
Appleの移動データを加工したらわかった東京の厳しい現実

こんにちは、Exploratoryの白戸です。
Appleは新型コロナウイルスの対策支援として、Appleマップでの経路検索をもとにした移動傾向のデータを公開しています。ところが、残念ながらこのデータはそのままでは簡単に可視化できるようなフォーマットになっておらず、ちょっとした加工を行う必要があります。
しかし逆に、加工の仕方さえわかってしまえばそれぞれの都市や地域の移動データを可視化することで、恐怖を煽るばかりのマスコミからは見えてこない現状を理解することができるようになります。
今回はこのAppleの移動傾向データを簡単に可視化できるようにするための基本的な加工方法を、みなさんと共有させていただければと思います。
データはこちらからダウンロードすることができます。
以下は「モダンでシンプルなUIを使ってデータサイエンスができる」Exploratoryを使って、「日本で最も自粛している都道府県はどこか?」といった問いに答えていきます。
データを使える形に加工・整形する
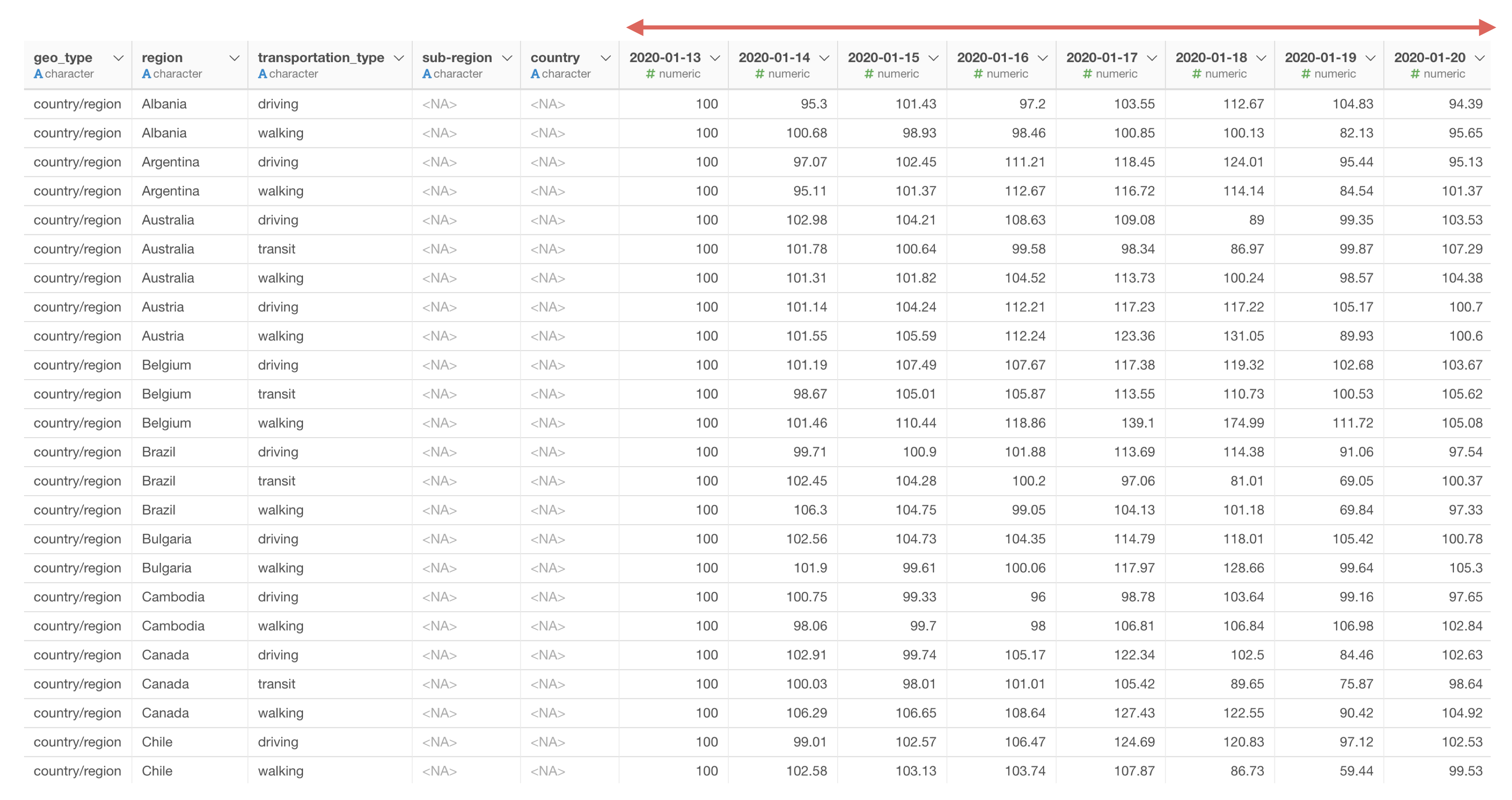
ExploratoryにAppleの移動傾向データをインポートすると、列数が453列と非常に多いことがわかります。これは、1日ごとに列があるデータになっており、2020年1月13日から2021年の4月までのデータがあるためです。ちなみに、1行はregion(地域)の単位になっていて、日本では都道府県や市区町村の単位でデータがあります。
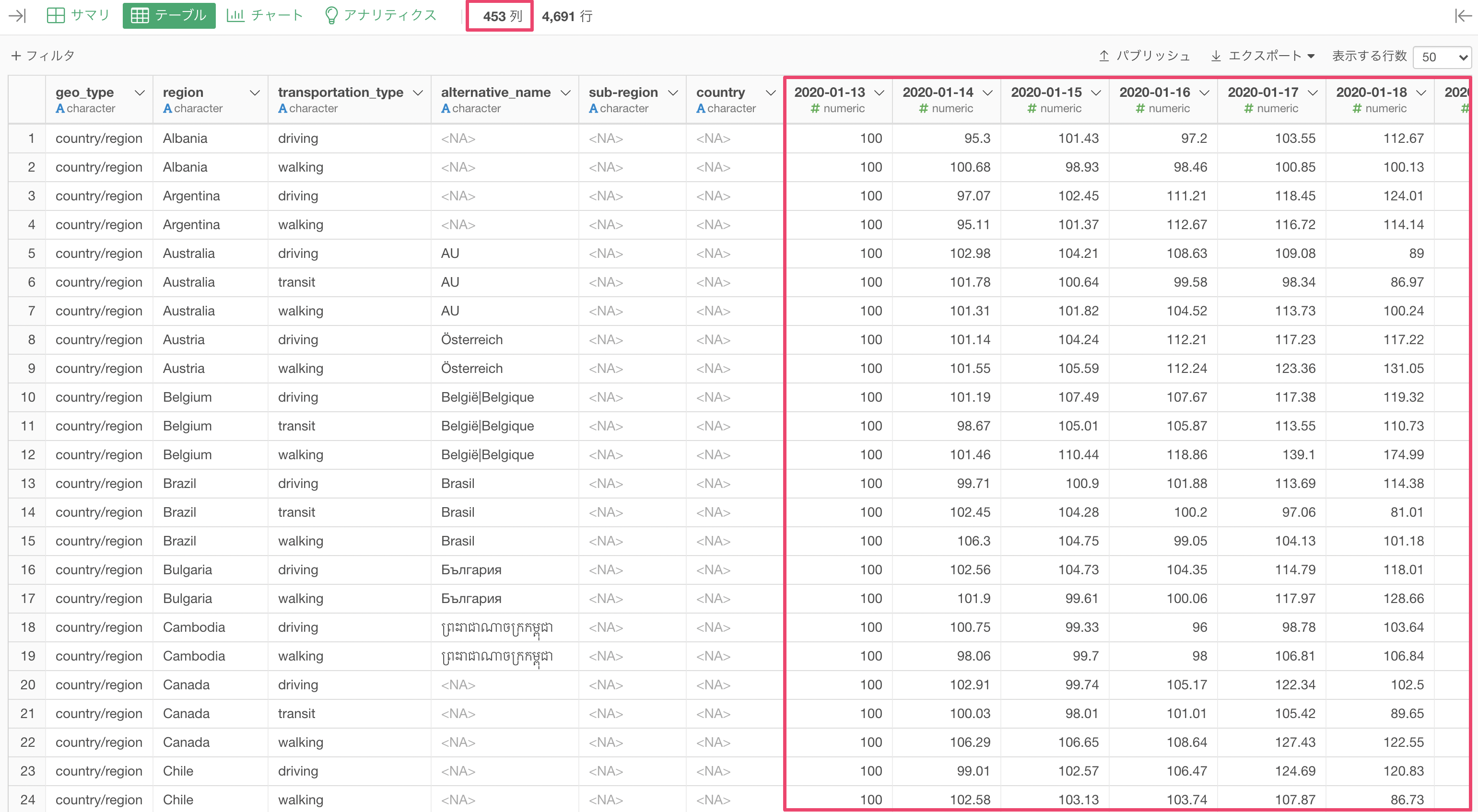
例えば、時系列の推移を可視化する時によく使用する「ラインチャート」を使って移動傾向の推移を可視化したいとします。
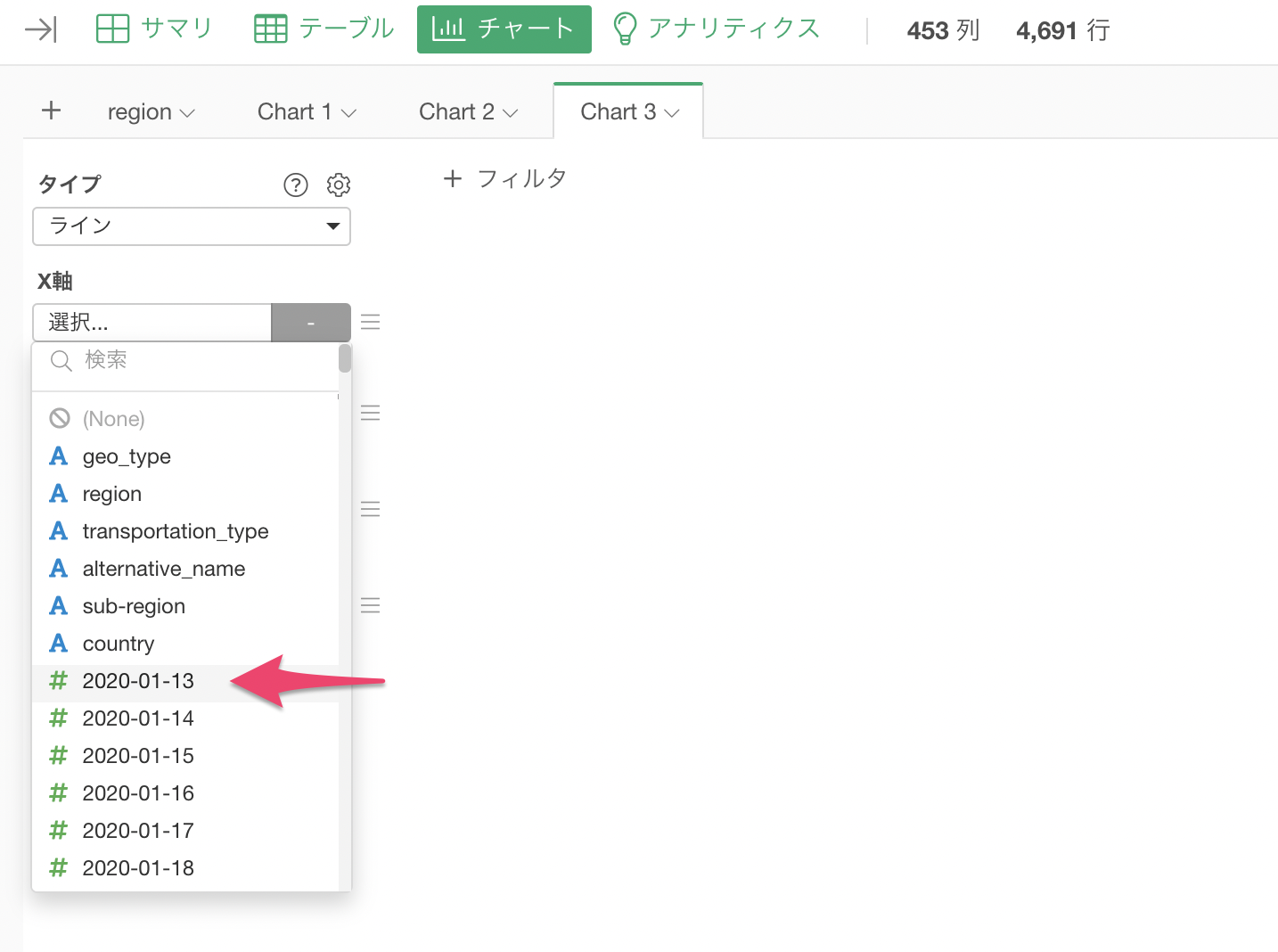
しかし、多くの可視化ツールでも同じように、X軸に日付を割り当てようとしても、1日単位で列があるデータでは一つの列しか選べないためうまく可視化ができません。
データにはワイド型(横長)とロング型(縦長)の2つの持ち方があります。
Appleの移動傾向のデータは、日付ごとに列がある横長のデータのためワイド型になります。
一方で、値の列が一列にまとまっている縦長のデータのことをロング型と言います。
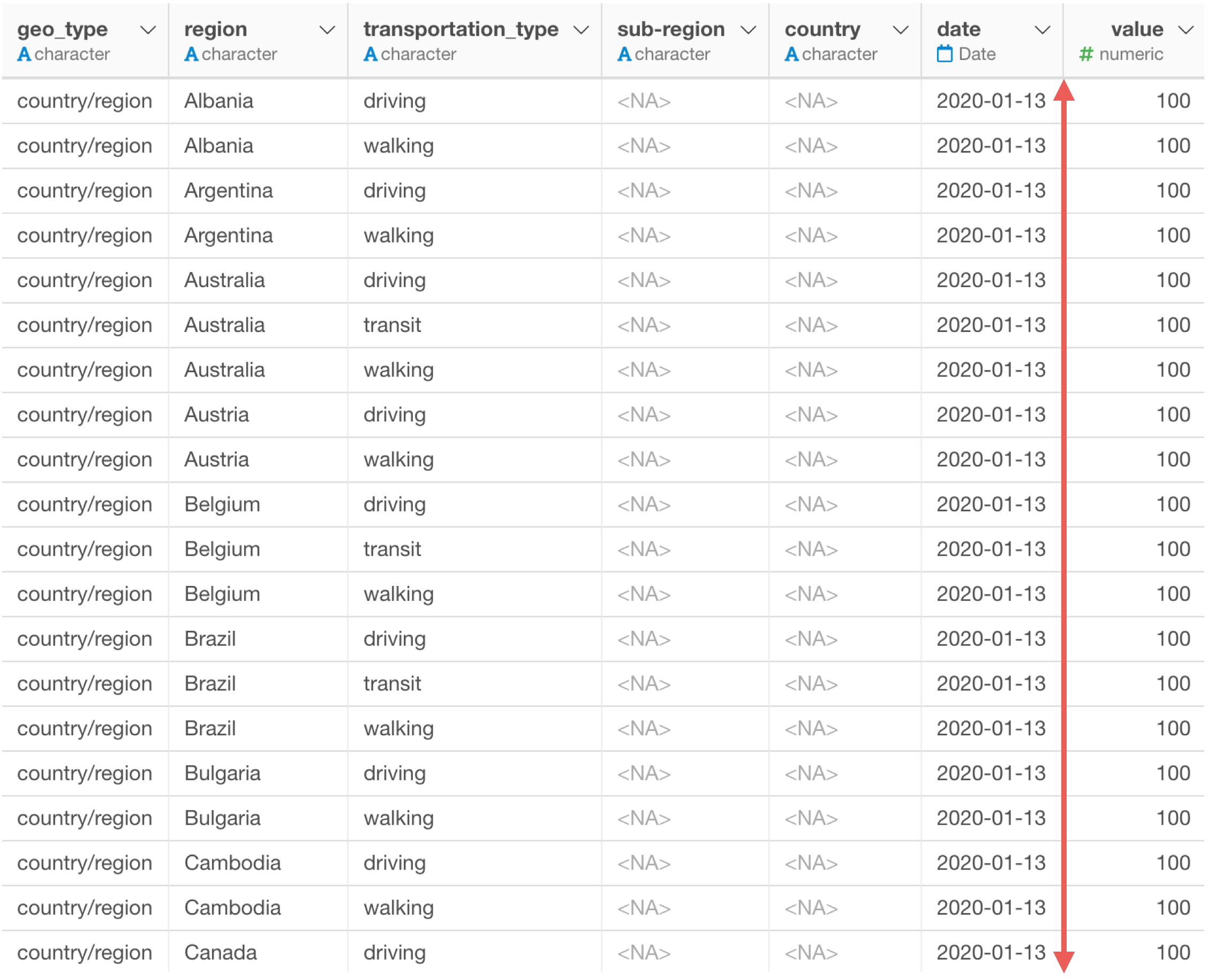
データを可視化する時には「列」を選択するため、ロング型のデータが望ましいと言われています。
ロング型にすることで、X軸に日付の列を、Y軸に値の列を割り当てていくことができます。
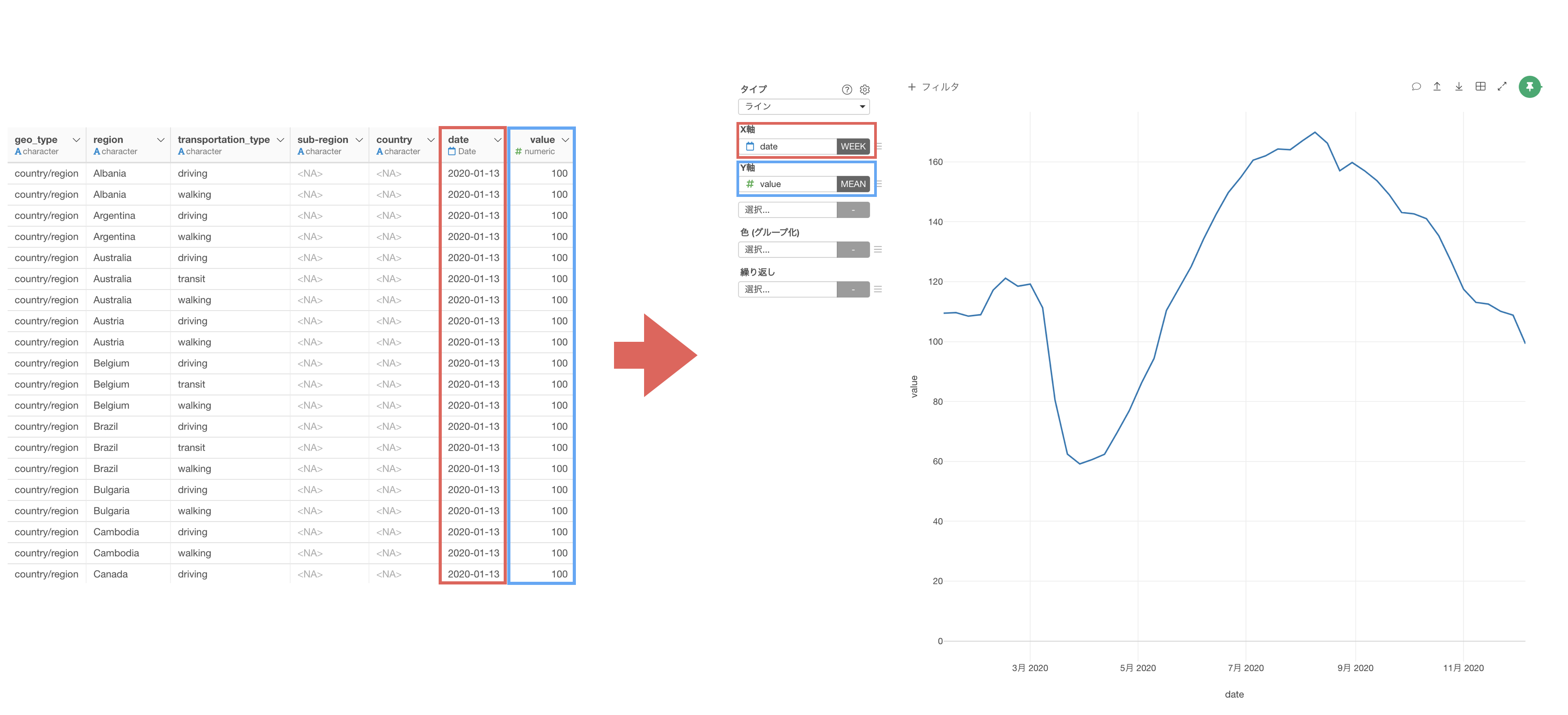
そのため、ワイド型からロング型へ変換する必要があります。
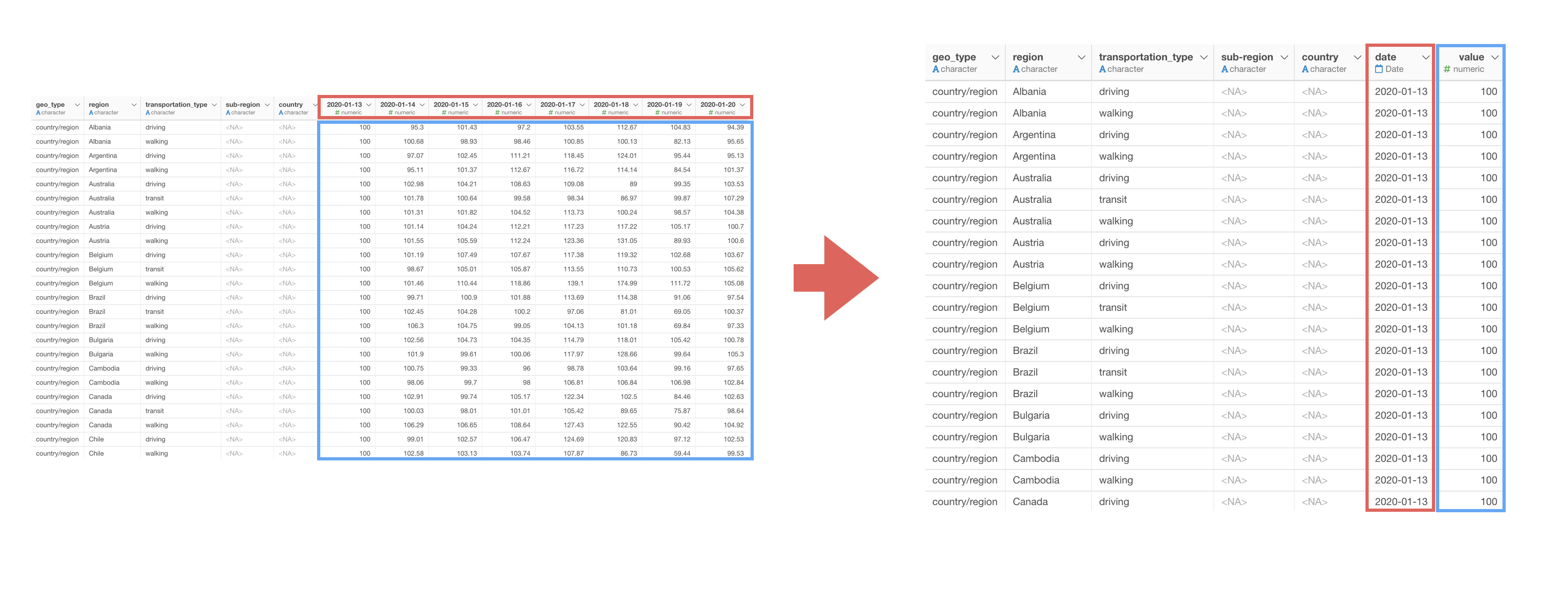
Exploratoryでは、ロング型にしたい列を選んだ状態で、列ヘッダメニューから「ワイド型からロング型へ」を簡単に呼び出して実行できます。
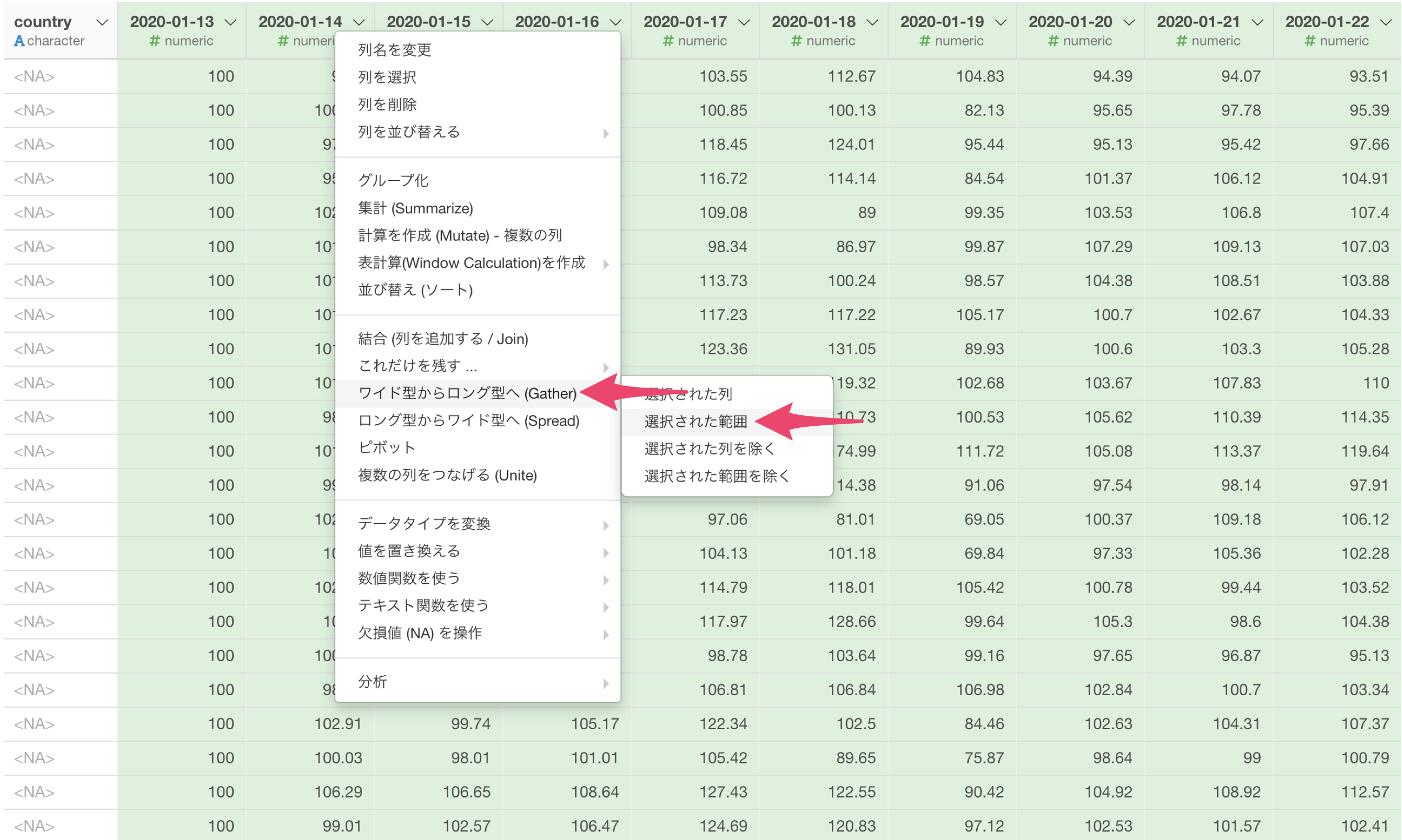
ワイド型からロング型へのダイアログで、開始に最初の日、末尾に最後の列を指定します。
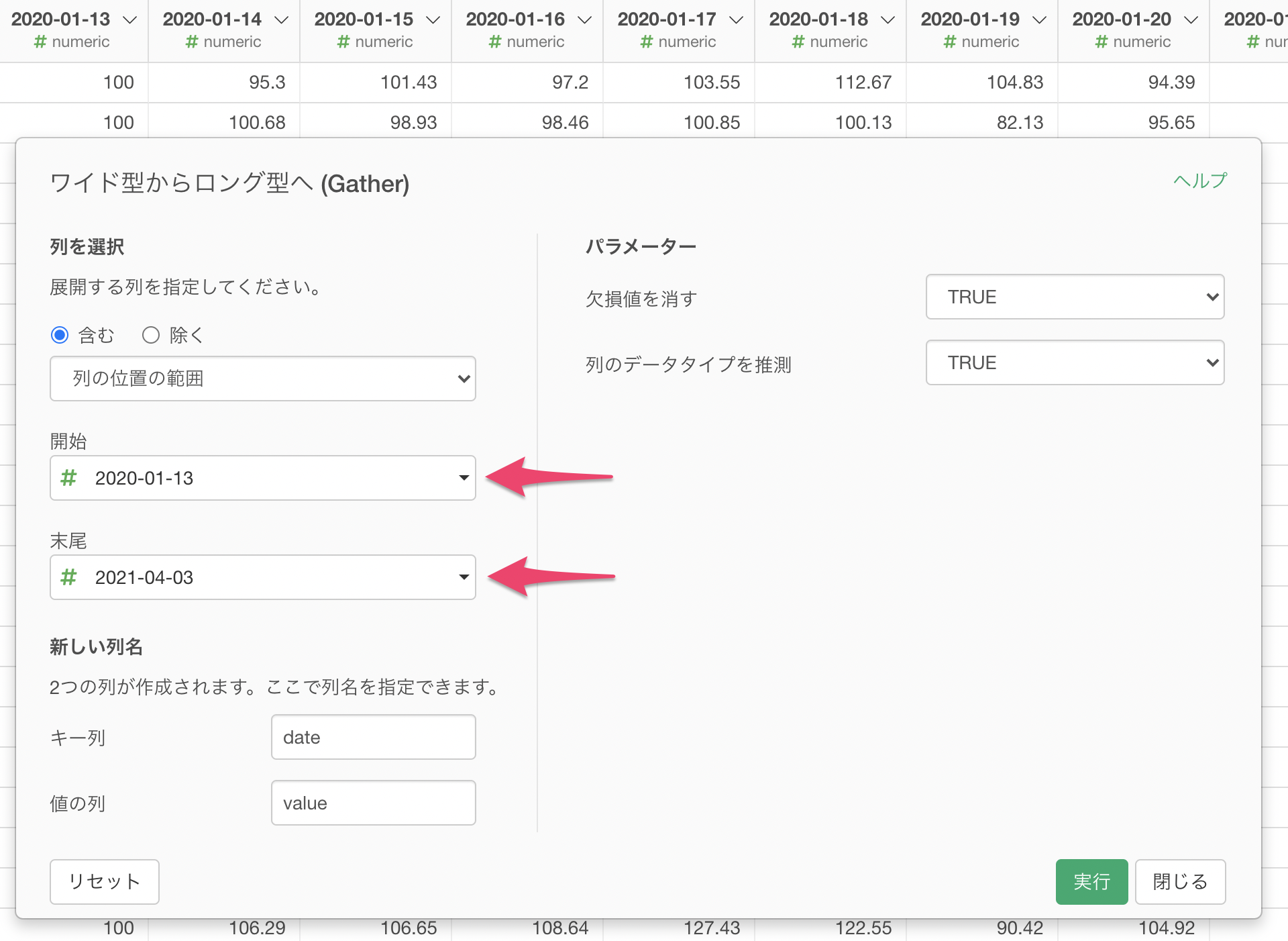
あとは、列名を指定して実行するだけです。
これにより、日ごとに列があるワイド型のデータを、日付と移動傾向の値をそれぞれ一つに列にまとめたロング型のデータに変換できます。
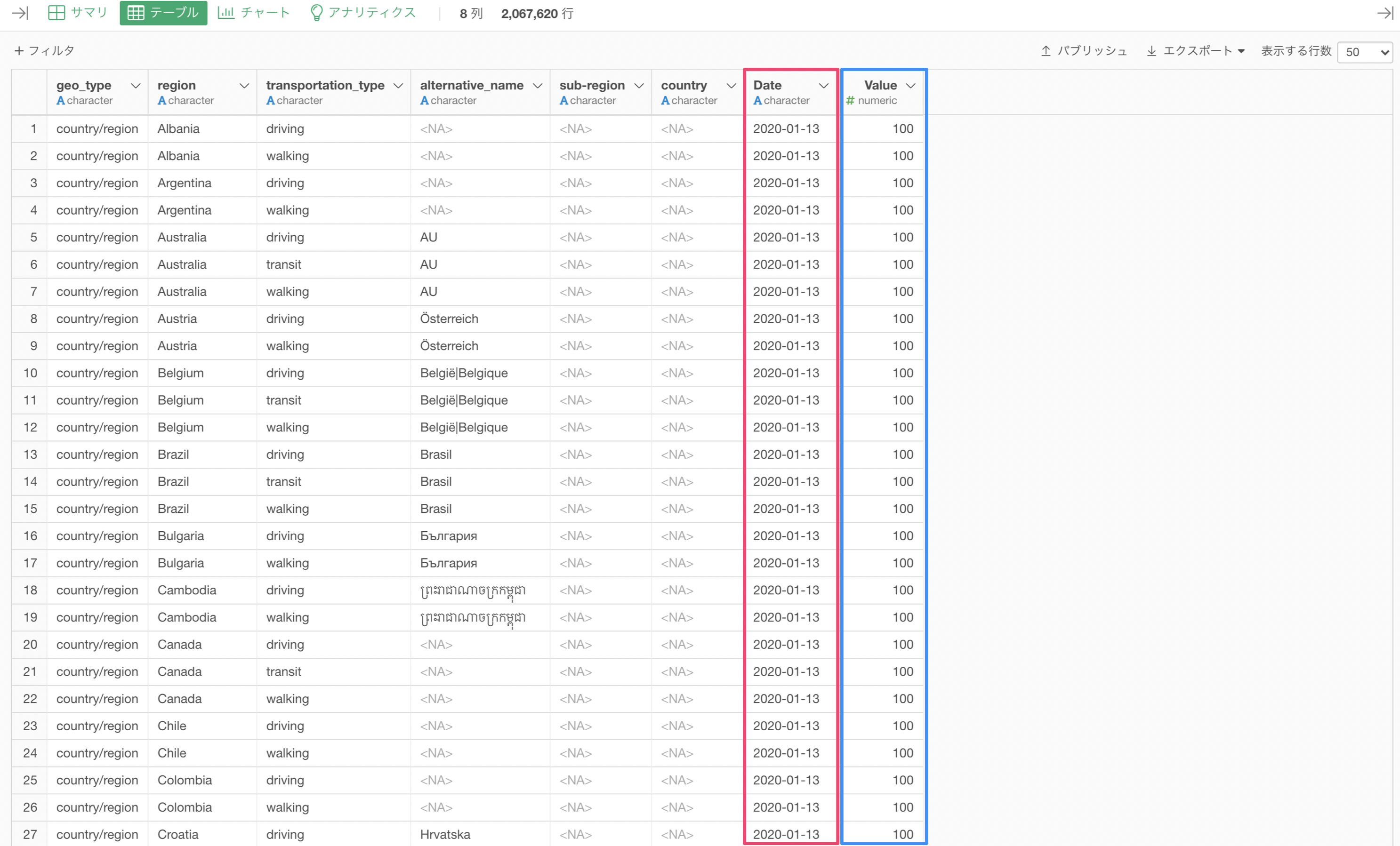
データはロング型のデータにできましたが、「データタイプ」にも注意を向ける必要があります。
Dateの列はcharacter型(文字列型)になっており、チャートで可視化する際にはDate型(日付型)にした方が可視化しやすくなります。(これはExploratoryが裏で使用しているRでも同じです。)
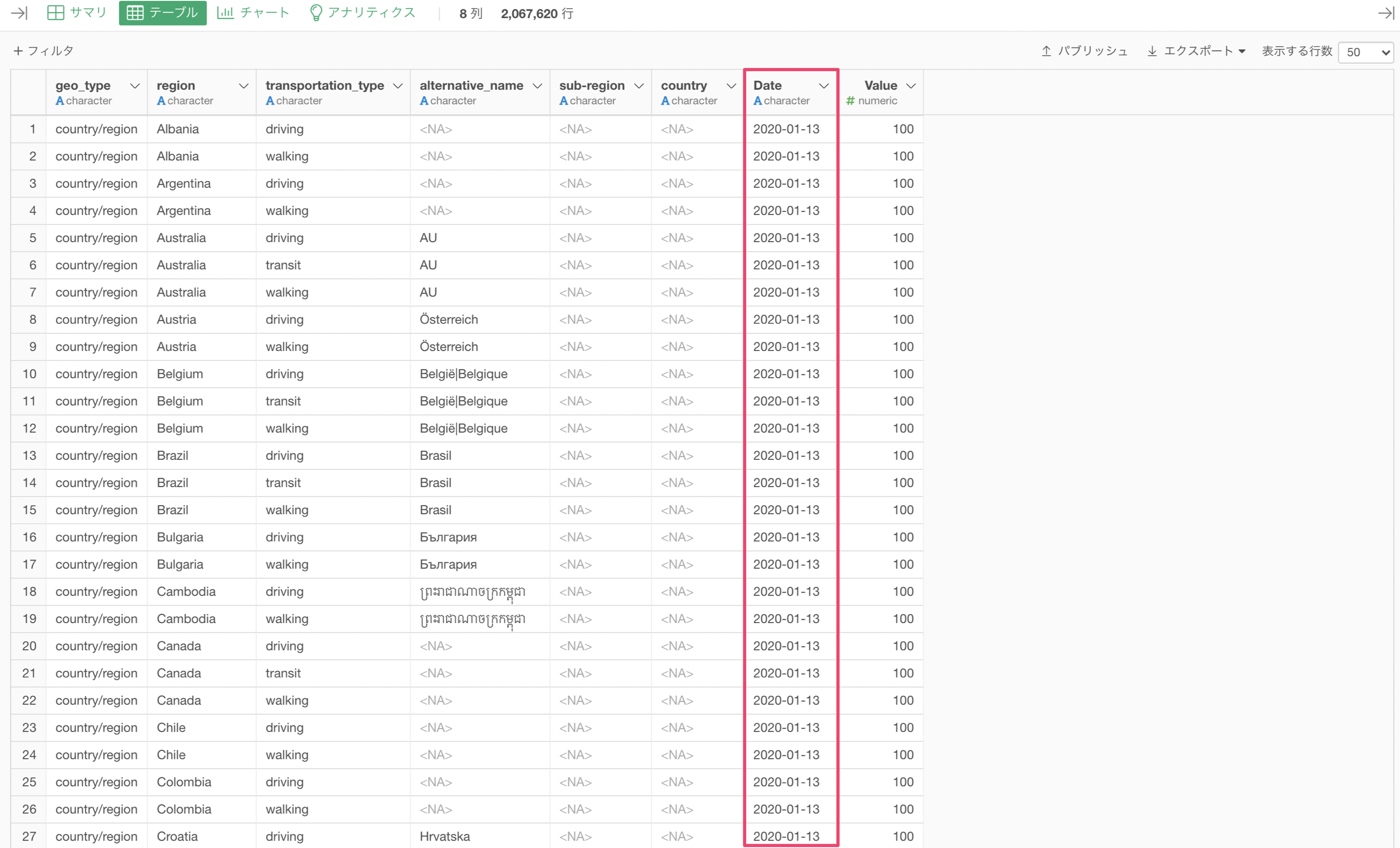
データタイプの変換は列ヘッダメニューから簡単に実行できます。
データタイプをcharacter型からDate型に変換できました。

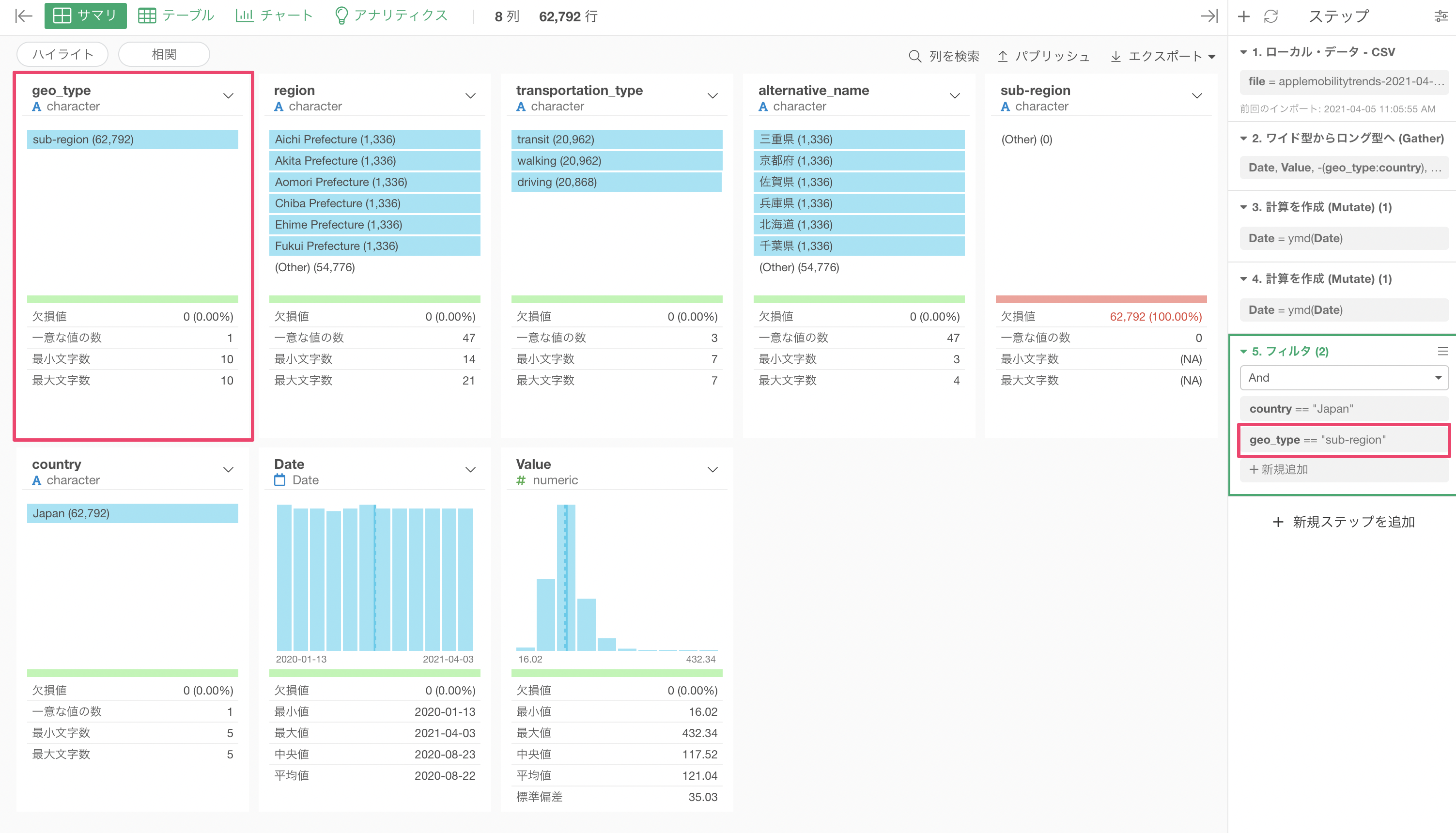
最後に、今回は日本のデータを可視化したいために「フィルタ」機能を使って日本のデータに絞り込んでいきます。
Exploratoryでは列ヘッダメニューから簡単にフィルタを呼び出すことができ、データタイプに合わせた多様な演算子が選べます。ここでは、countryの列からフィルタの等しいを選択します。
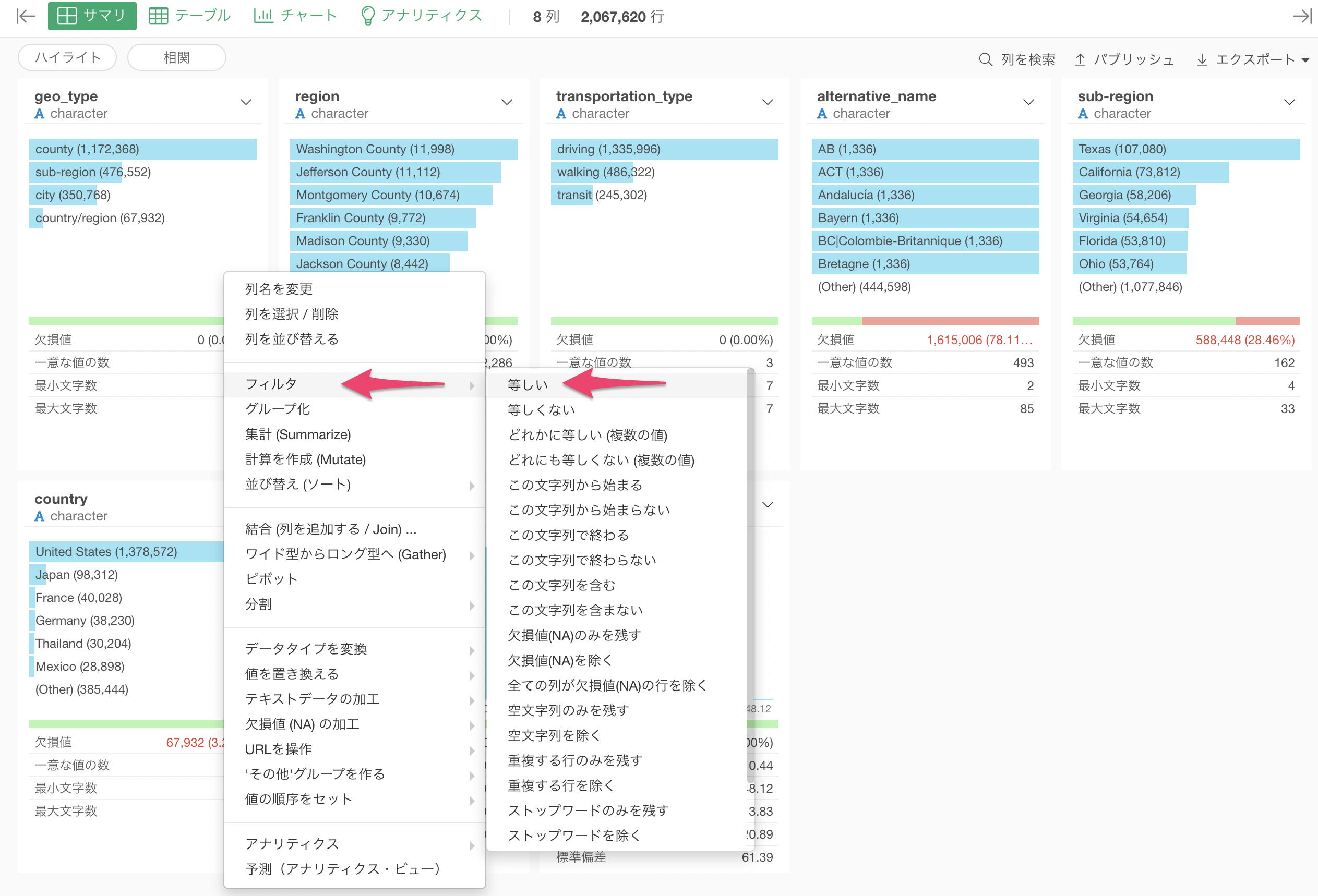
あとは値に"Japan"を選択して実行するだけです。
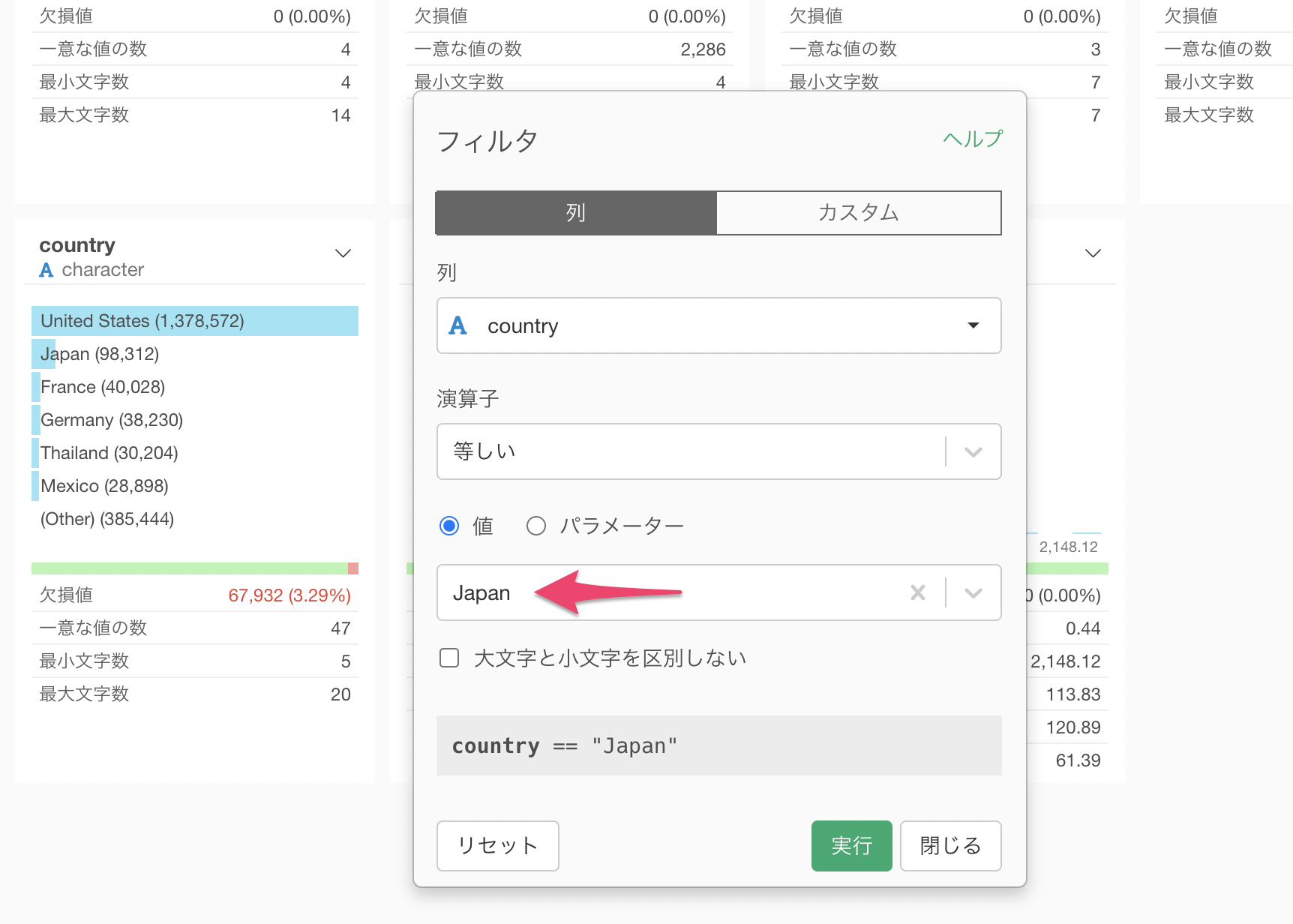
国を日本のデータだけにフィルタできました。
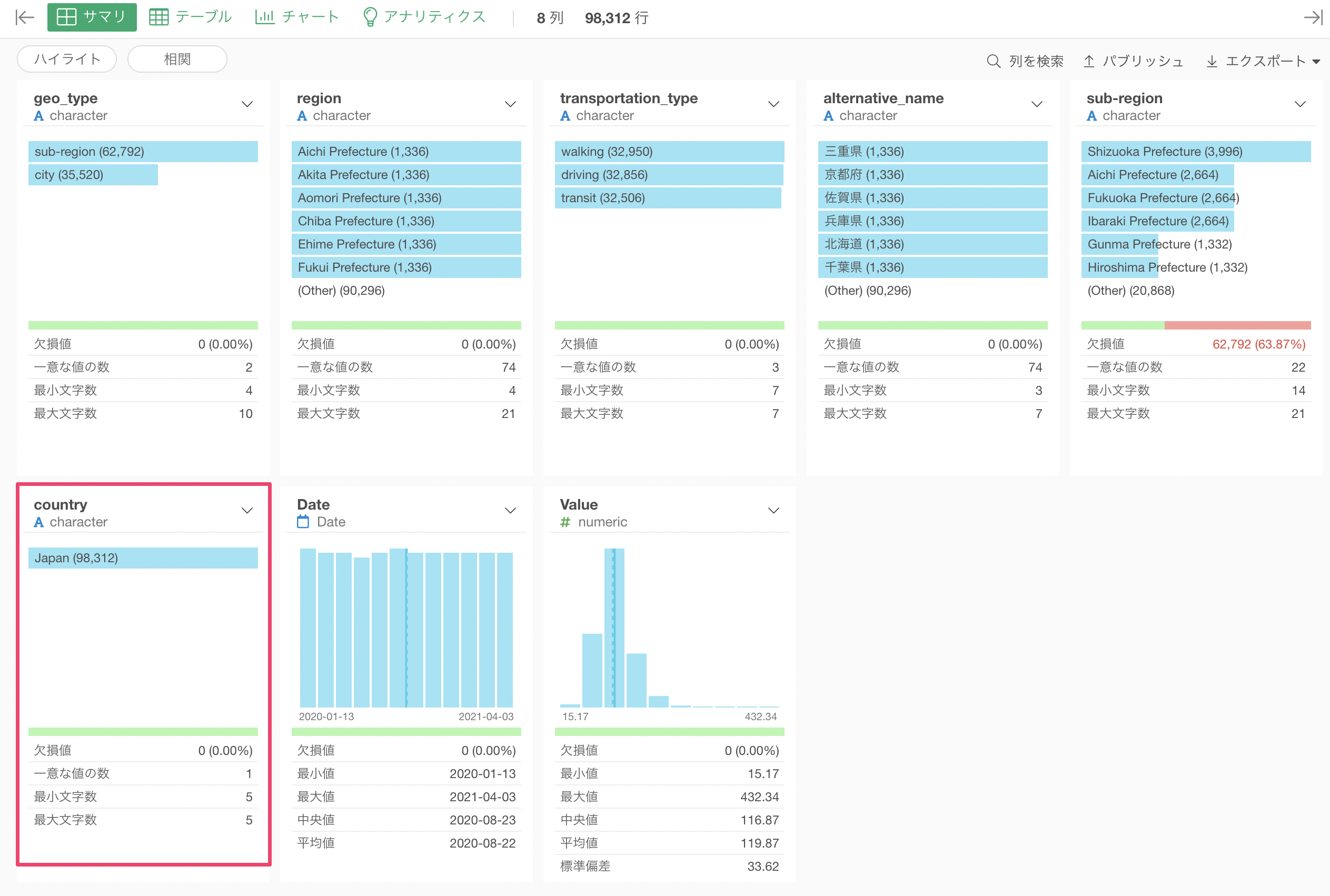
このデータでは市区町村レベルのデータと都道府県レベルのデータが入り混じっているので、先程と同じくフィルタで絞り込む必要があります。
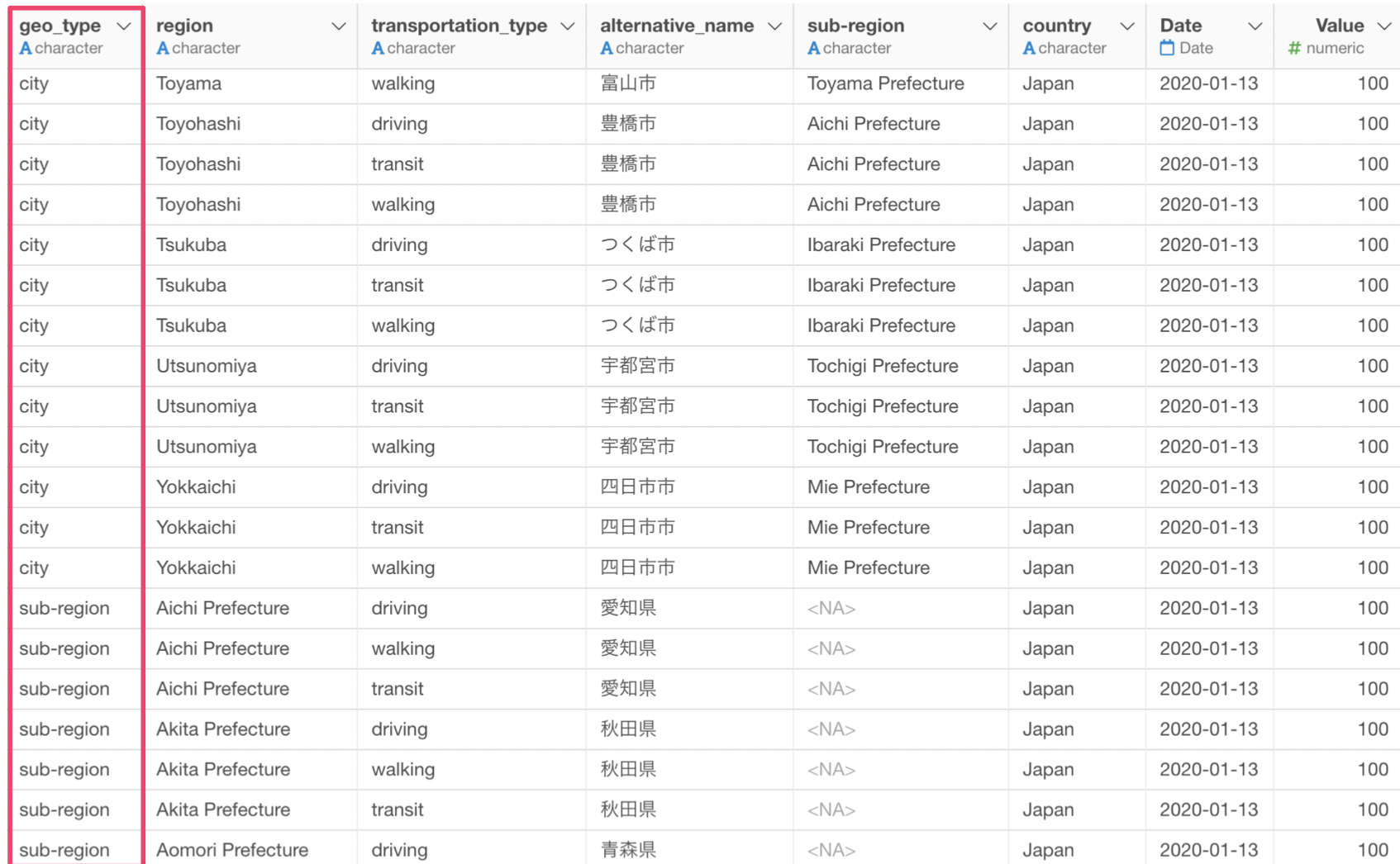
geo_type列の"sub-region"にフィルタすることで、都道府県レベルのデータにフィルタできます。
データ・ラングリングは以上です!
こうしてデータの準備さえできてしまえば、あとは簡単にデータを可視化して人の移動傾向を理解していくことができます。
最も自粛している都道府県はどこか?
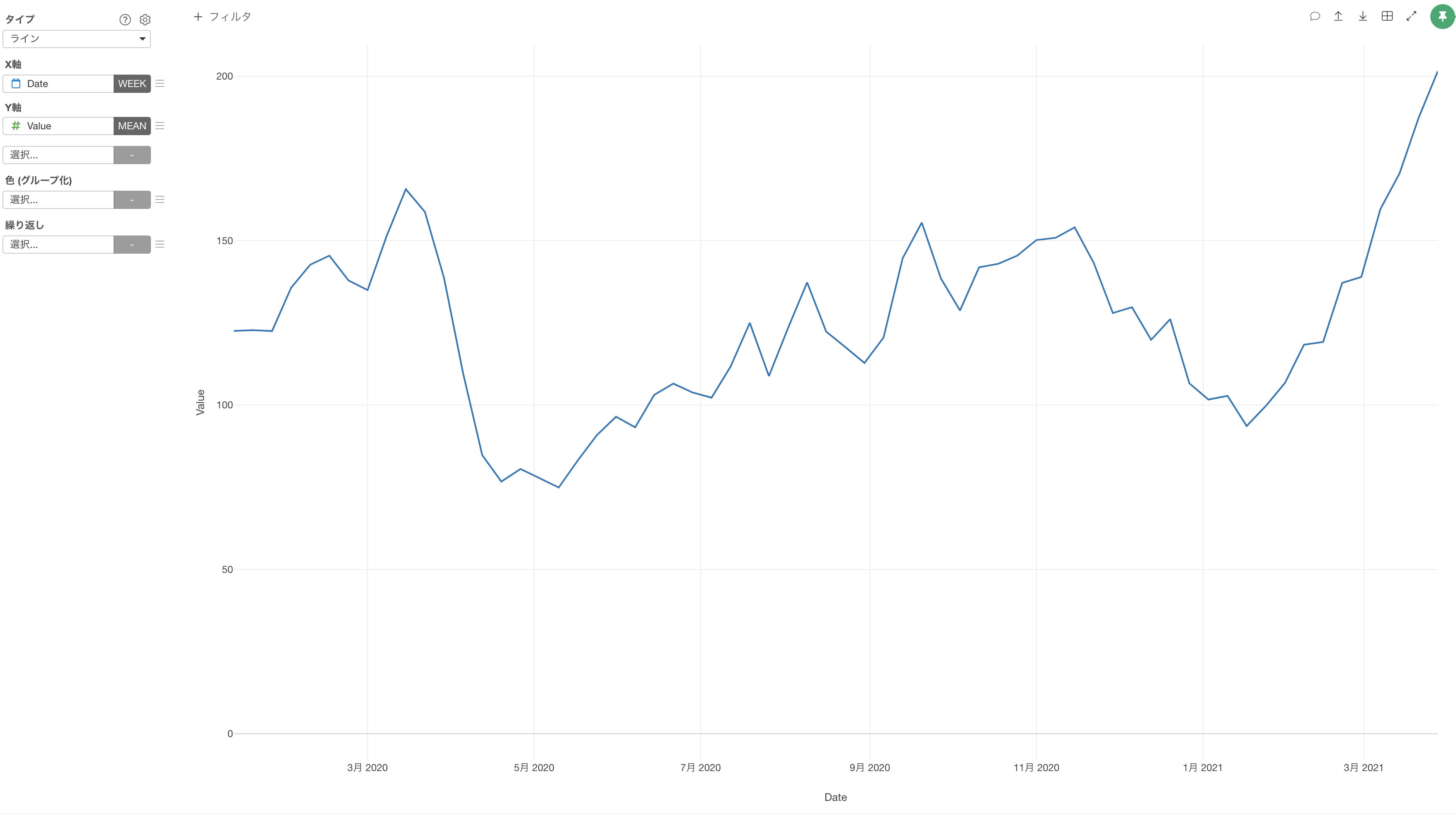
ラインチャートでX軸にDateを、Y軸にValue(移動傾向の値)を割り当てます。
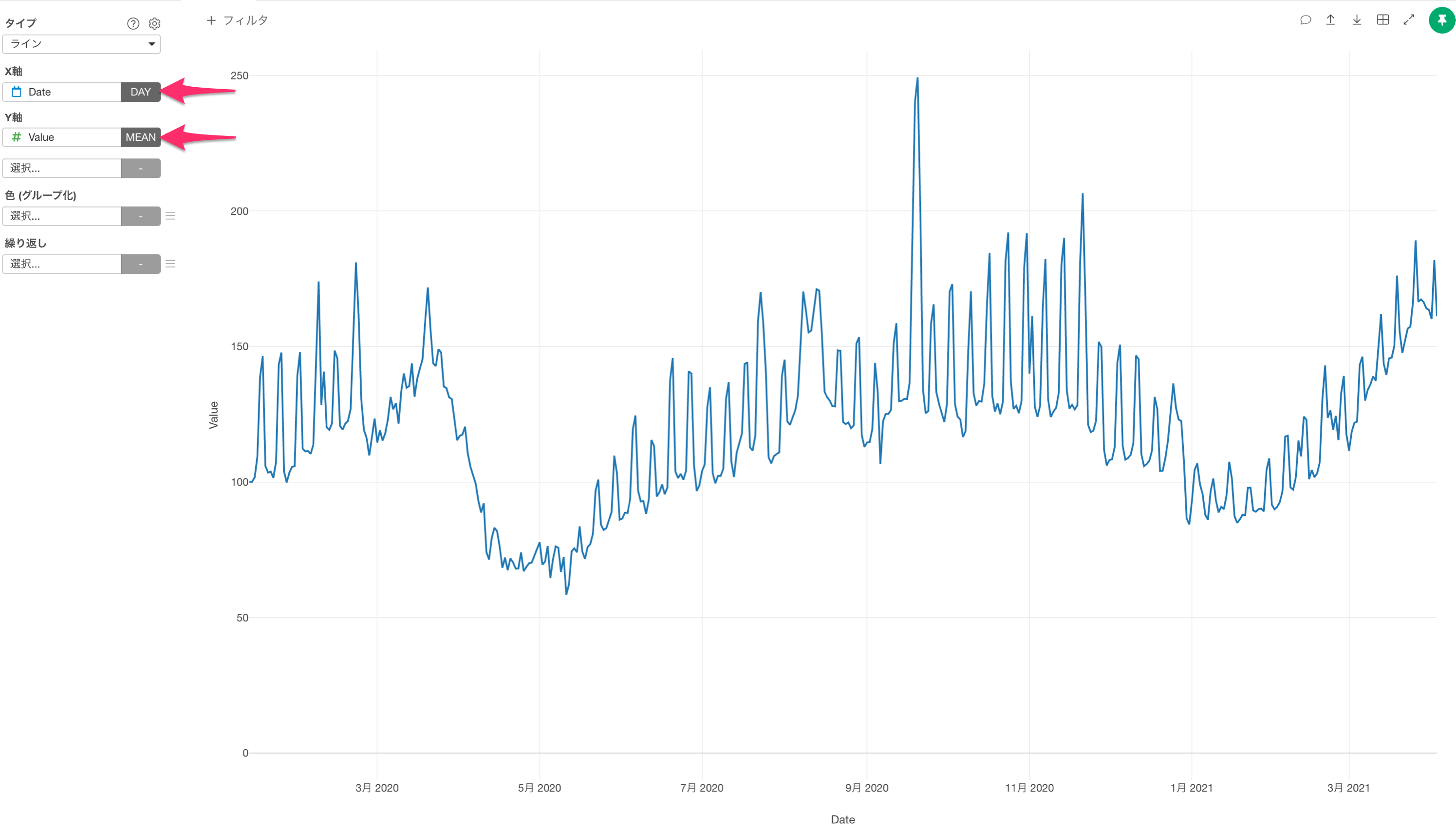
しかし、日毎に移動傾向の値は上下するため、大まかなトレンドがわかりづらくなっています。
そのため、一定区間ごとの平均値を区間をずらしながら求める「移動平均」を使用します。
ExploratoryではY軸のメニューにあるクイック表計算から簡単に移動平均を実行できます。
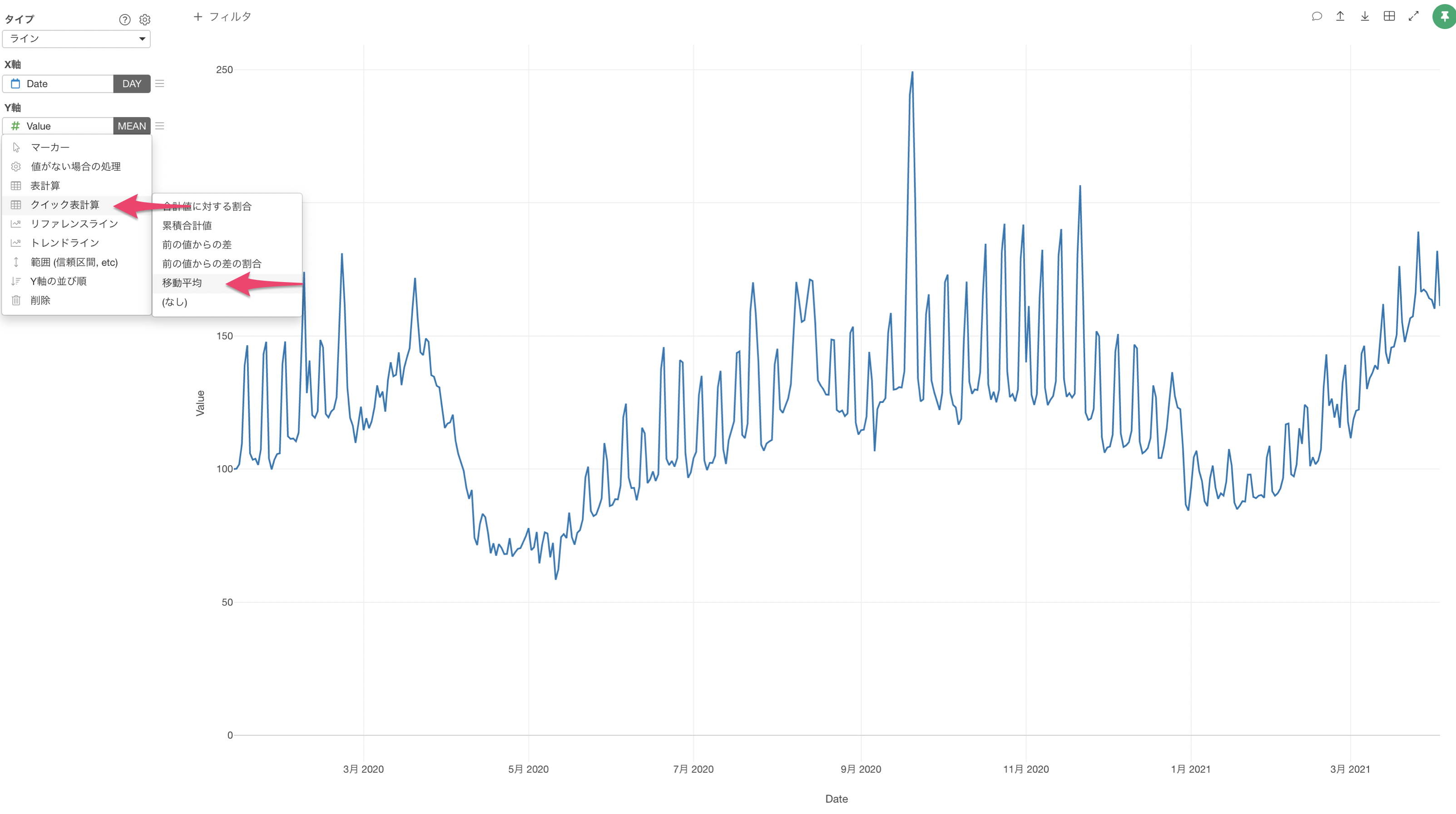
今回は、ウィンドウサイズを7にして実行します。
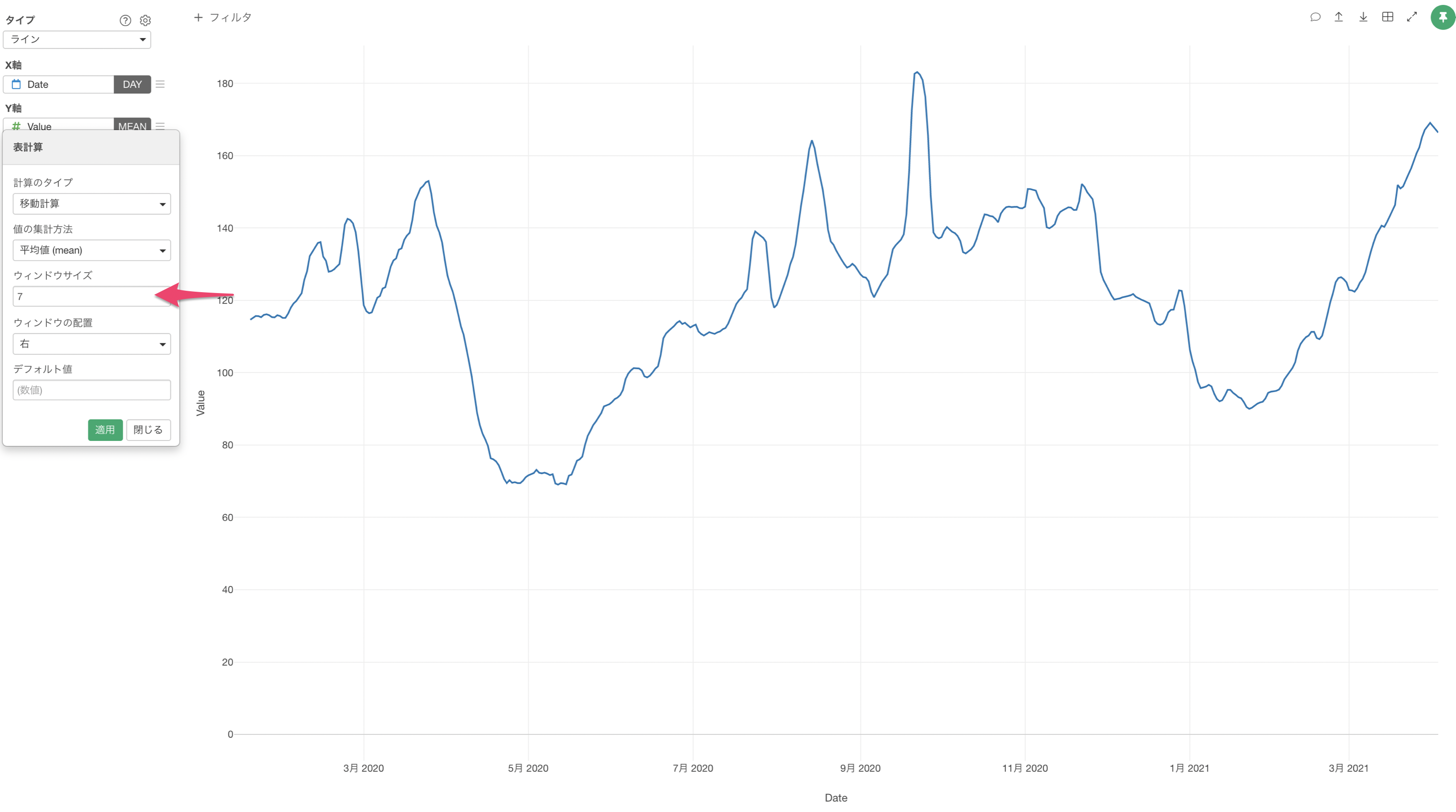
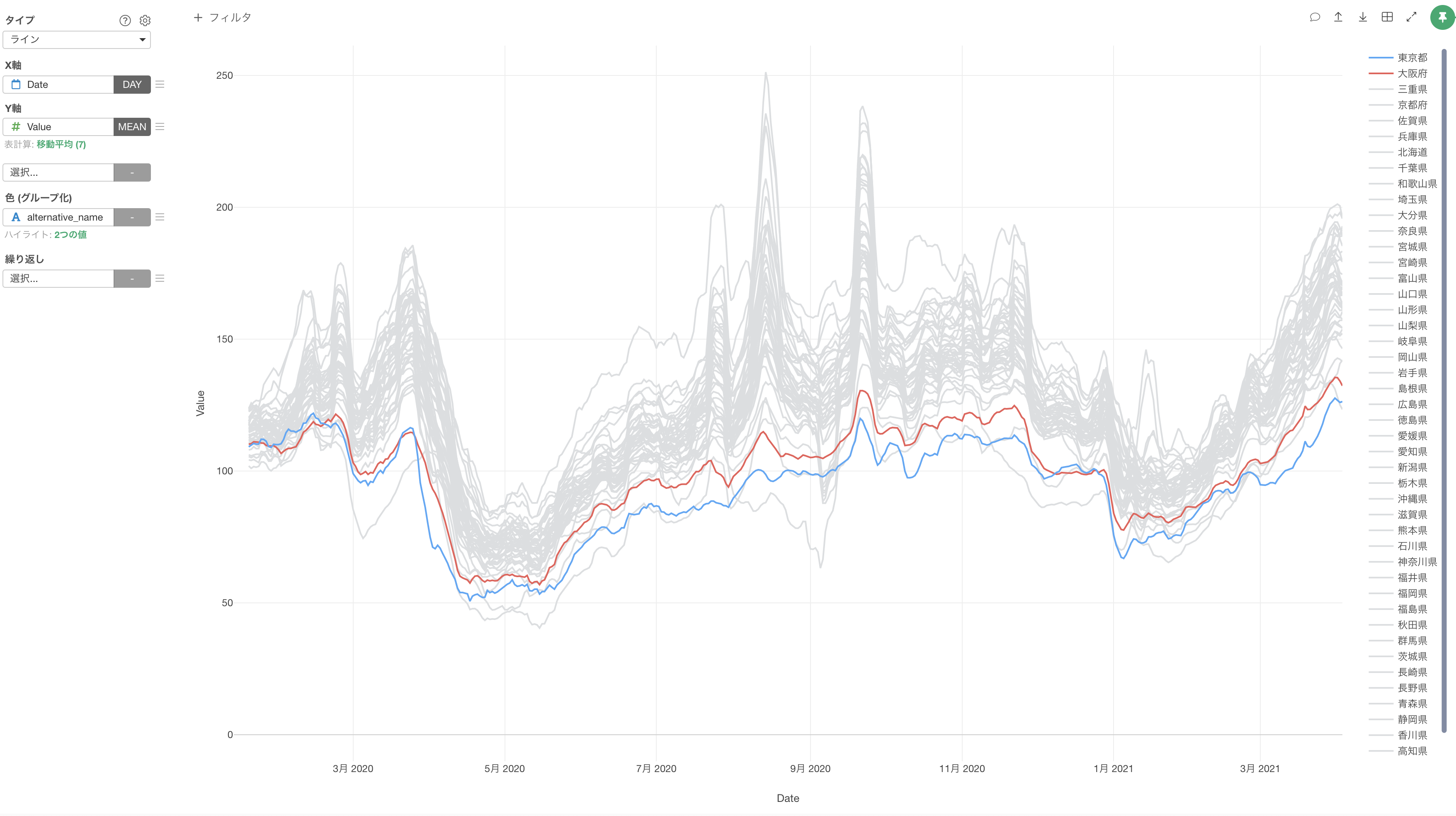
これにより、移動傾向の大まかなトレンドを可視化できました。
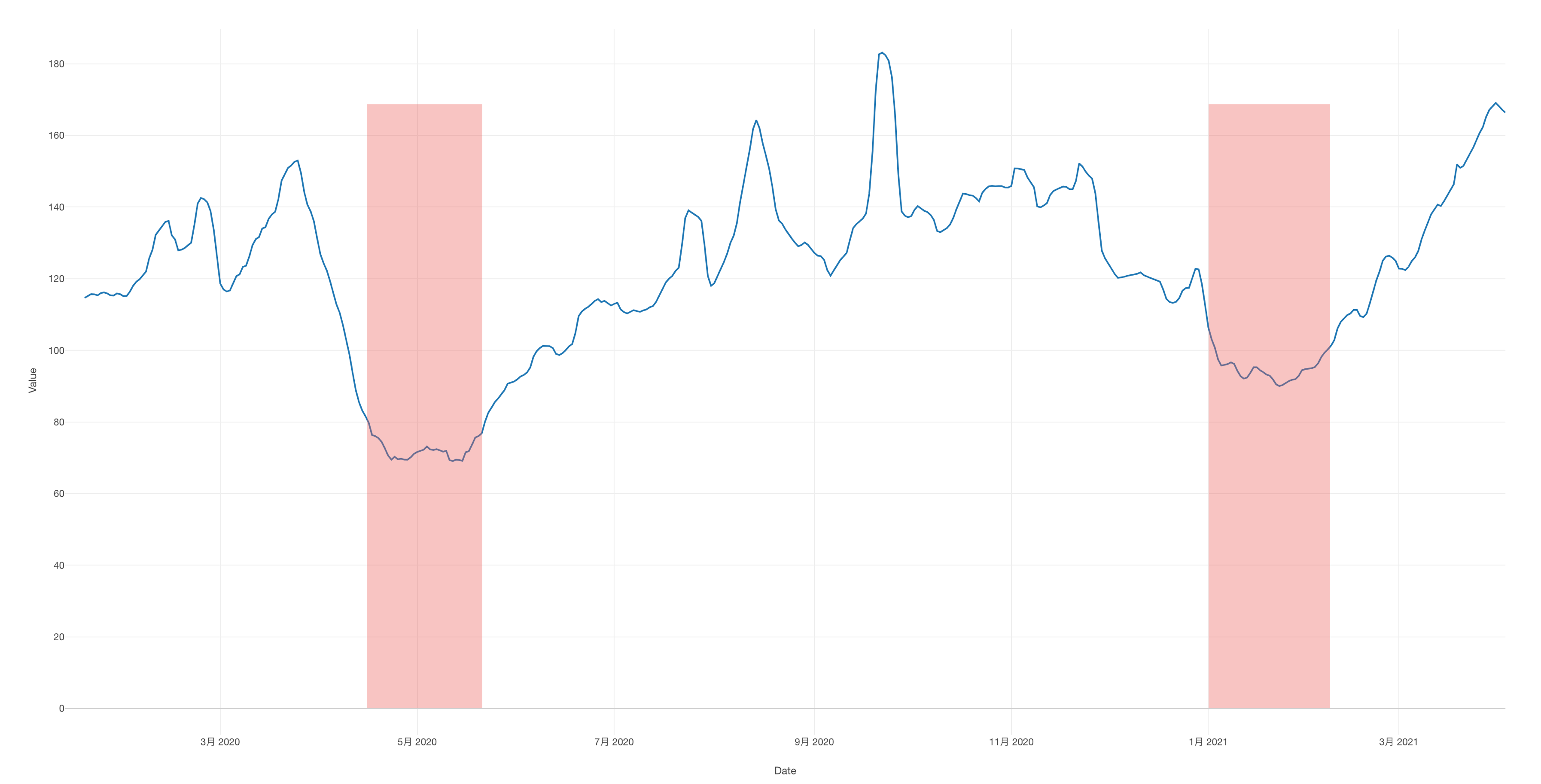
1回目と2回目の緊急事態宣言が行われた期間は移動が減少しており、自粛している人が多かったことがわかります。
次に、都道府県別で可視化するために色(グループ化)にalternative_name(都道府県)を割り当てます。

今回は、東京都と大阪に注目したいため色のメニューからハイライトを選択します。
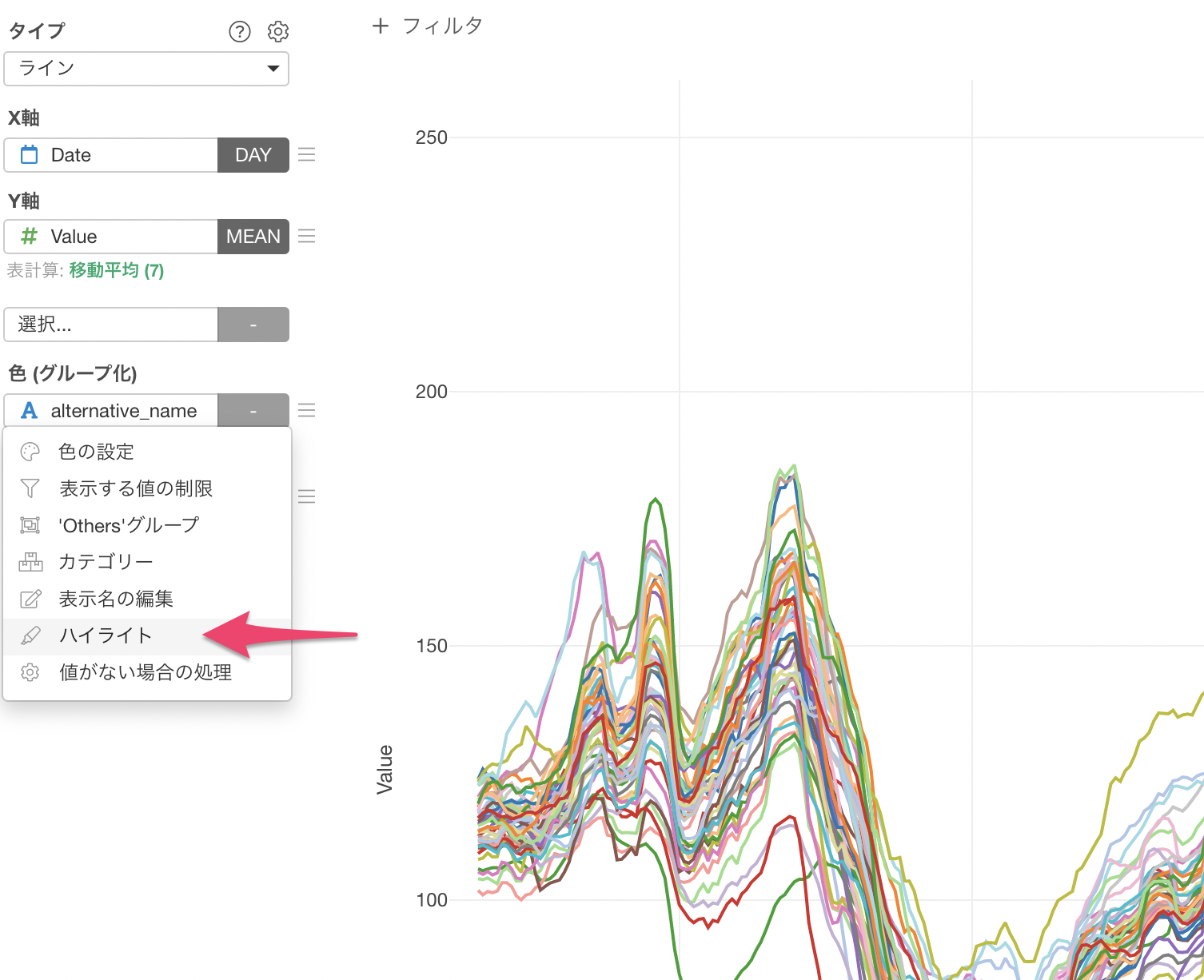
ハイライトする色に東京都と大阪を選択して適用します。
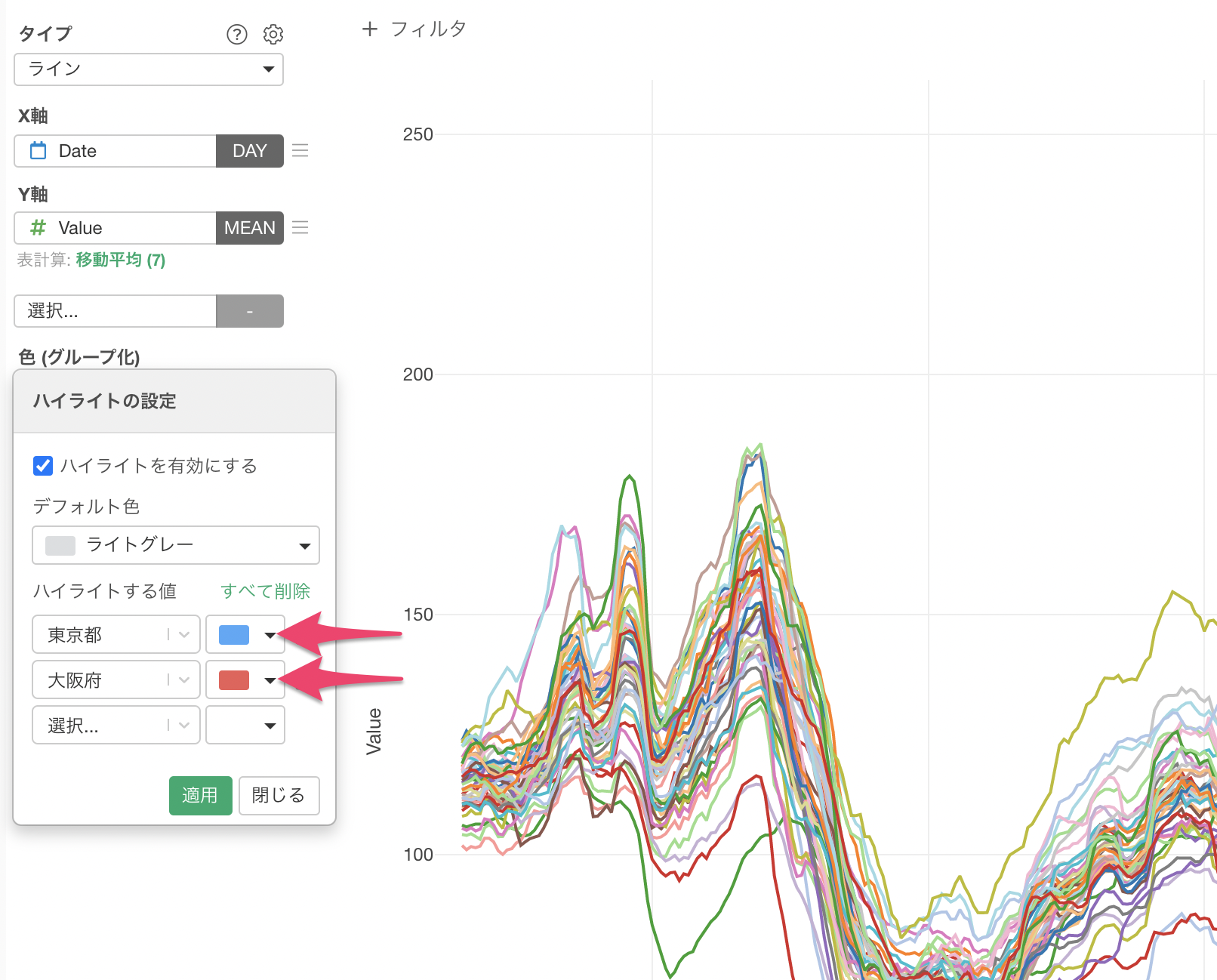
このチャートを見ると、東京は移動傾向の値がほぼ全ての期間で他の都道府県よりも低く、2021年3月以降は最も自粛していることがわかります。報道では東京の人出が増えていると言われていますが、他の都道府県に比べて実は自粛している人が多くいます。大阪も東京と同じく、移動する人は減少しているようです。
まとめ
今回は、Appleの移動傾向データを使って、「日本で最も自粛している都道府県はどこか?」といった質問に答えるためのデータラングリングの方法について紹介しました。
ここ10年近くのテクノロジーの進化によって様々な場所からデータを収集、取得することが格段に簡単になりました。
しかし、こうした時代の一番の問題はそういったデータを取得することではなく、データの加工・整形ができないがためにデータを活かしきれないということです。
Appleですら扱いづらいデータを公開していることからもわかるように、世界には沢山の「扱いづらいデータ」で溢れかえっています。
そのままでは、思うように可視化や分析ができずに、せっかくあるデータも宝の持ち腐れになってしまいます。
そこで必要になってくるのが、データを加工・整形して可視化や分析に沿った形に変えていくデータ・ラングリングです。
一度使えるように形を整えてあげれば、後は可視化するだけでも多くのことがデータからわかるようになります。
これが「データの分析の80%の時間はデータの加工に費やされる」と言われる所以ですね。
それでは、また近いうちに他にもまだたくさんあるコロナ関連のデータの加工の仕方を共有させていただきたく思います。
お楽しみに!
追記
このデータは「汚くない」とのコメントがあったので、補足をさせていただきます。
確かに、Appleの移動傾向データはよくあるExcelファイルのようにごちゃごちゃしたデータではないので汚くないと思われるかもしれません。
ただ、データの持ち方は、ハドリー・ウィッカム氏が提唱したTidyデータ(整然データ)にして扱いやすい形式にする必要があります。
整然データのルールは以下となります。
- それぞれの変数はそれぞれの列を持っているべき。
- それぞれの観測はそれぞれの行を持っているべき。
- それぞれの値はそれぞれのセルを持っているべき。
Appleのデータはこの整然データには該当しない、雑然データと言われるものになります。
理由としては、
日付と移動傾向の値はそれぞれ変数となりますが、このデータでは日付が列となり1番目のルールに合致しません。
このデータの本来の観測はそれぞれの地域ごとの1日の移動傾向の値になりますが、1行は1地域になっています。そのため、2番目のルールに合致しません。
このことより、行きすぎた言葉かもしれませんが汚いと使用していました。
もし気分を害された方は大変申し訳ございません。(タイトルなどは修正しております。)
データを可視化する時には、データの見た目上は綺麗だとしても整然データになっていなければ
結局は加工しないと使えないデータになってしまいます。
そこで、Rではtidyrのpivot_longerやgatherコマンドが必要になります。
Excelでも同じように、整然データにできるかもしれませんが、全ての人が同じように加工できる訳ではないと思っています。
そこで、少しでもデータの持ち方や加工方法についてご紹介した次第です。
ご参考になれば幸いです。
データラングリング・トレーニング、5月開催決定!

データラングリング(データの加工)の手法を1から体系的に、そして効果的に身に着けていただくために、データラングリング・トレーニングを提供しています。
データを自由自在に操れることで、実は思った以上に役に立つデータが身の回りにあるということに気づかれるはずです。そして思った以上にデータを使って答えることのできる質問がこの世の中には多くあるということにも気づいていただけると思っております。
詳細はこちらのページにあります。








コメント @norihitoishida
@norihitoishida21  @norihitoishida
@norihitoishida
0
データ分析者です。Appleのデータが汚いとはまったく思いません。
「データサイエンスの民主化」を謳いつつ、一般的なデータを「汚い」と称しExploratoryのデータ整形機能を喧伝するのはマッチポンプの感があり、不誠実ではないでしょうか。
Wickhamのtidy data(第3正規形)は扱いやすいですが、必須ではありません。
Wickham自身も
Other formulations of tidy data are possibleと述べています。詳細は元論文をお読みください。
さて、言葉の定義云々よりもより重大な問題は、以下の様な結論が導かれている事の様に思います。
今回扱っているデータは都道府県ごとの経路検索の2020/01/13に対する相対量であって、人口や都市のハブ性などの情報が加味されていません。

都道府県あたりの人口について、最多(東京)と最少(鳥取)それぞれの相対量の推移を図示すると以下のようになります。(明らかに鳥取の方が増加しています)
他の都道府県も比較してみると、人口と相対量には負の相関がありそうということが分かります。
よって、人口に関する補正なしのグラフを見て導かれた「東京が最も自粛している」という推察はあまり意味が無いのではないでしょうか。
また、そもそも「日本で最も自粛している都道府県はどこか?」という質問の答えが(仮に)判ったところで何が嬉しいのかよくわかりません。自粛していない人に「あなたが住んでいる県は最も自粛が少ないです。」と言った所で「じゃあ自粛しよう!」とはならないからです。
このデータを可視化して何か情報を推察し意思決定をするのならば、たとえば「2020/04/07~05/25の第1回緊急事態宣言は人の移動抑止に効果があったが、2021/01/07~03/18の第2回緊急事態宣言中は移動量は慢性的に増加しつづけている。よって、人の移動を防止する為には緊急事態宣言以外の手段が必要と考えられる。」とか「第1回緊急事態宣言前の東京の相対量は歩行者>車両だったのが、宣言後は車両の相対量の方が速く回復している。この情報を元に商品の仕入れを決定する。」等でしょうか。(他に分かることがあれば是非コメントください)

記事中のグラフについても、塗りつぶしの「1回目と2回目の緊急事態宣言が行われた期間」が正確ではありません。(悪意はないと思いますが、恣意的に一部分のみが切り取られているようにも見えてしまいます)
データサイエンスを民主化するというExploratoryのテーマに賛同しますし、GUIツールの普及に伴ってデータ分析者が増えることでこれまで活用されていなかったデータが有効活用されるのは素晴らしい事だと思いますが、ツールの使い方が不適切だったりデータの考察が不十分だったりして導かれる結論が間違ってしまうと本末転倒になってしまいます。
文句ばかり言うのもアレなので可視化に使ったPythonコードに解説を入れて掲載しておきます。
汚くて恐縮ですが「ここはこういうPEPに則ってないよ」とか「ここはこう書いたほうが効率的だよ」とかお気づきの方がいらっしゃればコメントいただけると幸いです。
import warnings import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns sns.set() warnings.simplefilter("ignore") # 前処理 df = pd.read_csv("./applemobilitytrends-2021-04-06.csv") # データ読み込み df = df[lambda x:x["country"]=="Japan"][lambda x:x["geo_type"]=="sub-region"].reset_index(drop=True) # 不要なデータ(海外等)を削除 df["region"] = df["region"].apply(lambda x:str(x).split(" ")[0]) # "Prefecture"を削除 df = df[lambda x:x["region"].isin(["Tokyo", "Osaka", "Aichi"])] # 東京/大阪/愛知を抽出 df.index = df["region"]+"-"+df["transportation_type"] # インデックス名を「都道府県+移動手段に」設定 df = df.iloc[:, 6:] # geo_type, regionなどの不要な情報をカット df = df.T # 転置 df = df.fillna(method="ffill") # 欠損値は前日の値で埋める # 経路検索の相対量の可視化(7日間の移動平均を取る) kargs = {"figsize":(16, 10),"fontsize":10,"title":"Tokyo vs Osaka vs Aichi","xlabel":"Date","ylabel":"Mobility Ratio (Today vs 2020-01-13)"} df.rolling(7).mean().plot(**kargs) # 非常事態宣言期間を塗りつぶす s1 = df.index.get_loc("2020-04-07") e1 = df.index.get_loc("2020-05-25") s2 = df.index.get_loc("2021-01-07") e2 = df.index.get_loc("2021-03-18") plt.axvspan(s1, e1, alpha=0.5) plt.axvspan(s2, e2, alpha=0.5) plt.legend(loc="upper left") # 凡例 plt.show() # 出力