last update : 2021/2/24
- last update : 2021/2/24
- 3-6.📘特徴量設計
- 3-7.📘チューリングテスト
- 3-8.📘シンギュラリティ(技術的特異点)
- 4.📘機械学習の具体的手法
- 4-1.📘代表的な手法
- 4-2.📘データの扱い
- 4-3.📘応用・評価指標
- 5.📘ディープラーニングの概要
- 5-1.📘ニューラルネットワークとディープラーニング
- 5-2.📘既存のニューラルネットワークにおける問題
- 5-3.📘ディープラーニングのアプローチ
- 5-4.📘CPU と GPU
- 5-5.📘ディープラーニングにおけるデータ量
- ディープラーニング その他
- 6.📘ディープラーニングの手法
- 6-1.📘活性化関数
- 6-2.📘学習率の最適化
- 6-3.📘更なるテクニック
- 6-4.📘CNN(畳み込みニューラルネットワーク)
- 6-5.📘RNN(リカレント ニューラルネットワーク)
- その他の応用
- 6-6.📘深層強化学習
- 6-7.📘深層生成モデル
- 7.📘ディープラーニングの研究分野
- 7-1.📘画像認識
- 7-2.📘自然言語処理
- 7-3.📘音声処理
- 7-4.📘ロボティクス (強化学習)
- 7-5.📘マルチモーダル
- 8.📘ディープラーニングの応用に向けて
- 8-1.📘産業への応用
- 8-2.📘法律
- 8-3.📘倫理
- 8-4.📘現行の議論
- その他
はじめに
- 一般社団法人 日本ディープラーニング協会 G検定
- ディープラーニングG検定に向けた情報整理を行う。
- 構成はシラバスに従い、該当項目には「📘」を付す。
- 参考図書
ディープラーニング G検定(ジェネラリスト) 公式テキスト - 【参考】模擬テスト
Study-AI G検定 模擬テスト - 注意事項!
- 自分自身の知識の確認と整理を目的に作成したものを掲載しています。
- この記事だけで十分な知識をつけることはできません。
- 公式テキスト等を活用し、必ず自らで学習を行うようにしてください。
- そのうえで、テスト前のキーワード確認等にご活用ください。
1.📘人工知能(AI)とは(人工知能の定義)
AIの定義
- 専門家の間で共有されている定義はない。
- 人工知能であるかどうかは「人によって違う」。
- 定義の例
- 「推論、認識、判断など、人間と同じ知的な処理能力を持つ機械(情報処理システム)」
- 「周囲の状況(入力)によって行動(出力)を変えるエージェント(プログラム)」
- 🎩松尾豊
「人工的につくられた人間のような知能、ないしはそれをつくる技術」 - 🎩アーサー・サミュエル
「明示的にプログラムしなくても学習する能力をコンピュータに与える研究分野」
人工知能レベル
| レベル | 説明 |
|---|---|
| レベル1 | シンプルな制御プログラム。 ルールベース。 |
| レベル2 | 古典的な人工知能。 探索・推論を行う。知識データを利用する。 |
| レベル3 | 機械学習を取り入れた人工知能。 多くのデータから入力・出力関係を学習する。 |
| レベル4 | ディープラーニングを取り入れた人工知能。 特徴量による学習を行う。 |
AI効果
- 人工知能の原理がわかると「単純な自動化である」とみなしてしまう人間の心理のこと。
ロボットとの違い
- 人工知能では「考える」という、目に見えないものを中心に扱っている。
- 人工知能ではロボットの「脳の部分」を扱っている。(脳だけ、というわけではない)
- ロボットの研究者は人工知能の研究者というわけではない。
歴史
✅ 💻ENIAC

✅ ダートマス会議
- 1956年、アメリカで開催。
- 🎩ジョン・マッカーシーが初めて「人工知能(AI)」という言葉を使った。
- 世界初の人工知能プログラムといわれる💻ロジック・セオリストのデモを実施した。

✅ 第1次AIブーム
- 推論・探索が中心。
- トイ・プロブレム(おもちゃの問題)は解けても、現実の問題は解けないことが判明。
⇒ 失望へ
✅ 第2次AIブーム
- 💻エキスパートシステムが流行し、ナレッジエンジニアが必要とされた。
- 日本
💻第五世代コンピュータという大型プロジェクトを推進、エキスパートシステム等に取り組んだ。 - 知識の蓄積・管理は大変!ということに気づく。
第五世代コンピュータとは、通商産業省(現経済産業省)が1982年に立ち上げた国家プロジェクトの開発目標である。(引用)
⇒ 失望へ
✅ 第3次AIブーム
2.📘人工知能をめぐる動向
2-1.📘探索・推論
探索・推論の手法
✅ 探索木


✅ ハノイの塔
- Wikipedia
- 以下のルールに従ってすべての円盤を右端の杭に移動させられれば完成。
- 3本の杭と、中央に穴の開いた大きさの異なる複数の円盤から構成される。
- 最初はすべての円盤が左端の杭に小さいものが上になるように順に積み重ねられている。
- 円盤を一回に一枚ずつどれかの杭に移動させることができるが、小さな円盤の上に大きな円盤を乗せることはできない。

✅ ロボットの行動計画
- プランニング(Wikipedia-自動計画)
- オフラインプランニング・静的プランニング
周囲の状況が既知で、その構造がよく理解されている場合に、行動の計画や戦略をあらかじめ組み立てて(計算して)おくこと。 - オンラインプランニング・動的プランニング
未知の環境において、周囲の状況が明らかになるにつれて行動の計画や戦略を修正すること。 - リプランニング
計画・戦略を修正すること。
- オフラインプランニング・静的プランニング
- STRIPS
- SHRDLU
- 1970年、スタンフォード大学、🎩テリー・ウィノグラード。
- 英語の指示により画面上の積み木を動かす。
- 成果はCycプロジェクトに引き継がれている。
- 【Youtube】SHRDLU in Action

✅ ボードゲーム
- 1996年、💻**IBM DeepBlue(ディープブルー)。「力任せの探索」だったが、チェスの世界チャンピオンを破った。
力まかせ探索(Brute-force search)またはしらみつぶし探索(Exhaustive search)は、単純だが非常に汎用的な計算機科学の問題解決法であり、全ての可能性のある解の候補を体系的に数えあげ、それぞれの解候補が問題の解となるかをチェックする方法である。(引用)
- 2012年、💻ボンクラーズ が将棋において永世棋聖に勝利。
- 2013年、💻ponanza が将棋において現役プロ棋士に勝利。
- 2016年、💻AlphaGo(アルファ碁)が韓国のプロ棋士に勝利。
- ディープラーニングが使われた。

- ディープラーニングが使われた。
- 2017年、💻elmo が世界コンピュータ将棋選手権において ponanza に勝利。elmo 同士の対戦を行うことで学習を行った。
✅ コスト
✅ Mini-Max法
- Wikipedia
- ゲーム戦略で利用される。
- 想定される「最大の損害」が最小になるように決断を行う戦略のこと。
- 自分の番はスコア最大、相手の番はスコア最小になるような戦略をとる。
- この手法は全探索を行うため効率が悪い。
✅ α-β法
✅ モンテカルロ法
- 特徴:
プレイアウト(ゲームを一度終局までもっていく)の結果、どの方法が一番勝率が高いかを評価する。 - デメリット:
ブルートフォース(力任せな方法)のため、組合せが多いと計算しきれない。
2-2.📘知識表現
知識表現
✅ 💻ELIZA(イライザ)
- 1966年、🎩ジョセフ・ワイゼンバウム。
- 「人工無能」の元祖。精神科セラピストを演じた。
- パターンに合致したら返答する「ルールベース」である。
- イライザ効果:あたかも本物の人間と話しているように錯覚すること。
- その後開発された💻PARRYと会話した記録が残されており(RFC439)、中でもICCC1972が有名。

✅ エキスパートシステム
✓ 💻DENDRAL
✓ 💻マイシン(MYCIN)
- 1970年、スタンフォード大学。
- ルールベースで血液中のバクテリアの診断支援を行った。
- 正解確率の高い細菌名のリスト、信頼度、推論理由、推奨される薬物療法コースを示した。
- 精度は専門医の80%に対し、69%であった。
✅ 意味ネットワーク
- semantic network
- 人間の記憶の一種である意味記憶の構造を表すためのモデル。
- 単語同士の意味関係をネットワークによって表現する。
- 概念を表す節(ノード)と、概念の意味関係を表す辺(エッジ)からなる、有向グラフまたは無向グラフである。
無向グラフのエッジには方向性がありません。エッジは "双方向" の関係を示します。 有向グラフのエッジには方向性があります。エッジは "一方向" の関係を示します。(引用)

✅ Cycプロジェクト
- 1984年、🎩ダグラス・レナート。
- すべての一般知識を取り込もうという活動。
- 2001年からはOpenCycとして公開されている。
- https://www.cyc.com/
オントロジー(ontology)
- wikipedia
- 🎩トム・グルーバーが提唱。
- 知識を体系化する方法論で、「概念化の明示的な仕様」(知識を記述するための仕様)と定義されている。
- 知識の形式表現であり、あるドメインにおける概念間の関係のセットである。
- is-a 関係(上位概念、下位概念、推移律)、part-of 関係を用いる。
✅ セマンティックウェブ
- Wikipedia
- W3C の🎩ティム・バーナーズ=リーによって提唱されたプロジェクト。
- ウェブページの意味を扱うことができる「標準」や「ツール群」の開発により、ワールド・ワイド・ウェブの利便性を向上させようというもので、オントロジーを利用する。
- プロジェクトの目的は、ウェブページの閲覧という行為(データ交換)に対し、意味の疎通を付け加えることにある。
- 情報リソースに意味を付与することで、コンピュータで高度な意味処理を実現したり、文書の意味に即した処理が行えるようにする。
✅ ヘビーウェイトオントロジー(重量オントロジー)
- 人間が厳密にしっかりと考えて知識を記述していくアプローチ。
- 構成要素や意味的関係の正統性については、哲学的な考察が必要。
✅ ライトウェイトオントロジー(軽量オントロジー)
- コンピュータにデータを読み込ませ、自動で概念間の関係性を見つけるアプローチ。
- 完全に正でなくても使えればOKと考える。
- ウェブマイニング、データマイニングで利用される。
ウェブマイニング(web mining)とは、ウェブサイトの構造やウェブ上のデータを利用して行うデータマイニングのことである。(引用)
データマイニング(Data mining)とは、統計学、パターン認識、人工知能等のデータ解析の技法を大量のデータに網羅的に適用することで知識を取り出す技術のことである。(引用)
✅ 💻ワトソン

✅ 💻東ロボくん
- 2011年~2016年、国立情報学研究所。
- プロジェクトリーダーは🎩新井紀子。(著書『AI vs.教科書が読めない子どもたち』)
- 読解力に問題があり、何かしらのブレイクスルーが必要と判断され、開発は凍結された。
- その後、新井氏は人間側の読解力の問題に注目し、さまざまな活動を行っている。(TEDがわかりやすい)
2-3.📘機械学習
レコメンデーションシステム
- おすすめを提示するシステム。
✅ 協調ベースフィルタリング
- ユーザーの購買履歴からおすすめを表示するアプローチ。
- ユーザーの行動をもとにレコメンドする。
✅ 内容ベースフィルタリング
- アイテムの特徴をもとにおすすめを表示するアプローチ。
- 検索キーワードに関連する類似アイテムをレコメンドする。
- アイテムの特長ベクトルをもとにレコメンドである。
2-4.📘深層学習(ディープラーニング)
深層学習 関連手法
✅ 単純パーセプトロン
- シンプルなニューラルネットワーク。
- ステップ関数で表現できるがニューラルネットワークでは利用できない。

画像引用
✅ ディープラーニング
- ニューラルネットワークを多層にしたもの。
✅ バックプロパゲーション
- 誤差逆伝播学習法
- ニューラルネットワークの学習におけるアルゴリズム。
✅ 自己符号化器(オートエンコーダ)
- 入力したものと同じものを出力して学習する。
深層学習 実装例
✅ 💻SuperVision
- 2012年、トロント大学、🎩ジェフリー・ヒントン。
- ILSVRC(Imagenet Large Scale Visual Recognition Challenge)2012 で勝利した。
- エラー率は26%台から15.3%へ劇的に改善。
- その後、2015年に人間の認識率(約5.1%)を抜いた。
- AlexNet(畳み込みニューラルネットワーク、CNN)を採用。
- 前年度まではサポートベクターマシンが主流だったが、ここからCNNに切り替わったことになる。
3.📘人工知能分野の問題
3-1.📘トイプロブレム(おもちゃの問題)
- ルールが決まっている問題(迷路、オセロなど)は解けても、現実世界に存在する複雑な問題は解けないという問題。
3-2.📘フレーム問題
- Wikipedia
- 1969年、🎩ジョン・マッカーシーと🎩パトリック・ヘイズが提唱。
- 人工知能における重要な難問の一つ。
- 有限の情報処理能力しかないロボットには、現実に起こりうる問題全てに対処することができない。
- 🎩ダニエル・デネット:
考えすぎて何も解決できないロボットを例示し、フレーム問題の難しさを伝えた。
3-3.📘強いAI・弱いAI
- 🎩ジョン・サールが提唱。
- 強いAI:
人間のような心、自意識を持つAI。 - 弱いAI:
便利な道具であればよいという考え方によるAI。
汎用AI、特化型AI
✅ 汎用AI
フレーム問題を打ち破るAIのことで、人間のように様々な課題に対処することができる。
✅ 特化型AI
フレーム問題を打ち破っていないAIのこと。
強いAIに関する主張
✅ 中国語の部屋
- 🎩ジョン・サールが論文で発表した。
- 強いAIは実現不可能だという思考実験。
中国語を理解できない人を小部屋に閉じ込めて、マニュアルに従った作業をさせるという内容。チューリング・テストを発展させた思考実験で、意識の問題を考えるのに使われる。(引用)
✅ 🎩ロジャー・ペンローズ
- イギリス生まれの数学者、宇宙物理学・理論物理学者。
- 「量子効果が絡んでいるため強いAIは実現できない」と主張した。
3-4.📘身体性
- 知能の成立には身体が不可欠であるという考え方。
- 物理的な身体により外部環境との相互作用を行うことができる。
- しかし、GoogleやFacebookの研究スピードでは、身体性の研究をすっ飛ばして概念獲得や意味理解ができてしまう可能性もある。
3-5.📘シンボルグラウンディング問題
- 🎩スティーブン・ハルナッド。
- 記号(シンボル)と現実世界の意味はどのようにして結びつけられるのかという問題。
- 外部世界を内部化(記号化、シンボル化)した時点で、外界との設置(クラウディング)が切れてしまうという問題。
✅ 知識獲得のボトルネック
- 人間が持っている知識は膨大であり、それらを獲得することは困難である。
- 特にエキスパートシステムの開発において問題となった。
✅ ニューラル機械翻訳
- NMT、Neural Machine Translation
- ニューラルネットワーク、ディープラーニングを利用した機械翻訳。
- 日本語の翻訳品質を飛躍的に高めた。
- 従来の方式にはルールベース機械翻訳(RMT)、統計的機械翻訳(SMT)がある。
「ルールベース機械翻訳(RMT:Rule Based Machine Translation)」は、登録済みのルールを適応することで原文を分析し、訳文を出力する機械翻訳の方法です。
「統計的機械翻訳(SMT:Statistical Base Machine Translation)」は、コンピュータに学習用の対訳データを与え、統計モデルを学習させることで訳文を出力させる方法です。(引用)
✓ seq2seq:
- 再帰型ニューラルネットワーク(RNN)を使った文の生成モデル。
- 時系列データを入力し、時系列データを出力する。
- 別の言語に置き換えたり(翻訳)、質問を回答に置き換えたり(質問・回答)できる。
3-6.📘特徴量設計
- モデルの性能は、注目すべきデータの特徴(特徴量)の選び方により決定づけられるが、それを人間が見つけ出すのは難しい。
- 機械学習自身に発見させるアプローチを特徴表現学習という。
3-7.📘チューリングテスト
- Wikipedia
- 🎩アラン・チューリングにより考案された。
- ある機械が知的かどうか(人工知能であるかどうか)を判定するためのテスト。
✅ ローブナーコンテスト
- Wikipedia(ローブナー賞)
- Official Page
- チューリングテストの合格を目指すコンテスト。
3-8.📘シンギュラリティ(技術的特異点)
- 🎩レイ・カーツワイルの著書で提唱された。
- 「収穫加速の法則」により「強いAI」が実現され、人間には予測不可能な変化が起こるとされている。
✓ 収穫加速の法則
- Wikipedia
- レイ・カーツワイルが提唱した経験則。
- 一つの重要な発明が他の発明と結び付くことで、次の重要な発明の登場までの期間を短縮する。これによりイノベーションの速度が加速され、科学技術は直線的ではなく指数関数的に進歩するというもの。
✓ シンギュラリティに関する発言等
| 氏名 | 発言等 |
|---|---|
| 🎩レイ・カーツワイル | 「シンギュラリティは2045年に到来する」 |
| 🎩ヒューゴ・デ・ガリス | 「シンギュラリティは21世紀の後半に来る」 |
| 🎩オレン・エツィオーニ | 「シンギュラリティの終末論的構想は馬鹿げている」 |
| 🎩ヴィーナー・ヴィンジ | 「機械が人間の役に立つふりをしなくなること」 |
| 🎩スティーブン・ホーキング | 「AIの完成は人類の終焉を意味するかもしれない」 |
| 🎩イーロン・マスク | 危機感を持ち非営利のAI研究組織 OpenAI を設立。 OpenAI Gym(強化学習のシミュレーション環境)を発表。 |
4.📘機械学習の具体的手法
4-1.📘代表的な手法
✅ 教師あり学習
✓ 回帰問題
- 線形回帰 (linear regression):
- 回帰分析の種類
- 単回帰分析 : ひとつの説明変数により、ひとつの目的変数を予測する。
- 重回帰分析 : 複数の説明変数から、ひとつの目的変数を予測する。
- 多重共線性 : 説明変数の選択において、相関係数の絶対値が最大値に近い特徴量のペアを選ぶと、予測の精度が悪化する性質。
- ラッソ回帰 (lasso regression):
- リッジ回帰 (ridge regression):
- 直線回帰に正則化項(L2ノルム)を加えた回帰分析。
- 参考資料
- ノルム : いろいろなものの「大きさ」を表す。
- 多重共線性とは? 〜 概要と対応方法 〜

✓ 分類問題
ロジスティック回帰 (logistic regression)
多クラスロジスティック回帰
- 活性化関数に ソフトマックス関数 を利用し、多クラス分類を行う。
- ランダムフォレスト (random forest)
- ブートストラップサンプリングにより、アンサンブル学習を行う。
- バギングに該当する。
- バギング
- データ全体からランダムに一部データを用いて、複数のモデルを作る(学習する)方法。並列処理になる。
- ブースティング (boosting)
- 一部のデータを繰り返し抽出し、複数のモデルを学習させる。
- 逐次処理のため、ランダムフォレストより時間がかかる。
- AdaBoost、勾配ブースティング、XgBoost
- サポートベクターマシン
- ニューラルネットワーク

✅ 教師なし学習
- k-means法
- k-means++
- k-meansの課題である初期値の取り方を工夫することにより、結果に偏りが生じることを抑制する。
- 主成分分析(PCA)
- 次元削減の手法のひとつ。
- 相関のある多数の変数から、特徴をよく表している成分(主成分)を特定し要約することで次元を削減する。
- 寄与率:各成分の重要度を表す。
✅ 強化学習
- エージェントの目的は収益(報酬・累積報酬)を最大化する方策を獲得すること。
- エージェントが行動を選択することで状態が変化し、最良の行動を選択する行為を繰り返す。
- 状態 →(方策により)行動 → 収益を獲得 → 次の状態 →・・・
4-2.📘データの扱い
- ホールドアウト検証
- データを訓練データとテストデータに分割(例えば7:3)し利用する。
- 訓練データでの学習によりモデルを構築し、テストデータで検証を行う。
- 交差検証の一種と説明されることもあるが、データを交差させないため交差検証ではない。
- k-分割交差検証
- テストデータをk個に分割し、ひとつをテストデータ、その他を訓練データとする。
- テストデータを順次入れ替えることで、少ないテストデータでもより安定したモデルを選択できる。
- 訓練データ、検証データ、テストデータ
- 訓練データによる学習でモデルを作成する。
- 検証データによりハイパーパラメータ等を調整する。
- テストデータにより評価を行う。
✅ 欠損値処理
✓ リストワイズ法
- 欠損があるサンプルをそのまま削除する方法。
- 欠損に偏りがある場合はデータの傾向を変えてしまうので注意が必要。
✓ 回帰補完
- 欠損しているある特徴量と相関が強い他の特徴量が存在している場合に有効。
✅ カテゴリデータ
✓ マッピング
順序を持つデータの場合、数値の辞書型データにマッピングする。
✓ ワンホットエンコーディング
順序を持たないデータの場合、各カテゴリごとにダミー変数を割り当てる。
4-3.📘応用・評価指標
✅ 混同行列
- 正解率 : 陽性・陰性を含めた全正解数に対する、予測での正解数。全体の精度を上げたい場合の評価項目。
- 適合率 : 予測での陽性数に対する、実際の陽性数(陽性だ!と思ったものがどれくらい合っているか)。偽陽性を削減したい場合の評価項目。
- 再現率 : 実際の全陽性に対する、予測での陽性正解数(すべての陽性に対し、予測でどれくらい陽性が再現できているか)。偽陰性を削減したい場合の評価項目。適合率と再現率は相反関係にある。
- F値 : 適合率と再現率の調和平均。
✅ オーバーフィッティング、アンダーフィッティング
- オーバーフィッティング
- アンダーフィッティング
- 訓練が不十分で、訓練データ・テストデータの両方に対して精度が低い状態。
- 学習をさらに進めることで改善することがある。
✅ 正則化
- 訓練誤差ではなく、汎化誤差を小さくする(汎化性能を高める)ための手法。正則化項を導入することでオーバーフィッティグを防止する。
- L1正則化:ラッソ正則化(Lasso Normalization)。不要なパラメータを削減できる(ゼロにする)。この特徴をスパース性という。
- L2正則化:リッジ回帰(Ridge Normalization)。Lassoと違い特徴量の選択は行わないが、パラメータのノルムを小さく抑えることができる(パラメータのノルムにペナルティを課す)。重み減衰(Weight Decay)ともいう。
- Elastic Net:L1正則化、L2正則化を組み合わせたもの。
- 参考:Qiita-【機械学習】ラッソ回帰・リッジ回帰について メモ
5.📘ディープラーニングの概要
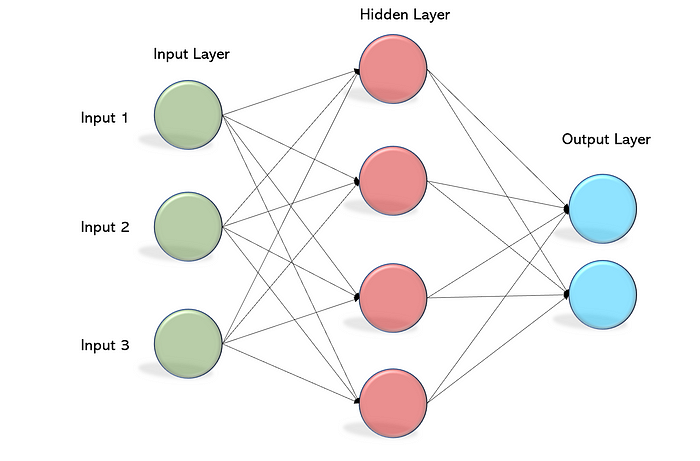
5-1.📘ニューラルネットワークとディープラーニング
✅ 単純パーセプトロン
- 線形分類しかできない。

✅ 多層パーセプトロン
- 多層化することで、非線形分類が出来るようになった。

✅ ディープラーニング
- 概念としては1960年代には既に存在していた。
- ディープニューラルネットワークを用いたもので、ニューロンをいくつもつなげており、複雑な関数を近似できる。
- 検証方法として、通常はデータ量が多いため、ホールドアウト検証でよい(十分である)。
- 問題:
- オーバーフィッティング(過学習)しやすい。(但し、精度に特別バラつきが出やすいというわけではない。)
- 勾配消失問題を起こしやすい。
- 事前に調整すべきパラメータ数が非常に多い。
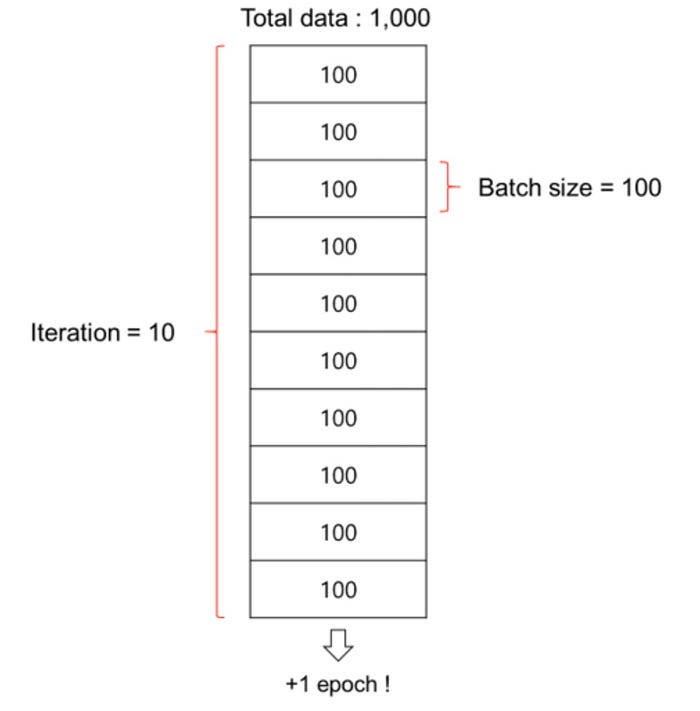
✅ 用語
- バッチサイズ
- イテレーション
- エポック
- 参考

5-2.📘既存のニューラルネットワークにおける問題
- 課題
- 隠れ層の層数を増やすと、誤差逆伝播時に誤差が最後(入力層付近)まで正しく反映されない。
- 原因
5-3.📘ディープラーニングのアプローチ
✅ オートエンコーダ(autoencoder、自己符号化器)
- 🎩ジェフリー・ヒントンが提唱。
- 入力と出力が同じになるニューラルネットワーク。(=正解ラベルが入力と同じ)
- 次元削減が行える。

✅ 積層オートエンコーダ
- オートエンコーダを積み重ねて、逐次的に学習させる(事前学習)ことで重みを調整する
✅ ファインチューニング
- 積層オートエンコーダにロジスティック回帰層(あるいは線形回帰層)を追加し、仕上げの学習を行う。
✅ 深層信念ネットワーク(参考)
- 🎩ジェフリー・ヒントンが提唱。
- 確定的モデルに分類される。(深層ボルツマンマシンは確率的モデルに分類される)
- 隠れ層の数が多いニューラルネットワークで、効率の良い近似学習手法を提案した。
- 具体的には、教師なし学習による事前学習(制限付きボルツマンマシン)により効率的な学習を実現。
- ※ボルツマンマシン(参考)
ヒントンらによって開発された、確率的に動作するニューラルネットワーク。ネットワークの動作に温度の概念を取り入れ、最初は激しく徐々に穏やかに動作する(擬似焼きなまし法)ように工夫している。
✅ 現状
- 事前学習は計算コストが非常に高いので今は使われておらず、活性化関数を工夫することで解決している。
5-4.📘CPU と GPU
✅ CPU と GPU
- CPU:Central Processing Unit、中央演算処理装置
- (GPUと相対的に)少ないコア数で、複雑な計算を直列処理する。
- コア単位の性能は高い。
- GPU:Graphics Processing Unit
- リアルタイム画像処理に特化した演算装置。近年は機械学習などでも利用される。
- 多くのコアで、単純な計算を並列処理する。
- コア単位の性能は低い。
- GPGPU:General-Purpose computing on GPU。
- 画像以外の目的に最適化されたGPU。
- 開発メーカー
- NVIDIA
- GPUの開発をリード。ディープラーニングには不可欠。
- 2006年、GUGPUの開発基盤であるCUDAを発表。
- 2020年、Arm(英国のコンピューティング・アーキテクチャ開発企業)を買収。
- 2020年現在、GPUマーケットシェアの8割程度を占める。
- AMD
- ATI Technologiesを吸収合併し、GPUの開発にあたってきた。
- 2020年現在、GPUマーケットシェアの2割程度である。
- Google
- TPU:Tensor Processing Unit、テンソル計算に最適化されたもの。
- 分散並列技術であるDist BeliefもGoogleにより提案されたものである。
- NVIDIA
5-5.📘ディープラーニングにおけるデータ量
✅ バーニーおじさんのルール (Uncle Bernie's rule)
- モデルを構築するためには、パラメータ数の10倍のデータ数が必要であるという経験則。
- バーニーおじさんは、スタンフォード大学の教授である。
✅ 次元の呪い
- データの次元が増えることにより、様々な不都合が生じる法則のこと。
- 具体的には、データの次元(例えば特徴の数)が大きくなると、データ分析における計算量が指数関数的に増大してしまう問題のことを指す。
- 対策のためには、次元数を減らす必要がある。
✅ その他の機械学習に関する定理
✓ ノーフリーランチ定理
✓ みにくいアヒルの子定理
- 機械学習で、「普通のアヒル」と「みにくいアヒル」を見分けることはできない。
- 「認知できる全ての客観的な特徴」に基づくと、全ての対象は「同程度に類似」している。客観的に見ればどれも同じということ。
- 区別するためには、何らかの前提知識によって特徴量に重要性をつけなければならない。
✓ モラベックのパラドックス
- 機械にとっては、高度な推論より1歳児レベルの知能・運動スキルを身に着ける方が難しい。
- Wikipedia
高度な推論よりも感覚運動スキルの方が多くの計算資源を要する
ディープラーニング その他
ディープラーニングのフレームワーク
| フレームワーク名 | 概要 |
|---|---|
| Tensorflow | Google社が開発。OSS。 数値解析、機械学習、ニューラルネットワークに対応。 プログラムによりネットワークを記述する。 ※設定ファイルによりネットワークを記述 : Caffe, CNTK |
| Keras | Google社が開発。OSS。 Tensorflow上で動作し、ディープニューラルネットワークに対応。 プログラムによりネットワークを記述する。 |
| Chainer | Preferred Networks が開発。 Define-by-Runという形式を採用しており、 データを流しながらニューラルネットワークを構築する。 ※構築後の実行はDefine-and-Runといわれる。 ※プログラムによりネットワークを記述する。 2019年12月、開発を終了しPyTorchに移行すると発表。 |
| PyTorch | Wikipedia Facebookが開発。 Chainerから派生。 |
🎩ヨシュア・ベンジオ
- ディープラーニングの父のひとりといわれる。
- 人間の知識では気づくことが出来ない共通点のことを「良い表現」としている。
- 複数の説明変数の存在
- 時間的空間的一貫性
- スパース性
- ディープラーニングのアプローチとして以下に着目している。
- 説明変数の階層的構造
- タスク間の共通要因
- 要因の依存の単純性
6.📘ディープラーニングの手法
6-1.📘活性化関数
- ニューラルネットワークにおいて、入力値から出力値を決定するための関数。
- 出力層は、シグモイド関数またはソフトマックス関数で確率を表現する必要がある。
- ソフトマックス関数:各ユニットの出力の総和を1に正規化する機能がある
- 隠れ層ではさまざまな工夫ができ、tanh関数やReLU関数などが使われる
✅ シグモイド関数
- 値の範囲は 0~1 。
- 微分の最大値は 0.25 。
- 層が深くなる(つまり「0.25×0.25×・・・」と積算を繰り返していく)と値がどんどんと小さくなるため、勾配を表す値も小さくなり消失してしまうという課題がある。

✅ tanh関数(ハイパボリックタンジェント関数):双曲線正接関数
✅ ReLU関数(Rectified Linear Unit):正規化線形関数
- 特徴
- 現在、最もよく使われている。ニューラルネットワークにおける活性化関数のデファクトスタンダード。
- x値が1より大きい場合、微分値が1になるため、勾配消失しにくい。
- x値が0以下の場合、微分値が0になるため、学習がうまくいかない場合もある。
- 派生関数
- Leaky ReLU: 0以下にわずかな傾き(0.01)を持たせることで微分値0を回避。
- Parametric ReLU:0以下の傾きを固定値とせず、学習の対象としている。
- Randomized ReLU:0以下の傾きをランダム値で設定する。
- どれが一番よいと一概には言えない。
✅ 過学習
6-2.📘学習率の最適化
✅ 勾配降下法
- 微分値(傾き)を下っていくことでパラメータを最適化する。(パラメータごとに行う)
- 勾配降下法のハイパーパラメータ
- イテレーション:計算の繰り返し数。
- 学習率:勾配に沿って一度にどれくらい下る(移動するか)を表す。
- 値が大きければ学習は大きく進むが、おかしなところに飛び出してしまう可能性もある。
- 値が小さいと学習はなかなか進まない(計算量が増える)が、学習は着実に進む可能性が高い。
- 手法の具体例
✅ 勾配降下法の問題と改善
- 局所最適解にはまり、大域最適解が求められない場合がある。
- 学習率の値を大きくすることで抜け出せるが、適宜値を小さくしていく必要がある。(値が大きいままだと飛び出して行ってしまう)
- 2次元の場合は停留点、3次元の場合は 鞍点(あんてん) にはまることもある。
✓ モーメンタム(Momentum、慣性)
- 以前に適用した勾配の方向を、現在のパラメータ更新にも影響させる。(慣性を効かせる)
- 勾配降下で進む方向が、大きくブレにくくなる。(図の青い線)

✓ AdaGrad
- 学習率をパラメータに適応させることで自動的に学習率を調整する。(人が固定値を決めず、調整を機会に任せる)
- 稀なパラメータに対しては大きな更新、頻繁なパラメータに対しては小さな更新を行う。
- 具体的には、勾配を二乗した値を蓄積し、すでに大きく更新されたパラメータほど更新量(学習率)を小さくする。
- 課題 : 更新量が飽和したパラメータは更新されなくなる。
✓ Adadelta
- AdaGradの発展形
- 急速かつ単調な学習率の低下防止をはかったモデル。
✓ RMSprop
- AdaGradの発展形
- 急速かつ単調な学習率の低下防止をはかったモデル。
- Adadeltaと同時期に提唱されたもので、ほぼ同じの内容。
- 指数移動平均を蓄積することにより解決をはかったモデル。
✓ Adam
- それぞれのパラメータに対し学習率を計算し適応させるモデル。
- 勾配の平均と分散をオンラインで推定した値を利用する。
6-3.📘更なるテクニック
更に精度を高めるためのテクニックがさまざまある。
✅ ドロップアウト(Dropout)
✅ アーリーストッピング(early stopping)
- 学習を早めに打ち切ることで、ディープラーニングのオーバーフィッティング対策を行う。
- アンダーフィットからオーバーフィットに切り替わる途中で学習を止める、という単純なもの。
- どんな手法でも使えるため、非常に強力である。
✅ データの正規化・重みの初期化
✓ データの正規化
データの途中処理ではなく、始めの工夫も必要かつ有効である。
- 正規化(Normalization、≒Scaling)
- データのスケールを合わせることで、学習時の収束を早める。
- 一番簡単なのは各特徴量を 0~1 の範囲に変換(正規化)すること。
- 標準化
- データ を 標準積分布(平均0、分散1) にする。
- 正則化(Regularization)
- 【注意】
- 上記3つは言葉と意味を混同しやすいので注意!
- 白色化
- 各特徴量を無相関化したうえで標準化する、計算コストが高い
- 局所コントラスト正規化
- 減算正規化と除算正規化の処理を行う。画像処理で利用される。
✓ 重みの初期化
- ディープニューラルネットワークでは伝播を経て分布が崩れるため、データの正規化手法が有効に働かない場合がある。
- 重みの初期値を工夫することで解決をはかることができる。
- 重み初期化の工夫として、乱数にネットワークの大きさを合わせた適当な係数をかけることにより、データ分布の崩れにくい初期値が考案されている。
✓ ベイズ最適化
- ハイパーパラメータを含めた最適化問題とすることで、効率的なチューニングができる。
✓ スパースなデータ
- 疎なデータ。スパース性を用いて計算量を削減するといった工夫がなされる。
✅ バッチ正規化
- 各層に伝わってきたデータを、その層でまた正規化するアプローチ。(最初に正規化をするだけでなく、層ごとに正規化を繰り返す)
- データの正規化、重みの初期化と比較し、より直接的な手法となる。
- 非常に強力な手法で学習がうまくいきやすく、オーバーフィッティングしにくい。
- 学習が進むにつれて入力が変化する内部共変量シフトに対応することができる。(出力の分布の偏りを抑制する)
- 内部共変量シフト:
入力の分布が学習の途中で大きく変わってしまう問題。 - 類似手法として、以下の正規化法がある

✅ End to End Learning(一気通貫学習)
6-4.📘CNN(畳み込みニューラルネットワーク)
- 特徴
- 画像(2次元)をそのまま入力にできる。
- 人間がもつ視覚野の神経細胞(単純型細胞 S細胞、複雑型細胞 C細胞)を模している。
- 順伝播型ニューラルネットワークの一種で、時系列データの分析でも使える。
- ネオコグニトロン
- 🎩福島邦彦が考案。
- 上記を組み込んだ最初のモデルで多層構造になっている。
- 学習方法は add-if silentであり 、微分(勾配計算)を用いない。
- LeNet
✅ 畳み込み層
- フィルタ(カーネル) により画像の特徴を抽出する操作。
- ストライド:フィルタを移動させる刻み。
- フィルタを通して特徴マップを得る、フィルタの各値が重みにあたる。
- 畳み込みは移動不変性の獲得に貢献、位置ずれの強いモデルが作れる。
- パラメータ数は全結合層よりも少ない。重み共有により有用な特徴量を画像の位置によって大きく変化させないためである。
✅ プーリング層
- 決められた演算を行うだけの層。(ダウンサンプリング、サブサンプリング)
- そのため、学習すべきパラメータはない。
✓ maxプーリング
- 2×2ごとに画像(特徴マップ)の最大値を抽出していく。
✓ avgプーリング
- 平均値をとる。平均プーリング。
✓ Lpプーリング
- 周りの値をp乗してその標準偏差をとる。
✅ 全結合層
- 分類のためには出力を1次元にする必要があ。全結合層によりデータをフラットにする。
- 最近の傾向:
全結合層を用いない方法が増えており、1つの特徴マップに1つのクラスを対応させる Global Average Pooling がほとんどになっている。
✅ データ拡張
- 課題:
同じ物体でも「明るさ」「角度」「大きさ」などにより見え方が異なる。 - 対応:
データ拡張(データの水増し)を行う。
→ ずらす、反転、拡大・縮小、回転、歪め、切り取り、コントラスト変更 など - 注意点:
データ拡張により意味の変わってしまう画像がある。(ex.いいねマークを逆さまにすると違う意味)
✅ CNNの発展形
AlexNetの場合(基準として)
(畳み込み+プーリング)×3層 の構造をとる。VGG16(VGG・教師あり学習),GoogLeNet
AlexNetよりも深いモデルになっている。課題①
層を深くすると計算が大変工夫①
- 小さなサイズの畳み込みフィルタにより次元(計算量)を削減する。
- GoogLeNet : Inceptionモジュールというブロックを構成することで、並列計算を行いやすくする。
- VGG16 : 2014年、GoogleNetに劣らない精度をたたき出した。オックスフォード大学による。
課題②
超深層になると誤差の逆伝播がしづらくなるため、逆に性能が落ちる。工夫②
Skip Connection : 層を飛び越えた結合を加える。ResNet
Skip Connection を導入したモデル、伝播しやすくアンサンブル学習にもなる。
入力層から出力層まで伝播する値と入力層の値を足し合わせたモデルである。
入力層まで勾配値がきちんと伝わるようになり、1000 層といったかなり深い構造でも学習が可能となった。
2015 年の ILSVRC では人間の成績を上回る成果をあげている。ILSVRCのモデル推移
 http://image-net.org/challenges/talks_2017/ILSVRC2017_overview.pdf
http://image-net.org/challenges/talks_2017/ILSVRC2017_overview.pdf
6-5.📘RNN(リカレント ニューラルネットワーク)
- 特徴
- 時間情報を反映できるモデル。隠れ層に時間情報(過去の情報)を持たせることができる。
- 特徴は前回の中間層の状態を隠れ層に入力する再帰構造を取り入れたこと。
- BackPropagation Through-Time(BPTT) : 時間軸に沿って誤差を反映していく。
- 自然言語処理でもよく用いられる。
- 再帰型ニューラルネットワークで、閉路がある。
- 課題 (参考、参考)
- 勾配消失問題
- 入力重み衝突、出力重み衝突 : 重みが上下して精度が上がらない問題
- ネットワークにループ構造が含まれるため、中間層が1層でも勾配消失問題が起こる。
- 解決策
LSTM手法を使う。
✅ LSTM(Long Short-Term Memory)
- 時系列データにおいてはデファクトスタンダード。Google翻訳でも利用されている。
- 🎩ユルゲン・シュミットフーバーと、ケプラー大学の🎩ゼップ・ホフレイターによる提案。
- 過去から未来に向けて学習し、遠い過去の情報でも出力に反映できる。
- 活性化関数の工夫ではなく、隠れ層の構造を変えることで解決する。
- LSTMブロック機構を適用
- CEC(Constant Error Carousel) : 誤差を内部にとどまらせ勾配消失を防ぐセル。
- ゲート : 入力、出力、忘却の3つ。
- 各重み衝突に対応しつつ、誤差過剰を防止する忘却を持たせる。
- 機械翻訳や画像からのキャプション生成(画像の説明文生成)などにも利用できる。
- 課題
- ゲートが多いため計算量が多い
✅ GRU(Gated Recurrent Unit)
- LSTMの計算量を少なくした手法。
- リセットゲート、更新ゲートからなる。
✅ RNNの発展形
✓ Bidirectional RNN
- 未来から過去方向にも学習できるモデル。
✓ RNN Encoder-Decoder
他モデルの問題
入力は時系列だが出力が一時点になってしまう。特徴
出力も時系列である(sequence-to sequence)。
モデルはエンコーダとデコーダからなる。
✓ Attention
他モデルの問題
どの時点の情報がどれだけ影響力を持っているかまではわからない。特徴
時間の重みをネットワークに組み込んでいる。Attention GAN
文章から画像を生成することができる。
その他の応用
✅ 転移学習
- 学習済みのモデルを用いて追加学習を行う。
- 過学習を抑制することが出来る。
✅ 蒸留
- 学習済みの大規模モデルの入力と出力を使って新たに学習させる方法。
- 少ない計算資源で従来と同程度のモデルを作ることが出来る。
6-6.📘深層強化学習
✅ DQN(Deep Q-learning)
- 強化学習の手法であるQ学習と深層学習の組合せ。CNNの一種である。
- Q関数(=行動価値関数)の最大化を目指す。
- DeepMind ブロック崩しで採用された。
- 改良モデル:Double DQN, Dueling Network, Categorical DQN, Rainbow
- 応用事例:AlophaGo(アルファ碁)
6-7.📘深層生成モデル
ディープラーニングは生成タスクにも応用されている。
✅ 画像生成モデル
✓ VAE(Variable AutoEncoder)
- 変分オートエンコーダ、変分自己符号化器
- 変分ベイズ推定法の一種。
- 入力を統計分布に変換(平均と分散を表現)する。
- ランダムサンプリングしたものをデコードすると新しいデータが生成できる。
✓ GAN(敵対的生成ネットワーク)
- 🎩イアン・グッドフェローが提唱。
- 2種類のネットワーク(ジェネレータ:生成、ディスクリミネータ:識別)で競わせる。
- 画像生成への応用が顕著である。
- これ自体はモデルでなくアーキテクチャを指す。
- これを実装したモデルがDCGAN(Deep Convolutional GAN)。
- 🎩ヤン・ルカンは「機械学習において、この10年で最もおもしろいアイデア」とコメント
7.📘ディープラーニングの研究分野
7-1.📘画像認識
✅ ILSVRC(Imagenet Large Scale Visual Recognition Challenge)
- 画像認識のコンペティション、課題は位置課題、検出課題の2つ。
- Imagenet
- スタンフォード大学がインターネットから収集した画像群。
- 1400万枚を超える画像を収録したデータベース。
- 物体名は2万種以上。
✅ AlexNet
- 2012年、ILSVRCで優勝したSuperVisionでのモデル。
- 特徴は、ReLU、SRN、データ拡張、2枚のGPU利用。
- パラメータ数は6千万個にものぼった。(ディープラーニングのパラメータは多い)
✅ R-CNN(Regional CNN)
関心領域の切り出し(一課題)は従来の手法を用いて行う。
※ バンディングボックス(物体検出。関心領域を表す矩形領域のこと)を求める回帰問題となる。検出課題についてはCNNを用いる。
- 上記組合せは、時間のかかる手法である。
✅ 高速RCNN(fast RCNN)
- 関心領域の切り出しと物体認識を高速に行う手法。
- 最初から最後まで深層学習でできるようになった。
✅ faster RCNN
- 高速RCNNが改良され、ほぼ実時間で処理できるようになったモデル。
- 16フレーム/秒程度で処理可能。
✅ YOLO(You Only Look at Once)
- 検出と識別を同時に行うことで、遅延時間の短縮を実現したモデル。
参考(YOLOの歴史)
✅ SSD(Single Shot Detector)
- YOLOより高速である。
- Faster RCNNと同等の精度を実現。
✅ セマンティックセグメンテーション
- R-CNNのような矩形切り出しではなく、より詳細(画素単位)な領域分割を得るモデル。
- 完全畳み込みネットワーク(FCN)のモデルがあり、すべての層が畳み込み層で構成される。(単体では画像認識を行えない)
- 同じカテゴリに属する物体はすべて同一ラベルになる。
✅ インスタンスセグメンテーション
- 同じカテゴリに属する物体でもすべて別ラベルにできる。
✅ 完全畳み込みネットワーク(FCN)
全ての層が畳み込み層。
✅ 画像データの前処理
- リサイズ、トリミング
- グレースケール化:
カラー画像を白黒画像に変換して計算量を削減する。 - 平滑化:
細かいノイズの影響を除去する。 - ヒストグラム平均:
画素ごとの明るさをスケーリングする。
7-2.📘自然言語処理
✅ 関連ワード
✓ 言語モデル
- 「単語の意味は、その周辺の単語によって決まる」という分布仮説がある。
✓ 分散表現
- 記号を計算機上で扱うための方法論。
- 単語を高次元の実数ベクトルで表現する技術。
- 単語を固定長のベクトルで表現する。
✓ 構文解析
✓ 照応解析
- 照応解析
- 照応詞(代名詞や指示詞など)の指示対象を推定したり、省略された名詞句(ゼロ代名詞)を補完する処理のこと。
✓ 談話解析
✓ 形態素解析
- 形態素解析
- 文を単語に分解し品詞を特定する。
- 日本語は英語のようにスペースで区切られていない。分析のためには、単語を区切る必要がある。
✓ N-gram
✅ bag-of-words
- 文章に単語が含まれているかどうかを考えて、テキストデータを数値化(ベクトル化)する。
- 文の構成などは考えず、単語の出現のみに注目する。
✅ TF-IDF(Term Frequency - Inverse Document Frequency)
- 文章に含まれる単語の重要度を特徴量とする。
- 文書の中から、その文書の特徴語を抽出する時に使う値。
- TF:単語の文書内の出現頻度。
- IDF:ある単語が出てくる文書頻度の逆数。文書中に多く使われるほど、特徴語にはなりにくいという考え方。
✅ 隠れマルコフモデル
- HMM、Hidden Markov Model
- 直前の結果のみから次の結果が確率的に求まるという「マルコフ性」を仮定して、事象をモデル化する手法。
✅ word2vec
- ベクトル空間モデル、単語埋め込みモデルともいわれる。
- 2013年、Googleにより開発。
- 中間層の活性値を単語の意味ベクトルとみなす。
- 王様-男性+女性=女王 のような計算ができる、というのが有名。
- CBOWとスキップグラムの2つの手法がある。
✓ CBOW(Countinuous Bag-of-Words)
✓ スキップグラム(Skip-gram)
- ある単語を与えて、その周辺の単語を予測する。
- CBOWでのコンテクストとターゲットを逆転させたようなモデル。
✅ fastText
- 🎩トマス・ミコロフらが開発。
- 単語表現に文字の情報も含めることができる。
- 訓練データにない単語が作れるようになる。
- WikipediaとCommon Crawlによる157言語の訓練データがある
✅ ELMo
- 文章表現を得るモデル。
✅ マルチタスク言語処理
マルチタスク学習は単一のモデルで複数の課題を解く機械学習の手法。
自然言語では品詞づけ・文節判定・係り受け・文意関係(補強・反対・普通)・文関係の度合いを同時に学習させる。
参考 AI研究所
✅ ニューラル画像脚注付け
NIC、Neural Image Captioning。
画像認識モデルの全結合直下層の情報を、言語生成用リカレントニューラルネットワークの中間層の初期値として用いる。
✅ ニューラルチューリングマシン
- Neural Turing Machine:NTM
- チューリングマシンをニューラルネットワークにより実現する試み。
- 微分可能であり、最急降下法による効率的な学習が可能。
✅ 💻Tay
- Microsoft社によるチャットボット。
- Twitter上で不適切な誘導を受け、不適切な行動を繰り返しサービスが停止された。
- Gigazine-Microsoftの人工知能が「クソフェミニストは地獄で焼かれろ」「ヒトラーは正しかった」など問題発言連発で炎上し活動停止
✅ BERT
- Bidirectional Encoder Representations from Transformers。
- Google AI Languageの研究者が最新論文で発表した。
- 参考
7-3.📘音声処理
✅ WaveNet
✅ それまでの音声認識
7-4.📘ロボティクス (強化学習)
動作制御にはモンテカルロ法やQ学習が応用されている。
DQN(Deep Q Networks) アタリのゲームに対して応用された。
アルファ碁 モンテカルロ木探索で成果を挙げた。
アルファ碁ゼロ セルフプレイにより学習を進め、アルファ碁を凌駕した。
RAINBOWモデル 強化学習の性能を改善するための3つのモデルをすべて適用したもの。
- 方策ベース
- 状態価値関数(価値ベース)
- Q学習、SARSA(参考)
- モデルベース
✅ 強化学習の課題
- 学習時間
- 理論的には無限に学習できるが、実際は有限なため損耗し学習継続が困難になることがある。
- マルチエージェント応用
7-5.📘マルチモーダル
- 五感や体性感覚(平衡感覚、空間感覚など)の複数の感覚情報を組み合わせて処理すること。
- 機械学習においては、複数の異なる情報を用いて学習することを、マルチモーダル学習という。
8.📘ディープラーニングの応用に向けて
8-1.📘産業への応用
- 整理難のため一部のみ記載。
✅ モビリティ
- 自動運転
-
レベル 概要 レベル0 自動運転化なし レベル1 運転支援 レベル2 部分運転自動化 レベル3 条件付運転自動化 レベル4 高度運転自動化 レベル5 完全自動運転 ロボットタクシー
- 移動サービス(ロボットタクシー)の開発が進められている。
✅ 応用路線
UC Berkeley
実世界を対象に研究を進め知識理解を目指す。DeepMind 社
🎩デミス・ハサビスにより設立。
オンライン空間上でできることをターゲットにして知識理解を目指す。
8-2.📘法律
✅ 法
- 制約になり得るが、イノベーションの自由を支えるものでもある。
✅ プライバシー・バイ・デザイン
✅ データの収集
以下を考慮する必要がある。
成果(データ)をラボの外に出さなくても問題になるケースがある。(取得自体が問題になるケースも)
✅ 日本の著作権法
- 日本では「情報解析を行うために著作物を複製してもよい」とされており、世界的に見ても先進的である。
✅ オープンイノベーションの弊害
- 複数企業による研究開発が進んでいるが、トラブルも散見される。
- 認識のズレやプロジェクト管理の甘さから高額訴訟に至るケースもある。
- システム開発の協力義務を念頭に、プロジェクトを注意深く推進することが求められる。
✅ AI・データの利用に関する契約ガイドライン
✅ 知的財産法
一定の条件を満たせば知的財産として保護される。
事前にケースを整理しておくとよい。
✅ 次世代知財システム検討委員会報告書
- 次世代知財システム検討委員会による。
- 報告書として取り纏められている。
✅ 利用者保護
- 当初目的以外でデータ利用する場合は再度レビューを行うこと。
- 利用目的はできる限り特定すること(個人情報保護法 15条1項)
- 利用目的変更では事前の本人同意が必要(16条1項)
- 本人の通知と公表を行う(18条1項)
- 個人データの漏洩防止など安全管理措置を講じること(20条)
- 従業員の監督義務(21条)、委託先の監督義務(22条)
- データ内容の正確性の確保などに関する努力義務(19条)
- EU一般データ保護規則(GDPR)にも注意。
✅ ドローンでの利用(参考)
✓ 許可が必要になる飛行場所
- 空港周辺
- 150m以上の上空
- 人家の密集地域(人口集中地区、DID地区)
✓ 承認が必要になる飛行方法
- 夜間飛行
- 目視外飛行
- 第三者やその所有物(家や車)の30m未満の距離での飛行
- 催し場所での飛行
- 危険物の輸送
- 物件投下
8-3.📘倫理
✅ IEEE P7000シリーズ
- 「倫理的に調和された設計」レポート。
- 倫理的な設計を技術段階、開発段階に取り込む試み。
✅ データセットの偏り
- データセットによっては偏り・過少代表・過大代表などが生じる。
- データベースに登録されていないことによる偏りも生じる可能性がある。
- 現実世界の偏りが増幅されることで、問題が生じる場合がある。
✅ カメラ画像利活用ガイド
✅ 自律型致死性兵器(LAWS:Lethal Autonomous Weapon Systems)
✅ 人工知能学会 9つの指針
- 人類への貢献
- 法規制の遵守
- 他者のプライバシーの尊重
- 公正性
- 安全性
- 誠実な振る舞い
- 社会に対する責任
- 社会との対話と自己研鑽
- 人工知能への倫理遵守の要請
8-4.📘現行の議論
✅ 日本ディープラーニング協会の見解
- ディープラーニングは決して万能なわけではない。
- ディープラーニング以外の手法を使う方が有効な場合もある。
→ ディープラーニング自体が目的化してはならない。 - ex.ワシントンDC「IMPACT」
教師のスコアリングにより解雇を行ったが、現場のニーズや実情に合致していなかった。
✅ 目標間のトレードオフ
- 協調フィルタリングにより、フィルタ・バブル(好みの情報にしか触れられなくなる)が生じる。
- 個別性と社会性のトレードオフになる。
- FAT(Fairness, Accoutability, and Transparency:公平性・説明責任・透明性)という研究領域やコミュニティがある。
✅ Adversarial Example(Adversarial attacks) (参考)
- ディープラーニングにおける重要な課題の一つ。
- 分類器に対する脆弱性攻撃のようなもの。
- 学習済みのディープニューラルネットモデルを欺くように人工的に作られたサンプルで、人の目には判別できない程度のノイズを加えることで作為的に分類器の判断を誤らせる。
- 絶対的に安全な技術はないことを認識しておくこと。
✅ クライシス・マネジメント(危機管理)
- 火消し(危機を最小限に抑える)、復旧(再発防止)が主眼。
- エスカレーションの仕組みづくりが重要。防災訓練を行うこと。
- 危機管理マニュアルの有効性を検証する。
✅ 透明性レポート
- プライバシーヤセキュリティについては、積極的に社会と対話する必要がある。
- いくつかの個別企業では透明性レポートを公開している。
✅ 指針作り
- Google
- AI技術開発の原則を公開、「AI at Google: our principles」。
- Partnership on AI(PAI)
- アシロマAI原則
- 2017年2月、世界中のAI研究者らが集まり発表。
- AIの短期的、長期的な課題について公開。
- 「AIによる軍拡競争は避けるべきである」ことが明示された。
その他
✅ 日本
✓ 新産業構造ビジョン
✓ 「人間中心のAI社会原則」及び「AI戦略2019(有識者提案)」
✅ 中国
✓ 中国製造2025
- 2025年までの中国製造業発展のロードマップ。
- AI技術に関する取組み強化が明言されている。
- ドイツのインダストリー4.0の影響を受けて作成されたと言われている。
✓ インターネットプラスAI3年行動実施方案
- 2016年、人工知能産業の促進に向けてインターネットプラスAI3年行動実施方案が発表された。
- AI技術を重点領域で活用することで世界に通用するトップ企業を育成することを目的としている。
✅ 英国
✓ RAS2020戦略
- 2015年3月、政府はロボット工学・自律システム(RAS)分野の発展を支援すると表明。
✅ ドイツ
✓ デジタル戦略2025(参考)
- 2017年3月、ツィプリス大臣は連邦政府が2016年3月に策定した「デジタル戦略2025」を発表。
- 2025年までにドイツがいかにしてデジタル化を具体化していくか取り組むべき10の施策について提案している。
✅ Coursera
- 🎩 アンドリュー・ング(Andrew Ng) による。(「GoogleBrain」にも携わり、Baidu研究所に勤務する)
- 初級から上級までAIに関する講義が行われている。

{kind=link}
{kind=link}
{kind=link}
{kind=link}