You have 2 free member-only stories left this month.
Comparison of AWS EC2, RDS, and Aurora for Database Solutions
When companies move their infrastructure from on-premise data centers to the clouds — AWS, Google Cloud Platform (GCP), Microsoft Azure, etc., it has to decide whether to use a database service or to set up the database on virtual machines. Specifically to AWS, one of the three options — EC2, RDS and Aurora have to be chosen based on the requirements of the specific company.
If you are interested in Google Cloud, please check my other comparison article of CloudSQL and Compute Engine (VMs).
A detailed comparison of EC2, RDS and Aurora for db solutions will be described first, and the general suggestions for making the choice between these three will be proposed in the end.
The background is that we need a database server with 16 CPU cores,128 GB memory and 2TB database size and a proper failover solution. The table below lists the comparison results of EC2, RDS and Aurora in 7 aspects based on our database requirements.
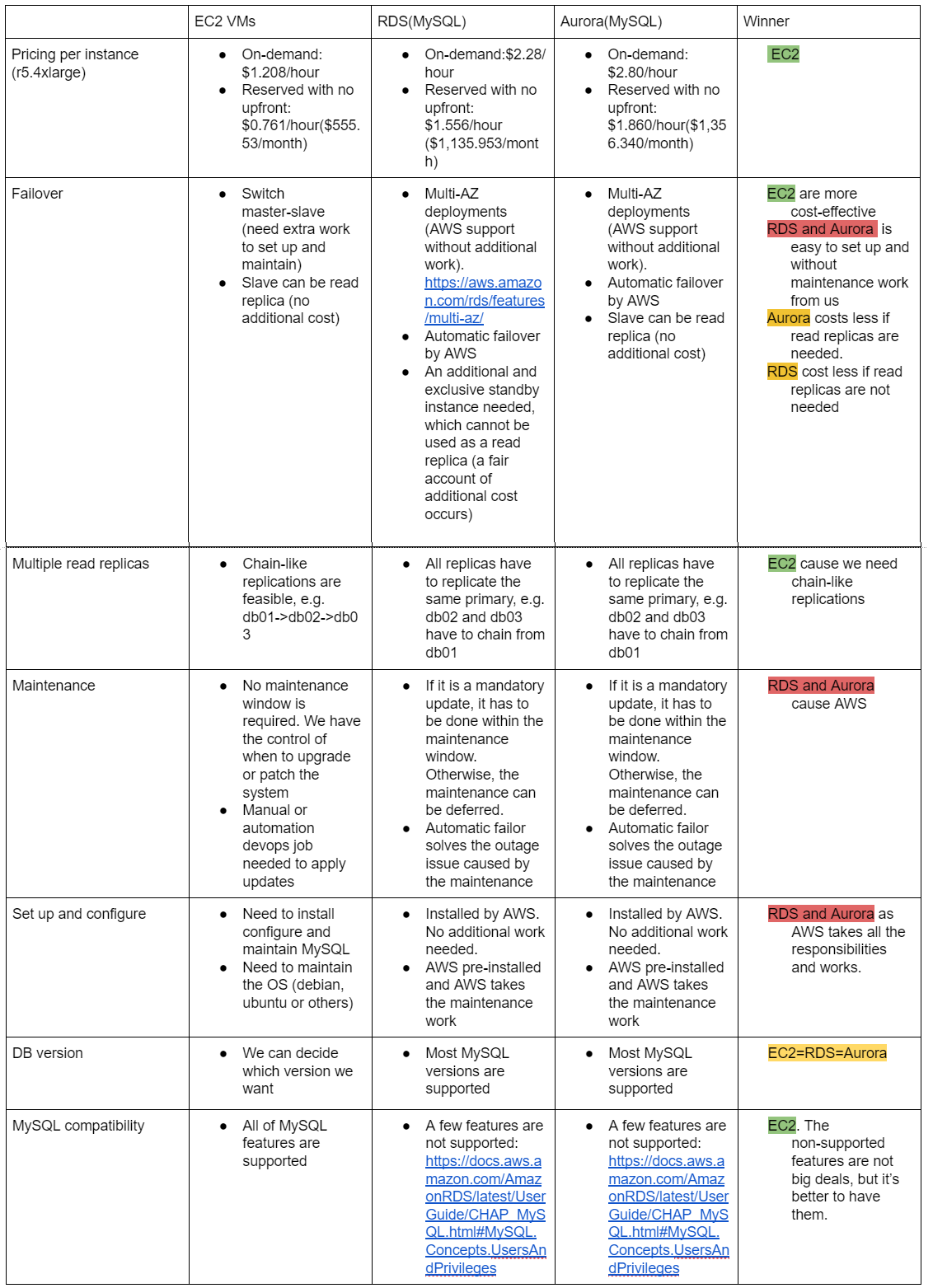
There are several advantages of using EC2 instances. First of all, EC2 instances are more cost-effective. From the row ‘Pricing per instance’ in the table, the per-instance cost of RDS is twice as the EC2 instances, and the cost of Aurora is approximately 23% more than RDS. From the row ‘Failover’, if we want to set up the failover and a read replication, we will need two additional instances for RDS, but we will only need one additional instance for the EC2 or Aurora solution because the read replica can be used as a fail-over. In total, the EC2 or Aurora solution could save ⅓ of the db instances. In addition, we will gain more flexibility with EC2 instances. From the row ‘Multiple read replicas’, RDS or Aurora does not support chain-like structure and the replica can not be used as a master/primary database. While, for EC2, we can decide the replication structure as what we want. Since the current state of dbs are chain-like replications, if we want to use RDS or Aurora, we will need to make some changes. From the rows ‘MySQL compatibility’, EC2 instances support all the features of MySQL. While for RDS or Aurora, there are a few MySQL features that are not supported, but we are not using these features, so it doesn’t affect our decision. However, these features may matter for other projects, so when making a choice among EC2, Aurora and RDS, this must be considered.
There is only one major disadvantage of EC2 solution, which is that we will have to take the work to set up and maintain the database. From the rows ‘Fail-over’, ‘Maintenance’ and ‘Set up and configure’, for EC2, the OS, MySQL and fail-over are set up by AWS which saves our time and work. But for EC2 solution, we will have to set it up by ourselves. Since we’ve been doing the similar works of setting up and maintaining MySQL for quite a while, we should be able to set it up properly in EC2.
Suggestions for making the decision would be as follows. Considering the cost, if the database is only for a small project, as the resources including CPUs and memory would be very small, the cost difference between RDS/Aurora and the EC2 solution would not be as significant as big project. Aurora would be recommended rather than RDS because Aurora can fail over to the read replica without needing an additional stand-by instance. Otherwise, the EC2 solution should be the first choice. With regard to the operational work, if the team has the expertise of setting up database and the saved cost of the EC2 solution is worth the time spent on setting up and maintaining the database, the EC2 solution should be the preferred. Otherwise, Aurora should be considered because without any expertise, the database and its fail-over and replicas are ready on AWS.