

はじめに
はじめまして。
NTTデータ数理システムでリサーチャーをしている大槻 (通称、けんちょん) です。
C や C++ を使用しているとしばしばビット演算を行う場面が出て来ます。
計算機リソースが限られている状況では、ビットを用いることでデータ量を少なく済ませたり、計算コストを小さく抑えたりすることができるメリットがあります。
本記事では、ビット演算を用いて実現できる処理について、簡単なものから高度なものまで集大成します。極力わかりやすく頑張って執筆しました。特に前半 4 つはビットの説明の中でもかなりわかりやすい方だと思います。後半の 7 つのテーマは比較的高度なアルゴリズムの話題ですので、フラグ管理やマスクビットについて詳しく学びたい方は前半 4 つを中心に読んでいただいて、後半 6 つは必要に応じて読んでいただければと思います。反対にビットの知識はあってビットを用いたアルゴリズムに関心のある方は前半を飛ばして読んでいただければと思います。
- ビット演算の基本
- std::bitset
- ビットを用いたフラグ管理
- マスクビット
- ビットを用いた集合演算
- bit 全探索
- 与えられた部分集合の部分集合を列挙
- next_combination
- Xorshift を用いた高速乱数生成
- Binary Indexed Tree (BIT)
- bit DP
0. ビットとは
私たちがビットと呼んでいるものの実体は、多くの場合はただの整数型です。ただし整数を二進法で考えます。C++ では整数は主に int 型で表します。45 という整数は二進法で表すと
45 = 0b00101101 (二進数は先頭に 0b をつけて表します、ここでは 8 bit で書いています)
です。これを {0, 2, 3, 5} という番号の集まりであると考えます。それは 00101101 の右から数えて 0 番目、2 番目、3 番目、5 番目が 1 になっているからです。番号の集まりが具体的に何を表すのかは用途によって様々ですが、電子回路の場面では「0 番目と 2 番目と 3 番目と 5 番目の LED が光っている状態」といったものを表しますし、フラグを管理する場面では「0 番目と 2 番目と 3 番目と 5 番目のフラグが立っている状態」といったものを表します。
ビットの用途
非常に多種多様です!!!
他にもありましたら、コメントで大募集中です!!!
- ゲームの状態管理 (「通常」「眠り」「毒」「戦闘不能」など)
- 業務システムの状態管理
- エラー処理分岐の管理
- RGB 値の操作
- ビットマップ画像マスク
- TCP/IP のサブネットマスク
- ハードウェアからの割り込み制御
- .Net の Keys 列挙体 (@keymoon さんから聞きました)
- Linux のファイルパーミッション
- bit を用いた高速乱数生成 (Xorshift)
- bit を用いた探索処理 (bit 全探索)
- bit を用いた動的計画法処理 (bit DP)
などが挙げられます (いくつかはリンク先にも使用例があります)。
1. ビット演算とは
AND
例えば、45 AND 25 という演算を考えてみましょう。これは 45 と 25 をそれぞれ二進法表記したときに各桁ごとに AND をとったものになります。
45 = 0b101101
25 = 0b011001
なので
45 AND 25 = 0b001001
すなわち
45 AND 25 = 9
になります。
#include <iostream>
using namespace std;
int main() {
int a = 45; // 実際上は 0b101101、あるいは 0x2d と書く
int b = 25;
cout << a << " AND " << b << " = " << (a&b) << endl;
}
45 AND 25 = 9
OR
OR は二進法表記したときに各桁ごとに OR をとったものになります。
45 = 0b101101
25 = 0b011001
より
45 OR 25 = 0b111101 = 61
になります。
#include <iostream>
using namespace std;
int main() {
int a = 45; // 実際上は 0b101101、あるいは 0x2d と書く
int b = 25;
cout << a << " OR " << b << " = " << (a|b) << endl;
}
45 OR 25 = 61
他に、NOT, NAND, NOR, XOR といったものがありますがそれらの詳細は以下の資料を読んでいただければと思います。本記事ではタイトルに C++ とつけましたが、ビット演算そのものについてはどの言語でも大差ないです。
2. std::bitset を用いた出力
上の例では cout するときに愚直にそのまま整数値を出力しましたが、std::bitset を用いるとより見やすい出力ができます。他にも様々な用途が考えられる機能です。
#include <iostream>
#include <bitset>
using namespace std;
int main() {
int A = 0x2d;
int B = 0x19;
cout << A << " AND " << B << " = " << (A&B) << endl;
cout << bitset<8>(A) << " AND " << bitset<8>(B) << " = " << bitset<8>(A&B) << endl;
}
45 AND 25 = 9
00101101 AND 00011001 = 00001001
3. ビット演算を用いたフラグ管理
ここからビットシフト演算子が登場します!
a 番目のフラグが立っている状態は (1<<a) と表せます。
さらに、a 番目と b 番目と c 番目のフラグが立っている状態は (1<<a) | (1<<b) | (1<<c) と表せます。
これを用いて以下のようなフラグ管理ができます!
| やりたいこと | 実装 |
|---|---|
| ビット bit に i 番目のフラグが立っているかどうか | if (bit & (1<<i)) |
| ビット bit に i 番目のフラグが消えているかどうか | if (!(bit & (1<<i))) |
| ビット bit に i 番目のフラグを立てる | bit|= (1<<i) |
| ビット bit に i 番目のフラグを消す | bit &= ~(1<<i) |
| ビット bit に何個のフラグが立っているか | __builtin_popcount(bit) |
| ビット bit に i 番目のフラグを立てたもの | bit|(1<<i) |
| ビット bit に i 番目のフラグを消したもの | bit & ~(1<<i) |
なお、それぞれ他の表現方法も色々考えられます。例えばビット bit に i 番目のフラグが立っているかどうかは if ((bit>>i) & 1) と書くこともできます。また、bit|(1<<i) といった書き方をしましたが、(1<<i) のようなものは以下のように予め define してしまうことも多いです (const unsigned int を使えという意見もあります)。
#define BIT_FLAG_0 (1<<0) // 0000 0000 0000 0001
#define BIT_FLAG_1 (1<<1) // 0000 0000 0000 0010
#define BIT_FLAG_2 (1<<2) // 0000 0000 0000 0100
#define BIT_FLAG_3 (1<<3) // 0000 0000 0000 1000
#define BIT_FLAG_4 (1<<4) // 0000 0000 0001 0000
#define BIT_FLAG_5 (1<<5) // 0000 0000 0010 0000
#define BIT_FLAG_6 (1<<6) // 0000 0000 0100 0000
#define BIT_FLAG_7 (1<<7) // 0000 0000 1000 0000
注意点として表のうち、__builtin_popcount() については GCC のビルトイン関数ですので、GCC で用いる必要があります。
以下にフラグ管理の具体的な動作確認を示します (ビットは const unsigned int で表しています):
#include <iostream>
#include <bitset>
using namespace std;
const unsigned int BIT_FLAG_0 = (1 << 0); // 0000 0000 0000 0001
const unsigned int BIT_FLAG_1 = (1 << 1); // 0000 0000 0000 0010
const unsigned int BIT_FLAG_2 = (1 << 2); // 0000 0000 0000 0100
const unsigned int BIT_FLAG_3 = (1 << 3); // 0000 0000 0000 1000
const unsigned int BIT_FLAG_4 = (1 << 4); // 0000 0000 0001 0000
const unsigned int BIT_FLAG_5 = (1 << 5); // 0000 0000 0010 0000
const unsigned int BIT_FLAG_6 = (1 << 6); // 0000 0000 0100 0000
const unsigned int BIT_FLAG_7 = (1 << 7); // 0000 0000 1000 0000
int main() {
// {1, 3, 5} にフラグの立ったビット
unsigned int bit = BIT_FLAG_1 | BIT_FLAG_3 | BIT_FLAG_5;
cout << "{1, 3, 5} = " << bitset<8>(bit) << endl;
// ビット {1, 3, 5} について、3 番目のフラグが立っていること
if (bit & BIT_FLAG_3) {
cout << "3 is in " << bitset<8>(bit) << endl;
}
// ビット {1, 3, 5} について、0 番目のフラグが立っていないこと
if (!(bit & BIT_FLAG_0)) {
cout << "0 is not in " << bitset<8>(bit) << endl;
}
// 新たなビット
unsigned int bit2 = BIT_FLAG_0 | BIT_FLAG_3 | BIT_FLAG_4; // {0, 3, 4}
cout << bitset<8>(bit) << " AND " << bitset<8>(bit2) << " = " << bitset<8>(bit & bit2) << endl; // {1, 3, 5} AND {0, 3, 4} = {3}
cout << bitset<8>(bit) << " OR " << bitset<8>(bit2) << " = " << bitset<8>(bit | bit2) << endl; // {1, 3, 5} OR {0, 3, 4} = {0, 1, 3, 4, 5}
// bit に 6 番目のフラグを立てる
cout << "before: " << bitset<8>(bit) << endl;
bit |= BIT_FLAG_6;
cout << "after : " << bitset<8>(bit) << " (6 included)" << endl;
// bit2 から 3 番目のフラグを消す
cout << "before: " << bitset<8>(bit2) << endl;
bit2 &= ~BIT_FLAG_3;
cout << "after : " << bitset<8>(bit2) << " (3 excluded)" << endl;
return 0;
}
{1, 3, 5} = 00101010
3 is in 00101010
0 is not in 00101010
00101010 AND 00011001 = 00001000
00101010 OR 00011001 = 00111011
before: 00101010
after : 01101010 (6 included)
before: 00011001
after : 00010001 (3 excluded)
4. マスクビット
ビットの使い方として最も多いものの 1 つがマスクビットです。なじみの深いもので言えば、IPアドレスのマスクビットや割り込み制御のマスクビットなどが挙げられます。多種多様な場面で使用されるマスクビットですが、基本的なアイディアは共通で、
- 複数のフラグをまとめて立てる
- 複数のフラグをまとめて消す
- 必要な情報だけを取り出すために、マスクした部分の情報のみを取り出す
といったものを効率良く実現するものです。現在のフラグ状態を表すビットを bit として、マスクビットを mask としたとき
| やりたいこと | 実装 |
|---|---|
| mask で表された部分のフラグをまとめて立てる | bit |= mask |
| mask で表された部分のフラグをまとめて消す | bit &= ~mask |
| mask で表された部分の情報のみを取り出したもの | bit & mask |
| mask で表された部分のどれかのフラグが立っているかどうか | if (bit & mask) |
| mask で表された部分のすべてのフラグが立っているかどうか | if ((bit & mask) == mask) |
として実現します。簡単な例を以下に示します。「毒」「麻痺」状態を「回復の薬」で回復させたりしてみます。
#include <iostream>
#include <bitset>
using namespace std;
const unsigned int BIT_FLAG_DAMAGE = (1 << 0); // HP が満タンでないか
const unsigned int BIT_FLAG_DOKU = (1 << 1); // 毒状態になっているか
const unsigned int BIT_FLAG_MAHI = (1 << 2); // 麻痺状態になっているか
const unsigned int BIT_FLAG_SENTOFUNO = (1 << 3); // 戦闘不能状態になっているか
// atack して、単にダメージを受ける
const unsigned int MASK_ATTACK = BIT_FLAG_DAMAGE;
// punch して、ダメージも受けて、麻痺もする
const unsigned int MASK_PUNCH = BIT_FLAG_DAMAGE | BIT_FLAG_MAHI;
// defeat して、相手の HP を 0 にする
const unsigned int MASK_DEFEAT = BIT_FLAG_DAMAGE | BIT_FLAG_SENTOFUNO;
// 「毒」と「麻痺」を回復させる: ~MASK_DOKU_MAHI をかけることで回復
const unsigned int MASK_DOKU_MAHI = BIT_FLAG_DOKU | BIT_FLAG_MAHI;
int main() {
// start: 0000, 初期状態
unsigned int status = 0;
cout << "start: " << bitset<4>(status) << endl;
// attacked: 0001 になる
status |= MASK_ATTACK;
cout << "attacked: " << bitset<4>(status) << endl;
// punched: 0101 になる, HPはすでに満タンでないので、BIT_FLAG_DAMAGE の部分は変化なし
status |= MASK_PUNCH;
cout << "punched: " << bitset<4>(status) << endl;
// 「毒」または「麻痺」かどうかを判定する
if (status & MASK_DOKU_MAHI) {
cout << "You are doku or mahi." << endl;
}
// kaihuku: 0001 にする, HPは回復しない、麻痺は回復する
status &= ~MASK_DOKU_MAHI;
cout << "kaihuku: " << bitset<4>(status) << endl;
// defeat: 1001 にする, 戦闘不能にする
status |= MASK_DEFEAT;
cout << "sentofuno: " << bitset<4>(status) << endl;
// kaihuku: 1001 のまま、戦闘不能状態は回復しない
status &= ~MASK_DOKU_MAHI;
cout << "sentofuno no mama: " << bitset<4>(status) << endl;
return 0;
}
start: 0000
attacked: 0001
punched: 0101
You are doku or mahi.
kaihuku: 0001
sentofuno: 1001
sentofuno no mama: 1001
途中で「毒」または「麻痺」かどうかを判定する部分
if (status & MASK_DOKU_MAHI)
について、マスクビットを用いないと
if ((status & BIT_FLAG_DOKU) || (status & BIT_FLAG_MAHI))
のように書くことになります。マスクビットを用いることでより見やすくなる効果があるのがわかるかと思います (乱用は禁物ですが...)。
マスクビットのより実践的な使用について以下の記事が参考になります:
- サブネットマスク(subnet mask)とは? - CMAN インターネットサービス
- 割込みの概要と簡単な実例
- 第47章 KeyDataより、修飾キーを取り出す
- umask関数 - ビットマスクでパーミッションを制限する
- 画像のマスク処理
5. ビット演算は集合演算
数学の人向けです。ここからは内容が少しずつ難しくなっていきます。ビット演算によるフラグ管理の表を集合の言葉で記述してみます:
| やりたいこと | 実装 | 集合で言うと |
|---|---|---|
| ビット S に i 番目のフラグが立っているかどうか | if (S & (1<<i)) | かどうか |
| ビット S に i 番目のフラグが消えているかどうか | if (!(S & (1<<i))) | かどうか |
| ビット S に i 番目のフラグを立てる | S|= (1<<i) | = {} |
| ビット S に i 番目のフラグを消す | S &= ~(1<<i) | = - {} |
| ビット S に何個のフラグが立っているか | __builtin_popcount(S) | の要素数 |
| すべてのフラグが消えている状態 | 0 | 空集合 |
| すべてのフラグが立っている状態 | (1<<n) - 1 | {} |
| ビット S に i 番目のフラグを立てたもの | S|(1<<i) | {} |
| ビット S に i 番目のフラグを消したもの | S & ~(1<<i) | - {} |
| S & T | ||
| S|T | ||
| if (S & T) | かどうか | |
| if (!(S & T)) | かどうか |
6. bit 全探索
bit 全探索とは、 個の要素からなる集合 {} の部分集合をすべて調べ上げる手法のことです。なお、ここでは、bit 全探索の方法と具体例を簡単に記していますが、より詳細な解説は以下の記事で行いました。疑問点が残った場合には、ぜひ読んでもらえたらと思います。
さて、bit 全探索は、以下のように実施できます:
#include <iostream>
#include <vector>
using namespace std;
int main() {
int n = 5;
// {0, 1, ..., n-1} の部分集合の全探索
for (int bit = 0; bit < (1<<n); ++bit)
{
/* bit で表される集合の処理を書く */
}
}
本当に出来ていることを確認してみましょう。
#include <iostream>
#include <vector>
using namespace std;
int main() {
int n = 5;
// {0, 1, ..., n-1} の部分集合の全探索
for (int bit = 0; bit < (1<<n); ++bit)
{
/* bit で表される集合の処理を書く */
/* きちんとできていることを確認してみる */
// bit の表す集合を求める
vector<int> S;
for (int i = 0; i < n; ++i) {
if (bit & (1<<i)) { // i が bit に入るかどうか
S.push_back(i);
}
}
// bit の表す集合の出力
cout << bit << ": {";
for (int i = 0; i < (int)S.size(); ++i) {
cout << S[i] << " ";
}
cout << "}" << endl;
}
}
0: {}
1: {0 }
2: {1 }
3: {0 1 }
4: {2 }
5: {0 2 }
6: {1 2 }
7: {0 1 2 }
8: {3 }
9: {0 3 }
10: {1 3 }
11: {0 1 3 }
12: {2 3 }
13: {0 2 3 }
14: {1 2 3 }
15: {0 1 2 3 }
16: {4 }
17: {0 4 }
18: {1 4 }
19: {0 1 4 }
20: {2 4 }
21: {0 2 4 }
22: {1 2 4 }
23: {0 1 2 4 }
24: {3 4 }
25: {0 3 4 }
26: {1 3 4 }
27: {0 1 3 4 }
28: {2 3 4 }
29: {0 2 3 4 }
30: {1 2 3 4 }
31: {0 1 2 3 4 }
確かに {0, 1, 2, 3, 4} の部分集合をすべて列挙できていますね。
それでは bit 全探索を用いて具体的な問題を解いてみたいと思います。組合せ最適化の分野では非常に有名な問題で、効率よく解けるアルゴリズムは恐らく存在しないと広く信じられています。もし万が一この問題を効率よく解けるアルゴリズムが開発できたならば、世界中のセキュリティを支えているRSA公開鍵暗号を効率よく解読するアルゴリズムも開発できることがわかっており、そのインパクトは半端ではないです。ノーベル賞も夢じゃないです。この辺りの事情に興味のある方はNP完全問題について調べていただければと思います。
部分和問題
個の整数 が与えられる。これらの整数から何個かの整数を選んで総和を とすることができるかどうかを判定せよ。
【制約】
・
・
・
【数値例】
1)
答え: Yes (2 と 9 を選べばよいです)
2)
答え: No
個の要素からなる集合 {} の部分集合をすべて列挙して調べ上げましょう。ここまでで整理した集合演算技法を用いて、以下のように実装できます。
#include <iostream>
using namespace std;
/* 入力 */
int n;
int a[25]; // 余裕をもってサイズ 25 に
int K;
int main() {
cin >> n;
for (int i = 0; i < n; ++i) cin >> a[i];
cin >> K;
// 全探索 --- bit は {0, 1, ..., n-1} の 2^n 通りの部分集合全体を動きます。
bool exist = false;
for (int bit = 0; bit < (1<<n); ++bit)
{
int sum = 0; // 部分集合の和
for (int i = 0; i < n; ++i) {
if (bit & (1<<i)) { // i が S に入っているなら足す
sum += a[i];
}
}
// sum が K に一致するか
if (sum == K) exist = true;
}
if (exist) cout << "Yes" << endl;
else cout << "No" << endl;
}
さて、この解法では例えば となると計算時間的に破綻してしまいます。for 文のループ回数が 回あるのですが、 であり、1秒間で処理できる回数は最大でも 回程度なので到底無理です。
しかしなんと、この問題は 程度でも解くことのできる解法があります!!! (しかしこれでもまだ効率よく解けると認められる解法ではないです)。興味のある方は擬多項式時間アルゴリズムについて調べるとともに、以下の記事を読んでいただけたらと思います:
7. 与えられた部分集合の部分集合を列挙
bit 全探索は {} の部分集合を列挙するアルゴリズムでした。今度は、例えば として、{} のように必ずしも のすべてが揃っているわけではない集合が与えられて、その部分集合を列挙する方法を考えます。
これは次のように実現できます:
#include <iostream>
#include <vector>
using namespace std;
int main() {
int n = 10;
int A = (1<<2) | (1<<3) | (1<<5) | (1<<7); // {A = {2, 3, 5, 7}
for(int bit = A; ; bit = (bit-1) & A) {
/* ここに処理を書く */
// 最後の 0 で break
if (!bit) break;
}
}
確かめてみましょう。
#include <iostream>
#include <vector>
using namespace std;
int main() {
int n = 10;
int A = (1<<2) | (1<<3) | (1<<5) | (1<<7); // {A = {2, 3, 5, 7}
for(int bit = A; ; bit = (bit-1) & A) {
/* ここに処理を書く */
/* きちんとできていることを確認してみる */
// bit の表す集合を求める
vector<int> S;
for (int i = 0; i < n; ++i) {
if (bit & (1<<i)) { // i が bit に入るかどうか
S.push_back(i);
}
}
// bit の表す集合の出力
cout << bit << ": {";
for (int i = 0; i < (int)S.size(); ++i) {
cout << S[i] << " ";
}
cout << "}" << endl;
// 最後の 0 で break
if (!bit) break;
}
}
172: {2 3 5 7 }
168: {3 5 7 }
164: {2 5 7 }
160: {5 7 }
140: {2 3 7 }
136: {3 7 }
132: {2 7 }
128: {7 }
44: {2 3 5 }
40: {3 5 }
36: {2 5 }
32: {5 }
12: {2 3 }
8: {3 }
4: {2 }
0: {}
確かにできていますね。こんなものがどこで必要になるのかと疑問に思うかもしれませんが、例えば な bit DP を実装するときにこのようなことをしたくなります。
8. next_combination
今度は 個の要素の集合 {} の部分集合のうち、要素数が のもののみを列挙する方法を考えます。これは以下のように実現できます (ただし、以下のコードは のときには動作しないので、その場合は例外処理する必要があります):
#include <iostream>
#include <vector>
using namespace std;
/* next combination */
int next_combination(int sub) {
int x = sub & -sub, y = sub + x;
return (((sub & ~y) / x) >> 1) | y;
}
int main() {
int n = 5; // {0, 1, 2, 3, 4} の部分集合を考える
int k = 3;
int bit = (1<<k)-1; // bit = {0, 1, 2}
for (;bit < (1<<n); bit = next_combination(bit)) {
/* ここに処理を書く */
}
}
確かめてみましょう。
#include <iostream>
#include <vector>
using namespace std;
/* next combination */
int next_combination(int sub) {
int x = sub & -sub, y = sub + x;
return (((sub & ~y) / x) >> 1) | y;
}
int main() {
int n = 5; // {0, 1, 2, 3, 4} の部分集合を考える
int k = 3;
int bit = (1<<k)-1; // bit = {0, 1, 2}
for (;bit < (1<<n); bit = next_combination(bit)) {
/* ここに処理を書く */
/* きちんとできていることを確認してみる */
// bit の表す集合を求める
vector<int> S;
for (int i = 0; i < n; ++i) {
if (bit & (1<<i)) { // i が bit に入るかどうか
S.push_back(i);
}
}
// bit の表す集合の出力
cout << bit << ": {";
for (int i = 0; i < (int)S.size(); ++i) {
cout << S[i] << " ";
}
cout << "}" << endl;
}
}
7: {0 1 2 }
11: {0 1 3 }
13: {0 2 3 }
14: {1 2 3 }
19: {0 1 4 }
21: {0 2 4 }
22: {1 2 4 }
25: {0 3 4 }
26: {1 3 4 }
28: {2 3 4 }
確かにできていますね!ここまで来ると大分マニアックですが、bit 演算は想像以上に色んなことができます。これが使えそうな問題として以下があります (使わなくてもできます):
9. Xorshift
ビットを用いたシンプルな乱数生成方法です。乱数の質が高い割に超高速です!
C 言語の rand() よりずっと速いです。乱数の質も、メルセンヌツイスターには及ばないものの、 の周期を持っていて値の偏りが小さく、実用上十分なことがほとんどです。高速な乱数生成を行いたい際には是非とも使用していきたいところです。
参考: Xorshift の論文
実装もとてつもなくシンプルです。以下に示すようにメイン部分はたった 4 行で書けます!
#include <iostream>
using namespace std;
unsigned int randInt() {
static unsigned int tx = 123456789, ty=362436069, tz=521288629, tw=88675123;
unsigned int tt = (tx^(tx<<11));
tx = ty; ty = tz; tz = tw;
return ( tw=(tw^(tw>>19))^(tt^(tt>>8)) );
}
int main() {
// サイコロを 100 回振ってみる
for (int i = 1; i <= 100; ++i) {
cout << randInt() % 6 + 1 << ", ";
if (i % 10 == 0) cout << endl; // 10 回ごとに改行
}
return 0;
}
3, 1, 1, 3, 1, 5, 4, 3, 1, 2,
3, 4, 5, 6, 5, 2, 5, 5, 5, 5,
3, 1, 1, 5, 6, 4, 4, 5, 1, 2,
2, 1, 5, 3, 4, 2, 3, 1, 4, 6,
3, 5, 1, 2, 2, 1, 2, 3, 1, 6,
1, 2, 6, 3, 1, 1, 4, 1, 5, 1,
3, 6, 1, 5, 2, 1, 1, 3, 6, 1,
5, 3, 4, 5, 1, 3, 5, 1, 5, 4,
6, 1, 6, 5, 5, 6, 3, 4, 2, 3,
2, 1, 3, 6, 1, 6, 1, 2, 1, 6,
100,000 回サイコロを振ってそれぞれの回数を数えてみます。
#include <iostream>
#include <map>
using namespace std;
unsigned int randInt() {
static unsigned int tx = 123456789, ty=362436069, tz=521288629, tw=88675123;
unsigned int tt = (tx^(tx<<11));
tx = ty; ty = tz; tz = tw;
return ( tw=(tw^(tw>>19))^(tt^(tt>>8)) );
}
int main() {
int count[6] = {0};
for (int i = 0; i < 100000; ++i) {
int rng = randInt() % 6;
count[rng]++;
}
for (int i = 0; i < 6; ++i) {
cout << i+1 << ": " << count[i] << " 回" << endl;
}
return 0;
}
1: 16602 回
2: 16512 回
3: 16556 回
4: 16689 回
5: 16939 回
6: 16702 回
かなり均等な結果となっていますね!
10. Binary Indexed Tree (BIT)
ビットを鮮やかに使いこなすデータ構造 BIT です。名前が凄まじくまぎらわしい!!!!!
BIT は区間に対する処理を高速に実現できるようになるデータ構造です。以下のようなクエリが大量に飛んでくる状況を考えてみましょう (a や b や v の値はクエリ毎に変わる想定です):
- 配列の a 番目から b 番目までに v を加算する
- 配列の a 番目から b 番目までの総和を求める
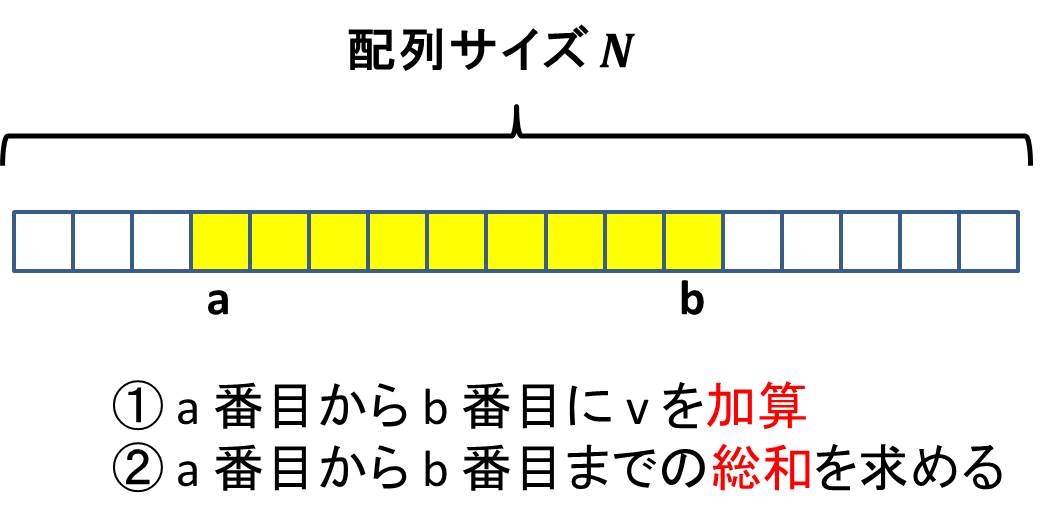
普通にやるとこれらはそれぞれ b - a + 1 箇所にアクセスすることになります。もし配列が巨大な場合、このようなクエリが大量に飛んで来られると途方もない時間がかかることになります。ビックデータという言葉が至るところに飛び交う昨今、このような大規模データを扱う大量のクエリを高速に実施していくタイプの要求はひたすらに高まっています。
そしてなんと、BIT を用いると、上のクエリをともに超高速に実現することができます!!!
具体的には配列サイズを とすると、普通にやったら かかるクエリを、 で実施することができます。ここでは詳しい解説は省略して、以下の資料を参照していただけたらと思います:
- Binary Indexed Tree のはなし (非常によくまとまっています)
- Peter M. Fenwick, 1994: A New Data Structure for Cumulative Frequency Tables (元論文です)
11. bit DP
最後にここまでに登場したビット演算技法を用いて bit DP な処理をサッと書いてみましょう。bit DP は、 個の要素の順列 ( 通りあります) としてありうるものの中から最適なものを求めたい場面でしばしば使えるテクニックです。bit DP は以下のような動的計画法フレームワークです:
- [] := 全体集合 {} の部分集合 について、その中で順序を最適化したときの、 の中での最小コスト
bit DP フレームワークでは、以下のような漸化式が成立することが多いです:
- [] = ([ - {}] + cost( \ {}, ))
この式の意味を簡単に解説します。
についてその中で順序を最適化したときのコスト [] を計算したいのですが、その順序の最後の要素がなんだったかで場合分けします:
の最後が だったとき、 の最後の を除いた部分集合についての最適解は [ - {}] になります。 - {} に を加えて増えるコストを cost( \ {}, ) とすると、結局最小コストは [ - {}] + cost( - {}, ) になります。
あとは を の範囲で全部試してあげて、総合的に一番コストが小さかったものを採用します。以上をまとめると bit DP フレームワークは以下のように表せます:
<bit DP 遷移式>
- [] = ([ - {}] + cost( - {}, ))
<初期値>
- [0] = 0 (何もない初期状態)
<最終的な最小コスト>
- [(1<<) - 1]
bit DP フレームワークを適用できる具体的な問題として、これまた組合せ最適化の分野では非常に有名な問題である巡回セールスマン問題を考えてみます。この問題もまた、効率よく解けるアルゴリズムは存在しないと広く信じられている NP 困難問題であり、万が一効率よく解けるアルゴリズムを開発できたらノーベル賞級です。
巡回セールスマン問題
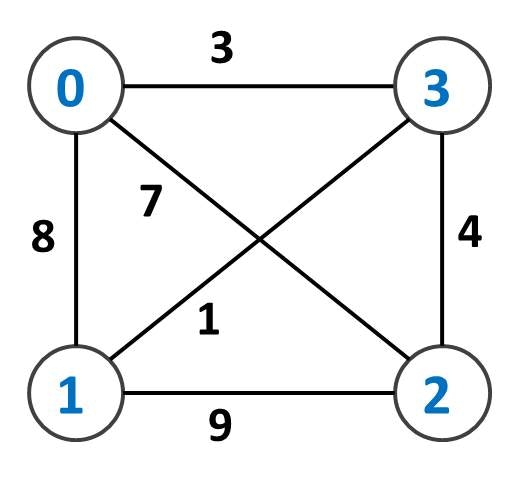
個の都市を、好きな都市から出発してちょうど一度ずつすべての都市を訪れたい。一度訪れた都市にはもう一度行くことはできない。所要時間を最短になるようにせよ。なお、街 から街 へと移動するのにかかる時間 [][] が与えられる。
【制約】
・
・
・
・
【数値例】
1)
0 5 2
5 0 4
2 4 0
答え: 6 (0 -> 2 -> 1 の順にだどると 6 秒で行けます)
2)
0 8 7 3
8 0 9 1
7 9 0 4
3 1 4 0
答え: 11 (1 -> 3 -> 0 -> 2 の順にたどると 11 秒で行けます)
まさに、 個の都市を巡る順序 ( 通りあります) を最適化する問題ですね。bit DP フレームワークに乗せて
- [] := 全体集合 {} の部分集合 について、その中で順序を最適化したときの、 の中での最小コスト
としたくなるのですが、今回は少しだけ工夫が必要です。bit DP の漸化式を見ると
- [] = ([ - {}] + cost( - {}, ))
となっており、cost( - {}, ) を計算できる必要があります。しかしこれは、 - {} のうち、どの都市が最後だったかに依存 (最後の都市が なら dist[][] です) してしまうため、このままでは一つに決まりません。そこで次のように DP テーブルを修正します:
- [][] := 全体集合 {} の部分集合 について、最後が であるという制約の下で順序を最適化したときの、 の中での最小コスト
DP 漸化式の方も少々の修正で実現できます:
- [][] = ([ - {}][] + dist[][])
今度は の最後は だとわかっているため、 - {} の最後が何かで場合分けしています。また初期値と最終的な値は次のようになります:
<初期値>
- [1<<][] ( からスタート)
<最終的な最小コスト>
- [(1<<) - 1][]
以上を実装すると以下のようになります。今回はメモ化再帰の形式で実装してみます。
#include <iostream>
#include <bitset>
using namespace std;
const int INF = 100000000; // 十分大きな値
/* 入力 */
int N;
int dist[21][21];
/* メモ再帰 */
int dp[(1<<20) + 1][21]; // dpテーブルは余裕をもったサイズにする
int rec(int bit, int v)
{
// すでに探索済みだったらリターン
if (dp[bit][v] != -1) return dp[bit][v];
// 初期値
if (bit == (1<<v)) {
return dp[bit][v] = 0;
}
// 答えを格納する変数
int res = INF;
// bit の v を除いたもの
int prev_bit = bit & ~(1<<v);
// v の手前のノードとして u を全探索
for (int u = 0; u < N; ++u) {
if (!(prev_bit & (1<<u))) continue; // u が prev_bit になかったらダメ
// 再帰的に探索
if (res > rec(prev_bit, u) + dist[u][v]) {
res = rec(prev_bit, u) + dist[u][v];
}
}
return dp[bit][v] = res; // メモしながらリターン
}
int main()
{
// 入力
cin >> N;
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
cin >> dist[i][j];
}
}
// テーブルを全部 -1 にしておく (-1 でなかったところは探索済)
for (int bit = 0; bit < (1<<N); ++bit) for (int v = 0; v < N; ++v) dp[bit][v] = -1;
// 探索
int res = INF;
for (int v = 0; v < N; ++v) {
if (res > rec((1<<N)-1, v)) {
res = rec((1<<N)-1, v);
}
}
cout << res << endl;
}
bit DP による計算時間の改善効果
bit DP は、 個の要素の順列としてありうるものの中から最適なものを求めたい場面で使えるフレームワークでした。計算時間の改善は、 から になります (巡回セールスマン問題の場合は )。
計算時間を改善しても結局指数時間なので、あまり有効でない雰囲気も漂わせていますが、 な全探索だと 程度までしか実施できない探索が、 程度までできるようになります。
| 計算量 | |||||||
|---|---|---|---|---|---|---|---|
| 1 | 25 | 100 | 225 | 400 | 625 | 900 | |
| 2 | 160 | 10,240 | 491,520 | 20,971,520 | 838,860,800 | 32,212,254,720 | |
| 1 | 120 | 3,628,800 | 1,307,674,368,000 | - | - | - |
この延命のような の伸びがクリティカルに効いてくる場面も少なくありません。私自身も実務案件で bitDP が有効に利用できた場面が過去二度ほどありました。
付録: next_combination の成立理由
今まで出て来た例のうち、next_combination はなぜあのような実装で実現できるのかがあまり自明ではありません。詳しく知りたい方はプログラミングコンテストチャレンジブックの P.143〜145 のコラムを読んでいただければと思います。
おおまかに以下のような性質を利用しています:
- bit の最も右の 1 のみを抽出する: nbit = bit & -bit (BIT でもおなじみの処理です)
- bit の最も右の 1 を 0 にする: nbit = bit & (bit - 1)
-1. おわりに
ビットが活用できる場面について、典型的なものから高度なアルゴリズムまで幅広く特集してみました。本特集がどこかでなんらかの課題の解決に寄与できたならば、とても嬉しく思います。


