

初投稿です
追記(20171031)
https://github.com/marcotcr/lime/commit/9a24c4487d71c3d0dbe3fcbaff5cae6e69411702
HTMLを出力する際のエンコードがasciiだったため日本語が文字化けしていましたが、UTF-8をサポートするようになったようです!
下記に文字化け対策の文章がありますが、読み飛ばしていただければ幸いです。
導入
セクシーなデータサイエンティストの皆様におかれましては、日々の業務で様々な機械学習のモデルを構築しておられるかと思います。それは例えば、あるサービスのユーザ情報を用いてコンバージョンするかしないかを予測していたり、またある時は年収を回帰で予測していたり、またあるときはユーザが投稿した画像情報についての二値分類やテキストデータについてのネガポジ分類をしていたりすることでしょう。
これらにつきものなのが、この予測モデルを実装する際の関係者への説明です。このモデルはどうしてこのような結果を出しているのか、なんでこのユーザは低い年収だと判定されているのか、この画像はどうして犬だと判定されているのか。説明する相手がこうした技術への興味が高いか低いかに関わらず、そもそもエラー分析を行う際などにこうしたモデルの解釈を行うことは必要不可欠です。えいやとデータを適当にxgboostに投げて、出来上がったモデルがAUC0.9超えたしまあいいかではないのです。これは自分への戒めでもありますが...
そんなモデルの解釈に役立つであろう技術を本記事では紹介いたします。
LIME: "Why Should I Trust You?": Explaining the Predictions of Any Classifier
https://arxiv.org/abs/1602.04938
KDD2016で採択されたこの論文では、LIME(Local Interpretable Model-agnostic Explainations)及びSP-LIMEという手法が提案されました。
前者はexplaining predictionを行うための技術です。explainig predictionというのはモデルがなぜそのような判断を下したのかを理解する、ことを指しており、本記事ではこのLIMEでどれくらいの解釈が可能になるのかを見ていくという感じです。
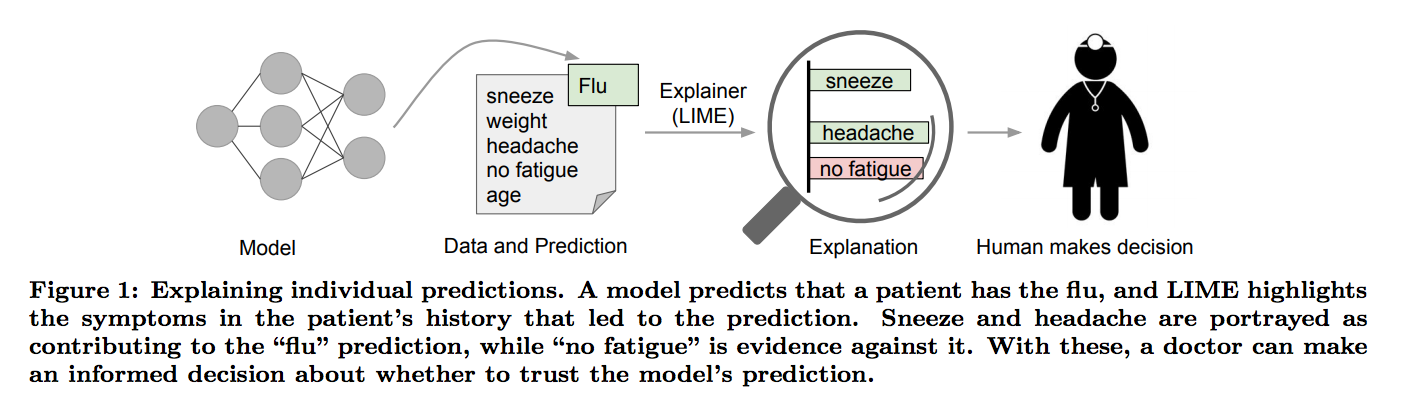
(画像は論文より引用)
なお、LIMEを用いることでこのような可視化が可能になります。この可視化部分がととてもいい感じです。
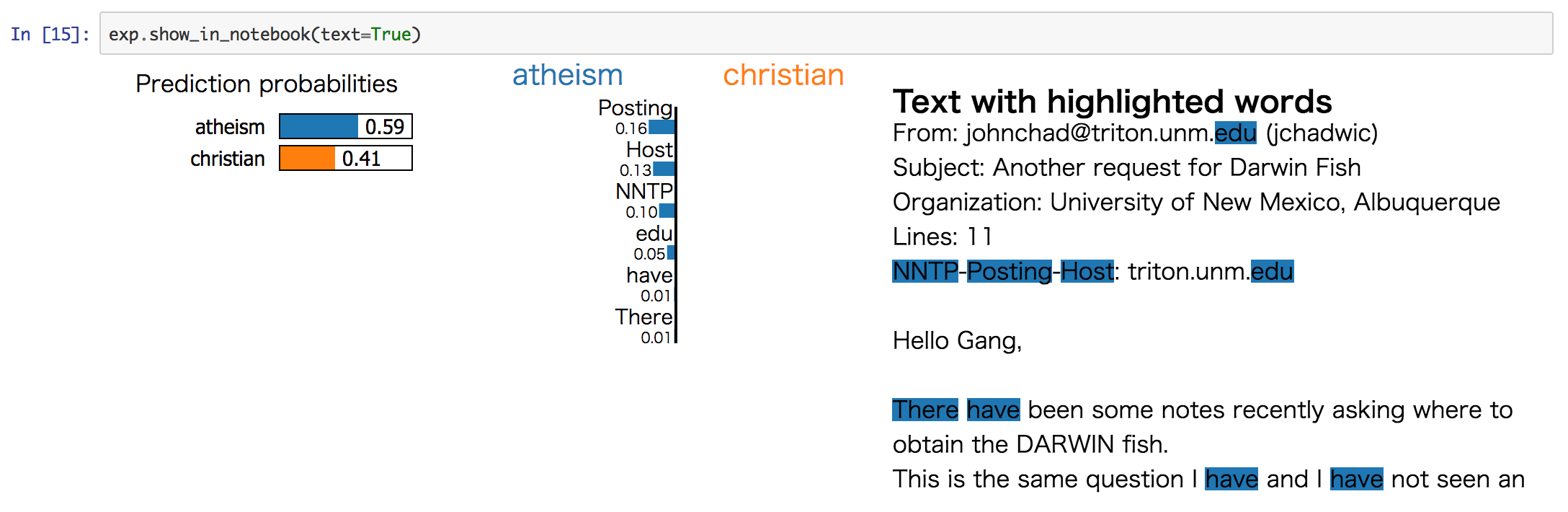
(https://marcotcr.github.io/lime/tutorials/Lime%20-%20basic%20usage%2C%20two%20class%20case.html)
対してSP-LIMEはexplaining modelsを行うための手法です。各モデルがどのような性質を持っているのかを劣モジュラ最適化によって一律の基準で比較する手法だとされています。こちらについては本記事で詳しく説明いたしませんので論文をご覧ください。
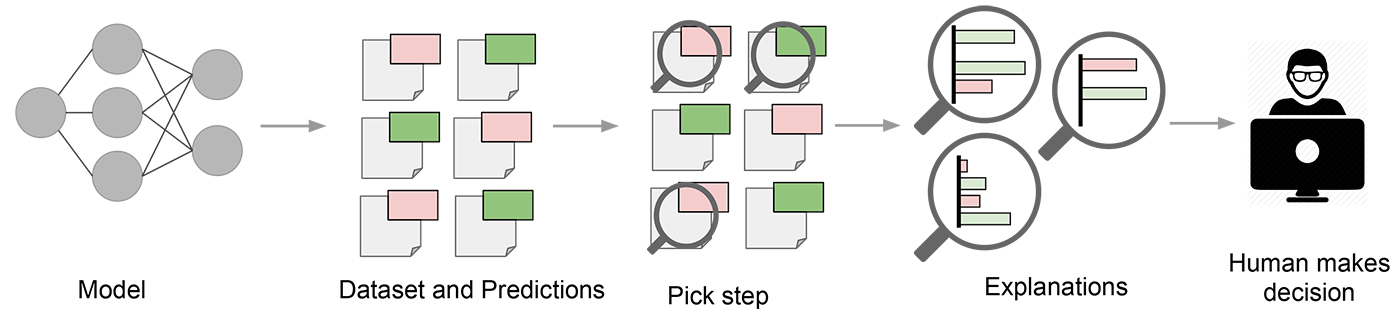
(https://www.oreilly.com/learning/introduction-to-local-interpretable-model-agnostic-explanations-lime より引用)
LIMEはどうやって予測結果の解釈を可能にするのか
LIMEでは、一つの予測結果があったときに、その結果に対してのみ局所的に近似させた単純な分類器を作って、その単純な分類器から予測に効いた特徴量を選ぶということをやっています。
大局的に近似させようとするのではなく、局所的に近似させることで近似の誤差を許容範囲内に収められているという感じですね。
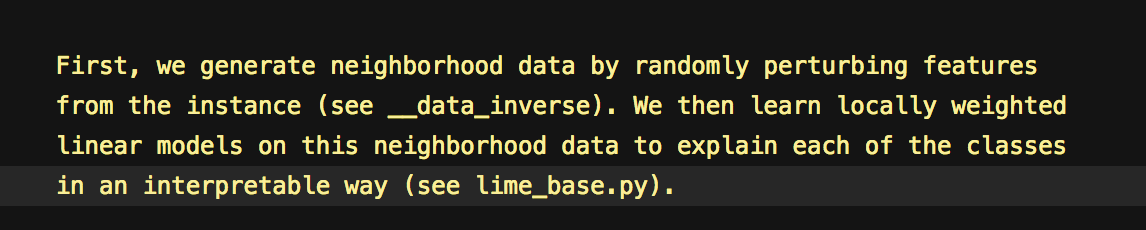
ではこの単純な分類器をどのように作るのか、ということですが、それを説明しているのが次の式です。
説明したい事象に対してそれを説明する分類器は次の目的関数によって求まります。
局所近似する分類器を求める目的関数
- : 解釈可能なモデルの集合
- : のうちの一つのモデル。例えば、線形モデルなど
- : 説明したい分類器
- : データとの距離
- : データの周辺でとの結果がどれだけ違っているか(は損失関数)
- : 説明用分類器の複雑さ
つまり事象の周辺で、できるだけ単純な分類器を作ろうとしているわけですね。
- : の周辺のデータの集合
- : 非ゼロ要素を一部だけ含むサンプリングにより生成された2値のスパースな点。で定義される
損失関数はこのようになっていて、説明したい分類器とLIMEで近似する分類器との距離を元データとの類似度で重み付けしたものになっています。
はこのような感じで、との距離関数にマイナスをかけたものをカーネル指数で割った感じです。は元データとサンプリングしたデータとの距離が近ければ近いほど小さくなる類似度関数となっているので、そのぶん損失関数も小さくなりやすくなる、というわけで損失関数の重み付けに使われています。
最後にですが、これはLIMEで作り出した単純な分類器が利用する特徴量の数が高々個であることを示す関数のようです(ここが一番わからない)。
そもそもLIMEで利用する特徴量個をどのように選ぶのかという話はここまでの式の中には全く出てきていませんでしたが、ではこの個をどのようにして選択するのかというと、筆者らがK-Lassoと呼んでいるLassoで正則化パスを使用して利用する特徴を個選択し、最小二乗法を介して重みを学習する方法を用いることで、選択していくとのことです。
という感じで、最終的には目的関数をRidge回帰で解いて、欲しい分類器を獲得し、その分類器の偏回帰係数から特徴量の寄与度を表示するわけです。
追記:
論文中にRidge回帰という記述はありません(線形モデルで解く、としか書いていない)。ただ、実装のコードでlime_base.explain_instance_with_data
(https://github.com/marcotcr/lime/blob/73f03130b1fa8dbb3378457e78c82d4889942f83/lime/lime_base.py#L104)
を確認すると、sklearn.linear_model.Ridgeを呼び出して、サンプリングしたデータに対してfitさせているため、Ridgeで解いていると思われます。

LIMEが受け取る入力と、分類器を作るためのデータサンプリング
ここからはもう少し、実際にどう使うかの部分を見ていきます。
LIMEを使う際に入力するデータはtabular、テキスト、画像のいずれにも対応しています。テキストの場合にはBoWが入力、画像の場合にはsuper-pixelsと呼ばれる任意のアルゴリズムを使用して計算されるものを用いて解釈可能なモデルの特徴表現としています。(特徴表現は0,10,1の2値で表され、1は元のsuper-pixels、0はグレーアウトされたsuper-pixels)
ここでいう事象とは説明したいモデルによってもたらされた予測結果です。ランダムフォレストで何かを二値分類した時に[0.2,0.8]などといった結果が得られると思いますが、これのことです。LIMEは入力としてこの予測結果とそれをもたらしたデータ及びモデルを受け取ります。
LIMEではそれらを受け取ったのち、予測対象のデータ周辺をサンプリングします。どのようにサンプリングしているのかについては論文を読んだだけではわからなかったのですが、実装を見ると対象データがテキストの場合には予測対象のデータからランダムに単語を除去してサンプルデータを作り出しているみたいですね。

(https://github.com/marcotcr/lime/blob/master/lime/lime_text.py)
tabularなデータの時には乱数を用いて、元データの一部を弄って新しいデータを作っている模様。

(https://github.com/marcotcr/lime/blob/master/lime/lime_tabular.py)
画像データの場合も同様に、乱数を加えてサンプリングしていました。
(https://github.com/marcotcr/lime/blob/master/lime/lime_image.py)
こうしてサンプリングした結果を用いて、次のような分布図が得られたと仮定します。

(論文より引用)
赤い+が元々の分類器でpositiveと判定された例、青い丸がnegativeの例です。その中にひときわ大きな赤い+がありますが、これが説明したい予測結果にあたり、この周辺にあるのが入力データからサンプリングしたデータについて予測した結果たちとなります。そしてそれらを分断している黒い点線がLIMEが作る新しい単純な分類器です。
実際にやってみた: タイタニック(Tabularデータ例)
公開してくれているノートブックを参考にしながらやれば、そんなにつまるところはないはずです。
import pandas as pd
#前処理
df = pd.read_csv("/Users/01018534/Downloads/train.csv")
#NAを含む行は削除する
df.dropna(inplace=True)
#予測列を抜き出す
y = df["Survived"]
#予測に使わない列を除く
df.drop(["PassengerId","Name","Ticket","Cabin","Survived"],axis=1,inplace=True)
#カテゴリデータを数値に変換する
from sklearn.preprocessing import LabelEncoder
feature_names = df.columns
categorical_features = [1,6]
categorical_names = {}
for feature in categorical_features:
le = LabelEncoder()
le.fit(df[feature_names[feature]])
df.loc[:, feature_names[feature]] = le.transform(df[feature_names[feature]])
categorical_names[feature] = le.classes_
df = df.astype(float)
#xgboostに食べさせる
import numpy as np
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
encoder = OneHotEncoder(categorical_features=categorical_features)
np.random.seed(1)
X_train, X_test, y_train, y_test = train_test_split(df.as_matrix(),y, train_size=0.80)
encoder.fit(df)
encoded_train = encoder.transform(X_train)
import xgboost
gbtree = xgboost.XGBClassifier(n_estimators=300, max_depth=5)
gbtree.fit(encoded_train, y_train)
from sklearn.metrics import accuracy_score
accuracy_score(y_test, gbtree.predict(encoder.transform(X_test)))
#LIMEの準備
import lime.lime_tabular
import re,itertools,json
def visualize_instance_html_japanese(self, exp, label, div_name, exp_object_name,
text=True, opacity=True):
if not text:
return u''
text = (self.indexed_string.raw_string()
.encode('utf-8', 'xmlcharrefreplace').decode())
text = re.sub(r'[<>&]', '|', text)
exp = [(self.indexed_string.word(x[0]),
self.indexed_string.string_position(x[0]),
x[1]) for x in exp]
all_ocurrences = list(itertools.chain.from_iterable(
[itertools.product([x[0]], x[1], [x[2]]) for x in exp]))
all_ocurrences = [(x[0], int(x[1]), x[2]) for x in all_ocurrences]
ret = '''
%s.show_raw_text(%s, %d, %s, %s, %s);
''' % (exp_object_name, json.dumps(all_ocurrences), label,
json.dumps(text), div_name, json.dumps(opacity))
return ret
from lime.lime_text import TextDomainMapper
TextDomainMapper.visualize_instance_html = visualize_instance_html_japanese
predict_fn = lambda x: gbtree.predict_proba(encoder.transform(x)).astype(float)
explainer = lime.lime_tabular.LimeTabularExplainer(X_train ,feature_names = feature_names,
class_names=["Not Survived","Survived"],
categorical_features=categorical_features,
categorical_names=categorical_names, kernel_width=3)
np.random.seed(1)
i = 10
exp = explainer.explain_instance(X_test[i], predict_fn, num_features=5)
exp.show_in_notebook(show_all=False)
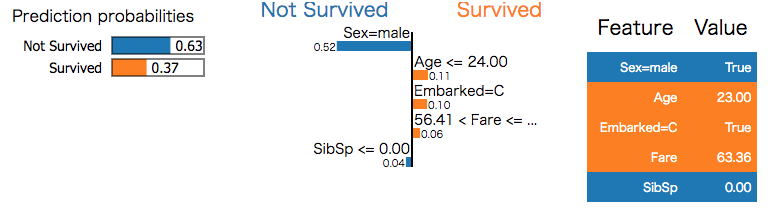
最終的にはこのような感じで結果を得ることができます。ここではこのように可視化をしていますが、exp.as_list()でplainなデータを結果を得ることもできる他、LIMEで近似した分類器の精度もexp.scoreで確認できます。
いくつかハマったところ
基本的にはノートブックを見れば大丈夫なのですが、LIMEを使う上でいくつかはまったところがあるので、書いていきます。主にテキストデータに関するものです。
1.可視化部分で日本語が文字化けする
マルチバイト文字に対応していないので、日本語を含んだ可視化をしようとすると文字化けします。可視化部分のエンコーディングがasciiになっているので、その部分を含めてメソッドを上書きしてしまいましょう。
import re,itertools,json
def visualize_instance_html_japanese(self, exp, label, div_name, exp_object_name,
text=True, opacity=True):
if not text:
return u''
text = (self.indexed_string.raw_string()
.encode('utf-8', 'xmlcharrefreplace').decode())
text = re.sub(r'[<>&]', '|', text)
exp = [(self.indexed_string.word(x[0]),
self.indexed_string.string_position(x[0]),
x[1]) for x in exp]
all_ocurrences = list(itertools.chain.from_iterable(
[itertools.product([x[0]], x[1], [x[2]]) for x in exp]))
all_ocurrences = [(x[0], int(x[1]), x[2]) for x in all_ocurrences]
ret = '''
%s.show_raw_text(%s, %d, %s, %s, %s);
''' % (exp_object_name, json.dumps(all_ocurrences), label,
json.dumps(text), div_name, json.dumps(opacity))
return ret
from lime.lime_text import TextDomainMapper
TextDomainMapper.visualize_instance_html = visualize_instance_html_japanese
2.ニューラルを使う場合は必ず出力層を二つ以上にする
LIMEはsklearnのAPIに準拠したモデルにのみ対応しており、二値分類の場合であってもmodel.predict_proba()で得られる[クラス0の確率、クラス1の確率]といった配列が来ることを前提とした作りになっています。
ニューラルでモデルを作成する際などに、二値分類であれば出力層を1つだけにすることはよくあると思いますが、LIMEで説明させたい場合においては必ず二つにしてください。
3. パイプラインで繋げる前処理クラスにtransformとfit_transformというメソッドを付け加える
テキストデータを受け取る際、LIMEの内部では空白で区切って文章を単語に分かち書きする処理が走りますが日本語では当然そのままだと無意味なので、予めmecabなどで各単語を分けた上で、空白で繋いだ文章を入力として与えてやる必要があるわけです。
ノートブックで言えば、exp = explainer.explain_instance(newsgroups_test.data[idx], c.predict_proba, num_features=6)の、newsgroups_test.data[idx]にあたる部分がそれになります。

(https://marcotcr.github.io/lime/tutorials/Lime%20-%20basic%20usage%2C%20two%20class%20case.html)
LIMEで入力されるデータは、テキストデータ分類問題の時にはテキストデータを入力しなくてはならないので、TFIDFなり、0パディングするなどしたい場合にはLIMEの内部でそれを行う必要があります。ノートブックではsklearnのパイプライン関数を使ってそれを実現していますね。

(TFIDFベクトルに変換する学習済みvectorizerを繋いでいる様子)
TFIDFの場合にはそのまま繋げばいいのですが、0パディングするいい感じのやつはsklearnにはないので他から持って来る必要があります。その上でその処理をするクラスに、sklearnのパイプ処理で動くようにtransformとfit_transformというメソッドを付け加える必要があります。例えばkerasでやる場合などは以下のようになるでしょうか。
import MeCab
def tokenize(text):
wakati = MeCab.Tagger("-O wakati")
wakati.parse("")
return wakati.parse(text)
df = pd.read_csv("../data/"+path+".csv", header=0)
#空白でつないだ文章の配列を獲得
tokenized_text_list = df[target].apply(lambda x: tokenize(x).replace("\n", "")).tolist()
#tokenizerを学習させて、0パディングの基準値(maxlen)を獲得
tokenizer = Tokenizer()
tokenizer.fit_on_texts(tokenized_text_list)
seq = tokenizer.texts_to_sequences(tokenized_text_list)
MAXLEN = max([len(x) for x in seq])
def transform(tokenized_text_list):
seq = tokenizer.texts_to_sequences(tokenized_text_list)
maxlen = MAXLEN
X = sequence.pad_sequences(seq, maxlen=maxlen)
return X
def fit_transform(text):
return text
tokenizer.transform = transform
tokenizer.fit_transform = fit_transform
ここではfit_transformは使われないので適当にしています。このtokenizerをノートブックでいうvectorizerと同じように扱えば、kerasのモデル説明の際などでも使えるはずです。
他の解釈性を高めるやり方との比較
他にも色々解釈性高める手法あるだろ!という感じですが、それらと比べてLIMEがそれなりにいい点を見てきます。追記するかも。
1. アテンション
機械翻訳ではアテンションでアラインメント可視化するぞというのがほぼ必須ですね。近頃は機械翻訳だけでなく関係抽出とか、画像にも適用先が広がっている感じです。

(https://www.quora.com/What-is-Attention-Mechanism-in-Neural-Networks キャプションを付与するタスクで、各単語が画像のどこにあたるのかをアテンションで示したもの)
他にも感情分析系のタスクで、各感情に対応した単語をハイライトするなどの形で使われてきています。ただ、アテンションができるのは当然ニューラルネットワークのみなので、any classifierに適用できるLIMEと比較するとLIMEの方が適用先は広いでしょう。計算時間もLIMEの方が断然早いです。kerasのモデルとかを説明しようとするとそれなりに時間かかりますが(サンプリングした各データに対してモデルの予測結果を求めているため)。
2. 決定木系モデルでの特徴量重要度
決定木系で計算できる特徴量重要度は非常に便利だといつも思います。ただ、LIMEと異なる点で言うと、LIMEは個別の予測結果に対しての説明を行うものであって特徴量重要度はモデルの説明に用いる、と言う点で、そもそもぶつかり合うものではないと言う認識です。SP-LIMEはぶつかり合う存在かもですが、両方併用して見るのが一番かと。
注意点
LIMEで近似した分類器が必ず正しいとは限りません。kerasのモデルを説明させた時などに、kerasの結果とLIMEの結果で大きく食い違うことが多々ありました。スコアをみて、良い結果を出した説明結果を選び出す必要があると思われます。Ridge回帰以外でやったらまた何か変わったりするんだろうか、というふうに思っているので、その辺色々試してみたいモチベがあるところです。
また、複雑なモデルの結果を説明しようとするときはかなり時間がかかったりします。時間がかかるなと思ったときはサンプル数を落として一通りやって見て、その上で近似分類器のスコアが高いものを見ていったり、特に結果に疑問が残るもののみやってみるなどしたほうがよいかもです。
最後に
なにはともあれLIME非常に便利なので使っていきましょう。

