
The concept of inhuman intelligence goes back to the deep prehistory of mankind. At first the province of gods, demons, and spirits, it transferred seamlessly into the interlinked worlds of magic and technology. Ancient Greek myths had numerous robots, made variously by gods or human inventors, while extant artefacts like the Antikythera calendrical computer show that even in 200 BCE we could build machinery that usefully mimicked human intellectual abilities.
There has been no age or civilisation without a popular concept of artificial intelligence (AI). Ours, however, is the first where the genuine article—machinery that comfortably exceeds our own thinking skills—is not only possible but achievable. It should not be a surprise, then, that our ideas of what that actually means and what will actually happen are hopelessly coloured by cultural assumptions ancient and modern.
We rarely get it right: Kubrick’s 2001 saw HAL 9000 out-thinking highly trained astronauts to murderous effect; Bill Gates’ 2001 gave us Clippy, which was more easily dealt with.
Now, with AI a multi-billion dollar industry seeping into our phones, businesses, cars, and homes, it’s time to bust some of the most important AI myths and dip into some reality.
Myth: AI is all about making machines that can think
When digital computing first became practical in the middle of the last century, there were high hopes that AI would follow in short order. Alan Turing was famously comfortable with the concept in his 1948 “Intelligent Machinery” paper, seeing no objections to a working, thinking machine by the end of the century. Sci-fi author Isaac Asimov created Multivac, a larger, brighter version of actual computers such as the 1951 UNIVAC 1, first used by the US Census Bureau. (The favour was later returned by IBM, when it named the first chess computer to outrank all humans Deep Blue after Douglas Adams’ hyperintelligent Deep Thought machine from the HitchHiker’s Guide To The Galaxy.)
There are many projects and much research going on into replicating human-like thought, mostly by hardware and software simulations of human brain structures and functions as new techniques reveal them. One of the higher-profile efforts is the Blue Brain project at the Brain and Mind Institute of the École Polytechnique Fédérale de Lausanne (EPFL) in Switzerland, which started in 2005 with a target date for a working model roughly equivalent to some human functions by 2023.
There are two main problems for any brain simulator. The first is that the human brain is extraordinarily complex, with around 100 billion neurons and 1,000 trillion synaptic interconnections. None of this is digital; it depends on electrochemical signaling with inter-related timing and analogue components, the sort of molecular and biological machinery that we are only just starting to understand.

Even much simpler brains remain mysterious. The landmark success to date for Blue Brain, reported this year, has been a small 30,000 neuron section of a rat brain that replicates signals seen in living rodents. 30,000 is just a tiny fraction of a complete mammalian brain, and as the number of neurons and interconnecting synapses increases, so the simulation becomes exponentially more complex—and exponentially beyond our current technological reach.
This yawning chasm of understanding leads to the second big problem: there is no accepted theory of mind that describes what “thought” actually is.
This underlying quandary—attempting to define “thought”—is sometimes referred to as the hard problem, and the results of understanding it are called strong AI. People engaged in commercial AI remain sceptical that it will be resolved any time soon, or that it is necessary or even desirable to do for any practical benefits. There is no doubt that artificial intelligences are beginning to do very meaningful work and that the speed of change of technology will continue to shunt things along, but full-blown sentience still seems far-fetched.
IBM Watson, one of the highest-profile successes in AI to date, started its life as an artificial contender on the American TV game show Jeopardy. It combines natural language processing with a large number of expert processes that try different strategies to match an internal knowledge database with potential answers. It then checks the confidence levels of its internal experts and chooses to answer the question if those levels are high enough (see below right).
The first serious application of Watson that might actually improve the quality of human life has been as a diagnostic aid in cancer medicine. Since 2011, Watson has been assisting oncologists by delving through patient medical records and trying to correlate that data with clinical expertise, academic research, or other sources of data in its memory banks. The end result is that Watson might offer up treatment options that the human doctor may not have previously considered.
“[It’s like] having a capable and knowledgeable ‘colleague’ who can review the current information that relates to my patient,” said Dr. James Miser, the chief medical information officer at Bumrungrad international hospital in Thailand. “It is fast, thorough, and has the uncanny ability to understand how the available evidence applies to the unique individual I am treating.”
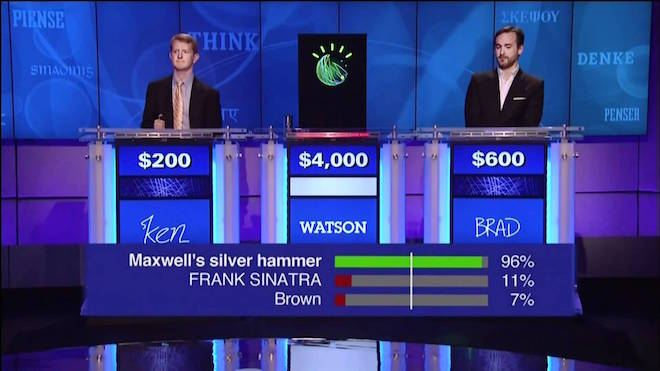
As marvellous as this sounds, it mostly serves to highlight the similarities and differences between current, narrow, practical AI and its strong, as-yet-mythical cousin. One basic engine of both is the neural network, a system based on basic biological concepts that takes a set of inputs and attempts to match them to things that have previously been seen by the neural network. The key concept is that the system isn’t told how to do this analysis; instead, it learns by being given both inputs and outputs for a correct solution and then adjusting its own computational pathways to create internal knowledge to be used on later, unknown inputs.
We are now at the point where Watson and other AI systems such as Facebook’s DeepFace facial recognition system can do this with narrow, constrained data sets, but they are generally incapable by themselves of extending beyond the very specific tasks they’ve been programmed to do.
Google, for its part, seems content with narrow AI—searching pictures by content, crunching environmental and science data, and machine language translation—than predicting the emergence of general strong AI. The human brain can find, utilise, and link together vastly more complicated and ill-defined data, performing feats of recognition and transformation that can model entire universes. Google projects like DeepMind are experimenting with combining different techniques—in one case, using neural networks alongside reinforcement learning where the machine generates random inputs until it happens to hit on a rewarding strategy, which it refines—to try and close the gap, but they still act on very specific, narrow tasks.
Most recently, the DeepMind project used this combination of techniques to “master a diverse range of Atari 2600 games.” Speaking to Wired, Google researcher Koray Kavukcuoglu said his team has built “a general-learning algorithm that should be applicable to many other tasks”—but learning how to perform a task is a long way away from consciously thinking about those tasks, what the repercussions of those tasks might be, or having the wherewithal to opt out of doing those tasks in the first place.




































reader comments
120 with 79 posters participatingShare this story