本記事はModern Best Practices for Testing in Javaの日本語訳です。元記事の著者から許可を得て翻訳、公開しています。
翻訳は不慣れなので変なところもあると思いますが、ご容赦ください。
メンテナンスしやすくて読みやすいテストコードは良いテストカバレッジを確立するために重要で、それにより何かを壊すことを恐れずに新機能の実装やリファクタリングが可能になります。この記事には、私がJavaでユニットテストや統合テストを長年に渡って書いて得られた多くのベストプラクティスが含まれています。それにはJUnit5やAssertJ、Testcontainers、Kotlinといったモダンな技術も含みます。中には当たり前と思われるようなこともあるかもしれませんし、あなたがソフトウェア開発やテストについての本で読んだことと相容れないこともあるかもしれません。
TL;DR
ヘルパー関数やパラメータ化テスト、AssertJの強力なアサーションを多用し、変数を使いすぎず、関連することだけを検証し、滅多に起こらないようなケースに対してテストを書くことを避けることで、小さくて明確なテストを書きましょう。
全ての関連があるパラメータを明確にし、データを正しく挿入し、継承よりもコンポジションを使うことで、自己完結しているテストを書きましょう。
本番コードの再利用を避け、出力値とハードコードされた値との比較に焦点を当てることで、ダンプテスト1を書きましょう。
KISSの原則 > DRY原則
完全な垂直スライドをテストする2ことに焦点を当て、インメモリデータベースの使用を避けて、本番環境に近いテストを書きましょう。
JUnit5とAssertJはとても良い選択です。
staticなアクセスを避け、コンストラクタインジェクションを使い、 Clock3を使い、非同期実行からビジネスロジックを分離することで、テストしやすい実装になるように労力を費やしましょう。
基本
Given, When, Then
テストは、1行の空行で分けられた3つのブロックで構成されるべきです。コードのそれぞれのブロックはできるだけ短くするべきです。ブロックを短くするためにサブ関数を使いましょう。
Given(入力): データの生成やモックの設定のようなテストの準備
When(実行): テスト対象のメソッドや動作の呼び出し
Then(出力): 出力や振る舞いが正しいかどうか検証するためのアサーションの実行
// 良い例@TestpublicvoidfindProduct(){insertIntoDatabase(newProduct(100,"Smartphone"));Productproduct=dao.findProduct(100);assertThat(product.getName()).isEqualTo("Smartphone");}“actual*” と “expected*” のプレフィックスを使う
// 悪い例ProductDTOproduct1=requestProduct(1);ProductDTOproduct2=newProductDTO("1",List.of(State.ACTIVE,State.REJECTED))assertThat(product1).isEqualTo(product2);同じ値かどうかのアサーションで変数を使うなら、変数名のプレフィックスとして"actual” や “expected” を付けましょう。これによって読みやすくなり、変数の意図が明確になります。その上、期待値と実測値を混同してしまう恐れが減ります。
// 良い例ProductDTOactualProduct=requestProduct(1);ProductDTOexpectedProduct=newProductDTO("1",List.of(State.ACTIVE,State.REJECTED))assertThat(actualProduct).isEqualTo(expectedProduct);// 素晴らしくて明確ランダム性のある値よりも固定値を使う
ランダム性のある値はテストを不安定にし、デバッグが困難になり、エラーメッセージが省略され、コードへのエラーの追跡が困難になるため避けましょう。
// 悪い例Instantts1=Instant.now();// 1557582788Instantts2=ts1.plusSeconds(1);// 1557582789intrandomAmount=newRandom().nextInt(500);// 232UUIDuuid=UUID.randomUUID();// d5d1f61b-0a8b-42be-b05a-bd458bb563ad
代わりに、全てに対して固定値を使用しましょう。固定値はテストの再現性を高くし、デバッグを容易にし、関連するコードの行への追跡を容易にするエラーメッセージが出力されます。
// 良い例Instantts1=Instant.ofEpochSecond(1550000001);Instantts2=Instant.ofEpochSecond(1550000002);intamount=50;UUIDuuid=UUID.fromString("00000000-000-0000-0000-000000000001");ヘルパー関数を使用することで、タイピング量を減らすことができます。
小さくて明確なテストを書く
ヘルパー関数を多用する
細かいコードや繰り返し出現するコードをサブ関数に抽出し、それに説明的な名前をつけましょう。それはテストを短く保ち、テストの要点が一目で簡単に把握できるようになるという意味で強力です。
// 悪い例@TestpublicvoidcategoryQueryParameter()throwsException{List<ProductEntity>products=List.of(newProductEntity().setId("1").setName("Envelope").setCategory("Office").setDescription("An Envelope").setStockAmount(1),newProductEntity().setId("2").setName("Pen").setCategory("Office").setDescription("A Pen").setStockAmount(1),newProductEntity().setId("3").setName("Notebook").setCategory("Hardware").setDescription("A Notebook").setStockAmount(2));for(ProductEntityproduct:products){template.execute(createSqlInsertStatement(product));}StringresponseJson=client.perform(get("/products?category=Office")).andExpect(status().is(200)).andReturn().getResponse().getContentAsString();assertThat(toDTOs(responseJson)).extracting(ProductDTO::getId).containsOnly("1","2");}// 良い例@TestpublicvoidcategoryQueryParameter2()throwsException{insertIntoDatabase(createProductWithCategory("1","Office"),createProductWithCategory("2","Office"),createProductWithCategory("3","Hardware"));StringresponseJson=requestProductsByCategory("Office");assertThat(toDTOs(responseJson)).extracting(ProductDTO::getId).containsOnly("1","2");}- データ(オブジェクト)の生成のため(
createProductWithCategory())と、複雑なアサーションのためにヘルパー関数を使ってください。ヘルパー関数には、テストに関係のあるパラメータのみを渡すようにします。それ以外の値については、適切なデフォルト値を使ってください。Kotlinでは、デフォルト引数を使うことで簡単に実現できます。Javaでは、擬似的なデフォルト引数を実現するためにメソッドチェーンとオーバーロードを使う必要があります - 可変長引数はテストコードをより簡潔にしてくれます(
ìnsertIntoDatabase()) - ヘルパー関数はシンプルな値をより簡単に生成するためにも使えます。拡張関数を使うことができるKotlinなら、よりやりやすいです。
// 良い例 (Java)Instantts=toInstant(1);// Instant.ofEpochSecond(1550000001)UUIDid=toUUID(1);// UUID.fromString("00000000-0000-0000-a000-000000000001")// 良い例 (Kotlin)valts=1.toInstant()valid=1.toUUID()
このヘルパー関数はKotlinではこのように実装します:
funInt.toInstant():Instant=Instant.ofEpochSecond(this.toLong())funInt.toUUID():UUID=UUID.fromString("00000000-0000-0000-a000-${this.toString().padStart(11, '0')}")変数を使い過ぎない
複数回使われている値を変数に抽出することは、開発者の常用手段です。
// 悪い例@Testpublicvoidvariables()throwsException{StringrelevantCategory="Office";Stringid1="4243";Stringid2="1123";Stringid3="9213";StringirrelevantCategory="Hardware";insertIntoDatabase(createProductWithCategory(id1,relevantCategory),createProductWithCategory(id2,relevantCategory),createProductWithCategory(id3,irrelevantCategory));StringresponseJson=requestProductsByCategory(relevantCategory);assertThat(toDTOs(responseJson)).extracting(ProductDTO::getId).containsOnly(id1,id2);}不幸にも、これはテストコードを著しく膨張させます。その上、得られるテスト失敗メッセージから、関連するコード行にさかのぼって値を追跡することは難しいです。
KISSの原則 > DRY原則
// 良い例@Testpublicvoidvariables()throwsException{insertIntoDatabase(createProductWithCategory("4243","Office"),createProductWithCategory("1123","Office"),createProductWithCategory("9213","Hardware"));StringresponseJson=requestProductsByCategory("Office");assertThat(toDTOs(responseJson)).extracting(ProductDTO::getId).containsOnly("4243","1123");}テストコードが短く保たれていれば(それは強く推奨されます)、同じ値がどこで使われているのか知るのに何の支障もありません。それに加え、メソッドはさらに短くなり、それゆえに理解が容易です。そして最後に、この場合の失敗メッセージは、コードをさかのぼって追跡することをより簡単にしてくれます。
既存のテストを「ただもう一つ小さなことをテストするだけ」のために拡張しない
// 悪い例publicclassProductControllerTest{@TestpublicvoidhappyPath(){// 大量のコードがここに...}}滅多に起こらないケースのテストを既存の(ハッピーパス4の)テストに追加することは魅惑的です。
しかし、そのテストは大きくて理解が難しいものになります。それは、その大きなテストによってカバーされる全ての関連するテストケースを把握することを困難にします。一般的に、こういったテストは「ハッピーパステスト」と呼ばれます5。
もしこのようなテストが失敗した時、何が壊れたのか正確に理解するのは難しいです。
// 良い例publicclassProductControllerTest{@TestpublicvoidmultipleProductsAreReturned(){}@TestpublicvoidallProductValuesAreReturned(){}@TestpublicvoidfilterByCategory(){}@TestpublicvoidfilterByDateCreated(){}}代わりに、期待する振る舞いについて全てわかる説明的な名前を持った新しいテストメソッドを作りましょう。はい、書く量は増えますが、関連する振る舞いだけをテストする、目的にぴったり合った明確なテストを作ることができます。繰り返しますが、ヘルパー関数はタイピング量を減らします。そして最後に、説明的な名前を持った、目的にぴったり合ったテストを追加することは、実装された振る舞いを記録する方法としてとても良いです。
テストしたいことだけをアサートする
本当にテストしたいことは何かということについて考えましょう。できるからといって、必要以上にアサートすることを避けましょう。さらに、前のテストにおいて既にテストしたことについて心に留めましょう。通常は、全てのテストにおいて同じことを何度もアサートする必要はありません。これによってテストが短く保たれ、明確に示され、期待する振る舞いについて気をそらされることがありません。
例について考えてみましょう。製品情報を返すHTTPエンドポイントについてテストします。テストスイートは下記のテストを含むべきです:
1 . データベースから取得した全ての値が正しいフォーマットで正しくマッピングされたJSONペイロードとして正しく返されることをアサートする大きな「マッピングテスト」。 equals()が正しく実装されているのであれば、AssertJの isEqualTo()(単一の要素用)または containsOnly()(複数の要素用)を使えば簡単にアサートできます。
StringresponseJson=requestProducts();ProductDTOexpectedDTO1=newProductDTO("1","evelope",newCategory("office"),List.of(States.ACTIVE,States.REJECTED));ProductDTOexpectedDTO2=newProductDTO("2","evelope",newCategory("smartphone"),List.of(States.ACTIVE));assertThat(toDTOs(responseJson)).containsOnly(expectedDTO1,expectedDTO2);2 . クエリパラメータの ?categoryの正しい振る舞いをチェックするテスト。私たちは正しくフィルタリングされるかをテストしたいわけです、全てのプロパティが正しくセットされているかどうかではなく。それは上記のケースで既にテストしています。したがって、返された製品IDだけを比較すれば十分です。
StringresponseJson=requestProductsByCategory("Office");assertThat(toDTOs(responseJson)).extracting(ProductDTO::getId).containsOnly("1","2");3 . 滅多に起こらないケース、または特別なビジネスロジックをチェックするテスト。たとえば、ペイロードの中の特定の値が正しく計算されているかどうか。このケースだと、興味があるのはペイロードのうち特定のJSONフィールドだけです。そのため、テスト対象のロジックのスコープを明確にして文書化するために、関連するフィールドだけをチェックすべきです。繰り返しますが、全てのフィールドを再度アサートする必要はありません、なぜならここでは関係ないからです。
assertThat(actualProduct.getPrice()).isEqualTo(100);
自己完結したテスト
関連するパラメータを隠さない(ヘルパー関数内)
// 悪い例insertIntoDatabase(createProduct());List<ProductDTO>actualProducts=requestProductsByCategory();assertThat(actualProducts).containsOnly(newProductDTO("1","Office"));はい、データの生成とアサーションのため、ヘルパー関数を使うべきです。しかし、それらをパラメータ化しなければいけません。テストのために重要で、テストによって制御される必要がある全てに対してパラメータを定義しましょう。ソースを読む人に対して、テスト内容を理解するために関数定義にジャンプさせるようなことを強いてはいけません。経験則: テストメソッドのみを見ることでテストの要点がわかるようにすべきです。
// 良い例insertIntoDatabase(createProduct("1","Office"));List<ProductDTO>actualProducts=requestProductsByCategory("Office");assertThat(actualProducts).containsOnly(newProductDTO("1","Office"));テストメソッドの中で正しくデータを挿入する
テストメソッドの中では全てが正しくある必要があります。再利用可能なデータの挿入コードを @Beforeメソッドに移動させることは魅惑的ですが、そうするとテストがどうなっているのか完全に理解するためには、ソースを読む人があちこち飛び回らなければならなくなります。繰り返しますが、データを挿入するヘルパー関数はこの繰り返し行うタスクを一行にすることの助けとなります。
継承よりもコンポジションを好む
テストクラスで複雑な継承階層を作ってはいけません。
// 悪い例classSimpleBaseTest{}classAdvancedBaseTestextendsSimpleBaseTest{}classAllInklusiveBaseTestextendsAdvancedBaseTest{}classMyTestextendsAllInklusiveBaseTest{}このような階層は理解を難しくしますし、あなたは結局現在のテストに必要ないたくさんのものを含むベースのテストクラスを継承することになる可能性が高いです。これはコードを読む人の気を散らし、バグが発生するかもしれません。継承は柔軟ではありません: AllInklusiveBaseTestから継承したものを全てを使うことは不可能ですが、そのスーパークラスの AdvancedBaseTestから継承したものは何もないでしょうか?6その上、コードを読む人は全体像を理解するために複数のベースクラスの間を飛び回らなければなりません。
「重複は誤った抽象化よりは良い」
RDX in 10 Modern Software Over-Engineering Mistakes
代わりに、コンポジションを使うことを推奨します。それぞれの特定のフィクスチャの作業ごとに小さいコードスニペットとクラスを書きましょう(テストデータベースの起動、スキーマの生成、データの挿入、モックのウェブサーバの起動)。@BeforeAllを付与したメソッドの中か、もしくは生成されたオブジェクトをテストクラスのフィールドに割り当てることでこれらのパーツを再利用しましょう。それで、あなたはこれらのパーツを再利用することで全ての新しいテストクラスを組み立てます。まるでレゴブロックのように。この方法で、全てのテストは自身にぴったり合った、内容を把握するのが簡単でハプニングとは無縁のフィクスチャを持ちます。そのテストクラスは、全ての関連がテストクラスの中で正しいため、自己完結しています。
// 良い例publicclassMyTest{// 継承の代わりのコンポジションprivateJdbcTemplatetemplate;privateMockWebServertaxService;@BeforeAllpublicvoidsetupDatabaseSchemaAndMockWebServer()throwsIOException{this.template=newDatabaseFixture().startDatabaseAndCreateSchema();this.taxService=newMockWebServer();taxService.start();}}// 別のファイルpublicclassDatabaseFixture{publicJdbcTemplatestartDatabaseAndCreateSchema()throwsIOException{PostgreSQLContainerdb=newPostgreSQLContainer("postgres:11.2-alpine");db.start();DataSourcedataSource=DataSourceBuilder.create().driverClassName("org.postgresql.Driver").username(db.getUsername()).password(db.getPassword()).url(db.getJdbcUrl()).build();JdbcTemplatetemplate=newJdbcTemplate(dataSource);SchemaCreator.createSchema(template);returntemplate;}}繰り返します:
KISSの原則 > DRY原則
ダンプテストは素晴らしい: 出力とハードコードされた値を比較する
本番コードを再利用しない
テストは本番コードをテストすべきです: 本番コードを再利用するのではなく。もしテストの中で本番コードを再利用すると、もはやそのコードはテストされない7ため、再利用されたコードによるバグを見落とすかもしれません。
// 悪い例booleanisActive=true;booleanisRejected=true;insertIntoDatabase(newProduct(1,isActive,isRejected));ProductDTOactualDTO=requestProduct(1);// 本番コードの再利用List<State>expectedStates=ProductionCode.mapBooleansToEnumList(isActive,isRejected);assertThat(actualDTO.states).isEqualTo(expectedStates);
代わりに、テストを書く時、入力と出力という観点から考えましょう。そのテストでは入力値をセットして、実際の出力値とハードコードされた値とを比較します。大抵の場合、コードの再利用は必要ありません。
// 良い例assertThat(actualDTO.states).isEqualTo(List.of(States.ACTIVE,States.REJECTED));
本番コードと同じロジックをテストで書かない
マッピングのコードはテストの中でロジックが再発明される、よくある例です。私たちのテストが、テストの最初に挿入されたエンティティと同じ値を含むことをアサートするのに使われるようなDTO戻り値を返すmapEntityToDto()メソッドを含むとしましょう。この場合、テストコードの中に本番コードと同じロジックを書いてしまう可能性が高いでしょう。それはバグを含むかもしれません。
// 悪い例ProductEntityinputEntity=newProductEntity(1,"evelope","office",false,true,200,10.0);insertIntoDatabase(input);ProductDTOactualDTO=requestProduct(1);// mapEntityToDto() は本番コードと同じマッピングロジックを含むProductDTOexpectedDTO=mapEntityToDto(inputEntity);assertThat(actualDTO).isEqualTo(expectedDTO);
繰り返しますが、解決策は actualDTOと、ハードコードされた値を含む手動で生成した参照オブジェクトを比較することです。それはとてもシンプルで、理解が容易で、エラーが発生しにくいです。
// 良い例ProductDTOexpectedDTO=newProductDTO("1","evelope",newCategory("office"),List.of(States.ACTIVE,States.REJECTED))assertThat(actualDTO).isEqualTo(expectedDTO);もし全ての値の比較はしたくなくて、それゆえに完全な参照オブジェクトを生成したくなければ、サブオブジェクトのみか、関連する値のみを比較することを検討してください。
ロジックを書きすぎない
繰り返しますが、テストとはほとんど入力と出力に関するものです。入力を提供し、実測値と期待値を比較することです。したがって、テストの中でロジックを書きすぎる必要はないし、そうすべきではありません。もし多数のループと条件を伴うロジックを実装するなら、テストは内容を把握するのが難しく、よりエラーが起こりやすくなります。さらに、複雑なアサーションロジックの場合には、AssertJの強力なアサーションがあなたのために重労働をやってくれます。8
現実に近いテスト
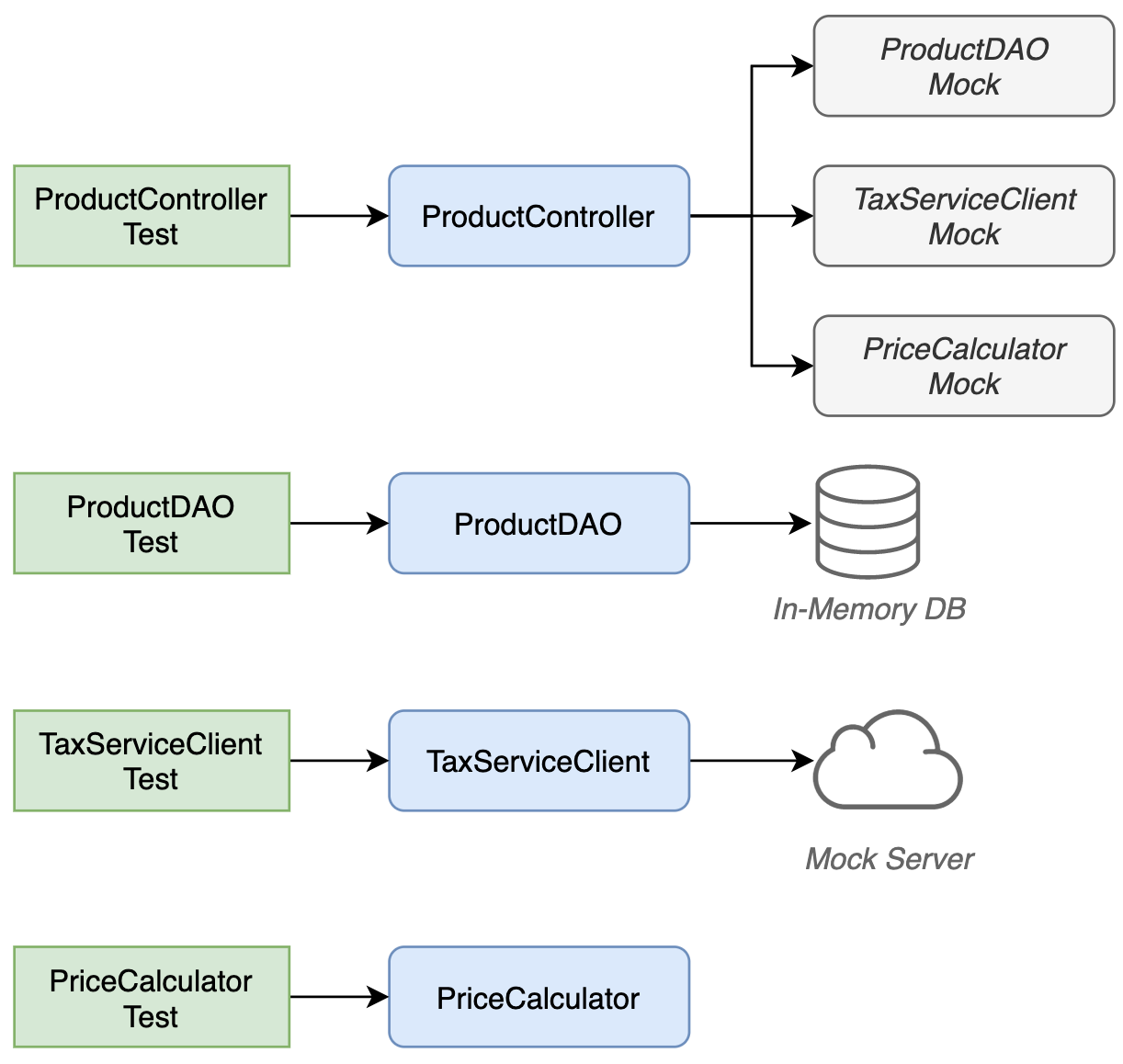
完全な垂直スライドのテストに集中する
一般的に、モックを使ってそれぞれのクラスを個別にテストすることが推奨されます。しかし、それには深刻な欠点があります: あなたは全てのクラスを統合してテストしているわけではなく、内部のクラスごとにテストがあるため、内部のリファクタリングが全てのテストを破壊するでしょう。そして最終的に、あなたは様々なテストを書き、メンテナンスしなければなりません。

各クラスを分離してモックを使ってテストすることは欠点をもたらします。
代わりに、統合テストに注目することを提案します。「統合テスト」とは、全てのクラスを一緒にして(本番コードのように)、全ての技術レイヤー(HTTP、ビジネスロジック、データベース)を完璧な垂直スライドで通り抜けるテストのことです。この方法だと、実装ではなく振る舞いをテストします。これらのテストは正確で、本番環境に近く、内部のリファクタリングに対して堅牢です。理想的に、一つのテストを書くだけで済みます。

統合テストに注目することを推奨します(= 現実のオブジェクトを一緒に書き、一度で全てをテストする)
このトピックについては、言うことがもっとたくさんあります。詳細は私のブログ記事の「Focus on Integration Tests Instead of Mock-Based Tests」をチェックしてください。
テストのためにインメモリデータベースを使用しない

インメモリデータベースを使うと、本番環境と違うデータベースに対してテストすることになります
テストのためにインメモリデータベースを使うこと(H2,HSQLDB,Fongo)は信頼性とテストのスコープを減らします。インメモリデータベースと本番環境で使われるデータベースとは異なる振る舞いをし、異なる結果を返すかもしれません。そのため、未熟なインメモリデータベースを基にしたテストは、本番環境のアプリケーションの正しい振る舞いをする保証がありません。その上、あなたは確かな(データベース固有の)機能を使用(またはテスト)することができない状況に簡単にぶつかります。なぜなら、インメモリデータベースはサポートしていないか、もしくは異なる動作をするからです。これについての詳細は、「Don’t use In-Memory Databases for Tests」の記事をチェックしてください。
解決策は実際のデータベースに対するテストを実行することです。幸運にも、Testcontainersというライブラリが、テストコードの中でコンテナを直接管理するための素晴らしいJavaのAPIを提供しています。実行速度を速めるには、ここを見てください。
Java/JVM
-noverify -XX:TieredStopAtLevel=1を使う
常に-noverify -XX:TieredStopAtLevel=1 JVMオプションを実行設定に追加しましょう。それによりテストが実行される前のJVMの起動時間が1〜2秒節約されます。これはIDE経由でテストを頻繁に実行する、テストの初期開発時に特に役に立ちます。
更新: Java 13から、 -noverifyは非推奨です。9
Tip: IntelliJ IDEAでは「JUnit」起動設定のテンプレートにこの引数を追加することができるため、新しい実行設定ごとに引数を追加する必要はありません。

AssertJを使う
AssertJは流れるような10型安全なAPIと、非常にバラエティに富んだアサーション、説明的なエラーメッセージを持った非常に強力で成熟したアサーションライブラリです。
あなたがしたいアサーションの全てがここにあります。これによりテストコードを短く保ちながら、ループや条件を持つ複雑なアサーションロジックを書かずに済みます。いくつかの例を示します:
assertThat(actualProduct).isEqualToIgnoringGivenFields(expectedProduct,"id");assertThat(actualProductList).containsExactly(createProductDTO("1","Smartphone",250.00),createProductDTO("1","Smartphone",250.00));assertThat(actualProductList).usingElementComparatorIgnoringFields("id").containsExactly(expectedProduct1,expectedProduct2);assertThat(actualProductList).extracting(Product::getId).containsExactly("1","2");assertThat(actualProductList).anySatisfy(product->assertThat(product.getDateCreated()).isBetween(instant1,instant2));assertThat(actualProductList).filteredOn(product->product.getCategory().equals("Smartphone")).allSatisfy(product->assertThat(product.isLiked()).isTrue());assertTrue()と assertFalse()を避ける
単純なassertTrue()や assertFalse()によるアサーションは不可解なエラーメッセージを出力するため避けましょう:
// 悪い例assertTrue(actualProductList.contains(expectedProduct));assertTrue(actualProductList.size()==5);assertTrue(actualProductinstanceofProduct);
expected: <true> but was: <false>
代わりに、特にカスタマイズしなくても11、良いエラーメッセージを出力するAssertJのアサーションを使いましょう。
// 良い例assertThat(actualProductList).contains(expectedProduct);assertThat(actualProductList).hasSize(5);assertThat(actualProduct).isInstanceOf(Product.class);
Expecting:
<[Product[id=1, name='Samsung Galaxy']]>
to contain:
<[Product[id=2, name='iPhone']]>
but could not find:
<[Product[id=2, name='iPhone']]>
もし本当にbooleanに対してチェックしなければならないのであれば、エラーメッセージを改善するためにAssertJのas()の使用を検討してください。
JUnit5を使う
JUnit5は(ユニット)テストのための最先端技術です。活発に開発され、多くの強力な機能(parameterized tests, grouping, conditional tests, lifecycle controlのような)を提供しています。
パラメータ化テストを使う
パラメータ化テストでは一つのテストを異なる値で複数回実行することができます。この方法では、テストコードを追加することなしに複数のケースを簡単にテストすることができます。そういったテストを書くための素晴らしい手段をJUnit5は提供します。@ValueSource、@EnumSource、@CsvSource、そして@MethodSourceです。
// 良い例@ParameterizedTest@ValueSource(strings=["§ed2d","sdf_","123123","§_sdf__dfww!"])publicvoidrejectedInvalidTokens(StringinvalidToken){client.perform(get("/products").param("token",invalidToken)).andExpect(status().is(400))}@ParameterizedTest@EnumSource(WorkflowState::class,mode=EnumSource.Mode.INCLUDE,names=["FAILED","SUCCEEDED"])publicvoiddontProcessWorkflowInCaseOfAFinalState(WorkflowStateitemsInitialState){// ...}私はこれらを広範囲に使うことを強く推奨します。なぜなら、最小限の努力でより多くのケースをテストできるからです。
最後に、パラメータで期待値もコントロールできる、より発展的なパラメータ化テストシナリオのために使用できる@CsvSourceと@MethodSourceのことを強調したいと思います。
@ParameterizedTest@CsvSource({"1, 1, 2","5, 3, 8","10, -20, -10"})publicvoidadd(intsummand1,intsummand2,intexpectedSum){assertThat(calculator.add(summand1,summand2)).isEqualTo(expectedSum);}@MethodSourceは、全ての関連するテストパラメータと期待値を含む専用のテストオブジェクトと組み合わせて使うと強力です。残念ながら、Javaでは、これらのデータ構造(POJO)を書くことが面倒です。それが、下記でこの機能の例を示すのにKotlinのデータクラスを使う理由です。
data classTestData(valinput:String?,valexpected:Token?)@ParameterizedTest@MethodSource("validTokenProvider")fun`parsevalidtokens`(data:TestData){assertThat(parse(data.input)).isEqualTo(data.expected)}privatefunvalidTokenProvider()=Stream.of(TestData(input="1511443755_2",expected=Token(1511443755,"2")),TestData(input="151175_13521",expected=Token(151175,"13521")),TestData(input="151144375_id",expected=Token(151144375,"id")),TestData(input="15114437599_1",expected=Token(15114437599,"1")),TestData(input=null,expected=null))テストをグループ化する
JUnit5の @Nestedはテストメソッドをグループ化するのに便利です。理にかなったグループは特定のタイプのテスト(InputIsXY、ErrorCasesのような)、またはテストの配下のそれぞれのメソッドを一つのグループにすることができます。(GetDesignとUpdateDesign)
publicclassDesignControllerTest{@NestedclassGetDesigns{@TestvoidallFieldsAreIncluded(){}@TestvoidlimitParameter(){}@TestvoidfilterParameter(){}}@NestedclassDeleteDesign{@TestvoiddesignIsRemovedFromDb(){}@Testvoidreturn404OnInvalidIdParameter(){}@Testvoidreturn401IfNotAuthorized(){}}}
JUnit5の@Nestedでグループ化
@DisplayNameまたはKotlinのバッククオートによる読みやすいテスト名
Javaでは、読みやすいテストの説明を書くのにJUnit5の@DisplayNameを使います。
publicclassDisplayNameTest{@Test@DisplayName("Design is removed from database")voiddesignIsRemoved(){}@Test@DisplayName("Return 404 in case of an invalid parameter")voidreturn404(){}@Test@DisplayName("Return 401 if the request is not authorized")voidreturn401(){}}
JUnit5の@DisplayNameを使った読みやすいテストメソッド名
Kotlinでは、バッククオートの中にメソッド名を書くことができ、半角スペースを含むこともできます。これで冗長性を避けつつ読みやすくすることができます。
@Testfun`designisremovedfromdb`(){}リモートサービスをモック化する
HTTPクライアントをテストするためには、リモートサービスをモック化する必要があります。私はそのためにOkHttpのWebMockServerを使うことを好みます。
MockWebServerserviceMock=newMockWebServer();serviceMock.start();HttpUrlbaseUrl=serviceMock.url("/v1/");ProductClientclient=newProductClient(baseUrl.host(),baseUrl.port());serviceMock.enqueue(newMockResponse().addHeader("Content-Type","application/json").setBody("{\"name\": \"Smartphone\"}"));ProductDTOproductDTO=client.retrieveProduct("1");assertThat(productDTO.getName()).isEqualTo("Smartphone");非同期コードのアサーションのためにAwaitilityを使う
Awaitilityは非同期コードのテストのためのライブラリです。最終的に失敗するまで、どれくらいの頻度でアサーションを行うのか簡単に定義できます。
privatestaticfinalConditionFactoryWAIT=await().atMost(Duration.ofSeconds(6)).pollInterval(Duration.ofSeconds(1)).pollDelay(Duration.ofSeconds(1));@TestpublicvoidwaitAndPoll(){triggerAsyncEvent();WAIT.untilAsserted(()->{assertThat(findInDatabase(1).getState()).isEqualTo(State.SUCCESS);});}この方法だと、不安定なThread.sleep()をテストの中で使うことを避けられます。
しかし、同期コードをテストすることのほうがはるかに簡単です。それが非同期実行と実際のロジックを分けるべき理由です。
ブートストラップDIは必要ない(Spring)
(Spring)DIフレームワークのブートストラップではテストが開始するまでに何秒かかかります。特にテストの初期開発の期間では、それによってフィードバックサイクルが遅くなります。
私が普段統合テストでDIを使わないのはそれが理由です。私は必要なオブジェクトを手動でnewを呼んでインスタンス化し、それらをまとめます。コンストラクタインジェクションを使っているなら、非常に簡単です。ほとんどの時間、あなたは自分が書いたビジネスロジックのテストをしたい。そのためにDIは必要ありません。一つの例として、統合テストについての私の投稿をチェックしてください。
一方で、Spring Boot 2.2では怠惰なBean初期化を簡単に使用できる機能が導入される予定で、DIベースのテストが著しくスピードアップするはずです。12
実装をテスト可能にする
staticアクセスを使わない。決して。これからも。
staticアクセスはアンチパターンです。第一に、それは依存性と副作用を難解にし、コード全体が理解しにくくなり、エラーが発生しやすくなります。第二に、staticアクセスはテスト容易性を害します。あなたはもはやオブジェクトを交換できません。しかしテストでは、あなたはモックまたは異なる設定を持った実際のオブジェクト(テストデータベースを指しているDAOのような)を使いたいはずです。
そのためstaticアクセスするコードの代わりに、staticではないメソッドにそのコードを書き、クラスをインスタンス化して、必要なオブジェクトのコンストラクタにそのオブジェクトを渡します。
// 悪い例publicclassProductController{publicList<ProductDTO>getProducts(){List<ProductEntity>products=ProductDAO.getProducts();returnmapToDTOs(products);}}// 良い例publicclassProductController{privateProductDAOdao;publicProductController(ProductDAOdao){this.dao=dao;}publicList<ProductDTO>getProducts(){List<ProductEntity>products=dao.getProducts();returnmapToDTOs(products);}}幸運にも、SpringのようなDIフレームワークがstaticアクセスを避ける簡単な方法を提供しています。私たちのために全てのオブジェクトの生成と配置を処理するからです。
パラメータ化
クラスの全ての関連する部分を、テストによってコントロール可能にしましょう。これは、この側面からコンストラクタのパラメータを作ることで実現できます。
たとえば、DAOのクエリ数の上限が1000になっているとします。この上限をテストするには、テストの中でデータベースエントリーを1001個生成することが求められるでしょう。この上限値をコンストラクタパラメータ化することで、その上限値が設定可能になります。本番環境では、このパラメータは1000です。テストでは、2を設定することができます。その上限機能のテストのために必要なテストエントリー数はたった3つだけで済みます。
コンストラクタインジェクションを使う
テスト容易性が低くなるため、フィールドインジェクションは邪悪です。
あなたはテストの中でのDI環境のブートストラップ、またはハッキーなリフレクションマジックを使わなければなりません。
そのため、コンストラクタインジェクションは好ましい方法です。なぜなら、テストの中で依存するオブジェクトのコントロールが簡単になるからです。
Javaでは、少し定型文が必要です。
// 良い例publicclassProductController{privateProductDAOdao;privateTaxClientclient;publicCustomerResource(ProductDAOdao,TaxClientclient){this.dao=dao;this.client=client;}}Kotlinでは、同じ内容がもっと簡潔になります。
// 良い例classProductController(privatevaldao:ProductDAO,privatevalclient:TaxClient){}Instant.now()またはnew Date()を使わない
本番コードでInstant.now()またはnew Date()を呼び出すことで現在のタイムスタンプを取得するようなことをしてはいけません。あなたがその振る舞いをテストしたいのであれば。
// 悪い例publicclassProductDAO{publicvoidupdateDateModified(StringproductId){Instantnow=Instant.now();// !Updateupdate=Update().set("dateModified",now);Queryquery=Query().addCriteria(where("_id").eq(productId));returnmongoTemplate.updateOne(query,update,ProductEntity.class);}}問題点は、その生成されたタイムスタンプをテストによってコントロールすることができないことです。テストの実行ごとに常に異なる値となるため、正確な値をアサートできません。代わりに、JavaのClockクラスを使いましょう。
// 良い例publicclassProductDAO{privateClockclock;publicProductDAO(Clockclock){this.clock=clock;}publicvoidupdateProductState(StringproductId,Statestate){Instantnow=clock.instant();// ...}}テストの中で、あなたは今clockのモックを生成できるようになり、それをProductDAOに渡して、そのclockのモックが固定のタイムスタンプを返すように設定できます。updateProductState()を呼んだ後、定義されたタイムスタンプがデータベースに挿入されたかどうかをアサートします。
非同期実行と実際のロジックを分ける
非同期コードをテストするのはトリッキーです。Awaitilityのようなライブラリは助けとなりますが、それはまだ面倒で、テストはまだ不安定です。もし可能なら、(多くの場合は同期的な)ビジネスロジックを非同期実行から分割することは理にかなっています。
たとえば、ビジネスロジックをProductControllerの中に配置することにより、簡単な同期実行でそれをテストすることができます。非同期的で並列的なロジックはProductSchedulerに集約され、分離してテストできます。
// 良い例publicclassProductScheduler{privateProductControllercontroller;@Scheduledpublicvoidstart(){CompletableFuture<String>usFuture=CompletableFuture.supplyAsync(()->controller.doBusinessLogic(Locale.US));CompletableFuture<String>germanyFuture=CompletableFuture.supplyAsync(()->controller.doBusinessLogic(Locale.GERMANY));StringusResult=usFuture.get();StringgermanyResult=germanyFuture.get();}}Kotlin
私のBest Practices for Unit Testing in Kotlinについての投稿は、Kotlinでテストを書くための多くのKotlin固有の推奨事項を含んでいます。