The Internet Archive is pleased to announce it has joined the The Information Delivery Services (IDS) Project, a mutually supportive resource-sharing cooperative whose 120 members include public and private academic libraries from across the country. As a member of the IDS Project, the Internet Archive expands its ability to support libraries and library patrons by providing access to two million monographs and three thousand periodicals in its physical collections available for non-returnable interlibrary loan (ILL) fulfillment.
“The Internet Archive is a wonderful addition to the IDS Project’s team of libraries. It is a great honor to be able to help IA reach more libraries and more patrons through the integration with IDS Logic,” said Mark Sullivan, Executive Director of the IDS Project.
If you want to learn more about the IDS Project and the Internet Archive, I will be speaking at the 17th Annual IDS Summer Conference on July 29th.
In addition to the IDS Project, the Internet Archive is also piloting a program with libraries through RapidILL. If there are other resource sharing efforts that we should investigate as we expand our ILL service, please reach out to me at brewster@archive.org.
Libraries have historically been trusted hubs to equalize access to credible information, a crucial role that they should continue to fill in the digital age. However, as more information is born-digital, digitized, or digital-first, libraries must build new policy, legal and public understandings about how advances in technology impact our preservation, community, and collection development practices.
This panel will bring together legal scholars Ariel Katz (University of Toronto) and Argyri Panezi (IE University Madrid/Stanford University) to discuss their work on library digital exhaustion and public service roles for digital libraries. They will be joined by Lisa Radha Weaver, Director of Collections and Program Development at Hamilton Public Library, who will discuss how library services have been transformed by digital delivery and innovation and Kyle Courtney of Library Futures/Harvard University, a lawyer/librarian who wrote the influential Statement on Controlled Digital Lending, signed by over 50 institutions. The panel will be moderated by Lila Bailey of Internet Archive.
Hansen, D. R., & Courtney, K. K. (2018, September 24). A White Paper on Controlled Digital Lending of Library Books. https://doi.org/10.31228/osf.io/7fdyr
Panezi, Argyri, A Public Service Role For Digital Libraries: The Unequal Battle Against (Online) Misinformation Through Copyright Law Reform And The Emergency Electronic Access To Library Material (March 26, 2021). Forthcoming, 31 CORNELL J.L. & PUB. POL’Y _ _ (2021), Available at SSRN: https://ssrn.com/abstract=3813320
Whenever I’ve had a book published I have celebrated every sale. But the biggest cause for celebration – the sale that always made me most proud – was when a library acquired a copy or two. Individuals may purchase a book, shelve it or pass it along to a friend, and thereafter it disappears. Libraries are forever.
Fran Moreland Johns
This is the belief that underscores my enthusiasm for the Internet Archive. While the Atlanta Public Library may one day cull my book to make room for someone else’s, those words I labored over and so treasure, whether anyone else ever treasures them or not, are safe with the Internet Archive. And may it thrive and prosper.
Johns writing cutlines under the rapt gaze of Richmond Times-Dispatch photographers. Disclaimer: Johns quit smoking in 1964.
This is all a very long way from my literary beginnings on a Royal portable typewriter. I wrote for newspapers and magazines – the Richmond Times-Dispatch, USA Today, National Real Estate Investor to cite just a few of the wildly different multiple dozens – from the early 1950s into the technologically bewildering 2020s. Eventually I added an MFA in short fiction to my BA in Art and veered into short stories, with a few tiny publication successes, including Dying unafraid (1999) and Perilous Times: An inside look at abortion before – and after – Roe v Wade (2013). When the internet came along, I tiptoed in via a blog for news aggregate site True/Slant.com which eventually morphed into today’s franjohns.net. With a little luck my short story collection, Marshallville Stories, will be published in 2022; the Internet Archive will get one of the first copies.
I’ve been following the conflict between U.S. publishers and the Internet Archive with some degree of horror and dismay. Publishers, I realize, are in business to make money and thereby stay in business. Do they not want people, as many people as possible, to read the books they publish? After the first flurry of sales (perhaps excluding the blockbuster books that will make big bucks for authors and publishers alike, may they also thrive and prosper) does it not follow that publishers would want their books to enjoy long and successful lives? That, at least, is the hope I believe most authors harbor. I can’t claim to speak for other authors, but this I know is personally true: I write for the joy of writing, and in the hope of being read. I’d be surprised if there were many writers out there who don’t feel the same.
So let’s hear it for libraries. And for the one that’s unique among all others, the Internet Archive.
***
Fran Moreland Johns has been writing (for newspapers, magazines, online sites) since the 1950s, and blogging since she was introduced to the idea via a paid blog for news aggregate site True/Slant in 2009. Her roots are in small town Virginia and her heart is in hometown San Francisco. She currently blogs on Medium.com and www.franjohns.net. You can read Dying unafraid (1999) online through the Internet Archive’s lending library.
Photo by Rory Mitchell, The Mercantile, 2020 – CC by 4.0
(L-R) Brewster Kahle, Tamiko Thiel, Carl Feynman at Thinking Machines, May 1985. Photo courtesy of Tamiko Thiel.
A Library of Everything
As a young man, I wanted to help make a new medium that would be a step forward from Gutenberg’s invention hundreds of years before.
By building a Library of Everything in the digital age, I thought the opportunity was not just to make it available to everybody in the world, but to make it better–smarter than paper. By using computers, we could make the Library not just searchable, but organizable; make it so that you could navigate your way through millions, and maybe eventually billions of web pages.
The first step was to make computers that worked for large collections of rich media. The next was to create a network that could tap into computers all over the world: the Arpanet that became the Internet. Next came augmented intelligence, which came to be called search engines. I then helped build WAIS–Wide Area Information Server–that helped publishers get online to anchor this new and open system, which came to be enveloped by the World Wide Web.
By 1996, it was time to start building the library.
This library would have all the published works of humankind. This library would be available not only to those who could pay the $1 per minute that LexusNexus charged, or only at the most elite universities. This would be a library available to anybody, anywhere in the world. Could we take the role of a library a step further, so that everyone’s writings could be included–not only those with a New York book contract? Could we build a multimedia archive that contains not only writings, but also songs, recipes, games, and videos? Could we make it possible for anyone to learn about their grandmother in a hundred years’ time?
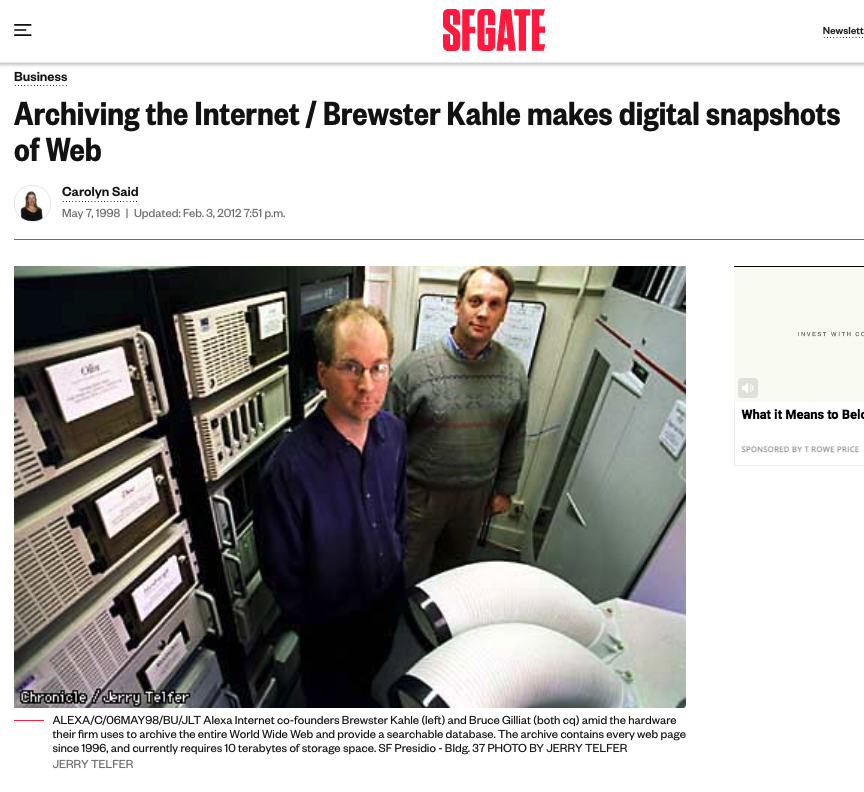
From the San Francisco Chronicle, Business Section, May 7, 1988. Photo by Jerry Telfer.
Not about an Exit or an IPO
From the beginning, the Internet Archive had to be a nonprofit because it contains everybody else’s things. Its motives had to be transparent. It had to last a long time.
In Silicon Valley, the goal is to find a profitable exit, either through acquisition or IPO, and go off to do your next thing. That was never my goal. The goal of the Internet Archive is to create a permanent memory for the Web that can be leveraged to make a new Global Mind. To find patterns in the data over time that would provide us with new insights, well beyond what you could do with a search engine. To be not only a historical reference but a living part of the pulse of the Internet.
John Perry Barlow, lyricist for the Grateful Dead & founder of the Electronic Frontier Foundation, accepting the Internet Archive Hero Award, October 21, 2015. Photograph by Brad Shirakawa – CC by 4.0
Looking Way Back
My favorite things from the early era of the Web were the dreamers.
In the early Web, we saw people trying to make a more democratic system work. People tried to make publishing more inclusive.
We also saw the other parts of humanity: the pornographers, the scammers, the spammers, and the trolls. They, too, saw the opportunity to realize their dreams in this new world. At the end of the day, the Internet and the World Wide Web–it’s just us. It’s just a history of humankind. And it has been an experiment in sharing and openness.
The World Wide Web at its best is a mechanism for people to share what they know, almost always for free, and to find one’s community no matter where you are in the world.
Brewster Kahle speaking at the 2019 Charleston Library Conference. Photo by Corey Seeman– CC by 4.0
Looking Way Forward
Over the next 25 years, we have a very different challenge. It’s solving some of the big problems with the Internet that we’re seeing now. Will this be our medium or will it be theirs? Will it be for a small controlling set of organizations or will it be a common good, a public resource?
So many of us trust the Web to find recipes, how to repair your lawnmower, where to buy new shoes, who to date. Trust is perhaps the most valuable asset we have, and squandering that trust will be a global disaster.
We may not have achieved Universal Access to All Knowledge yet, but we still can.
In another 25 years, we can have writings from not a hundred million people, but from a billion people, preserved forever. We can have compensation systems that aren’t driven by advertising models that enrich only a few.
We can have a world with many winners, with people participating, finding communities of like-minded people they can learn from all over the world. We can create an Internet where we feel in control.
I believe we can build this future together. You have already helped the Internet Archive build this future. Over the last 25 years, we’ve amassed billions of pages, 70 petabytes of data to offer to the next generation. Let’s offer it to them in new and exciting ways. Let’s be the builders and dreamers of the next twenty-five years.
See a timeline of Key Moments in Access to Knowledge, videos & an invitation to our 25th Anniversary Virtual Celebration at anniversary.archive.org.
If you’ve spent much time reading 19th-century novels, you’ve probably run across characters doing the same thing—that is, reading novels.
In Barchester Towers, Eleanor sits “in the window to get the advantage of the last daylight for her novel.” AnnaKarenina waits for her husband “in front of the fireplace with her English novel.” And in Jane Eyre, Georgiana falls “asleep on the sofa over the perusal of a novel.”
What novels were they reading? While Eleanor might have been reading Jane Eyre and Anna might have been perusing Barchester Towers, it’s more likely that they were reading some of the thousands of other novels published in that century. Novels were the binge-watched television, the hit podcasts of the era—immersive, addictive, commercial—and they were produced and consumed in huge numbers.
Some of those novels are, of course, still read today. But for every Pride and Prejudice or A Tale of Two Cities, dozens more have been forgotten. In the 20th century, the novel came to be regarded as serious literature, something to be taught and studied, and attention narrowed to a limited number of authors and works. And as the books themselves aged, their paper turning yellow and brittle, libraries removed them from their shelves. With readers having access only to the reprinted “classics” that still made money for publishers, the vast majority of 19th-century novels were forgotten and unread.
Now, however, thanks to preservation and scanning by libraries at the University of Illinois at Urbana-Champaign and elsewhere, thousands of those forgotten novels are available at the Internet Archive. The list below has links to fifty of them—mostly British novels published between 1800 and 1899—as well as to Wikipedia articles for many of the authors.
I compiled this list after reading a fascinating recent study by Melanie Walsh and Maria Antoniak about books regarded as classics by users of the book-rating site Goodreads. They found that readers today seem to read mainly the well-known canonical works. Jane Eyre, for example, has more than 1,700,000 ratings at Goodreads and over 45,000 reviews.
For the following list, I chose only 19th-century novels that, as of May 2021, have not been reviewed or rated by anyone at Goodreads. There are many such forgotten novels in the Internet Archive’s collections, and it’s likely that some of them have not been read by anyone for over a century.
Would you like to be the first?
Tom Gally lives in Yokohama, Japan, and teaches at the University of Tokyo. In 2019, he wrote about travel books found at the Internet Archive.
Last week the public interest Internet community lost one of its most passionate advocates, and I lost a friend. On July 7th, I learned that Sherwin Siy, Policy Counsel for the Wikimedia Foundation and my classmate at Berkeley Law School, had suddenly passed away at the age of 40.
Sherwin and I began our public interest tech careers together when we were students at the Samuelson Law, Technology & Public Policy Clinic. We were partners on a project helping the Internet Archive understand the legal landscape for archiving and making available television news. From that project and through the rest of my career, I learned so much from working with him, not just about substantive law and policy, but about collaboration and collegiality. He was thoughtful, patient, and kind. He was funny, and so very smart. He will be deeply missed.
You can find remembrances from other colleagues of his from EFF (here) and Public Knowledge (here).
In an effort to help more people understand how Controlled Digital Lending works, the Internet Archive is helping coordinate two sessions in July. Both sessions are free, virtual, and open to the public.
Empowering Libraries Through Controlled Digital Lending – July 13
The Internet Archive’s Open Libraries program empowers libraries to lend digital books to patrons using Controlled Digital Lending. Attendees will learn how CDL works, the benefits of the Open Libraries program, and the impact that the program is having for partner libraries and the communities they serve.
Implementation & Integration: CDL for All Libraries – July 14
For the second event in a summer series about the innovative library practice of Controlled Digital Lending, we’ll hear from libraries, consortia, and librarians who are exploring CDL implementations at their institutions and communities with hands on learning around potential and existing solutions. Learn about building institutional CDL policies, user experience for patrons and staff, technological platforms, and how you can get involved with the CDL community. Bring your questions, ideas, and be prepared to dig in!
Co-hosted by Library Futures, Internet Archive, Project Reshare, Open Library Foundation, and CDL Implementers
Much of the art gallery, artist, and arts organization materials that were once published in print form are now available primarily or solely on the web. These groups, like many in the cultural sector, have also been hit especially hard by the global pandemic, making their web presences particularly at-risk of being lost if they are not proactively collected and preserved.The creation of reference and research resources that promote streamlined access and enable new types of scholarly use will ensure that the art historical record of the 21st century, and especially of our current global pandemic, is readily accessible far into the future.
For this reason, the Internet Archive, along with the New York Art Resources Consortium (NYARC), are pleased to announce our project Consortial Action to Preserve Born-Digital, Web-Based Art History & Culture. The project recently received a two-year, $305,343 Humanities Collections and Reference Resources grant from the Division of Preservation and Access at the National Endowment for the Humanities. This award will support the formation of a cooperative group of 30+ art and museum libraries from across the United States to collaborate on the preservation of, and access to vital arts content from the web.
The Internet Archive has a long history of building and supporting collaborative communities and providing non-profit web, preservation, and access services to cultural heritage organizations. The multi-institutional initiative between Internet Archive, NYARC, and other arts and museum organizations will build on similar community-based archiving and professional cultivation projects in the Community Programs group, especially our Community Webs program, currently expanding nationally and internationally. Community Webs has received funding from The Andrew W. Mellon Foundation and IMLS to provide public libraries and cultural heritage organizations with services, training, and professional development opportunities to document their diverse local history.
NYARC are pioneers in collaborative web archiving and shared services, among art and museum libraries. NYARC’s robust web archive collections encompass art resources, artists’ websites, auction catalogs, catalogues raisonnes, and hundreds of New York City gallery websites. The Internet Archive and NYARC have partnered on work to build born-digital collecting capacity among arts organizations in the past, most recently in the IMLS-funded Advancing Art Libraries and Curated Web Archives National forum and related events. Through discussions, workshops and roadmapping sessions with leaders in art and museum libraries, a strategy and plan towards an inclusive, sustainable, cooperative approach to collecting and stewarding born-digital, locally-focused art history collection was developed, forming the basis of this broader cooperative effort.
Members in the project’s preliminary group of art and museum libraries will select topics and specific web content that is relevant to their expertise, will provide metadata to facilitate access to archived content, and will participate in planning and evaluation meetings, all while curating a valuable reference resource that will enhance their traditional collecting areas. The Internet Archive will coordinate communications, facilitate governance and collective curatorial activities, provide technical digital library and archive services, and help enable members to build and maintain discovery and access platforms, as well as facilitate researcher use of the collections resulting from the group’s work.
If your art or museum library is interested in joining this collaborative effort, please fill out this participation form by July 31 to join us!
The Library of Congress announced that Brewster Kahle, Digital Librarian and founder of the Internet Archive, has been named to the Copyright Public Modernization Committee (CPMC), with a mission to help modernize the technology-related aspects of the U.S. Copyright Office. More specifically the CPMC will support “the development of the new Enterprise Copyright System (ECS), which includes the Office’s registration, recordation, public records, and licensing IT applications, and will be encouraged to help spread awareness of the Library’s development efforts more broadly.”
The thirteen member panel is composed of leaders from the library and university worlds along with representatives from trade organizations representing the recording and publishing industries, and corporate giants Amazon and Warner Media. Kahle, who holds a BS in Computer Science and Engineering from the Massachusetts Institute of Technology, brings decades of experience in digital library issues, and is an inaugural member of the Internet Hall of Fame. “I am excited to collaborate to help modernize the U.S. Copyright Office. Let’s see how far we can get,” says Kahle.
The first meeting of the CPMC is on July 22, 2021 from 1-4 PM eastern time and is open to the public, by registration only. Register of Copyrights Shira Perlmutter and Library of Congress chief information officer Bud Barton will provide opening remarks, and Library subject-matter experts will provide an update on the development of ECS and other modernization efforts. Attendees will have an opportunity to hear directly from CPMC members and participate in a live Q&A. The meeting will be recorded and made available for viewing after the event.