動作環境
C++ builder XE4
やりたいこと
- 左欄に(key, value)のTEditがある
- 右欄に(key, value)のTEditがある
- ボタン押下
- 右欄の(key, value)をもとに左欄のkeyが同じTEditを探し
- その値をvalueで書換える
実装内容
二種類にて実装した
- A. 配列の使用
- 利点: keyを見つけたときに対応するvalueのTEditが確定する
- 欠点: 配列を用意する必要がある
- B. コンポーネント名からKeyを探し、FindComponentでValueを探す
- 利点: 配列を事前に用意する必要がない
- 項目数増加の時のミスを抑止
- 欠点: ルールに則った(一種類の)名前のコンポーネントだけを処理対象とする
- 拡張可能ではあるが
- 利点: 配列を事前に用意する必要がない
実装
Unit1.h
//---------------------------------------------------------------------------
#ifndef Unit1H
#define Unit1H
//---------------------------------------------------------------------------
#include <System.Classes.hpp>
#include <Vcl.Controls.hpp>
#include <Vcl.StdCtrls.hpp>
#include <Vcl.Forms.hpp>
#include <Vcl.Grids.hpp>
#include <Vcl.ExtCtrls.hpp>
//---------------------------------------------------------------------------
class TForm1 : public TForm
{
__published: // IDE で管理されるコンポーネント
TPanel *PNL_left;
TEdit *Device_L01;
TLabel *Label1;
TEdit *Item_L01;
TLabel *Label2;
TEdit *Device_L02;
TEdit *Item_L02;
TEdit *Device_L03;
TEdit *Item_L03;
TEdit *Device_L04;
TEdit *Item_L04;
TPanel *PNL_right;
TEdit *Device_R01;
TLabel *Label3;
TEdit *Item_R01;
TLabel *Label4;
TEdit *Device_R02;
TEdit *Item_R02;
TEdit *Device_R03;
TEdit *Item_R03;
TEdit *Device_R04;
TEdit *Item_R04;
TButton *B_toLeft1;
TButton *B_toLeft2;
void __fastcall B_toLeft1Click(TObject *Sender);
void __fastcall B_toLeft2Click(TObject *Sender);
private: // ユーザー宣言
static const int kNumDevice = 4; //
TEdit *m_deviceLefts[kNumDevice]; // replaceValue_arrayのKeyコンポーネント
TEdit *m_itemLefts[kNumDevice]; // replaceValue_arrayのValueコンポーネント
void __fastcall replaceValue_array(String keystr, String valstr);
void __fastcall replaceValue_findOnPanel(TPanel *pnlPtr, String keystr, String valstr);
public: // ユーザー宣言
__fastcall TForm1(TComponent* Owner);
};
//---------------------------------------------------------------------------
extern PACKAGE TForm1 *Form1;
//---------------------------------------------------------------------------
#endif
Unit1.cpp
//---------------------------------------------------------------------------
#include <vcl.h>
#pragma hdrstop
#include "Unit1.h"
//---------------------------------------------------------------------------
#pragma package(smart_init)
#pragma resource "*.dfm"
TForm1 *Form1;
//---------------------------------------------------------------------------
__fastcall TForm1::TForm1(TComponent* Owner)
: TForm(Owner)
{
// Left Items
// replaceValue_array()にて使用
m_deviceLefts[0] = Device_L01;
m_deviceLefts[1] = Device_L02;
m_deviceLefts[2] = Device_L03;
m_deviceLefts[3] = Device_L04;
m_itemLefts[0] = Item_L01;
m_itemLefts[1] = Item_L02;
m_itemLefts[2] = Item_L03;
m_itemLefts[3] = Item_L04;
}
//---------------------------------------------------------------------------
// イベント
void __fastcall TForm1::B_toLeft1Click(TObject *Sender)
{
// keystr: 探索のキー
// valstr: 更新内容
// keystr, valstr
replaceValue_array(Device_R01->Text, Item_R01->Text);
replaceValue_array(Device_R02->Text, Item_R02->Text);
replaceValue_array(Device_R03->Text, Item_R03->Text);
replaceValue_array(Device_R04->Text, Item_R04->Text);
}
void __fastcall TForm1::B_toLeft2Click(TObject *Sender)
{
TPanel *pnlPtr = PNL_left; // 対象TPanel
// keystr: 探索のキー
// valstr: 更新内容
// keystr, valstr
replaceValue_findOnPanel(pnlPtr, Device_R01->Text, Item_R01->Text);
replaceValue_findOnPanel(pnlPtr, Device_R02->Text, Item_R02->Text);
replaceValue_findOnPanel(pnlPtr, Device_R03->Text, Item_R03->Text);
replaceValue_findOnPanel(pnlPtr, Device_R04->Text, Item_R04->Text);
}
//---------------------------------------------------------------------------
// private function
//
void __fastcall TForm1::replaceValue_array(String keystr, String valstr)
{
// 方法A. 配列を使う
for(int idx=0; idx < kNumDevice; idx++) {
if (m_deviceLefts[idx] == NULL) {
continue;
}
if (m_deviceLefts[idx]->Text != keystr) {
continue;
}
m_itemLefts[idx]->Text = valstr;
}
}
//
void __fastcall TForm1::replaceValue_findOnPanel(TPanel *pnlPtr, String keystr, String valstr)
{
// 方法B. コンポーネント名からKeyを探し、FindComponentでValueを探す
static const String kString_keyComponentName = L"Device"; // 対象となるTEditのコンポーネント名に含まれる文字列
static const String kPrefix_key = L"Device"; // Keyコンポーネント名のプリフィックス
static const String kPrefix_value = L"Item"; // Valueコンポーネント名のプリフィックス
for(int idx=0; idx < pnlPtr->ControlCount; idx++) {
// 1. 対象Keyコンポーネントの探索
TEdit *devPtr = dynamic_cast<TEdit*>(pnlPtr->Controls[idx]);
if (devPtr == NULL) {
continue;
}
//
// 同じルールのコンポーネント名か (例: Device_XXX not Item_XXX)
if (devPtr->Name.Pos(kString_keyComponentName) == 0) {
continue;
}
//
if (devPtr->Text != keystr) { // 同じ項目のものだけ
continue;
}
// 2. 対象Valueコンポーネントの書換え
String itmCmpntNam = StringReplace(devPtr->Name, kPrefix_key, kPrefix_value, TReplaceFlags()<<rfReplaceAll);
TEdit *itmPtr = (TEdit *)FindComponent(itmCmpntNam);
if (itmPtr == NULL) {
continue; // not found
}
itmPtr->Text = valstr;
}
}
//---------------------------------------------------------------------------
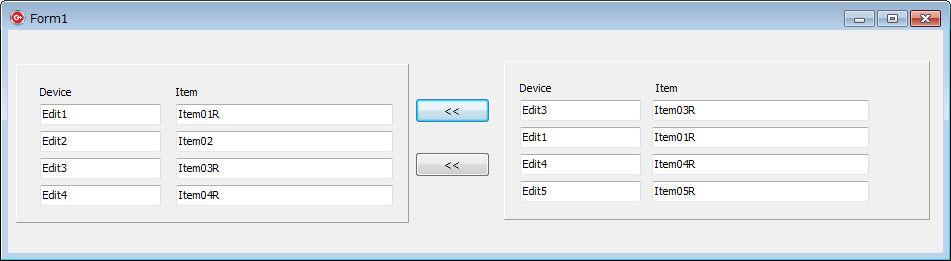
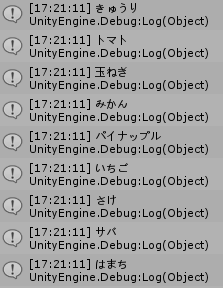
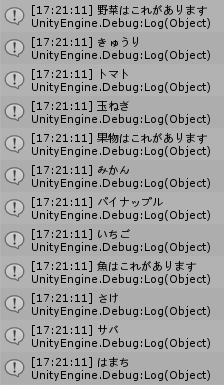
実行例
ソフト起動直後
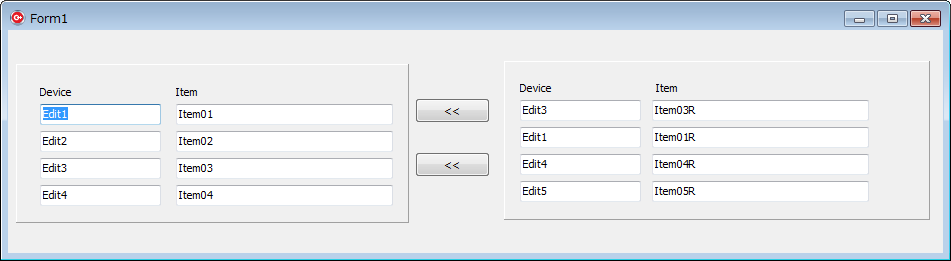
二つのボタンのいずれかを押した後