

はじめに
「メルアイコン」と呼ばれる、Melvilleさんの描くアイコンはその独特な作風から大勢から人気を集めています。

上はMelvilleさんのアイコンです。
特にこの方へアイコンの作成を依頼し、それをtwitterアイコンとしている人がとても多いことで知られています。
代表的なメルアイコンの例



(左から順にゆかたゆさん、みなぎさん、しゅんしゅんさんのものです (2020/12/1現在))
自分もこんな感じのメルアイコンが欲しい!!!!!!ということで機械学習でメルアイコン生成器を実装しました!!!!!.......というのが前回の大まかなあらすじです。
今回は別の手法を使って、キャラの画像をメルアイコンに変換するモデルを実装しました。例えばこんな感じで変換できます。

本記事ではこれに用いた手法を紹介していきます。
GANとは
画像の変換にあたってはUGATITという手法を使っています。これはGAN(Generative adversarial networks、敵対的生成ネットワーク)という手法をベースにしたもので、GANは以下のような構成をとっています。
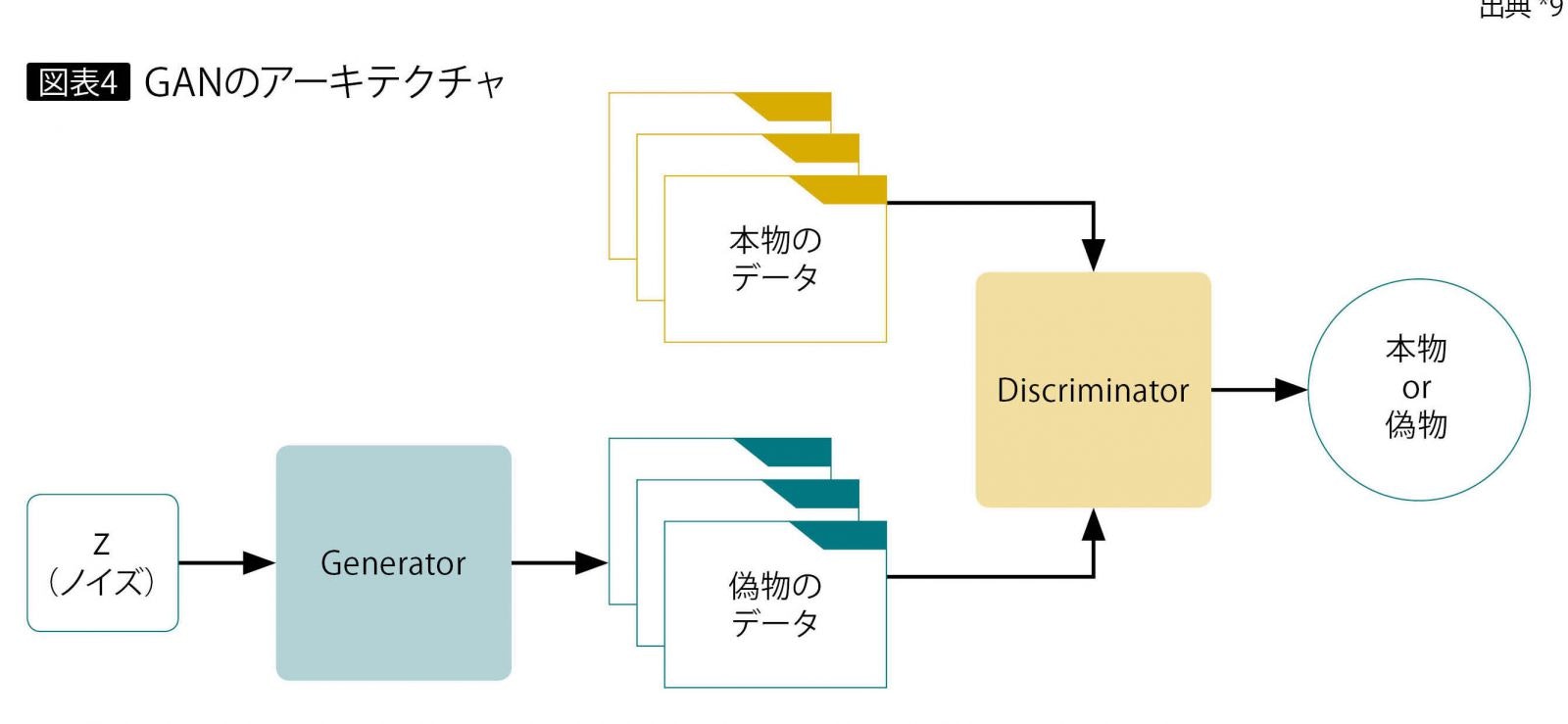
この手法では、画像を生成するニューラルネットワーク(Generator)と、画像を識別するニューラルネットワーク(Discriminator)の2つを組み合わせます。
Generatorは画像を生成し(偽画像と呼ぶことにします)、それによってDiscriminatorに本物画像だと誤認させることを目指して学習を進めます。一方でDiscriminatorはGeneratorに騙されないよう、より正確に画像を識別しようと学習します。
二つのニューラルネットワークがお互いに鍛え合うことで、Generatorは学習データに近い画像を生成できるようになっていく、というわけです。
要するにGenerator VS Discriminatorです。
UGATIT
今回、キャラの画像⇄メルアイコンの変換にはUGATITというものを用いました。
これはGenerator VS Discriminatorによって学習を進めていくGANを基とした方式で、大まかな全体図は以下の図のようになっています。
UGATITではGeneratorを2種類、Discriminatorを2種類用います。
まず「GeneratorA2B」を用意します。これはドメインA(図ではキャラの画像)に属する画像を入力に取り、ドメインB(図ではメルアイコン)に属する画像に変換するGeneratorです。またそれとは別に、「DiscriminatorB」を作ります。これは入力されたメルアイコンが本物なのか偽物なのかを識別します。
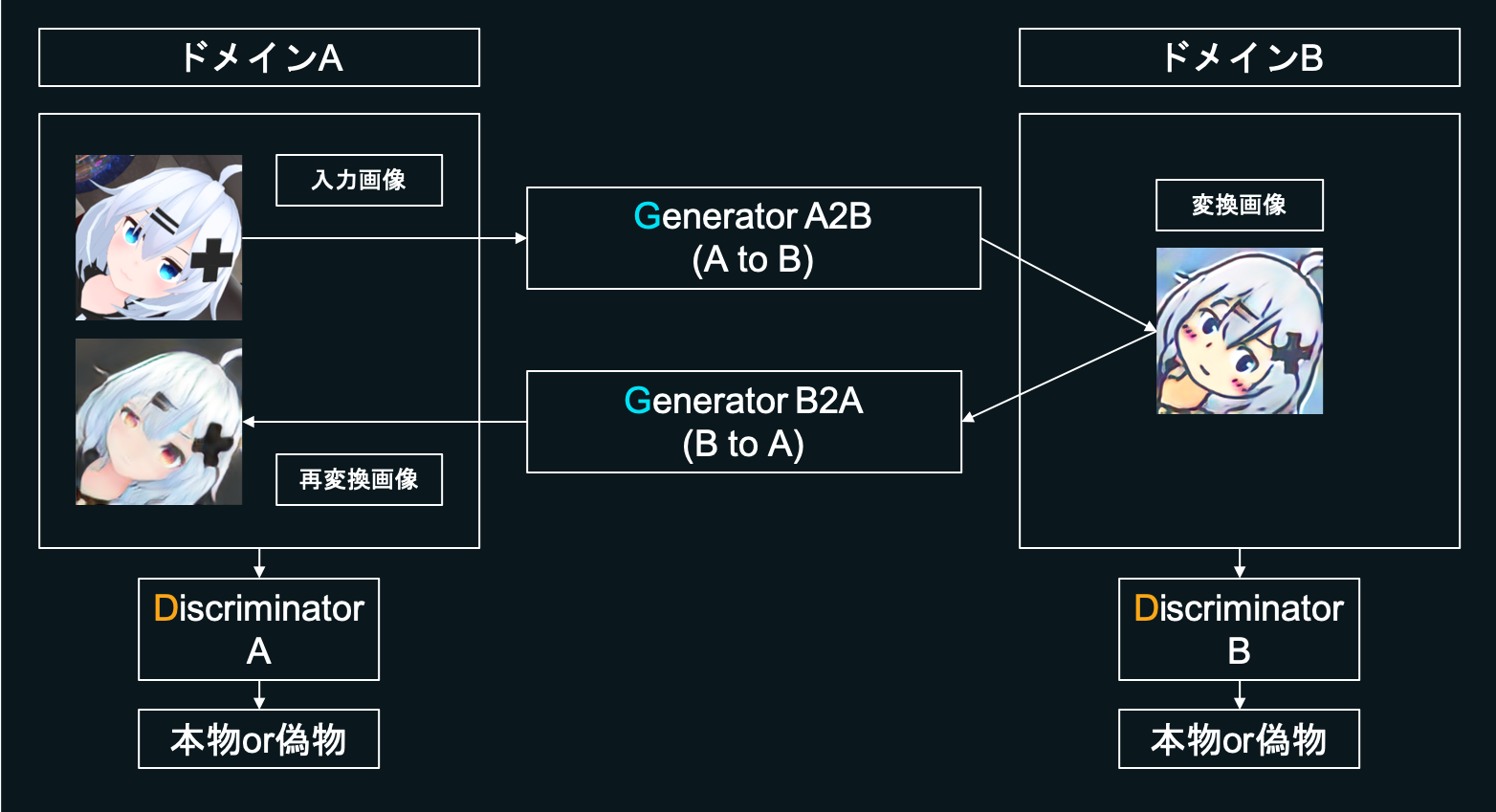
「ドメインA→ドメインB」の学習
DiscriminatorBは、本物のメルアイコンもしくはGeneratorA2Bによって生成された偽物のメルアイコンを入力に取り、それらが本物か偽物かを正しく識別できるように学習します。一方、GeneratorA2Bはキャラの画像を入力に取り、それを元に画像を生成し、DiscriminatorBを本物だと騙せるよう学習します。GeneratorA2BとDiscriminatorBが相互に鍛え合うことで、GeneratorA2Bはメルアイコンっぽい画像を生成できるようになっていきます。「ドメインA→ドメインB→ドメインA」の学習
さらにこれだけではなく、逆にドメインBをAに変換する「GeneratorB2A」と、ドメインAに属する画像を識別する「DiscriminatorA」を準備します。
先ほどGeneratorA2Bによって出力されたメルアイコンをGeneratorB2Aに入力します。つまり「ドメインA→ドメインB→ドメインA」という変換を施します。Discriminatorを騙すだけでなく、変換前のドメインAと、2回変換されて出てきたドメインAの画像が一致するようにも目指し学習を進めます。こうすることで生成結果に多様性を持たせ、モード崩壊の問題を軽減します。
また、「ドメインA→ドメインB」と「ドメインA→ドメインB→ドメインA」に関して説明しましたが、AとB逆バージョン「ドメインB→ドメインA」と「ドメインB→ドメインA→ドメインB」についても同様の学習を進めます。
データセットの用意
Generatorがキャラの画像→メルアイコンの変換ができるようになったり、Discriminatorが画像を本物か偽物か識別できるようになったりするためには、すでに存在するキャラの画像やメルアイコンをできるだけ大量に持ってきてデータセットを作り、これを学習に用いる必要があります。
キャラの画像の用意
まずキャラの画像を集めます。
lbpcascade_animefaceという画像内からキャラの顔を抽出してくれるソースコードがgithubにあったのでこれを使います。これを実行すると例えば下の画像のように、キャラの画像を入力に取り、顔の部分を赤く囲ったものを出力できます。

このソースコードを改造してgoogle画像検索やtwitterのメディア欄からキャラの画像を自動抽出、45°傾けて保存しまくるものを作りました。退屈なことはpythonにやらせましょう。

これを使って約900枚ほどの、45°傾いたキャラの顔の画像が集まりました。これらをデータセットに用います。
メルアイコンの用意
メルアイコン側のデータセットに関しては、Melvilleさんから頂いた約640枚の本家メルアイコンを使います。また、メルアイコン生成器 version2から約260枚ほど生成しこれらも一緒に使います。

例えばこんな感じの画像を生成しておきます。
これら合計で900枚ほどのメルアイコンをデータセットに用います。
Discriminatorの作成
Discriminatorの役割は、入力された画像が本物のメルアイコンなのか、Generatorによって作成された偽画像なのかを判定することです。Generatorに騙されないように精度を上げていくことを目標に学習します。
Discriminatorは、おおざっぱには下の図のような構成になっています。
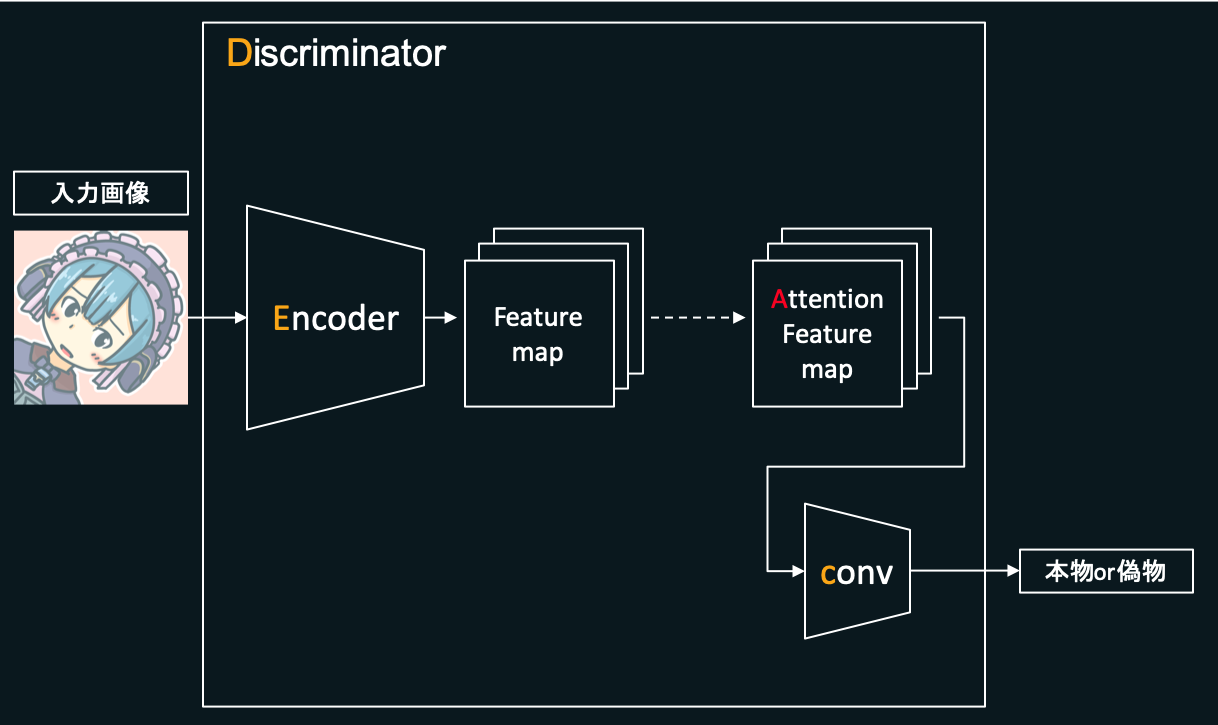
最初に入力された、本物または偽物のメルアイコン(チャネル数3(RGBの3つ)、縦横256×256pixelの画像)をEncoderと呼ばれる箇所に入力します。Encoder内では畳み込みを数回行うことでFeature mapを出力します。メルアイコンをメルアイコンたらしめている特徴を、入力画像から抽出し出力しているようなイメージです。
次にこのFeature mapを、後述するCAMという機能を用いてAttention Feature mapというものに変換します。メルアイコンの数ある特徴のうち、どういった特徴を集中的に見ると良いかという情報を付加しているようなイメージです。
このAttention Feature mapを次の層に渡し、さらに数回畳み込みを繰り返します(図の「conv」)。最終的に、入力された画像がどれだけ本物のメルアイコンっぽいかを表す値(本物っぽいほど大きな値になるよう学習します)を出力します。
CAMとは
CAM(Class Activation Map)とは、画像を識別するニューラルネットが、どのようにしてそう識別したかという情報を可視化する機能です。
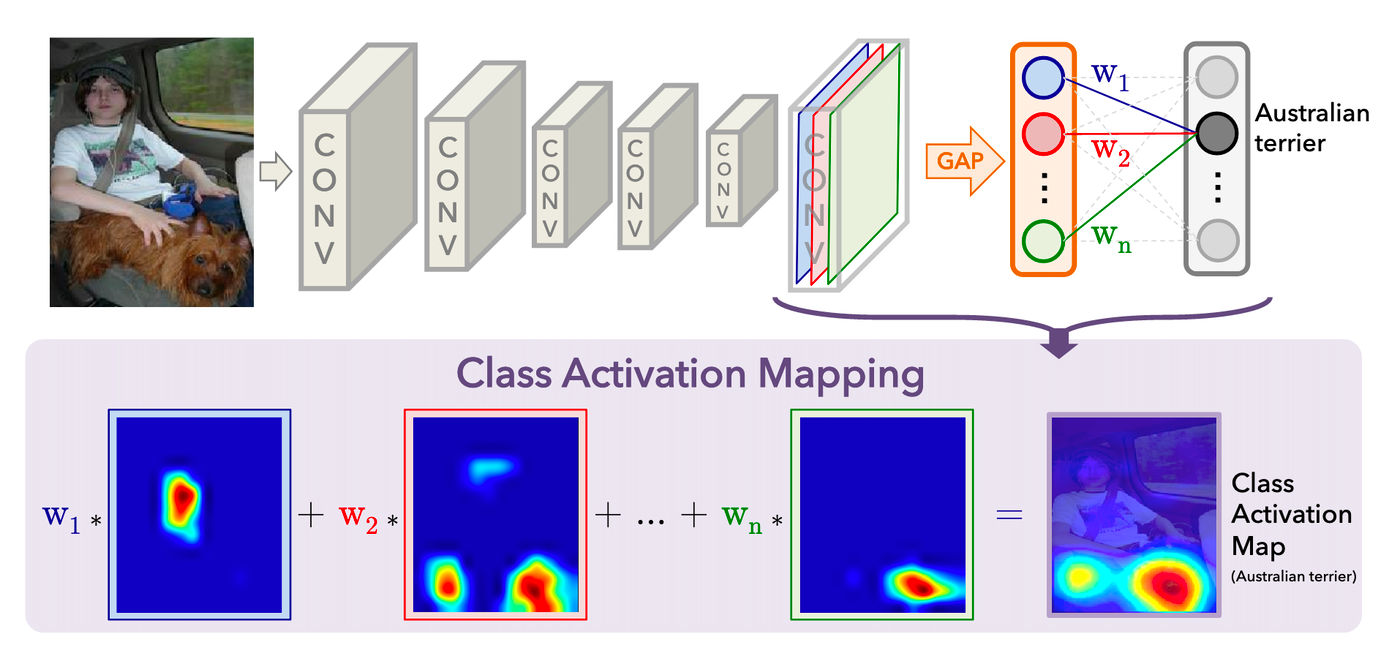
図の引用元
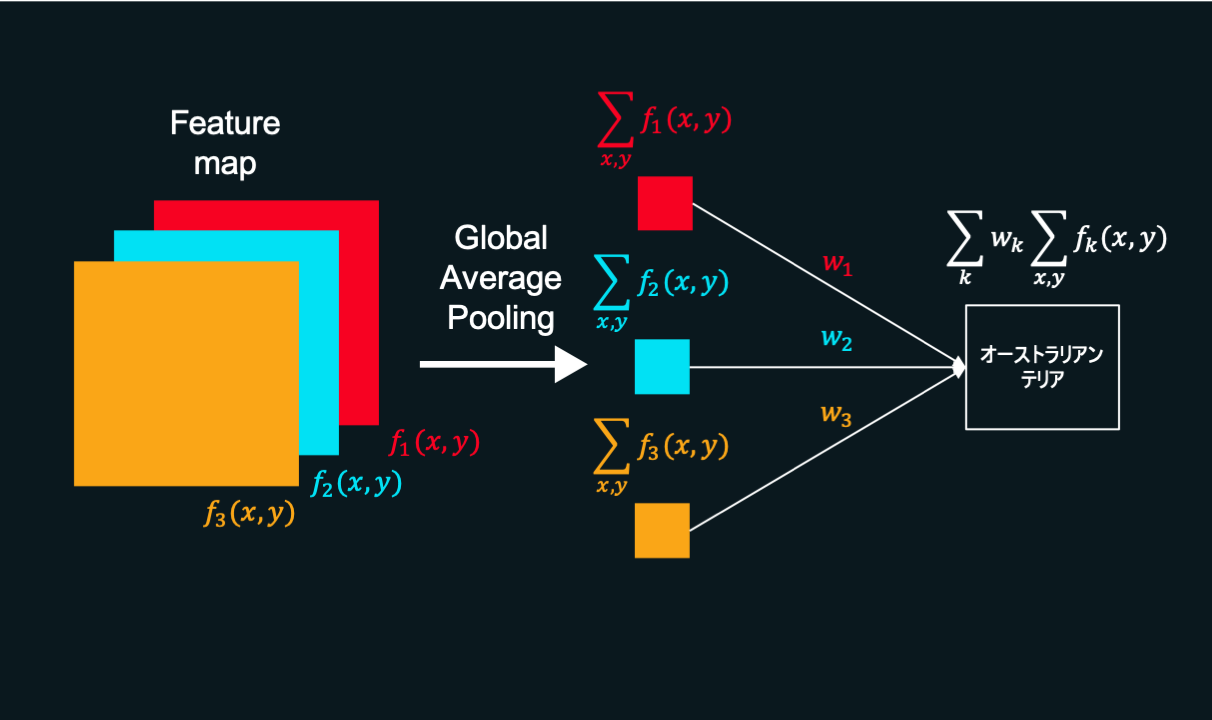
例えば上の画像では、ニューラルネットが犬を膝にのせた人間の画像を入力にとり、その画像がAustralian terrier(オーストラリアン・テリアという犬種)だと判定しています。
CAMを用いるとニューラルネットでただ画像を判定するだけでなく、判断に用いた根拠を可視化できるようになります。その結果が上の図の一番右下の「ヒートマップ」と呼ばれるものです。
この例では犬の顔を一番重要な判断材料、胴体を次に重要な判断材料としていることがわかります。
このヒートマップをメルアイコン変換器のDiscriminatorに用いることで、偽物か本物かをただ判断するだけでなく、画像のどこに注意を向けて判定すべきかという情報も一緒に学習できるようにします。
ヒートマップの計算方法
ではヒートマップは具体的にどうやって作成するのでしょうか。
上の図のニューラルネットの、最後のこの部分を見てみます。
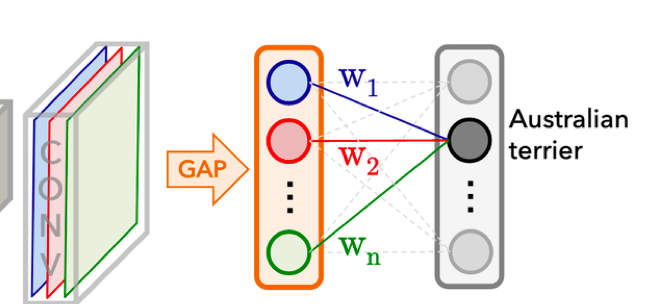
畳み込みを繰り返すことによって数枚のFeature mapを得て、その1つ1つに対しGAP(Global Average Pooling、縦横全ピクセルに対して平均値を求める操作)を施します。さらに得られた値を全結合層に入力し、各クラスについて具体的なスコアを得ます。例えばオーストラリアン・テリアというクラスのスコアが一番高ければ最終的な判断結果はオーストラリアン・テリアとします。
この操作を式に起こしてみます。

上の図の一番左側のようにcチャネル分Feature mapがあります(図の例ではc=3)。この各Feature mapをと表現することにします。例えば2枚目のFeature mapの(33,4)ピクセル目に位置する値はと表せます。
このc個のFeature mapについて、各々に対し平均をとりを得ます。
さらに、得られたc個の平均値を全結合層に入力し最終的なスコアを得ます。
ここで、得られたスコアはの位置を入れ替えることで
のように式変形できます。
こののうち、について足し合わせる前の値
に注目します。
各が、各々の特徴マップに対応する重みをつけることによってスコアを算出していると分かります。つまり、を見ればどの特徴に注意を向けた結果オーストラリアン・テリアのスコアが高くなったのかが分かるということになります。
さらに、について足し合わせる前の値であるため、位置の情報が残っています。つまり、どの特徴に注意を向けたかという情報だけでなく、具体的に画像のどの位置に注意を向けたか、という情報まで保持していることになります。
このが目的のヒートマップです。まさに下の図の一番右下そのものというわけです。
CAMの導入
DiscriminatorにこのCAMの機能を導入することで、判定の際に画像のどこに注意を向けるべきかという情報を学習できるようにします。
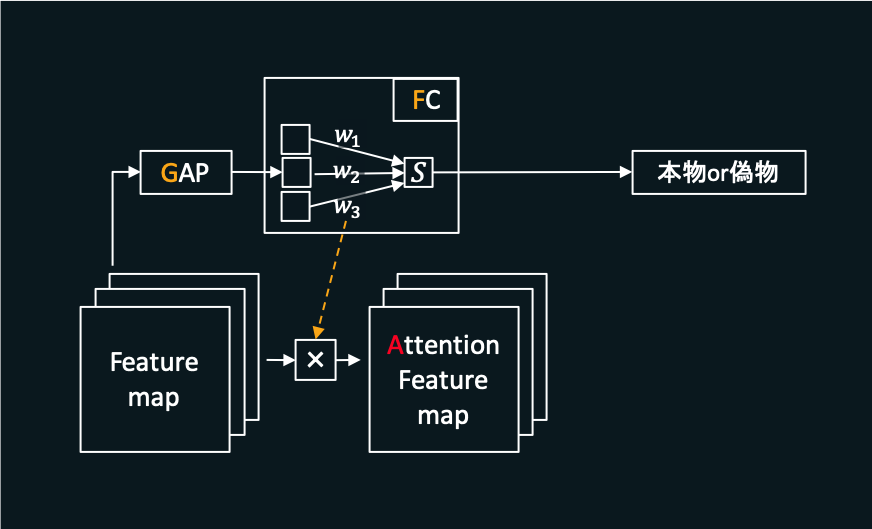
まずDecoderから出力されたFeature mapに対し、それぞれGAPをとります。さらにそれをFC(Full connection(全結合層))に入力し、どれだけ入力画像が本物に近いかを示す値(図の「本物or偽物」のところ)を得ます。入力画像が本物に近いほどこの値が大きくなるよう学習します。
学習の過程で、判断に重要となるFeature mapに対応するほど大きな値を持つようになり、反対に重要度の低いFeature mapに対応するほど小さな値を持つようになります。この各を用いてFeature mapに重み付けをすることでヒートマップ(図ではAttention Feature map)を計算します。
また、UGATITにおいてはCAMの計算途中でGAPを計算していますが、これに加えてGMP(Global Max Pooling)を使用するバージョンのCAMも一緒に使います。縦横全ピクセルに対して平均を計算するGAPに対し、GMPでは平均ではなく最大値を計算します。2種類のCAMを使用することで片方だけの場合と比べてより良い結果が期待できます。
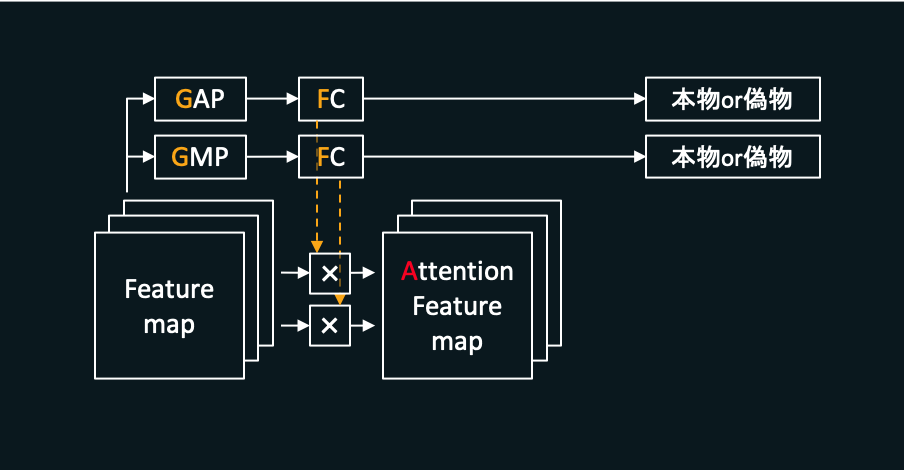
こうしてできあがったAttention Feature mapを次以降の畳み込み層へと渡し、最終的な判断結果を得ます。
Discriminatorの全体像
以上のようにしてDiscriminatorを構成します。全体像は以下のようになります。
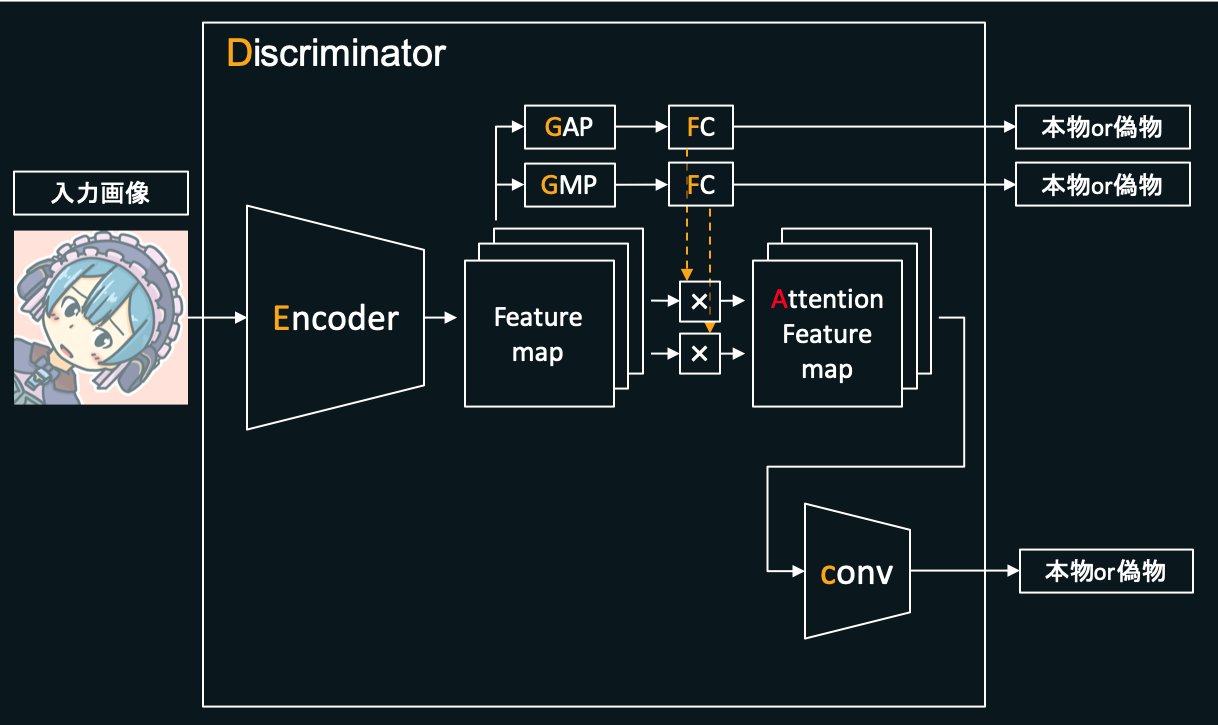
入力された画像がどれだけ本物のメルアイコンに近いかを示す値を合わせて3種類出力していますが、このうちCAMの機能によって出力される分(上の図の、上側の2つの「本物or偽物」)は判定において補助的な機能(Attention Feature mapの作成)を果たします。メインは下側の「本物or偽物」です。
また、メルアイコンを識別するDiscriminatorについて紹介しましたが、キャラの画像を識別するDiscriminatorも入力する画像の種類が違うだけで同様の構成をしています。
Generatorの作成
Generatorの役割は、入力されたキャラの画像(チャネル数3、縦横256×256pixel)をできるだけメルアイコンっぽく変換し、それを用いてDiscriminatorを本物のメルアイコンだと誤認させることです。うまく騙せるよう精度を上げることを目指して学習を進めます。
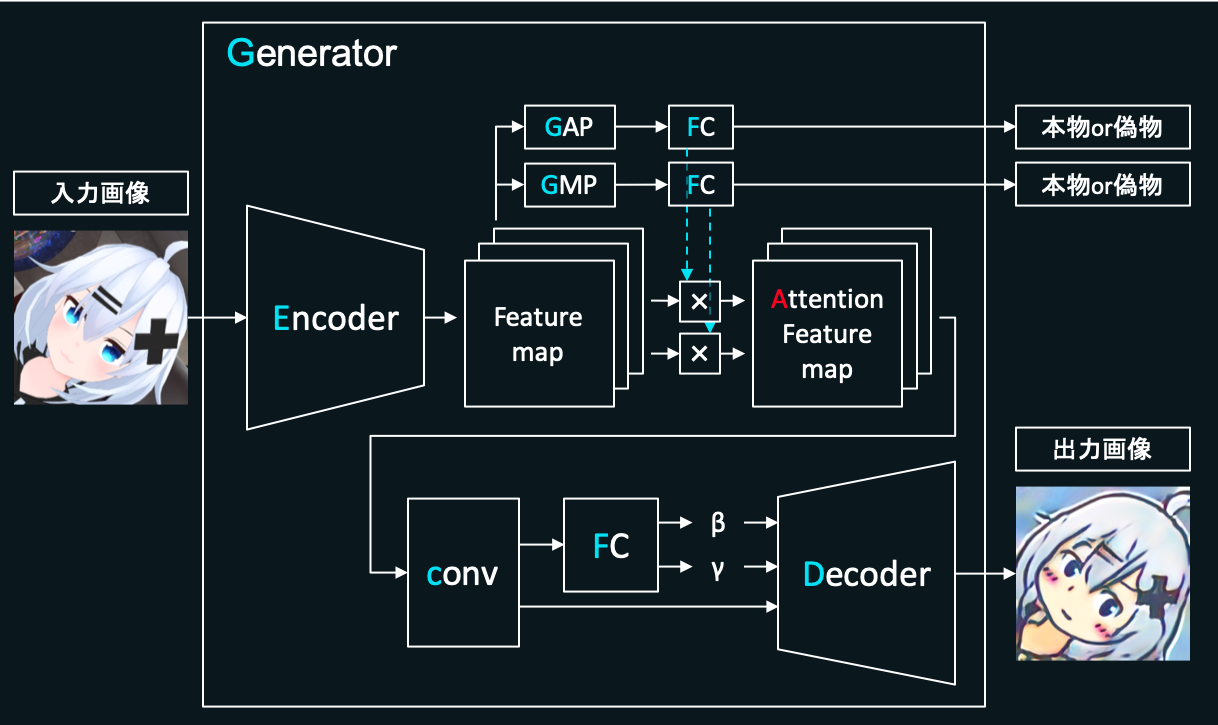
※Decoderの前にあるFC(全結合層),,については後述します。
入力画像をAttention Feature mapに変換するところまではDiscriminatorと似ています。Generatorにおいて、CAMの仕組みは「キャラの画像とメルアイコン両者において、明確に違うのはどういった特徴か」を学習するのに役立ちます。とてもアバウトなイメージですが、例えばGeneratorが「もしかしたら目のパーツが両者において明確に違うのでは?」ということを学習したとすると、入力画像に対してそこを重点的に変換することでよりDiscriminatorを騙しやすい画像を作成できます。
Attention Feature mapに対し畳み込みを実行し、さらにそれをDecoderと呼ばれる箇所に入力します。この部位で畳み込みとUpsamplingを繰り返し、最終的にチャネル数3、縦横256×256pixelの画像を生成します。
また、このDecoder内ではAdaILNという正規化をします。
AdaILN
ニューラルネットにおいて、畳み込みなどをするたびに「正規化」という操作を施すことがよくあります。
層と層の中間を流れるデータに対して正規化をかけると平均と分散を揃えることができ、学習の効率を改善できます。
正規化にはいろいろな種類がありますが、Generator内のDecoderにおいてはAdaILNという正規化を実行します。
これはやってきたデータに対し、Instance Normalizationをかけたものと、Layer Normalizationをかけたものの2つを比率で混ぜ合わせる正規化の手法です。は0以上1以下のパラメーターとし、AdaILN内で学習によって決定します。
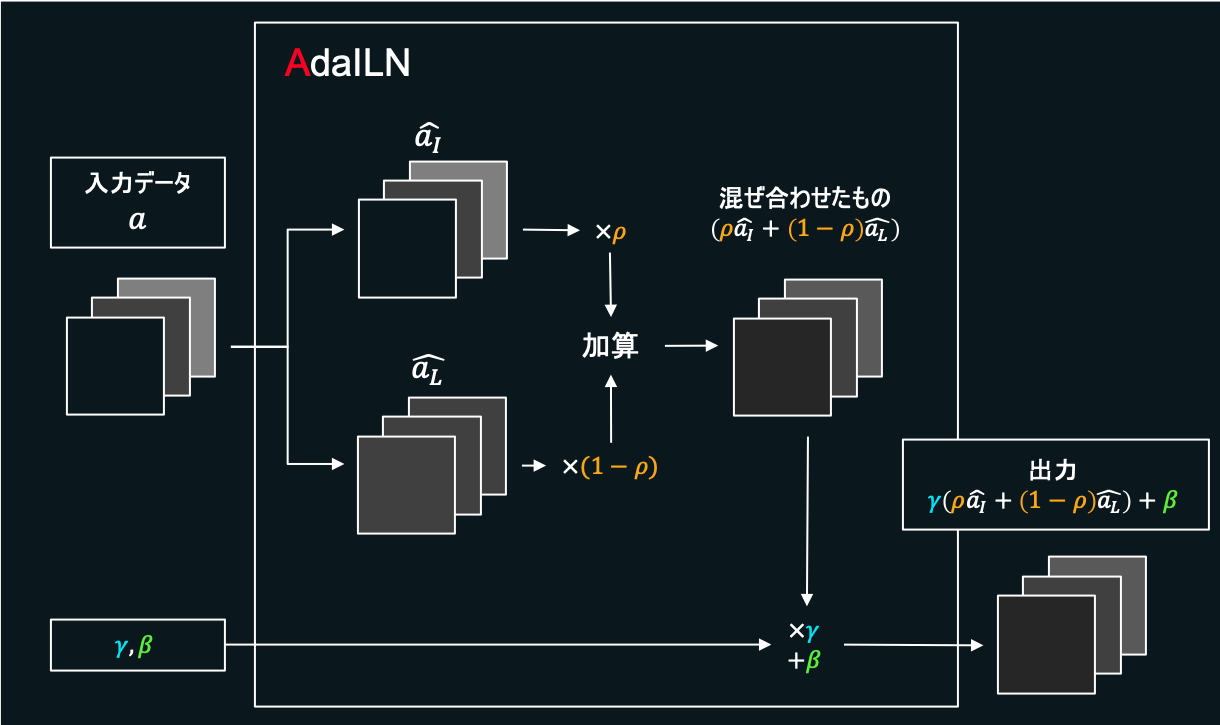
※,については後述します。
Instance Normalizationは各チャネルごとに正規化をかけるというもので、(各特徴ごとに正規化をかけているようなイメージ)、入力データの細かな特徴を保持するのが得意です。しかし、画像全体にまたがる大局的な特徴を捉えるのは不得意です。
一方反対に、Layer Normalizationはやってきたデータ全部に対し一度に正規化をかける手法で、大局的な特徴を捉えるのは得意ですが局所的な特徴が失われやすいという欠点を持ちます。
このようにInstance NormalizationとLayer Normalizationはこの点では正反対の特徴を持っています。
この2つを最適な比率で混ぜ合わせることで、双方の良いとこ取りを目指し、さらなる変換精度の向上を狙います。
Generatorの全体像
このAdaILNをDecoderへと導入します。
Generator内のCAMによって出力されたAttention Feature mapに対し畳み込みを実行し、さらにこれをFC(全結合層)へと入力し,を得ます。これをDecoder内のAdaILNに入力します。
また、上では「キャラの画像→メルアイコン」の変換を実行するGeneratorについて紹介しましたが、逆の「メルアイコン→キャラの画像」を行うGeneratorに関しても全く同様の構成です。入力する画像の種類と出力する画像の種類がそれぞれ逆なだけです。
学習方法・誤差関数
UGATITでは次に解説する4種類の誤差関数を用います。
Adversarial loss
Cycle loss
Identity loss
CAM loss
ただし変換元ドメインの画像の集合を(source),変換先ドメインの画像の集合を(target)とします。はミニバッチごとに平均をとる操作です。
これらについて順番に解説していきます。以下では変換元ドメイン(source)をキャラの画像、変換先ドメイン(target)をメルアイコンとして説明しますが、変換元と変換先逆バージョンについても同様のことをします。
Adversarial loss
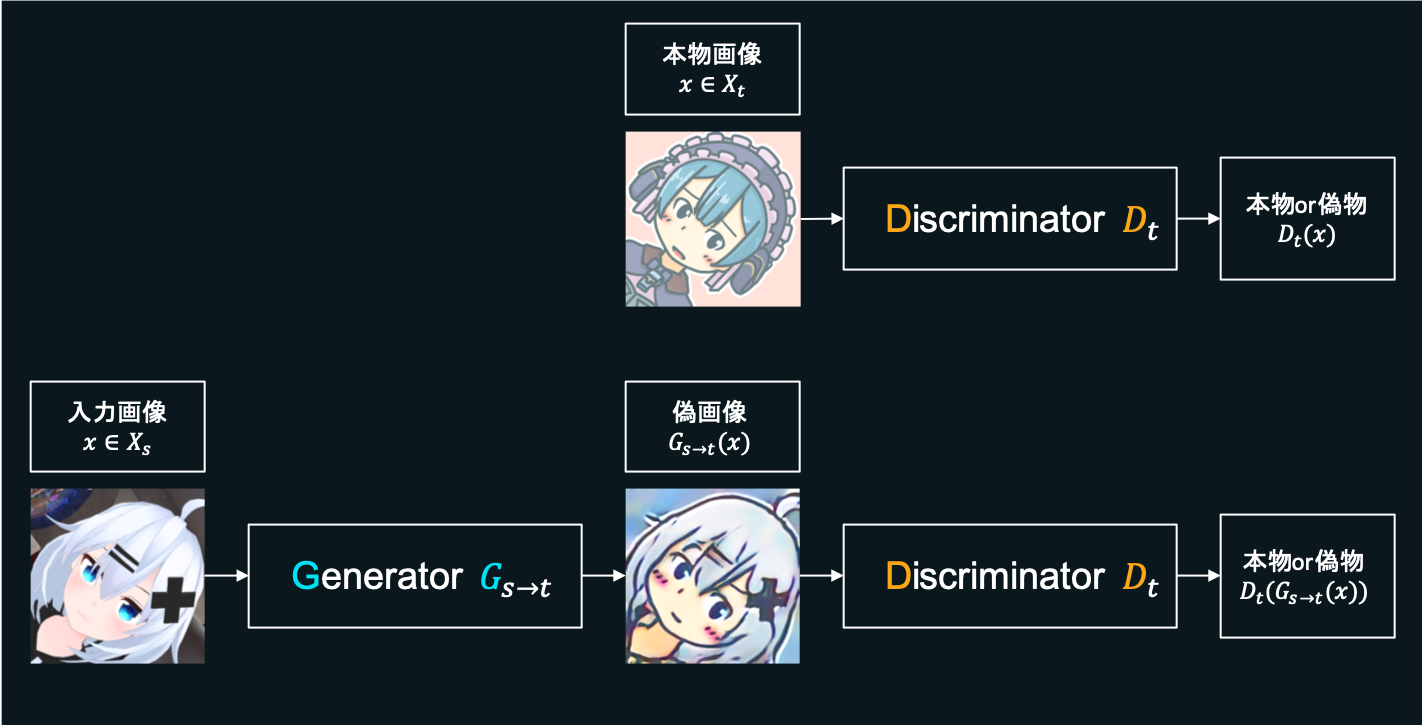
DiscriminatorはこのAdversarial lossを最大化するよう目指すことで、本物のメルアイコンほど1に近い値を出力し、Generatorによって生成された偽のメルアイコンほど0に近い値を出力できるよう学習します。Generatorに騙されないよう精度をあげるよう学習を進めます。
一方でGeneratorはこれを最小化するよう目指し、生成したメルアイコンでDiscriminatorを本物だと騙せるよう学習します。
Cycle loss
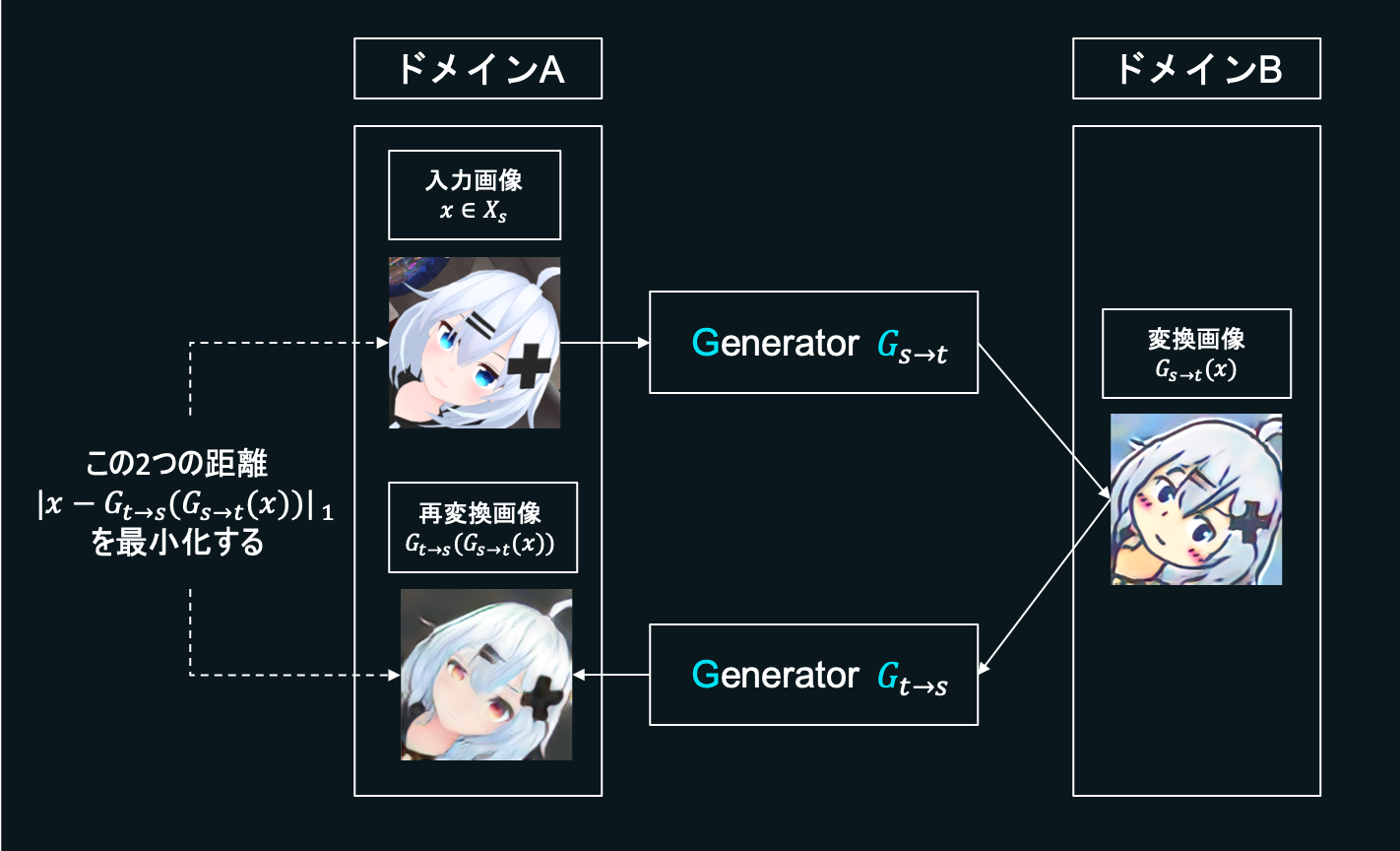
Cycle lossは「キャラの画像→メルアイコン→キャラの画像」と2回変換をかけたときに、ちゃんと元の画像に戻ってこれるようにするための項です。元のキャラの画像と、2回変換をかけたあとのキャラの画像のL1ノルムを最小化するよう目指すことでモード崩壊の問題を軽減します。
Identity loss

変換先ドメインに属する画像をGeneratorに入力、出力画像との距離を最小化します。(図のように、変換先ドメインに属する画像をGeneratorに入力した時、入力と出力が一致するのを目指す)
UGATITの論文中ではGeneratorはこの項を最小化することによって、入力画像と出力画像の色分布を似たものにできると言及されています。
自分的な解釈ですがおそらく「キャラの画像→メルアイコン」で、入力と出力を似たような画像にするための項です。
CAM loss
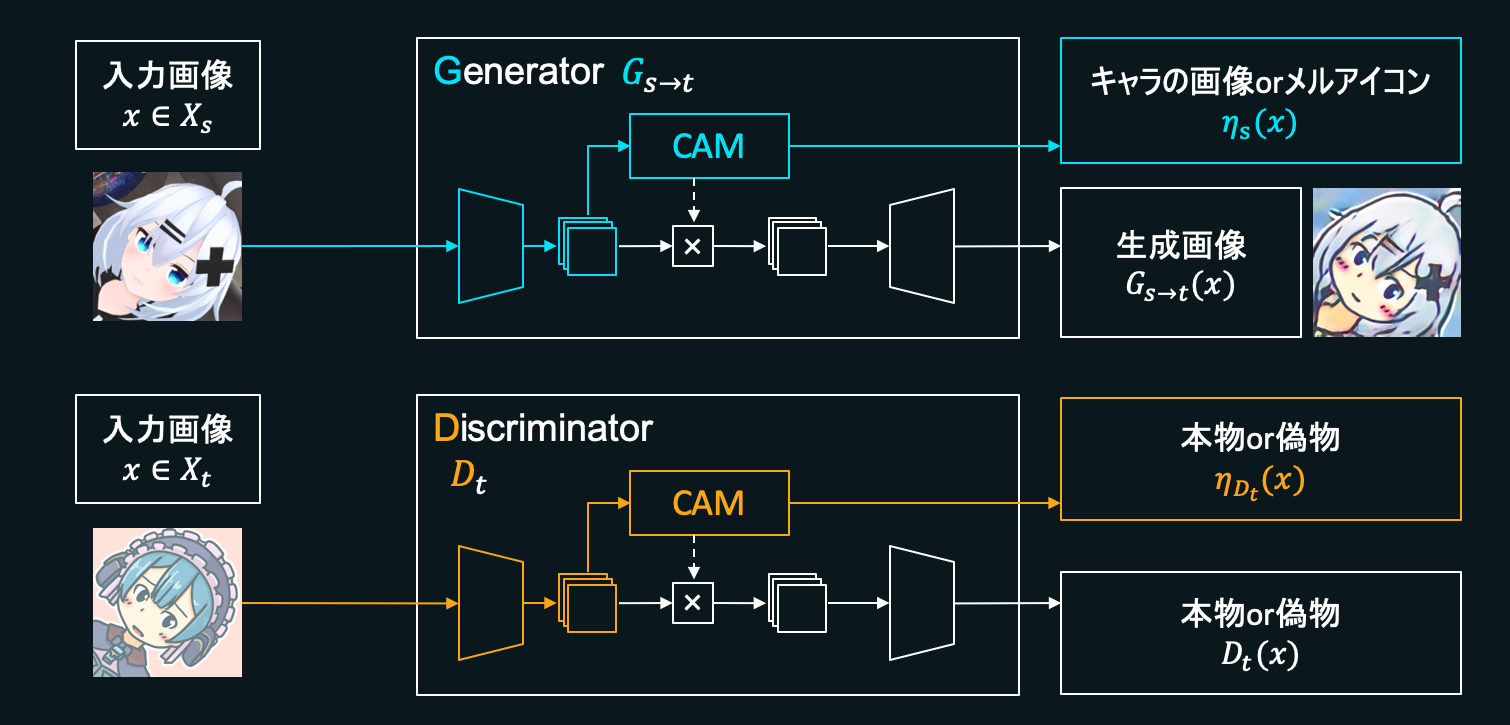
この項によって、先ほど解説したCAMの部分が画像を正しく分類できるようになるのを目指し、CAMでうまくヒートマップを作れるようにします。
誤差関数の全体像
以上で紹介した,,,を用いて、誤差関数は全体では以下のように表せます。
ただしで、他の項(,,)も似たように定義します。係数はそれぞれ,,,です。
学習方法
ミニバッチサイズは1とし、epoch数は40としました。誤差伝搬の最適化手法にはAdamを使い、学習率0.0001、Adamの一次モーメントと二次モーメント(モーメント推定に使う指数減衰率)はそれぞれ0.5と0.999に設定しました。
また、ある程度学習が進んだ段階から学習率を徐々に下げる処理を入れています。こうすることで汎化性能の向上が狙えるようです。(参考)
全体像
上でも紹介した画像の再掲ですが、先ほど作成したGeneratorとDiscriminatorを組み合わせ、UGATITを構成します。
いざ生成
用意したデータセットを用いて学習を行い、Generatorで「キャラの画像→メルアイコン」の変換を実行します。

UGATITすげえ!!!!!!!!!!!!
かなりうまく変換できているのではないでしょうか!?個人的にはめちゃめちゃ感動しました。
学習途中における出力は下のようになりました。
epoch1

epoch8

epoch20

epoch30

epoch40(最終的な出力)





徐々に学習が進められているのがわかります。
まとめ
UGATITによってキャラの画像からメルアイコンを生成できるようになりました。
機械学習で画像変換をする手法はUGATIT以外にもpix2pix,CycleGAN,StarGAN,ACGANなど他にも様々なものがあり、新しい手法もどんどん開拓されています。皆さんも是非GANでガンガン画像変換しましょう。
ソースコード
書いたコードはこのリポジトリにあります。
https://github.com/zassou65535/image_converter
前作
参考
U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation
U-GAT-IT — Official PyTorch Implementation
2019年までのCAM(Class Activation Map)まとめ
【論文紹介】U-GAT-IT
lbpcascade_animeface
学習率減衰/バッチサイズ増大とEarlyStoppingの併用で汎化性能を上げる@tensorflow2.0

