくる
(4)知らなければならない質問をリストアップする
をやった結果、わからないところは上限・下限を考えて幾何平均で推定して、数値まで入れたのが次の推定構造図である。

(クリックで拡大)
鍵となるのは、推定構造図の枝の先にあたる「細胞の大きさ」と「塩基対を構成する原子の数」である。
「細胞の大きさ」は、目には見えないこと(0.1mm(=10-4m、細い髪の毛の太さ)くらいなら何とか見えるからそれより小さい)、しかし最初期の顕微鏡(倍率はよくて100倍程度)では見えたことから小さくても10-4×10-2=10-6mくらいだと考え、これを下限と上限に幾何平均をとった。
結果、人の細胞中にDNAをつなげると約1メートルになることが推定される。
ほんとに便利なサイト、The Physics Factbookで「Length of a Human DNA Molecule」というページを見ると、人の細胞中にDNAをつなげると1.5〜3メートルとある。
◯タバコ1本あたりどれだけ寿命が短くなるか?
ちゃんと答えるには大規模な疫学調査が必要な問題も、大雑把になら見当をつけることができる。

(クリックで拡大)
「タバコの毒で直接死ぬというより肺がんなど病気にかかりやすくするのが、喫煙が命を縮める主たる理由だろう」というぼんやりした考えを元にして、「中年以降に死亡原因となる病気にかかりやすくなるだろう」というぼんやりした予想から、
・上限「ワーストケースとして40歳で肺がんになり死ぬとして、ベストケースで本当は80歳まで生きることができたはずだったとすると」
・下限「1年未満しか寿命が縮まないような軽微な影響だとすると、盛んに禁煙を勧めたり禁止したりする理由が立たないので」
として幾何平均をとり、タバコによる寿命短縮をざっくり√(1*40) ≒ 6年としたのが、この推定の中心である。
British Medical Journalに掲載された、そのままズバリの論文※によれば、喫煙者と非喫煙者の平均余命の差は6.5年とされている。
※Shaw, M., Mitchell, R., & Dorling, D. (2000). Time for a smoke? One cigarette reduces your life by 11 minutes. British Medical Journal, 320(7226), 53-53. (リンク)
◯1万人規模のイベントで仮設トイレは何個必要か?
ほんのり実用的(?)な問題もとりあげてみよう。
この問題を考えるには、待ち行列理論を使うにしても
・利用者はどれだけの頻度でトイレにやってくるか?
・一人当りどれだけの時間トイレを使用するか?
・待ち時間が出るとして、どれくらいの時間なら許容できるか?
などのデータが必要だが、これらを調べることなしに大雑把にでも推定することは可能だろうか?
ここでは2つの強力な(強引な)仮定をおいて、推定を可能にしている。
ひとつは【平均人の仮定】である。これは、「私(推定者)がある行動をする頻度は平均的である」というものである。
例えば、もし私が一日に平均10分間トイレを利用しているならば、十分に大きな人数について調べれば(10分以上の人も以下の人ももちろんいるだろうが)そのトイレの平均利用時間はやはり10分になる、と考えるのである。
もうひとつの仮定は【一様分布の仮定】である。これは、「人がある行為をする確率はある期間では一定である」という仮定である。
例えば、十分に大きな人数について調べれば、トイレは行くタイミングは均等にバラけており、特別に混雑する時間や閑散とする時間はない、と考えるのである。
これらの強力な仮定を置くことで、私(推定者)がトイレにいく頻度が分かれば、それをそのまま十分に大きな集団に適用できることになる。
私がトイレにいる平均時間がはっきりしないが、ここでは
・下限5分間:1回最低1分としても5回くらいは行く
・上限100分間:1日1時間半もトイレにはいない
として幾何平均をとり、私が1日のうちトイレにいる時間20分(起きている時間16時間≈1440分のうちの1/72)とした。
ここから必要なトイレの個数を1万人×1/70(70人につき1個)≈130個とした。

(クリックで拡大)
この推定の問題点は、休憩時間が決まっていて、その時間に利用者が集中するコンサートやスポーツのようなイベントは想定していないことである。
「仮設トイレの設置数はイベントの内容で条件が大きく変わるため必要数の算定方法がない」(出典:信濃毎日新聞 1996年6月27日)ようだが、災害用の仮設トイレ設置の基準だと、次のようになっている。

なお、利用者数に応じたトイレの利用者数の想定においては、日本だと、社団法人空気調和衛生工学会(HASS)による適正な衛生器具数の算定法※が広く用いられるが、休憩時間に利用が集中すると考えられるホール・劇場について、トイレの適正器具数の算定法について、リンク先(pdfファイル)を参照。
※空気調和衛生工学会規格(SHASE-S206)にて算定方法(技術要領「衛生器具の設置個数」)が示されている。
(参考文献)
○Swartz, C. E. (1972). Used math for the first two years of college science. Englewood Cliffs, N.J: Prentice-Hall.
オーダー推定やBack-of-the-Envelope (BotE) Reasoningに関する文献をたどっていくと、Clifford Swartzのこの書物に行き着く。
シュワルツは高校・大学の物理教員向けの専門誌The Physics Teacherの編集長を30年近くつとめ、この後も"A search for order in the physical universe"(1974)や"Back-of-the-Envelope Physics"(2003)という書物を著している。
"Back-of-the-Envelope Physics"はブルーバックスから以下の翻訳が出ている。
○Harte, J. (1988). Considere a spherical cow: A course in environmental problem solving. Mill Valley, Calif: University Science Books.
物質循環(生物地球化学サイクル)を中心とした環境科学について、Back-of-the-Envelopeで考える教科書。
原著タイトルを直訳するなら「牛(の形)が球であると仮定しよう」。
アメリカの大学関係者の間に伝わる次のようなフォークロアが元になっている。
報告書を受け取った、酪農家のなんとも言えない顔が思い浮かぶ。
この口伝を伝えた人はおそらく「理論(家)は実社会の役にたたない」という教訓を込めたと思われる。
しかしハートは、これを逆手にとり、問題解決のためには本質を変えることなく不要な詳細をうまく捨てて問題を単純化する必要があることを示す、モットーにした。
この書にはHarte, J. (2001). Consider a cylindrical cow: More adventures in environmental problem solving. Sausalito, Calif: University Science Books.(牛を円筒であると仮定しよう)という続編があり、この2冊はそれぞれCow-1、Cow-2という略称で呼ばれている。
Cow-1については(チャーミングなタイトルが見る影もなくなっているのが残念だが)、以下の邦訳がある。
○Weinstein, L., & Adam, J. A. (2008). Guesstimation: Solving the world's problems on the back of a cocktail napkin. Princeton, N.J: Princeton University Press.
タイトルのGuesstimation(Guesstimate)は、1934~35年ぐらいにつくられた、guess(推測する)とestimate(見積もる)のかばん語(混成語)。
オールドドミニオン大学でPhysics on the Back of an Envelopeのコースを担当していたワインシュタインは、収集した膨大な推定問題をネットでも公開していた(そのアーカイブ)。問題収集の協力者の一人、同僚で数学者のジョン・アダムスと共著で書いたのがこの書。
日常の問題からはじめて、科学的な問題に入っていく。幾何平均を使うテクニックも紹介している。
これにもWeinstein, L. (2012). Guesstimation 2.0: Solving today's problems on the back of a napkin. Princeton, N.J: Princeton University Press.という続編がある。
Guesstimationの方には、次の邦訳がある。
(参考サイト)
◯A View from the Back of the Envelope http://www.vendian.org/envelope/
Back-of-the-Envelope (BotE) Reasoningを含む、approximation(近似法)を扱った、最も浩瀚なサイト。
「Scaling the universe to your desktop」や「How Big Are Things?」は予備知識無しに楽しむことができるだろう。
ネット上のリソースから書籍、論文から絵本まで、大抵のものはこのサイトからたどることができる。
◯Science Plympics - Fermi Questions
274のフェルミ問題のリスト
◯ Wolfram Alpha
言わずと知れたウルフラム・リサーチ開発の質問応答システム。
いわゆるフェルミ問題をそのまま投げても(英語なら)、次のような感じでガチな答えを返してくれるので、自分でやってみた後の〈答え合わせ〉に使える。

それもただの答えでなく、[show detail]をクリックすると、概数を出した考え方まで表示してくれる。すげえ。

※Google人事部のシニア・バイス・プレジデントであるLaszlo Bockが、「雇う側からすると、brainteasers(パズルなどの難問奇問)は完全に時間のムダだった。飛行機にゴルフボールをいくつ詰め込むことができますか?マンハッタンにはガソリンスタンドはいくつありますか?完全に時間のムダ。候補者の能力を何も予測できない。もっぱら面接官を賢い気分にさせるのに役立っただけ。」といったことを、ニューヨーク・タイムスのインタビューで言っている。それで結局1970年代くらいから行われてる構造化行動面接に戻したらしい。がんばれ。
http://www.nytimes.com/2013/06/20/business/in-head-hunting-big-data-may-not-be-such-a-big-deal.html
"brainteasers"(脳をtease(じらす、からかう、悩ます)もの)という言い方が微苦笑を禁じ得ないが、今回の記事ではオーダー推定を、ゆるく楽して数量を扱うやり方として取り上げる。
手間がかかる精確な計算は後回しに、大まかな計算に基づいて、モデルや推論を評価したり、議論をすすめたりすることは、科学者や技術者のコミュニティで古くから行われてきた(著名な最古の例はアルキメデスの『砂の計算者』にみられる)。例えば物理学には、そこらへんの紙切れに(例えば封筒の裏に)さっと走り書きして概算で問題を考えることを指す“Back-envelope physics(封筒裏の物理学)”というステキな言い回しがある。
大雑把な計算は、その分手早くできるので、科学や工学の分野では、次のようなご利益がある。
・仮説やモデルからどんな結論が出てくるか、時間やコストをかけず大まかな予想を得ることができる
・精確な計算の結果について手早く検算することができる
・精確な答えを出すには情報が足りない場合でも、見当をつけることができる
・精密に測れないようなものについても、何らかの定量的な推測・評価を行うことができる
・未開拓の分野や問題について予測に使える理論が不整備な場合にも定量的な推測・評価を行うことができる
・代替案をつくる上で、どの範囲におさまっていればいいかという境界条件を導くのに使える
では科学者でもなんでもない一般人には(頭の体操や時間つぶし以外に)どんなご利益があるだろうか。
1.数を扱うスキルというか感覚を磨くことになる。特に億とか兆の付く数字、ナノやピコがつく数量がどの程度のものであるか、実際に扱うことで数覚とでもいうべきものが身につく。
2.数量を含む主張や議論を自分でチェックできるようになる。またはチェックする習慣が身につく。
3.意思決定を助ける。問題外の選択肢を詳しく検討する前に取り除いたり、ろくでもないアイデアをふるい落とすフィルターとして使える
4.問題解決に必須のメタスキル、Divide and conquer (D&C)(分割して征服せよ)の手ごろな練習になる。問題を「重複なく・漏れなく」分割すること、分割して推定した結果を掛け算という簡易で誰でもできる方法で統合すること、最終的に一つの数値を結論として出すことなど、手続き・得られる成果ともに明快でわかりやすい。
それでは、やり方を説明し、推定の例を示すことにしよう。
(時間がない人のためのまとめ)
1 桁数が推定できればOK
2 問題を分割し(Divide and conquer の原則)、推定構造図をつくる
3 分からない数値は上限と下限から考えて、幾何平均(相乗平均)を取る
4 分割した推定を掛け合わせて答えを出す
5 推定結果をチェックする(単位は合っているか、宇宙全体より大きくないか等)
1 桁数を推定する
今回取り上げる、大雑把に数量を求める方法をオーダー推定order-of-magnitude estimateという。
日本語で「指標」というと、〈指=ゆび・さす〉と〈標=しるし〉、普通の意味では「(物事の見当をつけるための)めじるし」程度の意味だが、やや専門的な意味に「正数の常用対数を整数と正の小数の和として表したときの整数部分」というのがある。
この意味でいう「指標」にあたる英語が“order of magnitude”であり、この“order of magnitude”を推定する(estimate)のがオーダー推定order-of-magnitude estimateである。
単なる「おおよその数」を推定しようというのではなく、要するに桁数を当てるのである。
ぶっちゃけ正解の1/10~10倍の範囲におさまればいい、という乱暴さだ。
この「桁数が分かればいい」というのをわざわざ強調するのは、この大前提からオーダー推定の次のような方針・アプローチが導き出されるからである。
・精確な数にこだわらず、計算しやすいように細かい数字は捨てる。
・モデル化にも計算しやすい仮定をどんどん使う
・間の数字を決めるには幾何平均を使う
◯指数表記のご利益
数字をm×10n(m掛ける10のn乗)の形で表すことを指数表記という。
仮数部:mの部分で有効数字をあらわす、1以上10未満の数字
指数部:nの部分で指数を表す→ぶっちゃけ桁数を表す
mの部分を、1 ≦ m < 10となるようにする(正規化)
例)
6.2×103 = 6200
3×108 = 300000000
6.77×10-11 = 0.0000000000667
これは科学的記数法scientífic notátion とも呼ばれて、科学・工学ではお馴染みの数値の表し方だ。
なんとなれば、科学・工学で取り扱うとても大きな数値や小さな数値を扱うのに便利な表し方だからである。
たとえば「300000000」の「3」を「4」と間違えてもせいぜい1.33倍ぐらいの誤差だが、0をひとつ付けそこなうと10倍の違いになってしまう。そして「3」を「4」に書き間違える人はあまりいないが、「0」が一つ多かったり少なかったりすることはとても生じやすい。
「300000000」を「3×108」を書くことにすれば(「8」を「7」や「9」と間違うことはそうない)こうしたミスは起こりにくくなる。
今の話は、オーダー推定の根っこにあるものでもある。
指数表記(m×10n:m掛ける10のn乗で表す)した場合、mの仮数部が違っていても大きな違いはない(最大でも1/10~10倍の違い)が、nの指数部が違っているなら最低でも1/10~10倍、まさにケタ違いの差になる。
なので、mの仮数部の数値が違っているのは許容するとして、せめてnの指数部の数値については当てたい、というのがオーダー推定である。
◯指数表記で掛け算が楽になる
オーダー推定では後述のように、問題を分解して推定し結果を掛け合わせて統合するから、掛け算が必須である。指数表記すると、この掛け算が簡単になる。
am × an = a(m+n)
という指数法則を思い出しておこう。
指数表記では数はすべてm×10nという形にしているから、掛け算といっても、重要な指数部を求めるには、足し算で済む。
加えて、nの指数部の数値がわかればいいオーダー推定ならば、最低限、mの仮数部は1桁に四捨五入して丸めても構わない(つまり最上位の1桁だけわかればいい)。これなら暗算でもいける。
例)6870×213= 1463310 =1.46331×106
例)6.9×103 × 2.1×102 = 14.28 × 10(3+2) = 1.4 × 106
例)7×103 × 2×102 = (7×2)×10(3+2) =14 × 105 = 1.4×106
「6870×213」が暗算で苦しい人でも、「7×2」なら大丈夫だろう。
あとは指数部の「3」と「2」を加えて「5」とすれば、14 × 105 と答えが出る。上の例で比べて分かるようにちゃんと計算した結果と、あまり変わらない。
◯幾何平均(相乗平均)で中を取る
オーダー推定では桁数を重要なので、二つの値の中間を求めたい時は、足して2で割る算術平均ではなく、掛けて平方根を求める幾何平均(相乗平均)を使う。
これは必要だ分からない数値について、上限と下限を考えてその中間を求めるアプローチで頻用する。
また複数のアプローチで導いた異なる推定値から、平均を求める場合にも用いる。
つまり下限1~上限100の間の数字を得るとき、算術平均(1+100)/2= 50.5ではなく幾何平均 √(1×100) = 10 (√(100×102) =101)を使うということだ。
ルートを計算するのが面倒、せっかくなので電卓など使わずできるように、さらに簡略な方法を述べると
・桁が二桁異なっているなら、ただその間の桁数にすればいい。1(=100)と100(=102)なら10(=101)ということだ。
・桁が一桁異なっているなら、下の桁を採用して3を掛ける。たとえば10と100なら30になる。本当は10=3.16227766だから、√(10×100) = √(101×102) =√(10)×101=31.62…くらいになるのだが、最上位の一桁だけわかればいいという方針だから30でいい。
三桁以上異なっている場合も上記に準ずる。つまり、
偶数桁の異なる場合は「二桁異なる場合」と同様、桁数の算術平均をとる。10(=101)と100000(=105)なら、(1+5)/2=3桁となり、1000(=103)となる。
奇数桁異なる場合は「一桁異なる場合」を参考に、10(=101)と10000(=104)だと、(1+4)/2=2.5だから、低い方の2桁を採用して、3を掛ける、つまり300(=3×102)となる。
2 問題を分割する
いわゆるDivide and conquer (D&C)(分割して征服せよ)の原則が用いられる。
取り付く島のない問題も、分割していくことで取り扱うことができるようになる。
手順として書き出せば、
(1)問題に関係ありそうな事実を書き出す
(2)一つかできればそれ以上の推定の方針をつくる
(3)問題を分割して推定の階層構造をつくる
(4)知らなければならない質問をリストアップする
という感じになる。
みんなが大好きな問題「シカゴにピアノの調律師は何人いるか?」を例にして、各ステップを説明しよう。
(1)問題に関係ありそうな事実を書き出す
関係ありそう、というかど真ん中にある事実はまず「ピアノの調律師はピアノを調律する」ことである。当たり前だ。
さらに「ピアノ」には所有者がいる。家庭にあるものもあれば、学校や(シカゴなら)教会にあるものも有るだろう。これらがピアノの所有者になりそうな人(組織)だ。
今回は、どれもシカゴという大都市にいる/ある「ピアノの調律師」「ピアノ」「家庭」「学校」「教会」について考えればいい。
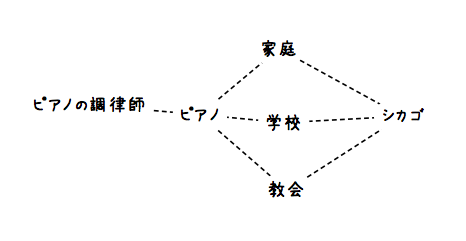
(2)一つかできればそれ以上の推定の方針をつくる
「ピアノの調律師の人数」と「ピアノの台数」を結びつけることはできるだろうか?
→ピアノの調律師が一人でどれくらいのピアノを調律するか分かれば、結び付けられそうだ。
「ピアノの台数」はどうすれば分かるだろうか?
「家庭の数」と「ピアノの台数」を結びつけることはできるだろうか?
「学校の数」と「ピアノの台数」を結びつけることはできるだろうか?
「教会の数」と「ピアノの台数」を結びつけることはできるだろうか?
→これらを全部足すとシカゴに有る「ピアノの台数」がわかりそうだ。
何からシカゴの「家庭の数」は分かるだろうか?→1世帯平均の人数が分かれば何とかなりそう。
何からシカゴの「学校の数」は分かるだろうか?→子供の数と1校あたりの平均的な生徒数が分かれば。
何からシカゴの「教会の数」は分かるだろうか?→よく分からない。今回は無視して計算しよう。
上記は「ピアノ台数」と「調律に必要な時間」から考えるアプローチだが、他にも、シカゴ全体で調律に支払われる代金総額からそれで食っていける調律師の数を割り出すなど、いくらもアプローチがあり得る。
(3)問題を分割して推定の階層構造をつくる
(2)でうだうだ考えたことを樹形図にまとめてみるとこんなふうになる。
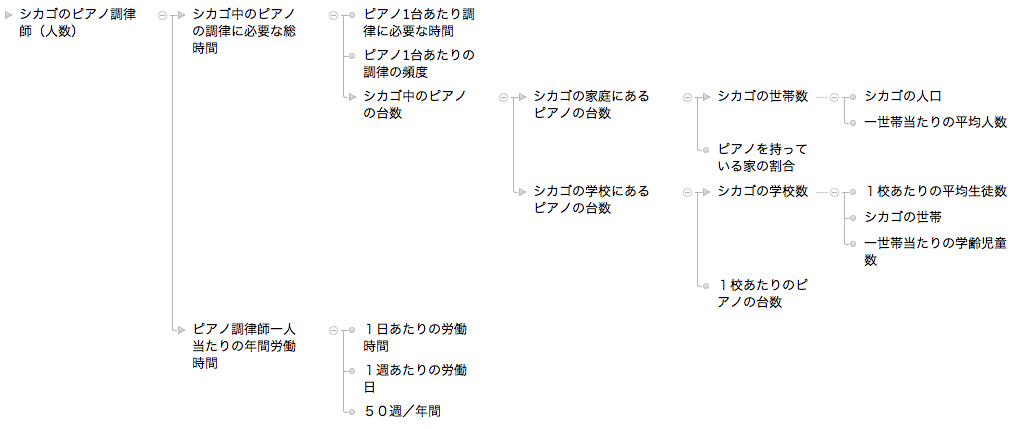
(クリックで拡大)
実際の作業は、(2)の段階を今回はアウトラインプロセッサーの上に問いと答えを順不同で書き出してから、(3)の作業として、並べ替えたり階層付けしたりして、上位下位関係を整理していった。
上の図は、「Tree」という通常のアウトライン表示とツリー(樹形樹)表示を切り替えられる、Mac用アウトラインプロセッサで整理したものを〈ツリー表示〉して作成した。
(4)知らなければならない質問
知らなくてはならないのは、推定階層図の先っぽ、葉に当たる部分の数値である。
これを埋めるために「3 分かる数値・知識をつかう」や「4 分からない数値は上限と下限を考える」へ進む。
◯推定階層図(樹形図)のメリット
正直、ピアノの調律師の数を計算する程度のシンプルな問題だと、わざわざ推定階層図を書くのは面倒くさい。
「5分で答えろ」といった就職面接のシーンだと書いていられないというのもある。
しかしせっかく就職面接用brainteasersという悪用から解放されたのだから、すこし丁寧にやってみたい。
推定階層図を書くと、まずどんな具合に推定を組み合わせたか、自分にも他人にも分かりやすい。
どこが根拠が弱い・根拠を欠いた推定かも、すぐ分かる。
いい加減に問題を分割した場合や、乱暴な決め付けで済ませた部分も明確に残る。
時間をおいて推定を見直した場合も、何をやっていたか分かりやすい。
時間をおくと弱点(乱暴な決め付けなど)にも気付きやすい。
思考の跡が残るということは、経験が蓄積しやすい・上達しやすいということでもある。
そして複雑な問題になっても、何をどこまで分解したか、常に把握しながら進められる。
試行錯誤しても、その過程が無駄にならない。
ワーキング・メモリを余計なところで消耗することを防ぎ、問題解決そのものに認知リソースを回しやすい。
とくに複数のアプローチをとる場合は、それだけ推定構造は大規模化・複雑化するから、推定階層図が助けになる。
3 分かる数値・知識をつかう
推定階層図が(ちゃんと書き出すか、頭の中だけでやるかは別にして)できれば、あとは推定階層図の先っぽ、葉に当たる部分の数値を埋めていけば、最終的な答え(推定)は出るはずである。
数値が分からないところは、さらに問題を分割して、推定階層図の枝を広げていくべきかもしれない。
後で触れることだが、この宇宙を量的に把握しようとすれば、宇宙の諸相をあらわす様々な数量は互いに連関していることが分かる。
このおかげで、ある数量(たとえば原子の大きさが概ね10-10mであること)が分かれば、それに関連する様々な数量を推定することができるようになる。
多くの物理定数は、そうした数量間の関連の結束点であると見なすことができる。
しかし、もし手がかりになる数量を知らなければ、資料など外部リソースがなければ、どれだけ分割しても分かる数値に行きつけない場合も多い。
そういう場合はもう手がないのだろうか? いろんな数値をあらかじめ知っておかなくては結局、推定なんてできないのだろうか?
たとえば「シカゴの人口」が分からないと、先の「ピアノの調律師の数」を推定する問題は解けないのだろうか?
否、否、三たび否。
4 分からない数値は上限と下限を考える
そのものずばりの数値は分からなくても「さすがに多すぎる」「いくらなんでも少なすぎる」と分かることは多い。
今の「シカゴの人口」だと、確かに何人かは分からないが、しかしシカゴはどこかの寒村ではなく、結構な大都市であることは、何となく分かる。
こうした場合、我々がおぼろげながら知っていることを、間違ってはいない程度に正しい数量に落とし込む方法がある。
分かる範囲でその上限と下限を考えてみるのである。
我々が知りたいのは、つまるところ桁数であったことを思い出そう。
「シカゴの人口」の例を続けよう。
まず下限を考える。シカゴの人口が、何十万人(=105)というのは、どうにも少なすぎる。というのも、何十万人では、いくらもある普通の地方都市レベルだからだ。
次に上限を考える。桁違いな数字を考えて、何千万人(=107人)ではどうか? いや、これは多すぎる。これだと世界にいくつかしかない屈指の都市レベルになってしまう。
そこで下限と上限を設定し、シカゴの人口は100万人~1000万人の間にある、と仮定しよう。
我々は桁数に関心があるから、100万と1000万の間をとるのに幾何平均を使う。
√(106×107)を計算するわけだが、先ほど触れた簡易法をつかってざっくり300万人だとしても、我々が求める精度では問題ない。
これでシカゴの人口が、極めて大雑把にだが見積もれた。
この方法は、桁数が分かればいい、という割り切りから導き出されるものだが、とても活用範囲が広い。
基本となる数値がわからないときは、多くの場合、この方法で切り抜けられる。
そして、分からない数量をエイヤッとダイレクトにあてずっぽうするよりも、慎重かつシステマティックであり、実際もましな概数値が得られることが多い。
さらに「シカゴのピアノ調律師」の例をつづけると、たとえば1世帯あたりの平均人数が分からないとする。
今の方法を用いるなら、
下限:1人(単身者世帯ってある。それもけっこうある)
上限:10人(何十人って家族はいまどきは珍しい。都市だともっと珍しい)
1と10の幾何平均をとって3人を平均世帯数として採用する。 (√(1×10)≈3)。
5 分割した推定を掛け合わせて答えを出す
こうして推定階層図に数値を入れていくと、次のようになる。
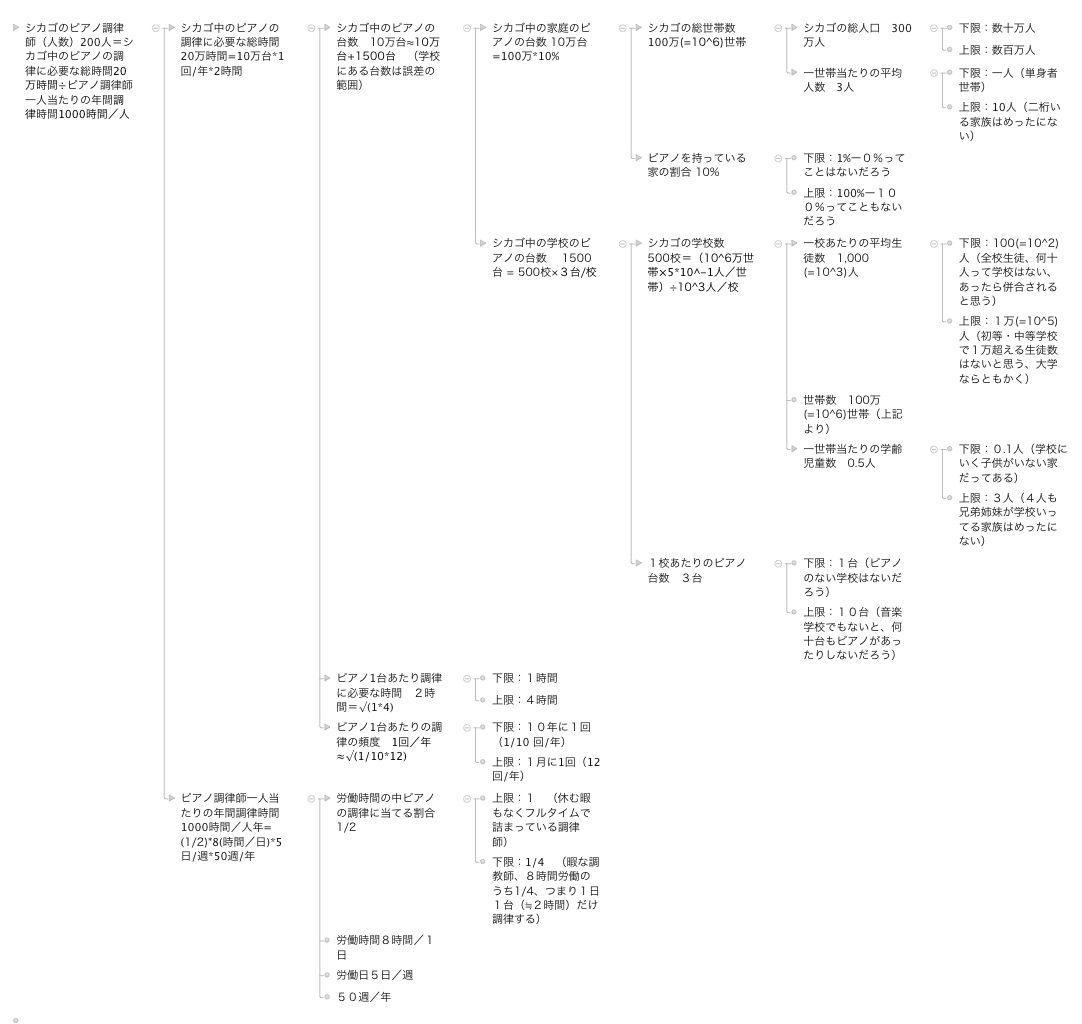
(クリックで拡大)
結局、シカゴには200人のピアノの調律師がいると推定した。
学校の数を500校と推測したが、学校にあるピアノの台数(1500台=3台/校×500校)は、今回、家庭が持っている台数に比べて、我々が知りたい精度でいうと、無視できるくらい少なかった。最初からピアノを持っているのは家庭だけと考えるアプローチも今回のような目的なら十分あり得るといえる。
もちろん家庭が持っている数がずっと少ないと、学校や教会が持っているピアノの台数も無視できなくなってくる。
当初の推定階層図から変更したのは、1日8時間労働として、全ての調律師が切れ間なく調律し続けるってのはどうだろうと思ったので(調律してない時間って結構あるんじゃないだろうか)、そこのところを追加した。
結局、8時間労働の内、忙しい人も暇な人も合わせて平均すると4時間ぐらいだろうとしたが、もしフルタイム可動だと推定は100人になる(推定階層図があるので、変更してどうなるかもすぐ分かる)。
1~2×102人だから、オーダー推定的には大した差ではない。
6 推定をチェックする
推定結果は、最後にチェックしておきたい。
(1)単位のチェック
単位付きで計算しておくと計算過程でもミスしにくい(ミスしても気づきやすい)が、それだけでなく、最後に求めたかった単位が出てくるかどうかで、推定の階層構造がおかしくないか最低限のチェックができる。
(2)上限下限のチェック
たとえば、今回の場合だと、最後に出てくる調律師の人数が、シカゴ全体の人口を超えていたりすると、どう考えてもおかしい。
そこまで行かなくても、ピアノ台数より調律師の数が多くなったりすれば、調律師は1年に1台の調律で食っていく訳で、その料金は年収レベルになるか調律師はみな他の商売で食っているかになるから、これもおかしいことになる。
先に触れた「調律料金~養える調律師の数」を考えるアプローチも合わせて行っていれば、こうした別アプローチが推定の妥当性のチェックの役割も担ってくれる。
複数アプローチをお勧めするのは、こうした理由からである。
最後に実際の数字を紹介しておこう。
シカゴの人口271万人、公立学校数は638校、ピアノ調律師は分からなかったが、すこし広げてmusical instrument repaires and tuners だと290人だった。
オーダー推定的には1/10~10倍の誤差は許容範囲だが、今回はちょっと出来過ぎた結果となった。
(おまけ)オーダー推定の例
ピアノ調律師やマンホールの数ばかり考えても仕方がないから(脈絡なく鉄球の落下速度を計算させられる授業がつまらないように)、趣向の違った例題を見てみよう。
科学や工学の分野で取り組まれてきた方法だから、ほんの少し科学や工学の知識を使うだけで、取り組める問題の幅は一気に広がる(逆に言うと、面接試験のはこの辺を削ぎ落とすから、空虚な数当てゲームに限定されてしまうともいえる)。
科学教育の分野で用いられるのは、そうした例が多い。
たとえば物理定数や公式など、暗記してもらおうとしても埒が明かないが、それらを使ってちょっとした問題を解いてもらうと忘れられなくなる。
科学は世界を量と量の関係として捉えることで発展した。科学が扱う様々な数量は互いに連関しあっていて、他の量と無関係に変動したりしない。だからこそ、数量の間の連関を辿って、我々は定量的に予測したり評価したりすることができる。
オーダー推定は、大股歩きではあるが、そうした量の相互関連をたどっていく体験である。
◯人の細胞中にDNAをつなげると何メートルになるか?
我々より小さな大きさで、知っておくと適用範囲が広がる数量が登場する例を取り上げよう(一度やっておくと原子の大きさや細胞の大きさを忘れなくなるので)。
原子の直径は、1~5×10-10 mである(注)。オーダーで言えば、10-10 mである。
(注)こういうことを調べるにはもってこいのサイトThe Physics Factbookから、「Diameter of an Atom」のページを見た。
これを元にして、人の細胞の中にあるDNAをつなげるとどれくらいになるかを推定したい。
(1)問題に関係ありそうな事実を書き出す
あなたがDNAについて知っていることは、それほど多くない。しかし何も知らないわけではない。
以下のような事実を知っている(前提にできる)としよう。
・人の体は細胞が集まって出来ている
・細胞はその中に核をもっている
・DNAは核の中に収められている
・DNAは塩基対が集まって出来ている
・塩基対は、原子が集まって出来ている
まとめて書くと「人間>細胞>核>DNA>塩基対>原子」という感じである。
(2)一つかできればそれ以上の推定の方針をつくる
何とかわかりそうなのは、大きい方と小さい方、すなわち人間の大きさ(体積)と原子の大きさである。
なので、トンネルを両側から掘るように、最大のものと最小のものの両側から挟み込むようにアプローチする。
(3)問題を分割して推定の階層構造をつくる
(4)知らなければならない質問をリストアップする
をやった結果、わからないところは上限・下限を考えて幾何平均で推定して、数値まで入れたのが次の推定構造図である。

(クリックで拡大)
鍵となるのは、推定構造図の枝の先にあたる「細胞の大きさ」と「塩基対を構成する原子の数」である。
「細胞の大きさ」は、目には見えないこと(0.1mm(=10-4m、細い髪の毛の太さ)くらいなら何とか見えるからそれより小さい)、しかし最初期の顕微鏡(倍率はよくて100倍程度)では見えたことから小さくても10-4×10-2=10-6mくらいだと考え、これを下限と上限に幾何平均をとった。
結果、人の細胞中にDNAをつなげると約1メートルになることが推定される。
ほんとに便利なサイト、The Physics Factbookで「Length of a Human DNA Molecule」というページを見ると、人の細胞中にDNAをつなげると1.5〜3メートルとある。
◯タバコ1本あたりどれだけ寿命が短くなるか?
ちゃんと答えるには大規模な疫学調査が必要な問題も、大雑把になら見当をつけることができる。

(クリックで拡大)
「タバコの毒で直接死ぬというより肺がんなど病気にかかりやすくするのが、喫煙が命を縮める主たる理由だろう」というぼんやりした考えを元にして、「中年以降に死亡原因となる病気にかかりやすくなるだろう」というぼんやりした予想から、
・上限「ワーストケースとして40歳で肺がんになり死ぬとして、ベストケースで本当は80歳まで生きることができたはずだったとすると」
・下限「1年未満しか寿命が縮まないような軽微な影響だとすると、盛んに禁煙を勧めたり禁止したりする理由が立たないので」
として幾何平均をとり、タバコによる寿命短縮をざっくり√(1*40) ≒ 6年としたのが、この推定の中心である。
British Medical Journalに掲載された、そのままズバリの論文※によれば、喫煙者と非喫煙者の平均余命の差は6.5年とされている。
※Shaw, M., Mitchell, R., & Dorling, D. (2000). Time for a smoke? One cigarette reduces your life by 11 minutes. British Medical Journal, 320(7226), 53-53. (リンク)
◯1万人規模のイベントで仮設トイレは何個必要か?
ほんのり実用的(?)な問題もとりあげてみよう。
この問題を考えるには、待ち行列理論を使うにしても
・利用者はどれだけの頻度でトイレにやってくるか?
・一人当りどれだけの時間トイレを使用するか?
・待ち時間が出るとして、どれくらいの時間なら許容できるか?
などのデータが必要だが、これらを調べることなしに大雑把にでも推定することは可能だろうか?
ここでは2つの強力な(強引な)仮定をおいて、推定を可能にしている。
ひとつは【平均人の仮定】である。これは、「私(推定者)がある行動をする頻度は平均的である」というものである。
例えば、もし私が一日に平均10分間トイレを利用しているならば、十分に大きな人数について調べれば(10分以上の人も以下の人ももちろんいるだろうが)そのトイレの平均利用時間はやはり10分になる、と考えるのである。
もうひとつの仮定は【一様分布の仮定】である。これは、「人がある行為をする確率はある期間では一定である」という仮定である。
例えば、十分に大きな人数について調べれば、トイレは行くタイミングは均等にバラけており、特別に混雑する時間や閑散とする時間はない、と考えるのである。
これらの強力な仮定を置くことで、私(推定者)がトイレにいく頻度が分かれば、それをそのまま十分に大きな集団に適用できることになる。
私がトイレにいる平均時間がはっきりしないが、ここでは
・下限5分間:1回最低1分としても5回くらいは行く
・上限100分間:1日1時間半もトイレにはいない
として幾何平均をとり、私が1日のうちトイレにいる時間20分(起きている時間16時間≈1440分のうちの1/72)とした。
ここから必要なトイレの個数を1万人×1/70(70人につき1個)≈130個とした。

(クリックで拡大)
この推定の問題点は、休憩時間が決まっていて、その時間に利用者が集中するコンサートやスポーツのようなイベントは想定していないことである。
「仮設トイレの設置数はイベントの内容で条件が大きく変わるため必要数の算定方法がない」(出典:信濃毎日新聞 1996年6月27日)ようだが、災害用の仮設トイレ設置の基準だと、次のようになっている。
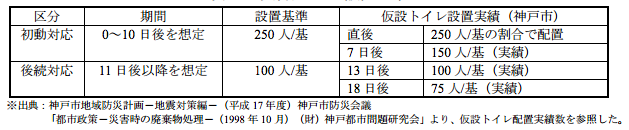
なお、利用者数に応じたトイレの利用者数の想定においては、日本だと、社団法人空気調和衛生工学会(HASS)による適正な衛生器具数の算定法※が広く用いられるが、休憩時間に利用が集中すると考えられるホール・劇場について、トイレの適正器具数の算定法について、リンク先(pdfファイル)を参照。
※空気調和衛生工学会規格(SHASE-S206)にて算定方法(技術要領「衛生器具の設置個数」)が示されている。
(参考文献)
○Swartz, C. E. (1972). Used math for the first two years of college science. Englewood Cliffs, N.J: Prentice-Hall.
 | Used Math for the First Two Years of College Science Swartz Amer Assn of Physics Teachers Amazonで詳しく見る |
オーダー推定やBack-of-the-Envelope (BotE) Reasoningに関する文献をたどっていくと、Clifford Swartzのこの書物に行き着く。
シュワルツは高校・大学の物理教員向けの専門誌The Physics Teacherの編集長を30年近くつとめ、この後も"A search for order in the physical universe"(1974)や"Back-of-the-Envelope Physics"(2003)という書物を著している。
"Back-of-the-Envelope Physics"はブルーバックスから以下の翻訳が出ている。
 | 物理がわかる実例計算101選 (ブルーバックス) クリフォード・スワルツ,園田 英徳 講談社 売り上げランキング : 85116 Amazonで詳しく見る |
○Harte, J. (1988). Considere a spherical cow: A course in environmental problem solving. Mill Valley, Calif: University Science Books.
 | Consider a Spherical Cow John Harte W.Kaufmann,U.S. 売り上げランキング : 1702290 Amazonで詳しく見る |
物質循環(生物地球化学サイクル)を中心とした環境科学について、Back-of-the-Envelopeで考える教科書。
原著タイトルを直訳するなら「牛(の形)が球であると仮定しよう」。
アメリカの大学関係者の間に伝わる次のようなフォークロアが元になっている。
牛乳の生産性が低かった酪農家が地域の大学に支援を得られるよう手紙を書いた。
早速、教授たちからなる学際的なサポートチームが結成され、二週間に渡る徹底的な現地調査が行われた。
データでいっぱいになったノートを持って学者たちは大学に戻り、最後に報告書作成の任務がチームリーダーの理論物理学者に委ねられた。
しばらくして酪農家は、大学から報告書を受け取った。
報告書は、酪農家にとって命の次に大切な牛について次のような記述で始まっていた。
「Considere a spherical cow.(牛(の形)が球であると仮定しよう)・・・」
報告書を受け取った、酪農家のなんとも言えない顔が思い浮かぶ。
この口伝を伝えた人はおそらく「理論(家)は実社会の役にたたない」という教訓を込めたと思われる。
しかしハートは、これを逆手にとり、問題解決のためには本質を変えることなく不要な詳細をうまく捨てて問題を単純化する必要があることを示す、モットーにした。
この書にはHarte, J. (2001). Consider a cylindrical cow: More adventures in environmental problem solving. Sausalito, Calif: University Science Books.(牛を円筒であると仮定しよう)という続編があり、この2冊はそれぞれCow-1、Cow-2という略称で呼ばれている。
Cow-1については(チャーミングなタイトルが見る影もなくなっているのが残念だが)、以下の邦訳がある。
 | 環境問題の数理科学入門 J. ハート,小沼 通二,蛯名 邦禎 丸善出版 売り上げランキング : 111745 Amazonで詳しく見る |
○Weinstein, L., & Adam, J. A. (2008). Guesstimation: Solving the world's problems on the back of a cocktail napkin. Princeton, N.J: Princeton University Press.
 | Guesstimation: Solving the World's Problems on the Back of a Cocktail Napkin Lawrence Weinstein,John A. Adam Princeton University Press Amazonで詳しく見る |
タイトルのGuesstimation(Guesstimate)は、1934~35年ぐらいにつくられた、guess(推測する)とestimate(見積もる)のかばん語(混成語)。
オールドドミニオン大学でPhysics on the Back of an Envelopeのコースを担当していたワインシュタインは、収集した膨大な推定問題をネットでも公開していた(そのアーカイブ)。問題収集の協力者の一人、同僚で数学者のジョン・アダムスと共著で書いたのがこの書。
日常の問題からはじめて、科学的な問題に入っていく。幾何平均を使うテクニックも紹介している。
これにもWeinstein, L. (2012). Guesstimation 2.0: Solving today's problems on the back of a napkin. Princeton, N.J: Princeton University Press.という続編がある。
Guesstimationの方には、次の邦訳がある。
 | サイエンス脳のための フェルミ推定力養成ドリル ローレンス・ワインシュタイン,ジョン・A・アダム,山下 優子,生田 りえ子 日経BP社 売り上げランキング : 15669 Amazonで詳しく見る |
(参考サイト)
◯A View from the Back of the Envelope http://www.vendian.org/envelope/
Back-of-the-Envelope (BotE) Reasoningを含む、approximation(近似法)を扱った、最も浩瀚なサイト。
「Scaling the universe to your desktop」や「How Big Are Things?」は予備知識無しに楽しむことができるだろう。
ネット上のリソースから書籍、論文から絵本まで、大抵のものはこのサイトからたどることができる。
◯Science Plympics - Fermi Questions
274のフェルミ問題のリスト
◯ Wolfram Alpha
言わずと知れたウルフラム・リサーチ開発の質問応答システム。
いわゆるフェルミ問題をそのまま投げても(英語なら)、次のような感じでガチな答えを返してくれるので、自分でやってみた後の〈答え合わせ〉に使える。
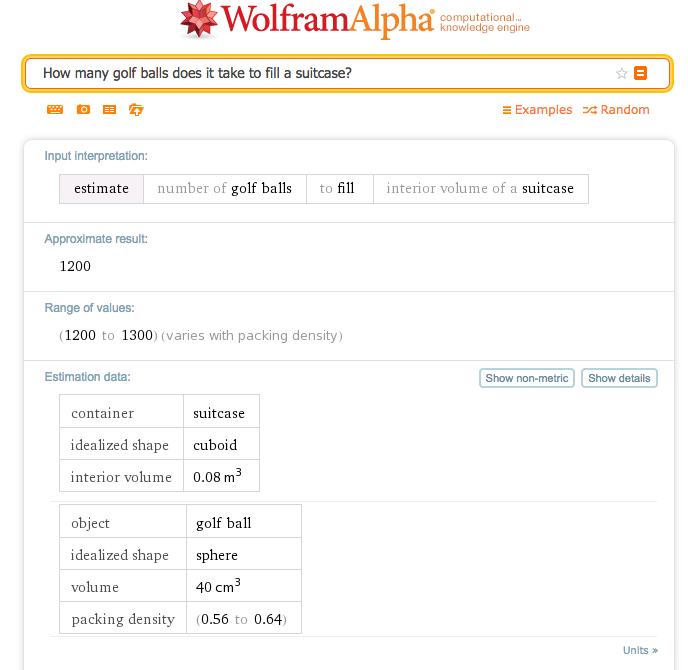
それもただの答えでなく、[show detail]をクリックすると、概数を出した考え方まで表示してくれる。すげえ。



◯仕掛けのあるバスタブ
少女:わー、ちっちゃいお風呂。禁煙さん、それ何ですか? ドール・ハウスの?
禁煙:ああ、これ。ううん、教材。友達に作ってもらったの。

少女:小さい蛇口もついてるんですね。……教材って何の?
禁煙:小学生に微分方程式を体験してもらう教材なの。
少女:ええっ、微分どころか方程式も習ってないんですよ。
禁煙:むかしシーモア・パパートって人も、数学をさんざん習わないと微分方程式にたどり着けないなんてダメすぎる、小さい子どもこそ味わうべきなんだ、といつも言ってたわ(それでLOGOってコンピュータ言語を作ったのだけど)。
少女:じゃあ、私にも分かりますか?
禁煙:試しに遊んでみる? デジタル表示が三つついているでしょ。
少女:はい。〈入る蛇口〉と〈出る蛇口〉と、あと〈バスタブ〉って書いてあります。
禁煙:〈バスタブ〉の数字は、文字通りバスタブに今入っている水の量を表してるの。〈入る蛇口〉の数字は1秒間にバスタブに水が入ってくる量を表してて、〈出る蛇口〉の方で1秒間にバスタブから水が出ていく量ね。二つの蛇口は、どちらも数値をセットすれば、入ってくる量/出ていく量を決められるの。
少女:わかります。
禁煙:あと毎回写実的(?)に描くと大変だから、簡略化した描き方をするわね。四角の箱が〈バスタブ〉、〈バスタブ〉に入ってくる矢印の真ん中にある小さな三角形の頭を付き合わせたようなのが〈入る蛇口〉を表してると思ってね。〈バスタブ〉から出ていく矢印についてるのが〈出る蛇口〉ね。

少女:説明おしまい?
禁煙:まだ少しあるけれど、あとはキッチンに持っていって実際に動かしながらにしましょうか。
少女:じゃあ〈入る蛇口〉を10にセットします。〈出る蛇口〉はゼロで。このバスタブ、何リットル入るんですか?

禁煙:1リットルで、この表示だと1000で一杯ね。
少女:じゃあ、1000÷10=100だから、水を入れ始めて100秒後にバスタブは一杯になります。

禁煙:じゃあ〈入る蛇口〉を10、〈出る蛇口〉を6にセットしましょう。

少女:入ってくるのが1秒あたり10で、出ていくのが1秒当たり6だから10-6=4で、1秒当たり4だけ増えます。1000÷4=250だから、250秒後にバスタブは一杯になります。……で?
◯指数関数的減少のモデル
禁煙:確かにこれだけだと、あまりにもつまらないわね。
少女:小さい頃に、こういう問題やった気がします。
禁煙:そこで取り出したのが、このコード。蛇口の裏に差し込むところがあるんだけど。
少女:何に使うんですか?
禁煙:〈入る蛇口〉や〈出る蛇口〉の数字は、今は人間がセットしてそのまま変わらなかったけれど、このコードをつなぐと、その数字を刻々とセットしなおしてくれる、というかコントロールしてくれるの。…バスタブは一杯になったかしら。
少女:なりました。
禁煙:〈バスタブ〉から〈出る蛇口〉へコードをつないで、〈バスタブ〉=バスタブの水の量が減るにしたがって〈出る蛇口〉も減らすようにしてみるわ。
少女:こんな感じですか?

禁煙:ええ。……はい、これを使って。
少女:何ですか? タイマー?
禁煙:1秒間隔でピッ、ピッと鳴らすわね。子どもたちには班に分かれてもらって、時間を計る役と、1秒ごとに〈バスタブ〉の表示を読み上げる役と、書き取る役を分担して、どんな風に水が減っていくかグラフを書いてもらうんだけど。
少女:確かに一人でやるのは大変です。……できました、こんな感じですか。


禁煙:うん、なかなか。実は今のが、応用例をいっぱい載せてる本なら、最初の方に出てくる微分方程式を、バスタブで表したものなの。
少女:え、どこが?
禁煙:見かけはずいぶん違っているけどね。今のモデルのポイントは、「水が減っていく速さは、バスタブに残っている水の量に比例する」ってこと。バスタブに入っている水の量をグラフにすると、最初は急な下り坂だけどだんだんなだらかになっていってるよね。
少女:応用例って言ったけど、今のは何かの役に立つんですか?
禁煙:たくさんあるけど、たとえば薬の血中濃度の変化のモデルで服用計画を考えたり、物の冷め方(温度の変化)のモデルで死亡推定時刻を計算したり。薬を服用してすぐで血中濃度が高いほど、その変化(下がり方)は激しいし、熱いモノほど温度は速く下がってしまうの。
少女:だから右下がりのグラフはだんだんゆるやかになるんですね。
禁煙:あとダイエットとかもそうね。同じ努力をしても体重が減るほど、減り方はゆるやかになる(下のグラフの青線)。ヒトは無意識に同じ努力には同じ結果が出るはずだと、グラフで言うと直線で描ける変化をイメージしてしまう(下のグラフの赤線)から、しばらくダイエットを続けていると効果がなくなったと思ってやる気がくじけちゃう。ほんとはちゃんと同じだけ効いてるからこそ、そういう変化になるんだけど。

少女:ええっ、これって学校で教えた方がいいんじゃ。
禁煙:ん?食いついた?
少女:というか、微分方程式というより、それって「残っている量に比例して減っていく」現象のモデルなんじゃ?
禁煙:ええ、そのとおり。だからいろんなところにこの種の現象は見つかるわ、自然にも社会にも。モデルとしてはとてもシンプルだけど、ダイエッターが勘違いするように、ヒトの量の感覚とは異なるものだから、数学の使い甲斐があるところなのだけれど。
◯指数関数的増加のモデル
少女:バスタブで作れるモデルって他にもあるんですか?
禁煙:ええ、もちろん。じゃあ今度は、〈バスタブ〉から〈入る蛇口〉へコードをつないで、バスタブの水の量が多いほど、ますます入ってくる水の量が増えるのを作ってみようか。

少女:これも何かの現象のモデルになるんですか。
禁煙:一番身近なのは複利計算かな。預金とか借金とか。
少女:まだ借金があるほどの甲斐性はないです。複利って何でしたっけ?
禁煙:たとえば一年間で1%の利子で100万円預けるとするわね。1年後には100万円の1%が利子となって加わり、預金残高は100+1=101万円に増える。次の年は、101万円の1%、つまり10,100円が利子にとなって加わり、預金残高は1,010,000+10,100=1,020,100円になる。……以下、繰り返しね。
少女:預金残高×利率=利子だから、預金残高=バスタブの水の量が多いほど、ますます入ってくる水の量が増えるちゃう。
禁煙:同じように1秒ごとに〈バスタブ〉の数字を書き取ってグラフにしてみて。
少女:今度はどんどんと坂がきつくなる上り坂みたいなのになりました。

禁煙:他には、「ネズミ算」って言葉があるけど、親ネズミの数に比例して子ネズミが生まれるとすると、ネズミが増えれば増えるほど、増え方が激しくなる。食料が十分な場合、生物はこんな増加の仕方をするわね。細菌とかホテイアオイとか。
少女:ホテイアオイって水草ですか?
禁煙:ええ。世界十大害草とか世界の外来侵入種ワースト100にも選ばれてて「青い悪魔」なんて呼ぶ人もあるくらい。寒さに弱くて冬はほとんど枯れるけど、ちょっとでも残っていると翌年にはまた大繁殖する。ああ池に少し浮いてるなあと思ってたら、いつの間にか池全面を覆っててびっくりしたりしない? この種の現象も、ヒトの数量の感覚からすると意外に感じるから「ネズミ算」なんて特別な言い回しがあるのね。
◯日常感覚とそれ以上をつなぐ
少女:これも前に禁煙さんが言ってた、日常の感覚を越えたものだから数学が役に立つって場面ですか?
禁煙:ええ。今のところでポイントは、「預金残高が多いほどほど利子も多い」「親が多いほど、生まれる子も多い」ってところは日常の感覚の通りだってこと。
少女:バスタブ・モデルが、日常感覚とそれを越えたものをつないでる?
禁煙:そして微分方程式の役目も、バスタブ・モデルのそれと同じだってこと。なぜ物理法則をはじめとして、科学の基本方程式の多くが微分方程式で書かれているのか、ここに理由があるの。
少女:微分方程式が、日常感覚とそれを越えたものをつないでる? うーん、微分方程式を知らないから、それがどう日常感覚とつながっているのか分からないです。
禁煙:たとえば止まったものに力を加えると動き出すよね。それまで速度ゼロだったのに動くってことは加速したってこと。より強い力だとそれだけ大きく加速するし、より重いものだとそんなに加速しない。
少女:うーん、そこだけ取り出したら、確かに日常の感覚ですけど。
◯空気抵抗のない落下運動
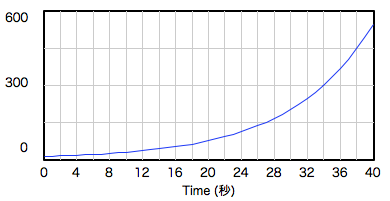
禁煙:たとえば空気抵抗がないところで物を落とすと、重力で引っ張られ続けるから、一定の度合いで速度は増加していく。速度が上がるってことは、1秒当たりに進む距離がどんどん増えていくってこと。さて、これのバスタブ・モデルをつくろうか。
少女:ええっ、見当もつかない。
禁煙:ちなみに速度が一定の割合で増加していくグラフはこんな感じ。

少女:一番最初のバスタブの水の量のグラフみたいですね。
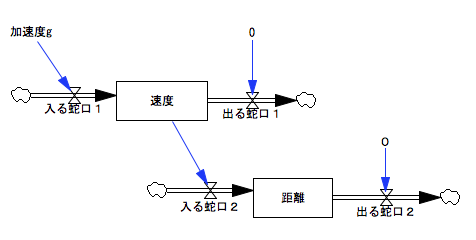
禁煙:ええ。一つ目のバスタブに〈速度〉って名札をつけておくわね。
少女:一定の割合で増加していくから、〈入る蛇口〉は最初に決めた数値に固定ですよね。どうしましょう?
禁煙:物を落とす話をしてたから、重力加速度にちなんで9.8にしときましょうか。
少女:速度がどんな風に増えていくかはバスタブ・モデルで表現できましたけど、この後は?
禁煙:ここにもうひとつバスタブを用意してみたわ。二つ目のバスタブに〈進んだ距離〉って名札をつけておくわね。
少女:あとは、このコードだけど、ふたつバスタブがあるから、コードでつなぐってことは予想がつくんですけど。あと、〈進んだ距離〉バスタブの〈入る蛇口〉ってまだ考えてなかったです。
禁煙:というか、それがほとんど答えね。
少女:そうか。貯まって〈進んだ距離〉になるものって……1秒あたり進む度合いって〈速度〉だもの。
〈進んだ距離〉バスタブの〈入る蛇口〉は速度だ。じゃあ、〈バスタブ〉に〈速度〉って名札をつけた一つ目のバスタブと、二つ目の〈入る蛇口〉をコードでつなぎます。

禁煙:じゃあ、バスタブ・モデルを動かしてみましょうか。二つ目のモデルの〈バスタブ〉の値を1秒ごとに記録してね。
少女:できました。

禁煙:これが世界最初の微分方程式だって人もいるわ。落体の運動を研究している時にガリレオが解いたんだけど。
◯空気抵抗のある落下運動
少女:学校では とかって、ガリレオが解いた結果だけを習いました。
とかって、ガリレオが解いた結果だけを習いました。
禁煙:数式のかたちで答えが得られると後で応用しやすいからね。でも、やぼったいバスタブ・モデルにもいいことがあるわ(といっても微分方程式なら当然できることだけど)。いまの2個のバスタブで作った落下運動のモデルだけど、コード1本追加すれば、「空気抵抗がある落下運動」のモデルに改造できるの。
少女:どうしたらいいんですか?
禁煙:ヒント。空気抵抗は、小さな物体がゆっくり動くときには、速度に比例すると考えていいの。速度が二倍になれば空気抵抗も二倍ね。
少女:空気抵抗って減速させるんですよね。今は一個目のバスタブに入っている水の量が速度を表してたから、このバスタブから出ていく=速度をおとすって考えればいいのかな?
禁煙:そのとおり。
少女:じゃあ、〈速度〉って名札をつけたから〈出る蛇口1〉へコードをつなぎます。

禁煙:大正解。じゃあ、またグラフを書いてもらえる? 今度は速度がどんなふうに変化するかを知りたいから、〈速度〉って名札をつけた〈スタック〉の数値を1秒ごとに書きとめてね。

少女:こんなグラフになりました。速度の上がり方は最初は急だけど、どんどんなだらかになっていきますね。
禁煙:うん。高い雲から落ちてくる雨粒は、地上につくころはほとんど加速せずに(速度のグラフがずいぶんなだらかになったところね)、大きさによってだいたい同じ速度におちついて落ちてくるわ。直径1ミリメートルでは毎秒約4メートル、5ミリメートルでは毎秒約9メートルぐらいかしら。
少女:雨が突き刺さらなくてよかったです。
◯ダイエットとやる気のモデル
禁煙:せっかくバスタブを2つ使うモデルが出たから、値が増えたり減ったりを繰り返すモデルも作っておこうか。
少女:実はもうちょっと着いていけなくなってるんですけど。
禁煙:普通はバネの話なんかするんだけど、せっかくだしリバウンドのモデルにしようね。
少女:えっ、狙い撃ち?
禁煙:1つめのバスタブに〈超過体重〉という名札をつけましょう。
少女:超過体重って?
禁煙:理想体重よりどれだけ重いかってこと。当然、理想体重より軽くなったら超過体重としてはマイナスにあるわ。
少女:えーと、バスタブだからマイナスの数とか表せないんじゃ?
禁煙:ほんとはね。少しズルをして、バスタブのデジタル表示をいじってちょうど半分水が入ったときに0と表示するようにしておくの。こうすつとー500から+500までの数字が扱えるわ。
少女:もう一つのバスタブは?
禁煙:〈やる気〉という名札をつけておきましょうか。こちらもマイナスの値が扱えるようにしておくの。
少女:ダイエットのやる気ってことですか?
禁煙:やる気が高いときはダイエットに一生懸命取り組むから体重の減り方が大きい、と考えるのはいいかしら?
少女:ええ。
禁煙:ではもうひとつ。現実的にはもっといろいろありそうだけど、ここは単純に、体重が重いほどより強く動機付けられてやる気も高まる、と考えましょうか。逆に体重が軽くなってくるとやる気も減ってく、ってことね。
少女:じゃあ〈やる気〉のバスタブから〈体重減少〉の蛇口へコードをつなぎます。それから〈超過体重〉のバスタブから〈やる気増加〉の蛇口へもコードをつないで、と。これでいいですか。

禁煙:これもグラフを描いてみましょうか。
少女:体重もやる気も上がったり下がったりを繰り返すグラフになりました。体重のアップダウンをやる気のアップダウンが追いかけてるみたい。あ、でも、これ……

禁煙:なあに?
少女:今のバスタブ・モデルには、さっき出た〈体重が減るほど減り方がゆるやかになる〉って話が入ってませんよね?
禁煙:じゃあ、さっきみたいに〈超過体重〉のバスタブから〈体重減少〉の蛇口にコードをつなぎましょうか。

少女:うーん、こんなグラフになりました。やっぱり体重のアップダウンをやる気が追いかけてるんですけど、アップダウンは同じ大きさじゃなくて形もなんか違いますね。ちょっと言葉で言い表すのは難しいです。

禁煙:このあたりまで来ると、自然言語でなかなか表現できないから、モデルを使って考える甲斐があるって思わない?
◯バスタブ・モデルの正体
少女:バスタブやコードを増やせば、もっと複雑なモデルも作れますか。
禁煙:ええ。たとえばさっきの、2つのバスタブで速度と位置を表すモデルを組み合わせて、車間距離のシミュレーションとかね。

(クリックで拡大)
(岡野 道治他(1997)『理工系システムのモデリング学習 : STELLAによるシステム思考』牧野書店,星雲社 (発売), p78-79 図4-10,4-12を元にVensim PLE用に改変)
少女:えーと、速度と位置を表すバスタブ2つが1セットで、車1つ分なんですね。
禁煙:ええ。とりあえず3台分で作ってみたけれど、後続車は前の車の車間距離と速度の差を見てアクセルやブレーキを踏む(加速や減速する)けれど、車によって対応の遅れに差がある場合ね。先頭車は時速10キロから徐々に加速して、後続車はぶつからないように(「車の位置」のグラフが交差すると、そこでぶつかることになるんだけど)、速度を合わせていく感じになったわ。

(クリックで拡大)
禁煙:こんな風にどんどん組み合わせればいいって言えばいいんだけど、ただ弱点があってね。
少女:なんですか?
禁煙:マイナスの値が使えないってのはさっきのトリックで何とかなったけど、現実問題として水の量を計っているから精度がよくないの。あとバスタブやコードがたくさんになると扱いが大変だし、場所はとるし、今みたいに水浸しになるし。見た目もやってることもベタだから、その点は分かりやすいのだけど。
少女:やってることはシンプルなんだから、コンピュータの上でできたら、バスタブもコードもいくらでも増やせそうだけど。というか、もうあるんじゃないですか?
禁煙:ええ、実はね。アメリカにMIT(マサチューセッツ工科大学)って学校があるけど、60年以上も昔、電気工学の学生としてやってきたジェイ・ライト・フォレスターって人がいてね。戦争中、兵器に自動調整装置を応用する研究室で働いていて、その絡みで戦後も軍のためにコンピュータ(Whirlwind)を開発したり、半自動な防空システム(SAGE)をつくったりしたんだけど、大きなプロジェクトを経験したせいか、進歩を阻害するのは技術的な問題よりも組織運営の問題の方だって痛感したみたい。電気回路や自動調節装置を扱うやり方で組織のマネジメントをモデル化できないかと考え出したの。
少女:リーダーって大変なんですね。
禁煙:ちょうどある大企業で雇用が短い周期で上下する問題があって、みんなは「これは景気が上下するせいだ、つまり組織の外に原因があるから、一企業には解決不可能だ」って言い張ったんだけど、フォレスターさんはそのアップダウンは組織の内から生まれていることを証明したの。
少女:ダイエットのモデルから、体重とやる気のアップダウンが生まれたみたいに?
禁煙:このときのモデルづくりの方法が、やがて企業だけじゃなくて世界とか都市とかいろんなものに応用されるようになって、その後、システム・ダイナミクスと呼ばれるようになるのだけれど。今じゃアメリカだと高校生やもっと下の学校でもやってるみたい。
少女:フォレスターさんもバスタブを使ったんですか?
禁煙:もう少しだけ抽象化したものだったけどね。今日〈バスタブ〉と呼んでたものを〈レベル変数〉、〈蛇口〉と言ってたものを〈レイト変数〉、と言い換えれば、フォレスターさんたちが使った、システム・ダイナミクスでモデルを記述するストック・フロー・ダイアグラムになるわ。というより話は逆で、ストック・フロー・ダイアグラムの、日常的で身近な〈たとえ〉として使われるのがバスタブ・ダイヤグラムなんだけどね。もともとメタファーに過ぎなかったものを、調子に乗って作ってもらったの。
少女:フローと風呂(バス)をかけてるんですか?
禁煙:それは気付かなかったわ。珍しいね、オチは地口オチ?
少女:二秒で忘れて。……でも、これがなんで微分方程式と関係あるんですか?
禁煙:バスタブというメタファーの利点は、微分と積分を、(単位時間に)〈入ってくる/出て行く水の量〉と〈バスタブに貯まる水の量〉っていう日常的に目にするものに置き換えてくれることね。それぞれストックとフローを表しているから当然といえば当然だけど。
少女:ストックとフローってよく聞くけど、よく分かってない気がします。
禁煙:語れば長いけれど、例を上げておくとこんな感じかしら。
少女:じゃあどれがストックでどれがフローなのかを整理して、その間の関係を矢印で結べば、バスタブ・モデルが作れるってことですか。
禁煙:そう。しかも下の4つの表現(バスタブ、ストック・フロー・ダイアグラム、積分方程式、微分方程式)は、同じ内容を表してるの。

(from Sterman, J. (2000). Business dynamics: Systems thinking and modeling for a complex world. Boston: Irwin/McGraw-Hill. p.194 FIGURE 6-2 Four equivalent representations of stock and flow structure - Each representation contains precisely the same information.)
◯バスタブ・モデルをコンピュータ上で動かす
少女:えーと、つまりバスタブをつかって現象のモデルが作れたら、微分方程式も立てられるってことですか?
禁煙:あと、システム・ダイナミクスのソフトを使えば、手を濡らさずにシミュレーションもできちゃう。ダイアグラムをお絵かきすれば、あとはお任せできるソフトがSTELLA / iThinkとかPowerSimとかいくつかあるけど、今回はネットからダウンロードできて個人用・教育用なら無料で使えるVensim PLE(http://vensim.com/free-download/)というソフトを使ってみたんだけど。
少女:ああ、そういうのがあるから中学・高校でシステム・ダイナミクスできるのかな。実際、何してるんですか?
禁煙:「システム・ダイナミクス」って独立した教科があるんじゃなくて、他の科目の内容に結びついてるみたいね。理科や歴史の授業で、環境問題とか文明のモデルをつくったりはもちろんあるけど、今日みたいに数学の授業に使ったり、英語(日本の国語科みたいなの)では文学作品を読んだり。
少女:いや、文学にシミュレーションもバスタブもいらないでしょ?
禁煙:有名なのだと(MIT のオンライン教材集Road Maps: A Guide to Learning System Dynamicsにも採用されてる)、ハムレットが復讐心をこじらせて王さま(クローディアス)を殺すまでのモデルとか。見てのとおり、ストック(私たちがいうところのバスタブ)4つでできてるんだけど。

(クリックで拡大)
(Hopkins, P. L. “Simulating Hamlet in the Classroom”, System Dynamics Review V8 N1, Winter 1992を元にVensim PLE用に改変)
少女:いったい何の意味が?
禁煙:登場人物の感情の高まりを視覚化して時間的変遷を詳細に検討できるとかもあるけれど、一旦モデルを作ってしまえば、モデルやパラメーターを変更して「もし~だったら、どうなったか?」をいくらでも検討できる、というのも大きいわね。
少女:いやシェイクスピアをマルチエンディングにしても……。事業計画とか政策立案の話だったら、確かにそういうのが必要だってわかるんですけど。
禁煙:理解の仕方っていろいろあると思うけど、感情移入して追体験するのもひとつなら、対象にいろいろ働きかけて返ってきた反応を通して知るというのもひとつ。一目見ればわかるシンプルなものならいいけど、相手が複雑なものだと〈やり取り〉を通して分かることも多いって感じかしら。
少女:うーん、いままで文学とか苦手だった子には、ちょっとウケよさそうかな。
禁煙:実験する学問でも、やっている人にとっては、論文に書ける完成品の実験よりも、そこに至るまでのいわば試作品の実験を繰り返してるうちにいろいろ分かってくるものが大事ってところがあるけど。システム・ダイナミクスに限らず、この手のシミュレーションって、社会とか生態系とか実験が難しいもの相手の、実験の代用品ってところがあるの。
少女:あー、でも、なんかの現象からバスタブ・モデルを自分で組み立てられる気がしません。
禁煙:ご希望なら、モデルの作り方は別にやってもいいわね。
(参考文献)
高校の数学の先生が書いた、システム・ダイナミクス・ソフト(この本ではSTELLAを使用)を使った数学の授業の作り方。
Fisher, D. M., & High Performance Systems, Inc. (2001). Lessons in mathematics: A dynamic approach : with applications across the sciences. Lebanon, N.H.: isee Systems.
上の本が入手できなかったので、(だいぶ違うけど)次の本を参考にした。
なお、Diana M.Fisher の別著 Fisher, D., & isee systems (Firm). (2007). Modeling dynamic systems: Lessons for a first course. Lebanon, N.H.: isee systems. については以下の邦訳がある。
この分野の定番教科書。
以下は上の本の翻訳のはずだが、肝心のシミュレーションやモデリングについての記述をごっそり削除している(なんと1000ページを超える原著が500ページ未満の邦訳になるのだから、どれだけのものを省いたか)。
著者スターマンは「システム原型(system archetypes)だ、システム思考だなんて分かった気になってちゃダメ。普通の人は何本もある微分方程式を頭の中だけでは解けないんだから、ちゃんとシミュレーションしなきゃ。」と苦言を呈していたはずだが気のせいだったか。
ダイエット関連では次の文献を参考にした。ウェイト・マネジメントにシステム・ダイナミクスをガチに導入してる。
浅学非才のうえ寡聞にして、システム・ダイナミクスといえば自治体の作りっぱなしモデルとか『成長の限界』のあれとか大雑把なマクロ・モデルに違いないという(1970年代で時間が止まったような)偏見があったので、新鮮だった。
しかし考えてみれば、アウトカムはきっちり数値で出るし、関連する要因は生化学から社会行動まで多分野に渡るし、そのどれにもフィードバックがかかっているしで、システム・ダイナミクスで扱うにはうってつけのテーマである。
ひょっとすると、ちゃんとしたデータが揃いにくい資源・環境系や、実践しようと思えばエラくなるしかない経営系の事例よりも、この身一つあれば(あと体脂肪計付き体重計があれば、血糖値計があれば言うことなし)がんがん測れて実践できる(しかも不断に我が身に返ってくる=否応なくフィードバックしてくる)ウェイト・マネジメントの方が、システム・ダイナミクスの入門には適しているのではないかとさえ思えてきた。
Abdel-Hamid, T. K. (2009). Thinking in circles about obesity: Applying systems thinking to weight management. New York: Springer.
オンラインで読めるものでは
・U.S. Department of Energy's Introduction to System Dynamics
合衆国エネルギー省提供のオンラインブック。システム・ダイナミクスの歴史から基礎から説き語り。コンパクト。
・Road Maps A Guide to Learning System Dynamics
初等・中等教育におけるシステムダイナミックスの活用と学習者中心の学習を奨励・支援するCreative Learning Exchangeのサイトにある教材集。かなりのボリューム。
・System Dynamics Self Study - MIT OpenCourseWare
システム・ダイナミクスの総本山MITスローン経営大学院が提供する自習用オープンコースウェア。
(今回使ったソフトVensim PLEについて)
・個人・教育用なら無料で使える(よく本に付いてくるようなお試し版ではなく、モデルの作成も保存も自由にできる)WINDOWS版とMAC版がここからダウンロードできる。
http://vensim.com/free-download/
・マニュアルの邦訳やモデリング・ガイドなど、参考になる日本語ドキュメント(313頁もある)は日本未来研究センターの次のページからダウンロードできる。
http://www.muratopia.net/sd/documents/Vensim6UsersGuide.pdf
・本家のオンラインヘルプ(英語)はここ
https://www.vensim.com/documentation/index.html
・自分でシステム・ダイナミクスのモデルをつくるときに役立つ、よく使うパターンを集めたのがこれ。
なお、この文献にまとめられた全パターンをモデル・ファイルにしたものがVensim PLEにも付属している(Helpフォルダ>Modelフォルダ>Moleculesフォルダ内)。
Jim Hines(1996->2005), Molecules of Structure Building Blocks for System Dynamics Models.
http://www.systemswiki.org/images/a/a8/Molecule.pdf
・事例集 Tom Fiddaman's System Dynamics Model LibraryにはVensimでつくられた様々なモデル(資源・環境系と経営・経済系のモデルが多い)を集められている。
http://www.metasd.com/models/index.html
少女:わー、ちっちゃいお風呂。禁煙さん、それ何ですか? ドール・ハウスの?
禁煙:ああ、これ。ううん、教材。友達に作ってもらったの。
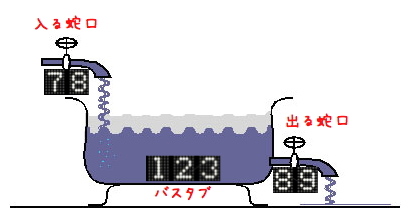
少女:小さい蛇口もついてるんですね。……教材って何の?
禁煙:小学生に微分方程式を体験してもらう教材なの。
少女:ええっ、微分どころか方程式も習ってないんですよ。
禁煙:むかしシーモア・パパートって人も、数学をさんざん習わないと微分方程式にたどり着けないなんてダメすぎる、小さい子どもこそ味わうべきなんだ、といつも言ってたわ(それでLOGOってコンピュータ言語を作ったのだけど)。
少女:じゃあ、私にも分かりますか?
禁煙:試しに遊んでみる? デジタル表示が三つついているでしょ。
少女:はい。〈入る蛇口〉と〈出る蛇口〉と、あと〈バスタブ〉って書いてあります。
禁煙:〈バスタブ〉の数字は、文字通りバスタブに今入っている水の量を表してるの。〈入る蛇口〉の数字は1秒間にバスタブに水が入ってくる量を表してて、〈出る蛇口〉の方で1秒間にバスタブから水が出ていく量ね。二つの蛇口は、どちらも数値をセットすれば、入ってくる量/出ていく量を決められるの。
少女:わかります。
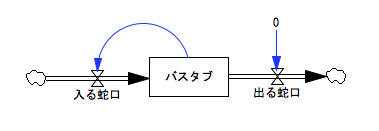
禁煙:あと毎回写実的(?)に描くと大変だから、簡略化した描き方をするわね。四角の箱が〈バスタブ〉、〈バスタブ〉に入ってくる矢印の真ん中にある小さな三角形の頭を付き合わせたようなのが〈入る蛇口〉を表してると思ってね。〈バスタブ〉から出ていく矢印についてるのが〈出る蛇口〉ね。

少女:説明おしまい?
禁煙:まだ少しあるけれど、あとはキッチンに持っていって実際に動かしながらにしましょうか。
少女:じゃあ〈入る蛇口〉を10にセットします。〈出る蛇口〉はゼロで。このバスタブ、何リットル入るんですか?

禁煙:1リットルで、この表示だと1000で一杯ね。
少女:じゃあ、1000÷10=100だから、水を入れ始めて100秒後にバスタブは一杯になります。
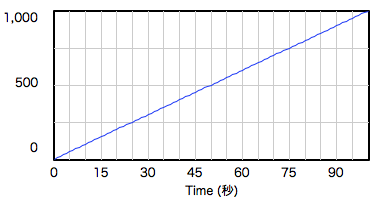
禁煙:じゃあ〈入る蛇口〉を10、〈出る蛇口〉を6にセットしましょう。
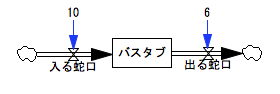
少女:入ってくるのが1秒あたり10で、出ていくのが1秒当たり6だから10-6=4で、1秒当たり4だけ増えます。1000÷4=250だから、250秒後にバスタブは一杯になります。……で?
◯指数関数的減少のモデル
禁煙:確かにこれだけだと、あまりにもつまらないわね。
少女:小さい頃に、こういう問題やった気がします。
禁煙:そこで取り出したのが、このコード。蛇口の裏に差し込むところがあるんだけど。
少女:何に使うんですか?
禁煙:〈入る蛇口〉や〈出る蛇口〉の数字は、今は人間がセットしてそのまま変わらなかったけれど、このコードをつなぐと、その数字を刻々とセットしなおしてくれる、というかコントロールしてくれるの。…バスタブは一杯になったかしら。
少女:なりました。
禁煙:〈バスタブ〉から〈出る蛇口〉へコードをつないで、〈バスタブ〉=バスタブの水の量が減るにしたがって〈出る蛇口〉も減らすようにしてみるわ。
少女:こんな感じですか?
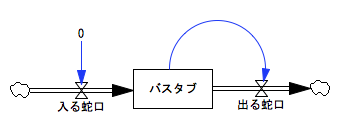
禁煙:ええ。……はい、これを使って。
少女:何ですか? タイマー?
禁煙:1秒間隔でピッ、ピッと鳴らすわね。子どもたちには班に分かれてもらって、時間を計る役と、1秒ごとに〈バスタブ〉の表示を読み上げる役と、書き取る役を分担して、どんな風に水が減っていくかグラフを書いてもらうんだけど。
少女:確かに一人でやるのは大変です。……できました、こんな感じですか。
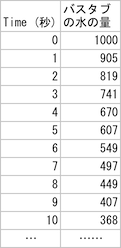
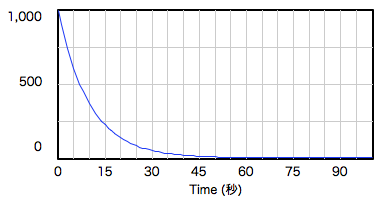
禁煙:うん、なかなか。実は今のが、応用例をいっぱい載せてる本なら、最初の方に出てくる微分方程式を、バスタブで表したものなの。
少女:え、どこが?
禁煙:見かけはずいぶん違っているけどね。今のモデルのポイントは、「水が減っていく速さは、バスタブに残っている水の量に比例する」ってこと。バスタブに入っている水の量をグラフにすると、最初は急な下り坂だけどだんだんなだらかになっていってるよね。
少女:応用例って言ったけど、今のは何かの役に立つんですか?
禁煙:たくさんあるけど、たとえば薬の血中濃度の変化のモデルで服用計画を考えたり、物の冷め方(温度の変化)のモデルで死亡推定時刻を計算したり。薬を服用してすぐで血中濃度が高いほど、その変化(下がり方)は激しいし、熱いモノほど温度は速く下がってしまうの。
少女:だから右下がりのグラフはだんだんゆるやかになるんですね。
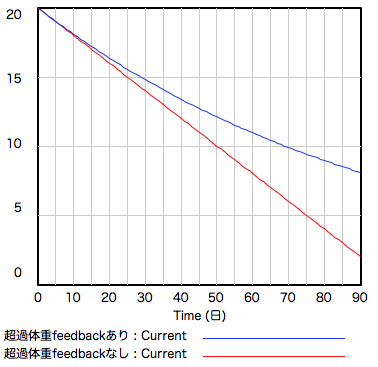
禁煙:あとダイエットとかもそうね。同じ努力をしても体重が減るほど、減り方はゆるやかになる(下のグラフの青線)。ヒトは無意識に同じ努力には同じ結果が出るはずだと、グラフで言うと直線で描ける変化をイメージしてしまう(下のグラフの赤線)から、しばらくダイエットを続けていると効果がなくなったと思ってやる気がくじけちゃう。ほんとはちゃんと同じだけ効いてるからこそ、そういう変化になるんだけど。
少女:ええっ、これって学校で教えた方がいいんじゃ。
禁煙:ん?食いついた?
少女:というか、微分方程式というより、それって「残っている量に比例して減っていく」現象のモデルなんじゃ?
禁煙:ええ、そのとおり。だからいろんなところにこの種の現象は見つかるわ、自然にも社会にも。モデルとしてはとてもシンプルだけど、ダイエッターが勘違いするように、ヒトの量の感覚とは異なるものだから、数学の使い甲斐があるところなのだけれど。
◯指数関数的増加のモデル
少女:バスタブで作れるモデルって他にもあるんですか?
禁煙:ええ、もちろん。じゃあ今度は、〈バスタブ〉から〈入る蛇口〉へコードをつないで、バスタブの水の量が多いほど、ますます入ってくる水の量が増えるのを作ってみようか。
少女:これも何かの現象のモデルになるんですか。
禁煙:一番身近なのは複利計算かな。預金とか借金とか。
少女:まだ借金があるほどの甲斐性はないです。複利って何でしたっけ?
禁煙:たとえば一年間で1%の利子で100万円預けるとするわね。1年後には100万円の1%が利子となって加わり、預金残高は100+1=101万円に増える。次の年は、101万円の1%、つまり10,100円が利子にとなって加わり、預金残高は1,010,000+10,100=1,020,100円になる。……以下、繰り返しね。
少女:預金残高×利率=利子だから、預金残高=バスタブの水の量が多いほど、ますます入ってくる水の量が増えるちゃう。
禁煙:同じように1秒ごとに〈バスタブ〉の数字を書き取ってグラフにしてみて。
少女:今度はどんどんと坂がきつくなる上り坂みたいなのになりました。
禁煙:他には、「ネズミ算」って言葉があるけど、親ネズミの数に比例して子ネズミが生まれるとすると、ネズミが増えれば増えるほど、増え方が激しくなる。食料が十分な場合、生物はこんな増加の仕方をするわね。細菌とかホテイアオイとか。
少女:ホテイアオイって水草ですか?
禁煙:ええ。世界十大害草とか世界の外来侵入種ワースト100にも選ばれてて「青い悪魔」なんて呼ぶ人もあるくらい。寒さに弱くて冬はほとんど枯れるけど、ちょっとでも残っていると翌年にはまた大繁殖する。ああ池に少し浮いてるなあと思ってたら、いつの間にか池全面を覆っててびっくりしたりしない? この種の現象も、ヒトの数量の感覚からすると意外に感じるから「ネズミ算」なんて特別な言い回しがあるのね。
◯日常感覚とそれ以上をつなぐ
少女:これも前に禁煙さんが言ってた、日常の感覚を越えたものだから数学が役に立つって場面ですか?
禁煙:ええ。今のところでポイントは、「預金残高が多いほどほど利子も多い」「親が多いほど、生まれる子も多い」ってところは日常の感覚の通りだってこと。
少女:バスタブ・モデルが、日常感覚とそれを越えたものをつないでる?
禁煙:そして微分方程式の役目も、バスタブ・モデルのそれと同じだってこと。なぜ物理法則をはじめとして、科学の基本方程式の多くが微分方程式で書かれているのか、ここに理由があるの。
少女:微分方程式が、日常感覚とそれを越えたものをつないでる? うーん、微分方程式を知らないから、それがどう日常感覚とつながっているのか分からないです。
禁煙:たとえば止まったものに力を加えると動き出すよね。それまで速度ゼロだったのに動くってことは加速したってこと。より強い力だとそれだけ大きく加速するし、より重いものだとそんなに加速しない。
少女:うーん、そこだけ取り出したら、確かに日常の感覚ですけど。
◯空気抵抗のない落下運動
禁煙:たとえば空気抵抗がないところで物を落とすと、重力で引っ張られ続けるから、一定の度合いで速度は増加していく。速度が上がるってことは、1秒当たりに進む距離がどんどん増えていくってこと。さて、これのバスタブ・モデルをつくろうか。
少女:ええっ、見当もつかない。
禁煙:ちなみに速度が一定の割合で増加していくグラフはこんな感じ。

少女:一番最初のバスタブの水の量のグラフみたいですね。
禁煙:ええ。一つ目のバスタブに〈速度〉って名札をつけておくわね。
少女:一定の割合で増加していくから、〈入る蛇口〉は最初に決めた数値に固定ですよね。どうしましょう?
禁煙:物を落とす話をしてたから、重力加速度にちなんで9.8にしときましょうか。
少女:速度がどんな風に増えていくかはバスタブ・モデルで表現できましたけど、この後は?
禁煙:ここにもうひとつバスタブを用意してみたわ。二つ目のバスタブに〈進んだ距離〉って名札をつけておくわね。
少女:あとは、このコードだけど、ふたつバスタブがあるから、コードでつなぐってことは予想がつくんですけど。あと、〈進んだ距離〉バスタブの〈入る蛇口〉ってまだ考えてなかったです。
禁煙:というか、それがほとんど答えね。
少女:そうか。貯まって〈進んだ距離〉になるものって……1秒あたり進む度合いって〈速度〉だもの。
〈進んだ距離〉バスタブの〈入る蛇口〉は速度だ。じゃあ、〈バスタブ〉に〈速度〉って名札をつけた一つ目のバスタブと、二つ目の〈入る蛇口〉をコードでつなぎます。
禁煙:じゃあ、バスタブ・モデルを動かしてみましょうか。二つ目のモデルの〈バスタブ〉の値を1秒ごとに記録してね。
少女:できました。

禁煙:これが世界最初の微分方程式だって人もいるわ。落体の運動を研究している時にガリレオが解いたんだけど。
◯空気抵抗のある落下運動
少女:学校では
とかって、ガリレオが解いた結果だけを習いました。禁煙:数式のかたちで答えが得られると後で応用しやすいからね。でも、やぼったいバスタブ・モデルにもいいことがあるわ(といっても微分方程式なら当然できることだけど)。いまの2個のバスタブで作った落下運動のモデルだけど、コード1本追加すれば、「空気抵抗がある落下運動」のモデルに改造できるの。
少女:どうしたらいいんですか?
禁煙:ヒント。空気抵抗は、小さな物体がゆっくり動くときには、速度に比例すると考えていいの。速度が二倍になれば空気抵抗も二倍ね。
少女:空気抵抗って減速させるんですよね。今は一個目のバスタブに入っている水の量が速度を表してたから、このバスタブから出ていく=速度をおとすって考えればいいのかな?
禁煙:そのとおり。
少女:じゃあ、〈速度〉って名札をつけたから〈出る蛇口1〉へコードをつなぎます。
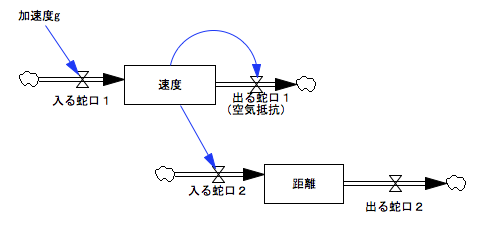
禁煙:大正解。じゃあ、またグラフを書いてもらえる? 今度は速度がどんなふうに変化するかを知りたいから、〈速度〉って名札をつけた〈スタック〉の数値を1秒ごとに書きとめてね。

少女:こんなグラフになりました。速度の上がり方は最初は急だけど、どんどんなだらかになっていきますね。
禁煙:うん。高い雲から落ちてくる雨粒は、地上につくころはほとんど加速せずに(速度のグラフがずいぶんなだらかになったところね)、大きさによってだいたい同じ速度におちついて落ちてくるわ。直径1ミリメートルでは毎秒約4メートル、5ミリメートルでは毎秒約9メートルぐらいかしら。
少女:雨が突き刺さらなくてよかったです。
◯ダイエットとやる気のモデル
禁煙:せっかくバスタブを2つ使うモデルが出たから、値が増えたり減ったりを繰り返すモデルも作っておこうか。
少女:実はもうちょっと着いていけなくなってるんですけど。
禁煙:普通はバネの話なんかするんだけど、せっかくだしリバウンドのモデルにしようね。
少女:えっ、狙い撃ち?
禁煙:1つめのバスタブに〈超過体重〉という名札をつけましょう。
少女:超過体重って?
禁煙:理想体重よりどれだけ重いかってこと。当然、理想体重より軽くなったら超過体重としてはマイナスにあるわ。
少女:えーと、バスタブだからマイナスの数とか表せないんじゃ?
禁煙:ほんとはね。少しズルをして、バスタブのデジタル表示をいじってちょうど半分水が入ったときに0と表示するようにしておくの。こうすつとー500から+500までの数字が扱えるわ。
少女:もう一つのバスタブは?
禁煙:〈やる気〉という名札をつけておきましょうか。こちらもマイナスの値が扱えるようにしておくの。
少女:ダイエットのやる気ってことですか?
禁煙:やる気が高いときはダイエットに一生懸命取り組むから体重の減り方が大きい、と考えるのはいいかしら?
少女:ええ。
禁煙:ではもうひとつ。現実的にはもっといろいろありそうだけど、ここは単純に、体重が重いほどより強く動機付けられてやる気も高まる、と考えましょうか。逆に体重が軽くなってくるとやる気も減ってく、ってことね。
少女:じゃあ〈やる気〉のバスタブから〈体重減少〉の蛇口へコードをつなぎます。それから〈超過体重〉のバスタブから〈やる気増加〉の蛇口へもコードをつないで、と。これでいいですか。
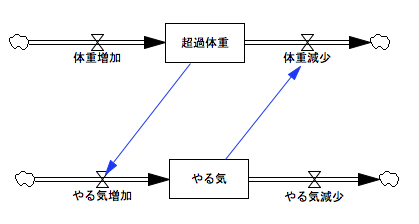
禁煙:これもグラフを描いてみましょうか。
少女:体重もやる気も上がったり下がったりを繰り返すグラフになりました。体重のアップダウンをやる気のアップダウンが追いかけてるみたい。あ、でも、これ……
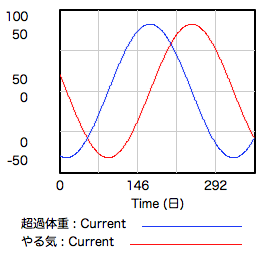
禁煙:なあに?
少女:今のバスタブ・モデルには、さっき出た〈体重が減るほど減り方がゆるやかになる〉って話が入ってませんよね?
禁煙:じゃあ、さっきみたいに〈超過体重〉のバスタブから〈体重減少〉の蛇口にコードをつなぎましょうか。

少女:うーん、こんなグラフになりました。やっぱり体重のアップダウンをやる気が追いかけてるんですけど、アップダウンは同じ大きさじゃなくて形もなんか違いますね。ちょっと言葉で言い表すのは難しいです。
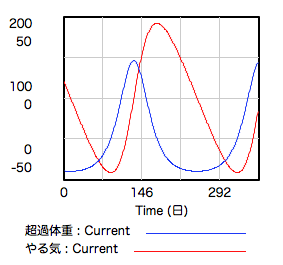
禁煙:このあたりまで来ると、自然言語でなかなか表現できないから、モデルを使って考える甲斐があるって思わない?
◯バスタブ・モデルの正体
少女:バスタブやコードを増やせば、もっと複雑なモデルも作れますか。
禁煙:ええ。たとえばさっきの、2つのバスタブで速度と位置を表すモデルを組み合わせて、車間距離のシミュレーションとかね。
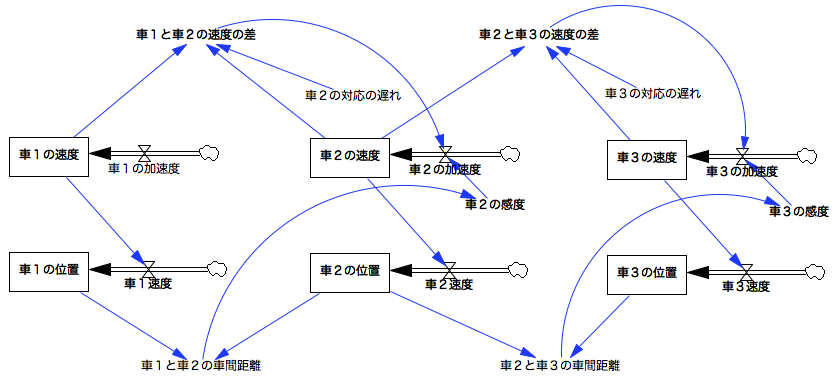
(クリックで拡大)
(岡野 道治他(1997)『理工系システムのモデリング学習 : STELLAによるシステム思考』牧野書店,星雲社 (発売), p78-79 図4-10,4-12を元にVensim PLE用に改変)
少女:えーと、速度と位置を表すバスタブ2つが1セットで、車1つ分なんですね。
禁煙:ええ。とりあえず3台分で作ってみたけれど、後続車は前の車の車間距離と速度の差を見てアクセルやブレーキを踏む(加速や減速する)けれど、車によって対応の遅れに差がある場合ね。先頭車は時速10キロから徐々に加速して、後続車はぶつからないように(「車の位置」のグラフが交差すると、そこでぶつかることになるんだけど)、速度を合わせていく感じになったわ。
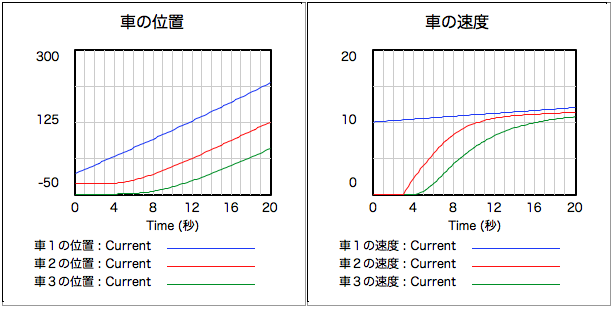
(クリックで拡大)
禁煙:こんな風にどんどん組み合わせればいいって言えばいいんだけど、ただ弱点があってね。
少女:なんですか?
禁煙:マイナスの値が使えないってのはさっきのトリックで何とかなったけど、現実問題として水の量を計っているから精度がよくないの。あとバスタブやコードがたくさんになると扱いが大変だし、場所はとるし、今みたいに水浸しになるし。見た目もやってることもベタだから、その点は分かりやすいのだけど。
少女:やってることはシンプルなんだから、コンピュータの上でできたら、バスタブもコードもいくらでも増やせそうだけど。というか、もうあるんじゃないですか?
禁煙:ええ、実はね。アメリカにMIT(マサチューセッツ工科大学)って学校があるけど、60年以上も昔、電気工学の学生としてやってきたジェイ・ライト・フォレスターって人がいてね。戦争中、兵器に自動調整装置を応用する研究室で働いていて、その絡みで戦後も軍のためにコンピュータ(Whirlwind)を開発したり、半自動な防空システム(SAGE)をつくったりしたんだけど、大きなプロジェクトを経験したせいか、進歩を阻害するのは技術的な問題よりも組織運営の問題の方だって痛感したみたい。電気回路や自動調節装置を扱うやり方で組織のマネジメントをモデル化できないかと考え出したの。
少女:リーダーって大変なんですね。
禁煙:ちょうどある大企業で雇用が短い周期で上下する問題があって、みんなは「これは景気が上下するせいだ、つまり組織の外に原因があるから、一企業には解決不可能だ」って言い張ったんだけど、フォレスターさんはそのアップダウンは組織の内から生まれていることを証明したの。
少女:ダイエットのモデルから、体重とやる気のアップダウンが生まれたみたいに?
禁煙:このときのモデルづくりの方法が、やがて企業だけじゃなくて世界とか都市とかいろんなものに応用されるようになって、その後、システム・ダイナミクスと呼ばれるようになるのだけれど。今じゃアメリカだと高校生やもっと下の学校でもやってるみたい。
少女:フォレスターさんもバスタブを使ったんですか?
禁煙:もう少しだけ抽象化したものだったけどね。今日〈バスタブ〉と呼んでたものを〈レベル変数〉、〈蛇口〉と言ってたものを〈レイト変数〉、と言い換えれば、フォレスターさんたちが使った、システム・ダイナミクスでモデルを記述するストック・フロー・ダイアグラムになるわ。というより話は逆で、ストック・フロー・ダイアグラムの、日常的で身近な〈たとえ〉として使われるのがバスタブ・ダイヤグラムなんだけどね。もともとメタファーに過ぎなかったものを、調子に乗って作ってもらったの。
少女:フローと風呂(バス)をかけてるんですか?
禁煙:それは気付かなかったわ。珍しいね、オチは地口オチ?
少女:二秒で忘れて。……でも、これがなんで微分方程式と関係あるんですか?
禁煙:バスタブというメタファーの利点は、微分と積分を、(単位時間に)〈入ってくる/出て行く水の量〉と〈バスタブに貯まる水の量〉っていう日常的に目にするものに置き換えてくれることね。それぞれストックとフローを表しているから当然といえば当然だけど。
少女:ストックとフローってよく聞くけど、よく分かってない気がします。
禁煙:語れば長いけれど、例を上げておくとこんな感じかしら。
| フロー | →累積(積分)→ | ストック |
| 一定期間内に流れた量 | ある一時点において貯蔵されている量 | |
| 時間を計る単位を変更することで値の変わる変数 | 時間を計る単位の変更によって値の変わらない変数 | |
| 国民所得 | 国富 | |
| 預金・引き出し | 預金残高 | |
| 生産・出荷 | 在庫調 | |
| 雇入れ・解雇 | 従業員数 | |
| 速度 | 距離 | |
| 加速度 | 速度 | |
| 力 | 運動量 | |
| 電流 | 電気量 | |
| 熱伝導率 | 熱量 | |
| 原子核崩壊率 | 原子核数 | |
| 化学反応速度 | 濃度 | |
| データ伝送レート | データ伝送量 |
少女:じゃあどれがストックでどれがフローなのかを整理して、その間の関係を矢印で結べば、バスタブ・モデルが作れるってことですか。
禁煙:そう。しかも下の4つの表現(バスタブ、ストック・フロー・ダイアグラム、積分方程式、微分方程式)は、同じ内容を表してるの。
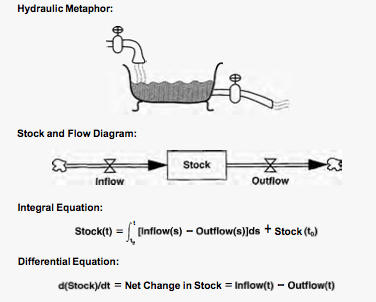
(from Sterman, J. (2000). Business dynamics: Systems thinking and modeling for a complex world. Boston: Irwin/McGraw-Hill. p.194 FIGURE 6-2 Four equivalent representations of stock and flow structure - Each representation contains precisely the same information.)
◯バスタブ・モデルをコンピュータ上で動かす
少女:えーと、つまりバスタブをつかって現象のモデルが作れたら、微分方程式も立てられるってことですか?
禁煙:あと、システム・ダイナミクスのソフトを使えば、手を濡らさずにシミュレーションもできちゃう。ダイアグラムをお絵かきすれば、あとはお任せできるソフトがSTELLA / iThinkとかPowerSimとかいくつかあるけど、今回はネットからダウンロードできて個人用・教育用なら無料で使えるVensim PLE(http://vensim.com/free-download/)というソフトを使ってみたんだけど。
少女:ああ、そういうのがあるから中学・高校でシステム・ダイナミクスできるのかな。実際、何してるんですか?
禁煙:「システム・ダイナミクス」って独立した教科があるんじゃなくて、他の科目の内容に結びついてるみたいね。理科や歴史の授業で、環境問題とか文明のモデルをつくったりはもちろんあるけど、今日みたいに数学の授業に使ったり、英語(日本の国語科みたいなの)では文学作品を読んだり。
少女:いや、文学にシミュレーションもバスタブもいらないでしょ?
禁煙:有名なのだと(MIT のオンライン教材集Road Maps: A Guide to Learning System Dynamicsにも採用されてる)、ハムレットが復讐心をこじらせて王さま(クローディアス)を殺すまでのモデルとか。見てのとおり、ストック(私たちがいうところのバスタブ)4つでできてるんだけど。
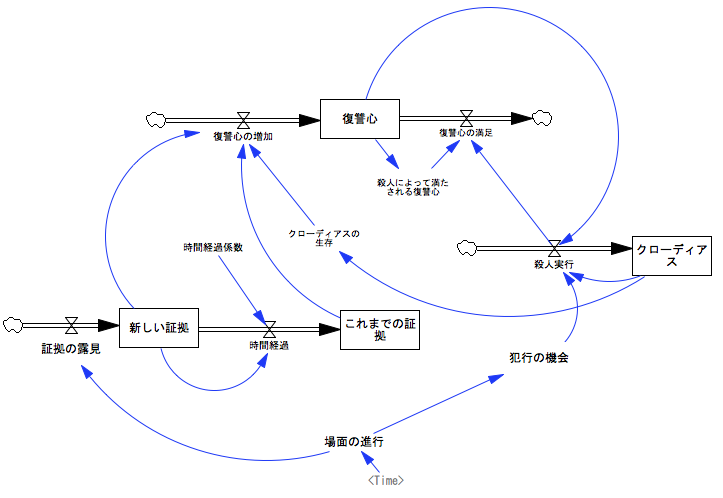
(クリックで拡大)
(Hopkins, P. L. “Simulating Hamlet in the Classroom”, System Dynamics Review V8 N1, Winter 1992を元にVensim PLE用に改変)
少女:いったい何の意味が?
禁煙:登場人物の感情の高まりを視覚化して時間的変遷を詳細に検討できるとかもあるけれど、一旦モデルを作ってしまえば、モデルやパラメーターを変更して「もし~だったら、どうなったか?」をいくらでも検討できる、というのも大きいわね。
少女:いやシェイクスピアをマルチエンディングにしても……。事業計画とか政策立案の話だったら、確かにそういうのが必要だってわかるんですけど。
禁煙:理解の仕方っていろいろあると思うけど、感情移入して追体験するのもひとつなら、対象にいろいろ働きかけて返ってきた反応を通して知るというのもひとつ。一目見ればわかるシンプルなものならいいけど、相手が複雑なものだと〈やり取り〉を通して分かることも多いって感じかしら。
少女:うーん、いままで文学とか苦手だった子には、ちょっとウケよさそうかな。
禁煙:実験する学問でも、やっている人にとっては、論文に書ける完成品の実験よりも、そこに至るまでのいわば試作品の実験を繰り返してるうちにいろいろ分かってくるものが大事ってところがあるけど。システム・ダイナミクスに限らず、この手のシミュレーションって、社会とか生態系とか実験が難しいもの相手の、実験の代用品ってところがあるの。
少女:あー、でも、なんかの現象からバスタブ・モデルを自分で組み立てられる気がしません。
禁煙:ご希望なら、モデルの作り方は別にやってもいいわね。
(参考文献)
高校の数学の先生が書いた、システム・ダイナミクス・ソフト(この本ではSTELLAを使用)を使った数学の授業の作り方。
Fisher, D. M., & High Performance Systems, Inc. (2001). Lessons in mathematics: A dynamic approach : with applications across the sciences. Lebanon, N.H.: isee Systems.
 | Lessons in mathematics: A dynamic approach Diana M.Fisher High Performance Systems 発売元サイトで詳しく見る |
上の本が入手できなかったので、(だいぶ違うけど)次の本を参考にした。
 | 理工系システムのモデリング学習―STELLAによるシステム思考 岡野 道治,福永 吉徳,福田 敦,吉江 修 牧野書店 売り上げランキング : 955866 Amazonで詳しく見る |
なお、Diana M.Fisher の別著 Fisher, D., & isee systems (Firm). (2007). Modeling dynamic systems: Lessons for a first course. Lebanon, N.H.: isee systems. については以下の邦訳がある。
 | システムダイナミックスモデリング入門―教師用ガイド Diana M.Fisher,豊沢 聡 カットシステム 売り上げランキング : 297160 Amazonで詳しく見る |
この分野の定番教科書。
![Business Dynamics: Systems Thinking and Modeling for a Complex World [With CDROM]](data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAkJCggKCAsLCQsKCwsLDhAMCgsNExcVEBQPFhISDhYSDxQPDxQSFBgTFhQZIBoeGRgrIRwkExwdMiIzKjclIjABBgsKCw0OCwwMDg4MDRAOHRQNDCIUFRcOHggXDBAWEBEXCxATFAsRGREeCRkMCCIYHRQPHRANDA8WEAsUFSMWGP/AABEIAKAAfAMBIgACEQEDEQH/xACmAAABBQEBAQAAAAAAAAAAAAAGAAMEBQcCAQgQAAIBAwIDBAQLBgQFBQAAAAECAwAEEQUSBiExEyJBURQyYYEVIzM1UnFydKGz0gdTYpGxsnODktNCQ0RVkxYkJYKjAQEAAgMBAQAAAAAAAAAAAAAAAQYCBAUDBxEAAQQABQIDBwQDAAAAAAAAAQACAxEEEiExQVFhEyJxBTJCgZGxwWKh0fAjQ1L/2gAMAwEAAhEDEQA/ANfsrLTPguyPoVmWa2hLMYkz8mv8NSTaaWRysLIe3sk/RXVkR8E2C+Po0P5a05REy1ppRXlYWQP+En6KRtNKI5WFkD/hJ+inq5Dx/TT+YoibNnpRHKwsh/lJ+ik1ppRXlYWQ/wApP0V32kX00/mKXaRfTT+YqLRNT2ulLGWSwsvfEn6Kb9Gsv+3ad/41/wBunZ5IjC3fTw8R5inYiGbuEHzwax5UqKINMI7tppDFThwqoSv28JyrxoNNUFjZaSFUZdyiYA8ySnIGsr0UW3pOtdlA0EvwXr4upimzt2N9lGRv+d2K5U/Q3AVLNtLPpmqlIfSltbbhy9ubPr20EMImliweTFkU1KLSjb6d42OlAdQ2xMbfpep09teGHTFUs1npKovrOUQAeXMp41nt7bWVvZ3NvYTvc2Q4PuBaznq0TTZU1UWxt/gTF3C93DDrGjwT2wTtWkEVrHAU2H1ydlEWsiDTTgCy0rew3omxNzJnG5RsyRSFvpzDMdjpT4JVtiIcMPBsJyNCk2nWp43glnD2jXNtDc6FOAEKmCCW3msWBGUG2ZZNi/Qrvgmyt7GzvkGYr+N4rHWLXoouIFYCdOQLelI6uWqERO0Fiqlvg7TuXlGv6KEOKbWxTUYQlrbIDbIxCxqBnfJ5CjaX5J/qoQ4r+cYPuqf3y0CIysiPgmwHj6NAf/zWnKbsmHwRYDx9Gg/LWnKzUJV4Ej+gv8hSZkRGeRlSNAWkdjhQo5kkmq4SXt9ztWa0tD0nI+PkHnCrckXyZxk+C+NKRSppdPt8ekvEmfVTGXb2IgBdj9QpoXDvj0bTJXJ5h7jbEvuVsyfzSnoLa1t8mKP4xuck7ktK583kbLmpFNOlooEq6j2Z7S1sI4wy9oVZmcDI9X4tRUxNiHkAB7K4n+Rb3f1FdAZrA7qUEWHDusxTXXpz2aWz2mqWdm8LM8jenXAug8isiBBEFpWWkcU2trPLFLZQagX0xYoY5X7GWCyQROksphyvpCk8thC1bpxNoLi8792voCTTTl4nCtFDJ2EzwHGJBE/Jqfm13R4J1hlllDvdfB8ZCEqbnsluCufYjLRFQRcNX8Wmm1EtsXOgzaRkE7BcyTGfI7vya01Fw7rNrDeG2aymlfW4dYtI5HZUMKdY3YRMVaigaxpf/wAVmVx8N/NndPe7gky/inIimJ+ItDtYtUluJpFTRJIodSwhJDSkKgT6eSalFCvdN1291y3uJp4FsIpob5FDs0sE6Ws1q8UK7ApSR5Q+8t4dKe4dsNYsZr641mSCW6uorO1LwszlxbI8fbSlkXvzb6mXGs6ZbJdvK05Nm0Ec0SIzO0k4VoUiUeuz7hUb/wBS6AWsVSad/hFY3gcRNsTtHMCLcHHxZeVWQZ8VqEV5L8k/1UIcV/OMH3VP75KL5gRG4PlQhxZ84wfdU/vloNyhRlZkfBNgM/8ATQ/lrXRKqpZ2Cqo3Mx5AAcySTXNmw+CbBfH0aH8tahTqLy6FmeVvCFmv/wCLJzHD/wDfGW9gA8azULiNTqLLPOpWyQh7S3bq7DmJph/Yp6dTz6WG+bPyRPl3hThpCoOqJrfL+5P+oUt837k/6hTopVFIo07y9kcw4GRz3DzFPRFi3eXb5DIP9K5n+RY/UfxFeCaMHIZax5UrOtBgiudU9Fm+SurLiOB/svqcCmqaZGThHhq5lIed7m71GeTzdQ8ufciAVoWnaLpWmX0t5bXN1NLMJlVJ3BjiWeUXMqwqqLjfIAedcyaHob6Za6czzm2sop4bfvjeVnjeB952cyFkbFTYRAt3dw26cKlxKTY6Xp9yhRGZBvvLUMZHRSsY7OB+bmomv8rrii28NQud59vosb3B/qtaIuhaIlncWna3DQ3NjBpTEuN628IcRlDswHy5JNN3PDmgXczTzy3Xat6VnDjGbmJbaU+p4Ig2+RJpYRUOo49L1Lb/AN24c/pDVnqSaNZazpt/ZCyuLCUwaff2kJRwm+dntLqJV6bLnepP8ZqzudK0i5F2jTzxzXrW1w8kbgOklsFSGSDKEDbhc5BBqInDWgRvZNHPdqtisKdgH7k/YyvcxNc9zJKSuzd0jJalhETTjuP48jQfxZ84wfdU/vlotllRkbvDJGABQlxZ84wfdU/vlqBuURhbSRx6JaO55RWkUj+xViDGmrBHS0V5eU10TdXH23wwX/LXao+zTEh36Bp9uP8Aqks4H+wwTcPegarI16KF5Xq0sGmwj+E0o+oj9NETtKmuzf8AfS/h+ml2b/vpce79NQidpYzTPZN++l/D9NOIGQEF3fyLeH1YAoiYtbu1ut3YSrhWK7m7oJDFDsz6wDDBxT6S2j7wLiAsm3cAw5FhuXdz5ZHOqg8NwtKS0nrmWWSXA3mV0WMjaFEYXuK55c3G6mm4csFJVpZ5AVZHDFT1SOINkpncixjaeoyalFd9pD4Sx+XJh16Ada6qkh0HT4LiKaFplMcqzbOW0sDIwz3c4zK3LNXdEUK+xFHFfJ69lIHk9sB7kg/kd31oKnnoK5KpJHJG43LIjIQfIjBqNYSPJp1t2hy8Sdk5/jQ9mfxWiKVQVxcANThA8LZPzJaNaCuL/nWH7sn5ktERD1sdAHgexJ91q5qz8arOmnaC30Tbj/VCYv6tVn41PRQq0Wt1ncbp1OXKqACF3EnAz1xT6QSCYSGVm7oVlPQ8gCeRxzxmpdeivIMasrVctrcqu0XcuPDugkcsdTTiQXSyIz3Lui+sm0Dd9ZqbSqMje/1KWlSGPZSNIDNeqhC8ltrazO9n6U7LfEQCZ2Mfo6wAqWUtzV7j8N1e3E3FMlvcRR2W1ZxKEZcrKCSwXDGUhQoZCPstU5ddsO3ELCRT6TNayucBUWFDMZSc+q4HdqXNq1hFLbosyN2zSLJJ0ESorsS+RyJZNoBwctRFVencRwjtRaIIEVO3Z1YAKoiLsFMpIwGl3f4ddw6jq8ujpdW9sJ7uZ3REjQ7YgAflA7KTlgRkHHOpUeuaVvk9IlEUKt8VMfVkXYkmQNu7nlv/ABmpDajpq29zPFKJEtEL3CxgnHNgFUY5lmUgY8RRFUTT8TyQTWzWZiE+I4rmEd5EZwpJPa8m7Ngc+BRqudO2i1lTwW4uNv8A5Xrq31PT3WKJ5kFxOQohTLHdz5KdoBA2tz6d00xpFzbSW88MbhplmkklUeCvNIU59Oe09PKp4KKxoL4v+dYfuyfmS0aUF8X/ADrD92T8yWoREzQtLwzb9n8rFaQTQ/bRElUe8rUuN0lijlQgpKiyJ9TDcKVi4Gk2I6n0aAkf5a9ah2QMEs9i3IRZntPI27tnaP8ACcleXhtqUU6kK8r0VCL2l4UqVESNKlXq8qIoJ0vReYWBGk5bjk7vVKAtzySFJAJ86Uuh6JzZ7fLsQxO5vXyj7+TdSyKSepIqsSx1S3hEcXYC6R5jPflvjZg7M65yhIAbsy3sTApi6tuKljldb5pw+5FihIDAt2qKUwme5vQ9eXZURXDaXpDtIXto2d9xdSzH1t+Wxu5Z7R/9ZpuHSre2gmtu3ldLidLiVnI5urrJ5YAcrzquFjr0d2ZvSUcMio8iPiYohaRIi7xsMZd1Y4ycK1TXs9QuNBks7yZJb8MsiSvzQukiyIe6gwDsGRjxNET81tplhBPd2cSCeKNo4CCSctyVEySAC3Qe011p9jY6bCIrULExSP0py5JZh4sXY45k4oXj0vVYHgsrO4gzaIs11L4FlZxAhypJLL3/AOFudT5NN1V5yskqTW0s1tJcys2JXSExNhgI8c2WTAH0qlET0F8X/OsP3ZPzJaNTzNBXF/zrD92T8yWoRcW3Gegw2NuksV6xhgiRsIMZCheWHqBd8caTIYntbHUvSbZt8EmE2N4Oj/HZ2uKzmSXbAiRoD3B326ZK4z58h0p+2ijSIO3McmVfFjgEgnyFZQFoY+TEkNAF0Ol7dyVvFkc0/g4RrnNoAEnd/wATthTRx21WjXX7RNAskRryw1NBL6nJP96oyftP4W5f+z1M+3ZH/vVmmu6VrGswo9hbPctbszThMAqrABQAxGenRaz2aG/sJglzDPbSYyElUqSPMBhzFa8cgkbnAygk0OctmtflqoxUBgldEDmLQLPGYtBP3oL6rseL+H7+1e5tHmdIRmdCAHX61LZriHjHRpGCLa3zMfYv+5XzPZ3k/a9pCxhcY37DhWHkw8QTitV0LN5Zy3yKirHiGdc99HPs8m8DXKx088Lc8TQWhvm583U9AtONpe9jDQBOvotNHE+lDOYLkjz5frp+013T72VIrdJt7/Sx+qs7uInxFsI2YO4kdD4H3VY8MWUjXu8KwEbKS/0uWanCyTSxRyveLfqAAKq9tdePMtyRjGuc0Ailo8twIU3FJHA6qnX8TVWeINOj7zRXB9mF/VXGo6ra2jGIfGTDmVXw+uhSe4t5339m0Tse83Ij+Qr1dj8KyVsT5g3XzGrAPQu2Hda+Tm67K2vOOdCsJ1hntb93Zd+VVCPzaesuMdNvLVri3s70dRB24VQze525VneoaRJfatFK4b0SGINLIvRsMTtBq33QhAImiVAAEUEAADwFWEMiuy4Zfh1Go63sQsAx5JoEj0RHacVaTb27KYLySd2aW5l2rl5T5Zk5DkAvkAKrn/arw1CxhmsNXR05OhSL/foNZ0RmDEYBPP34oN4qtUd4Lu3Xcz5iuNo8QAVLe7+lVyDESveWPbveV1cj9vRWXGYPCMjzwStzD3o84JI7DexytxtP2h8N3MAlitdQIzsIKpkH3S1Qa/xPpl/eRTRRXSqIAmHC+DufBzWTcNRXS3E8LxSokkYdWdSAHBAHUeIJoguO6yKRgquOX2mrsEUAqaXuDy3irCD7BNTvroxJc3KQq2ZXDtgD2c8ZrTtOgWS1CgMREdikk7ioPLJzzpWuhwRWkQhk7IOiucL1yASSfGrDA0+2hRMyBi2XPI5znyr3MseHAfMaDjlaavz0TxfDV0YIZ5ZMkY1rQXWnOqbuHuraXEE0kcbqA6DxIJIznNOE2mswNp2sxxydoCLS4xhkkwQMbcYP9cAGodzO05UlQu2opEpZQmdzEBAOu7PLFVbEYrNOZInEs002GgFjKVf4cA04YRTsaJKPn0zA2SDn+/aws61fRNT0TVGgmhnZEbME+xlWWPzXIo/4Qi1a01WGSaxvfg7UF7C6PZtjY/NH6dUajT9oxXstMR8GVYn7QirPR2J0nTzn/lJVmfE3wmPOuew5vGWjp89ivnwbrYNEHdK40+SByu0yx57pAyD9oYq1vJ107TAsCqksgCblGO+ep9wq7jHPceopqe1trhSs8auh6Z6g+anqKrEfs8wjEDDyvGdtRMJORrjufw38rafLnoOAsblZocqpdjkMSMnqW60tyt6p+tehq316xWzeEw7mt8Fct4OTu51RRgGUHy5n6qqT8EIw5smkgFl16XV/McLvw4OF+H8UuIdlJzXoCOK+StNMuRC7QSjdBKDkHwPT8RQ9qNm1hePCQSh70DeDIeY94q1jB7ZW8OpNPxXthdsbK9QNAPk7g9Q/8JxkCtnAOknBgrMGDMx/A6tPZ27O4Oi1MHjRhTmefI45XN57Eel69jSGDgjHQA7SfZTDhBklWd168sDJ5/hyFReI7xNHlniQ75A+21R/73oSteJ9SRh6UsVwnjy2v7itXrDySx08MElCst0b7GiOy4cMeHfJMZnujBefDdlse8dSLDkQOgmuGjJdHXAjwcHJHrDPLlTUly77O2XvhdpI8RubBOOWatQ1pqNrHeWpyV5gj11PijCqm6jbti3Xf3hjyyasbMRHiWEi2lpp7D7wfX544WzPhnQltlr2uFxyD3Szsfui2wumjhjimJ2bV7Nz/wAPIcj7DRJImnnSZZb5xDGDylPg3hsHiTWY/s9t31fjO3hvZppYIFkuXhdiVbZyVWFF37RLhPhSSFV2WunRLiFMKpcgNVdbESwRTVKwOzM6g0frWbyr2xOMjztmgY6KTQO1FGTSjQGm3n4Kr4JIbu4S2tGMksziKBSNpcnkOvIVoel6DbaMBqWvzwo8fyEWcqv63r530/V9Rj1mzuYZeyeOeMoEA2jvAVo19cahO7T3css0mMhpHLkA/RzyX3V7Yf2bEXZ7NA7d17ye1MVKwxuLG2KcQKJHIvi+aS4p1c6xqEsgUoiJiBPFUX9WSTVvp3E1nbWVpazW0/aQKsbOpG00D20Jmld+8e7hv61xOx7cbRgALy+oKDVgxUYEbGjYH8FcJ7ywCuq+jra4WcHYp5Haf6867ku7CFwk93axMeWJJFU+8FqxPijjO4sDJpmjttmbDXt2Oq8uUUVCFhpHEWoxemMyGOQAhZn+NdM5yvI4zVfGbXn+F6uLBuQF9G6rb3MtoZ7IpNGq/HRjDBl67k6glaCMJkthQTzOBj8AK94QtNatrtLhJmhs9uJ7ctvibkMqFzhTRPxFBax6XLNCkURd1LEDmTnNcDE+zXYuVlTOjaTT2akerW3XrwvQSEAgE166fTZBd7KsVqzKechEf1A5zihy8kC2hUHbvIAx1xTt5diSIAg7VbIHjVVcOZIB/A2fceVWjDYSDDSxQRtoVZPxF1aEnn+hcxxLpow7bgf30Q1rcNzeFbrdJLJGojdTz7g8RQtRwHZGbY3MH1TVFqdiEQXkAAidsSxD/gb9LGupicNX+Rg0+Id+v8roObypPDF61tqIhYnsrobCvhv6qaJ9RhYXPd6bRj+ZoD0vI1Wzx+/j/uFH2qF/SV2tgbBy97VXGyCKfNWj4/MO4cKK7cYMuDc0/wCucZD+ktNj9r+aZ/ZheR2fHUCydLtJrUfaYb1/FKMf2mWjDU2ZcLFfwDYfORO5WLwjUbW9iurZJkmglWeCRVPJ1YOrDl4EV9AXl/pnGHDdpNLJHZ3a5W5jc4eK4XxUOQSj1t7KuObmHcaj1C+frBGXVbVJAUZbiMMCPJxWl3t3Jbhm7F5Ix6zp4D2g1Dm4c1CGeKZvQbpIXD9tFKm/aDnOCwblU/cjAgkFWGCK1JMXNA5vh05pHmFd+vCsuAwcOJim8S45AaY66F5f+To7uqQauioxW2fYAThcZNRbPULDUr1IGeS0kmxHE7gFO0LHAYhgQDUGVJY3kRFYhWYA4zkA4FUU1tciZmSGUDO4YU8j1rrPnc8NvUb0quQSXMfwU7qG9dYuRdEsVuXE588OQa2h8sEeAhoSoeORPVKHmpGPDFAWqaNNqNhb6zYmOSe4hHwlZsQJRKo2NIgcgnftqNol7xBCiWUADb3EdtFcr3EJPMlyylVFa4cAT0tYTROeG5dx9luPC7Oba7ZjtgVwwY8lBxuaqfXbyXUEl7IHsogewXzwQS3vxVZxTq3o2nJo+mOhJUNezQ+r7UByc76VheQ3FlE7OiPtw6MQO8ORGDWzC0WZDV/COyzZoBHuWjU8Whq4BaIuMhee8DnjkedVqzKeXUHkaIZFjgndFZCmcpzBG01RXlt2b77fBXqVU9K2MSwuySsPnZsf09flz2JWvM0+V7feb9lFuFjMpMfc+voaiJLszHIN0b8nXzFTfXG0q5X8RXjWzr4K4x7/AH1vQYyOQBryGPrVvHyOy3Y52OFO8ruRx9VV2enGHW7SSAO1vu37yPUIBO1z0q21Vi16ceCqK9hkuIXUgEeY8CKj3e97l3bI3HK/Z8P5CuDicKRMJG14eSh1z3qPy1dcztZhTC2zI6bMenhBlDVf/9k=) | Business Dynamics: Systems Thinking and Modeling for a Complex World [With CDROM] John D. Sterman McGraw-Hill Europe 売り上げランキング : 57882 Amazonで詳しく見る |
以下は上の本の翻訳のはずだが、肝心のシミュレーションやモデリングについての記述をごっそり削除している(なんと1000ページを超える原著が500ページ未満の邦訳になるのだから、どれだけのものを省いたか)。
著者スターマンは「システム原型(system archetypes)だ、システム思考だなんて分かった気になってちゃダメ。普通の人は何本もある微分方程式を頭の中だけでは解けないんだから、ちゃんとシミュレーションしなきゃ。」と苦言を呈していたはずだが気のせいだったか。
 | システム思考―複雑な問題の解決技法 (BEST SOLUTION) ジョン・D・スターマン,小田 理一郎,枝廣 淳子 東洋経済新報社 売り上げランキング : 75133 Amazonで詳しく見る |
ダイエット関連では次の文献を参考にした。ウェイト・マネジメントにシステム・ダイナミクスをガチに導入してる。
浅学非才のうえ寡聞にして、システム・ダイナミクスといえば自治体の作りっぱなしモデルとか『成長の限界』のあれとか大雑把なマクロ・モデルに違いないという(1970年代で時間が止まったような)偏見があったので、新鮮だった。
しかし考えてみれば、アウトカムはきっちり数値で出るし、関連する要因は生化学から社会行動まで多分野に渡るし、そのどれにもフィードバックがかかっているしで、システム・ダイナミクスで扱うにはうってつけのテーマである。
ひょっとすると、ちゃんとしたデータが揃いにくい資源・環境系や、実践しようと思えばエラくなるしかない経営系の事例よりも、この身一つあれば(あと体脂肪計付き体重計があれば、血糖値計があれば言うことなし)がんがん測れて実践できる(しかも不断に我が身に返ってくる=否応なくフィードバックしてくる)ウェイト・マネジメントの方が、システム・ダイナミクスの入門には適しているのではないかとさえ思えてきた。
Abdel-Hamid, T. K. (2009). Thinking in circles about obesity: Applying systems thinking to weight management. New York: Springer.
 | Thinking in Circles About Obesity: Applying Systems Thinking to Weight Management Tarek K. A. Hamid Copernicus Amazonで詳しく見る |
 | Thinking in Circles About Obesity: Applying Systems Thinking to Weight Management Tarek K. A. Hamid Copernicus 売り上げランキング : 539386 Amazonで詳しく見る |
オンラインで読めるものでは
・U.S. Department of Energy's Introduction to System Dynamics
合衆国エネルギー省提供のオンラインブック。システム・ダイナミクスの歴史から基礎から説き語り。コンパクト。
・Road Maps A Guide to Learning System Dynamics
初等・中等教育におけるシステムダイナミックスの活用と学習者中心の学習を奨励・支援するCreative Learning Exchangeのサイトにある教材集。かなりのボリューム。
・System Dynamics Self Study - MIT OpenCourseWare
システム・ダイナミクスの総本山MITスローン経営大学院が提供する自習用オープンコースウェア。
(今回使ったソフトVensim PLEについて)
・個人・教育用なら無料で使える(よく本に付いてくるようなお試し版ではなく、モデルの作成も保存も自由にできる)WINDOWS版とMAC版がここからダウンロードできる。
http://vensim.com/free-download/
・マニュアルの邦訳やモデリング・ガイドなど、参考になる日本語ドキュメント(313頁もある)は日本未来研究センターの次のページからダウンロードできる。
http://www.muratopia.net/sd/documents/Vensim6UsersGuide.pdf
・本家のオンラインヘルプ(英語)はここ
https://www.vensim.com/documentation/index.html
・自分でシステム・ダイナミクスのモデルをつくるときに役立つ、よく使うパターンを集めたのがこれ。
なお、この文献にまとめられた全パターンをモデル・ファイルにしたものがVensim PLEにも付属している(Helpフォルダ>Modelフォルダ>Moleculesフォルダ内)。
Jim Hines(1996->2005), Molecules of Structure Building Blocks for System Dynamics Models.
http://www.systemswiki.org/images/a/a8/Molecule.pdf
・事例集 Tom Fiddaman's System Dynamics Model LibraryにはVensimでつくられた様々なモデル(資源・環境系と経営・経済系のモデルが多い)を集められている。
http://www.metasd.com/models/index.html

