From r/WSB to Numerai Signals
Using r/WallStreetBets data for Numerai Signals submisison.
I stumbled upon Arjun Rohlfing-Das ‘s excellent post on Sentiment Analysis for Trading with Reddit Text Data that uses r/wallstreetbets data for sentiment analysis which seems to be holding predictive power.
Just give me the code
This notebook is built upon the work of Arjun Rohlfing-Das’s notebook. It predicts for entire market. I have modified it to work with all listed symbols.
This is a ‘Run All’ notebook. Once you have setup the PRAW credentials, all you have to do is, just click Run all from colab and it will grenerate a .csv that you can submit to the tournament.
Since, sentiments are quantified using ML models, what about using this as a feature for Numerai Signal’s tournament. This can be combined with a strategy you are currently using or submit these scores directly as I did.
Workflow
- Symbols in the Signal universe
- Collect Reddit data using PRAW
- Symbol filtering
- To the moon? (Sentiment analysis)
- Rolling average of daily scores for top 400 extreme symbols
- Submit
Symbols in the Signals universe
Latest tickers(Symbols) in the universe can be downloaded using NumerAPI with Bloomberg to Yahoo mapping.
Collecting Reddit data using PRAW
You’ll need to setup credentials for PRAW. Check this article on Scrapping Reddit data. “Daily Discussion” data is scrapped with all comments. You can filter the comments by the number of up votes it has as not every comment will be useful.
Symbol filtering
If you explore r/WSB and look at the symbols, you’ll find some ambiguity in the way stocks are mentioned. Terminology is different so I decided to split the symbols by space. i.e, TSLA US -> TSLA and only consider new symbols with length ≥2 .
Another criteria for filtering symbols is stopwords. You might want to use appropriate stopwords that reddit users use which are also in the symbol list. This gives false impression of stock being discussed.
The symbols with only numbers are also removed because they may create ambiguity.
To the moon?
- Score all comments for a day based on sentiment
I have used VADER sentiment analysis model from NLTK. A better model can be used. Or, You can take historical Signals targets and historical comments data and train a simple classification model on that. So, It is trained on reddit data optimized for Signal’s targets.
2. Log all tickers mentioned in those comments
3. Assign the daily sentiment to tickers involved
Finding extreme stocks and scoring
Not all of 5k stocks will be discussed there. Here, the stocks having most positive and most negative sentiments across all the days are selected.
A rolling window of 14 days is applied and the scores for last day and will be used for submission.
Submission
Since the submission need tickers in the Bloomberg format, we need to re-map the filtered tickers back to original Bloomberg tickers. This may cause a hash collision so I have used the first occurrence of Bloomberg ticker to be used.
As usual, this is a Run all Colab notebook once you setup PRAW. This will create accept-worthy submissions.
What’s next
- Try different model
- Better cleaning of comments (use upvotes)
- Combine the daily sentiment scores with your current Numerai strategy.
- Predict for weeks in the validation data to see diagnostics.
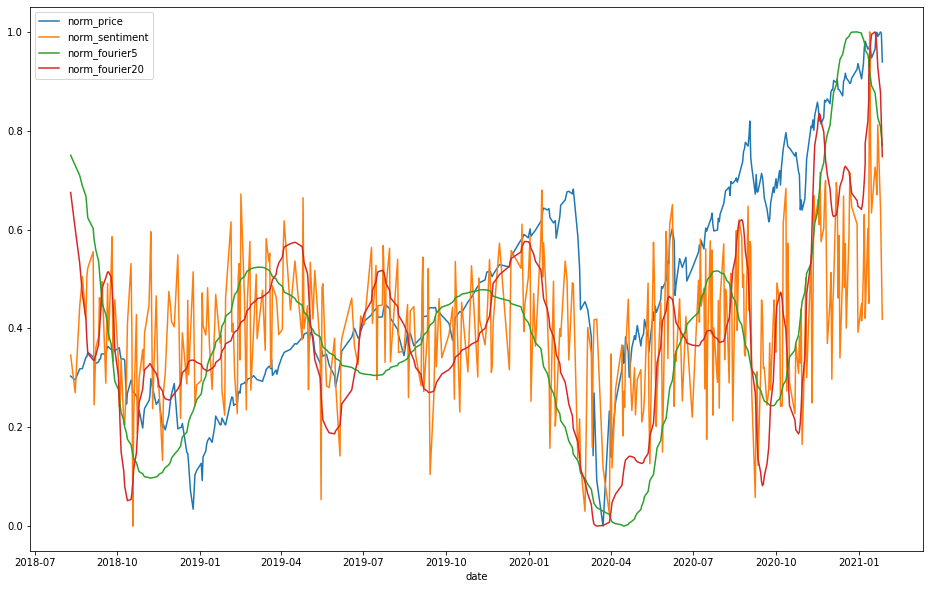
Below is a plot of Fourier transform of market sentiment vs. SPY ticker. This shows, there is some predictive power in the r/WSB.