この記事は
「競プロ!!」 競技プログラミング Advent Calendar 2017 - Adventar
の13日目の記事として書いています。
【HL分解でできること】
HL分解では、木(あるいは森 )上のパスを 個に分割することができます。
分割後のパスに対して操作を行った後にマージし直すことで、操作を高速に行うことができます。
HL分解を使えるかどうかの条件は、載せるデータ構造(セグ木、BIT)等のみに依存します。
つまり、ある単純な(一直線に並んでいるような)要素列に対しての問題が で解けるなら、
それが木の上のパスになった場合でも で解くことができます。
参考: mathさんのオーダー周りの記事
Heavy-Light Decomposition - math314のブログ
正直なんでlogになるのかよくわかっていない(ア
【実装例】
2020/01/08 更新
こわれている可能性があります
直す気はあんまりないです githubの方見て
beet-aizu.github.io
実装に当たってpekempeyさんのHL分解の記事を参考にしました。
http://pekempey.hatenablog.com/entry/2015/11/06/193123
https://github.com/beet-aizu/library/blob/master/heavylightdecomposition.cpp
struct HLDecomposition { int n,pos; vector<vector<int> > G; vector<int> vid, head, sub, hvy, par, dep, inv, type; HLDecomposition(){} HLDecomposition(int sz): n(sz),pos(0),G(n), vid(n,-1),head(n),sub(n,1),hvy(n,-1), par(n),dep(n),inv(n),type(n){} void add_edge(int u, int v) { G[u].push_back(v); G[v].push_back(u); } void build(vector<int> rs=vector<int>(1,0)) { int c=0; for(int r:rs){ dfs(r); bfs(r, c++); } } void dfs(int rt) { using T = pair<int,int>; stack<T> st; par[rt]=-1; dep[rt]=0; st.emplace(rt,0); while(!st.empty()){ int v=st.top().first; int &i=st.top().second; if(i<(int)G[v].size()){ int u=G[v][i++]; if(u==par[v]) continue; par[u]=v; dep[u]=dep[v]+1; st.emplace(u,0); }else{ st.pop(); int res=0; for(int u:G[v]){ if(u==par[v]) continue; sub[v]+=sub[u]; if(res<sub[u]) res=sub[u],hvy[v]=u; } } } } void bfs(int r,int c) { int &k=pos; queue<int> q({r}); while(!q.empty()){ int h=q.front();q.pop(); for(int i=h;i!=-1;i=hvy[i]) { type[i]=c; vid[i]=k++; inv[vid[i]]=i; head[i]=h; for(int j:G[i]) if(j!=par[i]&&j!=hvy[i]) q.push(j); } } } // for_each(vertex) // [l,r] <- attention!! void for_each(int u, int v, const function<void(int, int)>& f) { while(1){ if(vid[u]>vid[v]) swap(u,v); f(max(vid[head[v]],vid[u]),vid[v]); if(head[u]!=head[v]) v=par[head[v]]; else break; } } // for_each(edge) // [l,r] <- attention!! void for_each_edge(int u, int v, const function<void(int, int)>& f) { while(1){ if(vid[u]>vid[v]) swap(u,v); if(head[u]!=head[v]){ f(vid[head[v]],vid[v]); v=par[head[v]]; } else{ if(u!=v) f(vid[u]+1,vid[v]); break; } } } int lca(int u,int v){ while(1){ if(vid[u]>vid[v]) swap(u,v); if(head[u]==head[v]) return u; v=par[head[v]]; } } int distance(int u,int v){ return dep[u]+dep[v]-2*dep[lca(u,v)]; } };
dfsでheavy-pathを探してbfsで値を決定しています。
dfsが重いので非再帰にしてあります。
使い方は簡単で、
- コンストラクタにグラフのサイズを渡します。
- で と の間に辺を貼ります。
- で構築します。
頂点属性のクエリの場合は 、
辺属性のクエリの場合は で処理します。
具体的な使い方は下で問題を取り上げながら説明します。
変数の意味は以下の通りです
| 変数名 | 説明 |
|---|---|
| vid | HL分解後のグラフでのid |
| head | 頂点が属するheavy-pathのheadのid |
| sub | 部分木のサイズ |
| hvy | heavy-path上での次の頂点のid |
| par | 親のid |
| dep | 深さ |
| inv | HL分解前のグラフのid(添え字が分解後のid) |
| type | 森をHL分解するときの属する木の番号 |
問題例
長くなるのでライブラリ部分は省略します。
全体を見たい場合は各実装例の下のリンク先を確認してください。
ライブラリ単体はこちら。
GitHub - beet-aizu/library: ライブラリ群
【注意】
ここから先では問題のネタバレが多分に含まれるので、
見たくない方はブラウザバックしてください。
【yukicoder - No.529 帰省ラッシュ】
日本語なので概要は省略。
同じ道を二回以上通ってはいけないことから、
二重辺連結成分分解をして木にしてしまえばいいことがわかります。
クエリ1の がuniqueなので、最大値を求めればmap等で頂点の位置を特定できます。
また、頂点ごとの値はpriority_queueを用いることで で管理できます。
したがって、この問題は一点更新のクエリと頂点属性の最大値を求めるクエリを
処理する問題だと言い換えられるので、HL分解とセグメント木(うし木)で解くことができます。
うしさんの解説:
yukicoder
二重辺連結成分分解:
https://github.com/beet-aizu/library/blob/master/biconnectedgraph.cpp
うし木(一点更新区間取得):
https://github.com/beet-aizu/library/blob/master/segtree/ushi.cpp
実装例:
#217625 No.529 帰省ラッシュ - yukicoder
signed main(){ int n,e,q; scanf("%d %d %d",&n,&e,&q); BiconectedGraph big(n); big.input(e,-1); int E=0,V=big.build(); HLDecomposition hl(V); for(int i=0;i<V;i++) for(int j:big.T[i]) if(i<j) hl.add_edge(i,j),E++; hl.build(); SegmentTree<int,int> rmq(V, [](int a,int b){return max(a,b);}, [](int a,int b){return b;}, -1); vector<priority_queue<int> > pq(V); map<int,int> m; int num=0; for(int i=0;i<q;i++){ int d; scanf("%d",&d); if(d==1){ int u,w; scanf("%d %d",&u,&w); u--; u=big.belong[u]; u=hl.vid[u]; m[w]=u; if(pq[u].empty()||pq[u].top()<w) rmq.update(u,w); pq[u].push(w); num++; } if(d==2){ int s,t; scanf("%d %d",&s,&t); s--;t--; s=big.belong[s]; t=big.belong[t]; int ans=-1; hl.for_each(s, t, [&](int l, int r) { ans = max(ans,rmq.query(l, r + 1)); }); printf("%d\n",ans); if(~ans){ int k=m[ans]; pq[k].pop(); rmq.update(k,(!pq[k].empty()?pq[k].top():-1)); num--; } } } return 0; }
頂点属性のクエリなので、 を呼んでいます。
が元のグラフでのindexで、
渡したラムダ式が分解されたパスの両端のindex を引数として実行されます。
が閉区間であることに注意してください。
【ukuku09 Tree】
hoj.hamako-ths.ed.jp
(2020/02/15 リンクを修正)
こちらも日本語なので概要は省略。
うしさんの解説がわかりやすいので読んでください。
https://drive.google.com/drive/folders/0B6dHiK8u6-0heUtlSVJIY3lpbVU
このように、木DPと組み合わせて使うこともあります。
int N,M; vector< vector<int> > G,H; vector<int> U,V,dp; BIT<int> bit1,bit2; HLDecomposition hl; void dfs(int v,int p){ for(int u:G[v]){ if(u!=p){ dfs(u,v); bit1.add0(hl.vid[v],dp[u]); dp[v]+=dp[u]; } } for(int i:H[v]){ int res=hl.distance(U[i],V[i])+1; hl.for_each(U[i], V[i], [&](int l, int r) { res+=bit1.sum0(r)-bit1.sum0(l-1); res-=bit2.sum0(r)-bit2.sum0(l-1); }); dp[v]=max(dp[v],res); } bit2.add0(hl.vid[v],dp[v]); } signed main(){ cin.tie(0); ios::sync_with_stdio(0); cin>>N>>M; G.resize(N);H.resize(N);dp.resize(N); hl=HLDecomposition(N); bit1=BIT<int>(N+10); bit2=BIT<int>(N+10); U.resize(M);V.resize(M); for(int i=0;i<N-1;i++){ int A,B; cin>>A>>B; A--;B--; hl.add_edge(A,B); G[A].push_back(B); G[B].push_back(A); } hl.build(); for(int i=0;i<M;i++){ cin>>U[i]>>V[i]; U[i]--;V[i]--; H[hl.lca(U[i],V[i])].push_back(i); } dfs(0,-1); cout<<dp[0]<<endl; return 0; }
なんかスタック領域がMLの256MBより小さいのでREになりがちっぽい
定数倍に気をつけていこうな
【University CodeSprint 03 Simple Tree Counting】
Programming Problems and Competitions :: HackerRank
頂点の木が与えられる。各辺には から までの番号が振られている。
各辺について、その辺と同じ色の辺のみを使った極大な部分連結グラフを考え、
その頂点の集合を とする。
また、各色について、上の部分連結グラフの集合 を考える。
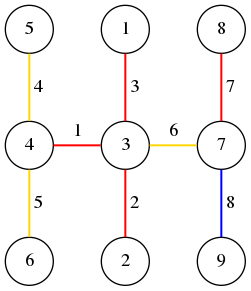
例えば上の図では 、 である。
また、 と定義する。以上を踏まえて、以下の三種類のクエリを合計 個処理しなさい。
クエリ1:
辺 の色を に変更する。
クエリ2:
を出力する。
クエリ3:
を出力する。制約
クエリ2を処理するのはBITを使えばよさそうです。
クエリ1と3はやばそうなんですが、クエリ先読みができるため、
変更箇所は高々 個であることに注目します。
各色ごとに頂点を作ってしまえば、クエリ1は
- 元の色の辺を切る
- 後の色の辺をつなぐ
という操作に言い換えることができます。


このグラフは高々 頂点の森になります。
以降では色ごとに別の頂点として考えることに注意してください。
このように考えると、頂点 を根とする連結な部分木のサイズを として、
各頂点について を保持しておけば、クエリ3を処理することができます。
あとはクエリ1です。まず、辺を切る操作について考察します。
頂点 が含まれる部分木の根を とします。
とすると、 は、 と を含む木の根を端点とするパス上の
が最大となる頂点になります。


辺を切った時に変化する量を考えると、辺 の両端をそれぞれ として、
変化量 となります。
次に、辺をつなぐ操作ですが、これは切る操作を反対にすればいいだけです。
をどのように管理すればいいかを考えます。
を求めるために必要な が変化するのは、辺を切るときとつなぐときだけです。
辺を切るときは、より深さが大きい方の頂点を として、 とすればいいです。
また、辺をつなぐときは、 とすればいいです。
最後に、 をどのように管理すればいいかを考えます。
が変化するのも、辺を切るときとつなぐときだけです。
辺を切るときは、 と を両端とするパス上の頂点全てから を引けばいいです。
また、辺をつなぐときは、 パス上の頂点全てに足せばいいです。


は一点更新区間取得なのでうし木で管理できます。
は区間更新一点取得なのでびーと木で管理できます。
以上より、この問題は で解くことができます。
初期化をするには、最初に全部の辺をつないでおいて、初期状態で
つながっていないものを切るようにすると簡潔に書くことができます。
細かい部分はコメントを入れたのでそちらも確認してください。
びーと木(区間更新一点取得):
https://github.com/beet-aizu/library/blob/master/segtree/beet.cpp
うし木:
https://github.com/beet-aizu/library/blob/master/segtree/ushi.cpp
BIT:
https://github.com/beet-aizu/library/blob/master/binaryindexedtree.cpp
実装例:
signed main(){ // クエリ2の処理用 BIT<Int> bit(1e6+100,0); int n; scanf("%d",&n); // 入力 vector<int> a(n),b(n),c(n); // グラフと頂点のindex vector<unordered_map<int,vector<int> > > G(n); vector<unordered_map<int,int > > R(n); // indexを管理しながら辺を張る int sz=0; using P = pair<int, int>; vector<P> edges; auto add_edge=[&](int x,int e){ edges.push_back(P(x,e)); if(!R[a[x]].count(e)) R[a[x]][e]=sz++; if(!R[b[x]].count(e)) R[b[x]][e]=sz++; G[a[x]][e].push_back(b[x]); G[b[x]][e].push_back(a[x]); }; for(int i=0;i<n-1;i++){ scanf("%d %d %d",&a[i],&b[i],&c[i]); a[i]--;b[i]--; add_edge(i,c[i]); } // クエリ先読み int Q; scanf("%d",&Q); vector<int> T(Q),A(Q),B(Q); for(int i=0;i<Q;i++){ scanf("%d",&T[i]); int t=T[i]; if(t==1){ scanf("%d %d",&A[i],&B[i]); int x=A[i],e=B[i]; x--; // あらかじめ全ての辺を張っておく add_edge(x,e); } if(t==2){ scanf("%d %d",&A[i],&B[i]); } if(t==3){ scanf("%d",&A[i]); } } vector<bool> used(sz); // de:深さ / dp:部分木のサイズ vector<int> de(sz),dp(sz); // 部分木のサイズを保持するセグ木(区間更新一点取得->びーと木) SegmentTree<int,int> beet(sz+100, [&](int a,int b){ return a+b;}, [&](int a,int b){ return a+b;}, 0,0); // 各頂点の各時点での根の情報を管理するセグ木(一点更新区間取得->うし木) SegmentTree2<int,int> ushi(sz+100, [&](int a,int b){ if(a<0) return b; if(b<0) return a; return de[a]>de[b]?a:b; }, [&](int a,int b){ return b;}, -1); // HL分解 HLDecomposition hld(sz); for(int i=0;i<n;i++){ for(auto &x:G[i]){ int co=x.first; auto &v=x.second; sort(v.begin(),v.end()); v.erase(unique(v.begin(),v.end()),v.end()); int p=R[i][co]; for(int u:v){ int q=R[u][co]; if(p<q) hld.add_edge(p,q); } } } // 部分木のサイズを求めるDFS function<int(int,int,int,int)> dfs=[&](int v,int p,int c,int d){ int x=R[v][c],res=1; de[x]=d;used[x]=1; for(int u:G[v][c]){ if(u==p) continue; res+=dfs(u,v,c,d+1); } return dp[x]=res; }; function<Int(Int)> calc=[](Int x){return x*(x-1)/2;}; // 根の集合を求め、森の各木についてDFSする vector<int> rs; for(int i=0;i<n;i++){ for(auto p:R[i]){ int r=p.second,co=p.first; if(used[r]) continue; rs.push_back(r); dfs(i,-1,co,0); bit.add(co,calc(dp[r])); } } // 根の情報を初期化 hld.build(rs); for(int r:rs){ hld.for_each(r,r,[&](int ll,int rr){ ushi.update(ll,r);}); } // 部分木のサイズを初期化 for(int i=0;i<n;i++){ for(auto &p:R[i]){ int r=p.second; hld.for_each(r,r,[&](int ll,int rr){ beet.update(ll,rr+1,dp[r]);}); } } // 頂点xが含まれる部分木の根のindexを返す auto root=[&](int x){ int res=-1; hld.for_each(x,rs[hld.type[x]],[&](int ll,int rr){ int tmp=ushi.query(ll,rr+1); res=ushi.f(res,tmp);}); return res; }; // index:x color:e のエッジを切る auto cut=[&](int x,int e){ int p=R[a[x]][e],q=R[b[x]][e]; if(de[p]>de[q]) swap(p,q); int r=root(p); // 切る前の重みを引く bit.add(e,-calc(beet.query(hld.vid[r]))); // 部分木のサイズの情報を更新する hld.for_each(p,r,[&](int ll,int rr){ beet.update(ll,rr+1,-beet.query(hld.vid[q]));}); // 新しい根の情報を更新する hld.for_each(q,q,[&](int ll,int rr){ ushi.update(ll,q);}); // 切った後の重みを足す bit.add(e,calc(beet.query(hld.vid[r]))); bit.add(e,calc(beet.query(hld.vid[q]))); }; // index:x color:e のエッジをつなぐ auto con=[&](int x,int e){ int p=R[a[x]][e],q=R[b[x]][e]; if(de[p]>de[q]) swap(p,q); int r=root(p); // つなぐ前の重みを引く bit.add(e,-calc(beet.query(hld.vid[r]))); bit.add(e,-calc(beet.query(hld.vid[q]))); // 部分木のサイズの情報を更新する hld.for_each(p,r,[&](int ll,int rr){ beet.update(ll,rr+1,beet.query(hld.vid[q]));}); // 削除した根の情報を更新する hld.for_each(q,q,[&](int ll,int rr){ ushi.update(ll,-1);}); // つないだ後の重みを足す bit.add(e,calc(beet.query(hld.vid[r]))); }; // 初期状態でつながっていないエッジを切る sort(edges.begin(),edges.end()); edges.erase(unique(edges.begin(),edges.end()),edges.end()); for(auto p:edges){ int x=p.first,e=p.second; if(c[x]!=e) cut(x,e); } // クエリを処理する for(int i=0;i<Q;i++){ int t=T[i]; if(t==1){ int x=A[i],e=B[i]; x--; if(c[x]==e) continue; cut(x,c[x]); con(x,e); c[x]=e; } if(t==2){ int l=A[i],r=B[i]; printf("%lld\n",bit.sum(r)-bit.sum(l-1)); } if(t==3){ int x=A[i]; x--; int p=R[a[x]][c[x]]; int r=root(p); printf("%lld\n",calc(beet.query(hld.vid[r]))); } } return 0; }
この問題も定数倍がきついです…
森のHL分解では、 の時に根の頂点群を引数にします。
それ以外は木の時と変わりません。
【閑話休題】
遅延伝播セグメント木について(旧:遅延評価セグメント木について) - beet's soil
おそらく上の記事を読んだ人の中には
「どうしてTとEをわける必要があるんだ?どっちもTにすればいいじゃん」
と思った人もいると思いますが、
この下にあるような問題でようやく分けた意味が活かせてきます。
【UVA 13192 Tobby and the Skeletons】
https://uva.onlinejudge.org/external/131/p13192.pdf
概要
頂点の木が与えられる。
各エッジごとに、 が与えられ、
これはその辺に 以上 以下の値が等確率で設定されていることを表す。
以下のクエリを 回処理しなさい。
を両端とするパス上のエッジの重みの最大値の期待値を出力する
辺属性の は、各辺を独立な頂点に対応付けすることで処理します。
前提として、対象のグラフは木であったので、 頂点 辺です。
少し考えると、根以外の頂点に自分の親との間の辺を対応させればいいことがわかります。

ノードの型は vector<double> で、 最大値が添え字の値になる確率を値にします。
そうすると、マージが結合的で可換なことがわかるので、セグ木に載せることができます。
(試してはいないけど式変形で示せるはず(多分)。)
変更クエリなしで区間取得なので、定数倍の軽いうし木を使います。
愚直にマージすると以下のようになります。
auto f=[](const VD& a,const VD& b){ VD r(101,0); for(int i=0;i<=100;i++) for(int j=0;j<=100;j++) r[max(i,j)]+=a[i]*b[j]; return r; };
ぐっと睨むと累積和を利用することでひとつ次元が落ちることがわかります。
auto f=[](const VD& a,const VD& b){ VD r(101,0); VD sa(101,a[0]),sb(101,b[0]); for(int i=1;i<=100;i++){ sa[i]=sa[i-1]+a[i]; sb[i]=sb[i-1]+b[i]; } for(int i=0;i<=100;i++){ r[i]+=a[i]*b[i]; r[i]+=a[i]*sb[i-1]; r[i]+=b[i]*sa[i-1]; } return r; };
ほんとはこれで終わりでいいはずなんですが、UVaのTLEの設定がクソなため、
定数倍改善をしないといけません。
いちいち累積和を計算している部分が遅そうなので、最初から累積和を渡したくなります。
// a,b は累積和 auto f=[](const VD& a,const VD& b){ VD r(101,0); r[0]=a[0]*b[0]; for(int i=1;i<=100;i++){ r[i]+=r[i-1]; r[i]+=(a[i]-a[i-1])*b[i-1]; r[i]+=a[i-1]*(b[i]-b[i-1]); r[i]+=(a[i]-a[i-1])*(b[i]-b[i-1]); } return r; };
セグ木の単位元は VD(101,1) となります。(0になる確率が1。)
実装例:
http://rhodon.u-aizu.ac.jp:8080/arena/submission_log.jsp?no=3765&runID=20463984
signed main(){ int n; while(scanf("%d",&n)!=EOF){ HLDecomposition hld(n); vector<int> a(n-1),b(n-1),x(n-1),y(n-1); for(int i=0;i<n-1;i++){ scanf("%d %d %d %d",&a[i],&b[i],&x[i],&y[i]); a[i]--;b[i]--; hld.add_edge(a[i],b[i]); } hld.build(); using VD = vector<double>; VD vd(101,1); vector<VD> v(n,VD(101,0)); for(int i=0;i<n-1;i++){ if(hld.vid[a[i]] > hld.vid[b[i]]) swap(a[i], b[i]); int k=hld.vid[b[i]]; for(int j=x[i];j<=y[i];j++) v[k][j]=1.0/(y[i]-x[i]+1); } for(int i=0;i<n;i++) for(int j=1;j<=100;j++) v[i][j]+=v[i][j-1]; auto f=[](const VD& a,const VD& b){ VD r(101,0); r[0]=a[0]*b[0]; for(int i=1;i<=100;i++){ r[i]+=r[i-1]; r[i]+=(a[i]-a[i-1])*b[i-1]; r[i]+=a[i-1]*(b[i]-b[i-1]); r[i]+=(a[i]-a[i-1])*(b[i]-b[i-1]); } return r; }; SegmentTree<VD,double> num(n, f, [](VD a,double b){return a;}, vd,v); int q; scanf("%d",&q); while(q--){ int u,v; scanf("%d %d",&u,&v); u--;v--; VD re=num.d1; hld.for_each_edge(u,v,[&](int l,int r){ re=f(re,num.query(l,r+1));}); double s=0; for(int i=1;i<=100;i++) s+=i*(re[i]-re[i-1]); printf("%.14f\n",s); } } return 0; }
定数倍が鬼のようにきついです。
時間帯によってACしたりTLEしたりします。闇。
【PCK2017 予選11問目 ネットワークの課金システム】
http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=0367
日本語なので概要は省略。
頂点の周りの辺全てに対して操作をするのは難しいため、
別の方法に言い換える必要があります。
考察すると、頂点 に加算された値を として保持しておき、
と をマージする際に以下のようにコストを決めればいいことがわかります。
この操作はmapを使って と十分高速に行えるため、セグ木に載せることができます。
一点更新区間取得なので、うし木を使います。
必要な情報は
- : 左端のindex
- : 右端のindex
- : 求める料金
の三つです。
区間を繋げる順番が非可換なため、クエリに対してはマージを工夫する必要があります。
具体的には以下のようにすればいいです。
vector に列をためておき、新たに追加する時は
- 既存の列のどれかとマージできる場合はして、
- できない場合は末尾に追加します。
最後に後ろから一つの列になるようにマージします。
僕のHL分解の実装では、各ステップでの要素数は高々2なので、
オーダーはこれまでの順番を気にせずマージする場合と変わりません。
うし木:
https://github.com/beet-aizu/library/blob/master/segtree/ushi.cpp
実装例:
AIZU ONLINE JUDGE: Code Review
signed main(){ Int n,k; cin>>n>>k; HLDecomposition hld(n); vector<map<Int,Int> > m(n); for(Int i=0;i<n-1;i++){ Int a,b,c; cin>>a>>b>>c; hld.add_edge(a,b); m[a][b]=m[b][a]=c; } hld.build(); using T = tuple<Int, Int, Int>; vector<Int> w(n,0); auto mget=[&](Int a,Int b){ Int res=w[a]+w[b]+m[a][b]; return (res%k==0)?0:res; }; auto f=[&](T a,T b){ if(a>b) swap(a,b); Int al,ar,av; tie(al,ar,av)=a; Int bl,br,bv; tie(bl,br,bv)=b; if(al<0||ar<0) return b; if(m[al].count(bl)||m[al].count(br)) swap(al,ar); if(m[ar].count(br)) swap(bl,br); if(!m[ar].count(bl)) return T(-1,-1,-1); return T(al,br,av+bv+mget(ar,bl)); }; auto g=[](T a,Int b){return T(b,b,0);}; SegmentTree<T,Int> seg(n,f,g,T(-1,-1,0)); for(Int i=0;i<n;i++) seg.update(i,hld.inv[i]); Int q; cin>>q; while(q--){ string op; cin>>op; if(op=="add"){ Int x,d; cin>>x>>d; w[x]+=d; seg.update(hld.vid[x],x); } if(op=="send"){ Int s,t; cin>>s>>t; vector<T> v; auto merge=[&](T x){ for(Int i=0;i<(Int)v.size();i++){ T y=f(x,v[i]); if(~get<2>(y)){ v[i]=y; return; } } v.push_back(x); }; hld.for_each(s,t,[&](Int l,Int r){merge(seg.query(l,r+1));}); while((Int)v.size()>1){ T x=v.back();v.pop_back(); merge(x); } cout<<(get<2>(v.front()))<<endl; } } return 0; }
【AOJ-ICPC Do use Segment Tree】
http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=2450
概要
頂点の木が与えられる。
各頂点には重み が割り当てられている。
以下の2種類のクエリを合計 回処理しなさい。
クエリ1:
頂点 を両端とするパス上の頂点の重みを に変更する。
クエリ2:
頂点 を両端とするパス上の、連続する部分列のうち、
重みの合計が最大となるようなものの、重みの合計を出力する。
(空集合は部分列とはみなさない)
AOJ-ICPCで1000ということもあり、不可能そうな気配を感じますが、
これもHL分解で解くことができます。
クエリ1は区間更新で非可換な操作なので、遅延セグ木を使えば処理できます。
クエリ2について考察します。
まず、連続性が必要なことから、マージの際にそれぞれの区間の両端のindexが必要です。
連続する部分列の最大値は、以下の4つの値を保持しながらマージすることで求められます。





クエリ1に戻ると、 の時はそのパス上の全ての頂点を使うべきであり、
の場合は一点だけ使うべきであることがわかります。
したがって、先ほどの値に加えて区間の長さ を保持しておくことで、以下のように更新できます。
のとき
のとき
ここまで考察すればもう実装に落とし込むだけです。
先ほどの問題と同様にマージが非可換なため、いい感じに処理します。
遅延セグ木:
https://github.com/beet-aizu/library/blob/master/segtree/chien.cpp
実装例:
http://judge.u-aizu.ac.jp/onlinejudge/review.jsp?rid=2640822#1
signed main(){ int n,q; scanf("%d %d",&n,&q); HLDecomposition hld(n); vector<int> w(n); for(int i=0;i<n;i++) cin>>w[i]; using P = pair<int,int>; for(int i=0;i<n-1;i++){ int a,b; cin>>a>>b; a--;b--; hld.add_edge(a,b); } hld.build(); using T = tuple<int,int,int,int,int,int,int>; T d1(-1,-1,-1,-1,-1,-1,-1); P d0(-1,-114514); auto &par=hld.par; auto &vid=hld.vid;; auto con=[&](int a,int b){ return par[a]==b||par[b]==a; }; auto f=[&](T a,T b){ if(a>b) swap(a,b); if(get<0>(a)<0) return b; int al,ar,as,ava,avi,avl,avr; tie(al,ar,as,ava,avi,avl,avr)=a; int bl,br,bs,bva,bvi,bvl,bvr; tie(bl,br,bs,bva,bvi,bvl,bvr)=b; if(con(al,bl)||con(al,br)){ swap(al,ar); swap(avl,avr); } if(con(ar,br)){ swap(bl,br); swap(bvl,bvr); } if(!con(ar,bl)) return d1; int cl=al,cr=br,cs=as+bs; int cva=ava+bva,cvi=max(avi,bvi),cvl=avl,cvr=bvr; cvi=max(cvi,avr+bvl); cvl=max(cvl,ava+bvl); cvr=max(cvr,avr+bva); return T(cl,cr,cs,cva,cvi,cvl,cvr); }; auto g=[&](T a,P p){ int al,ar,as,ava,avi,avl,avr; tie(al,ar,as,ava,avi,avl,avr)=a; int v=p.first,b=p.second; if(~v) al=ar=v,as=1; if(b>=0) return T(al,ar,as,b*as,b*as,b*as,b*as); return T(al,ar,as,b*as,b,b,b); }; auto h=[&](P a,P b){return b;}; vector<T> vt(n); for(int i=0;i<n;i++) vt[vid[i]]=g(d1,P(i,w[i])); SegmentTree<T,P> seg(n,f,g,h,d1,d0,vt); while(q--){ int t,a,b,c; scanf("%d %d %d %d",&t,&a,&b,&c); a--;b--; if(t==1){ hld.for_each(a,b,[&](int l,int r){ seg.update(l,r+1,P(-1,c)); }); } if(t==2){ vector<T> v; auto merge=[&](T x){ for(int i=0;i<(int)v.size();i++){ T y=f(v[i],x); if(~get<0>(y)){ v[i]=y; return; } } v.push_back(x); }; hld.for_each(a,b,[&](int l,int r){merge(seg.query(l,r+1));}); while(v.size()>1){ T x=v.back();v.pop_back(); merge(x); } int vl,vr,vs,vva,vvi,vvl,vvr; tie(vl,vr,vs,vva,vvi,vvl,vvr)=v.front(); printf("%d\n",max({vva,vvi,vvl,vvr})); } } return 0; }
【まとめ】
| 問題名 | アルゴリズム |
|---|---|
| 帰省ラッシュ | 二重辺連結成分分解 + HL分解 + セグ木 |
| Tree | HL分解 + BIT + 木DP |
| Simple Tree Counting | 森のHL分解 + うし木 + らて木 |
| Tobby and the Skeletons | HL分解 + 辺属性のクエリ |
| ネットワークの課金システム | HL分解 + 非可換モノイドのうし木 |
| Do use Segment Tree | HL分解 + 非可換モノイドの遅延セグ木 |
と、一通り網羅できた感があります。
HL分解を使った他の典型問題があればコメントで教えてください。
HL分解はどうやって使うのかの記事があまりなくてライブラリを作るときに苦労したので、
この記事が誰かの助けになってくれるとうれしいです。
(実装が重い問題が多くてとっつきにくい感もある)
明日はうしさんの記事です 楽しみですね!
