
本記事は、Dhilip Subramanian氏による「6 Cool Python Libraries That I Came Across Recently」(2021年7月12日公開)の和訳を、著者の許可を得て掲載しているものです。
最近見つけたクールなPythonライブラリ6選
機械学習のためのすごいPythonライブラリ

Image by Free-Photos from Pixabay
はじめに
Pythonは機械学習に不可欠な要素で、ライブラリは作業をより単純にしてくれます。最近、MLのプロジェクトに取り組んでいる時に、素晴らしいライブラリを6つ見つけました。ここでは、それを紹介します。
1. clean-text
clean-textは本当に素晴らしいライブラリで、スクレイピングやソーシャルメディアデータを処理する時にまず使うべきものです。最も素晴らしい点は、データをクリーンアップするために長く凝ったコードや正規表現を必要としないことです。
いくつかの例を見てみましょう。
インストール
!pip install cleantext
例
#Importing the clean text library
from cleantext import clean
# Sample text
text = """ Zürich, largest city of Switzerland and capital of the
canton of 633Zürich. Located in an Al\u017eupine.
([https://google.com](https://google.com/)). Currency is not ₹"""
# Cleaning the "text" with clean text
clean(text,
fix_unicode=True,
to_ascii=True,
lower=True,
no_urls=True,
no_numbers=True,
no_digits=True,
no_currency_symbols=True,
no_punct=True,
replace_with_punct=" ",
replace_with_url="",
replace_with_number="",
replace_with_digit=" ",
replace_with_currency_symbol="Rupees")
出力

上記から、Zurichという単語にUnicod(「u」の文字がエンコードされている)、ASCII文字(Al\u017eupine)、ルピー通貨記号、HTMLリンク、句読点を含むことがわかります。
clean関数では、必要なASCII、Unicode、URL、数値、通貨、句読点を指定するだけです。または、置換パラメータに置き換えることもできます。例えば、ルピー記号をRupeesに変更しました。
正規表現や長いコードは全く必要ありません。特に、スクレイピングやソーシャルメディアデータからテキストをクリーンアップしたい場合は、非常に便利なライブラリです。必要に応じて、引数をすべて組み合わせるのではなく、個別に渡すこともできます。
詳細については、GitHubリポジトリを確認してください。
2. drawdata
drawdataは、もう1つの便利なpythonライブラリです。MLの概念をチームに説明しなければならない状況に、何回遭遇しましたか?データサイエンスはチームワークが大事なので、よくあることでしょう。このライブラリは、Jupyterノートブックにデータセットを描くのに役立ちます。
個人的には、MLの概念をチームに説明する時に、このライブラリを使うのはとても楽しかったです。このライブラリを作成した開発者に賛辞を送ります!
drawdataは、4つのクラスの分類問題のみを対象としています。
インストール
!pip install drawdata
例
# Importing the drawdata
from drawdata import draw_scatter
draw_scatter()
出力

著者による画像
draw_Scatter()を実行すると、上記の描画ウィンドウが開きます。明らかに、A、B、C、Dの4つのクラスがあります。任意のクラスをクリックして、好きな点を描画できます。各クラスは、描画中に異なる色を描画します。データをcsvまたはjsonファイルとしてダウンロードするオプションもあります。また、データをクリップボードにコピーして、下記のコードから読み取ることもできます。
#Reading the clipboard
import pandas as pd
df = pd.read_clipboard(sep=",")
df
このライブラリの限界の1つは、4つのクラスで2つのデータポイントしか提供しないことです。しかしそれ以外の点では、このライブラリを使う価値は十分あります。
詳細については、GitHubリンクを確認してください。
3. Autoviz
matplotlibをって探索的データ分析をしていた時のことは一生忘れないでしょう。多くの単純な可視化ライブラリがありますが、最近、1行のコードであらゆるデータセットを自動的に可視化するAutovizを知りました。
インストール
!pip install autoviz
例
この例では、IRISデータセットを使用しました。
# Importing Autoviz class from the autoviz library
from autoviz.AutoViz_Class import AutoViz_Class
#Initialize the Autoviz class in a object called df
df = AutoViz_Class()
# Using Iris Dataset and passing to the default parameters
filename = "Iris.csv"
sep = ","
graph = df.AutoViz(
filename,
sep=",",
depVar="",
dfte=None,
header=0,
verbose=0,
lowess=False,
chart_format="svg",
max_rows_analyzed=150000,
max_cols_analyzed=30,
)
上記のパラメータはデフォルトです。詳細については、こちらを確認してください。
出力
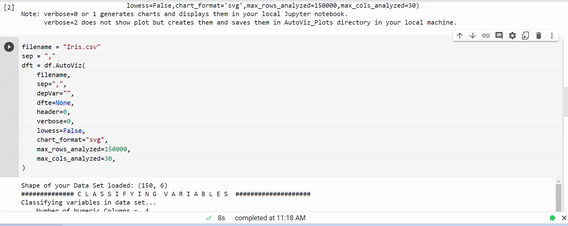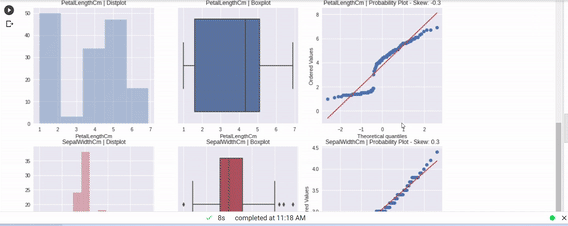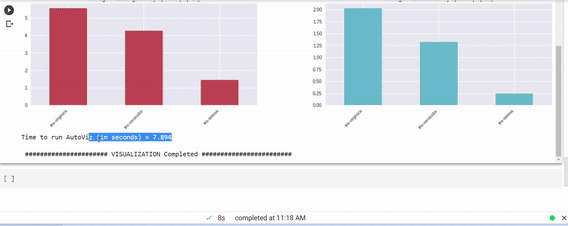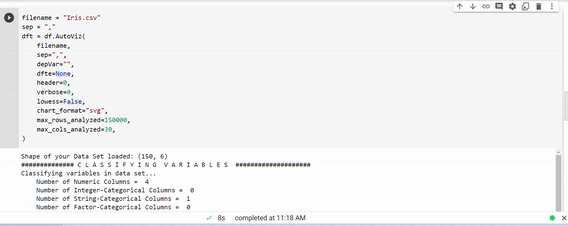
著者による画像
たった1行のコードで、全ビジュアルを確認し、EDAを完成させることができます。多くの自動可視化ライブラリがありますが、特にこのライブラリに慣れ親しむのはとても楽しかったです。
4. Mito
みんなExcelが好きですよね?Excelはデータセット探索の最も簡単な最初の方法の1つです。Mitoに出会ったのは数ヶ月前ですが、使ってみたのはつい最近で、とても気に入りました!
これはJupyter-lab拡張Pythonライブラリで、表計算機能を追加するGUIをサポートしています。csvデータを読み込み、データセットをスプレッドシートとして編集すると、自動的にPandasコードを生成します。とてもクールです。
Mitoを紹介するには、ブログ1記事を要します。しかし、今日はあまり詳しく説明しません。代わりに、簡単なタスクのデモを紹介します。詳細については、こちらを確認してください。
インストール
#First install mitoinstaller in the command prompt
pip install mitoinstaller
# Then, run the installer in the command prompt
python -m mitoinstaller install
# Then, launch Jupyter lab or jupyter notebook from the command prompt
python -m jupyter lab
インストールの詳細については、こちらを確認してください。
# Importing mitosheet and ruuning this in Jupyter lab
import mitosheet
mitosheet.sheet()
上記のコードを実行すると、jupyter labでmitosheetが開きます。私はIRISデータセットを使用しています。まず、2つの新しい列を作成します。1つはがく片長、もう1つはがく片幅の合計です。次に、平均がく片長の列名を変更します。最後に、平均がく片長の列のヒストグラムを作成します。
この手順を実行すると、コードが自動的に生成されます。
出力
